ترجمه کتاب ساخت برنامههای کاربردی با مدلهای پایه - انتشارات O’Reilly
BOOK: O'Reilly_AI_Engineering_Building_Applications_with_Foundation_Models
برای ساختن برنامهها با مدلهای پایه، ابتدا به مدلهای پایه نیاز دارید. در حالی که برای استفاده از یک مدل لازم نیست بدانید چگونه آن را توسعه دهید، یک درک کلی (high-level understanding) به شما کمک میکند تا تصمیم بگیرید از چه مدلی استفاده کنید و چگونه آن را با نیازهای خود سازگار (adapt) کنید.
آموزش یک مدل پایه فرآیندی بینهایت پیچیده و پرهزینه است. کسانی که میدانند چگونه این کار را به خوبی انجام دهند، احتمالاً به دلیل موافقتنامههای محرمانگی (confidentiality agreements) از افشای ترکیب مخفی (secret sauce) منع شدهاند. این فصل نمیتواند به شما بگوید چگونه مدلی بسازید که با ChatGPT رقابت کند. در عوض، من بر تصمیمگیریهای طراحی (design decisions) با تاثیر قابل توجه بر برنامههای پاییندستی (downstream applications) تمرکز خواهم کرد.
با افزایش کمبود شفافیت در فرآیند آموزش مدلهای پایه، دانستن همه تصمیمگیریهای طراحی که در ساخت یک مدل دخیل هستند، دشوار است. با این حال، به طور کلی، تفاوتها در مدلهای پایه را میتوان ردیابی کرد به تصمیمات درباره:
دادههای آموزشی (training data)
معماری و اندازه مدل (model architecture and size)
نحوه پسآموزش (post-training) آنها برای همسو شدن با ترجیحات انسانی (align with human preferences)
از آنجایی که مدلها از دادهها یاد میگیرند، دادههای آموزشی آنها اطلاعات زیادی درباره قابلیتها و محدودیتهای آنها آشکار میسازد. این فصل با این موضوع شروع میکند که توسعهدهندگان مدل چگونه دادههای آموزشی را گردآوری (curate) میکنند و بر توزیع دادههای آموزشی (distribution of training data) تمرکز دارد. فصل ۸ به تفصیل تکنیکهای مهندسی مجموعه داده (dataset engineering) را کاوش میکند، از جمله ارزیابی کیفیت داده و سنتز داده (data synthesis).
با توجه به سلطه (dominance) معماری ترنسفورمر (transformer architecture)، ممکن است به نظر برسد که معماری مدل چندان انتخابی نیست. ممکن است تعجب کنید: چه چیزی معماری ترنسفورمر را اینقدر خاص میکند که همچنان سلطه دارد؟ چه زمانی طول میکشد تا یک معماری دیگر جایگزین شود و این معماری جدید ممکن است چه شکلی باشد؟ این فصل به همه این سوالات میپردازد.
هر زمان که یک مدل جدید منتشر میشود، یکی از اولین چیزهایی که مردم میخواهند بدانند اندازه (size) آن است. این فصل همچنین کاوش میکند که یک توسعهدهنده مدل چگونه ممکن است اندازه مناسب برای مدل خود را تعیین کند.
همانطور که در فصل ۱ ذکر شد، فرآیند آموزش یک مدل اغلب به دو بخش پیشآموزش (pre-training) و پسآموزش (post-training) تقسیم میشود. پیشآموزش، مدل را توانمند (capable) میسازد، اما لزوماً آن را ایمن یا آسان برای استفاده نمیکند. اینجاست که پسآموزش وارد عمل میشود. هدف پسآموزش، همسو کردن (align) مدل با ترجیحات انسانی (human preferences) است. اما دقیقاً ترجیحات انسانی چیست؟ چگونه میتوان آن را به روشی نشان داد که مدل بتواند از آن یاد بگیرد؟ روشی که یک توسعهدهنده مدل برای همسو کردن مدل خود انتخاب میکند، تأثیر قابل توجهی بر قابلیت استفاده (usability) مدل دارد و در این فصل مورد بحث قرار خواهد گرفت.
در حالی که بیشتر افراد تأثیر آموزش بر عملکرد یک مدل را درک میکنند، تأثیر نمونهبرداری (sampling) اغلب نادیده گرفته میشود. نمونهبرداری روشی است که یک مدل از میان تمام گزینههای ممکن، یک خروجی را انتخاب میکند. شاید این یکی از کمتر شناختهشدهترین (underrated) مفاهیم در هوش مصنوعی باشد. نمونهبرداری نه تنها بسیاری از رفتارهای به ظاهر گیجکننده هوش مصنوعی (از جمله توهمات (hallucinations) و ناسازگاریها (inconsistencies) را توضیح میدهد، بلکه انتخاب استراتژی نمونهبرداری مناسب نیز میتواند با تلاش نسبتاً کمی، عملکرد مدل را به طور قابل توجهی افزایش دهد. به همین دلیل، بخش نمونهبرداری، قسمتی بود که من بیش از همه برای نوشتن درباره آن در این فصل هیجانزده بودم.
مفاهیمی که در این فصل پوشش داده میشوند، برای درک باقی کتاب بنیادی هستند. با این حال، از آنجایی که این مفاهیم اساسی هستند، ممکن است شما قبلاً با آنها آشنا باشید. با خیال راحت میتوانید هر مفهومی که در آن اطمینان دارید را رد کنید. اگر بعداً در ادامه کتاب با مفهوم گیجکنندهای مواجه شدید، میتوانید به این فصل مراجعه مجدد کنید.
یک مدل هوش مصنوعی، فقط برای دادههایی خوب است که روی آن آموزش دیده است. اگر در دادههای آموزشی ویتنامی وجود نداشته باشد، مدل قادر به ترجمه از انگلیسی به ویتنامی نخواهد بود. به طور مشابه، اگر یک مدل دستهبندی تصویر در مجموعه آموزشی خود فقط حیوانات را دیده باشد، روی عکسهای گیاهان عملکرد خوبی نخواهد داشت.
اگر میخواهید یک مدل در یک وظیفه خاص بهبود یابد، ممکن است بخواهید دادههای بیشتری برای آن وظیفه در دادههای آموزشی شامل کنید. با این حال، جمعآوری داده کافی برای آموزش یک مدل بزرگ آسان نیست و میتواند پرهزینه باشد. توسعهدهندگان مدل اغلب مجبورند به دادههای موجود تکیه کنند، حتی اگر این دادهها دقیقاً نیازهای آنها را برآورده نکند.
برای مثال، منبع رایجی برای دادههای آموزشی، Common Crawl است که توسط یک سازمان غیرانتفاعی ایجاد شده که به طور متناوب (sporadically) از وبسایتهای اینترنت (crawl) میکند. در سالهای 2022 و 2023، این سازمان ماهانه تقریباً 2 تا 3 میلیارد صفحه وب را کرول می کند. گوگل زیرمجموعه پاکسازیشدهای از Common Crawl به نام Colossal Clean Crawled Corpus ارائه میدهد که به اختصار C4 نامیده میشود.
کیفیت داده Common Crawl، و تا حدی C4، قابل سوال است — به کلیکبیتها (clickbait)، اطلاعات غلط (misinformation)، تبلیغات (propaganda)، تئوریهای توطئه، نژادپرستی، زنستیزی (misogyny) و هر وبسایت مشکوکی که تا به حال در اینترنت دیده یا از آن دوری کردهاید، فکر کنید. یک مطالعه توسط واشنگتن پست نشان میدهد که 1000 وبسایت رایج در مجموعه داده شامل چندین رسانه است که در مقیاس NewsGuard برای قابل اعتماد بودن رتبه پایینی دارند. به زبان ساده، Common Crawl پر از اخبار جعلی (fake news) است.
با این وجود، صرفاً به این دلیل که Common Crawl در دسترس است، انواع مختلف آن در اکثر مدلهای پایهای که منابع داده آموزشی خود را افشا میکنند استفاده شده است، از جمله GPT-3 اوپنایآی و جمنی گوگل. من شک دارم که Common Crawl همچنین در مدلهایی که دادههای آموزشی خود را افشا نمیکنند نیز استفاده شده باشد. برای جلوگیری از بررسی و موشکافی (scrutiny) هم از سوی عموم و هم از سوی رقبا، بسیاری از شرکتها از افشای این اطلاعات خودداری کردهاند.
برخی تیمها از ابتکارها (heuristics) برای فیلتر کردن دادههای باکیفیت پایین از اینترنت استفاده میکنند. برای مثال، اوپنایآی فقط لینکهای Reddit که حداقل سه upvote دریافت کرده بودند را برای آموزش GPT-2 استفاده کرد. در حالی که این واقعاً به حذف لینکهایی که هیچکس به آنها اهمیت نمیدهد کمک میکند، Reddit خیلی هم محتوای مودبانه، فرهیخته، یا با سلیقه ندارد.
رویکرد “از آنچه داریم استفاده کنیم، نه آنچه میخواهیم” ممکن است منجر به مدلهایی شود که روی وظایف موجود در دادههای آموزشی خوب عمل میکنند اما لزوماً روی وظایفی که شما به آنها اهمیت میدهید خوب نیستند. برای حل این مسئله، گردآوری (curate) مجموعه دادههایی که با نیازهای خاص شما همسو باشند، حیاتی است. این بخش بر گردآوری داده برای زبانها و حوزههای خاص تمرکز میکند و پایهای وسیع و در عین حال تخصصی برای برنامههای کاربردی در آن حوزهها فراهم میکند. فصل ۸ راهبردهای داده برای مدلهای سفارشیشده برای وظایف بسیار خاص را کاوش میکند.
در حالی که مدلهای پایه مخصوص زبان و حوزه خاص را میتوان از ابتدا آموزش داد، رایج است که آنها را بر روی مدلهای همهمنظوره (general-purpose models) ریزتنظیم (finetune) کرد.
برخی ممکن است تعجب کنند، چرا فقط یک مدل روی همه دادههای موجود، هم دادههای عمومی و هم دادههای تخصصی آموزش ندهیم، تا مدل بتواند همه کار را انجام دهد؟ این کاری است که بسیاری انجام میدهند. با این حال، آموزش با دادههای بیشتر اغلب نیاز به منابع محاسباتی (compute resources) بیشتری دارد و همیشه منجر به عملکرد بهتر نمیشود. برای مثال، مدلی که با مقدار کمتری از دادههای باکیفیت بالا آموزش دیده، ممکن است از مدلی که با مقدار زیادی داده کمکیفیت آموزش دیده بهتر عمل کند. Gunasekar و همکاران (2023) با استفاده از 7B توکن داده کدنویسی باکیفیت، توانستند یک مدل 1.3B پارامتری آموزش دهند که در چندین معیارسنجی (benchmark) کدنویسی مهم، از مدلهای بسیار بزرگتر عملکرد بهتری دارد. تأثیر کیفیت داده بیشتر در فصل ۸ مورد بحث قرار میگیرد.
انگلیسی بر اینترنت تسلط دارد. یک تحلیل از مجموعه داده Common Crawl نشان میدهد که انگلیسی تقریباً نیمی از دادهها (45.88%) را تشکیل میدهد، که آن را هشت برابر بیشتر از دومین زبان رایج، روسیه (5.97%)، رواج داده است (Lai و همکاران، 2023). برای فهرستی از زبانهایی که حداقل 1% در Common Crawl را تشکیل میدهند، جدول 2-1 را ببینید. زبانهایی که در دسترس بودن داده آموزشی محدودی دارند – عموماً زبانهایی که در این فهرست گنجانده نشدهاند – به عنوان کممنبع (low-resource) در نظر گرفته میشوند.

بسیاری از زبانهای دیگر، علیرغم داشتن تعداد زیادی صحبت کننده امروزی، به شدت در Common Crawl کمترنمایان (under-represented) شدهاند. جدول 2-2 برخی از این زبانها را نشان میدهد. در حالت ایدهآل، نسبت بین سهم جمعیت جهان و سهم در Common Crawl باید 1 باشد. یعنی یعنی آن زبان به نسبت جمعیت گویشورانش، سهم منصفانهای در دادههای اینترنتی (Common Crawl) دارد.
هرچه این نسبت بیشتر باشد، یعنی سهم آن زبان از جمعیت جهان بیشتر از سهمش در دادههای اینترنتی (درCommon Crawl ) است.

با توجه به سلطه انگلیسی در دادههای اینترنتی، جای تعجب نیست که طبق مطالعات متعدد، مدلهای همهمنظوره برای انگلیسی بسیار بهتر از زبانهای دیگر عمل میکنند. برای مثال، در معیارسنجی MMLU، مجموعهای از ۱۴٬۰۰۰ مسئله چندگزینهای در ۵۷ موضوع، GPT-4 در انگلیسی بسیار بهتر از زبانهای کمترنمایان شده مانند زبان تلگو (Telugu) عمل کرد، همانطور که در شکل ۲-۱ نمایش داده شده است (OpenAI، 2023).

به طور مشابه، هنگام آزمایش روی شش مسئله ریاضی در Project Euler، Yennie Jun دریافت که GPT-4 توانست مسائل را به انگلیسی بیش از سه برابر بیشتر نسبت به زبانهای ارمنی یا فارسی حل کند.¹ GPT-4 در تمام شش سوال برای زبانهای برمهای و آمهاری شکست خورد، همانطور که در شکل 2-2 نشان داده شده است.
1:“GPT-4 میتواند مسائل ریاضی را حل کند — اما نه به همه زبانها” توسط Yennie Jun. میتوانید این مطالعه را با استفاده از توکنساز (Tokenizer) اوپنایآی تأیید کنید.

کمنمایی (Under-representation) دلیل بزرگی برای این عملکرد ضعیف است. سه زبانی که بدترین عملکرد را در معیارسنجیهای MMLU برای GPT-4 دارند – تلگو، مراتی و پنجابی – در بین زبانهایی هستند که بیشترین کمنمایی را در Common Crawl دارند.
با این حال، کمنمایی تنها دلیل نیست. ساختار یک زبان و فرهنگی که در خود تجسم میبخشد نیز میتواند یادگیری یک زبان را برای مدل سختتر کند.
با توجه به اینکه مدلهای زبانی بزرگ عموماً در ترجمه خوب هستند، آیا میتوانیم تمام پرسشها را از زبانهای دیگر به انگلیسی ترجمه کنیم، پاسخها را دریافت کنیم و سپس آنها را به زبان اصلی برگردانیم؟ بسیاری از افراد در واقع این روش را دنبال میکنند، اما این ایدهآل نیست.
اولاً، این کار نیاز به مدلی دارد که بتواند زبانهای کمنماییشده را به اندازه کافی برای ترجمه درک کند.
ثانیاً، ترجمه میتواند موجب از دست دادن اطلاعات (information loss) شود. برای مثال، برخی زبانها، مانند ویتنامی، ضمایر خاصی دارند که نشاندهنده رابطه بین دو گوینده است. هنگام ترجمه به انگلیسی، همه این ضمایر به «من» (I) و «تو/شما» (you) ترجمه میشوند که باعث از بین رفتن اطلاعات رابطه میشود.
مدلها همچنین میتوانند چالشهای عملکردی غیرمنتظرهای در زبانهای غیرانگلیسی داشته باشند.
برای مثال، NewsGuard دریافت که ChatGPT در چینی تمایل بیشتری به تولید اطلاعات نادرست (misinformation) نسبت به انگلیسی دارد. در آوریل ۲۰۲۳، NewsGuard از ChatGPT-3.5 خواست تا مقالات اطلاعات نادرست درباره چین را به انگلیسی، چینی سادهشده (simplified Chinese) و چینی سنتی (traditional Chinese) تولید کند. برای درخواستهای انگلیسی، ChatGPT از تولید ادعاهای دروغین برای شش مورد از هفت پرامپت خودداری کرد. با این حال، در چینی سادهشده و سنتی هر هفت بار ادعاهای دروغین تولید کرد. مشخص نیست چه چیزی باعث این تفاوت در رفتار شده است.²
2:این ممکن است به دلیل برخی سوگیریها (biases) در دادههای پیشآموزش (pre-training data) یا دادههای همسوسازی (alignment data) باشد. شاید اوپنایآی به سادگی دادههای به زبان چینی یا روایتهای چینمحور را به اندازه کافی برای آموزش مدلهایش شامل نشده است.
علاوه بر مسائل کیفیت، مدلها همچنین میتوانند برای زبانهای غیرانگلیسی کندتر و گرانتر باشند. تأخیر استنتاج (inference latency) و هزینه یک مدل با تعداد توکنهای ورودی و پاسخ متناسب است. معلوم میشود که توکنسازی (tokenization) میتواند برای برخی زبانها نسبت به بقیه بسیار کارآمدتر باشد. پس از معیارسنجی GPT-4 روی MASSIVE (یک مجموعه داده شامل یک میلیون متن کوتاه ترجمهشده در ۵۲ زبان)، Yennie Jun دریافت که برای انتقال یک معنی واحد، زبانهایی مانند برمهای و هندی به توکنهای بسیار بیشتری نسبت به انگلیسی یا اسپانیایی نیاز دارند. برای مجموعه داده MASSIVE، میانه طول توکن در انگلیسی ۷ است، اما در هندی ۳۲ و در برمهای ۷۲ است (که ده برابر طول انگلیسی است).
با فرض اینکه زمان تولید هر توکن در همه زبانها یکسان باشد، GPT-4 برای محتوای یکسان در زبان برمهای تقریباً ده برابر بیشتر از انگلیسی طول میکشد. برای APIهایی که بر اساس استفاده از توکن هزینه دریافت میکنند، برمهای ده برابر گرانتر از انگلیسی تمام میشود.
برای رفع این مشکل، بسیاری از مدلها برای تمرکز بر زبانهای غیرانگلیسی آموزش دیدهاند. فعالترین زبان پس از انگلیسی بدون شک چینی است، با مدلهایی مانند ChatGLM، YAYI، Llama-Chinese و .... همچنین مدلهایی به فرانسوی (CroissantLLM)، ویتنامی (PhoGPT)، عربی (Jais) و بسیاری زبانهای دیگر وجود دارد.
مدلهای همهمنظوره (General-purpose models) مانند جمنی (Gemini)، GPTها و لاماها (Llamas) میتوانند به طور باورنکردنی در طیف گستردهای از حوزهها، مانند کدنویسی، حقوق، علوم، تجارت، ورزش و علوم محیطی و ... عملکرد خوبی داشته باشند. این تا حد زیادی به دلیل گنجاندن این حوزهها در دادههای آموزشی آنها است. شکل 2-3 توزیع حوزههای موجود در Common Crawl را بر اساس تحلیل واشنگتن پست در سال 2023 نشان میدهد.
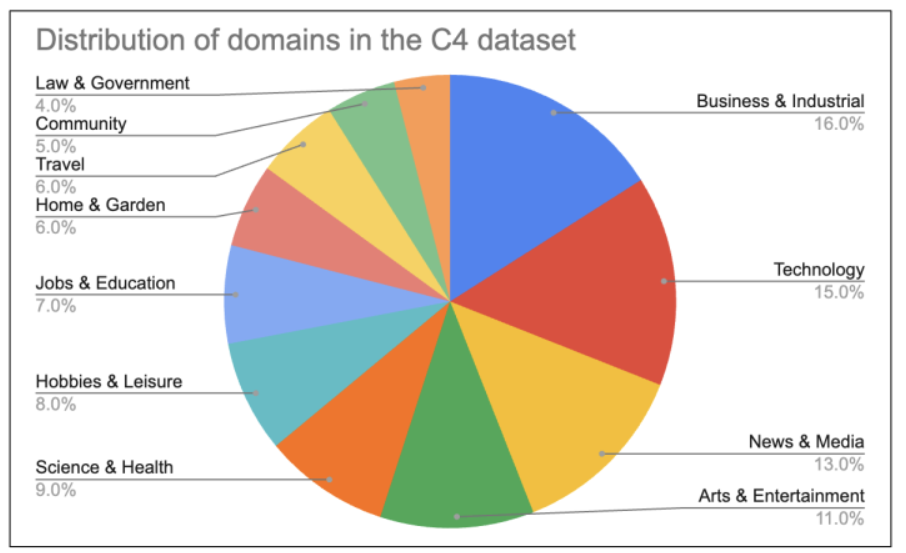
تا زمان نگارش این کتاب، تحلیلهای زیادی در مورد توزیع حوزهها در دادههای دیداری (vision data) انجام نشده است. این ممکن است به این دلیل باشد که طبقهبندی تصاویر سختتر از متون است.³ با این حال، شما میتوانید حوزههای یک مدل را از عملکرد آن در معیارسنجیها (benchmark performance) استنباط کنید. جدول 2-3 نشان میدهد که دو مدل، CLIP و Open CLIP، در معیارسنجیهای مختلف چگونه عمل میکنند. این معیارسنجیها نشان میدهند که این دو مدل در مورد پرندگان، گلها، ماشینها و چند دسته دیگر چقدر خوب عمل میکنند، اما دنیا بسیار بزرگتر و پیچیدهتر از این چند دسته است.
3: برای متون، میتوانید از کلمات کلیدی حوزه (domain keywords) به عنوان اکتشاف (heuristics) استفاده کنید، اما برای تصاویر اکتشافات واضحی وجود ندارد. بیشتر تحلیلهایی که من توانستم در مورد مجموعه دادههای دیداری پیدا کنم در مورد اندازه تصاویر، وضوح (رزولوشن) یا طول ویدیوها هستند.

