
در این مقاله میخوام که با یکی دیگر از قضیه ها و مفاهیمی که در طراحی سیستم (System Design) مفید هست بدانیم، صحبت کنم و اون هم مقیاس پذیری یا همون Scaling در دیتابیس ها هست. در ابتدایی که پروژه شما به تعداد یوزر بالایی نرسیده باشه شاید مقیاس پذیری یا اعمال بعضی از استراتژی ها در سرور های دیتابیستون شاید انچنان اولویتی نداشته باشه ولی وقتی که تعداد یوزر ها و درخواست ها بالا میرود و سرعت پاسخ دهی سرور دیتابیس پایین می آید برسی و اعمال استراتژی موثر و ساختارمند اونوقت هست که اولویت پیدا میکند.
البته این موضوع رو توجه داشته باشید که ما قراره دیتابیسمون رو کمکم و مرحلهای مقیاس کنیم. یعنی اگه الان فقط ۱۰ هزار کاربر داریم، اینکه بیایم از الان دیتابیس رو برای ۱۰ میلیون کاربر آماده کنیم، فقط وقت و انرژی هدر دادن و اسمش میشه زیادهروی توی مهندسی (Over-Engineering). ما فقط تا حدی دیتابیس رو بزرگ میکنیم که نیاز کسبوکارمون رو جواب بده و لازم نباشه بیخودی هزینه و زمان بذاریم.

کلیه دیتابیس ها به دو نوع کلی تقسیم می شوند که در ادامه بهشون میپردازیم:
SQL دیتابیسهای ساختاریافته مثل MySQL و PostgreSQL هستند که از جداول با اسکیمای ثابت و زبان SQL برای مدیریت دادهها استفاده میکنند و قوانین ACID را بهخوبی رعایت میکنند.
SQL مناسب پروژههایی هست که ساختار داده ای مشخصی دارد و روابط پیچیده بین داده ای دارد و برای مقیاس پذیری بهتر است از روش افزایش منابع استفاده کرد
دیتابیس های زیر از نوع SQL هستند:
MySQL
PostgreSQL
Oracle
SQL Server
SQLite
NoSQL دیتابیسهایی مثل MongoDB و Cassandra هستند که ساختار منعطفتر و بدون اسکیمای ثابت دارند و برای مدیریت دادههای بزرگ و غیرساختاریافته با مقیاسپذیری بالا استفاده میشوند. معمولاً محدودیتهای کمتری در ذخیره و بازیابی سریع دادهها دارند و مدل Eventual Consistency به جای ACID در بسیاری از آنها استفاده میشود. برای مقیاس پذیری در این نوع دیتابیس بهتر هست از روش مقیاس پذیری افقی (Horizontally Scale) استفاده کرد.
دیتابیس های زیر از نوع NoSQL هستند:
MongoDB
Cassandra
ایندکسینگ (Indexing) در دیتابیس یعنی ساخت یک ساختار داده کمکی (مثل یک کتابخانه با فهرست الفبایی) روی یک یا چند ستون جدول، تا هنگام اجرای کوئریها، دیتابیس بتواند دادههای موردنظر را سریع پیدا کند، بدون اینکه مجبور باشد کل جدول را خط به خط اسکن کند. این ایندکسها معمولاً با استفاده از ساختارهایی مثل B-Tree یا Hash Table ساخته میشوند.
زمانی که شما روی یک ستون ایندکس ایجاد میکنید
دیتابیس یک ساختار داده (مثلاً B-Tree) میسازد و مقادیر ستون + یک اشاره به ردیف آن داده را در این ساختار قرار میدهد.
وقتی کوئری اجرا میشود، دیتابیس بهجای اسکن کل جدول، از این ساختار برای پیدا کردن سریع مقدار استفاده میکند.
این ایندکسها بهروزرسانی میشوند هر زمان که داده جدید اضافه یا تغییر داده شود تا هماهنگ با جدول اصلی باقی بمانند.
زمانی که دادههای زیادی دارید و مرتباً روی ستون خاصی جستجو انجام میدهید.
برای ستونهایی که در WHERE، ORDER BY، GROUP BY یا JOIN استفاده میشوند.
برای بهبود سرعت گزارشگیری روی جداول حجیم.
سرعت جستجوی بالا: کوئریها روی ستونهای ایندکس شده بسیار سریعتر اجرا میشوند.
