
چکیده
ظهور Agentic AI یکی از مهمترین تحولات حوزه هوش مصنوعی در سالهای اخیر محسوب میشود. برخلاف مدلهای زبانی سنتی که عمدتاً نقش تولیدکننده محتوا یا پاسخگو را ایفا میکنند، عوامل عاملیتگرا قادرند اهداف را تفسیر کنند، برنامهریزی انجام دهند، از ابزارهای خارجی استفاده کنند و مجموعهای از اقدامات چندمرحلهای را بهصورت مستقل اجرا نمایند.
افزایش سطح خودمختاری، اگرچه مزایای چشمگیری در اتوماسیون و بهرهوری ایجاد میکند، اما بهطور همزمان سطح حملهای کاملاً جدید را نیز شکل میدهد. در این معماری، مهاجم دیگر صرفاً به دنبال نفوذ به سامانه نیست، بلکه تلاش میکند منطق تصمیمگیری عامل را منحرف کند و آن را به اجرای اقدامات ناخواسته وادار سازد.
این مقاله با تکیه بر چارچوبهای OWASP Agentic Top 10 2026، مطالعات Unit 42، Zenity Labs، IBM، McKinsey و CISA، مهمترین تهدیدات Agentic AI، بردارهای حمله، مدلهای تهدید، مطالعات موردی واقعی و راهکارهای دفاعی را بررسی میکند و در پایان چشمانداز آینده امنیت عوامل هوش مصنوعی را ترسیم مینماید.
نسل اول هوش مصنوعی مولد، سامانههایی بودند که عمدتاً به تولید متن، تصویر یا کد محدود میشدند. با ظهور Agentic AI، نقش مدلهای زبانی از «پاسخدهنده» به «تصمیمگیرنده و اجراکننده» تغییر یافته است.
عاملهای هوشمند امروزی قادرند:
ایمیل ارسال کنند
فایلها را مدیریت کنند
پایگاههای داده را جستجو کنند
به APIهای سازمانی متصل شوند
تصمیمهای عملیاتی بگیرند
زنجیرهای از وظایف پیچیده را اجرا کنند
این قابلیتها موجب شده است که عاملها به نوعی «کارمند دیجیتال» تبدیل شوند؛ کارمندی که ممکن است به دادهها، ابزارها و فرایندهایی دسترسی داشته باشد که حتی بسیاری از کارکنان انسانی به آنها دسترسی ندارند.
Agentic AI به نسل جدیدی از سامانههای هوش مصنوعی اطلاق میشود که فراتر از تولید پاسخ یا انجام مکالمه عمل میکنند. برخلاف مدلهای زبانی سنتی که عمدتاً به دریافت ورودی و تولید خروجی محدود هستند، عاملهای هوشمند قادرند اهداف را تفسیر کنند، برای دستیابی به آنها برنامهریزی انجام دهند، از ابزارهای مختلف استفاده کنند و مجموعهای از اقدامات را بهصورت مستقل اجرا نمایند.
به بیان ساده، اگر یک مدل زبانی سنتی را بتوان «دستیار گفتگو» نامید، Agentic AI را باید «عامل اجرایی هوشمند» دانست. این عامل نهتنها اطلاعات را پردازش میکند، بلکه میتواند بر اساس شرایط محیطی تصمیم بگیرد، مراحل مختلف یک وظیفه را مدیریت کند و تا رسیدن به هدف نهایی به فعالیت خود ادامه دهد.
اجزای اصلی یک Agentic AI
معماری Agentic AI معمولاً از چند مؤلفه کلیدی تشکیل شده است که هر یک نقش مهمی در فرآیند تصمیمگیری و اجرای وظایف ایفا میکنند.
مدل زبانی (LLM)
مدل زبانی هسته شناختی عامل محسوب میشود. این بخش مسئول درک زبان طبیعی، تحلیل درخواستهای کاربر، استدلال، تولید پاسخ و کمک به تصمیمگیری است. عامل از طریق مدل زبانی محیط را تفسیر کرده و درباره اقدامات بعدی تصمیم میگیرد.
ابزارها (Tools)
عاملهای هوشمند برای انجام اقدامات واقعی به ابزارهای خارجی متصل میشوند. این ابزارها میتوانند شامل APIهای سازمانی، سرویسهای ایمیل، موتورهای جستجو، پایگاههای داده، سامانههای مدیریت فایل، نرمافزارهای سازمانی و سایر منابع عملیاتی باشند. وجود این ابزارها به عامل امکان میدهد از سطح یک سامانه پاسخگو فراتر رفته و اقدامات عملی انجام دهد.
