ترجمه کتاب ساخت برنامههای کاربردی با مدلهای پایه - انتشارات O’Reilly
BOOK: O'Reilly_AI_Engineering_Building_Applications_with_Foundation_Models
یک مدل زبانی، اطلاعات آماری درباره یک یا چند زبان را کدگذاری میکند. به طور شهودی، این اطلاعات به ما میگویند که یک کلمه چقدر احتمال دارد در یک زمینه خاص ظاهر شود. برای مثال، با توجه به زمینه «رنگ مورد علاقه من __ است»، یک مدل زبانی که انگلیسی را کدگذاری کرده است، بیشتر از «ماشین»، «آبی» را پیشبینی میکند.
ماهیت آماری زبانها قرنها پیش کشف شد. در داستان «ماجرای مردان رقصان» (۱۹۰۵)، شرلوک هولمز از اطلاعات آماری ساده انگلیسی برای رمزگشایی دنبالهای از figures چوبی مرموز استفاده کرد. از آنجایی که رایجترین حرف در انگلیسی E است، هولمز استنتاج کرد که رایجترین figure چوبی باید نمایانگر E باشد.
بعدها، کلود شانون از آمار پیشرفتهتری برای decipher کردن پیامهای دشمن در طول جنگ جهانی دوم استفاده کرد. کار او درباره چگونگی مدلسازی انگلیسی، در مقاله مهم او با عنوان «پیشبینی و آنتروپی انگلیسی چاپی» (۱۹۵۱) منتشر شد. بسیاری از مفاهیم معرفی شده در این مقاله، از جمله آنتروپی، هنوز برای مدلسازی زبان استفاده میشوند.
در روزهای اولیه، یک مدل زبانی فقط یک زبان را شامل میشد. اما امروزه، یک مدل زبانی میتواند چندین زبان را دربرگیرد.
واحد پایه یک مدل زبانی، توکن (token) است. یک توکن میتواند یک نویسه (character)، یک کلمه، یا بخشی از یک کلمه (مانند -tion) باشد که بستگی به مدل دارد. برای مثال، GPT-4 (مدل پشت ChatGPT) عبارت «I can’t wait to build AI applications» را به ۹ توکن تجزیه میکند. توجه کنید که در این مثال، کلمه «can’t» به دو توکن «can» و «’t» شکسته شده است.

فرآیند شکستن متن اصلی به توکنها، توکنسازی (tokenization) نامیده میشود. برای GPT-4، طول متوسط یک توکن تقریباً ¾ طول یک کلمه است. بنابراین، ۱۰۰ توکن تقریباً معادل ۷۵ کلمه است.
مجموعه تمام توکنهایی که یک مدل میتواند با آنها کار کند، واژگان (vocabulary) مدل نامیده میشود. شما میتوانید با تعداد کمی توکن، تعداد زیادی کلمه متمایز بسازید، مشابه نحوه استفاده از چند حرف الفبا برای ساخت بسیاری از کلمات. مدل Mixtral 8x7B اندازه واژگانی معادل ۳۲,۰۰۰ توکن دارد. اندازه واژگان GPT-4 برابر ۱۰۰,۲۵۶ توکن است. روش توکنسازی و اندازه واژگان توسط توسعهدهندگان مدل تعیین میشود.
چرا مدلهای زبانی به جای کلمه (word) یا نویسه (character)، از توکن استفاده میکنند؟
سه دلیل اصلی وجود دارد:
۱. در مقایسه با کاراکترها، توکنها به مدل اجازه میدهند کلمات را به اجزای معنادار تجزیه کنند. برای مثال، «cooking» میتواند به «cook» و «ing» شکسته شود که هر دو جزء حاوی بخشی از معنای کلمه اصلی هستند.
۲. از آنجایی که توکنهای منحصر به فرد کمتر از کلمات منحصر به فرد هستند، این امر اندازه واژگان مدل را کاهش داده و مدل را کارآمدتر میسازد.
۳. توکنها به مدل در پردازش کلمات ناشناخته نیز کمک میکنند. برای مثال، یک کلمه ساختگی مانند «chatgpting» میتواند به «chatgpt» و «ing» تقسیم شود که به مدل کمک میکند ساختار آن را درک کند. توکنها تعادلی بین داشتن واحدهای کمتر نسبت به کلمات و حفظ معنای بیشتر نسبت به نویسههای مجزا برقرار میکنند.