بهبود سرعت عملیات JOIN: بهویژه وقتی ستونهای مشترک بین جداول ایندکس شده باشند.
بهبود سرعت ORDER BY و GROUP BY: مرتبسازی دادهها روی ستونهای ایندکس شده سریعتر انجام میشود.
کاهش مصرف CPU برای خواندن دادههای زیاد: زیرا بجای اسکن کل داده، مستقیم به رکورد میرسد.
افزایش مصرف فضای ذخیرهسازی: ایندکسها فضای اضافه روی دیسک مصرف میکنند.
کند شدن عملیات INSERT و UPDATE: چون هر بار داده جدیدی اضافه یا ویرایش میشود، ایندکس هم باید بهروزرسانی شود و این میتواند کمی سرعت نوشتن را کاهش دهد.
نیاز به مدیریت: ایندکسهای اضافی اگر بدون نیاز ساخته شوند، باعث کندی سیستم میشوند.

Partitioning (پارتیشنبندی) یعنی تقسیم یک جدول بزرگ به چند بخش کوچکتر (Partition) با این هدف که مدیریت، نگهداری و کوئری گرفتن از دادههای بزرگ سادهتر و سریعتر انجام شود. هر پارتیشن مانند یک جدول جداگانه عمل میکند اما از دید کاربر و کوئری، همچنان به عنوان یک جدول یکپارچه نمایش داده میشود.
وقتی شما جدول را پارتیشنبندی میکنید
جدول براساس یک ستون (مانند تاریخ، ID یا محدوده مقادیر) به چند قسمت تقسیم میشود.
دیتابیس هنگام اجرای کوئری، فقط به پارتیشن مربوطه دسترسی پیدا میکند و نیازی به اسکن کل دادهها ندارد (این ویژگی را Partition Pruning مینامند).
پارتیشنها میتوانند در فایلهای جداگانه ذخیره شوند و مدیریت آرشیو داده یا حذف دادههای قدیمی در آنها راحتتر است.
اگر اغلب کوئریهای شما روی محدوده خاصی از دادهها اجرا میشوند (مثلاً دادههای یک ماه یا یک سال خاص).
اگر نیاز به آرشیو یا حذف دادههای قدیمی بهصورت دورهای دارید.
اگر عملیات نگهداری مانند ایندکسسازی مجدد، بکاپگیری یا ریست کردن دادهها طولانی است.
من این مورد در یک پروژه شخصی امتحان کردم، همان طور که در بالا هم گفتم این روش از مقیاس پذیری دیتابیس به نظر من فقط برای زمانی مناسب هست که بشه داده هارو بر اساس یک منطقه یا زمانی جدا کرد ولی اگر بر اساس غیر از آن جدا کنید مثل بر اساس id داده ها تاثیر انچنانی بر سرعت دیتابیس شما نمی گذارد.
Range Partitioning: دادهها براساس بازهها تقسیم میشوند (مثلاً تاریخها)
List Partitioning: دادهها براساس یک لیست از مقادیر خاص تقسیم میشوند
Hash Partitioning: دادهها براساس یک تابع هش به چند پارتیشن تقسیم میشوند (برای توزیع یکنواخت داده)
Composite Partitioning: ترکیبی از روشهای بالا برای کنترل دقیقتر دادهها
افزایش سرعت کوئریها: بهویژه برای دادههای بزرگ، زیرا فقط بخشی از دادهها اسکن میشود.
مدیریت آسان دادههای قدیمی: میتوانید یک پارتیشن قدیمی را سریع حذف یا آرشیو کنید بدون تأثیر روی بقیه دادهها.
بهبود عملکرد در مدیریت دادههای بزرگ: جدولهای خیلی بزرگ به قسمتهای کوچک و قابل مدیریت تقسیم میشوند.
بهینهسازی نگهداری: بازسازی ایندکسها یا عملیات Vacuum (در PostgreSQL) سریعتر انجام میشود چون روی یک پارتیشن اجرا میشوند.
پشتیبانی از Parallel Processing: برخی دیتابیسها عملیات موازی روی پارتیشنها انجام میدهند.
پیچیدگی در طراحی: طراحی پارتیشنبندی نیاز به شناخت دقیق دادهها و الگوهای دسترسی دارد.
مدیریت بیشتر: نیاز به مدیریت و مانیتورینگ دقیق تعداد و وضعیت پارتیشنها دارد.