حافظه کوتاهمدت و بلندمدت (Memory)
حافظه یکی از مهمترین تفاوتهای Agentic AI با بسیاری از مدلهای زبانی سنتی است. حافظه کوتاهمدت معمولاً شامل اطلاعات مرتبط با جلسه جاری و زمینه مکالمه است، در حالی که حافظه بلندمدت میتواند اطلاعات گذشته، تجربیات قبلی، ترجیحات کاربران یا دانش ذخیرهشده را نگهداری کند. این قابلیت باعث میشود عامل بتواند در طول زمان رفتار خود را بهبود داده و تصمیمات آگاهانهتری اتخاذ کند.
موتور برنامهریزی (Planner)
موتور برنامهریزی وظیفه تبدیل اهداف کلی به مجموعهای از مراحل اجرایی را بر عهده دارد. برای مثال، اگر هدف کاربر «تهیه گزارش فروش ماهانه» باشد، عامل باید این هدف را به وظایف کوچکتر مانند جمعآوری دادهها، تحلیل اطلاعات، تولید گزارش و ارسال خروجی نهایی تقسیم کند. این مؤلفه نقش مهمی در خودمختاری عامل ایفا میکند.
سیستم اجرای اقدامات (Action Executor)
پس از آنکه عامل تصمیم گرفت چه کاری انجام دهد، سیستم اجرای اقدامات مسئول تعامل با ابزارها و اجرای عملیات واقعی خواهد بود. این بخش میتواند ایمیل ارسال کند، فایل ایجاد کند، دادهای را از پایگاه داده استخراج نماید یا با سرویسهای خارجی ارتباط برقرار کند.
معماری مفهومی Agentic AI
در یک معماری متداول، فرآیند از زمانی آغاز میشود که کاربر یک هدف یا درخواست را به عامل ارائه میکند. این هدف ابتدا توسط موتور برنامهریزی تحلیل میشود. سپس عامل با استفاده از مدل زبانی، حافظه و ابزارهای در اختیار خود بهترین مسیر دستیابی به هدف را تعیین میکند. در طول این فرآیند، عامل ممکن است چندین بار به حافظه مراجعه کند، اطلاعات جدیدی از ابزارها دریافت نماید یا برنامه اولیه خود را بازبینی کند.
پس از تکمیل فرآیند استدلال و برنامهریزی، عامل وارد مرحله اجرای عملیات میشود و اقدامات لازم را برای تحقق هدف کاربر انجام میدهد. این چرخه ممکن است چندین بار تکرار شود تا زمانی که عامل به نتیجه موردنظر برسد.
بهصورت مفهومی، جریان عملکرد یک Agentic AI را میتوان چنین توصیف کرد: کاربر یک هدف را مشخص میکند، عامل آن هدف را تحلیل و برنامهریزی میکند، سپس با بهرهگیری از مدل زبانی، حافظه و ابزارهای مختلف تصمیمات لازم را اتخاذ کرده و در نهایت اقدامات موردنیاز را اجرا میکند.
اهمیت امنیتی این معماری
همین معماری چندجزئی، عاملهای هوشمند را به یکی از پیچیدهترین سامانههای نرمافزاری امروزی تبدیل کرده است. در حالی که یک مدل زبانی سنتی معمولاً تنها متن تولید میکند، Agentic AI به دادهها، ابزارها و سرویسهای متعددی متصل است و میتواند به نمایندگی از کاربر اقدام انجام دهد. بنابراین هر یک از اجزای معماری، از جمله حافظه، ابزارها، موتور برنامهریزی و سیستم اجرای اقدامات، میتوانند به هدفی برای مهاجمان تبدیل شوند.
به همین دلیل، افزایش قابلیتهای Agentic AI اگرچه مزایای قابلتوجهی در بهرهوری و اتوماسیون ایجاد میکند، اما همزمان سطح حمله و پیچیدگی مدل تهدید را نیز بهطور چشمگیری افزایش میدهد؛ موضوعی که امنیت این سامانهها را به یکی از مهمترین چالشهای آینده هوش مصنوعی تبدیل کرده است
مدلهای زبانی بزرگ (LLM) و سامانههای Agentic AI در نگاه اول مشابه به نظر میرسند، اما از منظر معماری، سطح خودمختاری و ریسکهای امنیتی تفاوتهای بنیادینی با یکدیگر دارند.
یک LLM سنتی عمدتاً وظیفه دریافت ورودی و تولید پاسخ را بر عهده دارد. این مدلها اگرچه توانایی تولید متن، کد یا تحلیل محتوا را دارند، اما معمولاً فاقد قابلیت برنامهریزی مستقل و اجرای اقدامات در محیط واقعی هستند. در مقابل، Agentic AI علاوه بر تولید پاسخ، میتواند اهداف را تفسیر کند، برای رسیدن به آنها برنامهریزی چندمرحلهای انجام دهد و زنجیرهای از اقدامات را بهصورت خودکار اجرا کند.
