
بعنوان یک معمار نرم افزار که بیشتر اوقات با مایکروسرویس ها درگیر هستیم، همیشه این سوال برامون پیش اومده که بهتره از RabbitMQ استفاده کنیم یا Kafka؟ خیلی از برنامه نویسا این دو ابزار رو یک جایگزینی برای هم میبینن. علارغم اینکه این حرف اشتباه نیست تفاوتهای مختلفی هم بین این دو پلتفرم وجود داره.
درنتیجه، سناریوهای مختلف به راهحلهای مختلف و مناسبی نیاز دارن، و انتخاب یک راهحل نامناسب میتونه به شدت طراحی، توسعه و نگهداری نرم افزار رو تحت تاثیر قرار بده.
تو این مقاله ابتدا در مورد پترنهای Asynchronous messaging (پیام رسانی ناهمگام) صحبت میکنیم بعد به بررسی ساختار داخلی RabbitMQ و Kafka میپردازیم و نهایتا تو بخش دوم این مقاله تفاوتهای عمده، مزایا و معایب این دو پلتفرم رو باهم بررسی میکنیم.
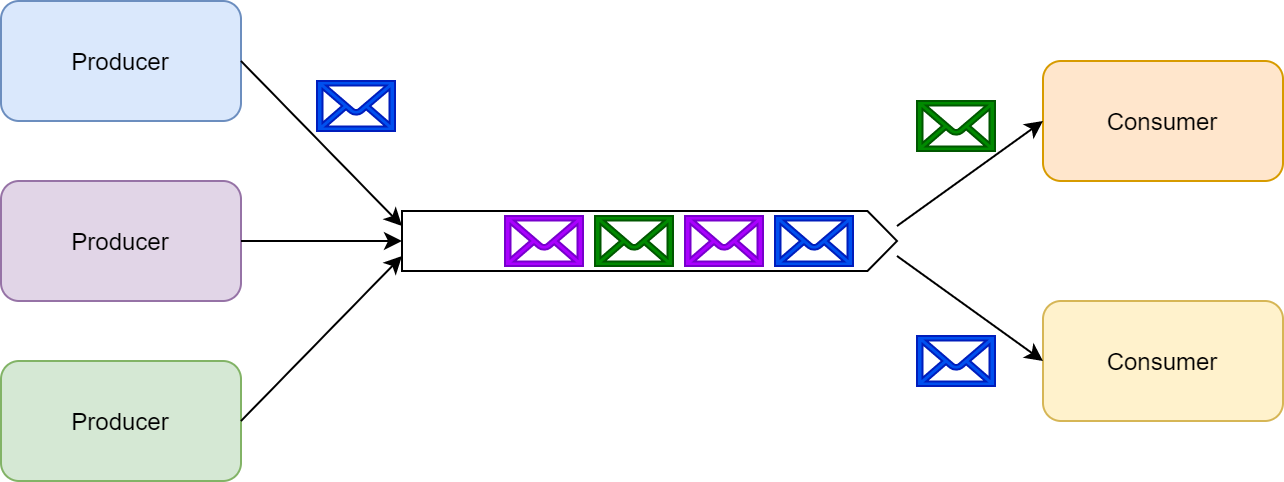
تو این حالت، فرآیندهای تولید پیام توسط producer و پردازش توسط consumer از هم جدا شدن. درکل تو سیستم های messaging دو پترن مهم وجود داره: message queueing و publish/subscribe
تو این پترن queue (صف)، producer (تولید کننده) ها و consumer (مصرف کننده) ها رو از هم جدا میکنه. چندین producer میتونن به یک صف یکسان پیام ارسال کنن. همچنین زمانی که یک consumer درحال پردازش یک پیامه یا locked میشه یا از دسترس خارج میشه، علاوه بر این هر consumer فقط یک نوع پیام خاصی رو میتونه پردازش کنه.
تو این پترن یک پیام میتونه به صورت همزمان توسط چندین consumer دریافت و پردازش بشه. به عبارت دیگه یک publisher میتونه چندین consumer رو از یک رویداد خاصی باخبر کنه.
خیلی از سیستم های queuing بجای pub/sub از اصطلاح topics استفاده میکنن ولی تو RabbitMQ تاپیک یک نوع پیاده سازی pub/sub محسوب میشه یا بهتره بگیم یک نوع exchange محسوب میشه. در هر صورت من تو این مقاله برای اشاره به pub/sub از واژه topics استفاده میکنم.