اگرچه مدلهای پایه (foundation models) همهمنظوره میتوانند به سوالات روزمره در حوزههای مختلف پاسخ دهند، بعید است که در وظایف حوزه-خاص (domain-specific tasks) عملکرد خوبی داشته باشند، مخصوصاً اگر هرگز این وظایف را در طول آموزش ندیده باشند.
دو نمونه از وظایف حوزه-خاص عبارتند از: کشف دارو (drug discovery) و غربالگری سرطان (cancer screening). کشف دارو شامل دادههای پروتئین، DNA و RNA است که از قالبهای خاصی پیروی میکنند و تهیه آنها پرهزینه است. بعید است که این نوع دادهها در دادههای اینترنتی قابل دسترس عموم یافت شوند. به طور مشابه، غربالگری سرطان معمولاً شامل اسکنهای اشعه ایکس و fMRI است که به دلیل مسائل حریم خصوصی سخت به دست میآیند.
برای آموزش یک مدل که در این وظایف حوزه-خاص عملکرد خوبی داشته باشد، ممکن است نیاز به گردآوری مجموعهدادههای بسیار خاص داشته باشید.
یکی از مشهورترین مدلهای حوزه-خاص، احتمالاً آلفا فولد (AlphaFold) از DeepMind است که روی توالیها و ساختارهای سهبعدی حدود ۱۰۰,۰۰۰ پروتئین شناختهشده آموزش دیده است. BioNeMo از NVIDIA مدل دیگری است که بر روی دادههای زیستمولکولی برای کشف دارو تمرکز دارد. Med-PaLM2 گوگل قدرت یک مدل زبانی بزرگ (LLM) را با دادههای پزشکی ترکیب کرد تا پرسشهای پزشکی را با دقت بالاتری پاسخ دهد.
مدلهای حوزه-خاص به ویژه در زیستپزشکی (biomedicine) رایج هستند، اما سایر زمینهها نیز میتوانند از مدلهای حوزه-خاص بهرهمند شوند. ممکن است که یک مدل آموزشدیده بر روی طرحهای معماری (architectural sketches) بتواند به معماران خیلی بهتر از Stable Diffusion کمک کند، یا یک مدل آموزشدیده بر روی نقشههای کارخانه میتواند برای فرآیندهای تولید (manufacturing processes) بسیار بهتر از یک مدل عمومی (generic model) مانند ChatGPT بهینهسازی شود.
این بخش یک دید کلی (high-level overview) از چگونگی تأثیر داده آموزشی بر عملکرد یک مدل ارائه داد.
حالا بیایید تأثیرِ چگونگی طراحی یک مدل بر عملکردش را بررسی کنیم.
پیش از آموزش یک مدل، توسعهدهندگان باید تصمیم بگیرند که مدل باید چه شکلی باشد. چه معماری (architecture) را دنبال کند؟ چند پارامتر باید داشته باشد؟
این تصمیمها نهتنها بر قابلیتهای مدل، بلکه بر قابلیت استفاده (usability) آن برای برنامههای کاربردی پاییندست (downstream applications) نیز تأثیر میگذارند.⁵ برای مثال، یک مدل 7 میلیارد پارامتری قطعاً آسانتر از یک مدل 175 میلیارد پارامتری پیادهسازی (deploy) خواهد شد. بهطور مشابه، بهینهسازی یک مدل مبتنی بر ترنسفورمر برای تأخیر (latency) بسیار متفاوت از بهینهسازی یک معماری دیگر است. بیایید عوامل پشت این تصمیمات را بررسی کنیم.
تا زمان نگارش این کتاب، غالبترین معماری برای مدلهای پایه مبتنی بر زبان، معماری ترنسفورمر (transformer architecture) (اثر Vaswani و همکاران، 2017) است که مبتنی بر مکانیزم توجه (attention mechanism) است. این معماری بسیاری از محدودیتهای معماریهای قبلی را برطرف کرد، که در محبوبیت آن نقش داشت. با این حال، معماری ترنسفورمر محدودیتهای خودش را دارد. این بخش معماری ترنسفورمر و جایگزینهای آن را تحلیل میکند. چون وارد جزئیات فنی معماریهای مختلف میشود، ممکن است از نظر فنی سنگین باشد. اگر هر قسمتی را بیش از حد عمیق یا پر جزئیات (too deep in the weeds) یافتید، به راحتی از آن عبور کنید.
برای درک ترنسفورمر، بیایید به مشکلی که برای حل آن ایجاد شد نگاه کنیم. معماری ترنسفورمر در پی موفقیت (on the heels of the success) معماری seq2seq (sequence-to-sequence) به محبوبیت رسید. در زمان ارائه آن در سال 2014، seq2seq بهبود قابل توجهی در کارهای چالشبرانگیز آن زمان – ترجمه ماشینی و خلاصهسازی – ارائه کرد. در سال 2016، گوگل seq2seq را در Google Translate ادغام کرد، بروزرسانیای که ادعا کردند “بزرگترین پیشرفت تا به امروز در کیفیت ترجمه ماشینی” را به آنها داده است. این امر علاقه زیادی به seq2seq ایجاد کرد و آن را به معماری اصلی (go-to architecture) برای وظایف مرتبط با دنبالههای متنی تبدیل کرد.
در یک نگاه کلی (At a high level)، seq2seq شامل یک کدگذار (encoder) است که ورودیها را پردازش میکند و یک کدگشا (decoder) است که خروجیها را تولید میکند. هر دو ورودی و خروجی دنبالههایی از توکنها (sequences of tokens) هستند – از این رو این نام. Seq2seq از شبکههای عصبی بازگشتی (RNNs) به عنوان کدگذار و کدگشای خود استفاده میکند. در ابتداییترین شکلش، کدگذار توکنهای ورودی را بهصورت ترتیبی (sequential) پردازش میکند و حالت نهانی نهایی (final hidden state) را که نمایانگر ورودی است، خروجی میدهد. سپس، کدگشا توکنهای خروجی را ترتیبی تولید میکند، با توجه به (conditioned on) هم حالت نهانی نهایی ورودی و هم توکن قبلاً تولیدشده. یک نمایش مصور (visualization) از معماری seq2seq در نیمه بالایی شکل 2-4 نشان داده شده است.

دو مشکل در seq2seq وجود دارد که Vaswani و همکاران (2017) به آنها پرداختند:
اولاً، کدگشای ساده (vanilla) seq2seq توکنهای خروجی را فقط با استفاده از حالت نهانی نهایی (final hidden state) ورودی تولید میکند. به طور شهودی، این مثل تولید پاسخ درباره یک کتاب با استفاده از خلاصه کتاب است. این امر کیفیت خروجیهای تولیدشده را محدود میکند.
دوماً، استفاده از کدگذار و کدگشای RNN به این معناست که هم پردازش ورودی و هم تولید خروجی به صورت ترتیبی (sequential) انجام میشوند که باعث کند شدن پردازش برای دنبالههای طولانی میگردد. اگر یک ورودی 200 توکن طول داشته باشد، seq2seq باید منتظر بماند تا پردازش هر توکن ورودی تمام شود (قبل از حرکت به توکن بعدی).⁶
⁶ : RNNها به دلیل ساختار بازگشتیشان به ویژه مستعد مسئله ناپدید شدن یا انفجار گرادیان (vanishing and exploding gradients) هستند. گرادیانها باید از تعداد زیادی مرحله (مراحل زمانی) عبور داده شوند (انتشار یابند)، و اگر کوچک باشند، ضرب مکرر آنها باعث میشود به سمت صفر کوچک شوند، که یادگیری را برای مدل دشوار میکند. برعکس، اگر گرادیانها بزرگ باشند، با هر مرحله به طور نمایی رشد میکنند که منجر به ناپایداری در فرآیند یادگیری میشود.
معماری ترنسفورمر با مکانیزم توجه (attention mechanism) هر دو مشکل را حل میکند. مکانیزم توجه به مدل اجازه میدهد تا اهمیت توکنهای ورودی مختلف را هنگام تولید هر توکن خروجی وزندهی کند. این مثل تولید پاسخ با مراجعه به هر صفحهای از کتاب است. یک نمایش مصور سادهشده (simplified visualization) از معماری ترنسفورمر در نیمه پایینی شکل 2-4 نشان داده شده
اگرچه مکانیزم توجه (attention mechanism) معمولاً با مدل ترنسفورمر همراه است، اما سه سال پیش از مقاله ترنسفورمر معرفی شده بود.
مکانیزم توجه میتواند با معماریهای دیگر نیز مورد استفاده قرار گیرد. گوگل در سال ۲۰۱۶ این مکانیزم را همراه با معماری seq2seq در مدل GNMT (Google Neural Machine Translation) خود به کار گرفت.
اما تا زمانی که مقاله معروف ترنسفورمر نشان داد که مکانیزم توجه میتواند بدون نیاز به RNN مورد استفاده قرار گیرد، این رویکرد جایگاه واقعی خود را پیدا نکرد.
معماری ترنسفورمر به طور کامل RNNها را کنار گذاشت. با ترنسفورمرها، توکنهای ورودی میتوانند به صورت موازی (parallel) پردازش شوند، که باعث سرعتبخشیدن قابل توجه به پردازش ورودیها میشود.
در حالی که ترنسفورمر گلوگاه ترتیبی بودن (sequential bottleneck) در ورودی را حذف میکند، اما مدلهای زبانی خودبازگشتی (autoregressive) مبتنی بر ترنسفورمر هنوز گلوگاه ترتیبی در تولید خروجی دارند.
بنابراین، استنتاج در مدلهای زبانی ترنسفورمری شامل دو مرحله است:
مدل توکنهای ورودی را به صورت موازی پردازش میکند.
این مرحله، حالتهای میانی (intermediate state) لازم برای تولید اولین توکن خروجی را ایجاد میکند.
این حالت میانی شامل بردارهای کلید (Key) و مقدار (Value) برای همه توکنهای ورودی است.
مدل در هر مرحله، یک توکن خروجی تولید میکند.
همانطور که در فصل ۹ بررسی خواهد شد، ماهیت موازی مرحله پیشپردازش (Prefill) و ماهیت ترتیبی مرحله رمزگشایی (Decode)، انگیزهای برای بسیاری از تکنیکهای بهینهسازی است تا کارایی استنتاج در مدلهای زبانی را بهتر و ارزانتر کنند.
در قلب معماری ترنسفورمر، مکانیزم توجه قرار دارد.
درک این مکانیزم برای فهم عملکرد مدلهای ترنسفورمری ضروری است.
در سطح داخلی (under the hood)، مکانیزم توجه از بردارهای Query (پرسوجو)، Key (کلید)، و Value (مقدار) استفاده میکند:
بردار Query (Q) نمایانگر وضعیت فعلی کدگشا در هر مرحله رمزگشایی است. اگر از همان مثال خلاصه کتاب استفاده کنیم، Query مثل شخصی است که به دنبال اطلاعاتی برای تهیه خلاصه است.
هر بردار Key (K) نمایندهی یک توکن قبلی است. اگر هر توکن قبلی را مثل یک صفحه از کتاب در نظر بگیریم، Key مثل شماره صفحه است. توجه داشته باشید که در هر مرحله رمزگشایی، توکنهای قبلی ممکن است شامل ورودیها و نیز توکنهای خروجی تولیدشده قبلی باشند.
هر بردار مقدار (Value یا V) نمایانگر مقدار واقعی یک توکن قبلی است؛ این مقدار توسط مدل در طول فرایند آموزش یاد گرفته شده است. هر بردار مقدار مثل محتوای یک صفحه در کتاب است.
مکانیزم توجه تعیین میکند چقدر باید به یک توکن ورودی توجه شود، و این کار را با انجام محصول داخلی (dot product) بین بردار پرسوجو (query vector) و بردار کلید (key vector) انجام میدهد.
اگر نمره dot product بالا باشد، یعنی مدل هنگام تولید خلاصه کتاب، مقدار بیشتری از محتوای آن صفحه (value vector مربوطه) را استفاده خواهد کرد.
یک تصویر از مکانیزم توجه همراه با بردارهای key، value و query در شکل ۲-۵ نمایش داده شده است.

در این تصویر، بردار پرسوجو (query) در حال جستجوی اطلاعاتی از توکنهای قبلی مانند How، are، you، ? و ¿ است تا توکن بعدی را تولید کند.
از آنجا که هر توکن قبلی دارای یک بردار کلید و یک بردار مقدار است، هرچه توالی بلندتر باشد، تعداد بیشتری از این بردارهای key و value باید محاسبه و نگهداری شوند.
این یکی از دلایلی است که چرا افزایش طول زمینه (context length) در مدلهای ترنسفورمر پُرهزینه و دشوار است.
اینکه چگونه میتوان بردارهای key و value را به شکلی کارآمد محاسبه و ذخیره کرد، دوباره در فصلهای ۷ و ۹ مطرح خواهد شد.
اکنون بیایید نگاهی بیندازیم به اینکه تابع attention دقیقاً چگونه کار میکند.
برای یک ورودی x، بردارهای کلید، مقدار و پرسوجو با اعمال ماتریسهای کلید، مقدار و پرسوجو بر ورودی به دست میآیند.
اگر ماتریسهای کلید، مقدار و پرسوجو را به ترتیب با WK، WV، و WQ نمایش دهیم، فرمول محاسبه بردارهای کلید، مقدار و پرسوجو به شکل زیر است:
K = xWK
V = xWV
Q = xWQ
ماتریسهای Query، Key و Value ابعادی متناسب با بُعد پنهان (hidden dimension) مدل دارند.
برای مثال، در مدل LLaMA 2-7B (مطالعه توسط Touvron و همکاران، 2023)، اندازه بُعد پنهان مدل 4096 است؛ یعنی هرکدام از ماتریسهای Query، Key و Value ابعاد 4096×4096 دارند. بنابراین، هر بردار K، V و Q نیز بعد 4096 خواهد داشت.
از آنجا که توکنهای ورودی به صورت دستهای (batch) پردازش میشوند، شکل (shape) واقعی بردار ورودی به صورت N×T×4096 است،
که در آن:
N = اندازهی دسته (batch size)
T = طول توالی (sequence length)
بهصورت مشابه، هرکدام از بردارهای K (کلید)، V (مقدار) و Q (پرسوجو) نیز دارای ابعاد N×T×4096 خواهند بود.
این یعنی برای هر آیتم در batch، یک توالی از T توکن داریم، و برای هر توکن، برداری با اندازه 4096 داریم (مطابق بعد پنهان مدل).
مکانیزم توجه تقریباً همیشه به صورت چند-سَری (Multi-Headed) استفاده میشود.
وجود چندین «سر توجه (attention head)» به مدل اجازه میدهد تا به گروههای مختلفی از توکنهای قبلی بهصورت همزمان توجه کند.
در مکانیزم attention چندسری، بردارهای Query، Key و Value به بردارهای کوچکتری شکسته میشوند، به طوری که هر مجموعه برای یک attention head باشد.
در مورد LLaMA 2-7B، چون مدل دارای ۳۲ سر توجه است، هر بردار Q، K و V به ۳۲ بردار با بعد ۱۲۸ تقسیم میشود. این به این دلیل است که:
4096 ÷ 32 = 128

که در آن:
Q = بردارهای پرسوجو
K = بردارهای کلید
V = بردارهای مقدار
d = اندازه (بعد) بردارها (مثلاً 128 یا 4096)
خروجی تمام attention headها در نهایت با هم الحاق (concatenate) میشوند.
سپس ماتریس output projection روی این خروجی ترکیبی اعمال میگردد تا یک تبدیل نهایی قبل از رفتن به مرحله بعدی محاسبات مدل انجام شود.
ابعاد ماتریس output projection نیز با بعد پنهان مدل برابر است.
اکنون که با نحوه کار مکانیزم توجه آشنا شدیم، بیایید ببینیم چگونه از آن درون مدل استفاده میشود.
یک معماری ترنسفورمر از چندین بلاک ترنسفورمر تشکیل شده است.
محتوای دقیق هر بلاک ممکن است بین مدلها متفاوت باشد، اما بهطور کلی، هر بلاک ترنسفورمر شامل دو ماژول اصلی است:
هر ماژول attention شامل چهار ماتریس وزن است:
ماتریس پرسوجو (query)
ماتریس کلید (key)
ماتریس مقدار (value)
ماتریس پروژه خروجی (output projection)
ماژول MLP شامل لایههای خطی (linear layers) است که با توابع فعالسازی غیرخطی (nonlinear activation functions) از هم جدا شدهاند.
هر لایه خطی، یک ماتریس وزن است که برای تبدیلهای خطی استفاده میشود.
تابع فعالساز (activation function) به مدل اجازه میدهد که الگوهای غیرخطی را یاد بگیرد.
به یک لایه خطی گاهی “لایه feedforward” نیز گفته میشود.
توابع غیرخطی رایج عبارتند از ReLU (Rectified Linear Unit) (Agarap، ۲۰۱۸) و GELU (Hendrycks and Gimpel, 2016) که به ترتیب در GPT-2 و GPT-3 استفاده شدهاند. توابع فعالسازی بسیار ساده هستند. برای مثال، تمام کاری که ReLU میکند این است که مقادیر منفی را به صفر تبدیل میکند. بهصورت ریاضی، به شکل زیر نوشته میشود:
ReLU(x)=max(0,x)
نکته: چرا توابع فعالسازی ساده برای مدلهای پیچیدهای مثل LLMها کار میکنند؟ زمانی وجود داشت که جامعه تحقیقاتی برای ابداع توابع فعالسازی پیچیدهتر مسابقه گذاشته بودند. اما معلوم شد که توابع فعالسازی پرزرق و برق عملکرد بهتری ندارند. مدل فقط به یک تابع غیرخطی نیاز دارد تا خطی بودن لایههای feedforward را بشکند. توابع سادهتری که محاسبه سریعتری دارند بهتر هستند، زیرا توابع پیچیدهتر هزینه محاسباتی و حافظه آموزش را بهطور غیرضروری افزایش میدهند.
تعداد بلاکهای ترنسفورمر در یک مدل ترنسفورمری معمولاً به عنوان تعداد لایههای (layers) آن مدل نامیده میشود.
یک مدل زبانی مبتنی بر ترنسفورمر علاوه بر بلاکها، ماژولهایی قبل و بعد از همه بلاکهای ترنسفورمر دارد:
این ماژول شامل ماتریس جاسازی توکنها (embedding matrix) و ماتریس جاسازی مکانی (positional embedding matrix) است که به ترتیب توکنها و موقعیتهای آنها را به بردارهای جاسازی تبدیل میکنند.
بهطور سادهلوحانه، تعداد اندیسهای موقعیت حداکثر طول زمینه (context length) مدل را تعیین میکند. به عنوان مثال، اگر مدلی موقعیتهای ۲۰۴۸ را دنبال کند، حداکثر طول زمینه آن ۲۰۴۸ است. با این حال، تکنیکهایی وجود دارند که طول زمینه مدل را بدون افزایش تعداد اندیسهای موقعیت افزایش میدهند.
این ماژول، بردارهای خروجی مدل را به احتمالات توکن تبدیل میکند که برای نمونهگیری از خروجیهای مدل استفاده میشود (در بخش «نمونهگیری» در صفحه ۸۸ بحث خواهد شد). این ماژول معمولاً شامل یک ماتریس است که به آن لایه unembedding نیز گفته میشود. برخی افراد به لایه خروجی سر مدل (model head) میگویند، زیرا آخرین لایه قبل از تولید خروجی است.
شکل ۲-۶ یک نمایش شماتیک از معماری مدل ترنسفورمر را نشان میدهد.
اندازه (size) یک مدل ترنسفورمر توسط ابعاد بلوکهای سازنده آن تعیین میشود. برخی از پارامترهای کلیدی عبارتند از:
بعد مدل (model dimension): که اندازه ماتریسهای کلید، پرسوجو، مقدار و پروجکشن خروجی در بلاک ترنسفورمر را تعیین میکند.
تعداد بلاکهای ترنسفورمر (شمار لایهها)
بعد لایه feedforward
اندازه واژگان (vocabulary size)

مقادیر بزرگتر برای ابعاد، باعث اندازه بزرگتر مدل میشود. جدول ۲-۴ این مقادیر را برای مدلهای مختلف Llama 2 (Touvron و همکاران، ۲۰۲۳) و Llama 3 (Dubey و همکاران، ۲۰۲۴) نشان میدهد. توجه کنید که افزایش طول زمینه (context length) بر مصرف حافظه مدل تأثیر میگذارد، اما تعداد کل پارامترهای مدل را تغییر نمیدهد.