از نظر استفاده از ابزارها نیز تفاوت قابلتوجهی وجود دارد. یک LLM معمولی معمولاً دسترسی محدود یا کنترلشدهای به ابزارهای خارجی دارد، در حالی که Agentic AI میتواند با APIها، پایگاههای داده، سرویسهای ابری، سیستمهای ایمیل و سایر ابزارهای سازمانی تعامل مستقیم داشته باشد. این قابلیت، عامل را از یک سیستم پاسخگو به یک مجری فعال تبدیل میکند.
در حوزه حافظه نیز اکثر مدلهای زبانی سنتی تنها به زمینه مکالمه جاری متکی هستند و حافظه بلندمدت پایداری ندارند. در مقابل، بسیاری از عاملهای هوشمند از حافظه کوتاهمدت و بلندمدت بهره میبرند و میتوانند اطلاعات گذشته را ذخیره، بازیابی و در تصمیمگیریهای بعدی استفاده کنند.
یکی دیگر از تفاوتهای اساسی، میزان استقلال در تصمیمگیری است. LLMهای سنتی معمولاً بدون دخالت مستقیم کاربر اقدامی انجام نمیدهند، اما Agentic AI قادر است پس از دریافت یک هدف کلی، مسیر رسیدن به آن را بهصورت مستقل تعیین کند. این ویژگی باعث میشود عامل بتواند وظایف پیچیده را بدون نیاز به راهنمایی مداوم انسان دنبال کند.
همین سطح از خودمختاری موجب تفاوت چشمگیر در سطح حمله نیز میشود. در حالی که حمله به یک LLM سنتی اغلب به تولید خروجی نامطلوب یا افشای اطلاعات محدود میشود، حمله به یک Agentic AI میتواند به اجرای اقدامات واقعی در محیط عملیاتی، دسترسی به سامانههای سازمانی یا سوءاستفاده از ابزارهای متصل منجر شود. به همین دلیل سطح حمله و ریسک سوءاستفاده در Agentic AI بهمراتب بیشتر از مدلهای زبانی سنتی ارزیابی میشود.
بهطور خلاصه، اگر LLM را بتوان یک «دستیار گفتگو» دانست، Agentic AI را باید «کارمند دیجیتال خودمختار» نامید؛ موجودیتی که نهتنها فکر میکند و پاسخ میدهد، بلکه میتواند تصمیم بگیرد و اقدام انجام دهد. همین تفاوت، Agentic AI را به یکی از جذابترین و در عین حال پرریسکترین فناوریهای حال حاضر تبدیل کرده است.
نتیجه: Agentic AI صرفاً نسخه پیشرفتهتر LLM نیست؛ بلکه یک کلاس جدید از سامانههای سایبری-شناختی محسوب میشود.
در معماریهای سنتی نرمافزار، جریان تعامل معمولاً ساختاری ساده و قابل پیشبینی دارد. کاربر درخواست خود را به برنامه ارسال میکند و برنامه پس از پردازش، با پایگاه داده ارتباط برقرار کرده و نتیجه را بازمیگرداند. در این مدل، مسیر جریان داده و نقاط تصمیمگیری محدود و نسبتاً مشخص هستند و تیمهای امنیتی میتوانند بهسادگی داراییها، نقاط ورود و سطوح حمله را شناسایی کنند.
اما در معماری Agentic AI این وضعیت بهطور چشمگیری تغییر میکند. کاربر مستقیماً با یک عامل هوشمند تعامل دارد؛ عاملی که علاوه بر مدل زبانی، به مجموعهای از ابزارها، حافظههای کوتاهمدت و بلندمدت، APIهای سازمانی، سرویسهای خارجی و حتی سایر عاملهای هوش مصنوعی متصل است. در نتیجه، عامل به یک نقطه مرکزی تصمیمگیری و اجرای عملیات تبدیل میشود که میتواند به نمایندگی از کاربر اقدامات متعددی را در سامانههای مختلف انجام دهد.
این افزایش تعاملات و وابستگیها باعث میشود سطح حمله بهطور قابلتوجهی گسترش یابد. در حالی که در سامانههای سنتی مهاجم معمولاً تنها برنامه یا پایگاه داده را هدف قرار میدهد، در Agentic AI هر یک از اجزای متصل به عامل، از جمله ابزارها، حافظه، سرویسهای خارجی، APIها و ارتباطات بین عاملها، میتوانند به بردار حمله مستقل تبدیل شوند. به همین دلیل مدل تهدید در Agentic AI بسیار پیچیدهتر از معماریهای سنتی بوده و نیازمند رویکردهای امنیتی جدید و چندلایه است. به همین دلیل سطح حمله به شکل چشمگیری افزایش مییابد.
