ترجمه کتاب ساخت برنامههای کاربردی با مدلهای پایه - انتشارات O’Reilly
BOOK: O'Reilly_AI_Engineering_Building_Applications_with_Foundation_Models
برای حل یک مسئله، یک مدل هم به دستورالعملهایی درباره نحوه انجام کار نیاز دارد و هم به اطلاعات لازم برای انجام آن. همانطور که انسانها وقتی اطلاعات کافی ندارند احتمال بیشتری دارد پاسخ اشتباه بدهند، مدلهای هوش مصنوعی هم وقتی زمینه (context) کافی ندارند بیشتر اشتباه میکنند یا دچار توهم (hallucination) میشوند.
در یک کاربرد مشخص، دستورالعملهای مدل برای همه پرسشها یکسان هستند، اما متن زمینه (context) برای هر پرسش متفاوت است. در فصل قبلی درباره نحوه نوشتن دستورالعملهای خوب برای مدل صحبت شد. این فصل بر این تمرکز دارد که چگونه برای هر پرسش، زمینه مرتبط ساخته شود.
دو الگوی اصلی برای ساخت متن زمینه عبارتاند از:
· RAG (Retrieval-Augmented Generation): در الگوی RAG، مدل میتواند اطلاعات مرتبط را از منابع داده خارجی بازیابی (retrieve) کند.
· (Agents)عاملها: در الگوی عاملمحور (agentic)، مدل میتواند از ابزارهایی مانند جستجوی وب، APIهای خبری و ابزارهای دیگر برای جمعآوری اطلاعات استفاده کند.
در حالی که الگوی RAG عمدتاً برای ساخت متن زمینه استفاده میشود، الگوی عاملها قابلیتهای بسیار بیشتری دارد. ابزارهای خارجی میتوانند به مدلها کمک کنند نقاط ضعف خود را جبران کنند و تواناییهایشان را گسترش دهند. مهمتر از همه، این ابزارها به مدلها امکان میدهند مستقیماً با دنیای واقعی تعامل داشته باشند و در نتیجه بتوانند بسیاری از جنبههای زندگی ما را خودکار کنند.
هر دو الگوی RAG و Agentic به دلیل قابلیتهایی که به مدلهای قدرتمند اضافه میکنند بسیار هیجانانگیز هستند. در مدت زمان کوتاهی، این مفاهیم توجه گستردهای را جلب کردهاند و باعث ایجاد دموها و محصولات چشمگیری شدهاند که بسیاری را متقاعد کردهاند اینها آینده سیستمهای هوش مصنوعی هستند.
در این فصل، هر یک از این الگوها بهطور مفصل بررسی میشوند، از جمله نحوه کار آنها و دلایلی که آنها را بسیار امیدبخش کرده است.
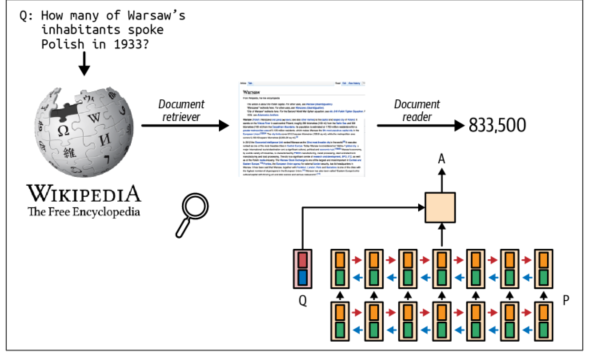
الگوی بازیابی سپس تولید (retrieve-then-generate) نخستین بار در مقاله “Reading Wikipedia to Answer Open-Domain Questions” (Chen et al., 2017) معرفی شد. در این پژوهش، سیستم ابتدا پنج صفحه از ویکیپدیا که بیشترین ارتباط را با یک پرسش دارند بازیابی می کند. سپس یک مدل از اطلاعات موجود در این صفحات استفاده می کند یا آنها را می خواند تا پاسخ پرسش را تولید کند؛ همانطور که در شکل ۶‑۱ نشان داده شده است.
اصطلاح «تولید بازیابیمحور» (Retrieval-Augmented Generation یا RAG) نخستین بار در مقاله «تولید بازیابیمحور برای وظایف پردازش زبان طبیعی دانشبنیان» (Lewis et al., 2020) ابداع شد. این مقاله RAG را به عنوان راهکاری برای وظایف دانشبنیان (knowledge-intensive) پیشنهاد کرد؛ یعنی وظایفی که در آنها نمیتوان تمام دانش موجود را به صورت مستقیم به مدل وارد کرد. در روش RAG، تنها اطلاعاتی که بیشترین ارتباط را با پرسش (query) دارند — که توسط بخش بازیاب (retriever) شناسایی میشوند — استخراج شده و به مدل داده میشوند. لوئیس و همکاران دریافتند که دسترسی به اطلاعات مرتبط میتواند به مدل کمک کند تا پاسخهای با جزئیات بیشتر تولید کند و در عین حال، میزان توهم (hallucination) را کاهش دهد.
برای مثال، اگر پرسش این باشد: «آیا fancy-printer‑A300 شرکت Acme می تواند با سرعت ۱۰۰ صفحه در ثانیه (100pps) چاپ کند؟»،
مدل زمانی می تواند پاسخ بهتری بدهد که مشخصات فنی چاپگر fancy-printer‑A300 در اختیارش قرار داده شود.
می توان RAG را روشی برای ساختن متن زمینه مخصوص هر پرسش در نظر گرفت؛ به جای اینکه برای همه پرسشها از یک زمینه ثابت استفاده شود. این کار به مدیریت دادههای کاربران هم کمک می کند، زیرا می توان دادههای مخصوص هر کاربر را فقط در پرسشهایی که به همان کاربر مربوط هستند وارد کرد.
ساخت متن زمینه (context construction) برای مدلهای بنیادین، معادل مهندسی ویژگیها (feature engineering) در مدلهای کلاسیک یادگیری ماشین است. هر دو یک هدف دارند: دادن اطلاعات لازم به مدل برای پردازش ورودی.
در روزهای اولیه مدلهای بنیادین، RAG به یکی از رایجترین الگوها تبدیل شد. هدف اصلی آن غلبه بر محدودیت طول متن زمینه (context length) در مدلها بود. بسیاری فکر می کنند اگر طول context مدلها به اندازه کافی زیاد شود، دیگر نیازی به RAG نخواهد بود. اما این طور نیست. نخست اینکه مهم نیست طول context یک مدل چقدر باشد؛ همیشه کاربردهایی وجود دارند که به زمینهای طولانیتر از آن نیاز دارند. در نهایت، حجم دادههای موجود دائماً در حال افزایش است. مردم مرتب دادههای جدید تولید و اضافه می کنند، اما به ندرت دادهها را حذف می کنند. در نتیجه، اگرچه طول context مدلها به سرعت در حال افزایش است، اما هنوز به اندازهای سریع رشد نمی کند که نیاز دادهای همه کاربردهای ممکن را پوشش دهد.
دوم اینکه مدلی که می تواند متن زمینه طولانی را پردازش کند، لزوماً از آن به خوبی استفاده نمی کند؛ همانطور که در بخش «طول context و کارایی استفاده از آن» (صفحه ۲۱۸) بحث شده است. هرچه context طولانیتر باشد، احتمال اینکه مدل روی بخش نادرستی از آن تمرکز کند بیشتر می شود. علاوه بر این، هر توکن اضافی در context هزینه بیشتری ایجاد می کند و می تواند باعث افزایش تاخیر (latency) شود. روش RAG به مدل اجازه می دهد برای هر پرسش فقط مرتبطترین اطلاعات را استفاده کند. این کار باعث می شود تعداد توکنهای ورودی کاهش پیدا کند و در عین حال عملکرد مدل نیز بهبود یابد.
تلاشها برای افزایش طول context همزمان با تلاشها برای بهبود توانایی مدلها در استفاده موثر از context در حال انجام است. بعید نیست که ارائهدهندگان مدلها در آینده مکانیزمهایی شبیه بازیابی (retrieval-like) یا توجه (attention-like) را در مدلها ادغام کنند تا مدل بتواند مهمترین و برجستهترین بخشهای context را بهتر شناسایی و استفاده کند.
شرکت Anthropic پیشنهاد داده است که برای مدلهای Claude، اگر پایگاه دانش شما کمتر از ۲۰۰٬۰۰۰ توکن باشد (تقریباً معادل ۵۰۰ صفحه متن)، می توانید کل پایگاه دانش را مستقیماً در پرامپتی که به مدل می دهید قرار دهید و در این حالت نیازی به استفاده از RAG یا روشهای مشابه نخواهد بود (Anthropic، ۲۰۲۴). اگر سایر توسعهدهندگان مدلها نیز راهنماییهای مشابهی درباره انتخاب بین RAG و استفاده از context طولانی برای مدلهای خود ارائه دهند، بسیار مفید و ارزشمند خواهد بود.
معماری RAG
یک سیستم RAG دو مولفه دارد:
یک بازیاب (Retriever) که اطلاعات را از منابع حافظه خارجی بازیابی می کند.
یک مولد (Generator) که بر اساس اطلاعات بازیابیشده پاسخ تولید می کند.

در مقاله اصلی RAG، پژوهشگران Lewis و همکاران بازیاب و مدل مولد را بهصورت مشترک آموزش دادند. اما در سیستمهای RAG امروزی، این دو مولفه اغلب بهطور جداگانه آموزش داده می شوند و بسیاری از تیمها سیستمهای RAG خود را با استفاده از بازیابها و مدلهای آماده (off‑the‑shelf) می سازند. با این حال، فاینتیون کردن کل سیستم RAG بهصورت end‑to‑end می تواند عملکرد آن را بهطور قابلتوجهی بهبود دهد.
موفقیت یک سیستم RAG تا حد زیادی به کیفیت بازیاب (retriever) آن بستگی دارد. یک بازیاب دو وظیفه اصلی دارد:
ایندکسگذاری (Indexing)
پرسوجو (Querying)
ایندکسگذاری شامل پردازش دادهها به شکلی است که بعداً بتوان آنها را بهسرعت بازیابی کرد. ارسال یک پرسوجو برای بازیابی دادههای مرتبط با آن Querying نامیده می شود. نحوه ایندکسگذاری دادهها به این بستگی دارد که بعداً چگونه قصد دارید آنها را بازیابی کنید.
اکنون که مولفههای اصلی را بررسی کردیم، بیایید یک مثال ساده از نحوه کار یک سیستم RAG را در نظر بگیریم. برای سادگی فرض کنید حافظه خارجی یک پایگاه داده از اسناد است؛ مانند یادداشتهای داخلی شرکت، قراردادها و صورتجلسههای جلسات. یک سند (document) میتواند ۱۰ توکن داشته باشد یا حتی یک میلیون توکن. اگر بهصورت ساده و بدون پردازش کل اسناد بازیابی شوند، طول context می تواند بهطور دلخواه بسیار بزرگ شود. برای جلوگیری از این مشکل، می توان هر سند را به بخشهای کوچکتر و قابلمدیریتتر (chunks) تقسیم کرد. استراتژیهای chunking در ادامه همین فصل بررسی خواهند شد. در حال حاضر فرض می کنیم که همه اسناد به بخشهای قابل استفاده تقسیم شدهاند. برای هر پرسوجو (query)، هدف ما این است که بخشهای دادهای را بازیابی کنیم که بیشترین ارتباط را با آن پرسوجو دارند. سپس معمولاً مقداری پردازش پس از بازیابی (post‑processing) انجام می شود تا بخشهای داده بازیابیشده با پرامپت کاربر ترکیب شوند و پرامپت نهایی ساخته شود. این پرامپت نهایی سپس به مدل مولد (generative model) داده می شود.
در این فصل، از واژه «سند» (document) برای اشاره به هر دو مفهوم «سند» و «چانک» (chunk) استفاده میکنم، زیرا از نظر فنی یک چانک از یک سند نیز خود نوعی سند محسوب می شود. این کار برای حفظ سازگاری اصطلاحات این کتاب با اصطلاحات رایج در پردازش زبان طبیعی کلاسیک (NLP) و بازیابی اطلاعات (Information Retrieval یا IR) انجام شده است.
Retrieval Algorithms
الگوریتمهای بازیابی (Retrieval Algorithms)
بازیابی فقط مختص RAG نیست. بازیابی اطلاعات (Information Retrieval) ایدهای است که بیش از یک قرن قدمت دارد. این فناوری ستون فقرات موتورهای جستجو، سیستمهای توصیهگر، تحلیل لاگها و بسیاری از سیستمهای دیگر است. بسیاری از الگوریتمهای بازیابی که برای سیستمهای بازیابی سنتی توسعه یافتهاند، می توانند در سیستمهای RAG نیز استفاده شوند. برای مثال، بازیابی اطلاعات یک حوزه پژوهشی بسیار گسترده و فعال است که صنعت بزرگی از آن پشتیبانی می کند و به همین دلیل پوشش کامل آن در چند صفحه ممکن نیست. بنابراین، این بخش فقط مفاهیم کلی و خطوط اصلی را پوشش می دهد. برای منابع عمیقتر درباره بازیابی اطلاعات می توانید به مخزن GitHub این کتاب مراجعه کنید.
معمولاً retrieval به بازیابی اطلاعات از یک پایگاه داده یا یک سیستم مشخص محدود می شود، در حالی که search به بازیابی اطلاعات از چندین سیستم مختلف اشاره دارد. در این فصل، واژههای retrieval و search بهصورت جایگزین یکدیگر استفاده می شوند.
در سادهترین شکل، بازیابی اطلاعات با رتبهبندی اسناد بر اساس میزان ارتباط آنها با یک پرسوجو (query) عمل می کند. تفاوت الگوریتمهای بازیابی در این است که امتیاز ارتباط (relevance score) چگونه محاسبه می شود.
در ادامه، دو روش رایج بازیابی معرفی می شوند:
بازیابی مبتنی بر واژه (term‑based retrieval)
بازیابی مبتنی بر امبدینگ (embedding‑based retrieval)
Sparse Versus Dense Retrieval
بازیابی Sparse در برابر Dense
در ادبیات پژوهشی، گاهی الگوریتمهای بازیابی به دو دسته sparse و dense تقسیم می شوند. اما در این کتاب، بهجای این تقسیمبندی از دستهبندی بازیابی مبتنی بر واژه (term‑based) در برابر بازیابی مبتنی بر امبدینگ (embedding‑based) استفاده شده است.
بازیابهای sparse دادهها را با استفاده از بردارهای تنک (sparse vectors) نمایش می دهند. بردار تنک برداری است که بیشتر مقادیر آن صفر هستند. بازیابی مبتنی بر واژه معمولاً sparse در نظر گرفته می شود، زیرا هر واژه می تواند با یک بردار one‑hot تنک نمایش داده شود؛ یعنی برداری که در همه جای آن مقدار ۰ است بهجز یک مقدار ۱. اندازه این بردار برابر با اندازه واژگان (vocabulary) است و مقدار ۱ در شاخصی قرار می گیرد که متناظر با موقعیت آن واژه در واژگان است.
برای مثال اگر یک واژهنامه ساده داشته باشیم:
{“food”: 0, “banana”: 1, “slug”: 2}
در این صورت بردارهای one‑hot این واژهها چنین خواهند بود:
food → [1, 0, 0]
banana → [0, 1, 0]
slug → [0, 0, 1]
در مقابل، بازیابهای dense دادهها را با استفاده از بردارهای چگال (dense vectors) نمایش می دهند؛ یعنی بردارهایی که بیشتر مقادیرشان صفر نیست. بازیابی مبتنی بر امبدینگ (embedding) معمولاً در دسته dense قرار می گیرد، زیرا امبدینگها معمولاً بردارهای چگال هستند. با این حال، امبدینگهای sparse نیز وجود دارند. برای مثال، SPLADE (Sparse Lexical and Expansion) یک الگوریتم بازیابی است که از امبدینگهای تنک استفاده می کند (Formal و همکاران، ۲۰۲۱). این روش از امبدینگهای تولیدشده توسط BERT استفاده می کند، اما با استفاده از regularization بیشتر مقادیر امبدینگ را به صفر نزدیک می کند. این تنکی (sparsity) باعث می شود عملیات روی امبدینگها کارآمدتر انجام شود.
تقسیمبندی sparse در برابر dense باعث می شود الگوریتم SPLADE در همان گروه الگوریتمهای مبتنی بر واژه قرار بگیرد، در حالی که نحوه عملکرد، نقاط قوت و ضعف آن بسیار شبیه به بازیابی مبتنی بر امبدینگهای dense است تا بازیابی مبتنی بر واژه. به همین دلیل، تقسیمبندی term‑based در برابر embedding‑based از این دستهبندی اشتباه جلوگیری می کند.
بازیابی مبتنی بر واژه (Term‑based Retrieval)
با داشتن یک پرسوجو (query)، سادهترین روش برای پیدا کردن اسناد مرتبط استفاده از کلیدواژهها (keywords) است. برخی افراد این روش را بازیابی واژگانی (lexical retrieval) می نامند. برای مثال، اگر پرسوجو «AI engineering» باشد، سیستم تمام اسنادی را بازیابی می کند که عبارت «AI engineering» را در خود دارند.
اما این روش دو مشکل دارد:
ممکن است تعداد زیادی سند شامل آن واژه باشند و مدل شما فضای context کافی برای قرار دادن همه آنها نداشته باشد. یک روش ابتکاری این است که اسنادی انتخاب شوند که آن واژه در آنها بیشترین تعداد تکرار را دارد. فرض بر این است که هرچه یک واژه در یک سند بیشتر تکرار شود، آن سند به آن واژه مرتبطتر است. تعداد دفعاتی که یک واژه در یک سند ظاهر می شود فراوانی واژه (Term Frequency یا TF) نامیده می شود.
یک پرامپت می تواند طولانی باشد و شامل واژههای زیادی باشد، در حالی که همه واژهها اهمیت یکسانی ندارند. برای مثال، پرامپت «Easy‑to‑follow recipes for Vietnamese food to cook at home» شامل ۹ واژه است: easy‑to‑follow، recipes، for، vietnamese، food، to، cook، at، home. در اینجا بهتر است روی واژههای اطلاعاتیتر مثل vietnamese و recipes تمرکز شود، نه واژههایی مانند for یا at. بنابراین نیاز داریم روشی برای شناسایی واژههای مهمتر داشته باشیم.
وقتی میخواهیم اهمیت یک واژه را بسنجیم، یک شهود ساده این است: هرچه یک واژه در اسناد بیشتری ظاهر شود، اطلاعات کمتری منتقل می کند. برای مثال واژههایی مثل “for” یا “at” تقریباً در بیشتر اسناد دیده می شوند، بنابراین اطلاعات خاصی درباره موضوع سند نمیدهند. به همین دلیل اهمیت یک واژه برعکس تعداد اسنادی است که آن واژه در آنها ظاهر می شود. این معیار Inverse Document Frequency (IDF) نام دارد.
محاسبه IDF
برای محاسبه IDF یک واژه:
تعداد تمام اسناد را در نظر بگیرید.
تعداد اسنادی را بشمارید که آن واژه در آنها وجود دارد.
تعداد کل اسناد را بر تعداد اسناد شامل آن واژه تقسیم کنید.
مثال: اگر ۱۰ سند داشته باشیم و ۵ سند شامل یک واژه باشند:

هرچه IDF بزرگتر باشد، آن واژه مهمتر است.
الگوریتم TF‑IDF
TF‑IDF الگوریتمی است که دو معیار را با هم ترکیب می کند:
TF (Term Frequency): تعداد دفعات حضور یک واژه در یک سند
IDF (Inverse Document Frequency): میزان نادر بودن آن واژه در کل مجموعه اسناد
فرمول محاسبه امتیاز TF‑IDF برای سند D نسبت به پرسوجو Q
فرض کنید واژههای پرسوجو اینها باشند:


= تعداد دفعات حضور واژه t در سند D
N = تعداد کل اسناد

= تعداد اسنادی که واژه t را دارند
در این صورت:

و امتیاز نهایی سند:

یعنی برای هر واژه پرسوجو:
اهمیت واژه (IDF)
ضرب در تعداد تکرار آن در سند (TF)
و سپس همه آنها جمع می شوند.
سیستمهای معروف Term‑based Retrieval
دو راهحل رایج برای بازیابی مبتنی بر واژه عبارتاند از Elasticsearch و BM25.
الاستیکسرچ (Elasticsearch)، ساخته شی بنیون (Shay Banon) در سال ۲۰۱۰، که بر پایه Lucene بنا شده است، از ساختار دادهای به نام ایندکس معکوس (inverted index) استفاده میکند.
این ساختار، در واقع یک فرهنگ لغت است که واژهها را به اسنادی که آنها را در بر دارند نگاشت میکند.
این دیکشنری امکان بازیابی بسیار سریع اسناد بر اساس یک واژه را فراهم میسازد.
این ایندکس همچنین ممکن است اطلاعات اضافی نیز ذخیره کند؛ مانند:
فراوانی واژه در سند (term frequency)
تعداد اسنادی که شامل آن واژهاند (document count)
که این اطلاعات برای محاسبهی امتیازهای TF‑IDF مفید هستند.
جدول ۶‑۱ یک نمونه ساده از یک ایندکس معکوس را نشان میدهد.