دو نوع اصلی مدل زبانی وجود دارد:
مدلهای زبانی پوشیده (masked language models) و مدلهای زبانی خودرگرسیو (autoregressive language models).
این دو بر اساس اطلاعاتی که برای پیشبینی یک توکن استفاده میکنند، تفاوت دارند:
مدل زبانی پوشیده: این نوع مدل آموزش دیده است تا توکنهای گمشده در هر نقطه از یک دنباله را با استفاده از زمینههای قبل و بعد از توکنهای گمشده پیشبینی کند. در essence، یک مدل زبانی پوشیده آموزش دیده است تا بتواند جای خالی را پر کند. برای مثال، با توجه به زمینه «My favorite __ is blue»، یک مدل زبانی پوشیده باید پیشبینی کند که جای خالی به احتمال زیاد «color» است. یک مثال شناخته شده از این نوع، BERT است. در زمان نوشتن این کتاب، مدلهای زبانی پوشیده معمولاً برای وظایف غیرتولیدی (non-generative) مانند تحلیل احساسات و طبقهبندی متن استفاده میشوند. آنها برای وظایفی که نیاز به درک کلی context دارند، مانند دیباگ کردن کد، نیز مفید هستند؛ جایی که مدل نیاز دارد هم کد قبل و هم بعد را بفهمد تا خطاها را شناسایی کند.
مدل زبانی خودرگرسیو: این نوع مدل آموزش دیده است تا توکن بعدی در یک دنباله را فقط با استفاده از توکنهای قبلی پیشبینی کند. این مدل پیشبینی میکند که بعد از «My favorite color is __» چه میآید. یک مدل خودرگرسیو میتواند به طور مداوم یک توکن پس از دیگری تولید کند. امروزه، مدلهای زبانی خودرگرسیو مدلهای انتخابی برای تولید متن هستند و به همین دلیل، محبوبیت بسیار بیشتری نسبت به مدلهای زبانی پوشیده دارند.
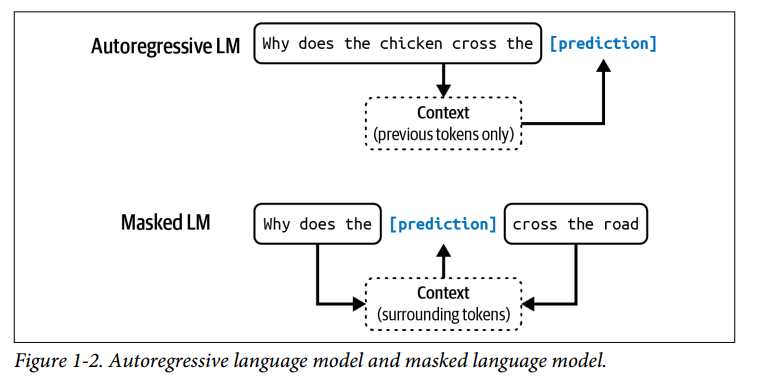
در این کتاب، مگر اینکه صراحتاً ذکر شود، «مدل زبانی» به یک مدل خودرگرسیو اشاره خواهد کرد.
خروجیهای مدلهای زبانی باز (open-ended) هستند. یک مدل زبانی میتواند از واژگان ثابت و محدود خود برای ساخت خروجیهای ممکن نامحدود استفاده کند. مدلی که میتواند خروجیهای open-ended تولید کند، تولیدی (generative) نامیده میشود، از این رو اصطلاح هوش مصنوعی تولیدی (generative AI) به وجود آمده است.
میتوانید یک مدل زبانی را به عنوان یک ماشین تکمیلکننده (completion machine) در نظر بگیرید: با دریافت یک متن (prompt)، سعی میکند آن متن را تکمیل کند. در اینجا یک مثال آورده شده است:
پِرامپت (از کاربر): “To be or not to be”
تکمیل (از مدل زبانی): “, that is the question.”
مهم است توجه داشته باشید که تکمیلها، پیشبینیهایی بر اساس احتمالات هستند و تضمینی برای صحیح بودن آنها وجود ندارد. این ماهیت احتمالاتی مدلهای زبانی، استفاده از آنها را هم بسیار هیجانانگیز و هم گاهی frustating میسازد.
هرچند ساده به نظر میرسد، اما تکمیل کردن به طور باورنکردنی قدرتمند است. بسیاری از وظایف، از جمله ترجمه، خلاصهسازی، کدنویسی و حل مسائل ریاضی، میتوانند به عنوان وظایف تکمیل قالببندی شوند.