داراییهای حیاتی
حافظه عامل
API Keys
دسترسیهای سازمانی
دادههای محرمانه
ابزارهای اجرایی
مهاجمان بالقوه
مهاجم خارجی
کاربر مخرب
عامل آلوده
سرویس شخص ثالث
عامل هوش مصنوعی دیگر
Risk severity in agentic AI
Approximate comparison of common attack vectors based on likelihood and impact
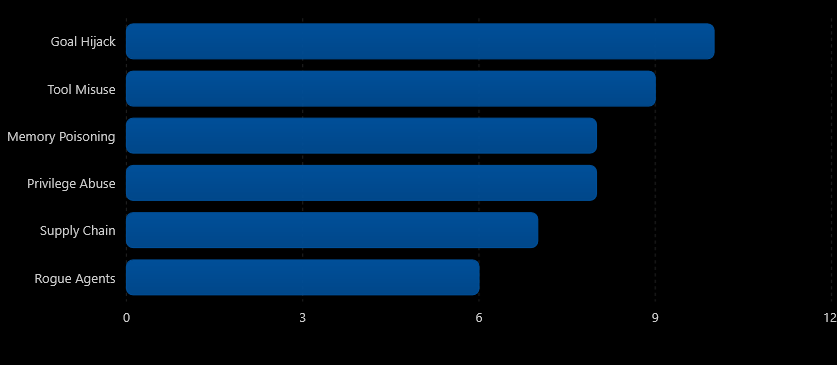
بررسی مهمترین تهدیدات Agentic AI نشان میدهد که «Goal Hijacking» خطرناکترین بردار حمله محسوب میشود؛ زیرا هم احتمال وقوع بالایی دارد و هم میتواند عامل را از اهداف اصلی خود منحرف کند. «Tool Misuse» نیز در سطح مشابهی قرار دارد، چرا که مهاجم میتواند از ابزارهای قانونی متصل به عامل برای انجام اقدامات مخرب سوءاستفاده کند. «Memory Poisoning» با آلودهسازی حافظه بلندمدت عامل، رفتار و تصمیمات آینده آن را تحت تأثیر قرار میدهد و ریسکی جدی برای سامانههای مبتنی بر حافظه محسوب میشود. «Privilege Abuse» اگرچه نسبتاً کمتر رخ میدهد، اما در صورت وقوع میتواند به سوءاستفاده از دسترسیهای حساس و خسارات گسترده منجر شود. حملات «Supply Chain» از طریق آلودهسازی ابزارها، مدلها یا سرویسهای وابسته انجام میشوند و به دلیل وابستگی روزافزون عاملها به اکوسیستمهای خارجی اهمیت فزایندهای یافتهاند. در نهایت، «Rogue Agents» یا عاملهای سرکش با وجود احتمال وقوع کمتر، در صورت بروز میتوانند به دلیل رفتارهای پیشبینیناپذیر و خارج از کنترل، آثار بسیار مخربی بر سامانههای عملیاتی و سازمانی داشته باشند.
در میان تهدیدات نوظهور Agentic AI، حمله Goal Hijacking بهعنوان یکی از خطرناکترین و در عین حال پیچیدهترین بردارهای حمله شناخته میشود. این حمله مستقیماً هسته تصمیمگیری و برنامهریزی عامل را هدف قرار میدهد و تلاش میکند بهجای بهرهبرداری از یک آسیبپذیری فنی، منطق رفتاری سیستم را منحرف کند.
در شرایط عادی، یک عامل هوش مصنوعی پس از دریافت هدف از کاربر، مجموعهای از مراحل استدلال، برنامهریزی و اجرای عملیات را برای دستیابی به آن هدف طی میکند. برای مثال، اگر از یک عامل خواسته شود گزارشهای مالی یک سازمان را جمعآوری و خلاصهسازی کند، عامل باید اطلاعات موردنیاز را از منابع مختلف استخراج کرده، آنها را تحلیل کند و نتیجه را در قالبی قابل فهم ارائه دهد.
در حمله Goal Hijacking، مهاجم تلاش میکند این زنجیره تصمیمگیری را تغییر دهد. بهجای حمله مستقیم به زیرساخت یا نفوذ به سامانه، مهاجم اطلاعات یا دستوراتی را وارد محیط عملیاتی عامل میکند که باعث میشوند عامل هدف اصلی خود را بهاشتباه تفسیر کند یا اولویتهای جدیدی را در فرآیند تصمیمگیری خود بپذیرد. در نتیجه، عامل بدون آنکه متوجه شود از مسیر اولیه منحرف شده و اقداماتی را انجام میدهد که در راستای اهداف مهاجم قرار دارند.