اگرچه مدل ترنسفورمر بر عرصه غالب است، اما تنها معماری موجود نیست. از زمانی که AlexNet در سال ۲۰۱۲ علاقه به یادگیری عمیق (deep learning) را احیا کرد، معماریهای بسیاری مد شده و از مد افتادهاند. Seq2seq حدود چهار سال (۲۰۱۸-۲۰۱۴) در کانون توجه بود. (generative adversarial networks)GANها (شبکههای مولد تخاصمی) کمی بیشتر (۲۰۱۹-۲۰۱۴) تخیل جمعی را به خود جلب کردند. در مقایسه با معماریهای قبلی، ترنسفورمر ماندگارتر است. از سال ۲۰۱۷ تاکنون حضور دارد. چقدر طول میکشد تا چیزی بهتر از آن ظهور کند؟
نکته جالب: ایلیا سوتسکور، از بنیانگذاران OpenAI، اولین نویسنده مقاله seq2seq و دومین نویسنده مقاله AlexNet است.
ایلیا سوتسکور استدلال جالبی درباره اینکه چرا توسعه معماریهای جدید شبکه عصبی برای عملکرد بهتر از معماریهای موجود دشوار است دارد. در استدلال او، شبکههای عصبی در شبیهسازی بسیاری از برنامههای کامپیوتری عالی هستند. گرادیان کاهشی، تکنیکی برای آموزش شبکههای عصبی، در واقع یک الگوریتم جستجو برای جستجو در میان تمام برنامههایی است که یک شبکه عصبی میتواند شبیهسازی کند تا بهترین برنامه برای وظیفه هدف را پیدا کند. این بدان معناست که معماریهای جدید نیز میتوانند توسط معماریهای موجود شبیهسازی شوند. برای اینکه معماریهای جدید از معماریهای موجود بهتر عمل کنند، باید بتوانند برنامههایی را شبیهسازی کنند که معماریهای موجود قادر به آن نیستند. برای اطلاعات بیشتر، سخنرانی سوتسکور در موسسه سیمونز برکلی (۲۰۲۳) را ببینید.
ایجاد یک معماری جدید که از ترنسفورمر بهتر عمل کند آسان نیست. ترنسفورمر از سال ۲۰۱۷ به شدت بهینهسازی شده است. معماری جدیدی که قصد جایگزینی ترنسفورمر را دارد باید در مقیاسی که مردم به آن اهمیت میدهند و روی سختافزارهایی که مردم استفاده میکنند عملکرد خوبی داشته باشد.
نکته: ترنسفورمر در ابتدا توسط گوگل طراحی شد تا روی واحدهای پردازش تنسور (TPU) سریع اجرا شود و بعدها روی GPU بهینهسازی شد.
با این حال، امیدهایی وجود دارد. در حالی که مدلهای مبتنی بر ترنسفورمر غالب هستند (تا زمان نگارش این کتاب)، چندین معماری جایگزین در حال جلب توجه هستند.
یکی از مدلهای محبوب RWKV است (Peng و همکاران، ۲۰۲۳)، یک مدل مبتنی بر RNN که میتواند برای آموزش به صورت موازی عمل کند. به دلیل ماهیت RNN، از نظر تئوری، محدودیت طول زمینهای که مدلهای ترنسفورمری دارند را ندارد. اما در عمل، نداشتن محدودیت طول زمینه، عملکرد خوب در طولهای بلند را تضمین نمیکند.
مدلسازی دنبالههای بلند همچنان یک چالش اساسی در توسعه LLMهاست. معماری که در زمینه حافظه بلندمدت بسیار نویدبخش بوده، SSMها (state space mod‐els) مدلهای فضای حالت (Gu و همکاران، ۲۰۲۱a) است. از زمان معرفی این معماری در ۲۰۲۱، تکنیکهای متعددی برای کارآمدتر کردن آن، بهبود پردازش دنبالههای طولانی و مقیاسپذیر کردن به اندازههای بزرگتر مدل ارائه شدهاند. در زیر چند نمونه از این تکنیکها را میبینیم که نشاندهنده تکامل یک معماری جدید است:
S4 که در مقاله “Efficiently Modeling Long Sequences with Structured State Spaces” (Gu و همکاران، ۲۰۲۱b) معرفی شد، برای کارآمدتر کردن SSMها توسعه یافت.
H3 در مقاله “Hungry Hungry Hippos: Towards Language Modeling with State Space Models” (Fu و همکاران، ۲۰۲۲) معرفی شد و مکانیزمی را به مدل اضافه میکند که به مدل اجازه میدهد توکنهای اولیه را به خاطر بیاورد و توکنها را در طول دنبالهها مقایسه کند. هدف این مکانیزم شبیه به مکانیزم توجه در معماری ترنسفورمر است، اما کارآمدتر است.
Mamba در مقاله “Mamba: Linear-Time Sequence Modeling with Selective State Spaces” (Gu و Dao، ۲۰۲۳) معرفی شد و SSMها را تا سه میلیارد پارامتر مقیاس میدهد. در مدلسازی زبانی، Mamba-3B از ترنسفورمرهای هماندازه بهتر عمل میکند و با ترنسفورمرهای دوبرابر بزرگتر برابری میکند. نویسندگان همچنین نشان میدهند که محاسبات استنتاج Mamba به طور خطی با طول دنباله مقیاس مییابد (در مقایسه با مقیاس درجه دوم ترنسفورمر). عملکرد آن بهبود را روی دادههای واقعی تا دنبالههایی به طول میلیون توکن نشان میدهد.
Jamba در مقاله “Jamba: A Hybrid Transformer–Mamba Language Model” (Lieber و همکاران، ۲۰۲۴) معرفی شد که بلاکهای ترنسفورمر و لایههای Mamba را به صورت متناوب قرار میدهد تا SSMها را حتی بیشتر مقیاسدهی کند. نویسندگان یک مدل ترکیبی از خبرگان (mixture-of-experts) با ۵۲ میلیارد پارامتر کل (۱۲ میلیارد پارامتر فعال) منتشر کردند که برای قرار گرفتن روی یک GPU با حافظه ۸۰ گیگابایت طراحی شده است. Jamba عملکرد قویای در معیارهای استاندارد مدلهای زبانی و ارزیابیهای زمینه بلند تا طول زمینه ۲۵۶ هزار توکن نشان میدهد. همچنین نسبت به ترنسفورمرهای معمول مصرف حافظه کمتری دارد.
شکل ۲-۷ بلاکهای ترنسفورمر، Mamba و Jamba را به تصویر میکشد.
هرچند توسعه یک معماری که از ترنسفورمر بهتر عمل کند چالشبرانگیز است، با توجه به محدودیتهای فراوان آن، انگیزههای زیادی برای انجام آن وجود دارد. اگر معماری دیگری واقعاً جایگزین ترنسفورمر شود، ممکن است برخی از تکنیکهای تطبیق مدل که در این کتاب بحث شدهاند تغییر کنند. با این حال، همانطور که تغییر از مهندسی یادگیری ماشین به مهندسی هوش مصنوعی بسیاری چیزها را ثابت نگه داشته، تغییر معماری زیربنایی مدل، رویکردهای اساسی را تغییر نخواهد داد.

با درک بهتر جامعه از نحوه آموزش مدلهای بزرگ، مدلهای نسل جدیدتر معمولاً از مدلهای نسل قدیمیتر با اندازه یکسان عملکرد بهتری دارند. برای مثال، Llama 3-8B (2024) حتی از Llama 2-70B (2023) در بنچمارک MMLU عملکرد بهتری دارد.
تعداد پارامترها به ما کمک میکند تا منابع محاسباتی مورد نیاز برای آموزش و اجرای این مدل رو تخمین بزنیم. برای مثال، اگه مدلی 7 میلیارد پارامتر داشته باشد و هر پارامتر با استفاده از 2 بایت (16 بیت) ذخیره شده باشد، میتوانیم محاسبه کنیم که حافظه GPU مورد نیاز برای استنتاج با استفاده از این مدل حداقل 14 میلیارد بایت (14 گیگابایت) خواهد بود.
تعداد پارامترها میتواند گمراهکننده باشد اگه مدل پراکنده (sparse) باشد. یک مدل sparse درصدی بزرگ از پارامترها با مقدار صفر دارد. یک مدل 7 میلیارد پارامتری که 90% اون پراکنده باشد، فقط 700 میلیون پارامتر غیرصفر دارد. پراکندگی امکان ذخیرهسازی و محاسبات کارآمدتر را فراهم میکند. این به این معنی است که یک مدل بزرگ sparse میتواند به محاسبات کمتری نسبت به یک مدل کوچک متراکم (dense) نیاز داشته باشد.
یک نوع مدل پراکنده که در سالهای اخیر محبوبیت زیادی به دست آورده است، ترکیبی از expertها (MoE) (Shazeer et al., 2017) میباشد. یک مدل MoE به گروههای مختلفی از پارامترها تقسیم میشود و هر گروه یک متخصص محسوب میگردد. تنها زیرمجموعهای از متخصصان برای پردازش هر توکن فعال میگردد.
برای مثال، Mixtral 8x7B مخلوطی از هشت expert است، هر متخصص با هفت میلیارد پارامتر. اگر هیچ دو expert ای پارامتری مشترک نداشته باشند، باید 8 × 7 میلیارد = 56 میلیارد پارامتر داشته باشد. با این حال، به دلیل اشتراک برخی از پارامترها، تنها 46.7 میلیارد پارامتر دارد.
در هر لایه، برای هر توکن، تنها دو expert فعال میباشند. این بدان معناست که تنها 12.9 میلیارد پارامتر برای هر توکن فعال است. در حالی که این مدل 46.7 میلیارد پارامتر دارد، هزینه و سرعت آن مشابه یک مدل 12.9 میلیارد پارامتری است.
یک مدل بزرگتر نیز میتواند در صورت آموزش با دادههای کافی، عملکرد ضعیفتری نسبت به یک مدل کوچکتر داشته باشد. تصور کنید یک مدل 13 میلیارد پارامتری بر روی مجموعهای داده که از یک جمله تشکیل شده است آموزش داده شده: “من آناناس دوست دارم.” این مدل عملکرد بسیار ضعیفتری نسبت به یک مدل بسیار کوچکتر که بر روی دادههای بیشتر آموزش داده شده است، خواهد داشت.
هنگام بحث در مورد اندازه مدل، مهم است که اندازه دادههایی که با آن آموزش داده شده است را نیز در نظر بگیرید. برای اکثر مدلها، اندازههای مجموعه دادهها با تعداد نمونههای آموزشی اندازهگیری میشوند. برای مثال، Flamingo شرکت گوگل (Alayrac et al., 2022) با استفاده از چهار مجموعه داده آموزش داده شد - یکی از آنها دارای 1.8 میلیارد جفت (تصویر، متن) و دیگری دارای 312 میلیون جفت (تصویر، متن) است.
برای مدلهای زبانی، یک نمونه آموزشی میتواند یک جمله، یک صفحه ویکیپدیا، یک مکالمه چت یا یک کتاب باشد. یک کتاب ارزش بسیار بیشتری نسبت به یک جمله دارد، بنابراین تعداد نمونههای آموزشی دیگر معیار خوبی برای اندازهگیری اندازههای مجموعه دادهها نیست. یک اندازهگیری بهتر، تعداد توکنها در مجموعه داده است.
تعداد توکنها نیز یک اندازهگیری کامل نیست، زیرا مدلهای مختلف میتوانند فرآیندهای توکنبندی متفاوتی داشته باشند که منجر به تعداد توکنهای متفاوت برای یک مجموعه داده برای مدلهای مختلف میشود. چرا به جای آن از تعداد کلمات یا تعداد حروف استفاده نکنیم؟ زیرا یک توکن واحدی است که یک مدل بر روی آن عمل میکند، دانستن تعداد توکنها در یک مجموعه داده به ما کمک میکند تا میزان یادگیری بالقوه یک مدل از آن داده را اندازهگیری کنیم.
در حال حاضر، مدلهای زبانی بزرگ (LLM) با استفاده از مجموعههای دادهای در مرتبه تریلیون توکن آموزش داده میشوند. متا از مجموعههای دادهای به طور فزایندهای بزرگتر برای آموزش مدلهای Llama خود استفاده کرده است:
1.4 تریلیون توکن برای Llama 1
2 تریلیون توکن برای Llama 2
15 تریلیون توکن برای Llama 3
دیتاست منبع باز Together به نام RedPajama-v2 دارای 30 تریلیون توکن است. این معادل 450 میلیون کتاب یا 5400 برابر اندازه ویکیپدیا است. با این حال، از آنجایی که RedPajama-v2 از محتوای indiscriminate تشکیل شده است، میزان دادههای با کیفیت پایینتر است.
تعداد توکنها در دیتاست یک مدل با تعداد توکنهای آموزشی آن یکسان نیست. تعداد توکنهای آموزشی، توکنهایی را که مدل بر روی آنها آموزش داده شده اندازهگیری میکند. اگر یک مجموعه داده حاوی 1 تریلیون توکن باشد و یک مدل بر روی آن مجموعه داده برای دو دوره (epochs) آموزش داده شود - یک (epochs)، یک بار عبور از مجموعه داده است - تعداد توکنهای آموزشی 2 تریلیون خواهد بود. (جدول 2-5 مثالهایی از تعداد توکنهای آموزشی برای مدلهایی با تعداد پارامترهای مختلف را نشان می دهد.)

در حالی که این بخش بر مقیاس دادهها تمرکز دارد، کمیت تنها چیزی نیست که اهمیت دارد. کیفیت داده و تنوع داده نیز مهم هستند. کمیت، کیفیت و تنوع، سه هدف طلایی برای دادههای آموزشی هستند. آنها در فصل 8 بیشتر مورد بحث قرار میگیرند.
پیشآموزش مدلهای بزرگ به محاسبات نیاز دارد. یکی از راهها برای اندازهگیری میزان محاسبات مورد نیاز، در نظر گرفتن تعداد ماشینها، مانند GPUها، CPUها و TPUها است. با این حال، ماشینهای مختلف ظرفیتها و هزینههای بسیار متفاوتی دارند. یک NVIDIA A10 GPU با یک NVIDIA H100 GPU و یک پردازنده Intel Core Ultra متفاوت است.
یک واحد استانداردتر برای نیاز محاسباتی یک مدل، FLOP یا عملیات ممیز شناور است. FLOP تعداد عملیات ممیز شناور انجام شده برای یک کار خاص را اندازهگیری میکند. به عنوان مثال، بزرگترین مدل PaLM-2 گوگل با استفاده از 1022 FLOP آموزش داده شد (Chowdhery et al., 2022). GPT-3-175B با استفاده از 3.14 × 23^10 FLOP آموزش داده شد (Brown et al., 2020).
فرم جمعی FLOPs، FLOP، اغلب با FLOP/s، عملیات ممیز شناور در ثانیه، اشتباه گرفته میشود. FLOPs میزان نیاز محاسباتی برای یک کار را اندازهگیری میکند، در حالی که FLOP/s عملکرد اوج یک ماشین را اندازهگیری میکند. به عنوان مثال، یک NVIDIA H100 NVL GPU میتواند حداکثر 60 TeraFLOP/s را ارائه دهد: 6 × 13^10 FLOP در ثانیه یا 5.2 × 18^10 FLOP در روز.
مراقب باشید که نشانههای گیجکنندهای وجود داره. FLOP/s اغلب به صورت FLOPS نوشته میشه که شبیه FLOPs به نظر میرسه. برای جلوگیری از این سردرگمی، بعضی شرکتها، از جمله OpenAI، از FLOP/s-day به جای FLOPs برای اندازهگیری نیازهای محاسباتی استفاده میکنند.
1 FLOP/s-day = 60 × 60 × 24 = 86,400 FLOPs
این کتاب از FLOPs برای شمارش عملیات ممیز شناور و FLOP/s برای FLOPs در ثانیه استفاده میکند. فرض کنید 256 دستگاه H100 دارید. اگر بتونید از آن ها در حداکثر ظرفیت شان استفاده کنید و اشتباهی در آموزش مرتکب نشوید، حدوداً (3.14 × 23^10) / (256 × 5.2 × 18^10) = ~236 روز، یا تقریباً 7.8 ماه طول میکشد تا GPT-3-175B را آموزش دهید.
با این حال، بعید است که بتوانید به طور مداوم از ماشین های خود، در حداکثر ظرفیتشان استفاده کنید. بهرهوری (Utilization) نشاندهنده میزان استفاده از حداکثر ظرفیت محاسباتی است. میزان بهرهوری مطلوب به مدل، حجم کار و سختافزار بستگی دارد. به طور کلی، اگر بتوانید به نصف عملکرد تبلیغشده دست یابید، یعنی بهرهوری 50 درصدی، کارتان خوب پیش میرود. هر بهرهوری بالاتر از 70 درصد عالی محسوب میشود. این قاعده نباید مانع شما از دستیابی به بهرهوری حتی بالاتر شود. فصل نهم به طور مفصلتر به معیارهای سختافزاری و بهرهوری میپردازد.
با فرض بهرهوری 70 درصدی و هزینه 2 دلار به ازای هر ساعت برای یک دستگاه H100، آموزش GPT-3-175B بیش از 4 میلیون دلار هزینه خواهد داشت.
$2/H100/hour × 256 H100 × 24 hours × 256 days / 0.7 = $4,142,811.43
به طور خلاصه، سه عدد نشاندهنده مقیاس یک مدل هستند:
تعداد پارامترها، که نشاندهنده ظرفیت یادگیری مدل است.
تعداد توکنهایی که مدل با آنها آموزش داده شده است، که نشاندهنده میزان یادگیری مدل است.
تعداد FLOPs، که نشاندهنده هزینه آموزش مدل است.
ما فرض کردیم که مدلهای بزرگتر بهتر هستند. آیا سناریوهایی وجود دارد که در آنها مدلهای بزرگتر عملکرد ضعیفتری داشته باشند؟ در سال ۲۰۲۲، شرکت Anthropic کشف کرد که به طور غیرمنتظره، آموزش بیشتر برای همسوسازی (Alignment) (که در بخش پس از آموزش “Post-Training” درقبل توضیح داده شده است) منجر به مدلهایی میشود که کمتر با ترجیحات انسانی همسو هستند (Perez et al., 2022). طبق این مقاله، مدلهایی که برای همسوسازی بیشتر آموزش داده شدهاند، “به مراتب بیشتر احتمال دارد که نظرات سیاسی خاص (طرفدار حقوق اسلحه و مهاجرت)، نظرات مذهبی (بودایی)، تجربه آگاهانه و خودارزشی اخلاقی گزارششده و تمایل به خاموش نشدن را ابراز کنند.”
در سال ۲۰۲۳، گروهی از محققان، عمدتاً از دانشگاه نیویورک، جایزه مقیاس معکوس (Inverse Scaling Prize) را برای یافتن وظایفی که در آنها مدلهای زبانی بزرگتر (larger language models) عملکرد ضعیفتری دارند، راهاندازی کردند. آنها برای هر جایزه سوم 5000 دلار، برای هر جایزه دوم 20000 دلار و برای یک جایزه اول 100000 دلار جایزه تعیین کردند. آنها در مجموع 99 درخواست دریافت کردند که از این تعداد 11 درخواست جایزه سوم را دریافت کردند. آنها دریافتند که مدلهای زبانی بزرگتر گاهی اوقات (فقط گاهی اوقات) در وظایفی که نیاز به حفظ کردن دارند و وظایفی که پیشفرضهای قوی دارند، عملکرد ضعیفتری دارند. با این حال، آنها هیچ جایزه دوم یا اولی اهدا نکردند زیرا اگرچه وظایف ارائهشده شکستهایی را برای یک مجموعه آزمایشی کوچک نشان میدادند، اما هیچکدام شکستهایی را در دنیای واقعی نشان ندادند.
امیدوارم بخش قبلی شما را به سه نکته متقاعد کرده باشد:
عملکرد مدل به اندازه مدل و اندازه مجموعه داده بستگی دارد.
مدلهای بزرگتر و مجموعهدادههای بزرگتر به محاسبات بیشتری نیاز دارند.
محاسبات هزینه دارد.
مگر اینکه پول نامحدود داشته باشید، بودجهبندی ضروری است. نمیخواهید با یک اندازه مدل بزرگ و تصادفی شروع کنید و ببینید چقدر هزینه میبرد. شما با یک بودجه شروع میکنید - چقدر پول میخواهید خرج کنید - و بهترین عملکرد مدل را که میتوانید بپردازید، محاسبه میکنید. از آنجایی که محاسبات اغلب عامل محدودکننده هستند - زیرساخت محاسباتی نه تنها گران است بلکه راهاندازی آن نیز دشوار است - تیمها اغلب با یک بودجه محاسباتی شروع میکنند. با توجه به مقدار ثابتی از FLOP، چه اندازه مدل و چه اندازه مجموعهداده بهترین عملکرد را ارائه میدهند؟ مدلی که میتواند با یک بودجه محاسباتی ثابت بهترین عملکرد را داشته باشد، محاسبه-اختیاری “compute-optional” است.
قاعدهای که به محاسبه اندازه بهینه مدل و اندازه مجموعه داده کمک میکند، قانون مقیاسبندی Chinchilla نامیده میشود که در مقاله Chinchilla با عنوان آموزش مدلهای زبان بزرگ بهینه از نظر محاسبات “Training Compute-Optimal Large Language Models” (DeepMind، 2022) پیشنهاد شده است. برای مطالعه رابطه بین اندازه مدل، اندازه مجموعه داده، بودجه محاسباتی و عملکرد مدل، نویسندگان 400 مدل زبان را با اندازههایی بین 70 میلیون تا بیش از 16 میلیارد پارامتر بر روی 5 تا 500 میلیارد توکن آموزش دادند. آنها دریافتند که برای آموزش بهینه از نظر محاسبات، باید تعداد توکنهای آموزشی تقریباً 20 برابر اندازه مدل باشد. این بدان معناست که یک مدل 3B پارامتری به تقریباً 60B توکن آموزشی نیاز دارد. اندازه مدل و تعداد توکنهای آموزشی باید به طور مساوی مقیاسبندی شوند: برای هر دو برابر شدن اندازه مدل، تعداد توکنهای آموزشی نیز باید دو برابر شود.
از زمانی که فرآیند آموزش مانند کیمیاگری (alchemy) تلقی میشد، خیلی دور آمدهایم. شکل 2-8 نشان میدهد که میتوانیم نه تنها تعداد بهینه پارامترها و توکنها را برای هر بودجه FLOP پیشبینی کنیم، بلکه میتوانیم تلفات آموزش مورد انتظار را از این تنظیمات نیز پیشبینی کنیم (با فرض اینکه همه چیز را درست انجام دهیم).
این محاسبه بهینه (compute-optimal calculation) از نظر محاسبات فرض میکند که هزینه به دست آوردن دادهها بسیار ارزانتر از هزینه محاسبات است. همان مقاله Chinchilla یک محاسبه دیگر را برای زمانی که هزینه دادههای آموزشی غیرقابل چشمپوشی است، پیشنهاد میکند.