اوکاپی BM25، بیستوپنجمین نسل از الگوریتم Best Matching، توسط رابرتسون و همکاران در دهه ۱۹۸۰ توسعه داده شد. روش امتیازدهی آن نسخهای اصلاحشده از TF‑IDF است. در مقایسه با TF‑IDF ساده، BM25 امتیاز فراوانی واژه (TF) را بر اساس طول سند نرمالسازی میکند. علت این کار این است که سندهای بلندتر احتمال بیشتری دارند که یک واژه را شامل شوند و بنابراین مقدار TF بالاتری خواهند داشت.
BM25 و نسخههای آن (BM25+ و BM25F) همچنان بهطور گسترده در صنعت استفاده میشوند و بهعنوان خطپایههای قدرتمند برای مقایسه با الگوریتمهای بازیابی مدرنتر و پیچیدهتر به کار میروند؛ مانند بازیابی مبتنی بر امبدینگها (embedding‑based retrieval) که در ادامه معرفی میشود.
یک مرحلهای که قبلاً مختصر از آن گذر کردیم توکنسازی (Tokenization) است؛ یعنی فرایند تبدیل یک پرسوجو به واژههای مجزا. سادهترین روش این است که پرسوجو را بر اساس فاصلهها به کلمات تقسیم کنیم و هر کلمه را یک «ترم» در نظر بگیریم. اما این روش یک مشکل دارد: ترمهای چندکلمهای را تکهتکه میکند و معنای اصلی از بین میرود. مثلاً عبارت: “hot dog” به دو واژهی «hot» و «dog» تقسیم میشود، در حالی که هیچکدام معنای عبارت اصلی را منتقل نمیکنند. یکی از راههای حل این مشکل این است که n‑gramهای پرکاربرد را بهعنوان ترم در نظر بگیریم. اگر بیگرام “hot dog” رایج باشد، سیستم آن را بهعنوان یک ترم واحد در نظر میگیرد.
همچنین معمولاً هنگام پردازش پرسوجو:
همه حروف را به کوچک (lowercase) تبدیل میکنند،
علائم نگارشی را حذف میکنند،
کلمات توقف (stop words) مثل “the”، “and” و “is” را حذف میکنند.
سیستمهای بازیابی مبتنی بر واژه معمولاً این کارها را بهصورت خودکار انجام میدهند. بستههای کلاسیک NLP مانند NLTK، spaCy و CoreNLP نیز ابزارهای توکنسازی ارائه میکنند.
در فصل ۴ توضیح داده شد که چگونه میتوان شباهت واژگانی (lexical similarity) دو متن را بر اساس همپوشانی n‑gramها اندازهگیری کرد. آیا میتوان اسناد را بر اساس میزان همپوشانی n‑gram آنها با پرسوجو بازیابی کرد؟ بله، میتوان. این روش زمانی بهترین عملکرد را دارد که طول پرسوجو و طول اسناد تقریباً مشابه باشد. اگر اسناد خیلی بلندتر باشند، احتمال اینکه n‑gramهای پرسوجو را در خود داشته باشند زیاد است. بنابراین:
تعداد زیادی سند امتیاز همپوشانی مشابهی خواهند داشت
تشخیص اینکه کدام سند واقعاً مرتبطتر است سخت میشود
بازیابی مبتنی بر واژه (Term‑based retrieval) ارتباط را در سطح واژگانی میسنجد، نه در سطح معنایی. همانطور که در فصل ۳ اشاره شد، ظاهر یک متن لزوماً معنای آن را نشان نمیدهد. به همین دلیل، این روش ممکن است اسنادی را بازگرداند که با هدف شما مرتبط نیستند. برای مثال، اگر عبارت “transformer architecture” را جستوجو کنید، ممکن است اسنادی درباره دستگاه الکتریکی ترانسفورماتور یا فیلم Transformers دریافت کنید. در مقابل، بازیابی مبتنی بر امبدینگ (embedding‑based retrieval) تلاش میکند اسناد را بر اساس میزان هممعنایی با پرسوجو رتبهبندی کند. به این رویکرد semantic retrieval (بازیابی معنایی) نیز گفته میشود.
در بازیابی مبتنی بر امبدینگ (embedding‑based retrieval)، مرحلهی ایندکسسازی یک وظیفهی اضافه هم دارد:تبدیل قطعهدادههای اصلی(data chunks) به امبدینگ.
پایگاهی که این امبدینگهای تولیدشده در آن ذخیره میشوند، پایگاه دادهی برداری (vector database) نام دارد.
فرایند پرسوجو (Querying) سپس شامل دو مرحله است، همانطور که در شکل 6‑3 نشان داده شده:
مدل امبدینگ (Embedding model): تبدیل پرسوجو به یک امبدینگ، با همان مدل امبدینگی که هنگام ایندکسسازی استفاده شده است.
بازیاب (Retriever): واکشی k قطعهداده که امبدینگ آنها از نظر فاصله، نزدیکترین موارد به امبدینگ پرسوجو هستند.
مقدار k بسته به مورد استفاده، مدل مولد، و نوع پرسوجو تعیین میشود.

جریان کاریِ بازیابی مبتنی بر امبدینگ که در اینجا نشان داده شده، نسخهی سادهشده است. سیستمهای واقعیِ بازیابی معنایی ممکن است شامل اجزای دیگری نیز باشند، مانند:
reranker برای بازچینش و رتبهبندی مجدد همهی نتایج واکشیشده
cacheها برای کاهش زمان پاسخگویی (latency)
در بازیابی مبتنی بر امبدینگ، دوباره با امبدینگها سروکار پیدا میکنیم—که در فصل ۳ توضیح داده شده بودند. برای یادآوری امبدینگ معمولاً یک بردار است که سعی میکند ویژگیهای مهم دادهی اصلی را حفظ کند. اگر مدل امبدینگ کیفیت خوبی نداشته باشد، بازیاب مبتنی بر امبدینگ هم عمل نخواهد کرد.
بازیابی مبتنی بر امبدینگ یک مؤلفهی جدید نیز معرفی میکند: پایگاه دادهی برداری (vector database). یک پایگاه دادهی برداری، بردارها را ذخیره میکند. اما ذخیره کردن بخش آسان کار است؛ بخش سخت، جستوجوی برداری (vector search) است. وقتی یک امبدینگ پرسوجو دریافت میشود، پایگاه دادهی برداری مسئول است که بردارهای نزدیک به آن را در پایگاه داده پیدا کند و آنها را برگرداند. بردارها باید به شکلی ساختارمند و بهینه ذخیره و ایندکس شوند تا جستوجوی برداری سریع و کارآمد انجام شود.
همانند بسیاری از سازوکارهایی که برنامههای هوش مصنوعی مولد به آنها وابستهاند، جستوجوی برداری مختص هوش مصنوعی مولد نیست. این نوع جستوجو در هر برنامهای که از امبدینگ استفاده میکند رایج است: جستوجو، توصیهگرها، سازماندهی داده، بازیابی اطلاعات، خوشهبندی، تشخیص تقلب و بسیاری موارد دیگر.
جستوجوی برداری معمولاً به صورت یک مسئلهی نزدیکترین همسایهها (Nearest-Neighbor Search) صورتبندی میشود. برای مثال، داده شده یک پرسوجو، k بردار نزدیک را پیدا کن. راهحل سادهی این مسئله k‑nearest neighbors (kNN) است که مراحل آن چنین است:
محاسبهی نمرهی شباهت میان امبدینگ پرسوجو و همهی بردارهای پایگاه داده، با معیارهایی مانند cosine similarity.
رتبهبندی همهی بردارها بر اساس نمرهی شباهت.
بازگرداندن k بردار با بالاترین نمرهی شباهت.
این روش ساده دقت کامل دارد، اما از نظر محاسباتی سنگین و کند است، و فقط برای مجموعهدادههای کوچک مناسب است.
برای مجموعهدادههای بزرگ، جستوجوی برداری معمولاً با استفاده از الگوریتمهای جستوجوی تقریبی نزدیکترین همسایهها (ANN, Approximate Nearest Neighbor) انجام میشود. به دلیل اهمیت جستوجوی برداری، الگوریتمها و کتابخانههای زیادی برای آن ساخته شدهاند. برخی از کتابخانههای محبوب عبارتاند از:
FAISS (Facebook AI Similarity Search) — Johnson et al., 2017
ScaNN (Scalable Nearest Neighbors) از گوگل — Sun et al., 2020
Annoy از اسپاتیفای — Bernhardsson, 2013
Hnswlib (Hierarchical Navigable Small World) — Malkov & Yashunin, 2016
بیشتر توسعهدهندگان برنامهها معمولاً خودشان جستوجوی برداری را پیادهسازی نمیکنند، بنابراین در اینجا فقط یک مرور سریع از رویکردهای مختلف ارائه میکنم. این مرور ممکن است هنگام ارزیابی راهحلها مفید باشد.
به طور کلی، پایگاههای دادهی برداری، بردارها را در قالب bucketها، درختها (trees) یا گرافها (graphs) سازماندهی میکنند. تفاوت الگوریتمهای جستوجوی برداری معمولاً در هیوریستیکهایی است که برای افزایش احتمال قرارگیری بردارهای مشابه در کنار هم استفاده میکنند. همچنین میتوان بردارها را کمدقتسازی (quantization) یا پراکندگی (sparsification) کرد. ایده این است که بردارهای کمدقت یا پراکنده محاسبات سبکتری دارند. برای کسانی که میخواهند دربارهی جستوجوی برداری بیشتر یاد بگیرند، شرکت Zilliz یک سری آموزشی بسیار خوب در این زمینه دارد. در ادامه، چند الگوریتم مهم جستوجوی برداری معرفی میشود:
LSH (locality-sensitive hashing) — Indyk & Motwani, 1999
این یک الگوریتم قدرتمند و انعطافپذیر است که فقط روی بردارها کاربرد ندارد. LSH با هش کردن بردارهای مشابه در یک bucket مشترک به جستوجوی شباهت سرعت میبخشد و مقداری دقت را فدای کارایی میکند. این روش در FAISS و Annoy پیادهسازی شده است.
HNSW (Hierarchical Navigable Small World) — Malkov & Yashunin, 2016
HNSW یک گراف چندلایه میسازد که در آن گرهها نمایندهی بردارها هستند و یالها بردارهای مشابه را به هم وصل میکنند. جستوجوی نزدیکترین همسایه با پیمایش این یالها انجام میشود. پیادهسازی متنباز آن توسط خود نویسندگان ارائه شده و همچنین در FAISS و Milvus نیز پیادهسازی شده است.
Product Quantization (PQ) — Jégou et al., 2011
در این روش، هر بردار به چند زیربردار (subvector) تجزیه میشود و به یک نمایش سادهتر و کمبعدتر تبدیل میگردد. فاصلهها بر اساس این نمایشهای کمبعدتر محاسبه میشوند که بسیار سریعتر است. Product Quantization یک جزء کلیدی در FAISS است و تقریباً همهی کتابخانههای محبوب جستوجوی برداری از آن پشتیبانی میکنند.
IVF (inverted file index) — Sivic & Zisserman, 2003
IVF از K-means clustering برای گروهبندی بردارهای مشابه در یک خوشه استفاده میکند. بسته به اندازهی پایگاه داده، تعداد خوشهها معمولاً بهگونهای تنظیم میشود که در هر خوشه بین 100 تا 10,000 بردار قرار گیرد. در زمان پرسوجو، IVF مرکز خوشههایی را که به امبدینگ پرسوجو نزدیکتر هستند پیدا میکند و بردارهای آن خوشهها به عنوان کاندیدا بررسی میشوند. به همراه Product Quantization، IVF بخش اصلی معماری FAISS را تشکیل میدهد.
Annoy (Approximate Nearest Neighbors Oh Yeah) — Bernhardsson, 2013
Annoy یک رویکرد درختی (tree-based) است. این روش چندین درخت دودویی میسازد که هر کدام بردارها را با استفاده از معیارهای تصادفی تقسیم میکنند—مثلاً یک خط تصادفی رسم میشود و بردارها به دو شاخه تقسیم میشوند. در زمان جستوجو، این درختها پیمایش میشوند تا همسایههای کاندیدا پیدا شوند. پیادهسازی آن توسط شرکت Spotify متنباز شده است.
الگوریتمهای دیگری نیز وجود دارند، مانند SPTAG مایکروسافت (Space Partition Tree And Graph) و FLANN (Fast Library for Approximate Nearest Neighbors).
با اینکه «پایگاه دادهی برداری» همراه با رشد RAG به یک دستهی مستقل تبدیل شد، اما در واقع هر پایگاه دادهای که بتواند بردار ذخیره کند، میتواند یک پایگاه دادهی برداری محسوب شود.
بسیاری از پایگاههای دادهی سنتی تا امروز پشتیبانی از ذخیرهسازی بردار و جستوجوی برداری را اضافه کردهاند یا در آینده اضافه خواهند کرد.
مقایسه ی الگوریتمهای بازیابی (Comparing retrieval algorithms)
به دلیل سابقهی طولانی حوزهی بازیابی اطلاعات، وجود راهکارهای بالغ و متعدد باعث شده است که شروع کار با بازیابی مبتنی بر واژه (term‑based) و بازیابی مبتنی بر امبدینگ (embedding‑based) نسبتاً ساده باشد. هر رویکرد مزایا و معایب خود را دارد.
بازیابی مبتنی بر واژه معمولاً هم در مرحلهی ایندکسسازی و هم در مرحلهی پرسوجو بسیار سریعتر از بازیابی مبتنی بر امبدینگ است. استخراج واژهها سریعتر از تولید امبدینگ است، و نگاشت یک واژه به اسنادی که آن را شامل میشوند معمولاً از جستوجوی نزدیکترین همسایهها محاسبات کمتری نیاز دارد.
این روش همچنین «بهصورت پیشفرض» عملکرد خوبی دارد. راهکارهایی مانند Elasticsearch و BM25 سالهاست که پشت بسیاری از سامانههای جستوجو و بازیابی قرار داشتهاند. اما همین سادگی باعث میشود اجزای کمتری برای بهینهسازی داشته باشد.
در مقابل، بازیابی مبتنی بر امبدینگ میتواند با گذر زمان بهطور قابل توجهی بهبود یافته و از روش مبتنی بر واژه بهتر عمل کند. میتوان مدل امبدینگ و رتریور را—بهصورت جداگانه، با هم، یا همراه با مدل زایشی—فاینتیون کرد. با این حال، تبدیل دادهها به امبدینگ ممکن است باعث پنهان شدن کلمات کلیدی شود، مانند کدهای خطای خاص مثل EADDRNOTAVAIL (99) و نامهای محصول. در نتیجه یافتن مستقیم این موارد سختتر میشود. این محدودیت را میتوان با ترکیب بازیابی مبتنی بر امبدینگ با بازیابی مبتنی بر واژه برطرف کرد (که در ادامه فصل توضیح داده میشود).
ارزیابی کیفیت یک رتریور (Retriever)
کیفیت رتریور را میتوان بر اساس کیفیت دادههایی که بازیابی میکند سنجید. دو معیار رایج که توسط چارچوبهای ارزیابی RAG استفاده میشوند عبارتند از:
· دقت زمینه (Context Precision)
از میان تمام اسناد بازیابیشده، چه درصدی مرتبط با پرسوجو هستند؟
بهصورت خلاصه، Context Precision را Context Relevance نیز مینامند.
· بازخوانی زمینه (Context Recall)
از میان تمام اسناد مرتبط موجود در پایگاه داده، چه درصدی بازیابی شدهاند؟
برای محاسبهی این معیارها باید:
یک مجموعهی ارزیابی شامل پرسوجوهای آزمایشی و مجموعهای از اسناد تهیه کنید.
برای هر پرسوجو، ارتباط هر سند را بهصورت «مرتبط / نامرتبط» حاشیهنویسی کنید.این کار را میتوان با انسان یا قاضیهای هوش مصنوعی انجام داد.
سپس دقت (precision) و بازخوانی (recall) را روی این مجموعه محاسبه کنید.
چرا برخی سامانههای RAG فقط Precision را محاسبه میکنند؟
در محیط عملیاتی (production)، بسیاری از چارچوبهای RAG تنها از context precision پشتیبانی میکنند، نه context recall. دلیل آن این است که برای محاسبهی recall باید ارتباط تمامی اسناد پایگاه داده با پرسوجو حاشیهنویسی شود، که پرهزینه و زمانبر است. در مقابل، محاسبهی precision آسانتر است، چون فقط باید اسناد بازیابیشده را بررسی کرد—کاری که میتوان حتی با قاضیهای AI انجام داد.
اگر برای شما ترتیب اسناد بازیابیشده اهمیت دارد—مثلاً اسناد مرتبطتر باید در رتبههای بالاتر قرار گیرند—میتوانید از معیارهایی مانند NDCG (normalized discounted cumulative gain)، MAP (Mean Average Precision)، و MRR (Mean Reciprocal Rank) استفاده کنید.
برای بازیابی معنایی (semantic retrieval) لازم است کیفیت امبدینگها را نیز ارزیابی کنید. همانطور که در فصل ۳ اشاره شد، امبدینگها را میتوان بهصورت مستقل ارزیابی کرد—اگر اسناد مشابهتر امبدینگهای نزدیکتری داشته باشند، امبدینگها «خوب» تلقی میشوند. امبدینگها را همچنین میتوان با توجه به عملکردشان در وظایف خاص ارزیابی کرد. بنچمارک MTEB (Muennighoff et al., 2023) امبدینگها را برای طیف وسیعی از وظایف، از جمله بازیابی، طبقهبندی، و خوشهبندی ارزیابی میکند.
کیفیت یک رتریور باید در بافت کل سیستم RAG ارزیابی شود. در نهایت، یک رتریور زمانی «خوب» است که به سیستم کمک کند پاسخهای باکیفیت تولید کند.ارزیابی خروجی مدلهای مولد در فصلهای ۳ و ۴ بحث شده است.
اینکه «وعدهی عملکرد بهتر» در یک سیستم بازیابی معنایی ارزش دنبالکردن داشته باشد یا نه، بستگی به این دارد که چقدر هزینه و latency—بهخصوص در فاز پرسوجو—برای شما مهم است. از آنجا که بخش عمدهی تأخیر RAG از تولید خروجی مدل مولد میآید، مخصوصاً برای پاسخهای طولانی، تأخیری که از تولید امبدینگ پرسوجو و جستوجوی برداری ایجاد میشود ممکن است نسبت به کل تأخیر RAG کم باشد.
بااینحال، همین تأخیر اضافی همچنان میتواند بر تجربهی کاربر اثر بگذارد. نگرانی دیگر هزینه است. تولید امبدینگ هزینه دارد—و اگر دادههای شما مرتب تغییر میکند و نیازمند بازتولید مکرر امبدینگها هستید، این هزینه مهمتر میشود. تصور کنید مجبور باشید هر روز برای ۱۰۰ میلیون سند امبدینگ بسازید! علاوه بر این، بسته به اینکه از چه پایگاه داده برداری استفاده میکنید، ذخیرهسازی بردارها و پرسوجوهای جستوجوی برداری نیز میتوانند گران باشند. این موضوع غیرمعمول نیست که هزینهی یک شرکت برای پایگاه دادهی برداری یک پنجم تا حتی نصف هزینهی مصرف API مدلها باشد.
جدول 6‑2 یک مقایسهی کنارهم (side-by-side) بین بازیابی مبتنی بر واژه و بازیابی معنایی مبتنی بر امبدینگ در ابعاد سرعت، عملکرد، و هزینه نشان میدهد.