مدلسازی زبان فقط یکی از الگوریتمهای یادگیری ماشین (ML) است. مدلهایی برای تشخیص اشیاء، مدلسازی موضوعی، سیستمهای پیشنهاددهنده، پیشبینی آب و هوا، پیشبینی قیمت سهام و غیره نیز وجود دارند. چه چیزی در مورد مدلهای زبانی خاص است که آنها را به مرکز رویکرد scalingی تبدیل کرد که منجر به «لحظه ChatGPT» شد؟
پاسخ این است که مدلهای زبانی میتوانند با استفاده از خود-نظارتی آموزش ببینند، در حالی که بسیاری از مدلهای دیگر نیاز به نظارت (supervision) دارند. نظارت به فرآیند آموزش الگوریتمهای ML با استفاده از دادههای برچسبدار (labeled data) اشاره دارد که میتواند گران و کند به دست آید. خود-نظارتی به غلبه بر گلوگاه برچسبزنی دادهها کمک میکند تا مجموعه دادههای بزرگتری برای یادگیری مدلها ایجاد شود و به طور مؤثر به مدلها اجازه scale up را میدهد.
با نظارت (supervision)، شما مثالها را برچسبگذاری میکنید تا رفتارهایی را که میخواهید مدل یاد بگیرد، نشان دهید و سپس مدل را با استفاده از این مثالها آموزش میدهید. پس از آموزش، میتوانید مدل را روی دادههای جدید اعمال کنید. به عنوان مثال، برای آموزش یک مدل شناسایی تقلب (fraud detection)، شما از نمونههایی از تراکنشها استفاده میکنید که هر کدام با برچسب «تقلب» یا «غیرتقلب» مشخص شدهاند. وقتی مدل از این نمونهها یاد گرفت، میتوانید از آن برای پیشبینی اینکه آیا یک تراکنش جدید تقلبی است یا خیر، استفاده کنید.
موفقیت مدلهای هوش مصنوعی در دهه ۲۰۱۰ در نظارت نهفته بود. مدلی که انقلاب یادگیری عمیق را آغاز کرد، AlexNet (Krizhevsky و همکاران، ۲۰۱۲)، یک مدل نظارتشده بود. این مدل آموزش دیده بود تا نحوه طبقهبندی بیش از ۱ میلیون تصویر در مجموعه داده ImageNet را یاد بگیرد. هر تصویر را در یکی از ۱۰۰۰ دسته مانند «ماشین»، «بالن» یا «میمون» طبقهبندی میکرد.
عیب نظارت این است که برچسبزنی دادهها گران و زمانبر است. اگر برچسبزنی یک تصویر برای یک نفر ۵ سنت هزینه داشته باشد، برچسبزنی یک میلیون تصویر برای ایمیج نت، ۵۰,۰۰۰ دلار هزینه در بر خواهد داشت. اگر بخواهید دو نفر متفاوت هر تصویر را برچسبزنی کنند - تا بتوانید کیفیت برچسب را cross-check کنید - هزینه دو برابر خواهد شد. از آنجایی که جهان بسیار بیشتر از ۱۰۰۰ شیء دارد، برای گسترش قابلیتهای مدلها برای کار با اشیاء بیشتر، باید برچسبهای دستههای بیشتری اضافه کنید. برای scale up کردن تا ۱ میلیون دسته بندی، تنها هزینه برچسبزنی به ۵۰ میلیون دلار افزایش مییابد.
برچسبزنی اشیاء روزمره کاری است که اکثر مردم بدون آموزش قبلی میتوانند انجام دهند. از این رو، میتوان آن را نسبتاً ارزان انجام داد. با این حال، همه وظایف برچسبزنی به این سادگی نیستند. تولید ترجمههای لاتین برای یک مدل انگلیسی به لاتین گرانتر است. برچسبزنی اینکه آیا یک سیتی اسکن نشانههایی از سرطان را نشان میدهد یا نه، هزینهای سرسامآور خواهد بود.
خود-نظارتی به غلبه بر گلوگاه برچسبزنی دادهها کمک میکند. در خود-نظارتی، به جای نیاز به برچسبهای صریح (explicit)، مدل میتواند برچسبها را از دادههای ورودی استنتاج کند. مدلسازی زبان self-supervised است زیرا هر دنباله ورودی، هم برچسبها (توکنهایی که باید پیشبینی شوند) و هم زمینههایی (contexts) که مدل میتواند برای پیشبینی این برچسبها استفاده کند را فراهم میکند. برای مثال، جمله “I love street food.” شش نمونه آموزشی تولید میکند، همان که در جدول 1-1 نشان داده شده است.