محدودیتهای دیتابیس: همه دیتابیسها به یک اندازه از پارتیشنبندی پشتیبانی نمیکنند یا محدودیتهایی دارند.
افزایش سربار در کوئریهای اشتباه: اگر پارتیشن Pruning بهدرستی انجام نشود، کل پارتیشنها اسکن میشوند.
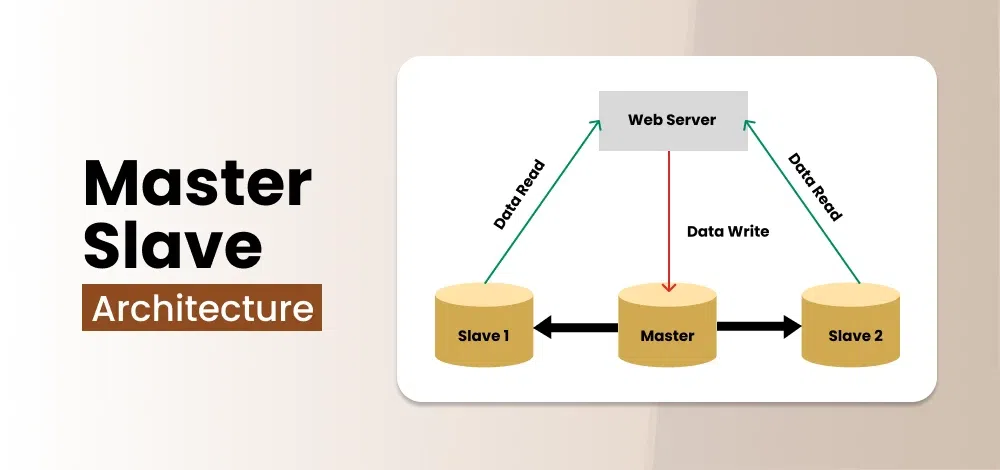
یکی دیگر از روش های اسکیلینگ دیتابیس استفاده از روش Master-Slave هست، این معماری تشکیل شده از چند سرور که یکی از آن سرور ها به عنوان Master باید باشه و وظیفه این را دارد که فقط درخواست های INSERT،UPDATE و DELETE را انجام دهد و یک یا چند سرور به عنوان Slave هستند که ضمن این که فقط به درخواست های Read پاسخ میدهند، خودشون رو با سرور Master جهت آپدیت داده ها از طریق Binary Log سینک میکنند.
افزایش مقیاسپذیری خواندن: میتوانید چندین Slave اضافه کنید و خواندن از دیتابیس را بین آنها توزیع کنید.
بهبود عملکرد: Master فقط روی نوشتن متمرکز است و بار خواندن کاهش مییابد.
افزونگی و در دسترس بودن بالا: اگر Master از دسترس خارج شود، میتوانید یکی از Slaveها را به Master ارتقا دهید.
پشتیبانگیری آسان: میتوانید از Slaveها برای گرفتن Backup بدون تأثیر روی عملکرد Master استفاده کنید.
مناسب برای Report و Analytics: چون Slave فشار زیادی روی Master وارد نمیکند.
احتمال تأخیر در Replication: بین Master و Slave ممکن است کمی تأخیر وجود داشته باشد (Replication Lag)، که میتواند دادههای خوانده شده از Slave بروز نباشد.
نقطه شکست تکی (Single Point of Failure): اگر Master از دسترس خارج شود و Failover تنظیم نشده باشد، نوشتن متوقف میشود.
پیچیدگی مدیریت: نیاز به مانیتورینگ، تنظیم Failover و نگهداری دقیق دارد.
خواندن داده قدیمی: ممکن است دادهای در Master نوشته شود اما هنوز به Slave منتقل نشده باشد و داده قدیمی به کاربر نمایش داده شود.