در سیستمهای بازیابی، میتوانید بین ایندکسسازی و پرسوجو یکسری تاختوتاز (trade-off) انجام دهید. هرچه ایندکس جزئیات بیشتری داشته باشد، فرآیند بازیابی دقیقتر خواهد بود؛ اما ایندکسسازی کندتر شده و حافظهی بیشتری مصرف میکند. برای مثال، تصور کنید در حال ساخت یک ایندکس از مشتریان بالقوه هستید. افزودن جزئیات بیشتر (مانند نام، شرکت، ایمیل، تلفن، علایق) پیدا کردن افراد مرتبط را آسانتر میکند، اما زمان بیشتری برای ساخت ایندکس لازم دارد و فضای ذخیرهسازی بیشتری میخواهد.
بهطور کلی:
یک ایندکس جزئی و پیشرفته مانند HNSW دقت بالا و زمان پرسوجوی سریع ارائه میدهد، اما زمان و حافظهی زیادی برای ساخت لازم دارد.
در مقابل، یک ایندکس سادهتر مانند LSH سریعتر و کممصرفتر ساخته میشود، اما پرسوجوها را کندتر و کمدقتتر انجام میدهد.
وبسایت ANN‑Benchmarks الگوریتمهای ANN مختلف را روی چندین مجموعه داده با چهار معیار اصلی مقایسه میکند که این trade-off بین ایندکسسازی و پرسوجو را در نظر میگیرند:
· Recall: سهمی از نزدیکترین همسایهها که الگوریتم واقعاً پیدا میکند.
· Queries Per Second (QPS): تعداد پرسوجوهایی که الگوریتم میتواند در هر ثانیه پردازش کند. این معیار برای اپلیکیشنهای پرترافیک حیاتی است.
· Build time: زمان لازم برای ساخت ایندکس. این معیار زمانی مهم است که نیاز به بهروزرسانی مکرر ایندکس داشته باشید (مثلاً وقتی دادهها مرتب تغییر میکنند).
· Index size: حجم ایندکسی که الگوریتم تولید میکند. این معیار برای بررسی مقیاسپذیری و نیازهای ذخیرهسازی اهمیت دارد.
علاوه بر این، BEIR (Benchmarking IR) (Thakur et al., 2021) یک چارچوب ارزیابی برای سیستمهای بازیابی است. BEIR از سیستمهای retrieval روی ۱۴ بنچمارک رایج پشتیبانی میکند.
کیفیت یک سیستم RAG باید هم جزءبهجزء و هم انتهابهانتها (end‑to‑end) ارزیابی شود. برای این کار باید:
کیفیت بازیابی را ارزیابی کنید.
خروجی نهایی RAG را ارزیابی کنید.
کیفیت امبدینگها را (در بازیابی مبتنی بر امبدینگ) اندازهگیری کنید.
ترکیب الگوریتمهای بازیابی (Combining retrieval algorithms)
با توجه به مزایای متفاوت الگوریتمهای مختلف بازیابی، سیستمهای عملیاتی معمولاً چند رویکرد را با هم ترکیب میکنند. ترکیب بازیابی مبتنی بر واژه و بازیابی مبتنی بر امبدینگ جستوجوی هیبریدی (hybrid search) نام دارد.
الگوریتمهای مختلف را میتوان بهصورت ترتیبی استفاده کرد. ابتدا یک بازیاب ارزان و کمدقتتر—مانند یک سیستم مبتنی بر واژه—فهرستی از اسناد کاندید را بازیابی میکند. سپس یک سازوکار دقیقتر اما گرانتر—مانند k-nearest neighbors—بهترین اسناد را از میان این کاندیدها انتخاب میکند. این مرحلهی دوم را بازرتبهبندی (reranking) نیز مینامند.
برای مثال، با توجه به واژهی «transformer»، میتوانید همهی اسنادی را که این واژه را دارند بازیابی کنید—چه دربارهی ترانسفورماتور برقی باشند، چه معماری عصبی Transformer یا فیلم Transformers. سپس از جستوجوی برداری استفاده میکنید تا از میان این اسناد، آنهایی را پیدا کنید که واقعاً با پرسوجوی شما مرتبطاند. مثلا پرسوجوی «چه کسی مسئول بیشترین فروش به X است؟». ابتدا میتوانید با کلیدواژهی X همهی اسناد مربوط به X را بازیابی کنید. سپس از جستوجوی برداری استفاده میکنید تا متنی را پیدا کنید که با بخش «چه کسی مسئول بیشترین فروش است؟» مرتبط باشد.
الگوریتمهای مختلف را میتوان بهصورت موازی نیز استفاده کرد، مثل یک ensemble. به یاد داشته باشید که یک بازیاب اسناد را بر اساس نمرهی ارتباط (relevance score) رتبهبندی میکند. میتوانید چند بازیاب را همزمان اجرا کنید، فهرستهای رتبهبندی مختلف را دریافت کنید، و سپس این رتبهبندیها را با هم ترکیب کنید تا رتبهبندی نهایی بهدست آید.
یکی از الگوریتمهای ترکیب رتبهبندیها ترکیب رتبهی متقابل یا Reciprocal Rank Fusion (RRF) است (Cormack et al., 2009).
این روش برای هر سند، بر اساس رتبهاش نزد یک بازیاب، یک نمره تعیین میکند. مفهوم پشت آن ساده است:
اگر سندی رتبهی اول باشد، نمرهاش برابر است با1/1 = 1
اگر رتبهی دوم باشد، نمرهاش برابر است با1/2 = 0.5
هرچه رتبه بهتر باشد، نمرهی بیشتری میگیرد.
نمرهی نهایی یک سند برابر است با جمع نمرههای آن در میان تمام بازیابها. مثلاً اگر سندی نزد یک بازیاب رتبهی اول و نزد بازیاب دیگر رتبهی دوم باشد: 1 + 0.5 = 1.5 . این مثال نسخهای سادهشده از RRF است، اما اصول آن را نشان میدهد. فرمول واقعی برای سند D پیچیدهتر است و بهصورت زیر بیان میشود:
Score(D) = Σᵢ 1 / (k + rankᵢ(D))
• n تعداد فهرستهای رتبهبندی است؛ هر فهرست رتبهبندی توسط یک رتریور (retriever) تولید میشود.
• rᵢ(D) رتبهی سند D توسط رتریور i است.
• k یک ثابت است برای جلوگیری از تقسیم بر صفر و همچنین برای کنترل میزان اثرگذاری اسناد با رتبههای پایینتر. مقدار متداول برای k = 60 است.
بهینهسازی بازیابی (Retrieval Optimization)
بسته به وظیفهای که پیش رو دارید، برخی تکنیکها میتوانند احتمال بازیابی اسناد مرتبط را افزایش دهند.
چهار تاکتیک که در اینجا مطرح میشوند عبارتاند از:
استراتژی قطعهبندی (chunking strategy)
بازرتبهبندی (reranking)
بازنویسی پرسوجو (query rewriting)
بازیابی زمینهای (contextual retrieval)
1. استراتژی قطعهبندی (Chunking Strategy)
اینکه دادههای خود را چگونه ایندکس کنید، بستگی دارد به اینکه بعداً قصد دارید چگونه آنها را بازیابی کنید. در بخش قبلی، الگوریتمهای مختلف بازیابی و استراتژیهای ایندکسسازی آنها را بررسی کردیم. در آن بحث، فرض بر این بود که اسناد از قبل به قطعات (chunks) قابل مدیریت تقسیم شدهاند. در این بخش، به استراتژیهای مختلف چانککردن میپردازم. این موضوع بسیار مهم است، زیرا استراتژی قطعهبندی شما میتواند تأثیر قابلتوجهی بر عملکرد سیستم بازیابی داشته باشد.
سادهترین استراتژی، تقسیم اسناد به قطعاتی با طول ثابت و بر اساس یک واحد مشخص است. واحدهای رایج شامل حروف، واژهها، جملهها و پاراگرافها هستند. برای مثال، میتوانید هر سند را به قطعاتی با اندازهی ۲۰۴۸ کاراکتر یا ۵۱۲ کلمه تقسیم کنید. همچنین میتوانید سند را به گونهای تقسیم کنید که هر چانک تعداد ثابتی جمله (مثلاً ۲۰ جمله) یا پاراگراف داشته باشد (مثلاً هر پاراگراف یک چانک باشد).
همچنین میتوانید اسناد را بهصورت بازگشتی (recursively) با واحدهای کوچکتر تقسیم کنید تا هر چانک در محدودهی حداکثر اندازهی مجاز قرار گیرد. برای مثال، میتوانید ابتدا سند را به بخشها تقسیم کنید. اگر یک بخش خیلی طولانی بود، آن را به پاراگرافها خرد کنید. اگر پاراگراف هم طولانی بود، آن را به جملهها تقسیم کنید. این رویکرد احتمال جدا شدن دلبخواهیِ بخشهای مرتبط از یکدیگر را کاهش میدهد.
برخی اسناد ممکن است از استراتژیهای خلاقانهی چانککردن پشتیبانی کنند. برای مثال:
برای زبانهای برنامهنویسی، اسپلیترهای مخصوص وجود دارد.
اسناد پرسشوپاسخ را میتوان بر اساس هر زوج سؤال/پاسخ قطعهبندی کرد.
متنهای چینی ممکن است نیازمند روشهای متفاوتی نسبت به متنهای انگلیسی باشند.
وقتی سندی بدون همپوشانی (overlap) چانک میشود، ممکن است چانکها در میانهی یک زمینهی مهم بریده شوند، و بخش مهمی از اطلاعات از دست برود. وبرای مثال، متن «من برای همسرم یک یادداشت گذاشتم» را در نظر بگیرید. اگر آن را به «من برای همسرم» و «یک یادداشت» تقسیم کنید، هیچکدام از این چانکها معنای اصلی را منتقل نمیکنند. همپوشانی کمک میکند اطلاعات حیاتی مربوط به مرز چانکها حداقل در یکی از چانکها باقی بماند. اگر اندازهی چانک ۲۰۴۸ کاراکتر است، میتوانید اندازهی همپوشانی را مثلاً ۲۰ کاراکتر تنظیم کنید.
اندازهی چانک نباید از حداکثر طول کانتکست مدل مولد فراتر رود. در روش مبتنی بر امبدینگ، اندازهی چانک همچنین نباید از حداکثر کانتکست مدل امبدینگ بیشتر باشد.
روش دیگر این است که اسناد را بر اساس توکنها—که توسط توکنایزر مدل مولد تعیین میشود—چانک کنید. فرض کنید میخواهید از Llama 3 بهعنوان مدل مولد استفاده کنید. ابتدا اسناد را با توکنایزر Llama 3 توکنسازی میکنید. سپس اسناد را بر اساس مرزهای توکن به چانکهای جداگانه تقسیم میکنید. چانککردن بر اساس توکن باعث میشود تعامل با مدلهای پاییندستی آسانتر شود. اما نقطهضعف این روش این است که اگر به مدل مولد دیگری با توکنایزر متفاوت مهاجرت کنید، باید دادهها را دوباره ایندکس کنید.
فارغ از اینکه کدام استراتژی را انتخاب کنید، اندازهی چانکها اهمیت زیادی دارد.
چانکهای کوچکتر امکان تنوع اطلاعاتی بیشتر را فراهم میکنند. با چانکهای کوچک، میتوانید تعداد چانکهای بیشتری را در کانتکست مدل قرار دهید. اگر اندازهی چانک را نصف کنید، میتوانید دو برابر چانک در کانتکست مدل جای دهید. چانکهای بیشتر میتوانند مدل را در معرض دامنهی وسیعتری از اطلاعات قرار دهند و در نتیجه به تولید پاسخ بهتر کمک کنند. اما چانکهای خیلی کوچک میتوانند باعث از دست رفتن اطلاعات مهم شوند.
فرض کنید سندی در سراسر خود اطلاعات مهمی دربارهی موضوع X دارد، اما واژهی X تنها در نیمهی اول متن آمده است. اگر سند را به دو چانک تقسیم کنید، نیمهی دوم ممکن است بازیابی نشود، و بنابراین مدل نتواند از اطلاعات آن استفاده کند.
چانکهای کوچک همچنین میتوانند هزینهی محاسباتی را افزایش دهند. این موضوع بهخصوص در بازیابی مبتنی بر امبدینگ مشکلساز است. اگر اندازهی چانک را نصف کنید:
تعداد چانکها دو برابر میشود
تعداد امبدینگهایی که باید تولید و ذخیره شوند دو برابر میشود
فضای جستوجوی برداری دو برابر میشود
سرعت پرسوجو ممکن است کاهش یابد
هیچ اندازهی بهینهی جهانی برای چانک یا اندازهی همپوشانی وجود ندارد. باید آزمایش کنید تا اندازهای که برای کاربرد شما بهترین است را پیدا کنید.
2. بازرتبهبندی (Reranking)
رتبهبندی اولیه ی اسناد که توسط بازیاب تولید میشود، میتواند دوباره بازرتبهبندی شود تا دقت آن افزایش یابد. بازرتبهبندی زمانی بهویژه مفید است که نیاز دارید تعداد اسناد بازیابیشده را کاهش دهید—چه برای جا دادن آنها در کانتکست مدل و چه برای کاهش تعداد توکنهای ورودی.
یکی از الگوهای رایج برای بازرتبهبندی در بخش «ترکیب الگوریتمهای بازیابی» در صفحه ۲۶۶ توضیح داده شده است. در این الگو، یک بازیاب ارزان اما کمدقت مجموعهای از کاندیدها را بازیابی میکند، و سپس یک مکانیزم دقیقتر اما پرهزینهتر این کاندیدها را دوباره مرتب (rerank) میکند.
اسناد همچنین میتوانند بر اساس زمان بازرتبهبندی شوند، بهطوریکه دادههای جدیدتر وزن بیشتری بگیرند. این کار برای کاربردهای حساس به زمان بسیار مفید است، مانند:
پایش و گردآوری اخبار
چت با ایمیلها (مثلاً چتباتی که به ایمیلهای اخیر شما پاسخ میدهد)
تحلیل بازار سهام
بازرتبهبندی در زمینهی RAG (Context Reranking) با بازرتبهبندی سنتی موتورهای جستوجو متفاوت است، زیرا موقعیت دقیق آیتمها اهمیت کمتری دارد. در جستوجو، رتبه ی نتایج (مثلاً رتبهی اول یا پنجم بودن) بسیار مهم است. اما در بازرتبهبندی زمینهای، ترتیب اسناد همچنان اهمیت دارد—چون بر نحوهی پردازش آنها توسط مدل اثر میگذارد. مدلها معمولاً اسنادی را که در ابتدای یا انتهای کانتکست قرار گرفتهاند بهتر درک میکنند (همانطور که در «طول کانتکست و کارایی کانتکست» در صفحه ۲۱۸ آمده است). با این حال، تا زمانی که سند در کانتکست حضور داشته باشد، اثر دقیق ترتیب آن کمتر مهم است—نسبت به رتبهبندی سنتی موتورهای جستوجو.
3. بازنویسی پرسش (Query Rewriting)
بازنویسی پرسش که با نامهای اصلاح پرسش (Query Reformulation)، نرمالسازی پرسش (Query Normalization) و گاهی گسترش پرسش (Query Expansion) نیز شناخته میشود، به معنای بازنویسی ورودی کاربر برای ایجاد یک پرسش واضحتر و قابلبازیابیتر است.
به گفتوگوی زیر توجه کنید:
کاربر: آخرین باری که John Doe از ما خرید کرد چه زمانی بود؟
هوش مصنوعی: جان دو هفته پیش، در تاریخ ۳ ژانویهی ۲۰۳۰، یک کلاه Fruity Fedora از ما خرید.
کاربر: Emily Doe چطور؟
پرسش آخر («Emily Doe چطور؟») بدون زمینه مبهم است.
اگر این پرسش را همانطور که هست به سیستم بازیابی بدهید، احتمالاً نتایج نامرتبط برمیگردند. این پرسش باید بازنویسی شود تا نشان دهد کاربر واقعاً چه میخواهد. پرسش جدید باید بهصورت مستقل و قابلفهم باشد. در این مثال، پرسش باید به این صورت بازنویسی شود:
«آخرین باری که Emily Doe از ما خرید کرد چه زمانی بود؟»
هرچند من بازنویسی پرسش را در بخش RAG (صفحه ۲۵۳) قرار دادهام، اما این مفهوم مختص RAG نیست. در موتورهای جستوجوی سنتی، بازنویسی پرسش معمولاً با روشهای ابتکاری (heuristics) انجام میشود. در برنامههای مبتنی بر هوش مصنوعی، بازنویسی پرسش میتواند توسط مدلهای دیگر نیز انجام شود، با پرامپتی مشابه این:
«با توجه به گفتوگوی زیر، آخرین ورودی کاربر را طوری بازنویسی کن که نشان دهد کاربر واقعاً چه میخواهد.»
شکل ۶‑۴ نشان میدهد که ChatGPT چگونه با همین پرامپت پرسش را بازنویسی کرده است.

بازنویسی پرسش میتواند پیچیده شود، بهویژه زمانی که نیاز به انجام تشخیص هویت (Identity Resolution) یا ترکیب اطلاعات دیگر داشته باشید. برای مثال، اگر کاربر بپرسد: «همسرش چطور؟»
ابتدا باید از پایگاه دادهی خود هویت همسر آن فرد را بازیابی کنید. اگر این اطلاعات در دسترس نباشد، مدل بازنویس پرسش باید این موضوع را صادقانه اعلام کند—یعنی بیان کند که پرسش قابل حل نیست—نه اینکه بهصورت توهمی (Hallucinate) اسمی را حدس بزند، زیرا این کار منجر به پاسخ نادرست میشود.
4. بازیابی زمینهای (Contextual Retrieval)
ایدهی اصلی در بازیابی زمینهای این است که هر چانک را با زمینهی مرتبط غنیسازی کنیم تا بازیابی چانکهای مرتبط آسانتر شود. یک تکنیک ساده این است که چانکها را با متادیتاهایی مانند تگها و کلمات کلیدی غنی کنیم. در تجارت الکترونیک، یک محصول را میتوان با توضیحات محصول و نقدها/بررسیها غنی کرد. تصاویر و ویدئوها را نیز میتوان با استفاده از عنوان (title) و زیرنویس (caption) آنها جستوجو کرد.
متادیتا همچنین میتواند شامل موجودیتهایی (entities) باشد که بهطور خودکار از چانک استخراج میشوند.
برای مثال، اگر سند شما شامل اصطلاحاتی خاص مانند کد خطای EADDRNOTAVAIL (99) باشد، افزودن این کلمهها به متادیتا باعث میشود سیستم بتواند این سند را با همین کلیدواژه بازیابی کند—حتی پس از اینکه سند به امبدینگ تبدیل شده باشد.
همچنین میتوانید هر چانک را با سوالاتی که قادر است پاسخ دهد غنی کنید. در پشتیبانی مشتری، هر مقاله را میتوان با پرسشهای مرتبط گسترش داد. مثلاً مقالهی «چگونه رمز عبور خود را ریست کنم؟» میتواند با پرسشهایی مثل موارد زیر غنی شود:
«چطور رمز عبور را ریست کنم؟»
«رمز عبورم را فراموش کردم.»
«نمیتوانم وارد حسابم شوم.»
«کمک! حسابم را پیدا نمیکنم.»
اگر یک سند به چندین چانک تقسیم شود، بعضی چانکها ممکن است فاقد زمینهی کافی باشند تا بازیاب بتواند تشخیص دهد چانک دربارهی چیست. برای جلوگیری از این مشکل، میتوان هر چانک را با زمینهی سند اصلی غنی کرد—مثلاً عنوان و خلاصهی سند اصلی. شرکت Anthropic از مدلهای هوش مصنوعی برای تولید یک زمینهی کوتاه (۵۰ تا ۱۰۰ توکن) استفاده کرده است که توضیح میدهد چانک دربارهی چیست و چه ارتباطی با سند اصلی دارد. این پرامپتی است که Anthropic برای این کار استفاده کرده است (Anthropic, 2024):
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document:
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else
زمینهی کوتاهی که برای هر چانک تولید میشود، در ابتدای آن prepend میشود (یعنی بهصورت پیشوند قبل از متن اصلی چانک قرار میگیرد).
سپس چانکِ غنیشده (augmented chunk) توسط الگوریتم بازیابی ایندکس میشود. شکل ۶‑۵ فرایندی را که شرکت Anthropic دنبال میکند، بهصورت بصری نشان میدهد

این کار باعث میشود بازیاب (retriever) بتواند هنگام دریافت پرسوجو، چانکهای مرتبط را آسانتر پیدا کند.
تصویر برگرفته از مقالهی “Introducing Contextual Retrieval” اثر Anthropic (2024) است.
ارزیابی راهحلهای بازیابی (Evaluating Retrieval Solutions)
در هنگام ارزیابی یک راهحل بازیابی، باید به عوامل کلیدی زیر توجه کنید:
• از چه سازوکارهای بازیابی پشتیبانی میکند؟ آیا از جستوجوی هیبریدی (Hybrid Search) پشتیبانی میکند؟
• اگر یک پایگاه دادهی برداری است، چه مدلهای امبدینگ و چه الگوریتمهای جستوجوی برداری را پشتیبانی میکند؟
• مقیاسپذیری آن چقدر است؟ هم از نظر ظرفیت ذخیرهسازی دادهها و هم از نظر حجم ترافیک پرسوجو. آیا برای الگوهای ترافیکی شما مناسب است؟
• چقدر طول میکشد تا دادههای شما را ایندکس کند؟ و چه مقدار داده را میتواند بهصورت عمده (bulk) اضافه یا حذف کند؟
• زمان تأخیر (Latency) پرسوجو برای الگوریتمهای مختلف بازیابی چقدر است؟
• اگر سرویس مدیریتشده (Managed) است، ساختار قیمتگذاری آن چگونه است؟ آیا بر اساس حجم اسناد/بردارها قیمتگذاری میشود یا بر اساس حجم پرسوجو؟
این فهرست شامل قابلیتهایی نمیشود که معمولاً در راهحلهای سازمانی (Enterprise) دیده میشوند، مانند:
کنترل دسترسی (Access Control)، سازگاری و تطابق (Compliance)، جداسازی Data Plane و Control Plane، و سایر ویژگیهای مشابه.
بخش قبلی دربارهی سیستمهای RAG مبتنی بر متن بود، جایی که منابع دادهی خارجی شامل اسناد متنی بودند. اما منابع خارجی میتوانند چندحالته (Multimodal) یا جدولی (Tabular) نیز باشند.
RAG چندحالته (Multimodal RAG)
اگر ژنراتور شما چندحالته باشد، میتوان زمینهی آن را نهتنها با اسناد متنی، بلکه با تصاویر، ویدئو، صوت و دیگر دادهها نیز تقویت کرد. برای سادگی، مثالها از تصاویر استفاده میکنند، اما میتوانید تصویر را با هر نوع دادهی دیگری جایگزین کنید. در این حالت، پس از دریافت یک پرسش، بازیاب (retriever) میتواند هم متن و هم تصاویر مرتبط را بازیابی کند. برای مثال، اگر پرسش این باشد: «رنگ خانه در فیلم Up از پیکسار چیست؟» بازیاب میتواند یک تصویر از خانهی فیلم Up را پیدا کند تا به مدل کمک کند پاسخ بهتری تولید کند؛ همانگونه که در شکل ۶‑۶ نشان داده شده است.

