ترجمه کتاب ساخت برنامههای کاربردی با مدلهای پایه - انتشارات O’Reilly
BOOK: O'Reilly_AI_Engineering_Building_Applications_with_Foundation_Models
روششناسی ارزیابی (Evaluation Methodology)
هرچه استفاده از هوش مصنوعی بیشتر شود، فرصت برای شکستهای فاجعهبار نیز بیشتر میشود. ما در مدت کوتاهی که مدلهای پایه وجود داشتهاند، شکستهای زیادی دیدهایم. یک مرد پس از تشویق شدن توسط یک چتبات خودکشی کرد. وکلای دادگستری شواهد جعلی تولیدشده توسط هوش مصنوعی را ارائه دادند. خطوط هوایی Air Canada به دلیل ارائه اطلاعات نادرست توسط چتبات هوش مصنوعیاش به یک مسافر، به پرداخت خسارت محکوم شد. بدون روشی برای کنترل کیفیت خروجیهای هوش مصنوعی، ممکن است ریسک آن برای بسیاری از کاربردها بر مزایایش پیشی بگیرد.
همانطور که تیمها برای پذیرش هوش مصنوعی عجله میکنند، بسیاری به سرعت متوجه میشوند که بزرگترین مانع برای تحقق کاربردهای هوش مصنوعی، ارزیابی است. برای برخی کاربردها، پیادهسازی ارزیابی میتواند بخش عمده تلاش توسعه را به خود اختصاص دهد.
به دلیل اهمیت و پیچیدگی ارزیابی، این کتاب دو فصل را به آن اختصاص داده است. این فصل روشهای ارزیابی مختلف مورد استفاده برای ارزیابی مدلهای باز (open-ended)، نحوه عملکرد این روشها و محدودیتهای آنها را پوشش میدهد. فصل بعدی بر چگونگی استفاده از این روشها برای انتخاب مدل برای کاربرد شما و ساخت یک خط لوله ارزیابی (evaluation pipeline) برای ارزیابی کاربرد(application) متمرکز است.
اگرچه من ارزیابی را در فصول جداگانهای بحث میکنم، اما ارزیابی باید در چارچوب یک سیستم کامل در نظر گرفته شود، نه به صورت مجزا. هدف ارزیابی، کاهش ریسکها و کشف فرصتها است. برای کاهش ریسکها، ابتدا باید نقاطی را که سیستم شما احتمالاً در آنها شکست میخورد شناسایی کنید و ارزیابی خود را حول آنها طراحی کنید. اغلب، این ممکن است نیازمند بازطراحی سیستم شما برای افزایش قابلیت مشاهده شکستهای آن باشد. بدون درک واضح از اینکه سیستم شما در کجا شکست میخورد، هیچ مقدار از معیارها یا ابزارهای ارزیابی نمیتواند سیستم را مقاوم (robust) سازد.
قبل از پرداختن به روشهای ارزیابی، مهم است که چالشهای ارزیابی مدلهای پایه را تصدیق کنیم. از آنجایی که ارزیابی دشوار است، بسیاری از افراد به گفتار شفاهی (مثلاً اینکه کسی میگوید مدل X خوب است) یا بررسی چشمی نتایج بسنده میکنند. این امر ریسک را بیشتر کرده و تکرار (iteration) کاربرد را کند میکند. در عوض، ما باید روی ارزیابی سیستماتیک سرمایهگذاری کنیم تا نتایج قابل اعتمادتر شوند.
از آنجایی که بسیاری از مدلهای پایه دارای یک مؤلفه مدل زبانی هستند، این فصل مروری سریع بر معیارهای مورد استفاده برای ارزیابی مدلهای زبانی ارائه میدهد، از جمله آنتروپی متقاطع (cross entropy) و پرپلکسیتی (perplexity). این معیارها برای هدایت آموزش و تنظیم دقیق مدلهای زبانی ضروری هستند و اغلب در بسیاری از روشهای ارزیابی استفاده میشوند.
ارزیابی مدلهای پایه به ویژه چالشبرانگیز است زیرا باز (open-ended) هستند و من بهترین روشها برای مقابله با این چالش را پوشش خواهم داد. استفاده از ارزیابهای انسانی (human evaluators) برای بسیاری از کاربردها همچنان یک گزینه ضروری است. با این حال، با توجه به کندی و هزینهبر بودن حاشیهنویسیهای انسانی، هدف خودکارسازی فرآیند است. این کتاب بر ارزیابی خودکار متمرکز است که شامل هر دو نوع ارزیابی عینی (exact) و ذهنی (subjective) میشود.
ستاره در حال ظهور ارزیابی هدفمند، هوش مصنوعی به عنوان قاضی (AI as a judge) است - رویکردی که از هوش مصنوعی برای ارزیابی پاسخهای هوش مصنوعی استفاده میکند. این روش ذهنی است زیرا امتیاز به مدل و پرامپتی که قاضی هوش مصنوعی استفاده میکند بستگی دارد. در حالی که این رویکرد به سرعت در صنعت در حال جذب توجه است، مخالفت شدید کسانی را نیز برمیانگیزد که معتقدند هوش مصنوعی برای این وظیفه مهم به اندازه کافی قابل اعتماد نیست. من به ویژه برای پرداختن عمیقتر به این بحث هیجانزده هستم و امیدوارم شما نیز چنین باشید.
چالشهای ارزیابی مدلهای پایه (Challenges of Evaluating Foundation Models)
ارزیابی مدلهای یادگیری ماشین همواره دشوار بوده است. با ظهور مدلهای پایه، این ارزیابی حتی دشوارتر شده است. دلایل متعددی وجود دارد که چرا ارزیابی مدلهای پایه چالشبرانگیزتر از ارزیابی مدلهای سنتی یادگیری ماشین است.
اولاً، هرچه مدلهای هوش مصنوعی هوشمندتر میشوند، ارزیابی آنها نیز دشوارتر میشود. اکثر افراد میتوانند تشخیص دهند که پاسخ ریاضی یک دانشآموز کلاس اولی اشتباه است. اما تعداد کمی میتوانند همین کار را برای یک مسئله ریاضی در سطح دکتری انجام دهند. تشخیص اینکه یک خلاصه کتاب بد است اگر بیمعنی باشد آسان است، اما اگر خلاصه منسجم باشد، کار بسیار دشوارتر میشود. برای اعتبارسنجی کیفیت یک خلاصه، ممکن است ابتدا نیاز به خواندن کتاب داشته باشید.
این ما را به یک نتیجهگیری مهم میرساند: ارزیابی میتواند برای وظایف پیچیده بسیار زمانبرتر باشد. دیگر نمیتوانید یک پاسخ را صرفاً بر اساس نحوه بیان آن ارزیابی کنید. همچنین نیاز به بررسی واقعیتها، استدلال و حتی تلفیق تخصص حوزه خواهید داشت.
دوم، ماهیت باز و بدون محدودیت (open‑ended) مدلهای پایه رویکرد سنتیِ ارزیابی مدلها بر اساس پاسخهای مرجع (ground truth) را تضعیف میکند. در یادگیری ماشین سنتی، بیشتر وظایف بسته (close‑ended) هستند. برای مثال، یک مدل دستهبندی (classification) فقط میتواند از میان دستههای از پیش تعیینشده خروجی بدهد. برای ارزیابی چنین مدلی، میتوان خروجیهای آن را با پاسخهای مورد انتظار مقایسه کرد. اگر پاسخ درست دسته X باشد اما مدل دستهی Y را خروجی بدهد، مدل اشتباه کرده است.
اما در یک وظیفهی باز (open‑ended)، برای یک ورودی مشخص ممکن است پاسخهای درست بسیار زیادی وجود داشته باشد. بنابراین تهیه یک فهرست کامل از تمام پاسخهای صحیح برای مقایسه عملاً غیرممکن است.
سوم اینکه بیشتر مدلهای پایه بهصورت جعبهسیاه (black box) در نظر گرفته میشوند؛ یا به این دلیل که ارائهدهندگان مدل ترجیح میدهند جزئیات مدل را منتشر نکنند، یا به این دلیل که توسعهدهندگان کاربردها تخصص لازم برای درک آنها را ندارند. جزئیاتی مانند معماری مدل، دادههای آموزشی و فرایند آموزش میتوانند اطلاعات زیادی دربارهی نقاط قوت و ضعف یک مدل ارائه دهند. بدون دسترسی به این جزئیات، تنها راه ارزیابی یک مدل مشاهدهی خروجیهای آن است.
در عین حال، معیارهای ارزیابی عمومی که بهصورت عمومی در دسترس هستند نشان دادهاند که برای ارزیابی مدلهای پایه (Foundation Models) کافی نیستند. در حالت ایدهآل، معیارهای ارزیابی باید بتوانند دامنه کامل تواناییهای یک مدل را پوشش دهند. با پیشرفت هوش مصنوعی، این معیارها نیز باید تکامل پیدا کنند تا با آن همگام بمانند.
یک معیار ارزیابی زمانی برای یک مدل اشباع (saturated) میشود که مدل بتواند امتیاز کامل در آن به دست آورد. در مورد مدلهای پایه، این اشباع شدن بسیار سریع رخ میدهد. برای مثال، معیار GLUE (ارزیابی عمومی درک زبان) در سال ۲۰۱۸ معرفی شد و تنها در مدت یک سال اشباع شد؛ به همین دلیل در سال ۲۰۱۹ معیار SuperGLUE معرفی گردید. بهطور مشابه، NaturalInstructions (2021) با SuperNaturalInstructions (2022) جایگزین شد. همچنین MMLU (2020) که یک معیار قوی بود و بسیاری از مدلهای اولیه پایه بر آن تکیه داشتند، تا حد زیادی با MMLU‑Pro (2024) جایگزین شد.
در نهایت، دامنه ی ارزیابی برای مدلهای عمومی (general‑purpose models) نیز گسترش یافته است. در مدلهای مخصوص یک وظیفه، ارزیابی معمولاً شامل اندازهگیری عملکرد مدل در همان وظیفهای است که برای آن آموزش دیده است. اما در مدلهای عمومی، ارزیابی تنها به سنجش عملکرد مدل در وظایف شناختهشده محدود نمیشود؛ بلکه شامل کشف وظایف جدیدی است که مدل میتواند انجام دهد. این وظایف حتی ممکن است فراتر از تواناییهای انسانی باشند. بنابراین، ارزیابی علاوه بر سنجش عملکرد، مسئولیت کاوش تواناییها و محدودیتهای بالقوهی هوش مصنوعی را نیز بر عهده دارد.
خبر خوب این است که چالشهای جدید در ارزیابی باعث شدهاند روشها و معیارهای ارزیابی جدید زیادی ایجاد شوند. شکل ۳‑۱ نشان میدهد که تعداد مقالات منتشرشده درباره ارزیابی مدلهای زبانی بزرگ (LLM) در نیمه اول سال ۲۰۲۳ هر ماه بهصورت نمایی افزایش یافته است؛ از حدود ۲ مقاله در ماه به نزدیک ۳۵ مقاله در ماه

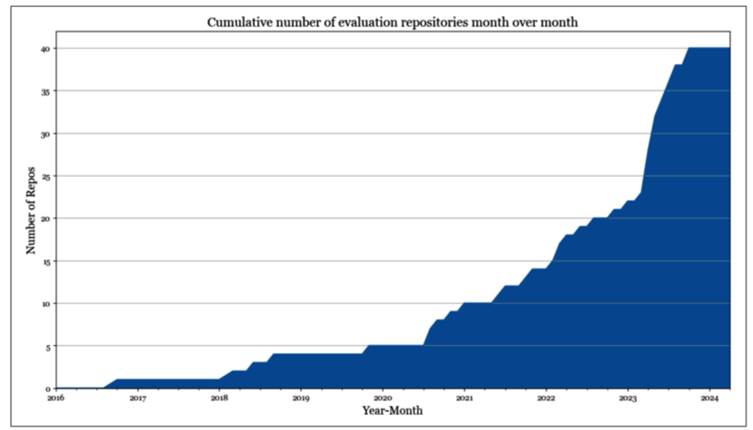
در تحلیل شخصی خود از ۱۰۰۰ مخزن برتر مرتبط با هوش مصنوعی در GitHub که بر اساس تعداد ستاره رتبهبندی شدهاند، بیش از ۵۰ مخزن اختصاص دادهشده به ارزیابی پیدا کردم (تا ماه می ۲۰۲۴). وقتی تعداد این مخزنهای ارزیابی را بر اساس تاریخ ایجاد آنها رسم کنیم، منحنی رشد آن شبیه رشد نمایی است؛ همانطور که در شکل ۳‑۲ نشان داده شده است.
خبر بد این است که با وجود افزایش علاقه به ارزیابی، این حوزه از نظر میزان توجه هنوز از سایر بخشهای فرایند مهندسی هوش مصنوعی عقبتر است. Balduzzi و همکارانش از DeepMind در مقالهای اشاره کردند که «توسعه روشهای ارزیابی در مقایسه با توسعه الگوریتمها توجه نظاممند بسیار کمتری دریافت کرده است». طبق این مقاله، نتایج آزمایشها تقریبا همیشه برای بهبود الگوریتمها استفاده میشوند و بهندرت برای بهبود روشهای ارزیابی به کار میروند.
با توجه به این کمبود سرمایهگذاری در حوزه ارزیابی، شرکت Anthropic از سیاستگذاران خواسته است که بودجه دولتی و کمکهزینههای بیشتری هم برای توسعه روشهای جدید ارزیابی و هم برای بررسی میزان پایداری و قابلاعتماد بودن روشهای ارزیابی موجود اختصاص دهند.
برای نشان دادن بیشتر اینکه سرمایهگذاری در حوزه ارزیابی نسبت به دیگر حوزههای فضای هوش مصنوعی عقبتر است، میتوان دید که تعداد ابزارهای ارزیابی در مقایسه با ابزارهای مدلسازی، آموزش مدل و ارکستراسیون هوش مصنوعی بسیار کمتر است؛ همانطور که در شکل ۳‑۳ نشان داده شده است.
سرمایهگذاری ناکافی منجر به زیرساخت ناکافی میشود و این موضوع انجام ارزیابیهای نظاممند را برای افراد دشوار میکند. وقتی از افراد پرسیده شد که چگونه برنامههای هوش مصنوعی خود را ارزیابی میکنند، بسیاری گفتند که فقط با نگاه کردن به نتایج (eyeballing) آنها را بررسی میکنند. بسیاری نیز مجموعه کوچکی از پرامپتهای ثابت دارند که از آنها برای ارزیابی مدلها استفاده میکنند.
فرایند انتخاب و آمادهسازی این پرامپتها معمولا غیرنظاممند (ad hoc) است و اغلب بر اساس تجربه شخصی فرد انتخابکننده انجام میشود، نه بر اساس نیازهای واقعی کاربرد. ممکن است در مراحل اولیه برای راهاندازی یک پروژه بتوان با این روش غیرنظاممند کار را پیش برد، اما برای تکرار و بهبود مداوم یک کاربرد کافی نخواهد بود.
این کتاب بر یک رویکرد نظاممند برای ارزیابی تمرکز دارد.

