درباره عدم قطعیت در یادگیری ماشین چرا Accuracyبالا کافی نیست ، زمانی که مدل اشتباه میکند ولی سطح اطمینانش به جواب قابل تحسین است .
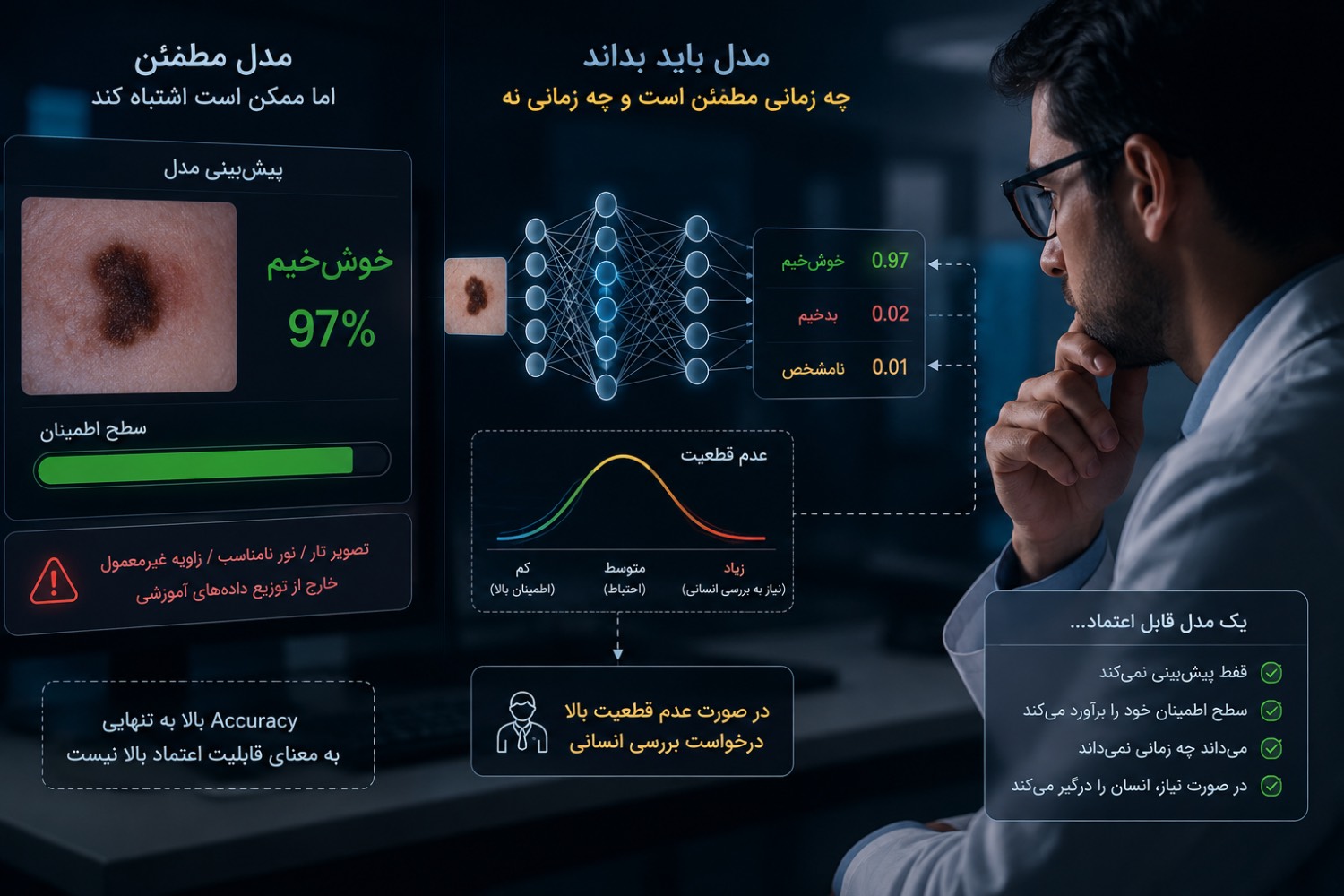
فرض کنید یک مدل تشخیص سرطان پوست روی صدها هزار تصویر آموزش دیده و در آزمونهای استاندارد به دقت ۹۴٪ رسیده است. روی کاغذ، این یک موفقیت چشمگیر به نظر میرسد.