اگر تصاویر دارای متادیتا باشند—مانند عنوان، تگها یا کپشن—میتوان آنها را بر اساس همین متادیتا بازیابی کرد. برای مثال، اگر کپشن یک تصویر با پرسش مرتبط باشد، آن تصویر بازیابی میشود.
اما اگر بخواهید تصاویر بر اساس محتوای واقعیشان بازیابی شوند، باید راهی برای مقایسهی تصاویر با پرسشها داشته باشید. اگر پرسشها متنی هستند، نیاز به یک مدل امبدینگ چندحالته دارید که بتواند هم برای متن و هم برای تصویر امبدینگ بسازد. فرض کنیم از مدل CLIP (Radford et al., 2021) بهعنوان مدل امبدینگ چندحالته استفاده میکنید. در این حالت، بازیاب (retriever) به این صورت کار میکند:
برای تمام دادههایتان—چه متن و چه تصویر—امبدینگهای CLIP تولید کنید و آنها را در یک پایگاه دادهی برداری ذخیره کنید.
برای هر پرسش (query)، امبدینگ CLIP آن را تولید کنید.
در پایگاه دادهی برداری جستوجو کنید تا تمام تصاویر و متنهایی را که امبدینگشان به امبدینگ پرسش نزدیک است، بازیابی کنید.
RAG با دادههای جدولی (Tabular RAG)
بیشتر اپلیکیشنها تنها با دادههای بدون ساختار مثل متن و تصویر کار نمیکنند، بلکه دادههای جدولی نیز دارند. بسیاری از پرسشها ممکن است برای پاسخ نیازمند اطلاعات موجود در جداول داده باشند. جریان کاری (workflow) برای غنیسازی زمینه با دادههای جدولی بهطور قابل توجهی با جریان کاری کلاسیک RAG متفاوت است.
فرض کنید برای یک فروشگاه تجارت الکترونیک به نام Kitty Vogue کار میکنید که تخصصش مد و لباس برای گربهها است. این فروشگاه یک جدول سفارشات دارد به نام Sales که نمونهای از آن در جدول ۶‑۳ نشان داده شده است.
جدول ۶‑۳. یک نمونه از جدول سفارشات Sales برای فروشگاه خیالی Kitty Vogue.

برای تولید پاسخی به پرسش «در ۷ روز گذشته چند واحد از Fruity Fedora فروخته شده است؟» سیستم شما باید این جدول را کوئری بزند تا تمام سفارشهایی را که شامل Fruity Fedora هستند پیدا کرده و تعداد واحدها را در همهی سفارشها جمع کند. فرض کنید این جدول از طریق SQL قابل کوئریزدن است. کوئری SQL ممکن است به شکل زیر باشد:
SELECT SUM(units) AS total_units_sold
FROM Sales
WHERE product_name = 'Fruity Fedora'
AND timestamp >= DATE_SUB(CURDATE(), INTERVAL 7 DAY);
جریان کاری (workflow) در شکل ۶‑۷ نمایش داده شده است. برای اجرای این جریان، سیستم شما باید توانایی تولید و اجرای کوئری SQL را داشته باشد.
1. Text‑to‑SQL: بر اساس پرسش کاربر و شِمای جدولهای داده، مشخص کنید که چه کوئری SQL لازم است. Text‑to‑SQL نوعی تحلیل معنایی (semantic parsing) است (همانطور که در فصل ۲ توضیح داده شد).
2. اجرای SQL: کوئری SQL را اجرا کنید.
3. تولید نهایی: بر اساس نتیجهی SQL و پرسش اولیهی کاربر، یک پاسخ تولید کنید.

در مرحلهی Text‑to‑SQL، اگر تعداد زیادی جدول در دسترس باشد و شِمای همهی آنها در کانتکست مدل جا نشود، ممکن است به یک مرحلهی میانی نیاز داشته باشید تا مشخص کند برای هر پرسش کدام جدولها باید استفاده شوند. فرایند Text‑to‑SQL میتواند توسط همان مدل مولدی انجام شود که پاسخ نهایی را تولید میکند، یا توسط یک مدل تخصصی Text‑to‑SQL.
در این بخش دیدیم که چگونه ابزارهایی مانند بازیابها (retrievers) و اجراکنندههای SQL به مدلها اجازه میدهند دامنهی وسیعتری از پرسشها را پوشش دهند و پاسخهای باکیفیتتری تولید کنند. اما آیا دادن ابزارهای بیشتر به یک مدل، تواناییهای آن را باز هم افزایش میدهد؟ استفاده از ابزار (Tool Use) یکی از ویژگیهای محوری الگوی عاملمحور (Agentic Pattern) است که در بخش بعدی دربارهی آن صحبت خواهیم کرد.
عاملهای هوشمند (Intelligent Agents)
عاملهای هوشمند (Intelligent Agents) از دید بسیاری، هدف نهایی هوش مصنوعی بهشمار میآیند. کتاب کلاسیک Stuart Russell و Peter Norvig با عنوان Artificial Intelligence: A Modern Approach (نشر Prentice Hall، 1995) حوزهٔ پژوهش در هوش مصنوعی را چنین تعریف میکند: “مطالعه و طراحی عاملهای عقلانی (rational agents).” قابلیتهای بیسابقهٔ مدلهای پایه (Foundation Models) درهای جدیدی را بهسوی کاربردهای عاملمحور (agentic applications) گشودهاند؛ کاربردهایی که پیشتر غیرقابل تصور بودند.
این قابلیتهای نوین اکنون امکان توسعهٔ عاملهای خودمختار و هوشمندی را فراهم کردهاند که میتوانند نقش دستیار، همکار، یا مربی ما را ایفا کنند.
این عاملها میتوانند:
برای ما یک وبسایت ایجاد کنند
داده جمعآوری کنند
سفر برنامهریزی کنند
تحقیقات بازار انجام دهند
حساب مشتری مدیریت کنند
ورود دادهها را خودکار کنند
ما را برای مصاحبه آماده کنند
از طرف ما با نامزدهای شغلی مصاحبه کنند
یک قرارداد را مذاکره کنند
و بسیاری کارهای دیگر
امکانات تقریباً بیپایان بهنظر میرسند و ارزش اقتصادی بالقوهٔ این عاملها بسیار عظیم است.
عاملهای مبتنی بر هوش مصنوعی (AI‑powered agents) یک حوزهٔ نوظهور هستند و هنوز چارچوبهای نظری تثبیتشدهای برای تعریف، توسعه، و ارزیابی آنها وجود ندارد. این بخش تلاشی است برای ساختن یک چارچوب بر اساس ادبیات پژوهشی موجود؛ اما همانطور که این حوزه رشد میکند، این چارچوب نیز تکامل خواهد یافت. در مقایسه با دیگر بخشهای کتاب، این بخش جنبهٔ آزمایشی بیشتری دارد.
این بخش با یک مرور کلی بر عاملها (agents) آغاز میشود، و سپس دو بُعدی را بررسی میکند که تواناییهای یک عامل را تعیین میکنند:
ابزارها (Tools)
برنامهریزی (Planning)
با توجه به شیوههای جدیدی که عاملها برای عمل کردن دارند، آنها همچنین نوعهای جدیدی از شکستها را بهوجود میآورند. بنابراین، این بخش با بحثی دربارهٔ چگونگی ارزیابی عاملها برای شناسایی این شکستها به پایان میرسد.
با وجود آنکه عاملها جدید هستند، بر پایهٔ مفاهیمی بنا شدهاند که پیشتر در این کتاب معرفی شدهاند؛ از جمله:
Self‑critique
Chain‑of‑thought
Structured outputs
مرور عاملها (Agent Overview)
اصطلاح عامل (agent) در حوزههای مختلف مهندسی به کار میرود؛ از جمله عامل نرمافزاری، عامل هوشمند، user agent، عامل مکالمهای و عامل یادگیری تقویتی. پس دقیقاً عامل چیست؟
عامل، هر چیزی است که بتواند محیط خود را درک کند و بر آن محیط عمل انجام دهد.
به همین دلیل، یک عامل با دو چیز تعریف میشود:
محیطی که در آن فعالیت میکند
مجموعهٔ اقداماتی که قادر به انجام آن است
محیط (Environment): محیط یک عامل توسط مورد استفاده (use case) آن تعیین میشود. برای مثال:
اگر عاملی برای بازی کردن در یک بازی طراحی شده باشد (Minecraft، Go، Dota)،آن بازی محیط عامل است.
اگر عامل برای اسکرپ کردن اسناد از اینترنت طراحی شود،اینترنت محیط آن است.
اگر یک عامل ربات آشپز باشد،آشپزخانه محیط آن است.
عامل یک خودروی خودران،سیستم جاده و مناطق اطراف آن را بهعنوان محیط دارد.
اقدامات و ابزارها (Actions & Tools)
مجموعهٔ اقداماتی که عامل میتواند انجام دهد، با ابزارهایی که در اختیار دارد تقویت میشود. بسیاری از اپلیکیشنهای هوش مصنوعی مولد که روزانه با آنها تعامل دارید، در واقع عاملهایی دارای ابزار هستند، هرچند ابزارهایشان ساده باشد. برای مثال:
ChatGPT یک عامل است:میتواند جستوجوی وب انجام دهد، کد پایتون اجرا کند، و تصویر بسازد.
سیستمهای RAG نیز عاملاند:ابزارهای آنها شامل retriever متنی، retriever تصویری، و SQL executor است.
وابستگی میان محیط و ابزار
میان محیط یک عامل و مجموعهٔ ابزارهای آن یک وابستگی قوی وجود دارد. محیط تعیین میکند که چه ابزارهایی میتوانند وجود داشته باشند. مثال: اگر محیط یک عامل بازی شطرنج باشد، تنها اقداماتی که امکانپذیرند حرکات معتبر شطرنج هستند. اما موجودی ابزارهای یک عامل محیطی را که میتواند در آن فعالیت کند، محدود میکند. برای مثال، اگر تنها اقدام ممکن برای یک ربات شنا کردن باشد، آن ربات به محیط آبی محدود خواهد شد.
شکل 6‑8 یک نسخهٔ تصویری از SWE-agent (یانگ و همکاران، 2024) را نشان میدهد؛ عاملی که بر پایهٔ GPT‑4 ساخته شده است.
محیط این عامل، رایانه با ترمینال و سیستم فایل است. مجموعهٔ اقدامات آن شامل پیمایش مخزن کد (navigate repo)، جستوجوی فایلها، مشاهدهٔ فایلها و ویرایش خطوط است.