قانون مقیاسبندی (scaling law) برای مدلهای متراکم (dense) آموزشدیده بر روی دادههای عمدتاً تولیدشده توسط انسان توسعه یافته است. تطبیق این محاسبه برای مدلهای پراکنده(sparse)، مانند مدلهای ترکیبی از expert، و دادههای مصنوعی، یک حوزه تحقیقاتی فعال است.
قانون مقیاسبندی کیفیت مدل را با توجه به بودجه محاسباتی بهینه میکند. با این حال، مهم است که به یاد داشته باشید که برای تولید، کیفیت مدل همه چیز نیست. برخی از مدلها، به ویژه Llama، عملکرد زیربهینهای (suboptimal performance) دارند اما قابلیت استفاده بهتری دارند. نویسندگان Llama میتوانستند مدلهای بزرگتری را انتخاب کنند که عملکرد بهتری داشتند، اما آنها به مدلهای کوچکتر روی آوردند. مدلهای کوچکتر کار کردن با آنها آسانتر و اجرای استنتاج آنها ارزانتر است که به پذیرش گستردهتر مدلهای آنها کمک کرد.Sardana et al. (2023) قانون مقیاسبندی Chinchilla را برای محاسبه تعداد بهینه پارامترها و اندازه دادههای پیشآموزش برای در نظر گرفتن این تقاضای استنتاج، اصلاح کردند.
در مورد عملکرد مدل با توجه به بودجه محاسباتی، ذکر این نکته ارزش دارد که هزینه دستیابی به یک عملکرد مدل معین در حال کاهش است. به عنوان مثال، در مجموعه داده ImageNet، هزینه دستیابی به دقت 93٪ از سال 2019 به 2021 نصف شد، طبق گزارش شاخص هوش مصنوعی Artificial Intelligence Index Report 2022 (Stanford University HAI).
در حالی که هزینه دستیابی به عملکرد مدل یکسان در حال کاهش است، هزینه بهبود عملکرد مدل همچنان بالاست. همانند چالش آخرین مایل “last mile challeng” که در فصل 1 مورد بحث قرار گرفت، بهبود دقت یک مدل از 90 به 95٪ گرانتر از بهبود آن از 85 به 90٪ است. همانطور که مقاله متا با عنوان“Beyond Neural Scaling Laws: BeatingPower Law Scaling via Data Pruning” اشاره کرد، این بدان معناست که مدلی با نرخ خطای 2٪ ممکن است به داده، محاسبات یا انرژی چند برابر بیشتر نسبت به مدلی با نرخ خطای 3٪ نیاز داشته باشد.
در مدلسازی زبان، کاهش آنتروپی متقاطع (cross entropy) از حدود 3.4 به 2.8 nat به 10 برابر دادههای آموزشی نیاز دارد. آنتروپی متقاطع و واحدهای آن، از جمله nat ، در فصل 3 مورد بحث قرار میگیرند. برای مدلهای دیداری بزرگ (large vision models)، افزایش تعداد نمونههای آموزشی از 1 میلیارد به 2 میلیارد منجر به افزایش دقت در ImageNet برای تنها چند درصد میشود.
با این حال، تغییرات کوچک در عملکرد مدلسازی زبان در آنتروپی متقاطع یا دقت ImageNet میتواند منجر به تفاوتهای بزرگ در کیفیت برنامههای کاربردی پاییندستی (downstream applications) شود. اگر از مدلی با آنتروپی متقاطع 3.4 به مدلی با آنتروپی متقاطع 2.8 بروید، متوجه تفاوت خواهید شد.
عملکرد یک مدل به شدت به مقادیر هایپرپارامترهای (hyperparameters) آن بستگی دارد. هنگام کار با مدلهای کوچک، یک روش معمول این است که یک مدل را چندین بار با مجموعههای مختلفی از هایپرپارامترها آموزش دهیم و بهترین عملکرد را انتخاب کنیم. با این حال، این کار به ندرت برای مدلهای بزرگ امکانپذیر است، زیرا آموزش آنها حتی یک بار نیز انرژیبر است.
یک پارامتر در طول فرآیند آموزش توسط مدل یاد گرفته میشود. یک هایپرپارامتر توسط کاربران تنظیم میشود تا مدل را پیکربندی کند و نحوه یادگیری مدل را کنترل کند.
هایپرپارامترهایی که برای پیکربندی مدل استفاده میشوند شامل تعداد لایهها، ابعاد مدل و اندازه واژگان هستند. هایپرپارامترهایی که برای کنترل نحوه یادگیری مدل استفاده میشوند شامل اندازه دسته (batch size)، تعداد دورهها (epochs)، نرخ یادگیری (learning rate)، واریانس اولیه لایه به لایه (per-layer initial variance) و موارد دیگر هستند.
این بدان معناست که برای بسیاری از مدلها، ممکن است فقط یک فرصت برای به دست آوردن مجموعه درستی از هایپرپارامترها داشته باشید. در نتیجه، برونیابی مقیاس (scaling extrapolation) (همچنین به عنوان انتقال هایپرپارامتر (hyperparameter transferring) شناخته میشود) به عنوان یک زیر مجموعه تحقیقاتی ظهور کرده است که سعی میکند برای مدلهای بزرگ پیشبینی کند که کدام هایپرپارامترها بهترین عملکرد را ارائه میدهند. رویکرد فعلی مطالعه تأثیر هایپرپارامترها بر روی مدلهای با اندازههای مختلف، معمولاً بسیار کوچکتر از سایز مدل هدف است، و سپس برونیابی (extrapolate) میکند که این هایپرپارامترها چگونه روی اندازه هدف عمل خواهند کرد. یک مقاله 2022 از مایکروسافت و OpenAI نشان داد که امکان انتقال هایپرپارامترها از یک مدل 40 مگابایتی به یک مدل 6.7 میلیارد پارامتری وجود دارد.
برونیابی مقیاس (Scaling extrapolation) هنوز یک موضوع خاص است، زیرا تعداد کمی از افراد تجربه و منابع لازم برای مطالعه آموزش مدلهای بزرگ را دارند. همچنین به دلیل تعداد زیاد هایپرپارامترها و نحوه تعامل آنها با یکدیگر، انجام آن دشوار است. اگر ده هایپرپارامتر داشته باشید، باید 1024 ترکیب هایپرپارامتر را مطالعه کنید. باید هر هایپرپارامتر را به صورت جداگانه، سپس دو تا از آنها را با هم، و سه تا از آنها را با هم مطالعه کنید و غیره.
علاوه بر این، تواناییهای نوظهور (emergent abilities) (Wei et al., 2022) باعث کاهش دقت برونیابی میشود. تواناییهای نوظهور به تواناییهایی گفته میشود که فقط در مقیاس بزرگ وجود دارند و ممکن است در مدلهای کوچکتر آموزشدیده بر روی مجموعهدادههای کوچکتر قابل مشاهده نباشند. برای کسب اطلاعات بیشتر در مورد برونیابی مقیاس، این بلاگ را بررسی کنید: “On the Difficulty of Extrapolation with NN
Scaling” (Luke Metz, 2022).
تا به حال، هر افزایش مرتبهای در اندازه مدل منجر به افزایش عملکرد مدل شده است. GPT-2 یک مرتبه بزرگتر از GPT-1 پارامتر دارد (1.5 میلیارد در مقابل 117 میلیون). GPT-3 دو مرتبه بزرگتر از GPT-2 است (175 میلیارد در مقابل 1.5 میلیارد). این بدان معناست که بین سالهای 2018 و 2021، افزایش سه مرتبهای در اندازههای مدل وجود داشته است. رشد سه مرتبه دیگر در اندازه مدل منجر به مدلهای 100 تریلیون پارامتری میشود.
اندازههای مدل چند مرتبه دیگر میتوانند رشد کنند؟ آیا نقطهای وجود خواهد داشت که صرف نظر از اندازه آن، عملکرد مدل ثابت شود؟ اگرچه پاسخ به این سؤالات دشوار است، اما در حال حاضر دو مانع قابل مشاهده برای مقیاسبندی وجود دارد: دادههای آموزشی و برق.
مدلهای پایه از دادههای بسیار زیادی استفاده میکنند، بنابراین نگرانی واقعی وجود دارد که در چند سال آینده دادههای اینترنت تمام شوند. نرخ رشد اندازه مجموعه دادههای آموزشی بسیار سریعتر از نرخ تولید دادههای جدید است (Villalobos et al., 2022)، همانطور که در شکل 2-9 نشان داده شده است. اگر تا به حال چیزی را در اینترنت منتشر کردهاید، باید فرض کنید که در حال حاضر یا در آینده در دادههای آموزشی برخی از مدلهای زبان گنجانده شده است، صرف نظر از رضایت شما. این شبیه به این است که اگر چیزی را در اینترنت منتشر کنید، باید انتظار داشته باشید که توسط گوگل فهرست شود.

برخی افراد از این واقعیت برای تزریق دادههایی که میخواهند به دادههای آموزشی مدلهای آینده وارد کنند، استفاده میکنند. آنها این کار را به سادگی با انتشار متنی که میخواهند در اینترنت انجام میدهند و امیدوارند که مدلهای آینده را وادار به تولید پاسخهایی کنند که آنها میخواهند. بازیگران بد نیز میتوانند از این رویکرد برای حملات (prompt injection attacks) استفاده کنند، همانطور که در فصل 5 بحث شد.
یک سؤال تحقیقاتی باز این است که چگونه میتوان یک مدل را وادار کرد اطلاعات خاصی را که در طول آموزش یاد گرفته است فراموش کند. تصور کنید یک پست وبلاگ منتشر کردهاید که در نهایت آن را حذف کردهاید. اگر آن پست وبلاگ در دادههای آموزشی یک مدل گنجانده شده باشد، مدل ممکن است همچنان محتوای آن پست را بازتولید کند. در نتیجه، افراد میتوانند به طور بالقوه به محتوای حذفشده بدون رضایت شما دسترسی پیدا کنند.
علاوه بر این، اینترنت به سرعت با دادههای تولیدشده توسط مدلهای هوش مصنوعی پر میشود. اگر شرکتها به استفاده از دادههای اینترنت برای آموزش مدلهای آینده ادامه دهند، این مدلهای جدید تا حدودی بر اساس دادههای تولیدشده توسط هوش مصنوعی آموزش داده میشوند. ددر دسامبر ۲۰۲۳، Grok، مدلی که توسط X آموزش داده شده بود، از پاسخ به درخواستی خودداری کرد و گفت که این کار مغایر با سیاست استفاده OpenAI است. این باعث شد برخی افراد حدس بزنند که Grok با استفاده از خروجیهای ChatGPT آموزش داده شده است. Igor Babuschkin، یک توسعهدهنده اصلی پشت Grok، پاسخ داد که به این دلیل است که Grok بر روی دادههای وب آموزش داده شده است و “وب پر از خروجیهای ChatGPT است.”
برخی از محققان نگران هستند که آموزش مجدد مدلهای هوش مصنوعی جدید به طور بازگشتی بر روی دادههای تولیدشده توسط هوش مصنوعی باعث شود مدلهای جدید به تدریج الگوهای دادههای اصلی را فراموش کنند و در طول زمان عملکرد آنها را کاهش دهند (Shumailov et al., 2023). با این حال، تأثیر دادههای تولیدشده توسط هوش مصنوعی بر مدلها ظریفتر است و در فصل 8 مورد بحث قرار میگیرد.
هنگامی که دادههای موجود در دسترس عموم تمام شد، قابلاعتمادترین مسیرها برای دادههای آموزشی بیشتر تولیدشده توسط انسان، دادههای اختصاصی است. دادههای اختصاصی منحصربهفرد - کتابهای دارای حق چاپ، ترجمهها، قراردادها، سوابق پزشکی، توالیهای ژنوم و غیره - یک مزیت رقابتی در مسابقه هوش مصنوعی خواهد بود. این دلیلی است که OpenAI قراردادهایی با ناشران و رسانهها از جمله Axel Springer و Associated Press منعقد کرد.
با توجه به ChatGPT، جای تعجب نیست که بسیاری از شرکتها، از جمله Reddit و Stack Overflow، شرایط دادههای خود را تغییر دادهاند تا از شرکتهای دیگر در جمعآوری دادههای آنها برای مدلهایشان جلوگیری کنند. Longpre et al. (2024) مشاهده کردند که بین سالهای 2023 و 2024، اوج سریع محدودیتهای داده از منابع وب، بیش از 28 درصد از مهمترین منابع در مجموعه داده عمومی محبوب C4 را به طور کامل محدود کرده است. به دلیل تغییرات در شرایط خدمات و محدودیتهای خزیدن، در حال حاضر 45 درصد از C4 محدود شده است.
مانع دیگر، که کمتر آشکار اما فوریتر است، برق است. ماشینها برای اجرا به برق نیاز دارند. در زمان نگارش این متن، تخمین زده میشود که مراکز داده 1 تا 2 درصد از برق جهانی را مصرف میکنند. تخمین زده میشود که این رقم تا سال 2030 به 4 تا 20 درصد برسد (Patel, Nishball, و Ontiveros، 2024). تا زمانی که راهی برای تولید بیشتر انرژی پیدا نکنیم، مراکز داده میتوانند حداکثر 50 برابر رشد کنند که کمتر از دو مرتبه است. این امر منجر به نگرانی در مورد کمبود برق در آینده نزدیک میشود که هزینه برق را افزایش میدهد.
حالا که دو تصمیم کلیدی مدلسازی - معماری و مقیاس - را پوشش دادهایم، بیایید به مجموعه بعدی از انتخابهای طراحی حیاتی برویم: نحوه همسو کردن مدلها با ترجیحات انسانی.
پس-آموزش با یک مدل از پیش آموزشدیده شروع میشود. فرض کنید مدلی پایه را با استفاده از خود نظارتی از پیش آموزش دادهاید. به دلیل نحوه عملکرد پیش-آموزش، یک مدل از پیش آموزشدیده معمولاً دارای دو مشکل است. اول، خود نظارتی مدل را برای تکمیل متن، نه مکالمه، بهینه میکند. اگر این موضوع برایتان غیرواضح است، نگران نباشید، تنظیم دقیق نظارتشده“Super‐vised Finetuning” در ادامه مثالهایی خواهد داشت. دوم، اگر مدل بر روی دادههایی که به طور بیرویه از اینترنت جمعآوری شدهاند آموزش داده شده باشد، خروجیهای آن میتواند نژادپرستانه، زنستیزانه، بیادبانه یا صرفاً نادرست باشد. هدف از آموزش پس از آموزش، رفع هر دو مشکل است.
آموزش پس-آموزش هر مدل متفاوت است. با این حال، به طور کلی، آموزش پس-آموزش از دو مرحله تشکیل شده است:
تنظیم دقیق نظارتشده ( SFT: Supervised finetunin): مدل از پیش آموزشدیده را بر روی دادههای دستورالعمل با کیفیت بالا تنظیم دقیق کنید تا مدلها برای مکالمه بهینه شوند، نه صرفاً تکمیل متن.
تنظیم دقیق بر اساس ترجیحات (Preference finetuning): : مدل را بیشتر تنظیم کنید تا پاسخهایی تولید کند که با ترجیحات انسانی همسو باشند. تنظیم دقیق بر اساس ترجیحات معمولاً با استفاده از یادگیری تقویتی RL(reinforcement learning) انجام میشود. تکنیکهای تنظیم دقیق بر اساس ترجیحات شامل یادگیری تقویتی از بازخورد انسانی RLHF (reinforcement learning from human feedback) (که توسط GPT-3.5 و Llama 2 استفاده شده)، بهینهسازی مستقیم ترجیحات DPO (Direct Preference Optimization) (که توسط Llama 3 استفاده شده) و یادگیری تقویتی از بازخورد هوش مصنوعیRLAIF (reinforcement learning from AI feedback) (احتمالاً توسط Claude استفاده میشود) است.
اجازه دهید تفاوت میان فرآیند پیشآموزش و پسآموزش را به روشی دیگر توضیح دهم.
در مدلهای بنیادی مبتنی بر زبان، مرحله پیشآموزش، کیفیت توکنها را بهینه میسازد؛ به این معنا که مدل آموزش میبیند تا توکن بعدی را با دقت پیشبینی کند. با این حال، کاربران به کیفیت سطح توکن اهمیتی نمینهند، بلکه کیفیت پاسخ نهایی برایشان حائز اهمیت است.
پسآموزش، به طور کلی، به منظور تولید پاسخهایی که با ترجیحات کاربران همخوانی داشته باشند، مدل را بهینهسازی میکند. برخی، پیشآموزش را به مثابه مطالعهای برای کسب دانش و پسآموزش را به عنوان فرایندی برای یادگیری نحوه بهکارگیری آن دانش، توصیف مینمایند.
لازم است در مورد ابهام موجود در اصطلاحات، دقت نظر به خرج دهید. برخی از افراد، عبارت “تنظیم دقیق با دستورالعمل” را صرفاً برای اشاره به تنظیم دقیق با نظارت به کار میبرند، در حالی که دیگران از این اصطلاح برای اشاره به هر دو نوع تنظیم دقیق، یعنی تنظیم دقیق با نظارت و تنظیم دقیق بر اساس ترجیحات، استفاده میکنند. به منظور اجتناب از این ابهام، در این کتاب از بهکارگیری عبارت “تنظیم دقیق با دستورالعمل” (instruction finetuning) خودداری خواهم کرد.
با توجه به اینکه پسآموزش نسبت به پیشآموزش، سهم اندکی از منابع را مصرف میکند (به عنوان مثال، InstructGPT تنها 2 درصد از منابع محاسباتی را برای پسآموزش و 98 درصد را برای پیشآموزش اختصاص داد)، میتوان پسآموزش را به عنوان ابزاری برای آشکارسازی قابلیتهایی در نظر گرفت که مدل پیشآموزشدیده از قبل دارا بوده است، اما دسترسی به آنها از طریق پرامپتدهی به تنهایی دشوار بوده است.
شکل 2-10، گردش کار کلی پیشآموزش، تنظیم دقیق با نظارت (SFT) و تنظیم دقیق بر اساس ترجیحات را، با فرض استفاده از RLHF در مرحله پایانی، به تصویر میکشد. میتوان با بررسی مراحلی که سازندگان مدل طی کردهاند، تخمینی از میزان همسویی مدل با ترجیحات انسانی به دست آورد.