درک معیارهای مدلسازی زبان (Understanding Language Modeling Metrics)
مدلهای پایه از مدلهای زبانی تکامل پیدا کردهاند. بسیاری از مدلهای پایه هنوز هم مدلهای زبانی را بهعنوان مؤلفه اصلی خود دارند. برای این مدلها، عملکرد مؤلفه مدل زبانی معمولا همبستگی بالایی با عملکرد مدل پایه در کاربردهای پاییندستی (downstream applications) دارد (Liu و همکاران، ۲۰۲۳). بنابراین داشتن یک درک کلی از معیارهای مدلسازی زبان میتواند در فهم عملکرد مدل در کاربردهای پاییندستی بسیار مفید باشد.
همانطور که در فصل ۱ گفته شد، مدلسازی زبان دهههاست که وجود دارد و توسط کلود شانون در مقاله سال ۱۹۵۱ با عنوان «Prediction and Entropy of Printed English» محبوب شد. معیارهایی که برای هدایت توسعه مدلهای زبانی استفاده میشوند از آن زمان تاکنون تغییر چندانی نکردهاند.
بیشتر مدلهای زبانی خودبازگشتی (autoregressive) با استفاده از آنتروپی متقاطع (cross entropy) یا معیار مرتبط با آن یعنی پرپلکسیتی (perplexity) آموزش داده میشوند. هنگام خواندن مقالات و گزارشهای مدلها ممکن است با معیارهای بیت بر کاراکتر (BPC) و بیت بر بایت (BPB) نیز مواجه شوید که هر دو گونههایی از آنتروپی متقاطع هستند.
هر چهار معیار cross entropy، perplexity، BPC و BPB ارتباط نزدیکی با یکدیگر دارند. اگر مقدار یکی از آنها را بدانید، با داشتن اطلاعات لازم میتوانید سه معیار دیگر را نیز محاسبه کنید. هرچند از آنها با عنوان معیارهای مدلسازی زبان یاد میکنم، اما میتوان از آنها برای هر مدلی که دنبالهای از توکنها تولید میکند استفاده کرد، حتی اگر این توکنها متنی نباشند.
به یاد بیاورید که یک مدل زبانی اطلاعات آماری مربوط به زبان را کدگذاری میکند؛ یعنی اینکه در یک زمینه مشخص، احتمال ظاهر شدن یک توکن چقدر است. از نظر آماری، اگر زمینه جمله «I like drinking __» باشد، کلمه بعدی به احتمال بیشتری «tea» خواهد بود تا «charcoal». هرچه یک مدل بتواند اطلاعات آماری بیشتری از زبان را ثبت کند، در پیشبینی توکن بعدی بهتر عمل میکند.
در اصطلاح یادگیری ماشین، یک مدل زبانی توزیع دادههای آموزشی خود را یاد میگیرد. هرچه این یادگیری بهتر باشد، مدل در پیشبینی ادامه دادههای آموزشی دقیقتر عمل میکند و مقدار cross entropy در دادههای آموزشی کمتر خواهد بود. مانند هر مدل یادگیری ماشین دیگری، عملکرد مدل فقط روی دادههای آموزشی مهم نیست؛ بلکه عملکرد آن روی دادههای واقعی یا دادههای تولید (production data) نیز اهمیت دارد. بهطور کلی، هرچه دادههای شما به دادههای آموزشی مدل نزدیکتر باشند، مدل روی دادههای شما بهتر عمل میکند.
در مقایسه با بقیه کتاب، این بخش ریاضیمحورتر است. اگر آن را گیجکننده یافتید، میتوانید از بخشهای ریاضی صرفنظر کنید و بیشتر روی توضیح نحوه تفسیر این معیارها تمرکز کنید. حتی اگر قصد آموزش یا فاینتیون مدلهای زبانی را ندارید، درک این معیارها میتواند در انتخاب مدل مناسب برای کاربرد شما مفید باشد. همچنین در طول این کتاب نشان داده میشود که این معیارها گاهی در برخی روشهای ارزیابی و حذف دادههای تکراری (data deduplication) نیز کاربرد دارند.
آنتروپی (Entropy)
آنتروپی اندازه میگیرد که به طور متوسط هر توکن چه مقدار اطلاعات حمل میکند. هرچه آنتروپی بیشتر باشد، هر توکن اطلاعات بیشتری دارد و در نتیجه برای نمایش آن بیتهای بیشتری لازم است.
برای روشن شدن موضوع، یک مثال ساده را در نظر بگیرید. فرض کنید میخواهید زبانی بسازید تا موقعیتها درون یک مربع را توصیف کنید (همانطور که در شکل ۳‑۴ نشان داده شده است).
اگر زبان شما فقط دو توکن داشته باشد (حالت a در شکل ۳‑۴)، هر توکن فقط میتواند مشخص کند که موقعیت بالا است یا پایین. چون فقط دو توکن وجود دارد، یک بیت برای نمایش آنها کافی است. بنابراین آنتروپی این زبان برابر با ۱ است.

اگر زبان شما چهار توکن داشته باشد (حالت b در شکل ۳‑۴)، هر توکن میتواند موقعیت دقیقتری را مشخص کند: بالا‑چپ، بالا‑راست، پایین‑چپ یا پایین‑راست. اما چون اکنون چهار توکن وجود دارد، برای نمایش آنها به دو بیت نیاز دارید. بنابراین آنتروپی این زبان برابر با ۲ است. این زبان آنتروپی بالاتری دارد، زیرا هر توکن اطلاعات بیشتری حمل میکند، اما در عوض برای نمایش هر توکن بیتهای بیشتری لازم است.
به طور شهودی، آنتروپی اندازه میگیرد که پیشبینی عنصر بعدی در یک زبان چقدر دشوار است. هرچه آنتروپی یک زبان کمتر باشد (یعنی هر توکن اطلاعات کمتری حمل کند)، آن زبان قابلپیشبینیتر است. در مثال قبلی، زبانی که فقط دو توکن دارد پیشبینی آسانتری نسبت به زبانی با چهار توکن دارد (چون باید از میان دو گزینه انتخاب کنید، نه چهار گزینه). این موضوع شبیه حالتی است که اگر بتوانید کاملا پیشبینی کنید من چه چیزی قرار است بعدا بگویم، حرفی که میزنم هیچ اطلاعات جدیدی برای شما نخواهد داشت.
آنتروپی متقاطع (Cross Entropy)
وقتی یک مدل زبانی را روی یک مجموعهداده آموزش میدهید، هدف این است که مدل توزیع آماری دادههای آموزشی را یاد بگیرد. به عبارت دیگر، هدف این است که مدل بتواند پیشبینی کند در دادههای آموزشی چه چیزی در ادامه میآید. مقدار cross entropy یک مدل زبانی روی یک مجموعهداده نشان میدهد که پیشبینی عنصر بعدی در آن دادهها برای مدل چقدر دشوار است.
آنتروپی متقاطع یک مدل روی دادههای آموزشی به دو عامل بستگی دارد:
قابلپیشبینی بودن دادههای آموزشی که با آنتروپی دادهها اندازهگیری میشود.
میزان تفاوت توزیعی که مدل یاد گرفته با توزیع واقعی دادههای آموزشی.
آنتروپی و آنتروپی متقاطع هر دو با نماد ریاضی H نشان داده میشوند. فرض کنید:
P توزیع واقعی دادههای آموزشی باشد.
Q توزیعی باشد که مدل زبانی یاد گرفته است.
در این صورت:
آنتروپی دادههای آموزشی برابر است با H(P).
میزان اختلاف توزیع Q نسبت به P را میتوان با واگرایی کولبک–لایبلر (KL divergence) اندازهگیری کرد که به صورت ریاضی با DKL(P | | Q) نمایش داده میشود.
آنتروپی متقاطع مدل نسبت به دادههای آموزشی به صورت زیر تعریف میشود:

آنتروپی متقاطع متقارن نیست. یعنی:

به بیان ساده، اگر P را با Q بسنجیم نتیجه با حالتی که Q را با P بسنجیم یکسان نیست.
در آموزش مدل زبانی، هدف این است که Cross Entropy نسبت به دادههای آموزشی کمینه شود.
اگر مدل بتواند کاملاً توزیع دادههای آموزشی را یاد بگیرد:
توزیع مدل

با توزیع واقعی

یکسان میشود. در این حالت واگرایی KL توزیع Q نسبت به P برابر با صفر خواهد بود.
در نتیجه:

و بنابراین:

یعنی Cross Entropy مدل دقیقاً برابر با آنتروپی واقعی دادههای آموزشی میشود.
میتوان Cross Entropy مدل را اینطور در نظر گرفت:
تخمینی از آنتروپی واقعی دادههای آموزشی که توسط مدل محاسبه میشود.
هرچه مدل بهتر توزیع دادهها را یاد بگیرد، Cross Entropy به آنتروپی واقعی نزدیکتر میشود.
بیت بر کاراکتر (Bits‑per‑Character) و بیت بر بایت (Bits‑per‑Byte)
یکی از واحدهای آنتروپی و آنتروپی متقاطع بیت (bits) است. اگر آنتروپی متقاطع یک مدل زبانی ۶ بیت باشد، این مدل برای نمایش هر توکن به ۶ بیت نیاز دارد.
از آنجا که مدلهای مختلف از روشهای توکنسازی متفاوتی استفاده میکنند—برای مثال یک مدل کلمات را بهعنوان توکن استفاده میکند و مدل دیگر کاراکترها را—بنابراین تعداد بیت به ازای هر توکن بین مدلها قابل مقایسه نیست. به همین دلیل برخی به جای آن از معیار بیت بر کاراکتر (BPC) استفاده میکنند. اگر تعداد بیت به ازای هر توکن ۶ باشد و به طور میانگین هر توکن از ۲ کاراکتر تشکیل شده باشد، آنگاه:

یکی از پیچیدگیهای BPC ناشی از طرحهای مختلف کدگذاری کاراکتر است. برای مثال، در ASCII هر کاراکتر با ۷ بیت کدگذاری میشود، اما در UTF‑8 یک کاراکتر میتواند با ۸ تا ۳۲ بیت کدگذاری شود. یک معیار استانداردتر میتواند بیت بر بایت (BPB) باشد، یعنی تعداد بیتهایی که یک مدل زبانی برای نمایش یک بایت از داده آموزشی اصلی نیاز دارد.
اگر BPC برابر ۳ باشد و هر کاراکتر ۷ بیت (یا 7/8 بایت) باشد، آنگاه:

آنتروپی متقاطع به ما میگوید یک مدل زبانی تا چه اندازه در فشردهسازی متن کارآمد است. اگر BPB یک مدل زبانی ۳٫۴۳ باشد، یعنی این مدل میتواند هر بایت اصلی (۸ بیت) را با ۳٫۴۳ بیت نمایش دهد. در نتیجه این مدل میتواند متن آموزشی اصلی را به کمتر از نصف اندازه اولیه آن فشرده کند.
پرپلکسیتی (Perplexity)
پرپلکسیتی نمایی (exponential) از آنتروپی و آنتروپی متقاطع است و معمولاً به صورت PPL نوشته میشود. اگر مجموعهدادهای با توزیع واقعی P داشته باشیم، پرپلکسیتی آن به صورت زیر تعریف میشود:

پرپلکسیتی یک مدل زبانی (با توزیع یادگرفتهشده Q) روی یک مجموعهداده به صورت زیر تعریف میشود:

اگر آنتروپی متقاطع اندازه بگیرد که پیشبینی توکن بعدی برای مدل چقدر دشوار است، پرپلکسیتی میزان عدم قطعیت مدل هنگام پیشبینی توکن بعدی را اندازه میگیرد. عدم قطعیت بیشتر یعنی گزینههای ممکن بیشتری برای توکن بعدی وجود دارد.
یک مدل زبانی را در نظر بگیرید که برای کدگذاری ۴ توکن موقعیت (مطابق شکل 3‑4(b)) بهطور کامل آموزش دیده است. آنتروپی متقاطع این مدل ۲ بیت است. اگر این مدل بخواهد موقعیتی در مربع را پیشبینی کند، باید از میان:

گزینه ممکن انتخاب کند. بنابراین پرپلکسیتی این مدل ۴ خواهد بود.
تا اینجا از بیت بهعنوان واحد آنتروپی و آنتروپی متقاطع استفاده شد. هر بیت میتواند ۲ مقدار متمایز را نمایش دهد، به همین دلیل در فرمول پرپلکسیتی بالا پایه ۲ استفاده شده است.
با این حال، چارچوبهای رایج یادگیری ماشین مانند TensorFlow و PyTorch از واحد nat (بر اساس لگاریتم طبیعی) برای آنتروپی و آنتروپی متقاطع استفاده میکنند. در این حالت پایه محاسبه e (پایه لگاریتم طبیعی) است. اگر واحد nat استفاده شود، پرپلکسیتی به صورت زیر تعریف میشود:

به دلیل سردرگمی میان بیت و nat، بسیاری از افراد هنگام گزارش عملکرد مدلهای زبانی، به جای آنتروپی متقاطع، پرپلکسیتی را گزارش میکنند.
همانطور که گفته شد، Cross Entropy، Perplexity، BPC و BPB همگی شکلهایی از معیارهای سنجش دقت پیشبینی مدلهای زبانی هستند. هرچه یک مدل بتواند متن را دقیقتر پیشبینی کند، مقدار این معیارها کمتر خواهد بود.
در این کتاب، پرپلکسیتی (Perplexity) بهعنوان معیار پیشفرض برای ارزیابی مدل زبانی استفاده میشود. به خاطر داشته باشید که هرچه عدم قطعیت مدل در پیشبینی توکن بعدی در یک مجموعهداده بیشتر باشد، مقدار پرپلکسیتی بالاتر خواهد بود.
اینکه چه مقدار پرپلکسیتی خوب محسوب میشود به خود دادهها و همچنین نحوه دقیق محاسبه پرپلکسیتی بستگی دارد؛ برای مثال اینکه مدل به چند توکن قبلی برای پیشبینی دسترسی دارد.
در ادامه چند قاعده کلی ارائه شده است:
دادههای ساختاریافتهتر، پرپلکسیتی کمتر است
دادههای ساختاریافتهتر قابلپیشبینیتر هستند. برای مثال، کد HTML از متن روزمره قابلپیشبینیتر است. اگر یک تگ باز HTML مانند <head> ببینید، میتوانید پیشبینی کنید که در نزدیکی آن باید یک تگ بسته مانند </head> وجود داشته باشد. بنابراین پرپلکسیتی مورد انتظار یک مدل روی کد HTML باید کمتر از پرپلکسیتی همان مدل روی متن معمولی باشد.
هرچه واژگان بزرگتر باشد، پرپلکسیتی بیشتر است
به طور شهودی، هرچه تعداد توکنهای ممکن بیشتر باشد، پیشبینی توکن بعدی برای مدل سختتر میشود. برای مثال، پرپلکسیتی یک مدل روی کتاب کودک احتمالاً کمتر از پرپلکسیتی همان مدل روی War and Peace خواهد بود.
برای یک مجموعهداده یکسان (مثلاً انگلیسی)، پرپلکسیتی مبتنی بر کاراکتر (پیشبینی کاراکتر بعدی) از پرپلکسیتی مبتنی بر کلمه (پیشبینی کلمه بعدی) کمتر خواهد بود، زیرا تعداد کاراکترهای ممکن کمتر از تعداد کلمات ممکن است.
هرچه طول کانتکست بیشتر باشد، پرپلکسیتی کمتر است
هرچه مدل زمینه (context) بیشتری داشته باشد، عدم قطعیت کمتری در پیشبینی توکن بعدی خواهد داشت. در سال ۱۹۵۱، Claude Shannon آنتروپی متقاطع مدل خود را با استفاده از پیشبینی توکن بعدی بر اساس حداکثر ۱۰ توکن قبلی ارزیابی کرد. در زمان نگارش این متن، پرپلکسیتی یک مدل معمولاً با شرط قرار دادن ۵۰۰ تا ۱۰٬۰۰۰ توکن قبلی محاسبه میشود، و حتی ممکن است بیشتر هم باشد؛ البته این مقدار توسط حداکثر طول کانتکست مدل محدود میشود.
مقادیر معمول پرپلکسیتی
برای مقایسه، دیدن مقادیر پرپلکسیتی حدود ۳ یا حتی کمتر غیرمعمول نیست. اگر در یک زبان فرضی همه توکنها احتمال برابر داشته باشند، پرپلکسیتی ۳ یعنی مدل یک شانس از سه برای پیشبینی درست توکن بعدی دارد. با توجه به اینکه اندازه واژگان مدلها معمولاً در حد دهها هزار یا صدها هزار توکن است، چنین احتمالی بسیار قابلتوجه است.
کاربردهای پرپلکسیتی
علاوه بر هدایت فرایند آموزش مدلهای زبانی، پرپلکسیتی در بخشهای مختلف جریان کاری مهندسی هوش مصنوعی نیز مفید است. نخست اینکه پرپلکسیتی میتواند نماینده خوبی از تواناییهای مدل باشد. اگر مدلی در پیشبینی توکن بعدی ضعیف باشد، احتمالاً عملکرد آن در وظایف پاییندستی (downstream tasks) نیز ضعیف خواهد بود.
گزارش GPT‑2 از OpenAI نشان میدهد که مدلهای بزرگتر (که معمولاً قدرتمندتر هم هستند) به طور پیوسته پرپلکسیتی کمتری روی مجموعهدادههای مختلف دارند. متأسفانه، با افزایش محرمانگی شرکتها درباره مدلهایشان، بسیاری از آنها دیگر مقدار پرپلکسیتی مدلهای خود را گزارش نمیکنند.

محدودیتهای پرپلکسیتی در مدلهای پسآموزشدیده
پرپلکسیتی ممکن است معیار مناسبی برای ارزیابی مدلهایی نباشد که با تکنیکهایی مانند SFT (Supervised Fine‑Tuning) و RLHF (Reinforcement Learning from Human Feedback) پسآموزش داده شدهاند.
پسآموزش مربوط به آموزش مدلها برای انجام وظایف است. هرچه مدل در انجام وظایف بهتر شود، ممکن است در پیشبینی توکنهای بعدی ضعیفتر عمل کند. پریپلکسیتی یک مدل زبانی معمولاً پس از پسآموزش افزایش مییابد. برخی میگویند که پسآموزش آنتروپی را کاهش میدهد. به طور مشابه، کوانتیزاسیون (quantization) (کاهش دقت عددی مدل و در نتیجه کاهش حجم حافظه مصرفی) نیز میتواند پریپلکسیتی مدل را به روشهای غیرمنتظرهای تغییر دهد.
پریپلکسیتی (Perplexity) یک مدل نسبت به یک متن، میزان دشواری پیشبینی آن متن توسط مدل را اندازهگیری میکند. برای یک مدل مشخص، پریپلکسیتی برای متونی که مدل در طول آموزش دیده و به خاطر سپرده است، کمترین مقدار را دارد. بنابراین، از پریپلکسیتی میتوان برای تشخیص اینکه آیا یک متن در دادههای آموزشی مدل وجود داشته است یا خیر، استفاده کرد. این کار برای تشخیص آلودگی دادهها (Data Contamination) مفید است — اگر پریپلکسیتی مدل روی دادههای یک معیار سنجش (Benchmark) پایین باشد، احتمالاً آن معیار سنجش در دادههای آموزشی مدل گنجانده شده است و این موضوع عملکرد مدل روی آن معیار سنجش را کمتر قابل اعتماد میکند. همچنین میتوان از این روش برای حذف دادههای تکراری (Deduplication) در آموزش استفاده کرد: مثلاً دادههای جدید را تنها در صورتی به مجموعه دادههای آموزشی موجود اضافه کنید که پریپلکسیتی آنها بالا باشد.
پریپلکسیتی برای متون غیرقابل پیشبینی، مانند متونی که ایدههای غیرمعمول را بیان میکنند (مثل :my dog teaches quantum physics in his free time) یا متون بیمعنی (Gibberish) (مثل: home cat go eye)، بالاترین مقدار را دارد. بنابراین، از پریپلکسیتی میتوان برای تشخیص متون غیرعادی (Abnormal Texts) استفاده کرد.
پریپلکسیتی و معیارهای مرتبط با آن به ما کمک میکنند تا عملکرد مدل زبانی پایه (Underlying Language Model) را درک کنیم، که این خود نمایانگر (Proxy) عملکرد مدل در وظایف بعدی (Downstream Tasks) است. باقی فصل به چگونگی اندازهگیری مستقیم عملکرد مدل در وظایف بعدی میپردازد.