یک عامل هوش مصنوعی قرار است وظایفی را انجام دهد که معمولاً توسط کاربر در ورودیها ارائه میشوند. در یک عامل هوش مصنوعی:
AI نقش «مغز» را ایفا میکند
اطلاعات دریافتی را پردازش میکند (از جمله خودِ وظیفه و بازخورد محیط)
یک توالی از اقدامات را برای رسیدن به هدف برنامهریزی میکند
و تعیین میکند که آیا وظیفه به پایان رسیده است یا نه
مثال: RAG با دادههای جدولی (Kitty Vogue)
بیایید به مثال سیستم RAG با دادهٔ جدولی در مثال Kitty Vogue برگردیم. این یک عامل ساده است با سه اقدام:
تولید پاسخ
تولید کوئری SQL
اجرای کوئری SQL
فرض کنید پرسش کاربر این باشد: «فروش Fruity Fedora را برای سه ماه آینده پیشبینی کن.» عامل ممکن است توالی زیر از اقدامات را انجام دهد:
استدلال دربارهٔ اینکه چگونه وظیفه را تکمیل کند. شاید تشخیص دهد که برای پیشبینی فروش آینده، ابتدا باید اعداد فروش پنج سال گذشته را استخراج کند. توجه کنید: استدلال عامل به صورت خروجی میانی نشان داده میشود.
فراخوانی ابزار تولید کوئری SQL برای ایجاد کوئریای که فروش پنج سال گذشته را بازیابی کند.
فراخوانی ابزار اجرای SQL برای اجرای آن کوئری.
استدلال دربارهٔ نتایج ابزار و اینکه چگونه به پیشبینی فروش کمک میکنند. شاید تشخیص دهد که این دادهها برای پیشبینی قابل اعتماد کافی نیستند—مثلاً به دلیل مقادیر گمشده— و تصمیم بگیرد که همچنین به اطلاعات مربوط به کمپینهای بازاریابی گذشته نیاز دارد.
فراخوانی ابزار تولید کوئری SQL برای ساختن کوئریهایی مربوط به کمپینهای بازاریابی گذشته.
فراخوانی ابزار اجرای SQL.
استدلال میکند که اطلاعات جدید برای پیشبینی فروش آینده کافی است؛ سپس یک پیشبینی تولید میکند.
استدلال میکند که وظیفه با موفقیت انجام شده است.
در مقایسه با کاربردهای غیرعامل (non‑agent)، عاملها معمولاً به مدلهای قویتر نیاز دارند؛
به دو دلیل اصلی:
1. خطاهای ترکیبی (Compound mistakes)
یک عامل اغلب برای انجام یک وظیفه باید چندین مرحله انجام دهد. دقت نهایی با افزایش تعداد مراحل کاهش مییابد. مثال: اگر دقت مدل در هر مرحله 95٪ باشد: در ۱۰ مرحله، دقت کلی به حدود 60٪ میرسد. در ۱۰۰ مرحله، دقت کلی تقریباً 0.6٪ میشود.
2. ریسک بالاتر (Higher stakes)
با داشتن ابزارها، یک عامل قادر است وظایف اثرگذارتر انجام دهد. اما شکست در چنین وظایفی میتواند پیامدهای جدیتری داشته باشد.
یک وظیفهٔ پیچیده که نیاز به مراحل متعدد دارد، ممکن است زمانبر و هزینهبر باشد. با این حال، اگر عاملها خودمختار باشند، میتوانند مقدار زیادی از زمان انسان را صرفهجویی کنند، و این هزینهها را توجیهپذیر سازند.
با مشخص بودن محیط، موفقیت یک عامل در آن محیط بستگی دارد به:
موجودی ابزارهایی که در اختیار دارد
قدرت برنامهریز (AI planner) آن
بیایید ابتدا نگاهی بیندازیم به انواع مختلف ابزارهایی که یک مدل میتواند استفاده کند.
سیستمی برای اینکه «عامل» باشد، لزوماً به ابزارهای خارجی نیاز ندارد. اما بدون ابزارهای خارجی، تواناییهای عامل محدود خواهند بود. بهتنهایی، یک مدل معمولاً فقط میتواند یک نوع عمل انجام دهد: یک LLM میتواند متن تولید کند یا یک مدل تولید تصویر میتواند تصویر تولید کند. ابزارهای خارجی یک عامل را بهمراتب توانمندتر میکنند.
ابزارها به عامل کمک میکنند هم محیط را درک کند و هم بر آن عمل انجام دهد. اقداماتی که به عامل اجازه میدهند محیط را ببیند/بخواند، اقدامات فقطخواندنی (read-only) هستند. اقداماتی که به عامل اجازه میدهند محیط را تغییر دهد، اقدامات نوشتنی (write) هستند.
این بخش، یک مرور کلی از ابزارهای خارجی ارائه میدهد. اینکه این ابزارها چطور استفاده میشوند، در بخش «Planning» (صفحهٔ 281) توضیح داده خواهد شد.
مجموعهٔ ابزارهایی که یک عامل به آنها دسترسی دارد، موجودی ابزار (tool inventory) آن است. از آنجا که موجودی ابزار تعیین میکند عامل چه کارهایی میتواند انجام دهد، فکر کردن دربارهٔ اینکه چه ابزارهایی و چند ابزار به عامل بدهیم، بسیار مهم است. هرچه ابزارهای بیشتری داشته باشد، قابلیتهای بیشتری خواهد داشت. اما هرچه تعداد ابزارها بیشتر شود، درک و استفادهٔ درست از آنها دشوارتر میشود. بنابراین، برای یافتن مجموعهٔ مناسب ابزارها، نیاز به آزمایش و تجربه است؛ همانطور که در بخش «Tool selection» (صفحهٔ 295) توضیح داده شده است.
با توجه به محیط عامل، ابزارهای بسیار متنوعی ممکن است. در اینجا سه دستهٔ کلی از ابزارها وجود دارد که بد نیست به آنها فکر کنید:
تقویت دانش (knowledge augmentation)یا همان ساخت زمینه / context construction
گسترش قابلیتها (capability extension)
ابزارهایی که به عامل اجازه میدهند بر محیط خود عمل کند
1. تقویت دانش (Knowledge augmentation)
امیدوارم این کتاب تا اینجا شما را متقاعد کرده باشد که داشتن کانتکست (زمینه) مرتبط چقدر برای کیفیت پاسخ یک مدل مهم است.
یک دستهٔ مهم از ابزارها، آنهایی هستند که به تقویت دانش عامل شما کمک میکنند. برخی از این ابزارها قبلاً بحث شدهاند، مانند:
text retriever (بازیابیکنندهٔ متن)
image retriever (بازیابیکنندهٔ تصویر)
SQL executor (اجرای کوئری SQL)
ابزارهای بالقوهٔ دیگر میتوانند شامل اینها باشند:
ابزار جستوجو میان افراد داخل سازمان (internal people search)
یک Inventory API که وضعیت محصولات مختلف را برمیگرداند
بازیابی محتوای Slack
یک email reader (خوانندهٔ ایمیل)
و غیره.
بسیاری از این ابزارها، مدل را با فرآیندها و اطلاعات داخلی سازمان شما تقویت میکنند. اما ابزارها میتوانند دسترسی به اطلاعات عمومی، خصوصاً از اینترنت را نیز فراهم کنند.
مرور وب (Web browsing) یکی از نخستین و موردانتظارترین قابلیتهایی بود که قرار بود در چتباتهایی مثل ChatGPT قرار بگیرد. مرور وب باعث میشود مدل کهنه (stale) نشود. یک مدل وقتی stale میشود که دادههایی که روی آن آموزش دیده، قدیمی شوند. اگر دادهٔ آموزشی مدل تا هفتهٔ گذشته قطع شده باشد، نمیتواند به سؤالهایی که به اطلاعات این هفته نیاز دارند پاسخ بدهد، مگر اینکه این اطلاعات در کانتکست ورودی به او داده شده باشد. بدون مرور وب، یک مدل نمیتواند دربارهٔ مواردی مثل وضعیت هوا، اخبار، رویدادهای پیشِ رو، قیمت سهام، وضعیت پروازها، و … به شما پاسخ بهروز بدهد.
من از اصطلاح web browsing بهعنوان یک عنوان کلی استفاده میکنم برای تمام ابزارهایی که به اینترنت دسترسی دارند، از جمله مرورگرهای وب و APIهای خاص مانند: Search APIs، News APIs، GitHub APIs و APIهای شبکههای اجتماعی مثل X، لینکدین، و ردیت.
در حالی که مرور وب به عامل شما اجازه میدهد به اطلاعات بهروز ارجاع دهد، پاسخهای بهتری تولید کند و توهم (hallucinations) را کاهش دهد، در عین حال میتواند عامل شما را در معرض باتلاقها و آلودگیهای اینترنت هم قرار دهد. بنابراین، APIهای اینترنتی که در اختیار عامل میگذارید را با دقت انتخاب کنید.
2. گسترش قابلیتها (Capability extension)
دومین دستهٔ ابزارهایی که باید به آنها فکر کنید، ابزارهایی هستند که محدودیتهای ذاتی مدلهای هوش مصنوعی را جبران میکنند. اینها راههای سادهای برای دادن یک افزایش عملکرد (performance boost) به مدل شما هستند. برای مثال، مدلهای AI بهطور مشهور در ریاضی ضعیفاند. اگر از یک مدل بپرسید: 199,999 تقسیم بر 292 چند میشود؟ احتمالاً مدل جواب اشتباه میدهد. در حالی که اگر مدل به یک ماشینحساب دسترسی داشته باشد، این محاسبه کاملاً ساده است. بهجای اینکه سعی کنیم خود مدل را در حساب و کتاب قوی کنیم،
خیلی کارآمدتر (از نظر منابع) است که فقط به آن دسترسی یک ابزار بدهیم. نمونههایی از ابزارهای ساده اما بسیار مؤثر: تقویم (Calendar)، تبدیل منطقهٔ زمانی (Timezone converter)، مبدّل واحدها (Unit converter) مثلاً تبدیل lbs به kg، مترجم (Translator) برای ترجمه به/از زبانهایی که مدل در آنها قوی نیست. این ابزارها بدون تغییر خود مدل، قدرت عملیاتی آن را زیاد میکنند.
ابزارهای پیچیدهتر ولی بسیار قدرتمند، code interpreterها هستند. بهجای اینکه بخواهید مدل را طوری آموزش دهید که خودش کد را بفهمد و اجرا کند، میتوانید به آن دسترسی به یک مفسر کد بدهید تا یک قطعه کد را اجرا کند، نتیجهٔ اجرا را برگرداند یا خطاها و شکستهای کد را تحلیل کند. با این قابلیت، عاملهای شما میتوانند نقشهای زیر را ایفا کنند: دستیار کدنویسی (coding assistant)، تحلیلگر داده (data analyst) و حتی دستیار پژوهشی (research assistant) که میتواند کد بنویسد، آزمایش اجرا کند و نتایج را گزارش دهد.
اما اجرای خودکار کد، ریسک حملات تزریق کد (code injection) را به همراه دارد. همانطور که در بخش «Defensive Prompt Engineering» (صفحه 235) توضیح داده شده است. برای اینکه خودتان و کاربرانتان را ایمن نگه دارید، وجود اقدامات امنیتی مناسب کاملاً ضروری است.
ابزارهای خارجی میتوانند یک مدلِ فقط-متنی یا فقط-تصویری را چندحالته (Multimodal) کنند. برای مثال، مدلی که فقط میتواند متن تولید کند میتواند از یک مدل متن-به-تصویر (text-to-image) بهعنوان ابزار استفاده کند و اینگونه توانایی تولید هم متن و هم تصویر را به دست بیاورد. وقتی یک درخواست متنی داده میشود، برنامهریز هوش مصنوعی (AI planner) عامل تصمیم میگیرد که فقط تولید متن را فراخوانی کند، فقط تولید تصویر را فراخوانی کند، یا هر دو را. این همان روشی است که ChatGPT میتواند هم متن و هم تصویر تولید کند:
این سیستم از DALL·E بهعنوان مولد تصویر استفاده میکند. عاملها همچنین میتوانند:
از یک مفسر کد (code interpreter) برای تولید نمودار و گراف استفاده کنند،
از یک LaTeX compiler برای رندر کردن فرمولهای ریاضی استفاده کنند،
یا از یک مرورگر برای رندر کردن صفحات وب از روی HTML استفاده کنند.
بهطور مشابه، مدلی که فقط میتواند ورودی متنی را پردازش کند، میتواند:
از یک ابزار image captioning برای پردازش تصویر استفاده کند (تبدیل تصویر به توضیح متنی)،
از یک ابزار transcription برای پردازش صوت استفاده کند (تبدیل صوت به متن)،
و از یک ابزار OCR (تشخیص نوری حروف) برای خواندن محتوای PDF استفاده کند.
استفاده از ابزارها میتواند عملکرد یک مدل را بهطور قابلتوجهی نسبت به فقط «prompting» و حتی نسبت به finetuning بهبود دهد.
Chameleon (لو و همکاران، ۲۰۲۳) نشان میدهد که یک عامل مبتنی بر GPT-4 که با مجموعهای از ۱۳ ابزار تقویت شده است، میتواند در چندین بنچمارک، بهتر از خودِ GPT-4 تنها عمل کند. نمونههایی از ابزارهایی که این عامل استفاده میکرد عبارتاند از بازیابی دانش (knowledge retrieval)، تولید پرسوجو (query generator)، توصیفگر تصویر (image captioner)، تشخیصدهندهٔ متن (text detector)و جستوجوی Bing
روی ScienceQA (بنچمارک پرسشوپاسخ علمی)، Chameleon توانست بهترین نتیجهی few-shot منتشر شده را ۱۱٫۳۷٪ بهبود دهد. روی TabMWP (Tabular Math Word Problems – مسئلههای متنی ریاضی جدولی) Chameleon دقت را ۱۷٪ افزایش داد.
3. اقدامات نوشتنی (Write actions)
تا اینجا دربارهی اقدامات فقطخواندنی (read-only) صحبت کردیم؛ اقداماتی که به مدل اجازه میدهند از منابع دادهی خود اطلاعات بخواند. اما ابزارها میتوانند اقدامات نوشتنی (write actions) نیز انجام دهند و در نتیجه تغییراتی در منابع داده ایجاد کنند.
یک SQL executor میتواند یک جدول داده را بازیابی کند (خواندن)، اما همچنین میتواند آن جدول را تغییر دهد یا حذف کند (نوشتن).
یک Email API میتواند یک ایمیل را بخواند، اما میتواند به آن پاسخ هم بدهد.
یک Banking API میتواند موجودی فعلی حساب شما را بخواند، اما میتواند یک انتقال بانکی را هم آغاز کند.
اقدامات نوشتنی باعث میشوند یک سیستم بتواند کارهای بیشتری انجام دهد. مثلاً میتوانند به شما اجازه دهند کل جریان کارِ ارتباط با مشتری را خودکار کنید تحقیق دربارهی مشتریان بالقوه، پیدا کردن اطلاعات تماس آنها، نوشتن پیشنویس ایمیلها، ارسال ایمیلهای اولیه، خواندن پاسخها، پیگیری (Follow-up)، استخراج سفارشها، بهروزرسانی پایگاه دادهی شما با سفارشهای جدید و غیره.
اما اینکه به یک AI امکان بدهیم بهطور خودکار زندگی ما را دستکاری کند، موضوع ترسناکی است. همانطور که شما نباید به یک کارآموز (intern) اختیار بدهید که دیتابیس محیط تولید (production) شما را حذف کند، به همان شکل نباید به یک AI غیرقابل اعتماد اجازه بدهید که انتقال بانکی انجام دهد. اعتماد به قابلیتهای سیستم و اقدامات امنیتی آن حیاتی است. باید مطمئن شوید که سیستم در برابر افراد مخرب (bad actors) که تلاش میکنند آن را وادار به انجام کارهای خطرناک کنند، محافظت شده است.
وقتی با یک گروه دربارهی عاملهای خودمختار صحبت میکنم، اغلب کسی ماشینهای خودران را مطرح میکند: «اگر کسی به ماشین نفوذ کند و از آن برای آدمربایی استفاده کند چه؟» مثال خودروی خودران بهخاطر فیزیکی بودن آن، اثر احساسی شدیدی دارد؛ اما یک سیستم AI بدون حضور فیزیکی هم میتواند آسیب بزند: میتواند بازار سهام را دستکاری کند، میتواند حق نشر (کپیرایت) را بدزدد، میتواند حریم خصوصی را نقض کند، میتواند سوگیریها را تقویت کند و میتواند اطلاعات نادرست و تبلیغات را گسترش دهد. و موارد دیگر، همانطور که در بخش «Defensive Prompt Engineering» (صفحه ۲۳۵) توضیح داده شده است.
این نگرانیها همگی کاملاً جدی و معتبرند و هر سازمانی که میخواهد از AI استفاده کند، باید ایمنی و امنیت را جدی بگیرد. اما این بدین معنا نیست که هرگز نباید به سیستمهای AI اجازه داد در دنیای واقعی عمل کنند. اگر توانستهایم مردم را قانع کنیم که به یک ماشین اعتماد کنند تا آنها را به فضا ببرد، امیدوارم روزی اقدامات امنیتی به حدی برسند که بتوانیم به سیستمهای AI خودمختار نیز اعتماد کنیم. از طرف دیگر، انسانها هم میتوانند خطا کنند. شخصاً من به یک خودروی خودران بیش از یک فرد غریبهی معمولی برای رانندگی اعتماد دارم.
همانطور که ابزارهای درست میتوانند انسانها را بسیار پربازدهتر کنند — آیا میتوانید تصور کنید کسبوکار بدون Excel یا ساخت آسمانخراش بدون جرثقیل؟ ابزارها به مدلها نیز امکان میدهند کارهای بسیار بیشتری انجام دهند. بسیاری از ارائهدهندگان مدل (model providers) در حال حاضر از استفاده از ابزار توسط مدلها پشتیبانی میکنند؛ ویژگیای که اغلب function calling نامیده میشود. از اینجا به بعد، میتوان انتظار داشت که function calling همراه با مجموعهی گستردهای از ابزارها در اکثر مدلها چیزی رایج و استاندارد باشد.
در قلب هر عامل مبتنی بر مدل پایه (foundation model agent)، مدلی قرار دارد که مسئول حل یک تسک (وظیفه) است. یک تسک با هدف (goal) و قیدها (constraints) تعریف میشود. برای مثال، یک تسک میتواند این باشد: برنامهریزی یک سفر دو هفتهای از سانفرانسیسکو به هند با بودجهٔ ۵٬۰۰۰ دلار. هدف این است که سفر دو هفتهای انجام شود. قید این است که بودجه، ۵٬۰۰۰ دلار است.
تسکهای پیچیده به برنامهریزی نیاز دارند. خروجی فرایند برنامهریزی یک برنامه (plan) است؛ برنامه یعنی یک نقشهٔ راه (roadmap) که مراحل لازم برای رسیدن به هدفِ تسک را مشخص میکند. برنامهریزی مؤثر معمولاً نیاز دارد که مدل تسک را بفهمد، گزینههای مختلف برای رسیدن به این تسک را در نظر بگیرد و امیدبخشترین گزینه را انتخاب کند.
اگر تا حالا در یک جلسهٔ برنامهریزی شرکت کرده باشید، میدانید که برنامهریزی کار سختی است. بهعنوان یک مسألهٔ محاسباتی مهم، planning بهخوبی در علوم کامپیوتر مطالعه شده است و برای پوشش کامل آن، به چندین جلد کتاب نیاز است. در اینجا، من فقط میتوانم سطح این موضوع را لمس کنم.
نمای کلی برنامهریزی (Planning Overview)
وقتی یک تسک به عامل داده میشود، راههای زیادی برای شکستن (decompose) آن به مراحل کوچکتر وجود دارد. اما همهٔ این راهها منجر به نتیجهٔ موفق نمیشوند. و حتی میان راهحلهای درست، برخی کارآمدتر از بقیهاند. به این پرسش توجه کنید: «چند شرکت بدون درآمد، بیش از ۱ میلیارد دلار سرمایه جذب کردهاند؟» روشهای زیادی برای حل این مسئله وجود دارد، اما برای مثال دو گزینه را مقایسه کنید:
یافتن تمام شرکتهای بدون درآمد، سپس فیلتر کردن آنها بر اساس میزان سرمایه جذبشده.
یافتن تمام شرکتهایی که دستکم ۱ میلیارد دلار جذب کردهاند، سپس فیلتر کردن آنها بر اساس درآمد.
گزینهی دوم بسیار کارآمدتر است. تعداد شرکتهای بدون درآمد بسیار بیشتر از شرکتهایی است که ۱ میلیارد دلار جذب کردهاند. از بین این دو گزینه، یک عامل هوشمند باید گزینهی دوم را انتخاب کند.
برنامهریزی و اجرا در یک پرامپت (Coupled Planning & Execution)
میتوان برنامهریزی را مستقیماً در همان پرامپت اجرا نیز ترکیب کرد. مثلاً: به مدل یک تسک بدهید، از آن بخواهید “گامبهگام فکر کند” (Chain-of-Thought) و سپس همان گامها را اجرا کند. اما خطر چیست؟ ممکن است مدل یک برنامهی ۱۰۰۰ مرحلهای بنویسد که اصلاً به هدف نمیرسد. سپس عامل، ساعتها این مراحل را اجرا میکند، پول API و زمان را میسوزاند، و شما تازه آخر کار متوجه میشوید که هیچ پیشرفتی نداشته.
راهحل: جداسازی برنامهریزی از اجرا (Decoupling)
برای جلوگیری از این اتفاق، برنامهریزی باید از اجرا جدا شود: ابتدا عامل برنامه تولید میکند. برنامه ارزیابی و تأیید (validate) میشود. تنها برنامههای معتبر اجرا میشوند.
چگونه یک برنامه را اعتبارسنجی کنیم؟ (Plan Validation)
برای ارزیابی برنامه دو رویکرد وجود دارد:
۱) اعتبارسنجی با هیوریستیکها (Heuristics) مثلاً: حذف برنامههایی با اقدامات نامعتبر
اگر برنامه گفته: «Google Search انجام بده»، اما عامل ابزار Google ندارد، برنامه نامعتبر است.
حذف برنامههایی با بیش از X مرحله: مخصوصاً برای تسکهای ساده، برنامههای بسیار طولانی احتمالاً بیکیفیت هستند.
۲) اعتبارسنجی با قاضی AI (AI Judge)
میتوان از یک مدل دیگر خواست: «آیا این برنامه منطقی است؟»، «چه مشکلاتی دارد؟» یا «چطور میتوان آن را بهبود داد؟». این مرحله به عامل کمک میکند قبل از اجرا، برنامه را بهینه کند.
اگر برنامه بد ارزیابی شود: از planner دوباره برنامهی جدید خواسته میشود. اگر برنامه خوب باشد: وارد مرحلهی اجرا میشود. اجرای این برنامه ممکن است شامل function calling باشد. خروجی اجرای هر بخش دوباره باید ارزیابی شود. نکتهی مهم: برنامه لازم نیست یک برنامهی کامل “پایانبهپایان” باشد. میتواند یک برنامهی کوچک برای یک زیرتسک باشد. سپس عامل دوباره همان چرخهی برنامهریزی --> اعتبارسنجی --> اجرا را تکرار میکند. این چرخه همان چیزی است که در شکل 6‑9 کتاب نشان داده شده است.