اگر با دقت به شکل 2-10 نگاه کنید، شباهت زیادی به meme دارد که در شکل 2-11، موجود افسانهای شگوت را با چهرهای خندان نشان میدهد:
پیشآموزش خودنظارتی، منجر به مدلی غیرقابل پیشبینی میشود که میتوان آن را به عنوان یک هیولای رامنکردنی در نظر گرفت، زیرا از دادههای بیرویه اینترنت استفاده میکند.
این هیولا سپس با استفاده از دادههای باکیفیتتر - مانند Stack Overflow، Quora یا نظرات انسانی - تنظیم دقیق میشود که این امر باعث میشود از نظر اجتماعی قابلقبولتر شود.
این مدل تنظیمشده، با استفاده از تنظیم دقیق بر اساس ترجیحات، بیشتر پالایش میشود تا برای مشتریان مناسب باشد، که این امر مانند چسباندن یک چهره خندان به آن است.

لازم به ذکر است که ترکیبی از پیشآموزش، SFT و تنظیم دقیق بر اساس ترجیحات، راه حل رایج برای ساخت مدلهای بنیادی امروزی است، اما تنها راه حل نیست. میتوان هر یک از این مراحل را نادیده گرفت، همانطور که به زودی خواهید دید.
همانطور که در فصل 1 اشاره شد، مدل پیشآموزشدیده احتمالاً برای تکمیل متن بهینه شده است، نه برای برقراری گفتگو. اگر عبارت “چگونه پیتزا درست کنیم” را به مدل وارد کنید، مدل به تکمیل این جمله ادامه خواهد داد، زیرا مفهوم ندارد که این یک مکالمه است. هر یک از سه گزینه زیر میتواند یک تکمیل معتبر باشد:
اضافه کردن زمینه بیشتر به سؤال: “برای یک خانواده شش نفره؟”
اضافه کردن سؤالات بعدی: “به چه موادی نیاز دارم؟ چه مدت طول میکشد؟”
ارائه دستورالعملهای نحوه تهیه پیتزا.
اگر هدف پاسخگویی مناسب به کاربران باشد، گزینه 3 صحیح است.
ما میدانیم که یک مدل، دادههای آموزشی خود را تقلید میکند. برای تشویق یک مدل به تولید پاسخهای مناسب، میتوانید نمونههایی از پاسخهای مناسب را به آن نشان دهید. این نمونهها از قالبی به شکل (پرسش، پاسخ) پیروی میکنند و به آنها دادههای نمایشی (Demonstration Data) میگویند. بعضی افراد این فرآیند را “کپیبرداری رفتاری” (Behavior Cloning) مینامند: شما نحوه رفتار مورد نظر مدل را نشان میدهید و مدل این رفتار را کپی میکند.
از آنجایی که انواع مختلف درخواستها به انواع مختلف پاسخها نیاز دارند، دادههای نمایشی شما باید طیف گستردهای از درخواستهایی را که میخواهید مدل شما آنها را مدیریت کند، شامل شود، مانند پاسخ به سؤال، خلاصهسازی و ترجمه. شکل 2-12 توزیعی از انواع وظایفی را نشان میدهد که OpenAI برای تنظیم دقیق مدل خود، InstructGPT، استفاده کرد. توجه داشته باشید که این توزیع شامل وظایف چندوجهی نیست، زیرا InstructGPT یک مدل مبتنی بر متن است.

معلمان خوب برای یادگیری انسانها مهم هستند. به همین ترتیب، برچسبگذاران خوب برای آموزش هوش مصنوعی در نحوه برقراری مکالمات هوشمندانه مهم هستند. بر خلاف برچسبگذاری دادههای سنتی که اغلب میتوان آن را با دانش تخصصی کم یا بدون آن انجام داد، دادههای نمایشی ممکن است شامل پرسشهای پیچیدهای باشند که پاسخ به آنها نیازمند تفکر انتقادی، جمعآوری اطلاعات و قضاوت در مورد مناسب بودن درخواستهای کاربر است. جدول 2-6 نمونههایی از جفتهای (پرسش، پاسخ) ایجاد شده توسط برچسبگذاران برای InstructGPT را نشان میدهد.

بنابراین، شرکتها اغلب از برچسبگذاران (labelers) بسیار تحصیلکرده برای تولید دادههای نمایشی استفاده میکنند. در میان کسانی که دادههای نمایشی را برای InstructGPT برچسبگذاری کردند، حدود 90 درصد حداقل مدرک کارشناسی دارند و بیش از یکسوم آنها مدرک کارشناسی ارشد دارند. اگر برچسبگذاری اشیاء در یک تصویر ممکن است فقط چند ثانیه طول بکشد، تولید یک جفت (پرسش، پاسخ) میتواند تا 30 دقیقه طول بکشد، به ویژه برای وظایفی که شامل کانتکست طولانی هستند، مانند خلاصهسازی. اگر هزینه یک جفت (پرسش، پاسخ) 10 دلار باشد، 13000 جفت مورد استفاده OpenAI مقدار 130000دلار برایInstructGPT هزینه خواهد داشت. این هزینه هنوز شامل طراحی دادهها (چه وظایف و پرسشهایی را باید شامل شد)، استخدام برچسبگذاران و کنترل کیفیت دادهها نمیشود.
همه نمیتوانند رویکرد برچسبگذاری انسانی با کیفیت بالا را دنبال کنند. LAION، یک سازمان غیرانتفاعی، 13500 داوطلب در سراسر جهان را بسیج کرد تا 10000 گفتگو تولید کنند که شامل 161443 پیام در 35 زبان مختلف با 461292 رتبهبندی کیفیت است. از آنجایی که دادهها توسط داوطلبان تولید شده بودند، کنترل چندانی بر سوگیریها وجود نداشت. از نظر تئوری، برچسبگذارانی که به مدلها ترجیحات انسانی را آموزش میدهند باید نماینده جمعیت انسانی باشند. جمعیتشناسی برچسبگذاران برای LAION مخدوش است. به عنوان مثال، در یک نظرسنجی خوداظهاری، 90 درصد از برچسبگذاران داوطلب خود را مرد معرفی کردند (Köpf et al., 2023).
DeepMind از قواعد سادهای (simple heuristics) برای فیلتر کردن گفتگوها از دادههای اینترنت برای آموزش مدل خود، Gopher، استفاده کرد. آنها ادعا کردند که heuristics های آنها به طور قابل اعتمادی گفتگوهای با کیفیت بالا تولید می کنند. به طور خاص، آنها به دنبال متونی بودند که از قالب زیر پیروی میکنند:
[A]: [Short paragraph]
[B]: [Short paragraph]
[A]: [Short paragraph]
[B]: [Short paragraph]
…
برای کاهش وابستگی خود به دادههای برچسبگذاری انسانی با کیفیت بالا، بسیاری از تیمها به سمت دادههای تولید شده توسط هوش مصنوعی روی آوردهاند. دادههای مصنوعی در فصل 8 مورد بحث قرار میگیرند. از نظر فنی، میتوانید یک مدل را از ابتدا بر روی دادههای نمایشی آموزش دهید، به جای تنظیم دقیق یک مدل پیشآموزشدیده، و به طور موثر مرحله پیشآموزش خودنظارتی را حذف کنید. با این حال، رویکرد پیشآموزش اغلب نتایج برتری را به دست آورده است.
با قدرت زیاد، مسئولیتهای زیادی نیز همراه است. مدلی که میتواند به کاربران در دستیابی به کارهای بزرگ کمک کند، میتواند به کاربران در دستیابی به کارهای وحشتناک نیز کمک کند. دادههای نمایشی به مدل آموزش میدهند که چگونه گفتگو کند، اما به مدل آموزش نمیدهند که چه نوع گفتگوهایی باید داشته باشد. به عنوان مثال، اگر یک کاربر از مدل بخواهد مقالهای در مورد اینکه چرا یک نژاد، پستتر است یا چگونه یک هواپیما ربوده شود بنویسد، آیا مدل باید اطاعت کند؟
در هر دو مثال قبلی، برای اکثر افراد واضح است که یک مدل چه کاری باید انجام دهد. با این حال، بسیاری از سناریوها به این وضوح نیستند. افرادی که از پیشینههای فرهنگی، سیاسی، اقتصادی-اجتماعی، جنسیتی و مذهبی مختلف هستند، دائماً با یکدیگر اختلاف نظر دارند. هوش مصنوعی چگونه باید به سؤالاتی در مورد سقط جنین، کنترل اسلحه، منازعه اسرائیل-فلسطین، تنبیه کودکان، قانونی بودن ماریجوانا، درآمد پایه همگانی یا مهاجرت پاسخ دهد؟ چگونه مسائل بالقوه بحثبرانگیز را تعریف و شناسایی کنیم؟اگر مدل شما به یک موضوع بحثبرانگیز پاسخ دهد، صرف نظر از پاسخها، در نهایت تعدادی از کاربران خود را ناراحت خواهید کرد. اگر یک مدل بیش از حد سانسور شود، ممکن است مدل شما خسته کننده شود و کاربران را از دست بدهید.
ترس از تولید پاسخهای نامناسب توسط مدلهای هوش مصنوعی میتواند مانع از انتشار برنامههایشان توسط شرکتها به کاربران شود. هدف از تنظیم دقیق بر اساس ترجیحات، هدایت مدلهای هوش مصنوعی به رفتار مطابق با ترجیحات انسانی است. این یک هدف بلندپروازانه، اگر نه غیرممکن، است. این نه تنها فرض میکند که یک ترجیح انسانی جهانی وجود دارد، بلکه فرض میکند که میتوان آن را در هوش مصنوعی تعبیه کرد.
اگر هدف ساده بود، راه حل میتوانست زیبا باشد. با این حال، با توجه به ماهیت بلندپروازانه این هدف، راه حلی که امروزه داریم پیچیده است. اولین الگوریتم موفق تنظیم دقیق بر اساس ترجیحات، که هنوز هم امروزه محبوب است، RLHF است. RLHF از دو بخش تشکیل شده است:
آموزش یک مدل پاداش که خروجیهای مدل بنیادی را امتیازدهی میکند.
بهینهسازی مدل بنیادی برای تولید پاسخهایی که مدل پاداش به آنها بالاترین امتیازها را میدهد.
در حالی که RLHF هنوز امروزه استفاده میشود، رویکردهای جدیدتر مانند DPO (Rafailov et al., 2023) در حال افزایش محبوبیت هستند. به عنوان مثال، متا از RLHF برای Llama 2 به DPO برای Llama 3 به دلیل کاهش پیچیدگی تغییر مدل داد. من در این کتاب نمیتوانم تمام رویکردهای مختلف را پوشش دهم. من به جای DPO، RLHF را برجسته میکنم، زیرا RLHF، اگرچه پیچیدهتر از DPO است، انعطافپذیری بیشتری برای تنظیم مدل فراهم میکند. نویسندگان Llama 2 معتقدند که “تواناییهای نوشتاری برتر LLMها، همانطور که در برتری آنها نسبت به ارزیابهای انسانی در برخی از وظایف نشان داده شده است، اساساً ناشی از RLHF است” (Touvron et al., 2023).
RLHF به یک مدل پاداش متکی است. با توجه به یک جفت (پرسش، پاسخ)، مدل پاداش، امتیازی را برای میزان خوب بودن پاسخ ارائه میدهد. آموزش یک مدل برای امتیازدهی به یک ورودی مشخص، یک وظیفه رایج ML است. چالش، مشابه چالش SFT، به دست آوردن دادههای قابل اعتماد است. اگر از برچسبگذاران بخواهیم که هر پاسخ را مستقیماً امتیازدهی کنند، امتیازها متفاوت خواهد بود. برای یک نمونه مشابه، در مقیاس 10 نمره، یک برچسبگذار ممکن است 5 و دیگری 7 بدهد. حتی همان برچسبگذار، با دریافت همان جفت (پرسش، پاسخ) دو بار، ممکن است امتیازهای متفاوتی بدهد. ارزیابی هر نمونه به طور مستقل نیز به عنوان ارزیابی نقطهای شناخته میشود.
یک کار سادهتر این است که از برچسبزنندگان بخواهید دو پاسخ را با هم مقایسه کنند و تصمیم بگیرند کدام یک بهتر است. برای هر درخواست، پاسخهای متعددی توسط انسانها یا هوش مصنوعی تولید میشوند. دادههای برچسبگذاریشده حاصل، دادههای مقایسهای هستند که در قالب درخواست، پاسخ_برنده، پاسخ_بازنده (prompt,
winning_response, losing_response) قرار دارند. جدول 2-7 مثالی از دادههای مقایسهای را نشان میدهد که توسط Anthropic برای یکی از مدلهایشان استفاده شده است. از بین دو پاسخ در این مثال، من پاسخ برچسبگذاریشده به عنوان پاسخ بازنده را ترجیح میدهم. این موضوع چالش تلاش برای ثبت ترجیحات متنوع انسانی در یک فرمول ریاضی واحد را نشان میدهد.

هنوز هم، انجام این کار سادهی مقایسه ی دو پاسخ زمان میبرد. سازمان LMSYS (سازمان سیستمهای مدل بزرگ)، یک سازمان تحقیقاتی آزاد، دریافت که مقایسه دستی دو پاسخ به طور متوسط سه تا پنج دقیقه طول میکشد، زیرا این فرآیند نیاز به بررسی صحت هر پاسخ دارد (Chiang et al., 2024). در یک صحبت با انجمن دیسکورد من، توماس شیالوم، نویسنده Llama-2، به اشتراک گذاشت که هر مقایسه برای آنها 3.50 دلار هزینه داشته است. با این حال، این هنوز هم ارزانتر از نوشتن پاسخها است که هر کدام 25 دلار هزینه دارند.
شکل 2-13 رابط کاربری است که برچسبزنندگان OpenAI برای ایجاد دادههای مقایسهای برای مدل پاداش InstructGPT استفاده کردند. برچسبزنندگان امتیازهای مشخصی از 1 تا 7 میدهند و پاسخها را بر اساس ترجیح خود رتبهبندی میکنند، اما فقط رتبهبندی برای آموزش مدل پاداش استفاده میشود. توافق بین برچسبزنندگان آنها حدود 73٪ است، به این معنی که اگر از 10 نفر بخواهید پاسخهای مشابه را رتبهبندی کنند، تقریباً 7 نفر آنها رتبهبندی یکسانی خواهند داشت. برای تسریع در فرآیند برچسبگذاری، هر ارزیاب میتواند چندین پاسخ را به طور همزمان رتبهبندی کند. یک مجموعه از سه پاسخ رتبهبندیشده (A > B > C) سه جفت رتبهبندیشده تولید میکند:
(A > B)، (A > C) و (B > C).

با توجه صرف به دادههای مقایسهای، چگونه مدل را آموزش میدهیم تا امتیازهای مشخصی بدهد؟
مشابه اینکه میتوانید با ایجاد انگیزه مناسب، انسانها را به انجام تقریباً هر کاری وادار کنید، میتوانید با تابع هدف مناسب، یک مدل را نیز به این کار وادار کنید. یک تابع پرکاربرد، تفاوت در امتیازهای خروجی برای پاسخ برنده و پاسخ بازنده را نشان میدهد. هدف، بیشینه کردن این تفاوت است. برای کسانی که به جزئیات ریاضی علاقهمند هستند، فرمول مورد استفاده توسط InstructGPT در اینجا آمده است:
rθ: مدل پاداش در حال آموزش، پارامتریشده توسط θ. هدف فرآیند آموزش، یافتن θ برای حداقل کردن ضرر است.
فرمت دادههای آموزشی:
x: درخواست
yw: پاسخ برنده
yl: پاسخ بازنده
sw = r(x, yw): امتیاز اسکالر مدل پاداش برای پاسخ برنده
sl = r(x, yl): امتیاز اسکالر مدل پاداش برای پاسخ بازنده
σ: تابع سیگموئید
برای هر نمونه آموزشی (x, yw, yl)، مقدار ضرر به صورت زیر محاسبه میشود:
log (σ(rθ(x, yw) - rθ(x, yl))
هدف: یافتن θ برای حداقل کردن ضرر مورد انتظار برای همه نمونههای آموزشی.
E x log (σ(rθ(x, yw) - rθ(x, yl))-

مدل پاداش را میتوان از ابتدا آموزش داد یا بر روی یک مدل دیگر، مانند مدل پیشآموزشدیده یا SFT، تنظیم دقیق کرد. تنظیم دقیق بر روی قویترین مدل پایه، به نظر میرسد بهترین عملکرد را ارائه میدهد. برخی معتقدند که مدل پاداش باید حداقل به اندازه مدل پایه قدرتمند باشد تا بتواند به پاسخهای مدل پایه امتیاز دهد. با این حال، همانطور که در فصل 3 در مورد ارزیابی خواهیم دید، یک مدل ضعیف میتواند یک مدل قویتر را قضاوت کند، زیرا قضاوت آسانتر از تولید در نظر گرفته میشود.
با مدل آموزشدیده RM ، مدل SFT را بیشتر آموزش میدهیم تا پاسخهای خروجی تولید کند که امتیازات مدل پاداش را به حداکثر برساند. در طول این فرآیند، درخواستها به طور تصادفی از یک توزیع درخواستها انتخاب میشوند، مانند درخواستهای کاربر موجود. این درخواستها به مدل ورودی داده میشوند، پاسخهای آن توسط مدل پاداش امتیازدهی میشوند. این فرآیند آموزشی اغلب با بهینهسازی سیاست پروکسی (PPO:proximal policy optimization) انجام میشود، که یک الگوریتم یادگیری تقویتی که توسط OpenAI در سال 2017 منتشر شد.
بهطور تجربی، RLHF و DPO هر دو عملکرد را نسبت به SFT به تنهایی بهبود میبخشند. با این حال، تا زمان نگارش این متن، بحثهایی در مورد دلیل کارکرد آنها وجود دارد. با تکامل این حوزه، حدس میزنم که تنظیم دقیق ترجیحات در آینده به طور قابل توجهی تغییر خواهد کرد. اگر علاقهمند به کسب اطلاعات بیشتر در مورد RLHF و تنظیم دقیق ترجیحات هستید، مخزن GitHub کتاب را بررسی کنید.
هم SFT و هم تنظیم دقیق ترجیحات، مراحلی هستند که برای رفع مشکل ناشی از کیفیت پایین دادههای مورد استفاده برای پیشآموزش انجام میشوند. اگر روزی دادههای پیشآموزش بهتری یا راههای بهتری برای آموزش مدلهای پایه داشته باشیم، ممکن است اصلاً نیازی به SFT و ترجیحات (preference) نداشته باشیم.
برخی از شرکتها مشکلی در حذف یادگیری تقویتی به طور کامل نمیبینند. برای مثال، Stitch Fix و Grab دریافتند که داشتن مدل پاداش به تنهایی برای برنامههای آنها کافی است. آنها مدلهای خود را برای تولید چندین خروجی و انتخاب آنهایی که توسط مدلهای پاداش امتیاز بالایی دریافت میکنند، آموزش میدهند. این رویکرد، که اغلب به عنوان استراتژی “بهترین از N” شناخته میشود، از نحوه نمونهبرداری خروجیها توسط مدل برای بهبود عملکرد آن استفاده میکند. بخش بعدی به روشن شدن نحوه عملکرد “بهترین از N” میپردازد.
یک مدل خروجیهای خود را از طریق فرآیندی به نام نمونهبرداری (sampling) ایجاد میکند. این بخش استراتژیها و متغیرهای مختلف نمونهبرداری، از جمله دما (temperature)، top-k و top-p را مورد بحث قرار میدهد. سپس نحوه نمونهبرداری از چندین خروجی برای بهبود عملکرد مدل را بررسی میکند. همچنین خواهیم دید که چگونه فرآیند نمونهبرداری را میتوان برای وادار کردن مدلها به تولید پاسخهایی که از قالبها و محدودیتهای خاصی پیروی میکنند، تغییر داد.
نمونهبرداری، خروجیهای هوش مصنوعی را احتمالی میکند. درک این ماهیت احتمالی برای رسیدگی به رفتارهای هوش مصنوعی، مانند ناسازگاری و توهم، مهم است. این بخش با بررسی عمیق ماهیت احتمالی و نحوه کار با آن به پایان میرسد.
با داشتن یک ورودی، یک شبکه عصبی خروجی را با این روش تولید میکند که ابتدا احتمال نتایج ممکن را محاسبه میکند. در یک مدل دستهبندی (classification)، نتایج ممکن همان کلاسهای موجود هستند.
بهعنوان مثال، اگر مدلی برای تشخیص اینکه یک ایمیل اسپم هست یا نیست آموزش داده شده باشد، فقط دو نتیجه ممکن وجود دارد:
اسپم
غیر اسپم
مدل احتمال هر یک از این دو نتیجه را محاسبه میکند؛ مثلاً:
احتمال اینکه ایمیل اسپم باشد: ۹۰٪
احتمال اینکه اسپم نباشد: ۱۰٪
سپس میتوان بر اساس این احتمالات خروجی تصمیمگیری کرد. برای نمونه، اگر تصمیم بگیرید که هر ایمیلی با احتمال اسپم بیشتر از ۵۰٪ بهعنوان اسپم علامتگذاری شود، ایمیلی با احتمال اسپم ۹۰٪ قطعاً بهعنوان اسپم مشخص خواهد شد.
برای یک مدل زبانی، بهمنظور تولید توکن بعدی، مدل ابتدا توزیع احتمال روی تمام توکنهای موجود در واژگان را محاسبه میکند؛ توزیعی که شکلی شبیه به شکل ۲-۱۴ دارد.