اما پزشکان متوجه نکتهای عجیب میشوند: مدل روی برخی تصاویر با کیفیت پایین، تصاویر تار، نور نامناسب یا زاویههای غیرمعمول، همچنان با اطمینان بسیار بالا پیشبینی میکند. برای تصویری که حتی یک متخصص باتجربه نیز با احتیاط درباره آن نظر میدهد، مدل ممکن است بگوید: «خوشخیم، با احتمال ۹۷٪.»
نکته جالب اینجاست که مسئله صرفاً اشتباه بودن یا نبودن پیشبینی نیست. حتی اگر مدل در نهایت پاسخ درستی داده باشد، این سؤال همچنان مطرح است که آیا میزان اطمینانی که ابراز کرده واقعاً با کیفیت شواهد موجود همخوانی دارد یا نه.
همین فاصله میان «درست بودن» و «برآورد میزان اطمینان نسبت به درستی» در سالهای اخیر به یکی از موضوعات مهم پژوهش در یادگیری ماشین تبدیل شده است.
اگر به تصمیمگیری انسانها نگاه کنیم، معمولاً متخصصان باتجربه فقط نتیجه را اعلام نمیکنند؛ بلکه سطح اطمینان خود را نیز در نظر میگیرند. یک پزشک زمانی که شواهد کافی در اختیار ندارد، آزمایشهای تکمیلی درخواست میکند. یک مهندس سازه در شرایط نامطمئن از ضرایب ایمنی استفاده میکند. به بیان دیگر، بخشی از تخصص به این مربوط میشود که بدانیم چه زمانی اطلاعات کافی نداریم.
بسیاری از مدلهای یادگیری ماشین، دستکم در شکل استاندارد خود، چنین قابلیتی را بهصورت طبیعی در اختیار ندارند.
یکی از محدودیتهای بنیادین بسیاری از مدلهای یادگیری ماشین این است که تقریباً همیشه باید پاسخی تولید کنند. در یک مدل طبقهبندی استاندارد، هدف آموزش این است که برای هر ورودی، برچسب صحیح پیشبینی شود. خروجی مدل معمولاً از طریق تابع Softmax به مجموعهای از احتمالها تبدیل میشود. اما این احتمالها لزوماً بیانگر میزان اطمینان واقعی مدل نیستند.
برای مثال، اگر مدلی که فقط حیوانات رایج را دیده، با تصویری بسیار غیرعادی یا خارج از توزیع آموزشی خود مواجه شود، باز هم معمولاً مجبور است یکی از کلاسهای موجود را انتخاب کند. در چنین شرایطی ممکن است عددی مانند «۷۸٪ احتمال سگ» تولید شود، حتی اگر ورودی اساساً مشابه هیچیک از نمونههای آموزشی نباشد.
به همین دلیل، در بسیاری از کاربردها دیگر نمیتوان احتمال خروجی مدل را بهسادگی معادل میزان اعتمادپذیری آن در نظر گرفت.
این مسئله در حوزههایی مانند پزشکی، خودروهای خودران، سامانههای مالی و سیستمهای تصمیمیار اهمیت ویژهای پیدا میکند؛ زیرا در چنین کاربردهایی، ناتوانی مدل در تشخیص «نمیدانم» میتواند هزینهبر یا حتی خطرناک باشد.
برای درک بهتر موضوع، سه مثال ساده را در نظر بگیرید.
وقتی یک تاس سالم میاندازید، نتیجه ذاتاً تصادفی است. حتی اگر همه چیز را درباره شرایط پرتاب بدانیم، همچنان نتیجه هر بار قابل پیشبینی دقیق نخواهد بود. این نوع عدم قطعیت به خود پدیده مربوط است.
در پیشبینی آبوهوا نیز بخشی از عدم قطعیت از پیچیدگی و رفتار آشوبناک جو ناشی میشود. البته بخشی دیگر میتواند به محدودیت دادهها یا مدلهای پیشبینی مربوط باشد.
حالا پزشکی را تصور کنید که با بیماری نادری مواجه شده که هرگز پیش از این ندیده است. در اینجا بخشی از عدم قطعیت ناشی از کمبود دانش و تجربه است و با اطلاعات بیشتر میتواند کاهش یابد.