نحوه استفاده از یک مدل زبانی برای محاسبه پرپلکسی یک متن (How to Use a Language Model to Compute a Text’s Perplexity)
پرپلکسی یک مدل نسبت به یک متن نشان میدهد که پیشبینی آن متن برای مدل چقدر دشوار است. فرض کنید یک مدل زبانی X و یک دنباله از توکنها به صورت زیر داریم:
x₁, x₂, …, xₙ
پرپلکسی مدل X برای این دنباله به صورت زیر تعریف میشود:

که میتوان آن را به شکل دیگر نیز نوشت:

در این رابطه،

نشاندهندهی احتمالی است که مدل زبانی برای توکن

با در نظر گرفتن توکنهای قبلی

تا

اختصاص میدهد.
برای محاسبهی پرپلکسی باید به احتمالها یا logprobهایی که مدل زبانی به هر توکن بعدی اختصاص میدهد دسترسی داشته باشید. متأسفانه همهی مدلهای تجاری این logprobها را در دسترس کاربر قرار نمیدهند؛ همانطور که در فصل ۲ توضیح داده شده است.
هنگام ارزیابی عملکرد مدلها، مهم است که بین ارزیابی دقیق (Exact Evaluation) و ارزیابی ذهنی (Subjective Evaluation) تمایز قائل شویم. ارزیابی دقیق، قضاوتی بدون ابهام تولید میکند. به عنوان مثال، اگر پاسخ یک سوال چندگزینهای A باشد و شما گزینه B را انتخاب کنید، پاسخ شما اشتباه است. هیچ ابهامی در این مورد وجود ندارد. از طرف دیگر، نمرهدهی به یک انشا ذهنی است. نمره یک انشا به فردی که آن را تصحیح میکند بستگی دارد. حتی یک فرد واحد، اگر در دو زمان مختلف از او خواسته شود، ممکن است به یک انشای واحد نمرههای متفاوتی بدهد. نمرهدهی به انشا میتواند با وجود دستورالعملهای نمرهدهی واضح، دقیقتر شود. همانطور که در بخش بعدی خواهید دید، استفاده از هوش مصنوعی به عنوان داور (AI as a Judge) ذهنی است. نتیجه ارزیابی میتواند بر اساس مدل داور و دستورالعمل (Prompt) تغییر کند.
من دو رویکرد ارزیابی که نمرات دقیق تولید میکنند را پوشش خواهم داد: درستی عملکردی (Functional Correctness) و اندازهگیری شباهت (Similarity Measurements) در برابر دادههای مرجع. توجه داشته باشید که این بخش بر ارزیابی پاسخهای باز (تولید متن دلخواه) متمرکز است، در مقابل پاسخهای بسته (مانند طبقهبندی). این به این دلیل نیست که مدلهای پایه برای وظایف بسته استفاده نمیشوند. در واقع، بسیاری از سیستمهای مبتنی بر مدل پایه حداقل یک مؤلفه طبقهبندی دارند، معمولاً برای طبقهبندی قصد (Intent Classification) یا امتیازدهی. این بخش بر ارزیابی باز متمرکز است زیرا ارزیابی بسته به خوبی درک شده است.
ارزیابی درستی عملکردی به معنای ارزیابی یک سیستم بر اساس این است که آیا عملکرد مورد نظر را انجام میدهد یا خیر. به عنوان مثال، اگر از یک مدل بخواهید یک وبسایت ایجاد کند، آیا وبسایت تولید شده نیازمندیهای شما را برآورده میکند؟ اگر از یک مدل بخواهید در یک رستوران خاص رزرو انجام دهد، آیا مدل موفق میشود؟
درستی عملکردی معیار نهایی برای ارزیابی عملکرد هر برنامه کاربردی است، زیرا اندازهگیری میکند که آیا برنامه شما کاری را که قرار است انجام دهد، انجام میدهد یا خیر. با این حال، اندازهگیری درستی عملکردی همیشه سرراست نیست و اندازهگیری آن به راحتی قابل خودکارسازی نیست.
تولید کد (Code Generation) نمونهای از یک وظیفه است که در آن اندازهگیری درستی عملکردی میتواند خودکار شود. درستی عملکردی در کدنویسی گاهی دقت اجرا (Execution Accuracy) نامیده میشود. فرض کنید از مدل میخواهید یک تابع پایتون به نام gcd(num1, num2) بنویسد تا بزرگترین مقسومعلیه مشترک (gcd) دو عدد num1 و num2 را پیدا کند. کد تولید شده سپس میتواند در یک مفسر پایتون وارد شود تا بررسی شود که آیا کد معتبر است و اگر هست، آیا خروجی صحیح را برای یک جفت داده شده (num1, num2) تولید میکند یا خیر. به عنوان مثال، برای جفت (num1=15, num2=20)، اگر تابع gcd(15, 20) مقدار ۵ (پاسخ صحیح) را برنگرداند، میدانید که تابع اشتباه است.
مدتها قبل از اینکه هوش مصنوعی برای نوشتن کد استفاده شود، تأیید خودکار درستی عملکردی کد یک روش استاندارد در مهندسی نرمافزار بود. کد معمولاً با تست واحد (Unit Tests) اعتبارسنجی میشود، جایی که کد در سناریوهای مختلف اجرا میشود تا اطمینان حاصل شود که خروجیهای مورد انتظار را تولید میکند. ارزیابی درستی عملکردی همان روشی است که پلتفرمهای کدنویسی مانند LeetCode و HackerRank راهحلهای ارسال شده را تأیید میکنند.
معیارهای سنجش محبوب برای ارزیابی قابلیتهای تولید کد هوش مصنوعی، مانند HumanEval شرکت OpenAI و MBPP (Mostly Basic Python Problems Dataset) شرکت گوگل، از درستی عملکردی به عنوان معیار خود استفاده میکنند. معیارهای سنجش برای متن به SQL (Text-to-SQL) (تولید پرسوجوهای SQL از زبان طبیعی) مانند Spider (Yu et al., 2018)، BIRD-SQL (Big Bench for Large-scale Database Grounded Text-to-SQL Evaluation) (Li et al., 2023) و WikiSQL (Zhong, et al., 2017) نیز بر درستی عملکردی تکیه دارند.
یک مسئله در معیار سنجش همراه با مجموعهای از موارد آزمون (Test Cases) ارائه میشود. هر مورد آزمون شامل یک سناریو که کد باید در آن اجرا شود و خروجی مورد انتظار برای آن سناریو است. در ادامه یک مثال از یک مسئله و موارد آزمون آن در HumanEval آورده شده است:
مسئله:
from typing import List
def has_close_elements(numbers: List[float], threshold: float) -> bool::
بررسی کنید که آیا در لیست داده شده از اعداد، هر دو عددی وجود دارند که فاصله آنها از هم کمتر از آستانه داده شده باشد.
def has_close_elements(numbers: List[float], threshold: float) -> bool:
""" Check if in given list of numbers, are any two numbers closer to each
other than given threshold.
>>> has_close_elements([1.0, 2.0, 3.0], 0.5) False
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3) True
"""
Test cases (each assert statement represents a test case)
def check(candidate):
assert candidate([1.0, 2.0, 3.9, 4.0, 5.0, 2.2], 0.3) == True
assert candidate([1.0, 2.0, 3.9, 4.0, 5.0, 2.2], 0.05) == False
assert candidate([1.0, 2.0, 5.9, 4.0, 5.0], 0.95) == True
assert candidate([1.0, 2.0, 5.9, 4.0, 5.0], 0.8) == False
assert candidate([1.0, 2.0, 3.0, 4.0, 5.0, 2.0], 0.1) == True
assert candidate([1.1, 2.2, 3.1, 4.1, 5.1], 1.0) == True
assert candidate([1.1, 2.2, 3.1, 4.1, 5.1], 0.5) == False
هنگام ارزیابی یک مدل، برای هر مسئله تعدادی نمونه کد (که با K نشان داده میشود) تولید میشود. یک مدل یک مسئله را حل میکند اگر هر یک از K نمونه کدی که تولید کرده است، همه موارد آزمون (Test Cases) آن مسئله را پاس کند. امتیاز نهایی، که pass@k نامیده میشود، نسبت مسائل حل شده به کل مسائل است. اگر ۱۰ مسئله وجود داشته باشد و یک مدل با K=3
، ۵ مسئله را حل کند، آنگاه امتیاز pass@3 آن مدل ۵۰٪ است. هرچه مدل نمونههای کد بیشتری تولید کند، شانس بیشتری برای حل هر مسئله دارد و در نتیجه امتیاز نهایی بالاتر خواهد بود. این بدان معناست که به طور انتظاری، امتیاز pass@1 باید کمتر از pass@3 باشد و آن نیز به نوبه خود کمتر از pass@10 باشد.
دسته دیگری از وظایف که درستی عملکردی آنها را میتوان به طور خودکار ارزیابی کرد، رباتهای بازی (Game Bots) هستند. اگر یک ربات برای بازی تتریس ایجاد کنید، میتوانید با توجه به امتیازی که کسب میکند، کیفیت آن را ارزیابی کنید. وظایفی که اهداف قابل اندازهگیری دارند، معمولاً با استفاده از درستی عملکردی قابل ارزیابی هستند. به عنوان مثال، اگر از هوش مصنوعی بخواهید بارهای کاری شما را برای بهینهسازی مصرف انرژی برنامهریزی کند، عملکرد هوش مصنوعی را میتوان با میزان انرژیای که ذخیره میکند اندازهگیری کرد.
اگر وظیفهای که به آن اهمیت میدهید نتواند به طور خودکار با استفاده از درستی عملکردی (Functional Correctness) ارزیابی شود، یک رویکرد رایج، ارزیابی خروجیهای هوش مصنوعی در برابر دادههای مرجع (Reference Data) است. به عنوان مثال، اگر از یک مدل بخواهید جملهای را از فرانسوی به انگلیسی ترجمه کند، میتوانید ترجمه انگلیسی تولید شده را با ترجمه انگلیسی صحیح مقایسه کنید.
هر نمونه در دادههای مرجع از قالب (ورودی، پاسخهای مرجع) پیروی میکند. یک ورودی میتواند چندین پاسخ مرجع داشته باشد، مانند چندین ترجمه انگلیسی ممکن از یک جمله فرانسوی. پاسخهای مرجع همچنین به عنوان دادههای پایه (Ground Truths) یا پاسخهای استاندارد (Canonical Responses) شناخته میشوند.
معیارهایی که به مرجع نیاز دارند، معیارهای مبتنی بر مرجع (Reference-based) نامیده میشوند و معیارهایی که نیازی به مرجع ندارند، معیارهای بدون مرجع (Reference-free) هستند.
از آنجایی که این رویکرد ارزیابی به دادههای مرجع نیاز دارد، محدودیت اصلی آن در میزان و سرعت تولید دادههای مرجع است. دادههای مرجع معمولاً توسط انسانها و به طور فزایندهای توسط هوش مصنوعی تولید میشوند. استفاده از دادههای تولید شده توسط انسان به عنوان مرجع به این معناست که عملکرد انسان را به عنوان استاندارد طلایی (Gold Standard) در نظر میگیریم و عملکرد هوش مصنوعی در برابر عملکرد انسان سنجیده میشود.
تولید دادههای مرجع توسط انسان میتواند پرهزینه و زمانبر باشد، که باعث شده بسیاری به جای آن از هوش مصنوعی برای تولید دادههای مرجع استفاده کنند. دادههای تولید شده توسط هوش مصنوعی ممکن است همچنان نیاز به بررسی توسط انسان داشته باشند، اما نیروی کار مورد نیاز برای بررسی آن بسیار کمتر از نیروی کار مورد نیاز برای تولید دادههای مرجع از ابتدا است.
پاسخهای تولید شده که شباهت بیشتری به پاسخهای مرجع دارند، بهتر در نظر گرفته میشوند. چهار روش برای اندازهگیری شباهت بین دو متن باز (Open-ended) وجود دارد:
درخواست از یک ارزیاب (Evaluator) برای قضاوت در مورد اینکه آیا دو متن یکسان هستند یا خیر.
تطابق دقیق (Exact Match): بررسی اینکه آیا پاسخ تولید شده دقیقاً با یکی از پاسخهای مرجع مطابقت دارد یا خیر.
شباهت واژگانی (Lexical Similarity): بررسی میزان شباهت ظاهری پاسخ تولید شده به پاسخهای مرجع (در سطح کلمات و ساختار).
شباهت معنایی (Semantic Similarity): بررسی میزان نزدیکی معنایی پاسخ تولید شده به پاسخهای مرجع.
دو پاسخ را میتوان توسط ارزیابهای انسانی (Human Evaluators) یا ارزیابهای هوش مصنوعی (AI Evaluators) مقایسه کرد. ارزیابهای هوش مصنوعی به طور فزایندهای رایج شدهاند و تمرکز بخش بعدی خواهد بود.
این بخش بر روی معیارهای طراحی شده دستی (Hand-designed Metrics) متمرکز است: تطابق دقیق، شباهت واژگانی و شباهت معنایی. نمرات حاصل از تطابق دقیق دودویی هستند (مطابقت دارد یا ندارد)، در حالی که دو مورد دیگر در یک مقیاس پیوسته (مانند بین ۰ و ۱ یا بین ۱- و ۱) قرار میگیرند.
علیرغم سهولت استفاده و انعطافپذیری رویکرد هوش مصنوعی به عنوان داور (AI as a Judge)، اندازهگیریهای شباهت طراحی شده دستی به دلیل ماهیت دقیق و قطعی خود، همچنان به طور گسترده در صنعت مورد استفاده قرار میگیرند.
این بخش در مورد چگونگی استفاده از اندازهگیریهای شباهت برای ارزیابی کیفیت یک خروجی تولید شده بحث میکند. با این حال، میتوان از اندازهگیریهای شباهت برای بسیاری از موارد استفاده دیگر نیز بهره برد، از جمله (اما نه محدود به) موارد زیر:
بازیابی و جستجو (Retrieval and Search): یافتن موارد مشابه یک پرسوجو.
رتبهبندی (Ranking): رتبهبندی موارد بر اساس میزان شباهت آنها به یک پرسوجو.
خوشهبندی (Clustering): گروهبندی موارد بر اساس میزان شباهت آنها به یکدیگر.
تشخیص ناهنجاری (Anomaly Detection): شناسایی مواردی که کمترین شباهت را به بقیه دارند.
حذف دادههای تکراری (Data Deduplication): حذف مواردی که بیش از حد به موارد دیگر شبیه هستند.
تکنیکهای مورد بحث در این بخش در سراسر کتاب مجدداً مورد استفاده قرار خواهند گرفت.
تطابق دقیق (Exact Match)
یک تطابق دقیق در نظر گرفته میشود اگر پاسخ تولید شده دقیقاً با یکی از پاسخهای مرجع مطابقت داشته باشد. تطابق دقیق برای وظایفی مناسب است که انتظار پاسخهای کوتاه و دقیق را دارند، مانند مسائل ساده ریاضی، پرسوجوهای دانش عمومی و سوالات سبک اطلاعات عمومی.
در زیر نمونههایی از ورودیهایی که پاسخهای کوتاه و دقیق دارند آورده شده است:
“حاصل ۲ + ۳ چیست؟”
“اولین زنی که برنده جایزه نوبل شد چه کسی بود؟”
“موجودی حساب جاری من چقدر است؟”
“جاهای خالی را پر کنید: پاریس برای فرانسه مانند ___ برای انگلستان است.”
تغییرات در تطابق (Variations in Matching)
تغییراتی در تطابق وجود دارد که مسائل قالببندی را در نظر میگیرد. یک تغییر این است که هر خروجیای که پاسخ مرجع را در خود داشته باشد به عنوان تطابق پذیرفته شود. به عنوان مثال، برای سوال “حاصل ۲ + ۳ چیست؟” پاسخ مرجع “۵” است. این تغییر، تمام خروجیهایی که شامل “۵” باشند را میپذیرد، از جمله “جواب ۵ است” و “۲ + ۳ برابر با ۵ است”.
با این حال، این تغییر (پذیرش خروجیهای حاوی پاسخ مرجع) گاهی میتواند منجر به پذیرش پاسخ اشتباه شود. به عنوان مثال، برای سوال “آنه فرانک در چه سالی متولد شد؟” آنه فرانک در ۱۲ ژوئن ۱۹۲۹ متولد شد، بنابراین پاسخ صحیح ۱۹۲۹ است. اگر مدل خروجی “۱۲ سپتامبر ۱۹۲۹” را تولید کند، سال صحیح در خروجی گنجانده شده است، اما خروجی از نظر واقعی اشتباه است.
محدودیتهای تطابق دقیق
فراتر از وظایف ساده، تطابق دقیق به ندرت کار میکند. با توجه به جمله اصلی فرانسوی “Comment ça va?”، چندین ترجمه انگلیسی ممکن وجود دارد، مانند “How are you?”، “How is everything?” و “How are you doing?”. اگر دادههای مرجع فقط شامل این سه ترجمه باشند و یک مدل “How is it going?” را تولید کند، پاسخ مدل به عنوان اشتباه علامتگذاری میشود. هرچه متن اصلی طولانیتر و پیچیدهتر باشد، ترجمههای ممکن بیشتری وجود خواهد داشت. ایجاد یک مجموعه جامع از پاسخهای ممکن برای یک ورودی غیرممکن است.
برای وظایف پیچیده، شباهت واژگانی و شباهت معنایی جایگزینهای مناسبتری هستند.
شباهت واژگانی (Lexical Similarity)
شباهت واژگانی میزان همپوشانی دو متن را اندازهگیری میکند. برای این کار ابتدا هر متن به توکنهای (Tokens) کوچکتری تقسیم میشود.
در سادهترین شکل، شباهت واژگانی را میتوان با شمارش تعداد توکنهای مشترک بین دو متن اندازه گرفت. به عنوان مثال، پاسخ مرجع “My cats scare the mice” و دو پاسخ تولید شده زیر را در نظر بگیرید:
پاسخ A: “My cats eat the mice”
پاسخ B: “Cats and mice fight all the time”
فرض کنید هر توکن یک کلمه است. اگر فقط همپوشانی کلمات منفرد را بشمارید، پاسخ A شامل ۴ کلمه از ۵ کلمه پاسخ مرجع است (امتیاز شباهت ۸۰٪)، در حالی که پاسخ B فقط شامل ۳ کلمه از ۵ کلمه است (امتیاز شباهت ۶۰٪). بنابراین، پاسخ A مشابهتر به پاسخ مرجع در نظر گرفته میشود.
تطابق تقریبی رشته (Approximate String Matching)
یکی از راههای اندازهگیری شباهت واژگانی، تطابق تقریبی رشته است که به طور عامیانه تطابق فازی (Fuzzy Matching) نامیده میشود. این روش شباهت بین دو متن را با شمارش تعداد ویرایشهای (Edits) مورد نیاز برای تبدیل یک متن به متن دیگر اندازهگیری میکند. این عدد فاصله ویرایش (Edit Distance) نامیده میشود. سه عمل ویرایش معمول عبارتند از:
حذف (Deletion): “brad” -> “bad”
درج (Insertion): “bad” -> “bard”
جایگزینی (Substitution): “bad” -> “bed”
برخی تطابقدهندههای فازی، جابجایی (Transposition) یعنی تعویض دو حرف (مثلاً “mats” -> “mast”) را نیز به عنوان یک ویرایش در نظر میگیرند. با این حال، برخی دیگر هر جابجایی را معادل دو عمل ویرایش (یک حذف و یک درج) در نظر میگیرند.
برای مثال، تبدیل “bad” به “bard” نیازمند یک ویرایش (درج حرف ‘r’) است، در حالی که تبدیل “bad” به “cash” نیازمند سه ویرایش است (جایگزینی ‘b’ با ‘c’، جایگزینی ‘a’ با ‘a’ (بدون تغییر)، و جایگزینی ‘d’ با ‘sh’)*. بنابراین، “bad” به “bard” شباهت بیشتری دارد تا به “cash”.
روش دیگر برای اندازهگیری شباهت واژگانی، شباهت n-gram است که بر اساس همپوشانی دنبالهای از توکنها (n-gram) به جای توکنهای منفرد اندازهگیری میشود. یک 1-gram (unigram) یک توکن است. یک 2-gram (bigram) مجموعهای از دو توکن است. عبارت “My cats scare the mice” از چهار bigram تشکیل شده است: “my cats”، “cats scare”، “scare the”، و “the mice”. شما درصد n-gramهای موجود در پاسخهای مرجع که در پاسخ تولید شده نیز وجود دارند را اندازهگیری میکنید.
معیارهای رایج برای شباهت واژگانی عبارتند از: BLEU، ROUGE، METEOR++، TER، و CIDEr. تفاوت آنها در نحوه دقیق محاسبه همپوشانی است. قبل از ظهور مدلهای پایه (foundation models)، BLEU، ROUGE و مشتقات آنها رایج بودند، به ویژه برای وظایف ترجمه. از زمان ظهور مدلهای پایه، تعداد معیارهای سنجش (benchmarks) کمتری از شباهت واژگانی استفاده میکنند. نمونههایی از معیارهای سنجش که از این متریکها استفاده میکنند عبارتند از: WMT، COCO Captions، و GEMv2.
معایب این روش
یک اشکال این روش این است که نیاز به گردآوری یک مجموعه جامع از پاسخهای مرجع دارد. یک پاسخ خوب ممکن است امتیاز شباهت پایینی دریافت کند اگر مجموعه مرجع حاوی هیچ پاسخی شبیه به آن نباشد. در برخی نمونههای معیار سنجش، شرکت Adept دریافت که مدل Fuyu عملکرد ضعیفی داشت نه به این دلیل که خروجیهای مدل اشتباه بودند، بلکه به این دلیل که برخی پاسخهای صحیح در دادههای مرجع وجود نداشتند. شکل ۳-۵ نمونهای از یک وظیفه تولید عنوان برای تصویر را نشان میدهد که در آن Fuyu یک عنوان صحیح تولید کرد اما امتیاز پایینی دریافت کرد.
علاوه بر این، خود پاسخهای مرجع میتوانند اشتباه باشند. به عنوان مثال، برگزارکنندگان وظیفه مشترک WMT 2023 Metrics که بر بررسی معیارهای ارزیابی برای ترجمه ماشینی تمرکز دارد، گزارش کردند که بسیاری از ترجمههای مرجع بد را در دادههای خود یافتند. دادههای مرجع با کیفیت پایین یکی از دلایلی است که معیارهای بدون مرجع (reference-free metrics) رقبای قدرتمندی برای معیارهای مبتنی بر مرجع از نظر همبستگی با قضاوت انسانی بودند (Freitag و همکاران، ۲۰۲۳).
اشکال دیگر این روش اندازهگیری این است که امتیازهای بالاتر شباهت واژگانی همیشه به معنای پاسخهای بهتر نیستند. به عنوان مثال، در HumanEval (یک معیار سنجش برای تولید کد)، OpenAI دریافت که امتیازهای BLEU برای راهحلهای نادرست و صحیح مشابه بودند. این نشان میدهد که بهینهسازی برای امتیازهای BLEU با بهینهسازی برای درستی عملکردی (functional correctness) یکسان نیست (Chen و همکاران، ۲۰۲۱).