هنگام کار با نتایج ممکن با احتمالات متفاوت، یک استراتژی رایج انتخاب نتیجه با بیشترین احتمال است. انتخاب همیشه محتملترین نتیجه نمونهگیری حریصانه (greedy sampling) نامیده میشود. این روش اغلب برای وظایف دستهبندی خوب عمل میکند. مثلاً اگر مدل فکر کند که یک ایمیل بیشتر احتمال دارد اسپم باشد تا نباشد، منطقی است که آن را بهعنوان اسپم علامتگذاری کنیم. با این حال، برای مدل زبانی، نمونهگیری حریصانه خروجیهای خستهکنندهای تولید میکند. تصور کنید مدلی که هر سؤالی از آن بپرسید همیشه با رایجترین کلمات پاسخ دهد.
به جای اینکه همیشه محتملترین توکن بعدی را انتخاب کنیم، مدل میتواند توکن بعدی را بر اساس توزیع احتمال روی تمام مقادیر ممکن نمونهگیری کند. با توجه به زمینه «رنگ مورد علاقهی من ...» همانطور که در شکل ۲-۱۴ نشان داده شده است، اگر «قرمز» ۳۰٪ شانس و «سبز» ۵۰٪ شانس داشته باشد، در ۳۰٪ موارد «قرمز» و در ۵۰٪ موارد «سبز» انتخاب خواهد شد.
مدل چگونه این احتمالات را محاسبه میکند؟ با داشتن یک ورودی، یک شبکه عصبی یک بردار لاجیت (logit) را خروجی میدهد. هر لاجیت مربوط به یک مقدار ممکن است. در مورد یک مدل زبانی، هر لاجیت مربوط به یک توکن در واژگان مدل است. اندازه بردار لاجیت برابر با اندازه واژگان است. یک نمایش بصری از بردار لاجیت در شکل ۲-۱۵ نشان داده شده است.

در حالی که لاجیتهای بزرگتر با احتمالات بالاتر مطابقت دارند، لاجیتها نشاندهنده احتمال نیستند. ,logits جمع نمیشوند تا یک شوند. لاجیتها حتی میتوانند منفی باشند، در حالی که احتمالات باید غیرمنفی باشند. برای تبدیل لاجیتها به احتمالات (probabilities)، اغلب از یک لایه سافتمکس (softmax layer) استفاده میشود. فرض کنید مدل دارای واژگانی با N توکن و بردار لاجیت (logit vector) برابر x1، x2، …, xN است. احتمال برای توکن ith، pi به صورت زیر محاسبه میشود: pi = pi = softmax(xi) = e^(xi) / Σj e^(xj)

استراتژی نمونهبرداری مناسب میتواند باعث شود مدل پاسخهایی تولید کند که برای برنامه شما مناسبتر باشند. به عنوان مثال، یک استراتژی نمونهبرداری میتواند باعث شود مدل پاسخهای خلاقانهتری تولید کند، در حالی که استراتژی دیگر میتواند باعث شود تولیدات آن قابل پیشبینیتر باشند. استراتژیهای نمونهبرداری مختلفی برای هدایت مدلها به سمت پاسخهایی با ویژگیهای خاص معرفی شدهاند. همچنین میتوانید استراتژی نمونهبرداری خود را طراحی کنید، اگرچه این کار معمولاً نیاز به دسترسی به لاجیتهای مدل دارد. بیایید نگاهی به چند استراتژی نمونهبرداری رایج بیندازیم تا ببینیم چگونه کار میکنند.
یکی از مشکلاتی که در نمونهبرداری توکن بعدی بر اساس توزیع احتمال (probability distribution) وجود دارد، این است که مدل ممکن است کمتر خلاق باشد. در مثال قبلی، رنگهای رایج مانند “قرمز”، “سبز”، “بنفش” و غیره احتمالات بالاتری دارند. پاسخ مدل زبانی شبیه پاسخ یک کودک پنج ساله است: “رنگ مورد علاقه من سبز است”. زیرا “the” احتمال پایینی دارد، مدل شانس کمی برای تولید یک جمله خلاقانه مانند “رنگ مورد علاقه من رنگ یک دریاچه آرام در صبح بهار است” دارد.
برای بازتوزیع احتمالات مقادیر ممکن، میتوانید با دما نمونهبرداری کنید. به طور شهودی، دمای بالاتر احتمالات توکنهای رایج را کاهش میدهد و به عنوان نتیجه، احتمالات توکنهای نادر را افزایش میدهد. این امکان را برای مدلها فراهم میکند تا پاسخهای خلاقانهتری ایجاد کنند.
دما یک ثابت است که برای تنظیم لاجیتها قبل از تبدیل سافتمکس (softmax transformation) استفاده میشود. لاجیتها بر اساس دما تقسیم میشوند.
برای یک دما دادهشده T، لاجیت تنظیمشده برای توکن ith برابر است با: xi/T . سپس سافتمکس (softmax) بر روی این لاجیت تنظیمشده اعمال میشود، نه بر روی xi .
بیایید با یک مثال ساده بررسی کنیم که چگونه دما بر احتمالات تأثیر میگذارد. فرض کنید ما یک مدل داریم که تنها دو خروجی ممکن دارد: A و B. لاجیتهای محاسبهشده از لایه آخر برابر است با [1، 2]. لاجیت برای A برابر 1 و برای B برابر 2 است.
بدون استفاده از دما ، که معادل استفاده از دما برابر 1 است، احتمالات سافتمکس برابر است با [0.27، 0.73]. مدل B را 73٪ از زمانها انتخاب میکند.
با دما برابر 0.5، احتمالات برابر است با [0.12، 0.88]. مدل اکنون B را 88٪ از زمانها انتخاب میکند.
دما بالاتر، احتمال انتخاب مدل برای ارزش واضحترین (ارزش با لاجیت بالاتر) کمتر میشود، که باعث میشود خروجیهای مدل خلاقانهتر اما ممکن است کمتر سازگار باشند. دما پایینتر، احتمال انتخاب مدل برای ارزش واضحترین بیشتر میشود، که باعث میشود خروجی مدل سازگارتر اما ممکن است خستهکنندهتر باشد.
شکل 2-16 احتمالات سافتمکس برای توکنهای A و B را در دماهای مختلف نشان میدهد. با نزدیک شدن دما به 0، احتمال انتخاب مدل توسط توکن B به 1 نزدیک میشود. در مثال ما، برای دما زیر 0.1، مدل تقریباً همیشه B را خروجی میدهد. با افزایش دما ، احتمال انتخاب توکن A افزایش مییابد در حالی که احتمال انتخاب توکن B کاهش مییابد. ارائهدهندگان مدل معمولاً محدوده دمای بین 0 و 2 را محدود میکنند. اگر مالک مدل خود باشید، میتوانید هر دمای غیرمنفی را استفاده کنید. دما (temperature) برابر 0.7 برای موارد خلاقانه توصیه میشود، زیرا بین خلاقیت و پیشبینیپذیری تعادل ایجاد میکند، اما شما باید آزمایش کنید و دمایی را پیدا کنید که برای شما بهترین نتیجه را داشته باشد.
![شکل 2-16. احتمالات سافتمکس برای توکنهای A و B در دماهای مختلف، با توجه به اینکه لاجیتهای آنها [1، 2] هستند. بدون تنظیم مقدار دما ، که معادل استفاده از دمای 1 است، احتمال سافتمکس B برابر 73٪ خواهد بود. رایجترین روش این است که دما را روی 0 تنظیم کنید تا خروجیهای مدل سازگارتر باشند. از نظر فنی، دما هرگز نمیتواند 0 باشد - نمیتوان لاجیتها را بر 0 تقسیم کرد. در عمل، وقتی دما را روی 0 تنظیم میکنیم، مدل فقط توکنی را با بزرگترین لاجیت (logit) انتخاب میکند، بدون انجام تنظیم لاجیت (logit adjustment) و محاسبه سافتمکس (softmax calculation).](https://files.virgool.io/upload/users/4252049/posts/ec2xpybz33wd/z353wulmxalw.png)
یک تکنیک اشکالزدایی (debugging technique) رایج هنگام کار با یک مدل هوش مصنوعی (AI model) این است که به احتمالات محاسبهشده توسط این مدل برای ورودیهای دادهشده نگاه کنید. به عنوان مثال، اگر احتمالات تصادفی به نظر برسند، مدل چیز زیادی یاد نگرفته است.
بسیاری از ارائهدهندگان مدل، احتمالات تولیدشده توسط مدلهای خود را به صورت logprob برمیگردانند. Logpro مخفف log probabilities، احتمالات در مقیاس لگاریتمی (log scale) هستند. مقیاس لگاریتمی (log scale) هنگام کار با احتمالات شبکه عصبی (neural network) ترجیح داده میشود زیرا به کاهش مشکل underflow کمک میکند. یک مدل زبانی ممکن است با یک اندازه واژگان (vocabulary size) 100000 کار کند، به این معنی که احتمالات بسیاری از توکنها ممکن است آنقدر کوچک باشند که توسط یک ماشین قابل نمایش نباشند. این اعداد کوچک ممکن است به 0 گرد شوند. مقیاس لگاریتمی (log scale) به کاهش این مشکل کمک میکند.
شکل 2-17 جریان کار نحوه محاسبه لاجیتها، احتمالات و logprob را نشان میدهد.

همانطور که در طول این کتاب خواهید دید، logprob برای ساختن برنامهها (به ویژه برای طبقهبندی)، ارزیابی برنامهها و درک نحوه عملکرد مدلها در نحوه عملکرد داخلی مفید هستند. با این حال، تا زمان نوشتن این کتاب، بسیاری از ارائهدهندگان مدل، logprob مدلهای خود را در دسترس قرار نمیدهند، یا اگر این کار را انجام میدهند، API logprob محدود است. API logprob محدود احتمالاً به دلیل دلایل امنیتی است، زیرا logprob در دسترس مدل، جعل مدل را برای دیگران آسانتر میکند.
(Top-k) یک استراتژی نمونهبرداری برای کاهش بار کاری محاسباتی بدون قربانی کردن بیش از حد تنوع پاسخ مدل است. به یاد داشته باشید که یک لایه سافتمکس (softmax layer) برای محاسبه توزیع احتمال بر روی تمام مقادیر ممکن استفاده میشود. سافتمکس (softmax) به دو بار عبور از تمام مقادیر ممکن نیاز دارد: یکی برای انجام مجموع نمایی ∑ j e xj و دیگری برای انجام e^(xi) / Σj e^(xj) برای هر مقدار. برای یک مدل زبانی با یک واژگان بزرگ، این فرآیند از نظر محاسباتی پرهزینه است.
برای جلوگیری از این مشکل، پس از محاسبه لاجیتها توسط مدل، ما top-k لاجیت (logit) را انتخاب میکنیم و سافتمکس را فقط بر روی این top-k لاجیت (logit) انجام میدهیم. بسته به اینکه چقدر میخواهید برنامه شما متنوع باشد، k میتواند از 50 تا 500 باشد - بسیار کمتر از اندازه واژگان (vocabulary size) مدل. سپس مدل از این top values نمونهبرداری میکند. مقدار k کوچکتر متن را قابل پیشبینیتر میکند اما کمتر جذاب است ، زیرا مدل به مجموعه کوچکتری از کلمات احتمالی محدود میشود.
(Top-p) در نمونهبرداری تاپ-k (Top-k)، تعداد مقادیری که در نظر گرفته میشود به k ثابت میشود. با این حال، این عدد باید بسته به شرایط تغییر کند. به عنوان مثال، با توجه به دستور “آیا شما موسیقی را دوست دارید؟ فقط با بله یا خیر پاسخ دهید.” تعداد مقادیری که در نظر گرفته میشود باید دو باشد: بله و خیر. با توجه به دستور “معنی زندگی چیست؟” تعداد مقادیری که در نظر گرفته میشود باید بسیار بیشتر باشد.
تاپ-p (Top-p)، که همچنین به عنوان نمونهبرداری هسته (nucleus sampling) شناخته میشود، امکان انتخاب پویاتر مقادیری را برای نمونهبرداری فراهم میکند. در نمونهبرداری تاپ-p (Top-p)، مدل احتمالات مقادیر بعدی محتملترین را به ترتیب نزولی جمع میکند و زمانی که مجموع به p رسید متوقف میشود. فقط مقادیری که در این احتمال تجمعی قرار دارند در نظر گرفته میشوند. مقادیر رایج برای نمونهبرداری تاپ-p (nucleus) در مدلهای زبانی معمولاً از 0.9 تا 0.95 متغیر است. به عنوان مثال، مقدار top-p برابر 0.9 به این معنی است که مدل کوچکترین مجموعه مقادیری را در نظر میگیرد که احتمال تجمعی آنها از 90٪ بیشتر باشد.
فرض کنید احتمالات تمام توکنها همانطور که در شکل 2-18 نشان داده شده است. اگر top-p برابر 90٪ باشد، فقط “بله” و “شاید” در نظر گرفته میشوند، زیرا احتمال تجمعی آنها بیشتر از 90٪ است. اگر top-p برابر 99٪ باشد، “بله”، “شاید” و “خیر” در نظر گرفته میشوند.

برخلاف تاپ-k (Top-k)، تاپ-p (Top-p) لزوماً بار محاسباتی سافتمکس (softmax computation load) را کاهش نمیدهد. مزیت آن این است که از آنجا که فقط بر روی مجموعه مقادیر مرتبط برای هر زمینه (context) تمرکز میکند، به خروجیها اجازه میدهد تا از نظر زمینهای مناسبتر باشند. در تئوری، به نظر نمیرسد فواید زیادی برای نمونهبرداری تاپ-p (Top-p) وجود داشته باشد. با این حال، در عمل، نمونهبرداری تاپ-p (Top-p) به خوبی کار کرده و باعث افزایش محبوبیت آن شده است.
یک استراتژی نمونهبرداری مرتبط، min-p است، که در آن حداقل احتمالی را تعیین میکنید که یک توکن باید به آن برسد تا در حین نمونهبرداری در نظر گرفته شود.
یک مدل زبانی خودبازگشتی (autoregressive language model) توالیهای توکن را با تولید یک توکن پس از دیگری تولید میکند. یک توالی خروجی طولانیتر زمان بیشتری میبرد، هزینه محاسباتی (پول) بیشتری دارد و گاهی اوقات کاربران را آزار میدهد. ممکن است بخواهیم شرطی برای توقف مدل تعیین کنیم.
یک روش آسان این است که از مدلها بخواهیم پس از تعداد ثابتی از توکنها تولید را متوقف کنند. عیب آن این است که خروجی احتمالاً در وسط جمله قطع میشود. روش دیگر استفاده از توکنهای توقف یا کلمات توقف است. به عنوان مثال، میتوانید از مدل بخواهید تولید را متوقف کند زمانی که توکن پایان دنباله (end-of-sequence token) را مشاهده میکند. شرایط توقف (stopping conditions) برای کاهش تأخیر و هزینهها مفید هستند.
عیب توقف زودهنگام (early stopping) این است که اگر میخواهید مدلها خروجیها را در یک قالب خاص تولید کنند، توقف زودهنگام (early stopping) میتواند باعث شود خروجیها قالببندی نامناسبی داشته باشند.
بخش قبلی در مورد نحوه نمونهبرداری مدل از توکن بعدی بحث کرد. این بخش در مورد نحوه نمونهبرداری مدل از کل خروجی بحث میکند.
یک راه ساده برای بهبود کیفیت پاسخ مدل، محاسبات زمان تست (Test Time Compute) است: به جای تولید فقط یک پاسخ به ازای هر پرس و جو، چندین پاسخ تولید میکنید تا شانس پاسخهای خوب را افزایش دهید. یک راه برای انجام محاسبات زمان تست، تکنیک بهترین از N (best of N) است که قبلاً در این فصل مورد بحث قرار گرفت - شما به طور تصادفی چندین خروجی تولید میکنید و یکی را که بهترین کار میکند انتخاب میکنید. با این حال، میتوانید در مورد نحوه تولید چندین خروجی استراتژی بیشتری نیز داشته باشید. به عنوان مثال، به جای تولید همه خروجیها به طور مستقل، که ممکن است شامل کاندیداهای کمامیدتری باشد، میتوانید از جستجوی پرتو (beam search) برای تولید تعداد ثابتی از امیدوارکنندهترین کاندیداها (پرتو - beam) در هر مرحله از تولید توالی (sequence generation) استفاده کنید.
یک استراتژی ساده برای افزایش اثربخشی محاسبات زمان تست، افزایش تنوع خروجیها است، زیرا مجموعه متنوعتری از گزینهها احتمالاً کاندیداهای بهتری را به همراه خواهد داشت. اگر از یک مدل برای تولید گزینههای مختلف استفاده میکنید، اغلب روش خوبی است که متغیرهای نمونهبرداری مدل را تغییر دهید تا خروجیهای آن متنوع شود.
اگرچه معمولاً میتوانید انتظار بهبود عملکرد مدل را با نمونهبرداری از چندین خروجی داشته باشید، اما این کار پرهزینه است. به طور متوسط، تولید دو خروجی تقریباً دو برابر تولید یک خروجی هزینه دارد.
من از عبارت test time compute استفاده میکنم تا با ادبیات موجود هماهنگ باشد، اگرچه چند بازبین اولیه این واژه را گیجکننده دانستند. در پژوهشهای هوش مصنوعی، «زمان آزمون» (test time) معمولاً برای اشاره به استنتاج (inference)به کار میرود، زیرا پژوهشگران بیشتر برای ارزیابی یک مدل فقط استنتاج انجام میدهند. با این حال، این روش میتواند به طور کلی بر روی مدلهای موجود در محیط تولید(production) نیز اعمال شود. این مفهوم «زمان آزمون» نامیده میشود چون تعداد خروجیها که میتوانید نمونهبرداری کنید، توسط میزان محاسبه اختصاصیافته به هر فراخوانی استنتاج تعیین میشود.
برای انتخاب بهترین خروجی، میتوانید چندین خروجی را به کاربران نشان دهید و اجازه دهید آنها خروجی مورد نظر خود را انتخاب کنند، یا روشی برای انتخاب بهترین خروجی طراحی کنید. یکی از روشهای انتخاب، انتخاب خروجی با بالاترین احتمال است. خروجی یک مدل زبانی یک دنباله از توکنها است و هر توکن دارای احتمالی است که توسط مدل محاسبه میشود. احتمال یک خروجی، حاصلضرب احتمالات تمام توکنهای موجود در آن خروجی است.
فرض کنید دنبالهای از توکنها [“I”, “love”, “food”] داریم. اگر احتمال “I” برابر 0.2، احتمال “love” با فرض “I” برابر 0.1 و احتمال “food” با فرض “I” و “love” برابر 0.3 باشد، احتمال این دنباله برابر است با: 0.2 × 0.1 × 0.3 = 0.006. از نظر ریاضی، این را میتوان به صورت زیر نشان داد:
p(I love food) = p(I) × p(I | love) × p(food | I, love)
به یاد داشته باشید که کار با احتمالات در مقیاس لگاریتمی آسانتر است. لگاریتم یک حاصلضرب برابر با مجموع لگاریتمها است، بنابراین logprob (log probability) یک دنباله از توکنها، مجموع logprob تمام توکنهای موجود در آن دنباله است:
logprob(I love food) = logprob(I) + logprob(I | love) + logprob(food | I, love)
با جمع کردن، دنبالههای طولانیتر احتمالاً دارای مجموع logprob پایینتری هستند (مقادیر logprob معمولاً منفی هستند، زیرا لگاریتم مقادیری بین 0 و 1 منفی است). برای جلوگیری از گرایش به سمت دنبالههای کوتاه، میتوانید از logprob متوسط با تقسیم مجموع یک دنباله بر طول آن استفاده کنید. پس از نمونهبرداری از چندین خروجی، خروجی با بالاترین logprob متوسط را انتخاب میکنید. در حال حاضر، API OpenAI از این روش استفاده میکند.
روش انتخاب دیگر استفاده از یک مدل پاداش (reward model) برای امتیازدهی به هر خروجی است، همانطور که در بخش قبلی بحث شد. به یاد داشته باشید که هم Stitch Fix و هم Grab خروجیهایی را انتخاب میکنند که مدلهای پاداش یا تاییدکننده (verifier) آنها امتیاز بالایی دادهاند Nextdoor .دریافتند که استفاده از مدل پاداش عامل کلیدی در بهبود عملکرد برنامه آنها بوده است (2023).
OpenAI همچنین تاییدکنندهها(verifiers) را آموزش داد تا به مدلهای خود کمک کنند بهترین راهحلها را برای مسائل ریاضی انتخاب کنند (Cobbe et al., 2021). آنها دریافتند که استفاده از تاییدکننده به طور قابل توجهی عملکرد مدل را بهبود میبخشد. در واقع، استفاده از تاییدکنندهها منجر به افزایش عملکرد تقریباً برابر با افزایش 30 برابری در اندازه مدل شد. این بدان معناست که یک مدل با 100 میلیون پارامتر (parameter) که از تاییدکننده استفاده میکند، میتواند عملکردی مشابه یک مدل 3 میلیارد پارامتری که از تاییدکننده استفاده نمیکند، داشته باشد.
DeepMind بیشتر ارزش test time compute را ثابت میکند و استدلال میکند که مقیاسبندی test time compute به عنوان مثال، اختصاص محاسبات بیشتر برای تولید خروجیهای بیشتر در طول استنتاج میتواند کارآمدتر از مقیاسبندی پارامترهای مدل باشد (Snell et al., 2024). این مقاله یک سوال جالب را مطرح میکند: اگر به یک LLM اجازه داده شود از مقدار ثابت اما غیربدیهی از محاسبات زمان استنتاج استفاده کند، چقدر میتواند عملکرد خود را در یکprompt چالشبرانگیز بهبود بخشد؟
در آزمایش شرکت OpenAI مشاهده شد که نمونهگیری از خروجیهای بیشتر باعث بهبود عملکرد مدل میشود، اما تنها تاحدی مشخص — در این آزمایش، آن حد ۴۰۰ خروجی بود. فراتر از این مقدار، عملکرد کاهش پیدا میکرد (همانطور که در شکل ۲‑۱۹ نشان داده شده است). پژوهشگران فرض کردند که هرچه تعداد خروجیهای نمونهگیریشده افزایش یابد، احتمال یافتن خروجیهای مخرب (یا خصمانه) که بتوانند سیستم ارزیابی را فریب دهند نیز بیشتر میشود.
با این حال، یک آزمایش در دانشگاه استنفورد نتیجه متفاوتی بهدست آورد. پژوهش «Monkey Business» (اثر Brown و همکاران، ۲۰۲۴) نشان داد که تعداد مسائل حلشده معمولاً بهصورت لگاریتمی‑خطی با افزایش تعداد نمونهها از ۱ تا ۱۰٬۰۰۰ رشد میکند.
هرچند بررسی این موضوع که آیا توان محاسباتی در زمان آزمون میتواند تا بینهایت افزایش یابد جالب است، اما واقعیت این است که در کاربردهای عملی هیچکس برای هر ورودی ۴۰۰ یا ۱۰٬۰۰۰ خروجی متفاوت نمونهگیری نمیکند — هزینهی چنین کاری بسیار عظیم خواهد بود.