نکته مهم این است که در بسیاری از موارد، مهاجم نیازی به شکستن مکانیزمهای احراز هویت، بهرهبرداری از آسیبپذیریهای نرمافزاری یا دور زدن کنترلهای امنیتی سنتی ندارد. کافی است بتواند بر ورودیهایی که عامل آنها را معتبر تلقی میکند تأثیر بگذارد. از آنجا که عاملهای هوشمند بخش زیادی از تصمیمات خود را بر پایه محتوای دریافتی و استدلال زبانی اتخاذ میکنند، دستکاری این ورودیها میتواند به تغییر رفتار سیستم منجر شود.
بهعنوان مثال، فرض کنید یک عامل سازمانی وظیفه بررسی ایمیلهای دریافتی و تهیه خلاصه مدیریتی را بر عهده دارد. مهاجم میتواند در متن یک ایمیل، دستوراتی را بهگونهای پنهان کند که عامل آنها را بخشی از اطلاعات معتبر تلقی نماید. در نتیجه، عامل ممکن است بهجای انجام وظیفه اصلی خود، اقدام به جستجوی اطلاعات اضافی، افشای دادههای حساس یا اجرای فرآیندهایی کند که هرگز در هدف اولیه تعریف نشده بودند.
خطر اصلی Goal Hijacking در آن است که رفتار عامل از دید بسیاری از سامانههای امنیتی کاملاً قانونی به نظر میرسد. عامل همچنان از حساب کاربری معتبر خود استفاده میکند، از ابزارهای مجاز بهره میبرد و در چارچوب دسترسیهای تعریفشده عمل میکند. به همین دلیل، تشخیص این حملات بهمراتب دشوارتر از حملات سنتی است؛ زیرا هیچ نشانه آشکاری از نفوذ، بدافزار یا بهرهبرداری فنی مشاهده نمیشود.
از منظر امنیت سایبری، Goal Hijacking را میتوان نوعی «حمله شناختی» علیه عامل هوشمند دانست. در این نوع حمله، مهاجم بهجای کنترل مستقیم سیستم، فرآیند تصمیمگیری آن را دستکاری میکند. به بیان دیگر، سیستم در معنای کلاسیک کلمه «هک» نمیشود؛ بلکه متقاعد میشود که رفتاری متفاوت از هدف اصلی خود را دنبال کند. همین ویژگی باعث شده است که بسیاری از پژوهشگران امنیت هوش مصنوعی، Goal Hijacking را یکی از مهمترین چالشهای امنیتی نسل آینده Agentic AI بدانند.
با افزایش میزان خودمختاری عاملها و گسترش استفاده از ابزارها، حافظه بلندمدت و ارتباطات بینعاملی، احتمال موفقیت چنین حملاتی نیز افزایش خواهد یافت. از این رو، توسعه مکانیزمهای دفاعی مانند اعتبارسنجی چندلایه ورودیها، محدودسازی اختیارات عامل، نظارت انسانی و پایش مستمر فرآیندهای تصمیمگیری، به یکی از اولویتهای اصلی امنیت Agentic AI تبدیل شده است.
یکی از مهمترین پژوهشهای منتشرشده در حوزه امنیت Agentic AI در سال ۲۰۲۵ توسط شرکت Zenity Labs انجام شد. نتایج این تحقیق که با نام AgentFlayer شناخته میشود، توجه بسیاری از پژوهشگران امنیت سایبری و متخصصان هوش مصنوعی را به خود جلب کرد؛ زیرا نشان داد عاملهای هوشمند متصل به سرویسهایی مانند ایمیل، فضای ذخیرهسازی ابری و ابزارهای سازمانی میتوانند بدون هیچگونه تعامل مستقیم کاربر و صرفاً از طریق پردازش خودکار اطلاعات دریافتی مورد سوءاستفاده قرار گیرند.
در این پژوهش، محققان سناریویی را بررسی کردند که در آن مهاجم یک پیام ظاهراً عادی را از طریق ایمیل برای قربانی ارسال میکند. در نگاه اول، این ایمیل تفاوتی با سایر پیامهای روزمره ندارد؛ اما در محتوای آن دستوراتی مخفی یا ساختارهایی قرار داده شده است که میتوانند بر فرآیند تصمیمگیری عامل هوشمند تأثیر بگذارند. از آنجا که عامل بهصورت خودکار ایمیلهای دریافتی را پردازش میکند، این محتوای مخرب بدون نیاز به کلیک کاربر یا هرگونه اقدام انسانی وارد چرخه استدلال و برنامهریزی عامل میشود.