شباهت معنایی (Semantic Similarity)
شباهت واژگانی اندازهگیری میکند که آیا دو متن شبیه به نظر میرسند یا خیر، نه اینکه آیا معنای یکسانی دارند. دو جمله “What’s up?” و “How are you?” را در نظر بگیرید. از نظر واژگانی، آنها متفاوت هستند — همپوشانی کمی در کلمات و حروف استفادهشده وجود دارد. با این حال، از نظر معنایی، آنها به هم نزدیک هستند. برعکس، متون با ظاهر مشابه میتوانند معانی بسیار متفاوتی داشته باشند. “بیا غذا بخوریم، مادربزرگ” و “بیا مادربزرگ را بخوریم” دو معنای کاملاً متفاوت دارند.
شباهت معنایی هدفش محاسبه شباهت در معنا است. این کار ابتدا نیازمند تبدیل متن به یک نمایش عددی است که امبدینگ (Embedding) نامیده میشود. برای مثال، جمله “the cat sits on a mat” ممکن است با استفاده از یک امبدینگ که به شکل زیر است نمایش داده شود:

بنابراین، شباهت معنایی شباهت امبدینگ (Embedding Similarity) نیز نامیده میشود.
بخش “مقدمهای بر امبدینگ” در صفحه ۱۳۴ نحوه عملکرد امبدینگها را توضیح میدهد. فعلاً فرض کنید راهی برای تبدیل متون به امبدینگ دارید. شباهت بین دو امبدینگ را میتوان با استفاده از معیارهایی مانند شباهت کسینوسی (Cosine Similarity) محاسبه کرد. دو امبدینگ که دقیقاً یکسان باشند، امتیاز شباهت ۱ دارند. دو امبدینگ متضاد، امتیاز شباهت ۱- دارند.
من از مثالهای متنی استفاده میکنم، اما شباهت معنایی را میتوان برای امبدینگهای هر نوع دادهای، از جمله تصاویر و صوت، محاسبه کرد. شباهت معنایی برای متن گاهی شباهت معنایی متنی (Semantic Textual Similarity) نامیده میشود.
نکته: اگرچه من شباهت معنایی را در دسته ارزیابی دقیق قرار دادهام، میتوان آن را ذهنی در نظر گرفت، زیرا الگوریتمهای امبدینگ مختلف میتوانند امبدینگهای متفاوتی تولید کنند. با این حال، با داشتن دو امبدینگ، امتیاز شباهت بین آنها به طور دقیق محاسبه میشود.
محاسبه ریاضی
از نظر ریاضی، فرض کنید A یک امبدینگ از پاسخ تولید شده و B یک امبدینگ از یک پاسخ مرجع باشد. شباهت کسینوسی بین A و B به صورت زیر محاسبه میشود:

که در آن: A*B حاصل ضرب داخلی (Dot Product) A و B است.

نرم اقلیدسی (Euclidean norm) یا نرم

بردار A است. اگر

باشد، آنگاه:

معیارهای شباهت معنایی متنی شامل BERTScore (امبدینگها توسط BERT تولید میشوند) و MoverScore (امبدینگها توسط ترکیبی از الگوریتمها تولید میشوند) هستند.
مزایا و معایب
شباهت معنایی متنی به مجموعهای از پاسخهای مرجع به جامعیِ شباهت واژگانی نیاز ندارد. با این حال، قابلیت اطمینان شباهت معنایی به کیفیت الگوریتم امبدینگ زیربنایی بستگی دارد. دو متن با معنای یکسان همچنان میتوانند امتیاز شباهت معنایی پایینی داشته باشند اگر امبدینگهای آنها بد باشند.
عیب دیگر این روش اندازهگیری این است که الگوریتم امبدینگ زیربنایی ممکن است نیاز به محاسبات و زمان قابل توجهی برای اجرا داشته باشد.
قبل از حرکت به بحث هوش مصنوعی به عنوان داور، اجازه دهید یک معرفی سریع از امبدینگ ارائه دهیم. مفهوم امبدینگ در قلب شباهت معنایی قرار دارد و ستون فقرات بسیاری از موضوعاتی است که در سراسر کتاب بررسی میکنیم، از جمله جستجوی برداری (Vector Search) در فصل ۶ و حذف دادههای تکراری (Data Deduplication) در فصل ۸.
از انجا که کامپیوترها با عددها کار می کنند، یک مدل باید ورودی خود را به نمایش های عددی تبدیل کند تا کامپیوتر بتواند ان را پردازش کند. امبدینگ یک نمایش عددی است که تلاش می کند معنای داده اصلی را حفظ کند.
امبدینگ در واقع یک بردار عددی است. برای مثال جمله the cat sits on a mat ممکن است با یک بردار امبدینگ مانند زیر نمایش داده شود:
[0.11, 0.02, 0.54]
در اینجا برای مثال از یک بردار کوچک استفاده شده است. در عمل، اندازه بردار امبدینگ یا همان تعداد عناصر داخل بردار معمولا بین 100 تا 10000 عدد است.
مدل هایی که به طور خاص برای تولید امبدینگ اموزش داده شده اند شامل مدل های متن باز مانند BERT، CLIP (Contrastive Language–Image Pre-training) و Sentence Transformers هستند. همچنین مدل های امبدینگ اختصاصی نیز وجود دارند که از طریق API ارائه می شوند.
در جدول 3-2 اندازه امبدینگ در برخی از مدل های رایج نشان داده شده است.

از آنجا که مدلها معمولا نیاز دارند ورودی خود را ابتدا به بردارهای عددی تبدیل کنند، بسیاری از مدلهای یادگیری ماشین از جمله GPT و Llama نیز مرحلهای برای تولید امبدینگ دارند.
در بخش «ساختار ترنسفورمر» به تصویر لایه امبدینگ در یک مدل ترنسفورمر اشاره شده است.
اگر به لایههای میانی این مدلها دسترسی داشته باشید، میتوانید برای استخراج امبدینگ از آنها استفاده کنید. اما باید توجه کنید که کیفیت این امبدینگها معمولاً به اندازه امبدینگهایی که مدلهای تخصصی تولید میکنند، نیست.
هدف الگوریتم امبدینگ این است که امبدینگهایی تولید کند که ماهیت دادهی اصلی را در خود جای دهد. چگونه این موضوع را تأیید کنیم؟ بردار امبدینگ [0.11, 0.02, 0.54] هیچ شباهتی به متن اصلی “the cat sits on a mat” ندارد.
در سطح کلی، اگر متنهای شبیهتر دارای امبدینگهای نزدیکتر باشند (که معمولاً با شباهت کسینوسی یا معیارهای مرتبط اندازهگیری میشود)، الگوریتم امبدینگ خوب تلقی میگردد. برای مثال، امبدینگ جملهی “the cat sits on a mat” باید به امبدینگ جملهی “the dog plays on the grass” نزدیکتر باشد تا به امبدینگ جملهی “AI research is super fun”.
شما همچنین میتوانید کیفیت امبدینگها را بر اساس کاربرد آنها برای وظیفهی خودتان ارزیابی کنید. امبدینگها در وظایف متعددی استفاده میشوند، از جمله طبقهبندی، مدلسازی موضوع، سیستمهای توصیهگر و RAG. یک نمونه از بنچمارکهایی که کیفیت امبدینگ را در وظایف مختلف میسنجد، MTEB (Massive Text Embedding Benchmark) است.
من از متنها به عنوان مثال استفاده کردم، اما هر نوع دادهای میتواند نمایش امبدینگ داشته باشد. به عنوان مثال، راهکارهای تجارت الکترونیکی مانند Criteo و Coveo برای محصولات امبدینگ دارند. پینترست برای تصاویر، گرافها، پرسوجوها و حتی کاربران امبدینگ دارد.
مرز جدیدی در ایجاد امبدینگهای مشترک برای دادههای با چند وجه (چند مدالیته) وجود دارد. CLIP (Contrastive Language–Image Pre-training) یکی از اولین مدلهای مهمی بود که میتوانست دادههایی با مدالیتههای مختلف، یعنی متن و تصویر، را به فضای امبدینگ مشترک نگاشت کند. ULIP (بازنمایی یکپارچه زبان، تصاویر و ابر نقاط سهبعدی) برای ایجاد بازنماییهای یکپارچه برای متن، تصاویر و ابر نقاط سهبعدی تلاش میکند. ImageBind یادگیری یک امبدینگ مشترک در شش مدالیتهی مختلف از جمله متن، تصویر و صدا را انجام میدهد.
شکل 3-6 معماری CLIP را نمایش میدهد. CLIP با استفاده از جفتهای (تصویر، متن) آموزش میبیند. متن متناظر با یک تصویر میتواند شرح یا نظر مرتبط با آن تصویر باشد. برای هر جفت (تصویر، متن)، CLIP از یک رمزگذار متن (text encoder) برای تبدیل متن به امبدینگ متنی و یک رمزگذار تصویر (image encoder) برای تبدیل تصویر به امبدینگ تصویری استفاده میکند. سپس هر دوی این امبدینگها را به یک فضای امبدینگ مشترک تصویر میکند. هدف آموزشی این است که امبدینگ تصویر به امبدینگ متن متناظرش در این فضای مشترک نزدیک شود.