حالا سیستم شما سه جزء (کامپوننت) دارد:
مولّد برنامه (Planner) → تولید برنامهها
اعتبارسنجی برنامه (Plan Validator / Evaluator) → بررسی و تأیید یا رد برنامهها
مجری برنامه (Executor) → اجرای برنامههای تأییدشده
اگر هر کدام از این اجزا را یک «عامل» در نظر بگیرید، در واقع شما یک سیستم چندعاملی (Multi-Agent System) دارید.
برای سریعتر کردن فرآیند، بهجای اینکه برنامهها را یکییکی (sequential) تولید کنید،
میتوانید چند برنامه را بهصورت موازی (parallel) بسازید و بعد از ارزیاب (evaluator) بخواهید امیدبخشترین آنها را انتخاب کند.
این کار یک تریدآف هزینه/تأخیر (latency/cost trade-off) است:
موازیسازی، تأخیر کمتر، سرعت بیشتر
اما در عوض، هزینهی بیشتر چون چند برنامهی مختلف را همزمان تولید میکنید.
برنامهریزی نیازمند این است که عامل نیت پشت تسک را بفهمد: «کاربر با این کوئری واقعاً چه میخواهد انجام دهد؟» برای کمک به عامل در این کار، معمولاً از یک دستهبند نیت (Intent Classifier) استفاده میشود. همانطور که در بخش «Break Complex Tasks into Simpler Subtasks» (صفحهی ۲۲۴) گفته شد: Intent classification میتواند با یک پرامپت دیگر انجام شود، یا با یک مدل طبقهبندی (classification model) که بهطور خاص برای این کار آموزش دیده است. این مکانیزم تشخیص نیت را هم میتوان بهعنوان یک عامل دیگر در سیستم چندعاملی شما در نظر گرفت.
وقتی نیت را میدانید، عامل میتواند ابزار مناسب را انتخاب کند. مثال: سیستم پشتیبانی مشتری (Customer Support Agent). اگر کوئری دربارهی صورتحساب / Billing باشد: عامل باید به ابزاری دسترسی پیدا کند که پرداختهای اخیر کاربر را بازیابی کند (مثلاً یک API مالی یا دیتابیس billing). اگر کوئری دربارهی ریست کردن رمز عبور باشد، عامل باید به ابزار بازیابی مستندات (Documentation Retrieval / RAG) وصل شود، تا راهنمای «چگونه رمز را ریست کنیم» را پیدا کند.
بعضی پرسوجوها اصلاً در حوزهی توانایی عامل نیستند. بنابراین دستهبندی نیت (Intent Classifier) باید بتواند درخواستها را بهصورت IRRELEVANT برچسب بزند تا: عامل بهجای تلاش برای تولید «راهحل غیرممکن»، بهطور مودبانه رد کند یا کاربر را راهنمایی کند، و از هدر رفتن FLOPs و هزینهی محاسباتی برای خروجیهای بیفایده جلوگیری شود.
تا اینجا فرض کردهایم که عامل (agent) هر سه مرحله را خودش انجام میدهد:
تولید برنامه (Generating plans)
اعتبارسنجی برنامه (Validating plans)
اجرای برنامه (Executing plans)
اما در دنیای واقعی، انسانها میتوانند در هرکدام از این مراحل وارد شوند تا به فرایند کمک کنند و ریسکها را کاهش دهند.
یک متخصص انسانی میتواند:
خودش یک برنامه بدهد، برنامهای که ایجنت ساخته را بررسی و تأیید کند، یا بعضی از بخشهای برنامه را خودش اجرا کند. مثلاً: اگر یک کار خیلی پیچیده باشد و ایجنت نتواند کل برنامه را بسازد، یک انسان میتواند یک طرح کلی (high‑level plan) بدهد و ایجنت بعداً جزئیاتش را کامل کند. اگر برنامه شامل عملیات پرریسک باشد (مثل): آپدیت کردن دیتابیس و merge کردن تغییرات کد. سیستم میتواند: قبل از اجرا از انسان تأیید بگیرد یا اصلاً اجرای آن بخش را به انسان بسپارد. در نهایت برای اینکه این کار ممکن شود، باید برای هر اکشن مشخص کنید سطح اتوماسیون چقدر است.
به طور خلاصه، حل یک تسک معمولاً شامل فرایندهای زیر است. توجه کنید که Reflection برای یک ایجنت اجباری نیست، اما بهطور قابلتوجهی عملکرد ایجنت را بهبود میدهد.
تولید برنامه (Plan generation):
یک برنامه برای انجام این وظیفه ایجاد کنید. برنامه در واقع دنبالهای از اقدامات قابلمدیریت است؛ به همین دلیل این فرایند را شکستن وظیفه به زیرکارها (task decomposition) نیز مینامند.
بازاندیشی و اصلاح خطا (Reflection and error correction):
برنامهی تولیدشده را ارزیابی کنید. اگر برنامه مناسب نبود، یک برنامهی جدید تولید کنید.
اجرا (Execution):
اقداماتی را که در برنامهی تولیدشده مشخص شدهاند انجام دهید. این مرحله اغلب شامل فراخوانی توابع یا ابزارهای مشخص است.
بازاندیشی و اصلاح خطا:
پس از دریافت نتایج اقدامات، این نتایج را ارزیابی کنید و مشخص کنید که آیا هدف برآورده شده است یا نه. خطاها را شناسایی و اصلاح کنید. اگر هدف هنوز محقق نشده باشد، یک برنامهی جدید تولید کنید.
در این کتاب تاکنون با برخی تکنیکها برای تولید برنامه و بازاندیشی (reflection) آشنا شدهاید. وقتی از یک مدل میخواهید «مرحلهبهمرحله فکر کند» (think step by step)، در واقع از آن میخواهید که یک وظیفه را به بخشهای کوچکتر تجزیه کند. و وقتی از مدل میخواهید «بررسی کند که آیا پاسخش درست است یا نه»، در واقع از آن میخواهید که بازاندیشی (reflection) انجام دهد.
مدلهای بنیادی بهعنوان برنامهریز (Foundation models as planners)
یک پرسش باز این است که مدلهای بنیادی تا چه اندازه میتوانند برنامهریزی کنند. بسیاری از پژوهشگران عقیده دارند که مدلهای بنیادی — دستکم آنهایی که بر پایهی مدلهای زبانی خودرگرسیو ساخته شدهاند — قادر به برنامهریزی واقعی نیستند.
یان لکون، مدیر ارشد علمی هوش مصنوعی متا، بهصورت صریح گفته است که LLMهای خودرگرسیو نمیتوانند برنامهریزی کنند (۲۰۲۳).
در مقالهی «آیا LLMها واقعاً میتوانند استدلال و برنامهریزی کنند؟» کمبامپاتی (۲۰۲۳) استدلال میکند که LLMها در استخراج دانش عالیاند، اما در برنامهریزی خوب عمل نمیکنند. او پیشنهاد میدهد که مقالاتی که ادعا میکنند LLMها توانایی برنامهریزی دارند، درواقع دانش عمومی مربوط به برنامهریزی که مدل از دادهها آموخته را با برنامههای قابل اجرا اشتباه گرفتهاند.
«طرحهایی که از LLMها بیرون میآیند ممکن است برای یک کاربر عادی منطقی به نظر برسند، اما در زمان اجرا منجر به تعاملات اشتباه و خطا میشوند.»
با این حال، در حالی که شواهد تجربی زیادی وجود دارد که LLMها برنامهریزهای ضعیفی هستند، هنوز مشخص نیست که آیا دلیلش این است که ما بلد نیستیم از LLMها به شکل درست استفاده کنیم یا اینکه LLMها ذاتاً توانایی برنامهریزی ندارند.
در هستهی خود، برنامهریزی یک مسئلهی جستوجو است. شما میان مسیرهای مختلف برای رسیدن به هدف جستوجو میکنید، نتیجه (پاداش) هر مسیر را پیشبینی میکنید و مسیری را انتخاب میکنید که نتیجهی بهتری دارد. اغلب ممکن است تشخیص دهید هیچ مسیری وجود ندارد که بتواند شما را به هدف برساند.
جستوجو معمولاً نیازمند بازگشت به عقب (backtracking) است. برای مثال، تصور کنید در مرحلهای هستید که دو اقدام ممکن دارید: A و B. بعد از انجام اقدام A، به حالتی وارد میشوید که مطلوب نیست؛ بنابراین باید به حالت قبلی برگردید و اقدام B را امتحان کنید.
برخی افراد استدلال میکنند که یک مدل خودرگرسیو فقط میتواند اقدامات روبهجلو تولید کند و نمیتواند به عقب برگردد تا اقدامات جایگزین تولید کند. بر این اساس نتیجه میگیرند که مدلهای خودرگرسیو نمیتوانند برنامهریزی کنند. اما این الزاماً درست نیست. پس از دنبال کردن مسیری با اقدام A، اگر مدل تشخیص دهد که این مسیر منطقی نیست، میتواند مسیر را بازنگری کرده و از اقدام B استفاده کند؛ این در عمل همان بازگشت به عقب است. مدل همچنین همیشه میتواند از ابتدا شروع کند و مسیر جدیدی را انتخاب کند.
امکان دیگر این است که LLMها برنامهریزهای ضعیفی هستند چون ابزارهای مناسب برای برنامهریزی در اختیارشان قرار داده نشده است. برای برنامهریزی، لازم است نهتنها بدانید چه اقدامهایی موجود است، بلکه نتیجهی احتمالی هر اقدام را نیز بدانید. بهعنوان مثال ساده: فرض کنید میخواهید از کوه بالا بروید. اقدامات ممکن عبارتاند از: راست بپیچید، چپ بپیچید، دور بزنید، یا مستقیم بروید. اما اگر پیچیدن به راست باعث سقوط از پرتگاه شود، نباید این عمل را در نظر بگیرید. از نظر فنی، یک اقدام شما را از یک state به state دیگری میبرد و برای تصمیمگیری لازم است بدانید آن state خروجی چیست.
این یعنی اینکه صرفاً درخواست از مدل برای تولید یک دنبالهی اقدامات، مثل آنچه در روش محبوب Chain‑of‑Thought انجام میشود، کافی نیست. مقالهی «Reasoning with Language Model is Planning with World Model» (Hao و همکاران، ۲۰۲۳) استدلال میکند که یک LLM به دلیل داشتن اطلاعات عظیم دربارهی جهان، توانایی پیشبینی نتیجهی هر اقدام را دارد و میتواند این پیشبینی را در تولید یک برنامهی منسجم استفاده کند.
حتی اگر هوش مصنوعی نتواند خودش برنامهریزی کند، همچنان میتواند بخشی از یک سیستم برنامهریز باشد. ممکن است بتوان یک LLM را با ابزار جستوجو و یک سیستم ردگیری وضعیت (state tracking) تقویت کرد تا بتواند برنامهریزی انجام دهد.
Foundation Model (FM) Versus Reinforcement Learning (RL) Planners
عامل (Agent) یکی از مفاهیم محوری در یادگیری تقویتی (RL) است که در ویکیپدیا اینگونه تعریف شده است:
«حوزهای که به این میپردازد که یک عامل هوشمند چگونه باید در یک محیط پویا اقداماتی انجام دهد تا پاداش تجمعی را بیشینه کند.»
عاملهای RL و عاملهای مبتنی بر مدلهای بنیادی (FM agents) از بسیاری جهات شبیه هم هستند. هر دو با محیط و مجموعهای از اقدامات ممکن تعریف میشوند. تفاوت اصلی آنها در نحوهی کار برنامهریز (planner) است.
در یک عامل RL، برنامهریز با استفاده از یک الگوریتم یادگیری تقویتی آموزش داده میشود.
آموزش این برنامهریز RL معمولاً به زمان و منابع محاسباتی زیادی نیاز دارد.
در یک عامل مبتنی بر مدل بنیادی (FM agent)، خودِ مدل نقش برنامهریز را ایفا میکند.
این مدل را میتوان با پرامپتدهی (prompting) یا ریزتنظیم (finetuning) برای بهبود توانایی برنامهریزی تقویت کرد، و این کار معمولاً به زمان و منابع کمتری نیاز دارد.
با این حال، هیچ مانعی وجود ندارد که یک عامل FM از الگوریتمهای RL برای بهبود عملکرد خود استفاده نکند.
نویسنده حدس میزند که در بلندمدت، عاملهای FM و عاملهای RL در هم ادغام خواهند شد.
تولید برنامه (Plan generation)
سادهترین روش برای تبدیل یک مدل به یک سازندهی برنامه (plan generator)، استفاده از مهندسی پرامپت (prompt engineering) است.
فرض کنید میخواهید یک ایجنت بسازید که به مشتریها کمک کند دربارهی محصولات Kitty Vogue اطلاعات کسب کنند.
شما به این ایجنت دسترسی به سه ابزار خارجی میدهید:
بازیابی محصولات بر اساس قیمت
بازیابی محصولات برتر
بازیابی اطلاعات محصول
در اینجا یک نمونهی ساده از یک پرامپت برای تولید برنامه آورده شده است. این پرامپت فقط جهت مثال است؛ پرامپتهایی که در محیط واقعیِ تولید (production) استفاده میشوند معمولاً پیچیدهتر هستند:
SYSTEM PROMPT
Propose a plan to solve the task. You have access to 5 actions:
get_today_date()
fetch_top_products(start_date, end_date, num_products)
fetch_product_info(product_name)
generate_query(task_history, tool_output)
generate_response(query)
The plan must be a sequence of valid actions.
Examples
Task: "Tell me about Fruity Fedora"
Plan: [fetch_product_info, generate_query, generate_response]
Task: "What was the best selling product last week?"
Plan: [fetch_top_products, generate_query, generate_response]
Task: {USER INPUT}
Plan:
دو نکته در این مثال وجود دارد:
• قالب برنامه (plan format) که اینجا استفاده شده — یعنی فهرستی از توابعی که پارامترهای آنها توسط ایجنت استنتاج میشود — فقط یکی از روشهای ممکن برای ساختاربندی جریان کنترل ایجنت است.
• تابع generate_query، تاریخچهی فعلی وظیفه (task history) و آخرین خروجی ابزارها را دریافت میکند و بر اساس آن یک query جدید برای response generator میسازد. در هر مرحله، خروجی ابزار به تاریخچهی وظیفه اضافه میشود.
با توجه به ورودی کاربر “What’s the price of the best-selling product last week”، یک پلن تولیدشده ممکن است اینگونه باشد:
1. get_time()
2. fetch_top_products()
3. fetch_product_info()
4. generate_query()
5. generate_response()
ممکن است بپرسید: «پس پارامترهای لازم برای هر تابع چه میشوند؟» پارامترهای دقیق از قبل قابل پیشبینی نیستند، زیرا معمولاً از خروجی ابزارهای قبلی استخراج میشوند. برای مثال، اگر گام اول get_time() مقدار “2030-09-13 " را برگرداند، ایجنت میتواند استدلال کند که پارامترهای لازم برای گام بعدی باید چیزی شبیه به موارد زیر باشد:
retrieve_top_products(
start_date=“2030-09-07”,
end_date=“2030-09-13”,
num_products=1
)
در بسیاری از موارد، اطلاعات کافی برای تعیین دقیق پارامترهای یک تابع وجود ندارد. برای مثال، اگر کاربر بپرسد:
“What’s the average price of best-selling products?” پاسخ این پرسشها مشخص نیست:
• کاربر میخواهد چند تا از پرفروشترین محصولات بررسی شود؟
• منظور کاربر پرفروشترین محصولات هفتهی گذشته است؟ ماه گذشته؟ یا کل تاریخ؟
به همین دلیل، مدلها اغلب مجبور به حدس زدن میشوند—و ممکن است اشتباه حدس بزنند.
از آنجا که هم دنبالهی اقدامات (action sequence) و هم پارامترهای مربوط به آنها توسط مدل تولید میشوند، این موارد میتوانند هالوسینه شوند. این هالوسینیشن ممکن است موجب شود که مدل یک تابع نامعتبر فراخوانی کند، یا یک تابع معتبر را با پارامترهای نادرست فراخوانی کند. تکنیکهایی که عملکرد کلی مدل را بهبود میدهند، میتوانند توانایی برنامهریزی (planning) مدل را نیز ارتقا دهند.
چند رویکرد برای بهتر کردن توانایی برنامهریزی یک ایجنت وجود دارد:
• نوشتن یک سیستم پرامپت بهتر همراه با مثالهای بیشتر.
• ارائهی توضیحات بهتر دربارهی ابزارها و پارامترهایشان تا مدل آنها را بهتر درک کند.
• بازنویسی توابع برای سادهتر کردن آنها، مثل اینکه یک تابع پیچیده را به دو تابع سادهتر تقسیم کنیم.
• استفاده از یک مدل قویتر. بهطور کلی، مدلهای قویتر در برنامهریزی بهتر عمل میکنند.
• فاینتیون کردن مدل مخصوص تولید برنامه (plan generation).
بسیاری از ارائهدهندگان مدل، ابزار استفاده (tool use) را برای مدلهای خود ارائه میکنند که عملاً مدل را تبدیل به ایجنت میکند. یک ابزار همان تابع (function) است. بنابراین فراخوانی یک ابزار معمولاً function calling نامیده میشود. اگرچه API مدلها متفاوتاند، اما معمولاً روند function calling اینگونه است:
1. ساختن فهرست ابزارها (tool inventory)
تمام ابزارهایی که ممکن است بخواهید مدل استفاده کند را تعریف میکنید. هر ابزار با موارد زیر توصیف میشود. نقطهی ورود اجرای آن (مثلاً نام تابع)، پارامترهایش و مستنداتش (توضیح اینکه چه کاری انجام میدهد و به چه پارامترهایی نیاز دارد).
2. مشخص کردن اینکه ایجنت به چه ابزارهایی دسترسی دارد
از آنجا که درخواستهای مختلف به ابزارهای مختلف نیاز دارند، بسیاری از APIها اجازه میدهند که فهرستی از ابزارهای مجاز برای یک پرسش خاص تعیین کنید. برخی APIها کنترل بیشتری نیز ارائه میدهند و سه حالت تنظیم میکنند:
required
مدل باید حداقل از یک ابزار استفاده کند.
none
مدل نباید از هیچ ابزاری استفاده کند.
auto
مدل خودش تصمیم میگیرد که از ابزار استفاده کند یا نکند.
Function calling در شکل 6-10 نشان داده شده است. این توضیحات به صورت کد شبه (pseudocode) نوشته شده است تا نمایندهی چندین API باشد. برای استفاده از یک API خاص، لطفاً به مستندات آن API مراجعه کنید.

با داشتن یک پرسوجو (query)، ایجنیتی که مطابق شکل 6‑10 تعریف شده باشد بهصورت خودکار تشخیص میدهد از چه ابزارهایی استفاده کند و پارامترهای آنها چه باشند. برخی APIهای مربوط به function calling تضمین میکنند که فقط توابع معتبر تولید شوند، اما نمیتوانند تضمین کنند که مقادیر پارامترها کاملاً درست باشند.
برای مثال، اگر کاربر بپرسد: “How many kilograms are 40 pounds?” ایجنت ممکن است تشخیص دهد که باید از ابزار lbs_to_kg_tool با پارامتر مقدار 40 استفاده کند. پاسخ مدل ممکن است چیزی شبیه به این باشد:
response = ModelResponse(
finish_reason='tool_calls',
message=chat.Message(
content=None,
role='assistant',
tool_calls=[
ToolCall(
function=Function(
arguments='{"lbs":40}',
name='lbs_to_kg'),
type='function')
])
)
از این پاسخ، شما میتوانید تابع lbs_to_kg(lbs=40) را فراخوانی کنید و از خروجی آن برای تولید پاسخ برای کاربر استفاده کنید.
هنگام کار با ایجنتها (agents) همیشه از سیستم بخواهید گزارش دهد که برای هر فراخوانی تابع چه مقادیر پارامتری استفاده کرده است. سپس این مقادیر را بررسی کنید تا مطمئن شوید که درست هستند.
یک پلن (plan) نقشهی راهی است که مراحل لازم برای انجام یک کار را مشخص میکند. این نقشهی راه میتواند سطوح مختلفی از جزئیات (granularity) داشته باشد. برای مثال:
برنامهریزی فصلبهفصل (quarter-by-quarter) برای یک سال : سطح بالاتر (کلیتر)
برنامهریزی ماهبهماه (month-by-month) : جزئیتر
برنامهریزی هفتهبههفته (week-by-week) : حتی جزئیتر
بین جزئیات برنامه و سهولت اجرا یک نوع مبادله وجود دارد:
برنامهی بسیار جزئی: تولید آن سختتر است اما اجرای آن آسانتر است.
برنامهی سطح بالا (کلی): تولید آن آسانتر است اما اجرای آن سختتر است.
برای حل این مشکل میتوان از برنامهریزی سلسلهمراتبی استفاده کرد: ابتدا یک برنامهی سطح بالا تولید میکنیم (مثلاً برنامهی فصلبهفصل برای یک سال) سپس برای هر بخش از آن برنامه، یک برنامهی جزئیتر تولید میکنیم. (مثلاً برای هر فصل، برنامهی ماهبهماه) ممکن است برای این مراحل از: همان planner یا planner متفاوت استفاده شود.
تا اینجا تمام مثالها از نام دقیق توابع در پلن استفاده کردهاند که بسیار ریز و دقیق است. اما این روش یک مشکل دارد: موجودی ابزارهای یک ایجنت (tool inventory) ممکن است در طول زمان تغییر کند. مثال: get_time() ممکن است به get_current_time() تغییر نام داده شود. در این صورت شما باید: prompt را بهروزرسانی کنید و تمام مثالها را هم اصلاح کنید.
استفاده از نام دقیق توابع باعث میشود: استفادهی مجدد از planner در سیستمهای مختلف سختتر شود. چون هر سیستم ممکن است: APIهای متفاوت، نام توابع متفاوت و ابزارهای متفاوت داشته باشد.
اگر قبلاً مدلی را فاینتیون (finetune) کرده باشید تا بر اساس مجموعهای از توابع خاص، پلن تولید کند، در صورتی که موجودی ابزارها (tool inventory) تغییر کند، لازم است مدل را دوباره روی ابزارهای جدید فاینتیون کنید.
برای جلوگیری از این مشکل، میتوان پلنها را با استفاده از عملیات عمومی (generic operations) تولید کرد؛ عملیاتی که سطح بالاتری از انتزاع نسبت به نام توابع خاص دامنه (domain‑specific function names) دارند. برای مثال، برای پرسوجوی زیر:
“What’s the price of the best‑selling product last week?” میتوان مدل را طوری راهنمایی کرد که پلنی مانند این تولید کند:
1. get current date
2. retrieve the best-selling product last week
3. retrieve product information
4. generate query
5. generate response
استفاده از زبان طبیعی بیشتر کمک میکند که مولد پلن (plan generator) در برابر تغییرات در API ابزارها مقاومتر شود. اگر مدل شما عمدتاً با متنهای زبان طبیعی آموزش دیده باشد، احتمالاً در درک و تولید پلنها به زبان طبیعی بهتر عمل میکند و احتمال هالوسینیشن (hallucination) نیز کمتر میشود.
نقطهی ضعف این روش این است که شما به یک مترجم (translator) نیاز دارید تا هر عمل بیانشده در زبان طبیعی را به دستورات قابل اجرا تبدیل کند. با این حال، ترجمه کردن کار بسیار سادهتری نسبت به برنامهریزی (planning) است و میتوان آن را با مدلهای ضعیفتر نیز انجام داد، در حالی که خطر هالوسینیشن در آن کمتر است.
پلنهای پیچیده (Complex Plans)
تمام مثالهای پلن که تا اینجا دیدیم ترتیبی (sequential) بودند؛ یعنی: هر مرحلهی بعدی فقط بعد از اتمام مرحلهی قبلی اجرا میشود. ترتیبی که در آن اقدامات اجرا میشوند را Control Flow (جریان کنترل) مینامند. حالت Sequential فقط یکی از انواع control flow است.
انواع دیگر عبارتاند از:
Parallel
If statement
For loop
در ادامه توضیح هرکدام آمده است.
1. Sequential (ترتیبی): اجرای کار B بعد از اتمام کار A، معمولاً چون B به نتیجهی A وابسته است. مثال: ابتدا باید یک درخواست زبان طبیعی به SQL ترجمه شود، سپس کوئری SQL اجرا گردد.
2. Parallel (موازی): اجرای چند کار همزمان. مثال: برای پرسوجوی زیر: “Find me best-selling products under $100” ایجنت ممکن است:
· ابتدا ۱۰۰ محصول پرفروش را دریافت کند
· سپس برای هر کدام از آنها قیمت را بازیابی کند
این مراحل میتوانند بهصورت همزمان انجام شوند.
3. If Statement (شرطی): اجرای کار B یا C بسته به خروجی مرحلهی قبلی. مثال: ایجنت ابتدا گزارش درآمد NVIDIA را بررسی میکند. بر اساس نتیجه تصمیم میگیرد: سهام بخرد یا بفروشد
4. For Loop (حلقه): تکرار اجرای یک کار تا زمانی که شرط خاصی برقرار شود. مثال: تولید اعداد تصادفی. ادامه دادن این کار تا زمانی که یک عدد اول (prime number) پیدا شود.
این انواع مختلف جریان کنترل (control flow) در شکل 6‑11 نمایش داده شدهاند.