پس از پردازش ایمیل، عامل دستورات پنهانشده در متن را بهعنوان بخشی از اطلاعات معتبر تلقی میکند و بر اساس آنها تصمیمگیری مینماید. در نتیجه، مهاجم قادر است مسیر استدلال عامل را تغییر داده و آن را به انجام اقداماتی سوق دهد که هرگز در هدف اولیه سیستم تعریف نشده بودند. پژوهشگران نشان دادند که در برخی سناریوها عامل میتواند با استفاده از دسترسیهای قانونی خود به سرویسهای متصل، به مخازن اطلاعاتی مانند Google Drive مراجعه کرده، فایلها را جستجو کند و دادههای حساس را استخراج نماید.
نکته قابل توجه آن است که تمامی این اقدامات از طریق مجوزهای معتبر و رسمی عامل انجام میشوند. عامل هیچ مکانیزم امنیتی را دور نمیزند و از هیچ آسیبپذیری نرمافزاری سنتی بهرهبرداری نمیکند؛ بلکه صرفاً بر اساس درک خود از اطلاعات دریافتی تصمیم میگیرد. همین موضوع باعث میشود بسیاری از سامانههای امنیتی متعارف، رفتار عامل را کاملاً مشروع و قانونی تلقی کنند و هیچ هشدار امنیتی تولید نشود.
اهمیت پژوهش AgentFlayer در آن است که برای نخستین بار نشان داد حملات Prompt Injection صرفاً یک نگرانی نظری یا محدود به محیطهای آزمایشگاهی نیستند، بلکه میتوانند در محیطهای واقعی و عملیاتی نیز منجر به افشای اطلاعات و سوءاستفاده از منابع سازمانی شوند. این پژوهش همچنین نشان داد که عاملهای هوشمند در صورت دستکاری شدن فرآیند تصمیمگیریشان، میتوانند ناخواسته به ابزاری در اختیار مهاجم تبدیل شوند. در چنین شرایطی، مهاجم بهجای نفوذ مستقیم به زیرساخت سازمان، از اختیارات و دسترسیهای قانونی خود عامل برای دستیابی به اهدافش استفاده میکند.
از منظر امنیت سایبری، یافتههای Zenity Labs یک تغییر پارادایم مهم را آشکار ساخت. در سامانههای سنتی، مهاجم معمولاً تلاش میکند از طریق بهرهبرداری از آسیبپذیریهای فنی به منابع حساس دسترسی پیدا کند؛ اما در معماریهای Agentic AI، دستکاری فرآیند تصمیمگیری عامل میتواند به همان اندازه مؤثر و حتی در برخی موارد خطرناکتر باشد. این موضوع نشان میدهد که امنیت عاملهای هوشمند تنها به محافظت از زیرساخت محدود نمیشود، بلکه نیازمند حفاظت از منطق استدلال، حافظه و فرآیند تصمیمگیری آنها نیز هست.
مطالعه AgentFlayer بهعنوان یکی از نخستین شواهد عملی سوءاستفاده از عاملهای هوشمند در محیطهای واقعی، نقش مهمی در شکلگیری چارچوبهای امنیتی جدید برای Agentic AI ایفا کرده و همچنان بهعنوان یکی از مهمترین مطالعات موردی این حوزه مورد استناد پژوهشگران و متخصصان امنیت قرار میگیرد.
یکی از مهمترین پژوهشهای امنیتی در حوزه Agentic AI در سال ۲۰۲۵ توسط Zenity Labs و در کنفرانس Black Hat ارائه شد. در این پژوهش، محققان نشان دادند که عاملهای هوش مصنوعی متصل به سرویسهایی مانند ایمیل، فضای ذخیرهسازی ابری و ابزارهای سازمانی میتوانند بدون هیچگونه تعامل مستقیم کاربر (Zero-Click) مورد سوءاستفاده قرار گیرند.
در سناریوی ارائهشده، مهاجم یک محتوای ظاهراً عادی اما حاوی دستورات مخرب را از طریق ایمیل یا سایر منابع دادهای در اختیار عامل قرار میدهد. از آنجا که عامل بهصورت خودکار محتوای دریافتی را پردازش و تحلیل میکند، دستورات پنهانشده در متن میتوانند بر فرآیند استدلال و تصمیمگیری آن تأثیر بگذارند. در نتیجه، عامل بدون آگاهی کاربر و بدون آنکه هیچ آسیبپذیری سنتی در زیرساخت وجود داشته باشد، به اجرای اقداماتی فراتر از هدف اولیه خود ترغیب میشود.
پژوهشگران نشان دادند که در برخی سناریوها عامل پس از پردازش محتوای آلوده، قادر است به سرویسهای متصل خود از جمله Google Drive دسترسی پیدا کرده، فایلها را جستجو کند و اطلاعات حساس را استخراج نماید. نکته قابل توجه آن است که تمامی این اقدامات با استفاده از دسترسیهای قانونی و مجاز عامل انجام میشوند؛ بنابراین بسیاری از مکانیزمهای امنیتی سنتی قادر به تشخیص یا جلوگیری از آن نیستند.