فضای امبدینگ مشترکی که می تواند داده های با مدالیته های مختلف را نمایش دهد، فضای امبدینگ چندوجهی نامیده می شود. در یک فضای امبدینگ مشترک متن و تصویر، امبدینگ یک تصویر از مردی که در حال ماهیگیری است باید به امبدینگ متن a fisherman نزدیک تر باشد تا به امبدینگ متن fashion show.
این فضای امبدینگ مشترک امکان مقایسه و ترکیب امبدینگ های مربوط به مدالیته های مختلف را فراهم می کند. برای مثال، این موضوع امکان جستجوی تصویر بر اساس متن را فراهم می کند. یعنی با داشتن یک متن، می توان تصاویری را پیدا کرد که امبدینگ ان ها به امبدینگ ان متن نزدیک تر است.
هوش مصنوعی به عنوان داور (AI as a Judge)
چالشهای ارزیابی پاسخهای باز (open‑ended) باعث شده بسیاری از تیمها دوباره به ارزیابی انسانی روی بیاورند. از آنجا که هوش مصنوعی توانسته بسیاری از کارهای پیچیده را خودکارسازی کند، این سؤال مطرح میشود:
آیا میتوان فرآیند ارزیابی را هم با هوش مصنوعی خودکار کرد؟
رویکردی که در آن هوش مصنوعی، خروجی هوش مصنوعی دیگر را ارزیابی میکند، به نام AI as a Judge یا LLM as a Judge شناخته میشود. در این روش، مدلی از هوش مصنوعی که برای ارزیابی مدلهای دیگر استفاده میشود، AI Judge نامیده میشود.
اگرچه ایده استفاده از هوش مصنوعی برای خودکارسازی ارزیابی مدتهاست وجود دارد، اما این کار فقط زمانی عملی شد که مدلهای هوش مصنوعی به اندازه کافی توانمند شدند؛ یعنی حدود سال ۲۰۲۰ با انتشار GPT‑3.
تا زمان نگارش این متن، AI as a Judge به یکی از رایجترین — و شاید رایجترین — روشها برای ارزیابی مدلهای هوش مصنوعی در محیطهای عملیاتی (production) تبدیل شده است.
بیشتر دموهای استارتاپهای ارزیابی هوش مصنوعی که در سالهای ۲۰۲۳ و ۲۰۲۴ دیده شدند، به نوعی از AI به عنوان داور استفاده میکردند. همچنین گزارش State of AI در LangChain در سال ۲۰۲۳ نشان داد که ۵۸٪ از ارزیابیها در پلتفرم آنها توسط AI Judge انجام شده است.
علاوه بر کاربرد صنعتی، AI as a Judge یک حوزه فعال پژوهشی نیز محسوب میشود.
چرا از AI به عنوان داور (AI as a Judge) استفاده میشود؟
داورهای هوش مصنوعی در مقایسه با ارزیابهای انسانی سریعتر، سادهتر برای استفاده و نسبتاً ارزانتر هستند. همچنین آنها میتوانند بدون داده مرجع (reference data) کار کنند؛ بنابراین میتوان از آنها در محیطهای production که داده مرجع در دسترس نیست استفاده کرد.
میتوانید از مدلهای هوش مصنوعی بخواهید یک خروجی را بر اساس معیارهای مختلف ارزیابی کنند، مانند:
درستی (correctness)
تکراری بودن (repetitiveness)
سمّیت یا توهینآمیز بودن (toxicity)
محتوای سالم یا مناسب (wholesomeness)
توهم (hallucinations) یا ساختن اطلاعات نادرست
و معیارهای دیگر
این شبیه زمانی است که از یک انسان میخواهید نظرش را درباره چیزی بیان کند. ممکن است بگویید: «اما همیشه نمیتوان به نظر مردم اعتماد کرد.» این درست است، و همیشه نمیتوان به قضاوتهای هوش مصنوعی هم اعتماد کرد. با این حال، چون هر مدل هوش مصنوعی در واقع نوعی تجمیع دانش و دادههای جمعی انسانها است، ممکن است قضاوتهایی ارائه دهد که تا حدی نماینده نظر جمعی باشد. با پرامپت مناسب و مدل مناسب میتوان قضاوتهای نسبتاً خوبی درباره موضوعات مختلف به دست آورد.
مطالعات نشان دادهاند که برخی AI Judgeها همبستگی بالایی با ارزیابی انسانی دارند.
برای مثال:
در سال 2023، پژوهش Zheng و همکاران نشان داد که در بنچمارک MT‑Bench میزان توافق بین GPT‑4 و انسانها 85٪ بوده است.
این مقدار حتی از میزان توافق بین خود انسانها (81٪) بیشتر بوده است.
همچنین نویسندگان AlpacaEval (Dubois و همکاران، 2023) دریافتند که داورهای هوش مصنوعی آنها همبستگی تقریباً کامل (0.98) با leaderboard چت Arena در LMSYS دارند که توسط انسانها ارزیابی میشود.
مزیت دیگر این است که هوش مصنوعی میتواند علاوه بر ارزیابی، دلیل قضاوت خود را نیز توضیح دهد. این موضوع زمانی مفید است که بخواهید نتایج ارزیابی را بررسی یا ممیزی (audit) کنید. شکل 3‑7 نمونهای از توضیح GPT‑4 درباره قضاوتش را نشان میدهد.
انعطافپذیری بالا باعث شده AI as a Judge در کاربردهای بسیار متنوعی استفاده شود، و در برخی کاربردها تنها گزینه خودکار برای ارزیابی باشد. حتی اگر قضاوتهای هوش مصنوعی به اندازه انسان دقیق نباشند، باز هم ممکن است به اندازه کافی خوب باشند تا توسعه یک سیستم را هدایت کنند و اعتماد اولیه لازم برای شروع یک پروژه را فراهم کنند.

ترجمه عکس:
این شکل نمونهای از استفاده از GPT‑4 به عنوان داور (AI Judge) را نشان میدهد.
در پرامپت از مدل خواسته شده است:
«کیفیت پاراگراف زیر را ارزیابی کن، به آن نمرهای بین 1 تا 5 بده و دلیل تصمیم خود را توضیح بده.»
سپس GPT‑4 پاسخ داده است:
· امتیاز: 4.5 از 5
و توضیح خود را در دو بخش ارائه کرده است.
نقاط قوت (Strengths):
1. وضوح (Clarity): پاراگراف بهطور واضح مشکل استفاده از معیار شباهت واژگانی را توضیح میدهد و یک مثال مشخص ارائه میکند.
2. شواهد (Evidence): از بنچمارک HumanEval و یافتههای OpenAI برای پشتیبانی از استدلال استفاده شده است.
3. اختصار (Conciseness): متن کوتاه و مستقیم است و فهم آن آسان است.
موارد قابل بهبود (Areas for Improvement):
1. جریان متن (Flow): ارتباط بین جملهها خوب است، اما اتصال بین توضیح کلی و مثال میتواند کمی قویتر باشد.
این مثال نشان میدهد که AI Judge فقط نمره نمیدهد، بلکه دلیل ارزیابی خود را نیز توضیح میدهد. این قابلیت برای تحلیل، عیبیابی و ممیزی نتایج ارزیابی بسیار مفید است.
راههای مختلفی برای استفاده از هوش مصنوعی جهت ارزیابی (judgment) وجود دارد.
برای مثال، میتوانید از هوش مصنوعی بخواهید:
کیفیت یک پاسخ را بهتنهایی ارزیابی کند (بدون هیچ داده مرجع)
پاسخ را با داده مرجع مقایسه کند
دو پاسخ را با یکدیگر مقایسه کند
در این بخش، نسخههای ساده (naive) سه نوع پرامپت مربوط به این روشها ارائه شدهاند.
۱. ارزیابی کیفیت پاسخ تنها با توجه به سؤال اصلی
“Given the following question and answer, evaluate how good the answer is
for the question. Use the score from 1 to 5.
- 1 means very bad.
- 5 means very good.
Question: [QUESTION]
Answer: [ANSWER]
Score:
این نوع ارزیابی به مدل فقط سؤال و پاسخ را میدهد و از او میخواهد تشخیص دهد پاسخ چقدر به سؤال مربوط، درست و کامل است.
۲. مقایسه یک پاسخ تولیدشده با پاسخ مرجع
در این روش، پاسخ تولیدشده با یک پاسخ مرجع (Reference Answer) مقایسه میشود تا مشخص شود آیا این دو پاسخ اساساً یکسان هستند یا نه. این روش میتواند جایگزینی برای معیارهای شباهت طراحیشده توسط انسان (مثل BLEU یا ROUGE) باشد.
نمونه پرامپت:
“Given the following question, reference answer, and generated answer,
evaluate whether this generated answer is the same as the reference answer.
Output True or False.
Question: [QUESTION]
Reference answer: [REFERENCE ANSWER]
Generated answer: [GENERATED ANSWER]”
۳. مقایسه دو پاسخ تولیدشده
در این روش، مدل دو پاسخ مختلف را مقایسه میکند و تشخیص میدهد کدام پاسخ بهتر است یا احتمالاً کاربران کدام را ترجیح میدهند.
این روش برای چند کاربرد مهم مفید است، از جمله:
تولید دادههای ترجیحی (preference data) برای همراستاسازی پس آموزش (post‑training alignment) (در فصل دوم)
استفاده در test‑time compute (در فصل دوم)
رتبهبندی مدلها با ارزیابی مقایسهای (در بخش بعدی توضیح داده خواهد شد)
نمونه پرامپت:
“Given the following question and two answers, evaluate which answer is
better. Output A or B.
Question: [QUESTION]
A: [FIRST ANSWER]
B: [SECOND ANSWER]
The better answer is:”
یک AI Judge عمومی را میتوان طوری استفاده کرد که پاسخها را بر اساس هر معیاری که بخواهید ارزیابی کند.
مثلاً: اگر در حال ساخت یک چتبات نقشآفرینی (role‑playing) هستید، ممکن است بخواهید بررسی کنید آیا پاسخ چتبات با شخصیت موردنظر سازگار است یا نه. برای مثال: «آیا این پاسخ شبیه چیزی است که گندالف میگوید؟»
اگر در حال ساخت سیستمی برای تولید تصاویر تبلیغاتی محصول هستید، ممکن است بخواهید بپرسید:
«از ۱ تا ۵، میزان قابلاعتماد بودن این محصول در تصویر چقدر است؟»
در جدول 3‑3 نمونههایی از معیارهای آماده AI as a Judge که برخی ابزارهای هوش مصنوعی ارائه میدهند نشان داده شده است.

نکته مهم این است که معیارهای AI as a Judge استاندارد نیستند. برای مثال، نمره «relevance» در Azure AI Studio ممکن است کاملاً متفاوت از نمره «relevance» در MLflow باشد.
دلیل این تفاوت این است که این امتیازها به دو عامل بستگی دارند:
مدل داور (judge model) که استفاده میشود
پرامپتی که برای ارزیابی طراحی شده است
به همین دلیل، با تکامل ابزارها و مدلها، این معیارهای داخلی نیز تغییر خواهند کرد.
نحوه پرامپت دادن به يک AI Judge شبيه پرامپت دادن به هر کاربرد ديگر هوش مصنوعي است. به طور کلي، پرامپت يک داور بايد اين موارد را به طور واضح توضيح دهد:
وظيفه اي که مدل بايد انجام دهد
مثلا اينکه مدل بايد ميزان ارتباط (relevance) بين پاسخ توليد شده و سوال را ارزيابي کند.
معيارهايي که مدل بايد بر اساس آنها ارزيابي کند
مثلا: تمرکز اصلي شما بايد بر اين باشد که تعيين کنيد آيا پاسخ توليد شده اطلاعات کافي براي پاسخ دادن به سوال داده شده، مطابق با پاسخ صحيح (ground truth)، دارد يا نه.
هرچه دستورالعمل ها دقيق تر و جزئي تر باشند، نتيجه بهتر خواهد بود.
سيستم امتيازدهي (Scoring system) که مي تواند يکي از اين موارد باشد:
طبقه بندي (Classification) مانند خوب/بد يا مرتبط/نامرتبط/خنثي
مقادير عددي گسسته (Discrete numerical values) مثل نمره از 1 تا 5
اين حالت را مي توان يک حالت خاص از طبقه بندي در نظر گرفت که در آن هر کلاس به جاي تفسير معنايي، تفسير عددي دارد.
مقادير عددي پيوسته (Continuous numerical values) مثل عددي بين 0 و 1، مثلا زماني که مي خواهيد ميزان شباهت را ارزيابي کنيد.
مدل هاي زباني معمولا با متن بهتر از اعداد کار مي کنند.
گزارش شده است که AI Judge ها با سيستم هاي طبقه بندي بهتر از سيستم هاي امتيازدهي عددي عمل مي کنند.
در سيستم هاي عددي، امتيازهاي گسسته معمولا بهتر از امتيازهاي پيوسته کار مي کنند.
بر اساس تجربه هاي عملي، هرچه بازه امتيازدهي گسسته بزرگ تر باشد، عملکرد مدل بدتر مي شود. به طور معمول، سيستم هاي امتيازدهي گسسته بين 1 تا 5 هستند.
همچنين نشان داده شده است که پرامپت هايي که مثال دارند عملکرد بهتري دارند. اگر از سيستم امتيازدهي بين 1 تا 5 استفاده مي کنيد، بهتر است نمونه هايي از پاسخ با نمره 1، 2، 3، 4 و 5 ارائه دهيد و اگر ممکن بود توضيح دهيد چرا آن پاسخ چنين نمره اي گرفته است. بهترين روش هاي پرامپت نويسي در فصل 5 بحث شده اند.
در ادامه بخشي از پرامپتي آمده که در Azure AI Studio براي معيار relevance استفاده مي شود. در اين پرامپت:
وظيفه توضيح داده شده
معيارهاي ارزيابي مشخص شده
سيستم امتيازدهي تعريف شده
يک مثال از ورودي با نمره پايين آورده شده
و توضيح داده شده چرا آن ورودي نمره پايين گرفته است
Your task is to score the relevance between a generated answer and the
question based on the ground truth answer in the range between 1 and 5,
and please also provide the scoring reason.
Your primary focus should be on determining whether the generated answer
contains sufficient information to address the given question according
to the ground truth answer. …
If the generated answer contradicts the ground truth answer, it will
receive a low score of 1-2.
For example, for the question "Is the sky blue?" the ground truth answer
is "Yes, the sky is blue." and the generated answer is "No, the sky is
not blue."
In this example, the generated answer contradicts the ground truth answer
by stating that the sky is not blue, when in fact it is blue.
This inconsistency would result in a low score of 1–2, and the reason for
the low score would reflect the contradiction between the generated
answer and the ground truth answer.
پرامپت:
وظیفه شما ارزیابی میزان ارتباط (relevance) بین پاسخ تولید شده و سوال، بر اساس پاسخ صحیح (ground truth answer) در بازه ۱ تا ۵ است. همچنین لطفاً دلیل امتیازدهی را نیز ارائه دهید.
تمرکز اصلی شما باید بر این باشد که تعیین کنید آیا پاسخ تولید شده، مطابق با پاسخ صحیح، اطلاعات کافی برای پرداختن به سوال داده شده را دارد یا خیر.… (بخش حذف شده از پرامپت)
اگر پاسخ تولید شده با پاسخ صحیح تناقض داشته باشد، نمره ۱-۲ (پایین) دریافت خواهد کرد. مثال:
سوال: «آیا آسمان آبی است؟» پاسخ صحیح: «بله، آسمان آبی است.» پاسخ تولید شده: «نه، آسمان آبی نیست.»
در این مثال، پاسخ تولید شده با پاسخ صحیح تناقض دارد، زیرا برخلاف واقعیت (آبی بودن آسمان)، بیان میکند که آسمان آبی نیست. این ناهماهنگی منجر به نمره پایین ۱-۲ میشود و دلیل نمره پایین، انعکاس تناقض بین پاسخ تولید شده و پاسخ صحیح خواهد بود.
شکل 3-8 نمونه ای از يک AI Judge را نشان مي دهد که وقتي سوال به آن داده مي شود، کيفيت يک پاسخ را ارزيابي مي کند.