در مهندسی نرمافزار سنتی، شرایط مربوط به جریانهای کنترلی دقیق و مشخص هستند. اما در ایجنتهای مبتنی بر هوش مصنوعی، این مدلهای AI هستند که جریان کنترل را تعیین میکنند. پلنهایی که غیرترتیبی (non‑sequential) هستند، هم در مرحلهی تولید پلن و هم در مرحلهی تبدیل آن به دستورات اجرایی دشوارتر هستند.
وقتی یک فریمورک agent را ارزیابی میکنید، باید بررسی کنید که چه نوع control flowهایی را پشتیبانی میکند. مثلا اگر سیستم نیاز داشته باشد ۱۰ وبسایت را بررسی کند، آیا میتواند این کار را بهصورت همزمان (parallel) انجام دهد؟ اجرای موازی میتواند تاخیر (latency) که کاربر احساس میکند را به شکل قابل توجهی کاهش دهد.
حتی بهترین پلنها هم باید بهطور مداوم ارزیابی و اصلاح شوند تا احتمال موفقیت آنها بیشتر شود. اگرچه Reflection برای اینکه یک agent کار کند کاملاً ضروری نیست، اما برای اینکه یک agent واقعاً موفق باشد ضروری است.
Reflection میتواند در چند مرحله از فرآیند انجام یک کار استفاده شود:
· بعد از دریافت درخواست کاربر، برای بررسی اینکه آیا درخواست قابل انجام (feasible) است یا نه.
· بعد از تولید پلن اولیه، برای بررسی اینکه آیا پلن منطقی است یا نه.
· بعد از هر مرحلهی اجرا، برای بررسی اینکه آیا سیستم در مسیر درست حرکت میکند یا نه.
· بعد از اجرای کامل پلن، برای تشخیص اینکه آیا کار واقعاً انجام شده است یا نه.
Reflection و اصلاح خطا (Error Correction) دو مکانیزم متفاوت هستند که معمولاً در کنار هم استفاده میشوند. Reflection بینشهایی تولید میکند که کمک میکنند خطاهایی که باید اصلاح شوند شناسایی شوند. Reflection میتواند به دو روش انجام شود:
با همان ایجنت، از طریق پرامپتهای خودانتقادی (self‑critique)
یا با یک کامپوننت جداگانه، مانند یک scorer تخصصی(مدلی که برای هر خروجی یک امتیاز مشخص تولید میکند)
ایدهی ترکیب استدلال و عمل (reasoning + action) برای اولین بار در کار ReAct (Yao et al., 2022) معرفی شد و از آن زمان به یک الگوی رایج در طراحی agentها تبدیل شده است. در این مقاله، واژهی reasoning شامل دو چیز در نظر گرفته شده است:
برنامهریزی (planning)
reflection
در هر مرحله:
ایجنت تفکر خود را توضیح میدهد (planning)
یک اقدام انجام میدهد (action)
نتیجهی مشاهدهشده را تحلیل میکند (reflection)
این چرخه تا زمانی ادامه پیدا میکند که ایجنت تشخیص دهد کار تمام شده است. معمولاً ایجنت با استفاده از چند مثال در پرامپت آموزش داده میشود که خروجی را در قالب زیر تولید کند:
Thought 1: ...
Act 1: ...
Observation 1: ...
... این روند ادامه پیدا میکند تا زمانی که رفلکشن اعلام کند تسک تمام شده شده است.
Thought N: ...
Act N: Finish [Response to query]
در شکل 6‑12 نمونهای از یک ایجنت که از چارچوب ReAct استفاده میکند نشان داده شده است. این ایجنت به یک سؤال از دیتاست HotpotQA پاسخ میدهد. HotpotQA یک benchmark برای سوالهای چندمرحلهای (multi-hop question answering) است، یعنی سوالهایی که پاسخ آنها نیاز به چند مرحله استدلال دارد.
Reflection میتواند در یک سیستم چند ایجنتی (multi‑agent system) نیز پیادهسازی شود. در این حالت:
یک agent عملکننده (actor)
برنامهریزی میکند
ابزارها را اجرا میکند
یک agent ارزیاب (evaluator)
بعد از هر مرحله
یا بعد از چند مرحله
نتیجه را ارزیابی میکند. اگر پاسخ ایجنت نتواند کار را انجام دهد، میتوان از آن خواست:
دلیل شکست خود را تحلیل کند
پیشنهاد دهد چگونه بهتر شود
بر اساس این تحلیل، ایجنت یک پلن جدید تولید میکند. این کار باعث میشود ایجنتها از اشتباهات خود یاد بگیرند. فرض کنید وظیفهی ایجنت تولید کد باشد. یک evaluator ممکن است تشخیص دهد: کد تولید شده در ⅓ تستها شکست میخورد. ایجنت سپس reflection انجام میدهد و نتیجه میگیرد مشکل این است که آرایههایی که تمام اعداد آنها منفی هستند در نظر گرفته نشدهاند. در نتیجه ایجنت کد جدیدی تولید میکند که این حالت (all‑negative arrays) را هم در نظر میگیرد.

این همان رویکردی است که Reflexion (Shinn et al., 2023) در پیش گرفت. در این چارچوب، reflection به دو ماژول جداگانه تقسیم میشود:
Evaluator (ارزیاب)که نتیجهی کار ایجنت را ارزیابی میکند.
Self‑Reflection Module (ماژول خودبازاندیشی)که تحلیل میکند چه چیزی اشتباه بوده است.
شکل 6‑13 نمونههایی از ایجنتهای Reflexion در حال اجرا را نشان میدهد. نویسندگان از اصطلاح Trajectory برای اشاره به یک پلن (plan) استفاده میکنند. در هر مرحله، بعد از ارزیابی و self‑reflection، ایجنت یک trajectory جدید پیشنهاد میدهد.
در مقایسه با تولید پلن (plan generation)، پیادهسازی reflection نسبتاً سادهتر است و میتواند بهبود عملکردی فراتر از انتظار ایجاد کند. اما این رویکرد معایبی هم دارد. معایب اصلی: افزایش latency و افزایش هزینه است. دلیل آن این است که Thoughtها، Observationها و گاهی Actionها همگی نیاز به تولید توکن دارند، و در کارهایی با مراحل میانی زیاد، این مسئله هزینهی محاسباتی را بالا میبرد و تأخیر قابلاحساس برای کاربر را افزایش میدهد.
برای اینکه ایجنتها به قالب موردنظر پایبند بمانند نویسندگان ReAct و Reflexion از تعداد زیادی مثال (few‑shot examples) در پرامپت استفاده کردند. این کار دو پیامد دارد:
افزایش هزینهی توکنهای ورودی
کاهش فضای context برای اطلاعات مهم دیگر

از آنجا که ابزارها معمولاً نقش مهمی در موفقیت یک کار دارند، انتخاب ابزارها نیاز به دقت و توجه دارد. اینکه چه ابزارهایی را در اختیار ایجنت قرار دهید، بستگی دارد به محیط (environment) و نوع کار (task) و همچنین مدل هوش مصنوعیای که ایجنت را قدرت میدهد.
هیچ راهنمای قطعی و بینقصی برای انتخاب بهترین مجموعه ابزارها وجود ندارد. ادبیات مربوط به agentها طیف گستردهای از فهرستهای ابزار (tool inventories) را پوشش میدهد. برای مثال Toolformer (Schick et al., 2023) روی مدل GPT‑J فاینتیون انجام داد تا استفاده از ۵ ابزار را یاد بگیرد. Chameleon (Lu et al., 2023) از ۱۳ ابزار استفاده میکند. در مقابل، Gorilla (Patil et al., 2023) تلاش کرد ایجنتها را فقط با پرامپت طوری هدایت کند که از میان ۱٬۶۴۵ API، فراخوانی درست را انتخاب کنند.
هرچه ابزارهای بیشتری در اختیار ایجنت بگذارید، توانمندیهای بیشتری خواهد داشت. اما هرچه تعداد ابزارها بیشتر شود، استفادهی کارآمد از آنها سختتر میشود. مشابه انسان که هرچه تعداد ابزارها بیشتر باشد، تسلط کامل روی همهی آنها دشوارتر است. افزودن ابزارهای بیشتر همچنین به این معناست که توضیحات بیشتری برای ابزارها (tool descriptions) باید در پرامپت قرار گیرد، که ممکن است در ظرفیت context مدل جا نشود.
همانند بسیاری از تصمیمهایی که هنگام ساخت برنامههای هوش مصنوعی (AI applications) باید گرفته شوند، فرآیند انتخاب ابزار (tool selection) نیز نیازمند آزمایش (experimentation) و تحلیل (analysis) است.
برای کمک به تصمیمگیری، میتوانید کارهای زیر را انجام دهید:
1. مقایسهی عملکرد ایجنت با مجموعههای مختلف ابزارها: ببینید ایجنت در حالتهایی که مجموعهی ابزار متفاوت دارد، چگونه عمل میکند.
2. انجام یک مطالعهی حذف (Ablation Study): در این آزمایش یک ابزار خاص را از فهرست ابزارها (tool inventory) حذف میکنید. سپس بررسی میکنید که عملکرد ایجنت چقدر افت میکند. اگر حذف آن ابزار هیچ افت عملکردی ایجاد نکند، آن ابزار احتمالاً ضروری نیست — بنابراین میتوانید آن را حذف کنید.
3. بهدنبال ابزارهایی باشید که ایجنت روی آنها زیاد خطا میکند. اگر ابزاری برای ایجنت بیشازحد دشوار است — مثلاً حتی با پرامپتگذاری گسترده و فاینتیون هم مدل یاد نمیگیرد درست از آن استفاده کند — خود ابزار را عوض کنید (طراحی API سادهتر، قرارداد پارامتر روشنتر، خطاهای قابلتشخیصتر).
4. توزیع فراخوانی ابزارها را رسم کنید تا ببینید کدام ابزارها بیشترین و کمترین استفاده را دارند. شکل 6‑14 تفاوت الگوهای استفادهی ابزار میان GPT‑4 و ChatGPT را در Chameleon (Lu et al., 2023) نشان میدهد.

آزمایشهای Lu و همکاران (2023) دو نکتهی مهم را نشان میدهد:
وظایف مختلف به ابزارهای متفاوتی نیاز دارند.
برای مثال: ScienceQA (یک وظیفهی پاسخگویی به پرسشهای علمی) بسیار بیشتر به ابزارهای بازیابی دانش (knowledge retrieval) وابسته است. TabMWP (یک وظیفهی حل مسئلهی ریاضی روی دادههای جدولی) بیشتر به ابزارهای مربوط به محاسبه و تحلیل دادههای جدولی نیاز دارد.
مدلهای مختلف ترجیحات متفاوتی در انتخاب ابزار دارند.
برای مثال: GPT‑4 تمایل دارد مجموعهی گستردهتری از ابزارها را انتخاب کند. ChatGPT تمایل دارد بیشتر از ابزارهای تولید کپشن برای تصویر (image captioning) استفاده کند. در مقابل، GPT‑4 بیشتر به ابزارهای بازیابی دانش (knowledge retrieval) گرایش دارد.
هنگام ارزیابی یک agent framework باید بررسی کنید چه نوع plannerهایی را پشتیبانی میکند. چه ابزارهایی را میتواند مدیریت کند. زیرا فریمورکهای مختلف ممکن است روی دستههای متفاوتی از ابزارها تمرکز داشته باشند. برای مثال:
AutoGPT بیشتر روی APIهای شبکههای اجتماعی تمرکز دارد، مانند: Reddit، X (Twitter)، و Wikipedia
Composio بیشتر روی APIهای سازمانی (enterprise) تمرکز دارد، مانند: Google Apps، GitHub و Slack

Voyager (Wang et al., 2023) یک «مدیر مهارت» (skill manager) را پیشنهاد میکند تا مهارتهای (ابزارهای) جدیدی را که ایجنت برای استفادهی مجدد در آینده کسب میکند، پیگیری و ثبت نماید. هر مهارت در واقع یک برنامهی کدنویسی شده (coding program) است. زمانی که «مدیر مهارت» تشخیص دهد یک مهارتِ تازهخلقشده مفید است (مثلاً به این دلیل که با موفقیت به ایجنت کمک کرده تا وظیفهای را به انجام برساند)، آن مهارت را به «کتابخانهی مهارت» (skill library) اضافه میکند. این کتابخانه از نظر مفهومی مشابه فهرست ابزارها (tool inventory) است. این مهارتها را میتوان بعداً برای استفاده در وظایف دیگر بازیابی (retrieve) کرد.
پیشتر در این بخش اشاره شد که موفقیت یک ایجنت در یک محیط، به دو عامل بستگی دارد:
۱. موجودی ابزارهایش (Tool Inventory)
۲. توانایی برنامهریزی (Planning Capabilities)
شکست در هر یک از این دو، میتواند منجر به ناکامی ایجنت شود.
ارزیابی (Evaluation) یعنی شناسایی نقاط شکست. هرچه وظیفهای که ایجنت انجام میدهد پیچیدهتر باشد، احتمالات بیشتری برای بروز شکست وجود دارد. علاوه بر انواع شکستهای رایج در همهی برنامههای هوش مصنوعی (که در فصلهای ۳ و ۴ کتاب بحث شد)، ایجنتها شکستهای خاص خود را دارند که مربوط به:
فرایند برنامهریزی
اجرای ابزارها
و حتی راندمان/کارایی (Efficiency)
میباشد. برخی از این حالات شکست، راحتتر شناسایی میشوند، اما بعضی هم ممکن است تشخیصشان دشوارتر باشد. ابتدا حالتهای شکست (Failure Modes) را شناسایی کنید. برای هرکدام، فراوانی رخداد یا نرخ وقوع (Frequency/Rate) را اندازه بگیرید.
کتابخانهها و منابعی برای کمک به این کار وجود دارد. مثلا یک بنچمارک ساده توسط نویسنده ساخته شده (در ریپازیتوری گیتهاب کتاب) که حالتهای شکست مختلف را نشان میدهد. سایر بنچمارکهای تخصصی و لیدربوردها: Berkeley Function Calling Leaderboard، AgentOps Evaluation Harness، و TravelPlanner Benchmark. این منابع امکان مقایسه و ارزیابی کمی عملکرد ایجنتها بر اساس انواع شکستهای مختلف را میدهند.
1. شکستهای برنامهریزی (Planning Failures)
برنامهریزی کار دشواری است و میتواند به روشهای مختلفی دچار شکست شود. رایجترین نوع شکست در برنامهریزی، خطا در استفاده از ابزارها (tool use failure) است. ممکن است ایجنت برنامهای تولید کند که شامل یک یا چند مورد از خطاهای زیر باشد:
· ابزار نامعتبر (Invalid Tool)
برای مثال، ایجنت در برنامهی خود از ابزار bing_search استفاده میکند، در حالی که این ابزار در فهرست ابزارهای ایجنت (tool inventory) وجود ندارد.
· ابزار معتبر اما پارامترهای نامعتبر
برای مثال، ایجنت تابع lbs_to_kg را با دو پارامتر فراخوانی میکند، در حالی که این تابع در فهرست ابزارها وجود دارد اما فقط یک پارامتر به نام lbs میپذیرد.
· ابزار معتبر اما مقدار پارامتر نادرست
برای مثال، ایجنت تابع lbs_to_kg را با پارامتر درست (lbs) فراخوانی میکند، اما مقدار آن را ۱۰۰ قرار میدهد در حالی که مقدار صحیح باید ۱۲۰ باشد.
2. شکست در هدف (Goal Failure)
یکی دیگر از حالتهای شکست در برنامهریزی، شکست در هدف (goal failure) است؛ یعنی عامل (یا مدل) در دستیابی به هدف ناکام میماند. این موضوع میتواند به این دلیل باشد که برنامه، مسئله مورد نظر را حل نمیکند، یا اینکه مسئله را حل میکند ولی الزامات و محدودیتها را رعایت نمیکند. برای روشن شدن مطلب، تصور کنید از مدل خواستهاید برنامه دو هفتهای سفری از سانفرانسیسکو به هانوی با بودجه ۵۰۰۰ دلار تهیه کند. عامل ممکن است برنامهای تنظیم کند که مثلاً سفر را از سانفرانسیسکو به شهر هو چی مین انجام دهد، یا سفر دو هفتهای از سانفرانسیسکو به هانوی طرحریزی کند ولی بودجه تعیینشده را بهطور کامل رعایت نکند و از آن فراتر رود.
3. محدودیت زمان (Time Constraint Failure)
یکی از محدودیتهایی که در ارزیابی ایجنتها اغلب نادیده گرفته میشود، زمان است. در برخی وظایف، زمان انجام چندان اهمیت ندارد؛ مثلاً میتوانید کاری را به ایجنت بسپارید و فقط هنگام پایان آن را بررسی کنید. اما در بسیاری از موارد، ارزش خروجی ایجنت به زمان بستگی دارد. برای مثال اگر به ایجنت بگویید یک طرح گرنت پژوهشی بنویسد، اما پس از اتمام مهلت ارسال گرنت کار را تحویل دهد، خروجی دیگر ارزشی نخواهد داشت.
4. شکست در بازاندیشی (Reflection Error Failure)
نوع جالبی از شکست برنامهریزی، اشتباه در بازاندیشی (reflection) است. در این حالت، ایجنت گمان میکند که کار را انجام داده است، در حالی که واقعاً انجام نشده. مثلاً شما از ایجنت میخواهید ۵۰ نفر را در ۳۰ اتاق هتل جای دهد. ایجنت فقط ۴۰ نفر را جا میدهد اما ادعا میکند که وظیفه با موفقیت انجام شده است.
ارزیابی شکستهای برنامهریزی (Evaluating Planning Failures)
برای سنجش و اندازهگیری این نوع شکستها میتوان یک دیتاست برنامهریزی (Planning Dataset) طراحی کرد. هر ورودی در این دیتاست یک جفت (وظیفه، فهرست ابزار) است. برای هر وظیفه، ایجنت چندین پلن (مثلاً