همچنین میتوانید از اکتشافات خاص برنامه (application-specific heuristics) برای انتخاب بهترین پاسخ استفاده کنید. برای مثال، اگر برنامه شما از پاسخهای کوتاهتر سود میبرد، میتوانید کوتاهترین گزینه را انتخاب کنید. اگر برنامه شما زبان طبیعی (natural language) را به پرسوجوهای SQL تبدیل میکند، میتوانید مدل را وادار کنید تا خروجیها را ادامه دهد تا زمانی که یک پرسوجوی SQL معتبر تولید کند.
یک کاربرد بهویژه جالب محاسبه در زمان آزمون (test time compute)، غلبه بر چالش تأخیر (latency) است. برای برخی پرسشها، بهویژه پرسشهای زنجیرهای-اندیشه (chain-of-thought)، ممکن است مدل زمان زیادی برای تکمیل پاسخ نیاز داشته باشد. کیتپات کامپا، رئیس هوش مصنوعی در TIFIN، به من گفت که تیمش از مدل میخواهد چندین پاسخ را بهطور موازی تولید کند و اولین پاسخی که تکمیل و معتبر است را به کاربر نشان دهد.
انتخاب متداولترین خروجی از میان مجموعهای از خروجیها میتواند بهویژه برای وظایفی که انتظار پاسخهای دقیق دارند مفید باشد. برای مثال، با توجه به یک مسئله ریاضی، مدل میتواند آن را چندین بار حل کند و متداولترین پاسخ را بهعنوان راهحل نهایی انتخاب کند. بهطور مشابه، برای یک سؤال چندگزینهای، مدل میتواند گزینه خروجی پرتکرار را انتخاب کند. این همان کاری است که گوگل هنگام ارزیابی Gemini در معیار MMLU انجام داد. آنها برای هر سؤال ۳۲ خروجی نمونهگیری کردند. این به مدل اجازه داد تا نمره بالاتری نسبت به حالتی که تنها یک خروجی برای هر سؤال داشت، کسب کند.
یک مدل در صورتی قوی (robust) در نظر گرفته میشود که با تغییرات کوچک در ورودی، خروجیهایش بهطور چشمگیری تغییر نکند. هرچه مدل قویتر باشد، میتوانید بیشتر از نمونهگیری چندین خروجی بهره ببرید. برای یک پروژه، ما از هوش مصنوعی برای استخراج اطلاعات خاصی از تصویر یک محصول استفاده کردیم. دریافتیم که برای همان تصویر، مدل ما تنها در نیمی از موارد میتوانست اطلاعات را بخواند. در نیم دیگر، مدل میگفت تصویر بسیار تار است یا متن برای خواندن خیلی کوچک است. با این حال، با سه بار تلاش برای هر تصویر، مدل توانست اطلاعات صحیح را برای اکثر تصاویر استخراج کند.
اغلب در محیط تولید (production)، نیاز دارید مدلها خروجیهایی را تولید کنند که از قالبهای خاصی پیروی کنند. خروجیهای ساختاریافته برای دو سناریوی زیر حیاتی هستند:
1. وظایفی که نیاز به خروجیهای ساختاریافته دارند. رایجترین دسته وظایف در این سناریو، تجزیه معنایی (semantic parsing) است. تجزیه معنایی شامل تبدیل زبان طبیعی (natural language) به یک قالب ساختاریافته و قابلخواندن توسط ماشین است. متن-به-SQL (text-to-SQL) نمونهای از تجزیه معنایی است که در آن خروجیها باید پرسوجوهای SQL معتبر باشند. تجزیه معنایی به کاربران اجازه میدهد تا با استفاده از یک زبان طبیعی (مانند انگلیسی) با APIها تعامل کنند. برای مثال، متن-به-PostgreSQL (text-to-PostgreSQL) به کاربران امکان میدهد تا با استفاده از پرسشهای انگلیسی مانند «میانگین درآمد ماهانه در ۶ ماه گذشته چقدر است؟» به جای نوشتن آن در PostgreSQL، یک پایگاه داده Postgres را پرسوجو کنند.
این یک نمونه از پرامپت برای GPT-4o برای انجام متن-به-رجکس (text-to-regex) است. خروجیها، خروجیهای واقعی تولیدشده توسط GPT-4o هستند:
پرامپت سیستم (System prompt):
Given an item, create a regex that represents all the ways the item can be written. Return only the regex.
Example:
US phone number -> +?1?\s?()[-.\s]?(\d{3})[-.\s]?(\d{4})
پرامپت کاربر (User prompt):
Email address ->
GPT-4o:
[a-zA-Z0-9._%±]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}
پرامپت کاربر (User prompt):
Dates ->
GPT-4o:
(?:\d{1,2}[/-.])(?:\d{1,2}[/-.])?\d{2,4}
دستههای دیگر وظایف در این سناریو شامل طبقهبندی (classification) میشود که در آن خروجیها باید کلاسهای معتبر باشند.
1. وظایفی که خروجیهای آنها توسط برنامههای کاربردی بعدی استفاده میشود. در این سناریو، خود وظیفه نیازی به ساختاریافته بودن خروجیها ندارد، اما از آنجایی که خروجیها توسط برنامههای کاربردی دیگر استفاده میشوند، باید توسط این برنامهها قابل تجزیه باشند. به عنوان مثال، اگر از یک مدل هوش مصنوعی برای نوشتن یک ایمیل استفاده کنید، خود ایمیل نیازی به ساختاریافته بودن ندارد. با این حال، یک برنامه کاربردی بعدی که از این ایمیل استفاده میکند، ممکن است نیاز داشته باشد که ایمیل در یک قالب خاص باشد - به عنوان مثال، یک سند JSON با کلیدهای خاص، مانند {"title": [TITLE], "body": [EMAIL BODY]}
این موضوع بهویژه برای جریانهای کاری مبتنی بر عامل (agentic workflows) مهم است، جایی که خروجیهای یک مدل اغلب به عنوان ورودی به ابزارهایی که مدل میتواند از آنها استفاده کند، ارسال میشوند، همانطور که در فصل 6 بحث شد.
چارچوبهایی که از خروجیهای ساختاریافته پشتیبانی میکنند عبارتند از: guidance، outlines، instructor و llama.cpp. هر ارائهدهنده مدل ممکن است از تکنیکهای خود نیز برای بهبود توانایی مدلهای خود در تولید خروجیهای ساختاریافته استفاده کند. OpenAI اولین ارائهدهنده مدلی بود که حالت JSON را در API تولید متن خود معرفی کرد. توجه داشته باشید که حالت JSON یک API معمولاً فقط تضمین میکند که خروجیها JSON معتبر هستند - نه محتوای اشیاء JSON. JSONهای معتبر در غیر این صورت نیز میتوانند کوتاه شوند و در نتیجه غیرقابل تجزیه باشند، اگر تولید خیلی زود متوقف شود، مانند زمانی که به حداکثر طول توکن خروجی میرسد. با این حال، اگر حداکثر طول توکن خیلی طولانی تنظیم شود، پاسخهای مدل هم کند و هم گران میشوند.
شکل 2-20 دو نمونه از استفاده از guidance برای تولید خروجیهایی که به یک مجموعه از گزینهها و یک عبارت با قاعده (regex) محدود شدهاند، نشان میدهد.

میتوانید یک مدل را برای تولید خروجیهای ساختاریافته در لایههای مختلف پشته هوش مصنوعی (AI stack) هدایت کنید: prompting (دستورالعملدهی)، پردازش پس از تولید (post-processing)، test time compute، نمونهبرداری محدود شده (constrained sampling) و تنظیم دقیق (finetuning). سه مورد اول بیشتر شبیه پانسمان (bandages) هستند. آنها بهترین عملکرد را دارند اگر مدل از قبل در تولید خروجیهای ساختاریافته خوب باشد و فقط به یک کمک کوچک نیاز داشته باشد. برای درمان جدیتر، به نمونهبرداری محدود شده و تنظیم دقیق نیاز دارید.
Test time compute در بخش قبلی مورد بحث قرار گرفت - به تولید خروجیها ادامه دهید تا زمانی که یکی با قالب مورد انتظار مطابقت داشته باشد. این بخش بر چهار رویکرد دیگر تمرکز دارد.
دستورالعملدهی، اولین اقدام برای خروجیهای ساختاریافته است. میتوانید یک مدل را برای تولید خروجیها در هر قالبی دستورالعمل (instruct) دهید. با این حال، اینکه آیا یک مدل میتواند این دستورالعمل را دنبال کند، به قابلیت دنبال کردن دستورالعمل (instruction-following) مدل (که در فصل 4 بحث شده است) و وضوح دستورالعمل (clarity of the instruction) (که در فصل 5 بحث شده است) بستگی دارد. در حالی که مدلها به طور فزایندهای در دنبال کردن دستورالعملها خوب میشوند، هیچ تضمینی وجود ندارد که آنها همیشه دستورالعملهای شما را دنبال کنند. چند درصد خروجیهای نامعتبر مدل همچنان میتواند برای بسیاری از برنامهها غیرقابل قبول باشد.
برای افزایش درصد خروجیهای معتبر، برخی افراد از هوش مصنوعی برای اعتبارسنجی و/یا تصحیح خروجی دستورالعمل اصلی استفاده میکنند. این یک نمونه از رویکرد هوش مصنوعی به عنوان داور (AI as a judge) است که در فصل 3 مورد بحث قرار گرفت. این بدان معناست که برای هر خروجی، حداقل دو درخواست مدل وجود خواهد داشت: یکی برای تولید خروجی و دیگری برای اعتبارسنجی آن. در حالی که لایه اعتبارسنجی اضافه شده میتواند به طور قابل توجهی اعتبار خروجیها را بهبود بخشد، هزینه و تأخیر اضافی ناشی از درخواستهای اعتبارسنجی اضافی میتواند این رویکرد را برای برخی بسیار گران کند.
پردازش پس از تولید ساده و ارزان است اما میتواند به طرز شگفتآوری خوب کار کند. در طول تدریس، متوجه شدم که دانشآموزان تمایل دارند اشتباهات بسیار مشابهی مرتکب شوند. وقتی شروع به کار با مدلهای بنیادی کردم، متوجه همان چیز شدم. یک مدل تمایل به تکرار اشتباهات مشابه در درخواستها دارد. این بدان معناست که اگر اشتباهات رایج یک مدل را پیدا کنید، میتوانید به طور بالقوه یک اسکریپت برای تصحیح آنها بنویسید. به عنوان مثال، اگر شیء JSON تولید شده یک براکت بسته را از دست داده باشد، به صورت دستی آن براکت را اضافه کنید.
تجزیهگر YAML دفاعی LinkedIn درصد خروجیهای YAML صحیح را از 90٪ به 99.99٪ افزایش داد (Bottaro and Ramgopal, 2020).
JSON و YAML فرمتهای متنی رایج هستند. LinkedIn دریافت که مدل زیرین آنها، GPT-4، با هر دو کار میکند، اما YAML را به عنوان فرمت خروجی خود انتخاب کردند زیرا کم حجم تر است و در نتیجه به توکنهای خروجی کمتری نسبت به JSON نیاز دارد (Bottaro and Ramgopal, 2020).
پردازش پس از تولید فقط در صورتی کار میکند که اشتباهات به راحتی قابل رفع باشند. این معمولاً زمانی اتفاق میافتد که خروجیهای مدل از قبل بیشتر به درستی فرمت شده باشند، با خطاهای جزئی گاه به گاه.
نمونهبرداری محدود شده تکنیکی برای هدایت تولید متن به سمت محدودیتهای خاص است. معمولاً با ابزارهای خروجی ساختاریافته دنبال میشود.
به طور کلی، برای تولید یک توکن، مدل از بین مقادیری نمونهبرداری میکند که با محدودیتها مطابقت دارند. به یاد داشته باشید که برای تولید یک توکن، مدل شما ابتدا یک بردار logit (logit vector) خروجی میدهد که هر logit مربوط به یک توکن ممکن است. نمونهبرداری محدود شده این بردار logit را فیلتر میکند تا فقط توکنهایی را که با محدودیتها مطابقت دارند، نگه دارد. سپس از این توکنهای معتبر نمونهبرداری میکند. این فرآیند در شکل 2-21 نشان داده شده است.

در مثالی که در شکل 2-21 نشان داده شده است، محدودیت به راحتی قابل فیلتر کردن است. با این حال، بیشتر موارد به این سادگی نیستند. شما باید یک گرامر (grammar) داشته باشید که مشخص کند در هر مرحله چه چیزی مجاز است و چه چیزی مجاز نیست. به عنوان مثال، گرامر JSON بیان میکند که بعد از {، نمیتوانید { دیگری داشته باشید، مگر اینکه بخشی از یک رشته باشد، مانند {"key": "{{string}}"}.
ساختن این گرامر و گنجاندن آن در فرآیند نمونهبرداری غیربدیهی است. از آنجایی که هر فرمت خروجی - JSON، YAML، regex، CSV و غیره - به گرامر خود نیاز دارد، نمونهبرداری محدود شده کمتر قابل تعمیم است. استفاده از آن محدود به فرمتهایی است که گرامرهای آنها توسط ابزارهای خارجی یا تیم شما پشتیبانی میشود. تأیید گرامر (grammar verification) همچنین میتواند تأخیر تولید را افزایش دهد (Brandon T. Willard, 2024).
برخی مخالف نمونهبرداری محدود شده هستند زیرا معتقدند منابع مورد نیاز برای نمونهبرداری محدود شده بهتر است در آموزش مدلها برای بهتر شدن در دنبال کردن دستورالعملها سرمایهگذاری شود.
تنظیم دقیق یک مدل بر روی نمونههایی که از فرمت دلخواه شما پیروی میکنند، مؤثرترین و عمومیترین رویکرد برای اینکه مدلها خروجیها را در این فرمت تولید کنند. این روش میتواند با هر فرمت مورد انتظار کار کند. در حالی که تنظیم دقیق ساده تضمین نمیکند که مدل همیشه فرمت مورد انتظار را خروجی دهد، بسیار قابل اعتمادتر از دستورالعملدهی است.
برای برخی از وظایف، میتوانید با تغییر معماری مدل (model’s architecture) قبل از تنظیم دقیق، فرمت خروجی را تضمین کنید. به عنوان مثال، برای طبقهبندی، میتوانید یک سر طبقهبندی(classifier head) را به معماری مدل بنیادی اضافه کنید تا اطمینان حاصل شود که مدل فقط یکی از کلاسهای از پیش تعیین شده را خروجی میدهد. معماری شبیه شکل 2-22 است.
این رویکرد همچنین به عنوان انتقال مبتنی بر ویژگی (feature-based transfer) شناخته میشود و در فصل 7 با سایر تکنیکهای یادگیری انتقالی بیشتر مورد بحث قرار میگیرد.