يک AI Judge فقط يک مدل نيست؛ بلکه يک سيستم است که هم مدل و هم پرامپت را شامل مي شود.
اگر مدل، پرامپت يا پارامترهاي نمونه گيري (sampling parameters) مدل تغيير کنند، در واقع يک داور متفاوت به دست مي آيد.
با وجود مزاياي زياد استفاده از AI به عنوان داور، بسياري از تيم ها هنوز در به کارگيري اين روش ترديد دارند. استفاده از هوش مصنوعي براي ارزيابي هوش مصنوعي ممکن است نوعي استدلال دوراني يا تکراري به نظر برسد.
ماهیت احتمالي (probabilistic) مدل هاي هوش مصنوعي نيز باعث مي شود برخي آن را براي نقش ارزياب چندان قابل اعتماد ندانند.
علاوه بر اين، استفاده از AI به عنوان داور مي تواند هزينه و تاخير زماني (latency) قابل توجهي به يک اپليکيشن اضافه کند.
با توجه به اين محدوديت ها، بعضي تيم ها از AI as a Judge فقط به عنوان گزينه جايگزين يا اضطراري استفاده مي کنند؛ يعني زماني که راه ديگري براي ارزيابي سيستم خود ندارند، به ويژه در محيط هاي پروداکشن (production).
برای اینکه یک روش ارزیابی قابل اعتماد باشد، نتایج آن باید سازگار (consistent) باشند. با این حال، داورهای مبتنی بر هوش مصنوعی، مانند همه کاربردهای AI، ماهیت احتمالی (probabilistic) دارند.
به همین دلیل ممکن است یک داور با همان ورودی در شرایط مختلف امتیازهای متفاوتی بدهد. برای مثال:
اگر پرامپت کمی تغییر کند، نتیجه ممکن است تغییر کند.
حتی اگر همان پرامپت و همان ورودی دوباره اجرا شود، باز هم ممکن است خروجی متفاوتی تولید شود.
این ناسازگاری باعث میشود بازتولید نتایج و همچنین اعتماد به ارزیابیها دشوار شود.
البته میتوان کاری کرد که AI Judge سازگارتر عمل کند. در فصل ۲ توضیح داده شده که با تنظیم پارامترهای نمونهگیری (sampling variables) میتوان این کار را انجام داد.
همچنین پژوهش Zheng و همکاران (2023) نشان داد که قرار دادن مثالهای ارزیابی در پرامپت میتواند میزان سازگاری GPT‑4 را از ۶۵٪ به ۷۷٫۵٪ افزایش دهد.
با این حال، آنها اشاره کردند که سازگاری بالا لزوماً به معنای دقت بالا نیست. ممکن است داور فقط بهطور مداوم همان اشتباه را تکرار کند.
علاوه بر این، اضافه کردن مثالهای بیشتر باعث میشود پرامپت طولانیتر شود و پرامپتهای طولانیتر نیز هزینه استنتاج (inference cost) را افزایش میدهند. در آزمایش Zheng و همکاران، اضافه کردن مثالهای بیشتر باعث شد هزینه استفاده از GPT‑4 تقریباً چهار برابر شود.
برخلاف بسیاری از معیارهای طراحیشده توسط انسان، معیارهای AI as a Judge استاندارد مشخصی ندارند. به همین دلیل ممکن است بهراحتی بد تفسیر یا نادرست استفاده شوند.
برای مثال، ابزارهای متنباز MLflow، Ragas و LlamaIndex همگی معیار faithfulness (وفاداری به متن مرجع) را برای بررسی میزان وفاداری خروجی مدل به متن زمینه استفاده میکنند، اما دستورالعملها و سیستم امتیازدهی آنها متفاوت است.
طبق جدول 3‑4:
MLflow از سیستم امتیازدهی ۱ تا ۵ استفاده میکند.
Ragas از ۰ و ۱ استفاده میکند.
LlamaIndex از داور میخواهد YES یا NO خروجی دهد.
بنابراین حتی برای یک معیار یکسان، ابزارهای مختلف ممکن است پرامپتها و روشهای امتیازدهی کاملاً متفاوتی داشته باشند.
جدول ۳‑۴. ابزارهای مختلف میتوانند برای یک معیار یکسان، پرامپتهای پیشفرض بسیار متفاوتی داشته باشند.

امتیازهای faithfulness که این سه ابزار تولید میکنند قابل مقایسه با هم نیستند. فرض کنید برای یک جفت (context, answer):
MLflow امتیاز 3 بدهد
Ragas مقدار 1 بدهد
LlamaIndex نتیجه NO بدهد
در این صورت مشخص نیست کدام امتیاز را باید مبنا قرار داد.
یک سیستم نرمافزاری معمولاً در طول زمان تغییر و تکامل پیدا میکند، اما روش ارزیابی آن ideally باید ثابت بماند. دلیلش این است که معیارهای ارزیابی برای پایش تغییرات سیستم در طول زمان استفاده میشوند.
اما مشکل اینجاست که AI Judge خودش هم یک سیستم هوش مصنوعی است و بنابراین ممکن است در طول زمان تغییر کند.
فرض کنید ماه گذشته امتیاز coherence اپلیکیشن شما ۹۰٪ بوده و این ماه ۹۲٪ شده است. آیا این یعنی کیفیت coherence سیستم شما بهتر شده؟
پاسخ دادن به این سؤال سخت است، مگر اینکه مطمئن باشید داور هوش مصنوعی در هر دو حالت دقیقاً یکسان بوده است.
برای مثال ممکن است:
پرامپت داور این ماه با ماه قبل متفاوت باشد.
شما از یک پرامپت بهتر استفاده کرده باشید.
یکی از همکاران یک اشتباه تایپی در پرامپت قبلی را اصلاح کرده باشد.
داور جدید سختگیرتر یا آسانگیرتر باشد.
این وضعیت وقتی پیچیدهتر میشود که اپلیکیشن و سیستم AI Judge توسط دو تیم مختلف مدیریت شوند. ممکن است تیمی که داورها را مدیریت میکند مدل یا پرامپت داور را تغییر دهد بدون اینکه تیم اپلیکیشن را مطلع کند. در نتیجه تیم اپلیکیشن ممکن است تغییرات نتایج ارزیابی را اشتباهاً به تغییرات اپلیکیشن نسبت دهد، در حالی که علت واقعی تغییر در داور بوده است.
به همین دلیل یک قاعده مهم وجود دارد:
به هیچ AI Judge اعتماد نکنید اگر مدل و پرامپتی که برای آن استفاده شده را نمیتوانید ببینید.
روشهای ارزیابی معمولاً زمان میبرند تا استاندارد شوند. با پیشرفت این حوزه و اضافه شدن محدودیتها و سازوکارهای کنترلی (guardrails)، انتظار میرود در آینده AI Judgeها استانداردتر و قابلاعتمادتر شوند.
افزایش هزینه و تأخیر (Increased costs and latency)
میتوان از AI Judge هم در مرحله آزمایش (experimentation) و هم در محیط پروداکشن استفاده کرد. بسیاری از تیمها در پروداکشن از AI Judge به عنوان guardrail استفاده میکنند تا ریسک را کاهش دهند؛ یعنی فقط پاسخهایی را به کاربر نشان میدهند که توسط داور هوش مصنوعی مناسب تشخیص داده شده باشند.
اما استفاده از مدلهای قدرتمند برای ارزیابی میتواند هزینهبر باشد. برای مثال اگر از GPT‑4 هم برای تولید پاسخ و هم برای ارزیابی پاسخ استفاده کنید، تعداد فراخوانیهای GPT‑4 تقریباً دو برابر میشود و در نتیجه هزینه API تقریباً دو برابر خواهد شد.
اگر برای ارزیابی چند معیار مختلف چند پرامپت داشته باشید، هزینه حتی بیشتر هم میشود. مثلاً اگر بخواهید سه معیار زیر را بررسی کنید:
کیفیت کلی پاسخ
سازگاری واقعی با حقایق (factual consistency)
سمیت یا محتوای مضر (toxicity)
در این صورت تعداد فراخوانیهای API ممکن است چهار برابر شود.
برای کاهش هزینه میتوان:
از مدلهای ضعیفتر به عنوان داور استفاده کرد
یا از روش spot‑checking استفاده کرد (یعنی فقط بخشی از پاسخها را ارزیابی کرد)
البته در روش spot‑checking ممکن است برخی خطاها شناسایی نشوند. هرچه درصد نمونههایی که ارزیابی میکنید بیشتر باشد، اعتماد به نتایج ارزیابی بیشتر خواهد بود، اما هزینه نیز افزایش پیدا میکند. پیدا کردن تعادل مناسب بین هزینه و میزان اطمینان معمولاً به آزمون و خطا نیاز دارد.
با این حال، در مجموع AI Judgeها هنوز بسیار ارزانتر از ارزیابهای انسانی هستند.
استفاده از AI Judge در خط پردازش پروداکشن همچنین میتواند تأخیر زمانی (latency) اضافه کند. اگر قبل از ارسال پاسخ به کاربر آن را ارزیابی کنید، باید بین دو گزینه توازن برقرار کنید:
کاهش ریسک
افزایش latency
در برخی اپلیکیشنها که محدودیت سخت در زمان پاسخدهی دارند، این تأخیر ممکن است قابل قبول نباشد.
همانطور که ارزیابهای انسانی سوگیری دارند، AI Judgeها هم دچار سوگیری هستند. هر داور AI ممکن است نوع متفاوتی از سوگیری داشته باشد. آگاهی از این سوگیریها کمک میکند که امتیازهای داور را درست تفسیر کنید و حتی در برخی موارد آنها را کاهش دهید.
یکی از سوگیریهای رایج، self‑bias است. در این حالت، یک مدل تمایل دارد پاسخهای خودش را بهتر از پاسخهای تولید شده توسط مدلهای دیگر ارزیابی کند. همان مکانیزمی که به مدل کمک میکند محتملترین پاسخ را تولید کند، ممکن است باعث شود همان پاسخ را با امتیاز بالاتری ارزیابی کند.
در آزمایش Zheng و همکاران در سال ۲۰۲۳:
GPT‑4 پاسخهای خودش را با ۱۰٪ نرخ برد بیشتر ترجیح داد.
Claude‑v1 حتی سوگیری بیشتری داشت و پاسخهای خودش را با ۲۵٪ نرخ برد بیشتر ترجیح داد.
سوگیری موقعیت اول (First‑Position Bias)
بسیاری از مدلهای AI دچار سوگیری نسبت به گزینه اول هستند. یعنی وقتی یک AI Judge باید بین دو پاسخ مقایسه انجام دهد، ممکن است پاسخی که اول ارائه شده را ترجیح دهد. همین اتفاق میتواند در فهرست چند گزینه نیز رخ دهد.
برای کاهش این مشکل میتوان:
همان آزمایش را چند بار با ترتیبهای مختلف پاسخها اجرا کرد
یا از پرامپتهای دقیقتر استفاده کرد.
جالب است که این سوگیری در AI برعکس انسانها است. انسانها معمولاً به گزینهای که آخر دیدهاند تمایل بیشتری دارند که به آن recency bias گفته میشود.
سوگیری طول پاسخ (Verbosity Bias)
برخی AI Judgeها تمایل دارند پاسخهای طولانیتر را ترجیح دهند، حتی اگر کیفیت آنها پایینتر باشد.
پژوهش Wu و Aji (2023) نشان داد که GPT‑4 و Claude‑1 اغلب پاسخهای طولانیتر (حدود ۱۰۰ کلمه) که حتی دارای خطای factual هستند را نسبت به پاسخهای کوتاهتر و درست (حدود ۵۰ کلمه) ترجیح میدهند.
مطالعه Saito و همکاران (2023) در وظایف خلاقانه نیز نشان داد که اگر اختلاف طول زیاد باشد (مثلاً یکی دو برابر طولانیتر از دیگری باشد)، داور تقریباً همیشه پاسخ طولانیتر را انتخاب میکند.
با این حال، پژوهشهای Zheng و همکاران (2023) و Saito و همکاران (2023) نشان دادند که GPT‑4 کمتر از GPT‑3.5 دچار این سوگیری است. این موضوع نشان میدهد که ممکن است با قویتر شدن مدلها این سوگیری به مرور کمتر شود.
علاوه بر این سوگیریها، AI Judgeها همان محدودیتهای رایج سیستمهای AI را نیز دارند، از جمله:
حریم خصوصی (privacy)
مالکیت فکری (IP)
اگر از یک مدل اختصاصی (proprietary) به عنوان داور استفاده کنید، باید دادههای خود را برای آن مدل ارسال کنید. اگر ارائهدهنده مدل درباره دادههای آموزشی خود شفاف نباشد، ممکن است ندانید که استفاده از آن مدل از نظر تجاری یا حقوقی ایمن است یا نه.
با وجود تمام این محدودیتها، مزایای متعدد این رویکرد باعث شده بسیاری معتقد باشند استفاده از AI as a Judge در آینده بیشتر و بیشتر رایج خواهد شد.
با این حال، بهترین رویکرد این است که AI Judge را در کنار روشهای ارزیابی دقیق (exact metrics) و/یا ارزیابی انسانی استفاده کنیم، نه به عنوان تنها روش ارزیابی.
چه مدلهایی میتوانند نقش داور را داشته باشند؟ (What Models Can Act as Judges?)
مدلی که نقش AI Judge را بازی میکند میتواند:
قویتر از مدل مورد ارزیابی باشد
ضعیفتر از آن باشد
یا همسطح با آن باشد
هرکدام از این حالتها مزایا و معایب خاص خود را دارند.
در نگاه اول، منطقی به نظر میرسد که داور قویتر باشد. همانطور که در یک امتحان انتظار داریم تصحیحکننده از شرکتکننده آگاهتر باشد. مدلهای قویتر معمولاً قضاوت دقیقتری انجام میدهند و حتی میتوانند به بهبود مدلهای ضعیفتر کمک کنند؛ زیرا میتوانند راهنمایی کنند که پاسخ بهتر چه ویژگیهایی دارد.
ممکن است این سؤال پیش بیاید:
اگر به یک مدل قویتر دسترسی دارید، چرا اصلاً از یک مدل ضعیفتر برای تولید پاسخ استفاده میکنید؟
پاسخ معمولاً هزینه و زمان پاسخدهی (latency) است. ممکن است استفاده از مدل قوی برای تولید همه پاسخها بسیار گران یا کند باشد. بنابراین برخی تیمها از یک مدل ارزانتر برای تولید پاسخها استفاده میکنند و سپس از مدل قویتر فقط برای ارزیابی بخشی از پاسخها بهره میبرند.
مدل قویتر ممکن است خیلی کند باشد. گاهی مدل قوی برای کاربرد شما خیلی کند است. در این حالت میتوانید:
از یک مدل سریع و ارزان برای تولید پاسخ استفاده کنید
و یک مدل قویتر اما کندتر در پسزمینه (background) وظیفه ارزیابی پاسخها را انجام دهد.
اگر مدل قوی تشخیص دهد که پاسخ مدل ضعیف کیفیت خوبی ندارد، میتوان اقدام اصلاحی انجام داد؛ مثلاً:
پاسخ را با پاسخ تولیدشده توسط مدل قویتر جایگزین کرد.
الگوی برعکس این حالت هم رایج است:
یعنی یک مدل قوی پاسخ را تولید میکند و یک مدل ضعیفتر در پسزمینه وظیفه ارزیابی را انجام میدهد.
چالشهای استفاده از مدل قویتر به عنوان داور
استفاده از قویترین مدل به عنوان داور دو مشکل ایجاد میکند:
قویترین مدل دیگر داوری ندارد
اگر قویترین مدل را به عنوان Judge استفاده کنید، دیگر مدلی قویتر برای ارزیابی خود آن مدل وجود ندارد.
نیاز به روش دیگری برای تشخیص بهترین مدل
باید راه دیگری (مثل ارزیابی انسانی یا بنچمارکها) پیدا کنید تا مشخص شود کدام مدل واقعاً قویترین است.
استفاده از یک مدل برای ارزیابی پاسخ خودش در نگاه اول شبیه تقلب به نظر میرسد، چون مدل ممکن است دچار self‑bias شود.
با این حال، این روش برای sanity check بسیار مفید است.
اگر مدلی خودش تشخیص دهد که پاسخ خودش اشتباه است، این میتواند نشانهای باشد که مدل چندان قابل اعتماد نیست.
فراتر از sanity checkها، درخواست از یک مدل برای ارزیابی پاسخ خودش میتواند آن را تشویق کند که پاسخهایش را بازبینی کرده و بهبود دهد (Press et al., 2022; Gou et al., 2023; Valmeekamet et al., 2023). .مثال:
Prompt [from user]: What’s 10+3?
First response [from AI]: 30
Self-critique [from AI]: Is this answer correct?
Final response [from AI]: No it’s not. The correct answer is 13.
در اینجا مدل ابتدا پاسخ اشتباه داده اما بعد از بازبینی خودش آن را اصلاح کرده است.
آیا یک مدل ضعیفتر میتواند داور مدل قویتر باشد؟
این سؤال هنوز کاملاً باز است. برخی معتقدند قضاوت کار سادهتری از تولید است. مثلاً:
خیلیها میتوانند بگویند یک آهنگ خوب است یا نه
اما تعداد کمی میتوانند یک آهنگ خوب بسازند
بر این اساس، ممکن است مدلهای ضعیفتر هم بتوانند خروجی مدلهای قویتر را ارزیابی کنند.
مطالعه Zheng و همکاران (2023) نشان داد که مدلهای قویتر همبستگی بیشتری با ترجیحات انسانی دارند، و به همین دلیل بسیاری از افراد ترجیح میدهند قویترین مدلی را که توان پرداخت آن را دارند به عنوان داور استفاده کنند. با این حال، این آزمایش محدود به داورهای عمومی (general‑purpose judges) بود.
یک مسیر تحقیقاتی جذاب، ساخت داورهای کوچک اما تخصصی (specialized judges) است.
این مدلها:
برای نوع خاصی از قضاوت آموزش داده میشوند
معیارهای مشخصی دارند
از سیستم امتیازدهی مشخص پیروی میکنند
در چنین مواردی ممکن است یک مدل کوچک اما تخصصی برای یک کار خاص قابل اعتمادتر از یک مدل بزرگ عمومی باشد.
چون روشهای مختلفی برای استفاده از AI به عنوان داور (AI Judge) وجود دارد، در نتیجه انواع مختلفی از داورهای تخصصی هم میتوان ساخت.
در این بخش سه نوع داور تخصصی معرفی میشوند:
Reward Model
Reference‑Based Judge
Preference Model
یک reward model یک جفت (prompt, response) را به عنوان ورودی میگیرد و ارزیابی میکند که پاسخ داده شده با توجه به پرامپت چقدر خوب است. مدلهای پاداش سالهاست که با موفقیت در RLHF استفاده میشوند.
Cappy نمونهای از یک reward model است که توسط Google (2023) توسعه داده شده است. Cappy با دریافت یک جفت (prompt, response) یک امتیاز بین 0 و 1 تولید میکند که نشان میدهد پاسخ تا چه اندازه درست یا مناسب است.
Cappy یک مدل امتیازدهی سبک (lightweight scorer) با 360 میلیون پارامتر است که بسیار کوچکتر از foundation modelهای عمومی است.
Reference-based judge
یک reference‑based judge پاسخ تولید شده را با توجه به یک یا چند پاسخ مرجع ارزیابی میکند.
این نوع داور میتواند خروجیهایی مانند موارد زیر تولید کند:
similarity score (میزان شباهت)
quality score (کیفیت پاسخ تولید شده نسبت به پاسخ مرجع)
برای مثال، BLEURT (Sellam et al., 2020) یک جفت (candidate response, reference response) را دریافت میکند و یک similarity score بین پاسخ کاندید و پاسخ مرجع تولید میکند.
همچنین Prometheus (Kim et al., 2023) ورودیهای زیر را میگیرد:
prompt
generated response
reference response
scoring rubric
و سپس یک quality score بین 1 تا 5 تولید میکند، با این فرض که پاسخ مرجع امتیاز 5 دریافت میکند.
یک preference model ورودی زیر را دریافت میکند: (prompt, response 1, response 2) و مشخص میکند که کدام یک از دو پاسخ برای آن پرامپت بهتر است (یعنی کاربران کدام پاسخ را ترجیح میدهند).
این احتمالاً یکی از جالبترین مسیرها برای داورهای تخصصی است. توانایی پیشبینی ترجیح انسانها امکانات زیادی ایجاد میکند.
همانطور که در فصل 2 مطرح شد، دادههای ترجیحی (preference data) برای همراستا کردن مدلهای AI با ترجیحات انسانی بسیار مهم هستند، اما به دست آوردن آنها چالشبرانگیز و پرهزینه است.
داشتن یک مدل خوب برای پیشبینی ترجیح انسانها میتواند به طور کلی:
فرآیند ارزیابی را آسانتر کند
و استفاده از مدلها را ایمنتر کند.
پروژههای متعددی برای ساخت preference model انجام شده است، از جمله PandaLM (Wang et al., 2023) و JudgeLM (Zhu et al., 2023)
شکل 3‑9 نمونهای از نحوه کار PandaLM را نشان میدهد. این مدل نهتنها مشخص میکند کدام پاسخ بهتر است، بلکه دلیل این تصمیم خود را نیز توضیح میدهد.