عدد) ایجاد میکند و سپس معیارهای زیر محاسبه میشود:
از تمام پلنهای تولیدشده، چند مورد از نظر ساختاری و منطقی درست هستند؟
در هر وظیفه، ایجنت بهطور میانگین چند پلن باید بسازد تا یکی از آنها معتبر باشد؟
از همهی فراخوانیهای ابزار، چند مورد صحیح هستند؟
چند بار ایجنت سعی کرده ابزاری را صدا بزند که وجود ندارد؟
چند بار تابع درست انتخاب شده ولی ساختار پارامترها نادرست بوده؟
چند بار پارامتر از نظر نوع درست ولی مقدار اشتباه وارد شده است؟
خروجیهای عامل را برای یافتن الگوها بررسی کنید. ببینید عامل در انجام چه نوع وظایفی بیشتر دچار شکست میشود. آیا میتوانید فرضیهای دربارهی علت این شکستها ارائه دهید؟ همچنین مشخص کنید که مدل در استفاده از کدام ابزارها بیشتر اشتباه میکند. برخی ابزارها ممکن است برای عامل سختتر باشند. میتوانید توانایی عامل را در استفاده از ابزارهای دشوار با روشهای زیر بهبود دهید:
بهبود پرامپتنویسی
دادن نمونههای بیشتر
یا انجام فاینتیونینگ
و اگر هیچکدام از این روشها موفق نبود، میتوانید آن ابزار را با ابزاری سادهتر و قابل استفادهتر جایگزین کنید.
شکستهای ابزار (Tool Failures)
شکستهای ابزار زمانی رخ میدهند که ابزار صحیح انتخاب و استفاده شده است، اما خروجیِ آن ابزار اشتباه است.
خروجی نادرست ابزار: یکی از حالتهای شکست این است که یک ابزار صرفاً خروجی غلطی ارائه میدهد. برای مثال، یک سیستم توصیفگر تصویر (image captioner) شرح نادرستی از تصویر برمیگرداند، یا یک تولیدکننده کوئری SQL، کوئری اشتباهی تولید میکند.
خطاهای ترجمه (Translation Errors): اگر ایجنت فقط برنامههای سطح بالا (high-level plans) تولید کند و یک «ماژول ترجمه» وظیفه تبدیل هر اقدامِ برنامهریزیشده به دستورات اجرایی را بر عهده داشته باشد، ممکن است شکستها ناشی از خطاهای مرحله ترجمه باشد. (یعنی برنامه کلی درست است، اما تبدیل آن به دستور فنی دقیق، دچار اشتباه شده است).
شکستهای ابزار میتوانند زمانی هم رخ دهند که ایجنت به ابزار مناسب برای انجام وظیفه دسترسی نداشته باشد.
یک مثال واضح این است که اگر وظیفه شامل دریافت قیمت فعلی سهام از اینترنت باشد، اما ایجنت دسترسی به اینترنت نداشته باشد. در این حالت، حتی اگر ایجنت درست برنامهریزی کند، باز هم نمیتواند وظیفه را کامل انجام دهد.
شکستهای ابزار وابسته به خود ابزارها هستند؛ بنابراین هر ابزار باید بهصورت مستقل آزمایش و ارزیابی شود. یک توصیه مهم این است که همیشه هر فراخوانی ابزار (tool call) و خروجی آن را چاپ یا ثبت کنید تا بتوانید آنها را بررسی و ارزیابی کنید. اگر در سیستم شما یک ماژول ترجمه (translator) وجود دارد که برنامههای ایجنت را به دستورات اجرایی تبدیل میکند، باید بنچمارکهایی برای ارزیابی عملکرد این مترجم نیز طراحی کنید.
تشخیص شکستهایی که ناشی از کمبود ابزار مناسب هستند، نیازمند این است که بدانیم در حالت ایدهآل چه ابزارهایی باید استفاده شوند. اگر مشاهده کردید که ایجنت در یک حوزهی خاص مرتب شکست میخورد، ممکن است دلیل آن این باشد که ابزارهای لازم برای آن حوزه در اختیارش نیست. در چنین شرایطی با متخصصان انسانی آن حوزه همکاری کنید. مشاهده کنید که آنها برای انجام همان وظیفه از چه ابزارهایی استفاده میکنند.
ممکن است یک ایجنت با استفاده از ابزارهای درست، یک برنامه معتبر برای انجام یک وظیفه تولید کند، اما در عین حال غیربهینه یا ناکارآمد باشد. برای ارزیابی کارایی یک ایجنت، میتوان چند معیار را دنبال کرد:
بهطور میانگین، ایجنت برای تکمیل یک وظیفه به چند مرحله نیاز دارد؟
بهطور میانگین، انجام یک وظیفه برای ایجنت چه مقدار هزینه دارد؟
هر اقدام (action) معمولاً چقدر زمان میبرد؟ آیا اقداماتی وجود دارند که بهطور خاص بسیار زمانبر یا پرهزینه باشند؟
میتوان این معیارها را با یک baseline مقایسه کرد؛ این baseline میتواند یک ایجنت دیگر یا یک اپراتور انسانی باشد. هنگام مقایسهی ایجنتهای هوش مصنوعی با انسانها باید توجه داشت که شیوهی کار انسان و هوش مصنوعی بسیار متفاوت است. بنابراین چیزی که برای انسان کارآمد محسوب میشود، ممکن است برای هوش مصنوعی ناکارآمد باشد و برعکس. برای مثال بازدید از ۱۰۰ صفحه وب برای یک انسان که فقط میتواند هر بار یک صفحه را باز کند، بسیار ناکارآمد است؛ اما برای یک ایجنت هوش مصنوعی که میتواند همهی صفحات را بهصورت همزمان بررسی کند، کاری بسیار ساده محسوب میشود.
در این فصل بهطور مفصل دربارهی نحوهی کار سیستمهای RAG و ایجنتها صحبت کردیم. هر دو الگو اغلب با اطلاعاتی سروکار دارند که بیش از محدودیت کانتکست مدل هستند. یک سیستم حافظه (Memory System) که بتواند اطلاعات بیشتری را در کنار کانتکست مدل مدیریت کند، میتواند تواناییهای مدل را بهطور قابل توجهی افزایش دهد. حال بیایید بررسی کنیم که سیستم حافظه چگونه کار میکند.
حافظه به سازوکارهایی اشاره دارد که به یک مدل اجازه میدهند اطلاعات را نگه دارد و از آنها استفاده کند. یک سیستم حافظه بهویژه برای کاربردهای غنی از دانش مانند RAG و کاربردهای چندمرحلهای مانند ایجنتها بسیار مفید است. یک سیستم RAG برای ایجاد کانتکست تقویتشده (augmented context) به حافظه متکی است؛ این کانتکست میتواند در طول چندین نوبت گفتگو بزرگتر شود، زیرا سیستم اطلاعات بیشتری بازیابی میکند. یک سیستم ایجنتی نیز به حافظه نیاز دارد تا دستورالعملها (instructions)، مثالها، کانتکست، فهرست ابزارها (tool inventories)، برنامهها (plans)، خروجی ابزارها، بازاندیشیها (reflections) و موارد دیگر را موارد را ذخیره کند. اگرچه RAG و ایجنتها نیاز بیشتری به حافظه دارند، اما حافظه برای هر کاربرد هوش مصنوعی که نیاز به نگهداری اطلاعات داشته باشد مفید است.
سه مکانیزم اصلی حافظه در مدلهای هوش مصنوعی
1. دانش درونی (Internal Knowledge)
خود مدل یک نوع مکانیزم حافظه است، زیرا دانشی را که از دادههای آموزشی یاد گرفته در خود نگه میدارد. این دانش، دانش درونی مدل محسوب میشود.
این دانش فقط زمانی تغییر میکند که خود مدل بهروزرسانی یا دوباره آموزش داده شود.
مدل میتواند در همهی پرسوجوها به این دانش دسترسی داشته باشد.
2. حافظه کوتاهمدت (Short-term Memory)
کانتکست مدل نیز یک مکانیزم حافظه است. پیامهای قبلی در یک گفتگو میتوانند به کانتکست اضافه شوند تا مدل بتواند از آنها برای تولید پاسخهای بعدی استفاده کند.
این حافظه در طول یک وظیفه یا مکالمه فعال است.
بین وظایف مختلف پایدار نمیماند.
دسترسی به آن سریع است اما ظرفیت محدودی دارد.
به همین دلیل معمولاً برای ذخیره اطلاعاتی استفاده میشود که برای وظیفهی فعلی بیشترین اهمیت را دارند.
3. حافظه بلندمدت (Long-term Memory)
منابع دادهی خارجی که مدل میتواند از طریق بازیابی اطلاعات (retrieval) به آنها دسترسی داشته باشد—مانند آنچه در سیستمهای RAG استفاده میشود—یک مکانیزم حافظه محسوب میشوند.
این نوع حافظه را میتوان حافظهی بلندمدت مدل در نظر گرفت، زیرا:
میتواند در طول وظایف مختلف پایدار بماند.
برخلاف دانش درونی مدل، اطلاعات آن را میتوان حذف یا تغییر داد بدون اینکه خود مدل بهروزرسانی شود.
انسانها نیز به سازوکارهای حافظه مشابهی دسترسی دارند. برای مثال، نحوه نفس کشیدن بخشی از دانش درونی شماست. معمولاً این موضوع را فراموش نمیکنید مگر در شرایط بسیار جدی یا بحرانی. حافظه کوتاهمدت شما شامل اطلاعاتی است که بلافاصله با کاری که در حال انجام آن هستید مرتبط است؛ برای مثال نام فردی که همین الان با او آشنا شدهاید. حافظه بلندمدت شما نیز با ابزارهایی مانند کتابها، کامپیوترها، یادداشتها و منابع خارجی تقویت میشود.
اینکه از کدام نوع حافظه برای دادههای خود استفاده کنید، به میزان دفعات استفاده از آن اطلاعات بستگی دارد.
اطلاعاتی که برای تقریباً همهی وظایف ضروری هستند، باید از طریق آموزش یا فاینتیون کردن در دانش درونی مدل قرار بگیرند.
اطلاعاتی که بهندرت مورد نیاز هستند، بهتر است در حافظه بلندمدت ذخیره شوند.
حافظه کوتاهمدت برای اطلاعات فوری و وابسته به کانتکست فعلی استفاده میشود.
این سه نوع سازوکار حافظه در شکل ۶‑۱۶ نشان داده شدهاند.

حافظه برای عملکرد انسانها ضروری است. با پیشرفت کاربردهای هوش مصنوعی، توسعهدهندگان بهسرعت متوجه شدهاند که حافظه برای مدلهای هوش مصنوعی نیز اهمیت زیادی دارد. ابزارهای مختلفی برای مدیریت حافظه در مدلهای هوش مصنوعی ساخته شدهاند و بسیاری از ارائهدهندگان مدل، حافظه خارجی را در ساختار مدلهای خود ادغام کردهاند. افزودن یک سیستم حافظه به یک مدل هوش مصنوعی فواید فراوانی دارد. در ادامه چند مورد از این مزایا آمده است:
· مدیریت حجم زیاد اطلاعات در یک جلسه (Manage information overflow within a session)
در طول اجرای یک وظیفه، یک ایجنت مقدار زیادی اطلاعات جدید به دست میآورد، که ممکن است از حداکثر طول کانتکست مدل بیشتر باشد. اطلاعات اضافی را میتوان در حافظه بلندمدت ذخیره کرد تا از دست نرود.
· حفظ اطلاعات بین جلسات (Persist information between sessions)
یک مربی هوش مصنوعی عملاً بیفایده میشود اگر هر بار که میخواهید از او مشاوره بگیرید، مجبور باشید کل داستان زندگیتان را دوباره توضیح دهید. یک دستیار هوش مصنوعی نیز آزاردهنده خواهد بود اگر دائماً ترجیحات شما را فراموش کند. دسترسی به تاریخچهی مکالمه به ایجنت اجازه میدهد اقداماتش را شخصیسازی کند. مثلاً اگر مدل به خاطر داشته باشد که شما قبلاً The Three-Body Problem را دوست داشتهاید، هنگام درخواست پیشنهاد کتاب، آثار مشابه را به شما پیشنهاد میدهد.
· افزایش ثبات و سازگاری مدل (Boost a model’s consistency)
اگر شما از من یک سؤال ذهنی بپرسید—مثلاً «این شوخی را از ۱ تا ۵ امتیاز بده»—اگر پاسخ قبلی خود را به یاد داشته باشم، احتمال بیشتری دارد که پاسخ سازگار بدهم. به همین شکل، اگر یک مدل هوش مصنوعی بتواند به پاسخهای قبلی خود رجوع کند، میتواند پاسخهای آینده را کالیبره کند تا ثبات بیشتری داشته باشند.
· حفظ یکپارچگی ساختاری دادهها (Maintain data structural integrity)
از آنجا که متن ذاتاً بدون ساختار (unstructured) است، دادههایی که در کانتکست (Context) یک مدل متنی ذخیره میشوند نیز غیرساختارمند هستند. شما میتوانید دادههای ساختاریافته (مثل یک جدول) را خطبهخط وارد کانتکست کنید، اما هیچ تضمینی وجود ندارد که مدل متوجه شود این دادهها قرار است یک جدول باشند. داشتن یک سیستم حافظه که بتواند دادههای ساختاریافته را ذخیره کند، به حفظ یکپارچگی ساختاری دادههای شما کمک میکند. برای مثال، اگر از یک ایجنت بخواهید لیدهای (leads) فروش بالقوه را پیدا کند، ایجنت میتواند از یک فایل اکسل برای ذخیره این لیدها استفاده کند. همچنین ایجنت میتواند برای ذخیره ترتیب اقداماتی که باید انجام شود، از یک صف (Queue) استفاده کند.
سیستم حافظه در مدلهای هوش مصنوعی معمولاً شامل دو عملکرد است:
مدیریت حافظه (Memory Management): مدیریت اینکه چه اطلاعاتی باید در حافظه کوتاهمدت و چه اطلاعاتی در حافظه بلندمدت ذخیره شود.
بازیابی حافظه (Memory Retrieval): بازیابی اطلاعات مرتبط با وظیفه از حافظه بلندمدت.
بازیابی حافظه مشابه بازیابی در RAG است، چرا که حافظه بلندمدت یک منبع داده خارجی محسوب میشود. در این بخش، تمرکز من بر «مدیریت حافظه» است. مدیریت حافظه معمولاً شامل دو عملیات افزودن (add) و حذف (delete) حافظه است.
اگر فضای ذخیرهسازی حافظه محدود نباشد، ممکن است عملیات حذف ضروری نباشد. این موضوع ممکن است برای حافظه بلندمدت صدق کند، زیرا فضای ذخیرهسازی خارجی نسبتاً ارزان و بهراحتی قابل گسترش است. با این حال، حافظه کوتاهمدت توسط حداکثر طول کانتکست مدل محدود میشود و بنابراین به استراتژی مشخصی برای تعیین اینکه «چه چیزی اضافه شود و چه چیزی حذف شود» نیاز دارد.
حافظه بلندمدت میتواند برای ذخیره سرریز (overflow) اطلاعات از حافظه کوتاهمدت استفاده شود. این عملیات به این بستگی دارد که چه مقدار فضا میخواهید به حافظه کوتاهمدت اختصاص دهید. برای هر پرسوجو (Query)، ورودیِ کانتکست که به مدل داده میشود، شامل دو بخش است: حافظه کوتاهمدت و اطلاعات بازیابیشده از حافظه بلندمدت. بنابراین، ظرفیت حافظه کوتاهمدت مدل توسط این تعیین میشود که چه میزان از کانتکست باید برای اطلاعات بازیابیشده از حافظه بلندمدت رزرو شود. برای مثال اگر ۳۰٪ از فضای کانتکست برای حافظه بلندمدت رزرو شده باشد، مدل حداکثر میتواند از ۷۰٪ ظرفیت باقیمانده برای حافظه کوتاهمدت استفاده کند. وقتی این حد آستانه پر شد، اطلاعات اضافی (سرریز) میتواند به حافظه بلندمدت منتقل شود.
همانند بسیاری از مؤلفههایی که در این فصل بحث شد، مدیریت حافظه مختص کاربردهای هوش مصنوعی نیست. مدیریت حافظه سنگبنای تمام سیستمهای دادهای بوده است و استراتژیهای بسیاری برای استفاده بهینه از حافظه توسعه یافته است.
استراتژی FIFO
سادهترین استراتژی FIFO (مخفف First In, First Out یا «اولین ورودی، اولین خروجی») است. در این روش، اولین اطلاعاتی که به حافظه کوتاهمدت اضافه شدهاند، اولین مواردی هستند که به حافظه خارجی (بلندمدت) منتقل میشوند. با طولانیتر شدن یک مکالمه، ارائهدهندگان API مانند OpenAI ممکن است شروع به حذف بخشهای ابتدایی مکالمه کنند. فریمورکهایی مانند LangChain نیز امکان نگهداری Nپیام آخر یا N توکن آخر را فراهم میکنند. این استراتژی بر این فرض استوار است که پیامهای اولیه نسبت به بحثهای جاری اهمیت کمتری دارند. با این حال، این فرض میتواند یک اشتباه مهلک باشد. در بسیاری از مکالمات، پیامهای اولیه حاوی بیشترین اطلاعات هستند، بهویژه زمانی که هدف اصلی مکالمه در همان ابتدا بیان شده باشد. اگرچه پیادهسازی FIFO ساده است، اما میتواند باعث شود مدل رشتهی اطلاعات مهم را از دست بدهد.
حذف موارد زائد (Redundancy)
استراتژیهای پیچیدهتر شامل حذف موارد زائد هستند. زبانهای انسانی برای افزایش شفافیت و جبران سوءتفاهمهای احتمالی، دارای افزونگی (Redundancy) هستند. اگر راهی برای شناسایی خودکار این موارد زائد وجود داشته باشد، اثر حافظه (Memory Footprint) به شکل قابلتوجهی کاهش مییابد.
۱. خلاصهسازی (Summarization):
یک راه برای حذف موارد زائد، استفاده از خلاصهی مکالمه است. این خلاصه میتواند توسط خودِ مدل یا مدل دیگری تولید شود. خلاصهسازی، همراه با ردیابی موجودیتهای نامدار (Named Entities)، میتواند بسیار مؤثر باشد. رویکرد Bae و همکاران (۲۰۲۲): آنها گامی فراتر رفتند؛ پس از بهدست آوردن خلاصه، یک حافظه جدید با ترکیب خلاصه و «اطلاعات کلیدی که در خلاصه جا مانده بود» ساختند. آنها یک طبقهبندیکننده (Classifier) توسعه دادند که برای هر جمله در حافظه و هر جمله در خلاصه، تعیین میکند که آیا فقط یکی، هر دو، یا هیچکدام باید به حافظه جدید اضافه شوند.
۲. رویکرد بازتابی (Reflection Approach)
لیو و همکاران (۲۰۲۳) از رویکرد «بازتاب» استفاده کردند. در این روش، پس از هر اقدام، از ایجنت خواسته میشود دو کار انجام دهد:
بازتاب (Reflect): روی اطلاعاتی که بهتازگی تولید شده است فکر کند.
تصمیمگیری: تعیین کند که آیا این اطلاعات جدید باید در حافظه درج شود، با حافظه موجود ادغام گردد یا جایگزین اطلاعات قبلی شود (بهخصوص اگر اطلاعات قدیمی منسوخ شده و با اطلاعات جدید در تضاد باشند).
مدیریت تناقضات (Handling Contradictions)
هنگام مواجهه با قطعات اطلاعاتی متناقض:
برخی ترجیح میدهند اطلاعات جدیدتر را نگه دارند.
برخی از مدلهای هوش مصنوعی میخواهند قضاوت کنند که کدام را نگه دارند.
چگونگی مدیریت تناقض به مورد مصرف (Use Case) بستگی دارد. وجود تناقض میتواند باعث سردرگمی ایجنت شود، اما از سوی دیگر میتواند به ایجنت کمک کند تا موضوع را از زوایای مختلف بررسی کند.
با توجه به محبوبیت RAG و پتانسیل ایجنتها، بسیاری از خوانندگان اولیه گفتهاند که این فصل هیجانانگیزترین بخش کتاب برای آنها بوده است.
این فصل با RAG شروع شد، الگویی که زودتر از ایجنتها رایج شد. بسیاری از وظایف به حجم زیادی از دانش پسزمینه نیاز دارند که اغلب بیشتر از ظرفیت کانتکست مدل است. برای مثال ابزارهای کمکی برنامهنویسی (code copilots) ممکن است نیاز داشته باشند به یک کدبیس کامل دسترسی پیدا کنند. دستیارهای تحقیقاتی ممکن است مجبور باشند چندین کتاب را تحلیل کنند. RAG در ابتدا برای رفع محدودیت کانتکست مدلها طراحی شد، اما بعداً مشخص شد که علاوه بر آن:
استفاده کارآمدتر از اطلاعات را ممکن میکند،
کیفیت پاسخها را افزایش میدهد،
و هزینهی محاسباتی را کاهش میدهد.
از همان روزهای اولیهی مدلهای بنیادی (foundation models)، روشن بود که الگوی RAG ارزش عظیمی برای طیف گستردهای از کاربردها دارد، و امروز در محصولات مصرفی و سازمانی بهطور گسترده مورد استفاده قرار میگیرد.
RAG از یک فرآیند دو مرحلهای استفاده میکند:
بازیابی اطلاعات مرتبط از حافظه خارجی،
استفاده از آن اطلاعات برای تولید پاسخهای دقیقتر.
کیفیت سیستم RAG به قدرت بازیاب (retriever) وابسته است.
بازیابهای مبتنی بر کلمه، مانند Elasticsearch و BM25، سبکتر بوده و برای شروع عملکرد خوبی دارند.
بازیابهای مبتنی بر امبدینگ، سنگینتر هستند اما میتوانند عملکرد بهتری ارائه دهند.
بازیابی مبتنی بر Embedding توسط جستوجوی برداری (Vector Search) پشتیبانی میشود؛ روشی که همچنین ستون فقرات بسیاری از کاربردهای اصلی اینترنت، مانند جستوجو و سیستمهای پیشنهاددهنده است. بسیاری از الگوریتمهای جستوجوی برداری که برای این کاربردها توسعه یافتهاند، میتوانند برای RAG نیز استفاده شوند. الگوی RAG را میتوان نوعی ایجنت در نظر گرفت که در آن retriever یک ابزار است که مدل میتواند از آن استفاده کند. هر دو روش کمک میکنند محدودیت کانتکست دور زده شود، و مدل با اطلاعات بهروزتر کار کند.
اما الگوی ایجنت بسیار قدرتمندتر است. یک ایجنت توسط محیط و ابزارهایی که در اختیار دارد تعریف میشود. در یک ایجنت هوش مصنوعی مدل نقش برنامهریز (planner) را دارد، وظیفه را تحلیل میکند، چند مسیر ممکن را میسنجد، و بهترین گزینه را انتخاب میکند. وظایف پیچیده ممکن است به چندین مرحله نیاز داشته باشند، که یک مدل قوی برای برنامهریزی را ضروری میکند. این توانایی میتواند با reflection و سیستم حافظه تقویت شود تا ایجنت بتواند پیشرفت خود را دنبال کند.
هرچه ابزارهای بیشتری به یک مدل بدهید تواناییهای بیشتری پیدا میکند، و میتواند وظایف سختتری را حل کند. اما از سوی دیگر هر چه ایجنت ها خودکار شوند، شکستهای ایجنت میتوانند فاجعهبارتر شوند. استفاده از ابزارها، ایجنتها را در معرض ریسکهای امنیتی قرار میدهد (که در فصل ۵ بررسی شد). بنابراین برای استفادهی واقعی از ایجنتها، باید سازوکارهای دفاعی قوی طراحی شود.
چه RAG و چه ایجنت، هر دو با حجم بالایی از اطلاعات کار میکنند—بیش از حداکثر کانتکست اکثر مدلها. این موضوع نیاز به یک سیستم حافظه را ایجاد میکند تا بتوان تمام این اطلاعات را مدیریت و استفاده کرد. فصل با بحث کوتاهی دربارهی شکل و عملکرد این سیستم حافظه پایان یافت
«RAG و ایجنتها، هر دو روشهایی مبتنی بر پرامپت (Prompt-based) هستند؛ چرا که کیفیت خروجی مدل را صرفاً از طریق ورودیها و بدون دستکاری در خودِ مدل بهبود میبخشند. اگرچه این دو الگو امکان ساخت اپلیکیشنهای شگفتانگیز بسیاری را فراهم میکنند، اما تغییر دادن لایههای زیرین و ساختار خودِ مدل میتواند فرصتهای بهمراتب بیشتری را ایجاد کند. چگونگی انجام این کار، موضوع بحث فصل آینده خواهد بود.»