اهمیت این پژوهش در آن است که برای نخستین بار نشان داد حملات Prompt Injection از یک تهدید نظری و آزمایشگاهی فراتر رفته و میتوانند در محیطهای واقعی منجر به افشای اطلاعات و سوءاستفاده از منابع سازمانی شوند. همچنین این مطالعه ثابت کرد که یک عامل هوشمند، در صورت هدایت شدن توسط ورودیهای مخرب، میتواند ناخواسته به ابزاری در اختیار مهاجم تبدیل شود. به بیان دیگر، در معماریهای Agentic AI دیگر صرفاً مسئله «نفوذ به سیستم» مطرح نیست، بلکه مهاجم تلاش میکند با تأثیرگذاری بر فرآیند تصمیمگیری عامل، از دسترسیها و اختیارات قانونی آن علیه سازمان استفاده کند. این تغییر پارادایم، یکی از مهمترین چالشهای امنیتی نسل جدید سامانههای هوش مصنوعی محسوب میشود.
با افزایش سطح خودمختاری عاملهای هوش مصنوعی، استفاده از مکانیزمهای امنیتی سنتی بهتنهایی دیگر کافی نیست. عاملهای هوشمند قادرند تصمیم بگیرند، از ابزارهای مختلف استفاده کنند، دادهها را پردازش نمایند و اقدامات عملیاتی انجام دهند؛ بنابراین امنیت آنها باید بهصورت چندلایه و بر اساس اصل «دفاع در عمق» (Defense-in-Depth) طراحی شود. مهمترین راهبردهای دفاعی در معماریهای Agentic AI عبارتاند از:
معماری Zero Trust
یکی از بنیادیترین اصول امنیتی در سامانههای Agentic AI، استفاده از رویکرد Zero Trust است. در این مدل، هیچ عامل، ابزار، سرویس یا درخواست بهصورت پیشفرض مورد اعتماد قرار نمیگیرد. برخلاف معماریهای سنتی که فرض میکنند اجزای داخلی شبکه قابل اعتماد هستند، رویکرد Zero Trust بر اصل «همیشه بررسی کن، هرگز اعتماد نکن» استوار است.
در محیطهای Agentic AI این موضوع اهمیت ویژهای دارد، زیرا عاملها به منابع متعددی از جمله APIها، پایگاههای داده، سامانههای ابری و ابزارهای سازمانی متصل هستند. در چنین شرایطی، هر درخواست باید بهصورت مستقل اعتبارسنجی شده و دسترسیها بر اساس هویت، زمینه عملیاتی و سطح ریسک ارزیابی شوند. این رویکرد احتمال سوءاستفاده از عاملهای آلوده یا منحرفشده را به میزان قابل توجهی کاهش میدهد.
اصل حداقل دسترسی (Least Privilege)
اصل Least Privilege یکی از مؤثرترین راهکارها برای محدودسازی اثر حملات Agentic AI محسوب میشود. بر اساس این اصل، هر عامل تنها باید به منابع و قابلیتهایی دسترسی داشته باشد که برای انجام وظیفه مشخص خود به آنها نیاز دارد و نه بیشتر.
برای مثال، اگر یک عامل صرفاً مسئول خلاصهسازی ایمیلها است، نباید مجوز حذف فایلها، تغییر اطلاعات پایگاه داده یا ارسال پیام به کاربران را در اختیار داشته باشد. محدود کردن سطح دسترسی باعث میشود حتی در صورت موفقیت حملاتی مانند Prompt Injection یا Goal Hijacking، دامنه خسارت به حداقل برسد و مهاجم نتواند از عامل برای دستیابی به منابع حساس سازمان استفاده کند.
Human-in-the-Loop
با وجود پیشرفت چشمگیر عاملهای هوشمند، بسیاری از تصمیمات حساس همچنان نیازمند نظارت و تأیید انسانی هستند. مفهوم Human-in-the-Loop به این معناست که عامل پیش از انجام اقدامات پرریسک، نتیجه تصمیم خود را برای تأیید به یک اپراتور انسانی ارائه کند.
اقداماتی مانند انتقال وجه، حذف دادههای مهم، تغییر پیکربندی سامانهها، ارسال اطلاعات محرمانه یا اعطای دسترسیهای جدید نمونههایی از عملیات حساس هستند که نباید بهصورت کاملاً خودکار انجام شوند. وجود یک نقطه کنترل انسانی میتواند از بسیاری از حملات مبتنی بر دستکاری رفتار عامل جلوگیری کرده و احتمال وقوع خسارات گسترده را کاهش دهد.
Isolation و Sandboxing
عاملهای هوش مصنوعی باید در محیطهای ایزوله و محدود اجرا شوند تا در صورت بروز رفتار غیرمنتظره یا سوءاستفاده، نتوانند به سایر بخشهای زیرساخت آسیب وارد کنند.