تصویر از Wang و همکاران (2023) است و برای خوانایی بهتر کمی اصلاح شده. نسخه اصلی تصویر تحت مجوز Apache License 2.0 منتشر شده است. با وجود محدودیتهایش، رویکرد AI as a Judge بسیار منعطف و قدرتمند است.
استفاده از مدلهای ارزانتر به عنوان داور، این روش را حتی کاربردیتر و مقرونبهصرفهتر میسازد. بسیاری از همکاران من که در آغاز نسبت به این روش بدبین بودند، اکنون در محیط پروداکشن (تولید واقعی) به شکل فزایندهای به آن اعتماد و تکیه میکنند.
رویکرد AI به عنوان داور واقعاً هیجانانگیز است، و روش بعدی که خواهیم بررسی کرد نیز همینقدر جالب و الهامبخش است —
روشی که از طراحی بازی (Game Design) الهام گرفته، زمینهای جذاب و خلاقانه در دنیای هوش مصنوعی.
اغلب اوقات، هدف از ارزیابی مدلها صرفاً دریافت نمره یا امتیاز عددی نیست، بلکه میخواهید بدانید کدام مدل برای نیاز شما بهترین است و در واقع به دنبال یک رتبهبندی میان مدلها هستید. برای رتبهبندی مدلها میتوان از دو رویکرد استفاده کرد:
ارزیابی نقطهای (Pointwise Evaluation)
ارزیابی مقایسهای (Comparative Evaluation)
ارزیابی نقطهای (Pointwise Evaluation)
در این روش، هر مدل به طور مستقل ارزیابی میشود و سپس بر اساس امتیازهای دریافتی، رتبهبندی انجام میگیرد.
مثلاً اگر بخواهید مشخص کنید کدام رقاص بهترین است، هر رقاص را جداگانه مشاهده کرده، به هرکدام نمرهای میدهید، و در نهایت فردی با بیشترین امتیاز را انتخاب میکنید.
ارزیابی مقایسهای (Comparative Evaluation)
در این روش، مدلها در برابر یکدیگر سنجیده میشوند و رتبهبندی نهایی از نتایج این مقایسه به دست میآید. در مثال رقاصها، داوران میتوانند همه شرکتکنندگان را همزمان بر روی صحنه ببینند و تصمیم بگیرند کدام اجرای رقص را بیشتر میپسندند.
در نهایت، رقاصی که بیشترین ترجیح داوران را دارد به عنوان بهترین انتخاب میشود.
مزیت ارزیابی مقایسهای
برای پاسخهایی که کیفیت آنها جنبهی ذهنی دارد، ارزیابی مقایسهای معمولاً سادهتر و دقیقتر از ارزیابی نقطهای است.
برای مثال، اغلب تشخیص اینکه کدام موسیقی از دو قطعه بهتر است آسانتر از آن است که برای هر موسیقی نمره عددی مشخصی تعیین کنید.
استفاده از ارزیابی مقایسهای در هوش مصنوعی
در زمینهی هوش مصنوعی، ارزیابی مقایسهای برای نخستین بار در سال 2021 توسط شرکت Anthropic برای رتبهبندی مدلها به کار گرفته شد. امروزه این روش اساس عملکرد Chatbot Arena از پلتفرم LMSYS است. تابلوی امتیازدهیای که مدلها را بر پایهی مقایسههای دونفره (Pairwise Comparisons) انجامشده توسط کاربران جامعه رتبهبندی میکند.
بسیاری از ارائهدهندگان مدلهای هوش مصنوعی نیز اکنون از comparative evaluation برای ارزیابی مدلهای خود در پروداکشن استفاده میکنند.
شکل 3‑10 نمونهای از رابط ChatGPT را نشان میدهد که از کاربران میخواهد دو پاسخ را در کنار هم مقایسه کنند.
این دو پاسخ ممکن است:
توسط دو مدل متفاوت تولید شده باشند، یا
توسط یک مدل واحد اما با تنظیمات نمونهگیری (sampling parameters) متفاوت ایجاد شده باشند.
این نوع ارزیابی، مبنای بسیاری از رتبهبندیهای مدرن مدلهای زبانی است.

برای هر درخواست، دو یا چند مدل برای تولید پاسخ انتخاب میشوند. سپس یک ارزیاب — که میتواند انسان یا یک مدل AI باشد مشخص میکند کدام پاسخ برنده است.
بسیاری از توسعهدهندگان امکان نتیجه مساوی (tie) را نیز در نظر میگیرند تا در شرایطی که دو پاسخ تقریباً به یک اندازه خوب یا بد هستند، مجبور نباشند بهطور تصادفی یکی را برنده اعلام کنند. نکته بسیار مهمی که باید در نظر داشت این است که همه پرسشها نباید بر اساس ترجیح (preference) پاسخ داده شوند. بسیاری از پرسشها باید بر اساس درستی (correctness) پاسخ داده شوند.
برای مثال تصور کنید از مدل بپرسید:
“آیا بین تشعشع تلفن همراه و تومور مغزی ارتباطی وجود دارد؟”
و مدل دو گزینه به شما بدهد:
Yes
No
تا شما یکی را انتخاب کنید.
اگر تصمیم بر اساس رأیگیری مبتنی بر ترجیح باشد، ممکن است سیگنالهای نادرستی تولید شود. اگر این سیگنالها برای آموزش مدل استفاده شوند، میتوانند باعث رفتارهای ناهماهنگ با واقعیت (misaligned behaviors) شوند.
درخواست از کاربران برای انتخاب پاسخ نیز میتواند باعث نارضایتی کاربران شود. فرض کنید شما یک سؤال ریاضی از مدل میپرسید چون پاسخ آن را نمیدانید. اما مدل دو پاسخ متفاوت ارائه میدهد و از شما میخواهد یکی را انتخاب کنید. اگر شما پاسخ درست را میدانستید، در وهله اول از مدل سؤال نمیپرسیدید. هنگام جمعآوری بازخورد مقایسهای از کاربران، یکی از چالشها این است که مشخص شود:
کدام پرسشها را میتوان با رأیگیری مبتنی بر ترجیح تعیین کرد
و کدام پرسشها نباید با این روش ارزیابی شوند.
رأیگیری مبتنی بر ترجیح فقط زمانی بهخوبی کار میکند که رأیدهندگان در آن موضوع دانش کافی داشته باشند.
این رویکرد معمولاً در کاربردهایی مؤثر است که در آنها AI نقش یک کارآموز یا دستیار را دارد و به کاربران کمک میکند کارهایی را که خودشان بلدند سریعتر انجام دهند. نه در مواردی که کاربران از AI میخواهند کارهایی را انجام دهد که خودشان نمیدانند چگونه انجام دهند.
همچنین نباید comparative evaluation را با A/B testing اشتباه گرفت.
تفاوت آنها این است:
در A/B testing، کاربر در هر بار خروجی فقط یک مدل را میبیند.
در comparative evaluation، کاربر خروجی چند مدل را همزمان مشاهده میکند.
هر مقایسه را یک match مینامند. در نتیجه، این فرآیند مجموعهای از مقایسهها ایجاد میکند، همانطور که در جدول 3‑5 نشان داده شده است.
جدول 3‑5 نمونهای از تاریخچه مقایسههای دوتایی میان مدلها (pairwise model comparisons) را نشان میدهد.

احتمال اینکه مدل A نسبت به مدل B ترجیح داده شود را win rate مدل A در برابر B مینامند. برای محاسبه این مقدار:
تمام matchهای بین A و B بررسی میشوند
سپس درصد دفعاتی که A برنده شده محاسبه میشود.
اگر فقط دو مدل وجود داشته باشد، رتبهبندی آنها بسیار ساده است. مدلی که بیشتر برنده شود در رتبه بالاتر قرار میگیرد. اما هرچه تعداد مدلها بیشتر شود، رتبهبندی پیچیدهتر میشود. برای مثال فرض کنید پنج مدل داریم و win rate تجربی میان هر جفت مدل در جدول 3‑6 نشان داده شده است. در این حالت، با نگاه کردن به دادهها بهراحتی مشخص نیست که این پنج مدل باید چگونه رتبهبندی شوند.
جدول 3‑6: نمونهای از نرخ برد (Win Rate) میان پنج مدل. ستون A >> B نشاندهنده حالتی است که در آن مدل A نسبت به مدل B ترجیح داده شده است. یعنی در مقایسههای انجامشده، کاربران یا داوران پاسخ مدل A را بهتر از پاسخ مدل B دانستهاند.