در صورتی که دو روش قبلی یعنی Indexing و Partitioning دیگر جواب نمی دهد
زمانی که تعداد درخواستهای خواندن بالا هست و نیاز به توزیع بار دارید
در زمانی که کاربران مختلف و زیاد در نقاط مختلف جغرافیایی دارید و میخواید با ایجاد یک سرور Slave در نقاط مختلف جغرافیایی سرعت خواندن از دیتابیستون رو بیشتر کند
برای گرفتن بکاپ بدون تأثیر روی عملکرد سیستم اصلی
زمانی که نیاز به افزونگی و Disaster Recovery دارید
MySQL
PostgreSQL (با Streaming Replication)
MongoDB (در قالب Primary-Secondary)
Redis
Cassandra (در قالب Masterless Architecture با Replication)
این نوع معماری مانند معماری Master-Slave می باشد با این تفاوت که به جای یک سرور Master چند سرور Master داریم که هر سرور مستر هم زمان قابلیت این رو دارند که هم عملیات های INSERT،UPDATE و DELETE را انجام بدند و هم عملیات Read. این نوع معماری برای دیتابیس هایی مناسب هستند که کاربران در نقاط مختلف قرار دارند و میخواهند بر اساس منطقه جغرافیایی درخواست هارو پاسخ دهند.

تقسیمبندی دیتابیس (Database Sharding) اگر بخوام به صورت ساده توضیح بدم به این مفهموم اشاره دارد که به جای داشتن یک دیتابیس بزرگ، چندین دیتابیس کوچک ایجاد میکنیم که هرکدام بخشی از داده را نگهدارند و باهم یک دیتابیس واحد را بسازند. حالا نحوه کار این نوع از روش مقیاس پذیری به ان صورت هست که داده ها بر اساس یک Shard Key (مثل user_id، customer_id یا country) تقسیم می شوند و هر Shard میتواند روی یک سرور جداگانه قرار بگیرد و درفرایند، اپلیکیشن تصمیمگیری میکند که برای گرفتن اطلاعات یا اپدیت داده ای به کدام Shard درخواست بزند.
بر اساس محدوده (Range-based Sharding)
دادهها بر اساس محدوده (Range) تقسیم میشوند.
مزیت: ساده و قابل درک.
عیب: ممکن است منجر به Hotspot روی یک Shard شود اگر دادههای جدید فقط در یک Range باشند.
بر اساس هش (Hash-based Sharding)
از هش (Hash) روی Shard Key برای توزیع یکنواخت داده استفاده میشود.
مزیت: توزیع یکنواخت دادهها و جلوگیری از Hotspot.
عیب: افزودن Shard جدید دشوار است چون نیاز به Rehash و انتقال دادهها دارد.
مبتنی بر دایرکتوری (Directory-based Sharding)
از یک Shard Map Directory استفاده میشود که معلوم میکند هر داده در کدام Shard است.
مزیت: انعطافپذیری بالا و امکان تغییر Shard بدون تغییر Shard Key.
عیب: اضافه شدن یک نقطه Failure (Directory) و پیچیدگی مدیریت.
کاهش فشار بر سرورها: هر Shard فقط بخشی از دادهها را مدیریت میکند.
افزایش سرعت Queryها: چون دادهها کمتر هستند، ایندکسها کوچکتر و Query سریعتر اجرا میشود.
افزایش Availability: اگر یک Shard از دسترس خارج شود، Shardهای دیگر همچنان فعال میمانند.
پیچیدگی مدیریت: نگهداری بکاپ، مانیتورینگ، مانیتور Queryها و Migration داده بین Shardها دشوارتر است
Queryهای Cross-Shard سخت و کند هستند: اگر نیاز به Join بین Shardها باشد، Query پیچیده میشود
تعیین Shard Key اشتباه میتواند باعث عدم تعادل شود: اگر Shard Key به درستی انتخاب نشود، یک Shard ممکن است خیلی سنگین و دیگری سبک بماند (Hotspot)
پیادهسازی نیازمند تغییر در لایه اپلیکیشن است: اپلیکیشن باید باید تعین کند هر درخواست به کدام Shard ارسال شود
حجم داده و درخواستها به حدی زیاد شده که دیگر ایندکسینگ و پارتیشنبندی روی یک سرور جوابگو نیست و Scale عمودی (Vertical Scaling) دردی را دوا نمی کند
اپلیکیشن شما دارای الگوی دسترسی به داده قابل تقسیم است (مثلاً کاربران فقط داده خود را میخواهند).
MongoDB
Cassandra
Elasticsearch
Vitess (برای MySQL)
CockroachDB
Amazon DynamoDB
HBase
Redis
Couchbase
YugabyteDB
ممنون که تا این لحظه همراه من بودید. اگر سوال، انتقاد و یا پیشنهادی داشتید خوشحال میشم در بخش کامنت های این مطلب با من درمیون بزارید.