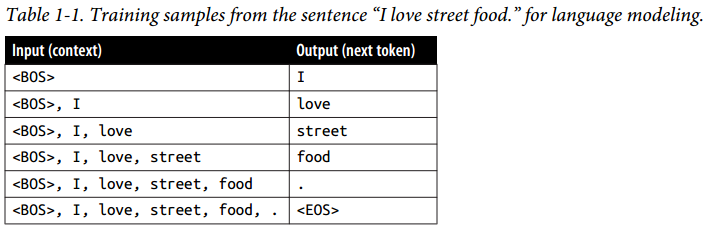
در جدول 1-1، <BOS> و <EOS> به ترتیب نشانگر آغاز و پایان یک دنباله (sequence) هستند.
این نشانگرها برای اینکه یک مدل زبانی بتواند با چندین دنباله کار کند، ضروری هستند. هر نشانگر معمولاً به عنوان یک توکن ویژه (special token) توسط مدل در نظر گرفته میشود. نشانگر پایان دنباله به ویژه اهمیت دارد، زیرا به مدلهای زبانی کمک میکند تا بدانند چه زمانی باید پاسخهای خود را به پایان برسانند.
یادگیری self-supervised با یادگیری بدون نظارت (unsupervised) متفاوت است. در یادگیری self-supervised، برچسبها از دادههای ورودی استنتاج میشوند. در یادگیری بدون نظارت، شما اصلاً به برچسب نیاز ندارید.
یادگیری self-supervised به این معنی است که مدلهای زبانی میتوانند از دنبالههای متنی بدون نیاز به هیچ برچسبزنی یاد بگیرند. از آنجایی که دنبالههای متنی همه جا وجود دارند - در کتابها، پستهای وبلاگ، مقالات و نظرات Reddit - امکان ساخت حجم عظیمی از دادههای آموزشی وجود دارد که به مدلهای زبانی اجازه میدهد تا scale up کنند و به LLM تبدیل شوند.
با این حال، LLM (Large Language Model ) به سختی یک اصطلاح علمی است. یک مدل زبانی چقدر باید بزرگ باشد تا بزرگ در نظر گرفته شود؟ آنچه امروز بزرگ است ممکن است فردا کوچک در نظر گرفته شود. اندازه یک مدل معمولاً توسط تعداد پارامترهای (parameters) آن اندازهگیری میشود. یک پارامتر یک متغیر در درون یک مدل ML است که از طریق فرآیند آموزش بهروزرسانی میشود. به طور کلی، هرچه یک مدل پارامترهای بیشتری داشته باشد، ظرفیت بیشتری برای یادگیری رفتارهای desired دارد (اگرچه این همیشه صادق نیست).
وقتی اولین مدل مولد پیشآموزشدیده ترنسفورمر اوپنایآی (GPT) در ژوئن ۲۰۱۸ عرضه شد، ۱۱۷ میلیون پارامتر داشت و در آن زمان بزرگ در نظر گرفته میشد. در فوریه ۲۰۱۹، وقتی اوپنایآی مدل GPT-2 را با ۱.۵ میلیارد پارامتر معرفی کرد، مدل ۱۱۷ میلیونی به عنوان مدلی کوچک تنزل رتبه یافت. در زمان نوشتن این کتاب، مدلی با ۱۰۰ میلیارد پارامتر، بزرگ در نظر گرفته میشود. شاید روزی این اندازه نیز کوچک به حساب آید.
پیش از آنکه به بخش بعدی برویم، میخواهم به این سوال که معمولاً بدیهی فرض میشود بپردازم: چرا مدلهای بزرگتر (larger models) به دادههای بیشتری نیاز دارند؟ مدلهای بزرگتر ظرفیت یادگیری بیشتری دارند و در نتیجه برای حداکثر کردن عملکرد خود به دادههای آموزشی بیشتری نیاز خواهند داشت. شما میتوانید یک مدل بزرگ را روی یک مجموعه داده کوچک نیز آموزش دهید، اما این کار هدر دادن منابع پردازشی خواهد بود. با مدلهای کوچکتر میتوانستید به نتایج مشابه یا حتی بهتری روی این مجموعه داده دست یابید.