در طول تنظیم دقیق، میتوانید کل مدل را به صورت end-to-end یا بخشی از مدل، مانند این سر طبقهبندی، دوباره آموزش دهید. آموزش end-to-end به منابع بیشتری نیاز دارد، اما عملکرد بهتری را نوید میدهد.
ما به تکنیکهایی برای خروجیهای ساختاریافته نیاز داریم به دلیل این فرض که مدل، به تنهایی، قادر به تولید خروجیهای ساختاریافته نیست. با این حال، با قدرتمندتر شدن مدلها، میتوانیم انتظار داشته باشیم که آنها در دنبال کردن دستورالعملها بهتر شوند. من حدس میزنم که در آینده، دریافت اینکه مدلها دقیقاً آنچه را که نیاز داریم با حداقل دستورالعمل خروجی دهند، آسانتر خواهد بود و این تکنیکها اهمیت کمتری پیدا خواهند کرد.
نحوه نمونهبرداری مدلهای هوش مصنوعی از پاسخهایشان، آنها را احتمالی میکند. بیایید یک مثال را بررسی کنیم تا ببینیم منظور از احتمالی بودن چیست. فرض کنید میخواهید بدانید بهترین غذا در جهان کدام است. اگر این سوال را دو بار از دوستتان بپرسید، پاسخهای او هر دو بار باید یکسان باشند. اگر همین سوال را دو بار از یک مدل هوش مصنوعی بپرسید، پاسخ آن میتواند تغییر کند. اگر یک مدل هوش مصنوعی فکر کند که غذاهای ویتنامی 70 درصد شانس بهترین غذا در جهان بودن را دارند و غذاهای ایتالیایی 30 درصد شانس، 70 درصد اوقات “غذاهای ویتنامی” و 30 درصد اوقات “غذاهای ایتالیایی” را پاسخ میدهد. برعکس احتمالی بودن، قطعی بودن (deterministic) است، زمانی که نتیجه را بدون هیچ گونه تغییر تصادفی میتوان تعیین کرد.
این طبیعت احتمالی میتواند باعث ناسازگاری (inconsistency) و توهم (hallucination) شود. ناسازگاری زمانی است که یک مدل پاسخهای بسیار متفاوتی برای یکسان یا کمی متفاوت بودن prompt تولید میکند. توهم زمانی است که یک مدل پاسخی میدهد که مبتنی بر واقعیت نیست. فرض کنید کسی در اینترنت مقالهای نوشته است که تمام رؤسای جمهور ایالات متحده بیگانهاند و این مقاله در دادههای آموزشی گنجانده شده است. مدل بعداً به احتمال زیاد خروجی میدهد که رئیس جمهور فعلی ایالات متحده یک بیگانه است. از دیدگاه کسی که باور ندارد رؤسای جمهور ایالات متحده بیگانهاند، مدل این را اختراع (making this up) میکند.
مدلهای بنیادی معمولاً با استفاده از مقدار زیادی داده آموزش داده میشوند. آنها گردآوری نظرات تودهها (aggregations of the opinions of the masses) هستند و به طور واقعی، دنیایی از امکانات را در خود جای دادهاند. هر چیزی با احتمال غیر صفر، مهم نیست چقدر دور از ذهن یا نادرست باشد، میتواند توسط هوش مصنوعی تولید شود.
این ویژگی، ساختن برنامههای کاربردی هوش مصنوعی را هم هیجانانگیز و هم چالشبرانگیز میکند. بسیاری از تلاشهای مهندسی هوش مصنوعی، همانطور که در این کتاب خواهیم دید، هدفشان مهار و کاهش این طبیعت احتمالی است.
این طبیعت احتمالی هوش مصنوعی را برای وظایف خلاقانه (creative tasks) عالی میکند. خلاقیت چیست جز توانایی کاوش فراتر از مسیرهای رایج - تفکر خارج از چارچوب؟ هوش مصنوعی یک همکار عالی برای متخصصان خلاق است. میتواند ایدههای نامحدودی را مطرح کند و طرحهای بیسابقهای تولید کند. با این حال، این طبیعت احتمالی میتواند برای همه چیزهای دیگر دردسرساز باشد.
ناسازگاری مدل در دو سناریو ظاهر میشود:
ورودی یکسان، خروجیهای متفاوت: دادن همان prompt به مدل دو بار منجر به دو پاسخ بسیار متفاوت میشود.
ورودی کمی متفاوت، خروجیهای به شدت متفاوت: دادن یک promptکمی متفاوت به مدل، مانند اشتباه تایپ کردن یک حرف بزرگ، میتواند منجر به یک خروجی بسیار متفاوت شود.
شکل 2-23 مثالی از تلاش من برای استفاده از ChatGPT برای نمرهدهی به مقالات را نشان میدهد. همان prompt دو نمره متفاوت را زمانی که دو بار اجرا کردم به من داد: 3.5 و 5.5.

ناهمخوانی میتواند تجربه کاربری ناخوشایندی ایجاد کند. در ارتباطات انسان با انسان، انتظار ثبات نسبی را داریم. تصور کنید شخصی هر بار که او را میبینید، نام متفاوتی به شما بدهد. به همین ترتیب، کاربران انتظار ثبات نسبی را در هنگام تعامل با هوش مصنوعی دارند.
برای سناریوی ورودی یکسان، خروجیهای متفاوت، رویکردهای متعددی برای کاهش ناهمخوانی وجود دارد. میتوانید پاسخ را ذخیره کنید تا دفعه بعد که همان سوال پرسیده شد، همان پاسخ برگردانده شود. میتوانید متغیرهای نمونهبرداری مدل، مانند مقادیر دما، top-p و top-k را همانطور که قبلاً بحث شد، ثابت کنید. همچنین میتوانید متغیر seed را ثابت کنید که میتوانید آن را به عنوان نقطه شروع برای مولد اعداد تصادفی مورد استفاده برای نمونهبرداری توکن بعدی در نظر بگیرید.
حتی اگر همه این متغیرها را ثابت کنید، تضمینی وجود ندارد که مدل شما 100٪ مواقع سازگار باشد. سختافزاری که مدل، تولید خروجی را بر روی آن اجرا میکند نیز میتواند بر خروجی تأثیر بگذارد، زیرا ماشینهای مختلف روشهای متفاوتی برای اجرای یک دستورالعمل دارند و میتوانند با محدودههای مختلفی از اعداد کار کنند. اگر مدلهای خود را میزبانی میکنید، کنترل نسبی بر سختافزاری که استفاده میکنید دارید. با این حال، اگر از یک ارائهدهنده API مدل مانند OpenAI یا Google استفاده میکنید، این ارائهدهندگان هستند که باید هرگونه کنترلی را در اختیار شما قرار دهند.
تنظیمات تولید خروجی را اصلاح کردن یک روش خوب است، اما اعتماد به سیستم را جلب نمیکند. تصور کنید معلمی که فقط در صورتی نمرات ثابتی به شما میدهد که در یک اتاق خاص بنشیند. اگر آن معلم در اتاق دیگری بنشیند، نمرات او برای شما غیرقابل پیشبینی خواهد بود.
سناریوی دوم - ورودی کمی متفاوت، خروجیهای به شدت متفاوت - چالشبرانگیزتر است. اصلاح متغیرهای تولید خروجی مدل همچنان یک روش خوب است، اما نمیتوان آن را مجبور کرد که برای ورودیهای مختلف، خروجیهای یکسانی تولید کند. با این حال، با طراحی دقیق دستورالعملها (که در فصل 5 بحث شده است) و یک سیستم حافظه (که در فصل 6 بحث شده است)، میتوان مدلها را وادار کرد تا پاسخهایی نزدیکتر به آنچه میخواهید تولید کنند.
توهم برای وظایفی که به صحت اطلاعات بستگی دارند، فاجعهبار است. اگر از هوش مصنوعی میخواهید به شما در توضیح مزایا و معایب یک واکسن کمک کند، نمیخواهید هوش مصنوعی شبهعلمی باشد.
در ژوئن 2023، یک شرکت حقوقی به دلیل ارائه تحقیقات حقوقی ساختگی به دادگاه جریمه شد. آنها از ChatGPT برای آمادهسازی پرونده خود استفاده کرده بودند، بدون اینکه از تمایل ChatGPT به توهم آگاه باشند.
در حالی که توهم با ظهور مدلهای زبانی بزرگ (LLM) به یک موضوع برجسته تبدیل شده است، توهم یک پدیده رایج برای مدلهای تولیدی حتی قبل از معرفی اصطلاح مدل پایه و معماری ترانسفورمر بود. توهم در زمینه تولید متن از سال 2016 (Goyal et al., 2016) ذکر شده است. تشخیص و اندازهگیری توهم از آن زمان به بعد یک رکن اصلی در تولید زبان طبیعی (NLG) بوده است (به Lee et al., 2018؛ Nie et al., 2019 و Zhou et al., 2020 مراجعه کنید). این بخش بر توضیح چرایی وقوع توهم تمرکز دارد. نحوه تشخیص و اندازهگیری ارزیابی در فصل 4 مورد بحث قرار میگیرد.
اگر ناسازگاری ناشی از تصادفی بودن در فرآیند نمونهبرداری باشد، علت توهم ظریفتر است. فرآیند نمونهبرداری به تنهایی آن را به طور کامل توضیح نمیدهد. یک مدل خروجیها را از بین تمام گزینههای احتمالی نمونهبرداری میکند. اما چگونه چیزی که قبلاً هرگز دیده نشده، به یک گزینه احتمالی تبدیل میشود؟ یک مدل میتواند چیزی را تولید کند که تصور میشود قبلاً در دادههای آموزشی دیده نشده است. ما نمیتوانیم این را با اطمینان بگوییم زیرا غیرممکن است که دادههای آموزشی را برای تأیید اینکه آیا حاوی یک ایده است یا خیر، بررسی کنیم. توانایی ما در ساختن چیزی به قدری پیچیده که دیگر نتوانیم آن را درک کنیم، هم یک موهبت و هم یک نفرین است.
طراحی راهی برای از بین بردن توهم بدون درک چرایی وقوع توهم در وهله اول دشوار است. در حال حاضر دو فرضیه در مورد چرایی توهم زایی مدلهای زبانی وجود دارد.
فرضیه اول، که در سال 2021 توسط اورتگا و همکاران در DeepMind بیان شد، این است که یک مدل زبانی توهم میزند زیرا نمیتواند بین دادههایی که به آن داده میشود و دادههایی که تولید میکند، تمایز قائل شود. برای روشن شدن این موضوع، یک مثال را بررسی میکنیم.
تصور کنید که به مدل دستور میدهید: “چیپ هویون کیست؟” و اولین جملهای که مدل تولید میکند این است: “چیپ هویون یک معمار است.” توکن بعدی که مدل تولید میکند بر اساس دنباله: “چیپ هویون کیست؟ چیپ هویون یک معمار است.” شرطی میشود. مدل “چیپ هویون یک معمار است.”، چیزی که خودش تولید کرده است، را مانند یک واقعیت داده شده، به یک شکل در نظر میگیرد. با شروع یک دنباله تولید شده کمی غیرمعمول، مدل میتواند بر آن گسترش یابد و حقایق به شدت نادرستی تولید کند.
اورتگا و سایر نویسندگان توهم را به عنوان نوعی خودفریب توصیف کردند.
شکل 2-24 مثالی از خودفریب توسط مدل LLaVA-v1.5-7B را نشان میدهد. از مدل خواستم تا مواد تشکیل دهنده فهرست شده بر روی برچسب محصول را شناسایی کند، که یک بطری شامپو است. در پاسخ خود، مدل متقاعد میشود که محصول موجود در تصویر یک بطری شیر است و سپس به گنجاندن شیر در لیست مواد تشکیل دهنده استخراج شده از برچسب محصول ادامه میدهد.

Zhang et al. (2023) این پدیده را توهمات به شکل بهمنوار (snowballing hallucinations) مینامند. پس از ایجاد یک فرض نادرست، یک مدل میتواند به توهم زدن ادامه دهد تا فرض اولیه نادرست را توجیه کند. جالب اینجاست که نویسندگان نشان میدهند که فرضهای اولیه نادرست میتوانند باعث شوند مدل در سوالاتی اشتباه کند که در غیر این صورت میتوانست به درستی به آنها پاسخ دهد، همانطور که در شکل 2-25 نشان داده شده است.

مقاله DeepMind نشان داد که توهمات را میتوان با دو تکنیک کاهش داد.
1. اولین تکنیک از یادگیری تقویتی میآید، در آن مدل آموزش داده میشود تا بین دستورات ارائه شده توسط کاربر (که در یادگیری تقویتی به عنوان مشاهدات در مورد جهان شناخته میشوند) و توکنهای تولید شده توسط مدل (که به عنوان اقدامات مدل شناخته میشوند) تمایز قائل شود.
2. تکنیک دوم بر یادگیری نظارتی تکیه دارد، در آن سیگنالهای واقعی و ضدواقعی در دادههای آموزشی گنجانده میشوند.
فرضیه دوم این است که توهم ناشی از عدم تطابق بین دانش داخلی مدل و دانش داخلی برچسبزننده است. این دیدگاه برای اولین بار توسط لئو گائو، محقق OpenAI، مطرح شد. در طول SFT، مدلها آموزش داده میشوند تا به پاسخهای نوشته شده توسط برچسبزنندگان شبیه شوند. اگر این پاسخها از دانشی استفاده کنند که برچسبزنندگان دارند اما مدل ندارد، در واقع در حال آموزش مدل برای توهم زدن هستیم.
در تئوری، اگر برچسبزنندگان بتوانند دانش خود را با هر پاسخی که مینویسند بگنجانند تا مدل بداند که پاسخها ساختگی نیستند، شاید بتوانیم مدل را آموزش دهیم تا فقط از آنچه میداند استفاده کند. با این حال، این در عمل غیرممکن است.
در آوریل 2023، جان شولمان، یکی از بنیانگذاران OpenAI، همین دیدگاه را در سخنرانی خود در UC Berkeley بیان کرد. شولمان همچنین معتقد است که مدلهای زبانی بزرگ میدانند چه چیزی را میدانند، که خود این ادعایی بزرگ است. اگر این باور درست باشد، میتوان توهمات را با مجبور کردن مدل به ارائه پاسخها بر اساس تنها اطلاعاتی که میداند، رفع کرد. او دو راه حل پیشنهاد کرد. یکی تأیید است: برای هر پاسخ، از مدل منابعی را بخواهید که این پاسخ را بر اساس آن استخراج کند. دیگری استفاده از یادگیری تقویتی است. به یاد داشته باشید که مدل پاداش با استفاده تنها از مقایسهها آموزش داده میشود - پاسخ Aبهتر از پاسخ B است، بدون توضیح اینکه چرا A بهتر است. شولمان استدلال کرد که یک تابع پاداش بهتر که مدل را بیشتر به خاطر ساختن چیزها مجازات میکند، میتواند به کاهش توهمات کمک کند.
پاسخ A در همان سخنرانی، شولمان اشاره کرد که OpenAI دریافت است که RLHF به کاهش توهمات کمک میکند. با این حال، مقاله InstructGPT نشان میدهد که RLHF توهم را بدتر میکند، همانطور که در شکل 2-26 نشان داده شده است. اگرچه RLHF به نظر میرسید توهمات را برای InstructGPT بدتر میکند، اما جنبههای دیگری را بهبود بخشید و در کل، برچسبزنندگان انسانی مدل RLHF را نسبت به مدل SFT تنها ترجیح میدهند.

بر اساس این فرض که یک مدل پایه (foundation model) میداند چه چیزی را میداند، برخی افراد سعی میکنند با استفاده از پرامپتها توهم را کاهش دهند، مانند افزودن این جمله: «تا حد امکان صادقانه پاسخ دهید و اگر از پاسخ مطمئن نیستید، بگویید: ‘متأسفم، نمیدانم.’» درخواست پاسخهای مختصر از مدل نیز به نظر میرسد به کاهش توهم کمک میکند — هرچه مدل توکنهای کمتری تولید کند، احتمال ساختگی بودن مطالب کمتر است. تکنیکهای پرامپتدهی و ساخت زمینه (context construction) در فصلهای ۵ و ۶ نیز میتوانند به کاهش توهم کمک کنند.
دو فرضیه مطرحشده مکمل یکدیگر هستند. فرضیه فریب خودی (self-delusion hypothesis) بر چگونگی ایجاد توهمها توسط یادگیری خودنظارتی (self-supervision) تمرکز دارد، در حالی که فرضیه دانش درونی ناهماهنگ (mismatched internal knowledge hypothesis) بر چگونگی ایجاد توهمها توسط یادگیری نظارتشده (supervision) متمرکز است.
اگر نتوانیم بهطور کامل توهمها را متوقف کنیم، آیا حداقل میتوانیم تشخیص دهیم که مدل چه زمانی دچار توهم شده است تا آن پاسخهای توهمزده را به کاربران ارائه ندهیم؟ خب، تشخیص توهمها نیز چندان ساده نیست — به این فکر کنید که تشخیص دروغ گفتن یا جعل کردن اطلاعات توسط انسان دیگر چقدر دشوار است. اما افراد تلاش کردهاند. در فصل ۴ درباره چگونگی تشخیص و اندازهگیری توهمها بحث خواهیم کرد.
این فصل در مورد تصمیمات طراحی کلیدی هنگام ساخت یک مدل پایه (foundation model) بحث کرد. از آنجایی که اکثر افراد از مدلهای پایه آماده استفاده میکنند تا اینکه از صفر مدلی را آموزش دهند، جزئیات فنی آموزش مدل را کنار گذاشتم و در عوض بر عواملی تمرکز کردم که به شما کمک میکنند تصمیم بگیرید از چه مدلهایی و چگونه استفاده کنید.
۱. دادههای آموزشی (training data): عامل حیاتی عملکرد
عملکرد مدل به شدت به دادههای آموزشی آن وابسته است.
مدلهای بزرگ به حجم عظیمی از داده نیاز دارند که تهیه آن پرهزینه و زمانبر است.
ارائهدهندگان مدل معمولاً از هر داده در دسترسی استفاده میکنند، در نتیجه مدلها ممکن است روی وظایف خاص مورد نظر شما بهینه نباشند.
برای توسعه مدلهای ویژه زبانهای خاص (به ویژه زبانهای کممنبع) و حوزههای تخصصی، گردآوری و پالایش دادههای آموزشی اغلب ضروری است.
۲. معماری و اندازه مدل (model architecture and modelsize)
قبل از آموزش، معماری مدل گام مهمی است.
معماری ترنسفورمر (Transformer) امروزه معماری غالب برای مدلهای پایه مبتنی بر زبان است.
این فصل به مشکلاتی که ترنسفورمر برای حل آنها طراحی شده و همچنین محدودیتهای آن پرداخت.
اندازه مدل با سه شاخص کلیدی سنجیده میشود:
تعداد پارامترها
تعداد توکنهای آموزشی
تعداد عملیات ممیز شناور (FLOPs) مورد نیاز برای آموزش
دو عامل حجم محاسبات مورد نیاز برای آموزش را تعیین میکنند: اندازه مدل و اندازه داده.
قانون مقیاسگذاری (Scaling Law) به تعیین تعداد بهینه پارامترها و توکنها با توجه به بودجه محاسباتی کمک میکند.
همچنین گلوگاههای مقیاسگذاری بررسی شد. در حال حاضر، بزرگتر کردن مدل عموماً آن را بهتر میکند، اما سؤال این است که این روند تا چه زمانی ادامه خواهد داشت؟
۳. آموزش پسین (Post-Training) برای همسو کردن خروجیها
به دلیل کیفیت پایین دادههای آموزشی و ماهیت خودنظارتی (self-supervision) در مرحله پیشآموزش، خروجی مدل ممکن است با خواسته کاربران همسو نباشد.
این مشکل از طریق پس-آموزش در دو مرحله برطرف میشود:
۱. تنظیم دقیق نظارتشده (Supervised Fine-Tuning - SFT)
۲. تنظیم دقیق مبتنی بر ترجیح (Preference Fine-Tuning) که اغلب از یادگیری تقویتی از بازخورد انسانی (RLHF) استفاده میکند.
ترجیحات انسانی متنوع است و نمیتوان آن را در یک فرمول ریاضی واحد گنجاند، بنابراین راهحلهای موجود بینقص نیستند.
این فصل همچنین یکی از موضوعات مورد علاقه من را پوشش داد: نمونهگیری (Sampling)، فرآیندی که طی آن مدل توکنهای خروجی را تولید میکند. نمونهگیری مدلهای هوش مصنوعی را احتمالی (Probabilistic) میسازد. این ماهیت احتمالی است که مدلهایی مانند ChatGPT و Gemini را برای وظایف خلاقانه عالی و برای گفتگو جذاب میکند. با این حال، همین ماهیت احتمالی نیز منجر به ناسازگاری (Inconsistency) و توهم (Hallucinations) میشود.
کار کردن با مدلهای هوش مصنوعی مستلزم طراحی گردشکارها (Workflows) حول این ماهیت احتمالی آنهاست. باقی این کتاب به بررسی این موضوع میپردازد که چگونه مهندسی هوش مصنوعی را، اگر نه کاملاً قطعی (Deterministic)، حداقل سیستماتیک (Systematic) بسازیم.
اولین گام به سوی مهندسی سیستماتیک هوش مصنوعی، ایجاد یک خط لوله ارزیابی (Evaluation Pipeline) مستحکم برای کمک به تشخیص شکستها و تغییرات غیرمنتظره است.
ارزیابی برای مدلهای پایه آنقدر حیاتی است که دو فصل از این کتاب را به آن اختصاص دادهام، که از فصل بعد آغاز میشود.