این تمایز، ما را به دو نوع اصلی عدم قطعیت در یادگیری ماشین میرساند؛ مفهومی که در سالهای اخیر نقش مهمی در طراحی سامانههای قابل اعتماد پیدا کرده است.
عدم قطعیت ذاتی (Aleatoric Uncertainty)
این نوع عدم قطعیت به نویز، ابهام یا تصادفی بودن خود دادهها مربوط است و حتی با جمعآوری دادههای بیشتر نیز به طور کامل از بین نمیرود. برای مثال، در بسیاری از مسائل مالی، بخشی از نوسانات کوتاهمدت بازار ناشی از عواملی است که ذاتاً پیشبینیناپذیرند. یا در پزشکی، ممکن است یک نمونه واقعاً در مرز میان دو دسته تشخیصی قرار داشته باشد و حتی متخصصان درباره آن به توافق کامل نرسند.
از دیدگاه مدلسازی، هدف معمولاً حذف این نوع عدم قطعیت نیست؛ بلکه تلاش میشود آن را به شکلی مناسب نمایش دهیم. به همین دلیل، در برخی مسائل به جای پیشبینی یک مقدار واحد، توزیع یا بازهای از نتایج ممکن ارائه میشود.
عدم قطعیت معرفتی (Epistemic Uncertainty)
این نوع عدم قطعیت از محدودیت دانش مدل ناشی میشود و معمولاً با دادههای بیشتر، دادههای متنوعتر یا مدلهای بهتر کاهش مییابد.
فرض کنید یک سیستم خودروی خودران عمدتاً در شرایط آبوهوایی آفتابی آموزش دیده باشد. اگر برای نخستین بار با برف سنگین مواجه شود، ممکن است در تشخیص مسیر یا موانع دچار مشکل شود. این مشکل ناشی از کمبود تجربه مدل در چنین شرایطی است.
یا فرض کنید یک مدل پزشکی فقط روی بیماران ۲۰ تا ۶۰ ساله آموزش دیده باشد. اگر با بیماری بسیار مسن مواجه شود، طبیعی است که انتظار داشته باشیم نسبت به پیشبینی خود محتاطتر باشد.
در پژوهشهای یادگیری ماشین، روشهایی مانند Active Learning، شبکههای عصبی بیزی و Monte Carlo Dropout عمدتاً برای برآورد یا کاهش این نوع عدم قطعیت مورد استفاده قرار میگیرند.
به طور کلی، هر زمان مدل با شرایطی مواجه شود که بهخوبی در دادههای آموزشی نمایندگی نشدهاند، معمولاً بخشی از عدم قطعیت مشاهدهشده از نوع معرفتی است.
فرض کنید دو مدل تشخیص تقلب مالی داریم که هر دو روی یک مجموعه آزمون، دقت یکسانی کسب کردهاند.
مدل اول هنگام اعلام «۹۵٪ اطمینان» در عمل فقط در حدود ۶۵٪ مواقع درست است. همچنین روی دادههای غیرمعمول نیز با اطمینان بالا پیشبینی میکند.
مدل دوم هنگام اعلام «۹۵٪ اطمینان» تقریباً در همان حدود درست عمل میکند و هرگاه با نمونههای ناشناخته یا غیرعادی مواجه شود، سطح اطمینان خود را کاهش میدهد و درخواست بررسی انسانی میکند.
اگر فقط Accuracy را ببینیم، این دو مدل تقریباً یکسان به نظر میرسند. اما از منظر قابلیت اعتماد، تفاوت میان آنها بسیار عمیق است.
در بسیاری از کاربردهای واقعی، دانستن اینکه چه زمانی نباید به مدل اعتماد کرد، تقریباً به اندازه خود دقت مدل اهمیت دارد. به همین دلیل، در سالهای اخیر معیارهای مرتبط با عدم قطعیت و کالیبراسیون توجه قابل توجهی در جامعه پژوهشی دریافت کردهاند.
فرض کنید مدلی بارها پیشبینیهایی با اطمینان ۸۰٪ ارائه میکند.
اگر در بلندمدت تقریباً ۸۰٪ این پیشبینیها درست باشند، میگوییم مدل کالیبره است.
نمونهای آشنا از این مفهوم را میتوان در پیشبینی آبوهوا مشاهده کرد. اگر در تمام روزهایی که هواشناس «۷۰٪ احتمال باران» اعلام کرده، تقریباً در ۷۰٪ موارد باران ببارد، میتوان گفت این پیشبینیها بهخوبی کالیبره شدهاند.