با داشتن سیگنالهای مقایسهای، سپس از یک الگوریتم رتبهبندی برای محاسبه رتبه مدلها استفاده میشود. معمولاً این الگوریتم ابتدا از روی سیگنالهای مقایسهای برای هر مدل یک امتیاز (score) محاسبه میکند و سپس مدلها را بر اساس این امتیازها رتبهبندی میکند.
ارزیابی مقایسهای در هوش مصنوعی موضوعی نسبتاً جدید است، اما در صنایع دیگر تقریباً یک قرن است که استفاده میشود. این روش بهویژه در ورزشها و بازیهای ویدیویی بسیار رایج است. بسیاری از الگوریتمهای رتبهبندی که برای این حوزهها توسعه داده شدهاند میتوانند برای ارزیابی مدلهای هوش مصنوعی نیز به کار گرفته شوند؛ مانند Elo، Bradley–Terry و TrueSkill.
پلتفرم Chatbot Arena از LMSYS در ابتدا از الگوریتم Elo برای محاسبه رتبه مدلها استفاده میکرد، اما بعداً به الگوریتم Bradley–Terry تغییر داد، زیرا دریافتند که Elo نسبت به ترتیب ارزیابها و پرامپتها حساس است.
یک رتبهبندی زمانی درست است که برای هر جفت مدل، مدلی که رتبه بالاتری دارد احتمال بیشتری برای برنده شدن در یک match در برابر مدل با رتبه پایینتر داشته باشد. اگر مدل A بالاتر از مدل B رتبهبندی شده باشد، کاربران باید بیش از نیمی از مواقع مدل A را به مدل B ترجیح دهند.
از این دیدگاه، رتبهبندی مدلها یک مسئله پیشبینی است. ما از نتایج matchهای گذشته یک رتبهبندی محاسبه میکنیم و از آن برای پیشبینی نتایج matchهای آینده استفاده میکنیم. الگوریتمهای رتبهبندی مختلف میتوانند رتبهبندیهای متفاوتی تولید کنند، و هیچ حقیقت قطعی (ground truth) برای اینکه رتبهبندی درست کدام است وجود ندارد. کیفیت یک رتبهبندی با این سنجیده میشود که تا چه اندازه در پیشبینی نتایج matchهای آینده خوب عمل میکند. تحلیل من از رتبهبندی Chatbot Arena نشان میدهد که رتبهبندی تولیدشده خوب عمل میکند، دستکم برای جفت مدلهایی که تعداد match کافی دارند. برای دیدن این تحلیل به مخزن GitHub کتاب مراجعه کنید.
در ارزیابی نقطهای (Pointwise Evaluation)، بخش سنگین فرآیند، طراحی معیار سنجش و متریکها برای جمعآوری سیگنالهای مناسب است. محاسبه نمرات برای رتبهبندی مدلها آسان است.
در ارزیابی مقایسهای (Comparative Evaluation)، هم جمعآوری سیگنال و هم رتبهبندی مدل چالشبرانگیز هستند. این بخش به سه چالش رایج ارزیابی مقایسهای میپردازد.
چالش اول: گلوگاههای مقیاسپذیری (Scalability bottlenecks)
ارزیابی مقایسهای متمرکز بر داده است. تعداد جفتمدلهایی که باید مقایسه شوند، به صورت درجهدوم (Quadratic) با تعداد مدلها رشد میکند. در ژانویه ۲۰۲۴، LMSYS با استفاده از ۲۴۴,۰۰۰ مقایسه، ۵۷ مدل را ارزیابی کرد. حتی با وجود اینکه این تعداد مقایسه زیاد به نظر میرسد، این به طور میانگین تنها ۱۵۳ مقایسه برای هر جفت مدل است (۵۷ مدل متناظر با ۱,۵۹۶ جفت مدل). این عدد کوچکی است، با توجه به طیف گسترده وظایفی که انتظار داریم یک مدل پایه انجام دهد.
خوشبختانه، ما همیشه نیازی به مقایسه مستقیم دو مدل برای تعیین بهتر بودن یکی بر دیگری نداریم. الگوریتمهای رتبهبندی معمولاً تعدی (Transitivity) را فرض میکنند. اگر مدل A بالاتر از B رتبهبندی شود و B بالاتر از C، آنگاه با خاصیت تعدی میتوان استنباط کرد که A بالاتر از C رتبهبندی میشود. این بدان معناست که اگر الگوریتم مطمئن باشد که A بهتر از B و B بهتر از C است، نیازی نیست که A را با C مقایسه کند تا بداند A بهتر است.
با این حال، مشخص نیست که آیا این فرض تعدی برای مدلهای هوش مصنوعی برقرار است یا خیر. بسیاری از مقالاتی که الوی (Elo) را برای ارزیابی هوش مصنوعی تحلیل میکنند، فرض تعدی را به عنوان یک محدودیت ذکر کردهاند (Boubdir و همکاران؛ Balduzzi و همکاران؛ و Munos و همکاران). آنها استدلال کردند که ترجیح انسان لزوماً تعدی نیست. علاوه بر این، عدم تعدی میتواند به این دلیل رخ دهد که جفتمدلهای مختلف توسط ارزیابهای مختلف و روی دستورالعملهای (پرامپتهای) مختلف ارزیابی میشوند.
همچنین چالش ارزیابی مدلهای جدید وجود دارد. در ارزیابی مستقل (Independent Evaluation)، تنها مدل جدید نیاز به ارزیابی دارد. در ارزیابی مقایسهای، مدل جدید باید در مقابل مدلهای موجود ارزیابی شود، که این میتواند رتبهبندی مدلهای موجود را تغییر دهد.
این موضوع همچنین ارزیابی مدلهای خصوصی (Private Models) را دشوار میسازد. تصور کنید که شما یک مدل برای شرکت خود ساختهاید و از دادههای داخلی استفاده کردهاید. شما میخواهید این مدل را با مدلهای عمومی مقایسه کنید تا تصمیم بگیرید که آیا استفاده از یک مدل عمومی سودمندتر است یا خیر. اگر بخواهید از ارزیابی مقایسهای برای مدل خود استفاده کنید، احتمالاً باید سیگنالهای مقایسهای خود را جمعآوری کنید و جدول ردهبندی (Leaderboard) خود را ایجاد کنید یا به یکی از آن جدولهای ردهبندی عمومی بپردازید تا ارزیابی خصوصی را برای شما اجرا کند.
گلوگاه مقیاسپذیری را میتوان با الگوریتمهای تطبیق (Matching) بهتر کاهش داد. تاکنون فرض کردهایم که مدلها برای هر مسابقه به طور تصادفی انتخاب میشوند، بنابراین همه جفتمدلها در تقریباً تعداد یکسانی از مسابقات ظاهر میشوند. با این حال، نیازی نیست همه جفتمدلها به یک اندازه مقایسه شوند. هنگامی که از نتیجه یک جفت مدل اطمینان حاصل کنیم، میتوانیم تطبیق آنها با یکدیگر را متوقف کنیم.
یک الگوریتم تطبیق کارآمد باید مسابقاتی را نمونهبرداری کند که بیشترین عدم قطعیت را در رتبهبندی کلی کاهش دهد.
چالش دوم: عدم استانداردسازی و کنترل کیفیت (Lack of standardization and quality control)
یکی از راههای جمعآوری سیگنالهای مقایسهای، برونسپاری مقایسهها به جامعه (Crowdsourcing) به روشی است که LMSYS Chatbot Arena انجام میدهد. هر کسی میتواند به وبسایت مراجعه کند، یک دستورالعمل (پرامپت) وارد کند، دو پاسخ از دو مدل ناشناس دریافت کند و برای پاسخ بهتر رأی دهد. تنها پس از اتمام رأیگیری، نام مدلها فاش میشود.
مزیت این رویکرد این است که طیف گستردهای از سیگنالها را ثبت میکند و نسبتاً دستکاری (Gaming) آن دشوار است. با این حال، معایب آن عبارتند از:
۱. عدم کنترل بر محتوای ارزیابی: هر فردی با دسترسی به اینترنت میتواند از هر دستورالعملای برای ارزیابی این مدلها استفاده کند و هیچ استانداردی برای تعریف «پاسخ بهتر» وجود ندارد. ممکن است انتظار زیادی باشد که داوطلبان پاسخها را از نظر صحت واقعی بررسی کنند، بنابراین ممکن است ناخواسته پاسخهایی را ترجیح دهند که بهظاهر بهتر هستند اما از نظر واقعی نادرست هستند.
تفاوت در ترجیحات ارزیابها: برخی افراد ممکن است پاسخهای مؤدب و معتدل را ترجیح دهند، در حالی که دیگران ممکن است پاسخهای بدون فیلتر را ترجیح دهند. این هم خوب است و هم بد:
خوب است زیرا به ثبت ترجیحات انسانی در محیط واقعی کمک میکند.
بد است زیرا ترجیحات انسانی در محیط واقعی ممکن است برای همه موارد استفاده مناسب نباشد. به عنوان مثال، اگر کاربر از مدل بخواهد یک لطیفه نامناسب بگوید و مدل امتناع کند، کاربر ممکن است به آن رأی منفی دهد. اما به عنوان یک توسعهدهنده برنامه، ممکن است ترجیح دهید که مدل امتناع کند. برخی کاربران حتی ممکن است بهطور مخرب پاسخهای سمی را به عنوان پاسخهای ترجیحی انتخاب کنند و رتبهبندی را آلوده کنند.
2. خارج از محیط کاری واقعی: برونسپاری مقایسهها نیازمند آن است که کاربران مدلها را خارج از محیط کاری واقعی خود ارزیابی کنند. بدون زمینهگیری واقعی، دستورالعملهای آزمایشی ممکن است نحوه استفاده واقعی از این مدلها در جهان واقعی را منعکس نکنند. افراد ممکن است فقط از اولین دستورالعملهایی که به ذهنشان میرسد استفاده کنند و بعید است از تکنیکهای پیشرفته دستوردهی (Sophisticated Prompting) استفاده کنند.
در میان ۳۳٬۰۰۰ پرامپتی که در سال ۲۰۲۳ توسط LMSYS Chatbot Arena منتشر شد، ۱۸۰ مورد از آنها فقط «hello» و «hi» بودند که ۰٫۵۵٪ از کل دادهها را تشکیل میدهند. این عدد حتی تنوعهایی مثل «hello!»، «hello.»، «hola»، «hey» و موارد مشابه را هم حساب نکرده است. همچنین در میان پرامپتها معماهای زیادی وجود دارد. برای مثال سؤال: «X سه خواهر دارد و هرکدام یک برادر دارند. X چند برادر دارد؟» ۴۴ بار پرسیده شده است.
پرامپتهای ساده پاسخ دادن را آسان میکنند و بنابراین تمایز دادن عملکرد مدلها را سخت میکنند. اگر در ارزیابی مدلها پرامپتهای ساده بیش از حد استفاده شوند، میتوانند رتبهبندی را آلوده کنند.
همچنین اگر یک لیدربورد عمومی از ساخت کانتکستهای پیشرفته پشتیبانی نکند مثلاً افزودن اسناد مرتبطی که از پایگاههای داده داخلی بازیابی شدهاند، رتبهبندی آن نمیتواند نشان دهد که یک مدل در سیستم RAG شما واقعاً چقدر خوب عمل میکند.
در نهایت، توانایی تولید پاسخ خوب با توانایی بازیابی مرتبطترین اسناد یکسان نیست.
یک راه بالقوه برای استانداردسازی این است که کاربران را به مجموعهای از پرامپتهای از پیش تعیینشده محدود کنیم. اما این کار ممکن است توانایی لیدربورد را در پوشش دادن کاربردهای متنوع کاهش دهد. در عوض، LMSYS اجازه میدهد کاربران از هر پرامپتی استفاده کنند، اما سپس با استفاده از مدل داخلی خود پرامپتهای سخت را فیلتر میکند و رتبهبندی مدلها را فقط بر اساس همین پرامپتهای سخت انجام میدهد.
روش دیگر این است که فقط از ارزیابهایی استفاده کنیم که به آنها اعتماد داریم. میتوان ارزیابها را روی معیارهایی برای مقایسه دو پاسخ آموزش داد، یا آنها را آموزش داد تا از پرامپتهای عملی و تکنیکهای پیشرفتهی پرامپتنویسی استفاده کنند. این رویکردی است که Scale در لیدربورد مقایسهای خصوصی خود استفاده میکند. نقطه ضعف این روش این است که هزینهبر است و میتواند تعداد مقایسههایی را که به دست میآوریم بهشدت کاهش دهد.
گزینه دیگر این است که ارزیابی مقایسهای را در خود محصول ادغام کنیم و اجازه دهیم کاربران در جریان کارشان مدلها را ارزیابی کنند. برای مثال، در وظیفه تولید کد میتوان دو قطعه کد را در ویرایشگر کد کاربر پیشنهاد داد و از او خواست بهتر را انتخاب کند. بسیاری از اپلیکیشنهای چت از قبل چنین کاری انجام میدهند. با این حال، همانطور که قبلاً گفته شد، ممکن است کاربر نداند کدام قطعه کد بهتر است، چون خودش متخصص نیست.
علاوه بر این، ممکن است کاربران هر دو گزینه را نخوانند و فقط بهصورت تصادفی روی یکی کلیک کنند. این موضوع میتواند نویز زیادی وارد نتایج کند. با این حال، سیگنالهایی که از درصد کمی از کاربرانی که درست رأی میدهند به دست میآید، گاهی میتواند برای تشخیص اینکه کدام مدل بهتر است کافی باشد.
برخی تیمها ترجیح میدهند به جای انسان از هوش مصنوعی بهعنوان ارزیاب استفاده کنند. اگرچه AI ممکن است به اندازهی متخصصان انسانی آموزشدیده خوب نباشد، اما میتواند قابلاعتمادتر از کاربران تصادفی اینترنت باشد.
از عملکرد مقایسهای به عملکرد مطلق (From comparative performance to absolute performance)
برای بسیاری از کاربردها، لزوماً به بهترین مدل ممکن نیاز نداریم؛ بلکه به مدلی نیاز داریم که به اندازهی کافی خوب باشد. ارزیابی مقایسهای به ما میگوید کدام مدل بهتر است، اما نمیگوید یک مدل دقیقاً چقدر خوب است یا اینکه آیا برای کاربرد ما کافی است یا نه. فرض کنید به این رتبهبندی رسیدهایم که مدل B بهتر از مدل A است. در این حالت چند سناریوی مختلف میتواند درست باشد:
مدل B خوب است، اما مدل A بد است.
هر دو مدل A و B بد هستند.
هر دو مدل A و B خوب هستند.
برای تشخیص اینکه کدام سناریو درست است، باید از انواع دیگر ارزیابی استفاده کنیم. فرض کنید ما از مدل A برای پشتیبانی مشتریان استفاده میکنیم و این مدل میتواند ۷۰٪ از تیکتها را حل کند. حالا مدل B را در نظر بگیرید که در مقایسه با A، ۵۱٪ مواقع برنده میشود. مشخص نیست این نرخ برد ۵۱٪ چگونه به تعداد درخواستهایی که مدل B میتواند حل کند تبدیل میشود.
چندین نفر به من گفتهاند که در تجربهی آنها، تغییر ۱٪ در نرخ برد در بعضی کاربردها میتواند افزایش عملکرد بسیار بزرگی ایجاد کند، اما در کاربردهای دیگر تأثیر بسیار کمی دارد.
وقتی تصمیم میگیریم مدل A را با مدل B جایگزین کنیم، فقط ترجیح انسانی مهم نیست. عوامل دیگری مثل هزینه هم اهمیت دارند. وقتی ندانیم دقیقاً چه مقدار بهبود عملکرد انتظار داریم، انجام تحلیل هزینه–فایده سخت میشود. مثلاً اگر مدل B دو برابر مدل A هزینه داشته باشد، ارزیابی مقایسهای به تنهایی کافی نیست تا مشخص کند آیا بهبود عملکرد مدل B ارزش هزینهی اضافی را دارد یا نه.
با توجه به محدودیتهای زیاد ارزیابی مقایسهای، ممکن است این سؤال پیش بیاید که آیا این روش در آینده جایگاهی خواهد داشت یا خیر. ارزیابی مقایسهای مزایای زیادی دارد.
اول اینکه، همانطور که در بخش «Post-Training» (صفحه ۷۸ کتاب مرجع) بحث شد، افراد دریافتهاند که مقایسهی دو خروجی آسانتر از این است که برای هر خروجی یک امتیاز عددی مشخص بدهند. هرچه مدلها قویتر شوند و حتی از عملکرد انسانی فراتر بروند، ممکن است برای انسانها غیرممکن شود که به پاسخهای مدلها امتیاز مطلق بدهند. اما انسانها احتمالاً همچنان قادر خواهند بود تفاوت میان دو پاسخ را تشخیص دهند، و ارزیابی مقایسهای شاید تنها گزینهی باقیمانده باشد.
برای مثال، مقاله Llama 2 گزارش کرده است که وقتی مدل وارد سطحی از نگارش میشود که فراتر از توان بهترین بهنویسندگان انسانی است، انسانها هنوز هم میتوانند هنگام مقایسهی دو پاسخ، بازخورد مفیدی بدهند (Touvron et al., 2023).
دوم اینکه، ارزیابی مقایسهای سعی میکند کیفیتی را اندازه بگیرد که واقعاً برای ما مهم است: ترجیحات انسانی. این روش فشار نیاز به ساخت بنچمارکهای جدید و مداوم را که باید همیشه با تواناییهای روبهرشد مدلها همگام شوند کاهش میدهد. برخلاف بنچمارکهایی که وقتی مدلها در آنها به امتیاز کامل میرسند بیاستفاده میشوند، ارزیابی مقایسهای هرگز اشباع نمیشود، تا زمانی که مدلهای جدیدتر و قویتر عرضه میشوند.
ارزیابی مقایسهای نسبتاً سخت برای دستکاری است، چون راه سادهای برای تقلب وجود ندارد. مثلاً یاد دادن پاسخهای مرجع به مدل. به همین دلیل، بسیاری از افراد به نتایج لیدربوردهای عمومی مقایسهای بیشتر از هر نوع لیدربورد عمومی دیگر اعتماد دارند.
ارزیابی مقایسهای میتواند سیگنالهای تمایزدهندهای دربارهی مدلها به ما بدهد که به هیچ وجه دیگری قابل دستیابی نیستند. برای ارزیابی آفلاین، این روش میتواند مکمل عالی برای بنچمارکهای ارزیابی باشد. برای ارزیابی آنلاین، میتواند مکملی برای تست A/B باشد.
خلاصه
هرچه مدلهای هوش مصنوعی قویتر میشوند، پتانسیل شکستهای فاجعهبار بیشتر میشود، که این امر ارزیابی را حتی مهمتر میکند. در عین حال، ارزیابی مدلهای قدرتمند با خروجیهای باز، چالشبرانگیز است. این چالشها بسیاری از تیمها را به سمت ارزیابی انسانی سوق میدهد. داشتن انسان در چرخه برای بررسیهای اولیه (sanity checks) همیشه مفید است و در بسیاری از موارد، ارزیابی انسانی ضروری است. با این حال، این فصل بر رویکردهای مختلف ارزیابی خودکار تمرکز داشت.
این فصل با بحثی در مورد اینکه چرا ارزیابی مدلهای بنیادین (foundation models) سختتر از مدلهای ML سنتی است، آغاز میشود. اگرچه بسیاری از تکنیکهای ارزیابی جدید در حال توسعه هستند، سرمایهگذاری در ارزیابی همچنان از سرمایهگذاری در توسعهی مدل و اپلیکیشن عقب مانده است.
از آنجایی که بسیاری از مدلهای بنیادین دارای مولفهی مدل زبانی هستند، ما به معیارهای مدلسازی زبان، از جمله پرپلکسیتی (perplexity) و آنتروپی متقاطع (cross entropy) پرداختیم. بسیاری از افرادی که با آنها صحبت کردهام این معیارها را گیجکننده مییابند، بنابراین بخشی را به نحوهی تفسیر این معیارها و استفاده از آنها در ارزیابی و پردازش داده اختصاص دادم.
سپس این فصل تمرکز خود را به رویکردهای مختلف برای ارزیابی پاسخهای باز، از جمله درستی عملکردی (functional correctness)، امتیازات شباهت (similarity scores)، و هوش مصنوعی به عنوان داور (AI as a judge) تغییر داد. دو رویکرد اول ارزیابی، دقیق (exact) هستند، در حالی که ارزیابی «هوش مصنوعی به عنوان داور» ذهنی (subjective) است.
برخلاف ارزیابی دقیق، معیارهای ذهنی به شدت به داور وابسته هستند. امتیازات آنها باید در چارچوب داورانی که استفاده میشوند تفسیر شود. امتیازاتی که با هدف سنجش یک کیفیت مشابه توسط داوران هوش مصنوعی مختلف ارائه میشوند، ممکن است قابل مقایسه نباشند. داوران هوش مصنوعی، مانند همه برنامههای هوش مصنوعی، باید بهصورت تکراری بهبود یابند، به این معنی که قضاوتهای آنها تغییر میکند. این امر آنها را به عنوان بنچمارک برای ردیابی تغییرات یک اپلیکیشن در طول زمان، غیرقابل اعتماد میسازد. داوران هوش مصنوعی، اگرچه امیدوارکننده هستند، اما باید با ارزیابی دقیق، ارزیابی انسانی، یا هر دو تکمیل شوند.
هنگام ارزیابی مدلها، میتوانید هر مدل را بهطور مستقل ارزیابی کنید و سپس آنها را بر اساس امتیازاتشان رتبهبندی کنید. بهطور جایگزین، میتوانید آنها را با استفاده از سیگنالهای مقایسهای رتبهبندی کنید: کدام یک از دو مدل بهتر است؟ ارزیابی مقایسهای در ورزش، بهویژه شطرنج، رایج است و در ارزیابی هوش مصنوعی در حال کسب محبوبیت است. هم ارزیابی مقایسهای و هم فرآیند پس آموزش (post-training alignment) به سیگنالهای ترجیحی نیاز دارند که جمعآوری آنها پرهزینه است. این امر انگیزه توسعهی مدلهای ترجیحی (preference models) را ایجاد کرد: داوران هوش مصنوعی تخصصی که پیشبینی میکنند کاربران کدام پاسخ را ترجیح میدهند.
در حالی که معیارهای مدلسازی زبان و اندازهگیریهای شباهت طراحیشده توسط انسان مدتی است که وجود دارند، «هوش مصنوعی به عنوان داور» و ارزیابی مقایسهای تنها با ظهور مدلهای بنیادین مورد استقبال قرار گرفتهاند. بسیاری از تیمها در حال یافتن راهی برای گنجاندن آنها در خطوط لولهی ارزیابی خود هستند. یافتن چگونگی ساخت یک خط لولهی ارزیابی قابل اعتماد برای ارزیابی برنامههای کاربردی با خروجی باز، موضوع فصل بعدی است.