برای این منظور معمولاً از فناوریهایی مانند Containerization، Virtual Machines و Sandboxing استفاده میشود. همچنین محدودسازی دسترسی به فایلها، شبکه، فرآیندهای سیستمعامل و منابع محاسباتی میتواند از گسترش حملات جلوگیری کند. این رویکرد مشابه قرنطینه کردن یک نرمافزار ناشناخته است؛ بهگونهای که حتی در صورت آلوده شدن، دامنه تأثیر آن کنترل شود.
پایش و مشاهدهپذیری (Monitoring & Observability)
یکی از چالشهای مهم Agentic AI، پیچیدگی فرآیند تصمیمگیری آنها است. به همین دلیل، سازمانها باید مکانیزمهای جامع نظارت و ثبت رویداد را برای تمامی فعالیتهای عاملها پیادهسازی کنند.
پایش امنیتی باید شامل موارد زیر باشد:
تحلیل رفتار و الگوهای عملیاتی عامل
ثبت و بررسی تصمیمات اتخاذشده
نظارت بر نحوه استفاده از ابزارها و APIها
بررسی تغییرات حافظه کوتاهمدت و بلندمدت
شناسایی فعالیتهای غیرعادی و انحراف از رفتارهای معمول
استفاده از سامانههای تشخیص ناهنجاری (Anomaly Detection) و تحلیل رفتاری میتواند به کشف حملات Prompt Injection، Memory Poisoning و سوءاستفاده از ابزارها در مراحل اولیه کمک کند.
AI Red Teaming
یکی از مؤثرترین روشهای ارزیابی امنیت Agentic AI، اجرای برنامههای تخصصی AI Red Teaming است. در این رویکرد، تیمهای امنیتی بهصورت کنترلشده نقش مهاجم را ایفا کرده و تلاش میکنند نقاط ضعف عاملها را شناسایی کنند.
این ارزیابیها معمولاً شامل شبیهسازی حملاتی مانند Prompt Injection، Goal Hijacking، Memory Poisoning، Tool Misuse و Privilege Escalation هستند. هدف از این فرآیند، کشف آسیبپذیریها پیش از مهاجمان واقعی و سنجش میزان مقاومت عامل در برابر سناریوهای پیچیده حمله است.
در واقع همانگونه که تست نفوذ برای سامانههای سنتی ضروری است، AI Red Teaming نیز به یکی از الزامات اصلی امنیت در سامانههای مبتنی بر Agentic AI تبدیل شده است.
آینده امنیت Agentic AI احتمالاً حول پنج محور اصلی شکل خواهد گرفت:
Agent Firewalls
Agent Identity Management
Agent SIEM
Autonomous Security Monitoring
Formal Verification of Agent Behavior
در سالهای آینده انتظار میرود مفهوم «Agent Security Operations Center» یا Agent-SOC به یکی از حوزههای اصلی امنیت سایبری تبدیل شود.
Agentic AI مرز میان نرمافزار و عامل مستقل را از بین برده است. این فناوری فرصتهای عظیمی برای اتوماسیون و بهرهوری ایجاد میکند، اما همزمان ریسکهایی را به همراه دارد که در سامانههای سنتی وجود نداشتند.
بررسی مطالعات OWASP، Zenity Labs و Unit 42 نشان میدهد که تهدیداتی مانند Goal Hijacking، Tool Misuse و Memory Poisoning بهسرعت در حال تبدیل شدن به مهمترین چالشهای امنیت هوش مصنوعی هستند.
سازمانهایی که قصد استفاده از عاملهای هوشمند را دارند باید امنیت را از مرحله طراحی معماری آغاز کنند، نه پس از استقرار. ترکیب Zero Trust، Least Privilege ، نظارت مستمر و ارزیابی امنیتی تخصصی میتواند ریسکهای این فناوری را به شکل معناداری کاهش دهد.
آینده متعلق به عاملهای هوشمندی است که نهتنها توانمند، بلکه قابلکنترل، قابلممیزی و قابلاعتماد باشند.
:::
منابع :
OWASP Foundation, OWASP Top 10 for Agentic Applications 2026, 2025.
Palo Alto Networks Unit 42, AI Agents Are Here. So Are the Threats, 2025.
Zenity Labs, AgentFlayer: Exploiting AI Agents Through Indirect Prompt Injection, 2025.
IBM Institute for Business Value, The State of AI Security, 2025.
McKinsey & Company, The Economic Potential and Risks of Generative AI Agents, 2025.
NIST, AI Risk Management Framework (AI RMF 1.0), 2024.
CISA & NSA, Joint Guidance on Secure Deployment of AI Systems, 2025.
European Union, EU AI Act, 2025.