در مقابل، یک مدل بیشازحد مطمئن (Overconfident) ممکن است مرتباً احتمالهای بالا اعلام کند، در حالی که نرخ موفقیت واقعی آن بهمراتب کمتر باشد.
یکی از معیارهای رایج برای سنجش این موضوع، Expected Calibration Error یا ECE است. هرچه مقدار این معیار کمتر باشد، همخوانی میان اطمینان اعلامشده و عملکرد واقعی مدل بیشتر خواهد بود.
روشهایی مانند Temperature Scaling، Platt Scaling و Isotonic Regression نیز برای بهبود کالیبراسیون مدلها توسعه یافتهاند و همچنان در بسیاری از سامانههای عملی مورد استفاده قرار میگیرند.
در بسیاری از سامانههای واقعی، مسئله فقط پیشبینی اشتباه نیست؛ بلکه ناتوانی در تشخیص شرایط نامطمئن است. مدل ممکن است با دادههایی مواجه شود که تفاوت قابل توجهی با دادههای آموزشی دارند. اگر سامانه نتواند این وضعیت را تشخیص دهد، ممکن است تصمیمهایی با اطمینان ظاهری بالا اما کیفیت واقعی پایین اتخاذ شود.
نمونههای متعددی در پژوهشهای پزشکی نشان دادهاند که مدلهایی با عملکرد مطلوب در یک بیمارستان، پس از انتقال به بیمارستانی دیگر و مواجهه با جمعیت بیمار متفاوت یا پروتکلهای متفاوت، عملکرد ضعیفتری پیدا میکنند.
این پدیده که معمولاً با عنوان Distribution Shift شناخته میشود، یکی از چالشهای مهم استقرار مدلهای یادگیری ماشین در محیطهای واقعی به شمار میرود.
با ظهر مدلهای زبانی بزرگ، موضوع عدم قطعیت اهمیت بیشتری پیدا کرده است.
این مدلها معمولاً پاسخها را به صورت متن تولید میکنند و برخلاف بسیاری از مدلهای طبقهبندی، سطح اطمینان آماری خود را مستقیماً نمایش نمیدهند.
نکته مهم اینجاست که عباراتی مانند «فکر میکنم»، «احتمالاً» یا «مطمئن نیستم» لزوماً بازتاب دقیقی از عدم قطعیت درونی مدل نیستند. این عبارات بخشی از الگوهای زبانی آموختهشدهاند و به تنهایی نمیتوانند مبنای مناسبی برای ارزیابی اعتمادپذیری پاسخ باشند.
برای تخمین عدم قطعیت در مدلهای زبانی، پژوهشگران از روشهای مختلفی استفاده میکنند:
Ensemble Methods
Monte Carlo Dropout
Bayesian Deep Learning
Conformal Prediction
همچنین برخی مطالعات نشان دادهاند که مقایسه پاسخهای متعدد مدل به یک سؤال میتواند اطلاعاتی درباره میزان پایداری پاسخ فراهم کند. البته پایداری پاسخ الزاماً به معنای درست بودن آن نیست؛ یک مدل میتواند بارها با اطمینان کامل همان پاسخ اشتباه را تکرار کند.
در بسیاری از کاربردهای واقعی، موفقیت یک مدل فقط به دقت آن وابسته نیست.
مدلی که بتواند شرایط نامطمئن را تشخیص دهد، محدودیتهای خود را بشناسد و در مواقع لازم درخواست بررسی انسانی کند، معمولاً از مدلی که همیشه با اطمینان بالا پاسخ میدهد قابل اعتمادتر است.
شاید یکی از مهمترین درسهایی که در سالهای اخیر از استقرار مدلهای یادگیری ماشین در دنیای واقعی آموختهایم همین باشد: یک سیستم هوشمند فقط نباید پاسخهای خوب تولید کند؛ بلکه باید بداند در چه شرایطی نباید به پاسخ خود بیش از حد اعتماد کند.
به همین دلیل، ارزیابی عدم قطعیت و کالیبراسیون امروز دیگر صرفاً یک موضوع پژوهشی حاشیهای نیست، بلکه به بخشی جداییناپذیر از توسعه و استقرار سامانههای یادگیری ماشین، بهویژه در حوزههای حساس و پرریسک، تبدیل شده است