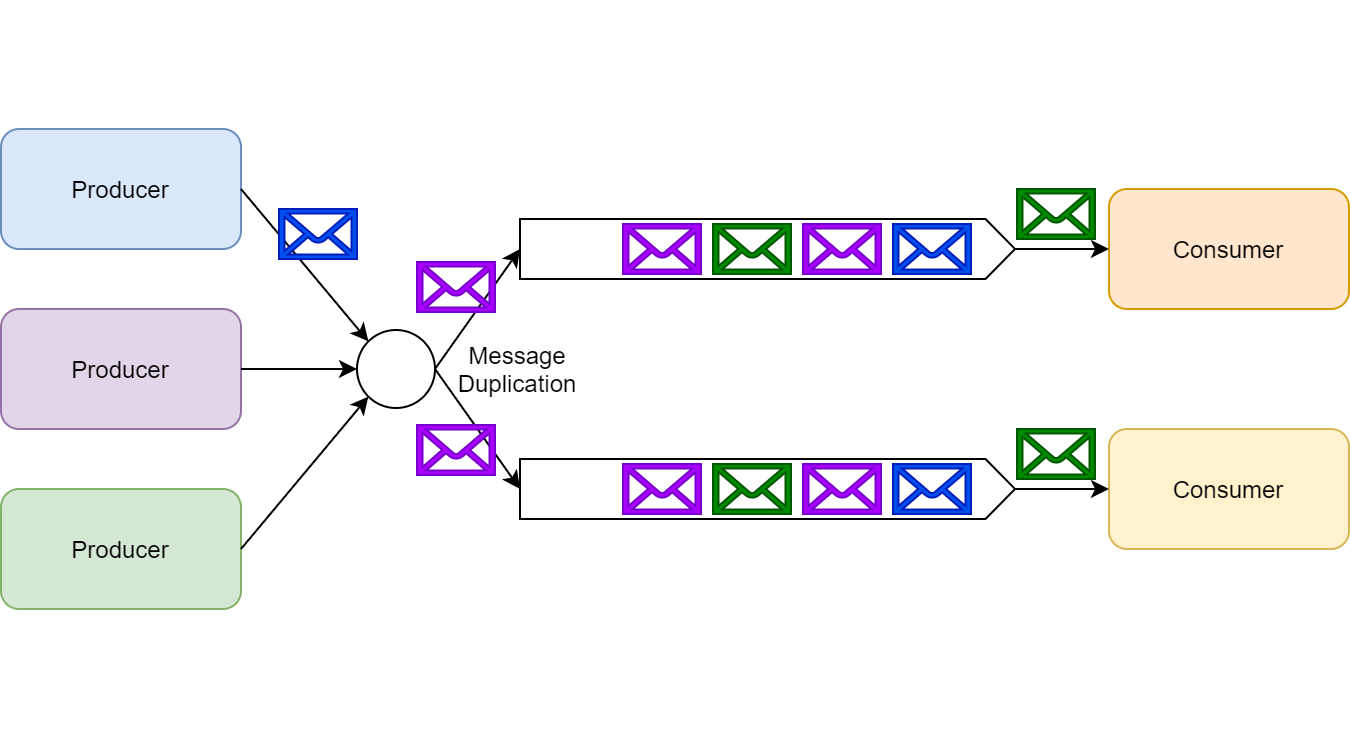
در کل میشه گفت ما دو نوع subscription بیشتر نداریم:
1. An ephemeral subscription
تو این حالت قرارداد بین consumer و publisher تا زمانی که consumer فعال هست، برقراره و با shut down شدن consumer قرارداد و پیامهایی که باید توسط consumer پردازش میشدن از بین میرن.
2. A durable subscription
تو این حالت قرارداد بین consumer و publisher تا زمانی که به صراحت حذف نشده برقراره و با shut down شدن consumer پلتفرم، قرارداد و پیامهارو نگه میداره که بعدا عملیات پردازشش دوباره انجام بشه.
این ابزار یک message broker هست که البته اخیرا بهش service bus هم میگن که بصورت native از هر دو پترنی که بالاتر بهش اشاره شد پشتیبانی میکنه. یه سری message broker های دیگه ای هم هستن از جمله ActiveMQ ، ZeroMQ، Azure Service Bus و Amazon Simple Queue Service که همه اینا نقاط مشترک زیادی دارن و بسیاری از مفاهیم که تو این مقاله توضیح داده شدن شامل اینا هم میشن.
ربیت ام کیو از message queuing کلاسیک پشتیبانی میکنه یعنی یک برنامه نویس میتونه یک صف نامگذاری شده تعریف کنه و بعد publisher ها میتونن پیامهاشونو از طریق این صف ارسال کنن. از اون طرف consumer ها هم که دارن به همین صف گوش میدن میتونن پیامهارو دریافت و پردازش کنن.
ربیت ام کیو حالت pub/sub رو با استفاده از exchange ها پیاده سازی کرده. یعنی یک publisher پیامو میده به exchange بدون اینکه اطلاعی از صفی که قرار پیامش توش ارسال بشه داشته باشه.
هر consumer ای که میخواد با exchange ارتباط برقرار کنه یک صف ایجاد میکنه و بعد exchange از طریق همون صف پیامهارو به consumer میفرسته. همچنین exchange میتونه براساس یک سری routing rules پیامهای خاصی رو به consumer فیلتر کنه.
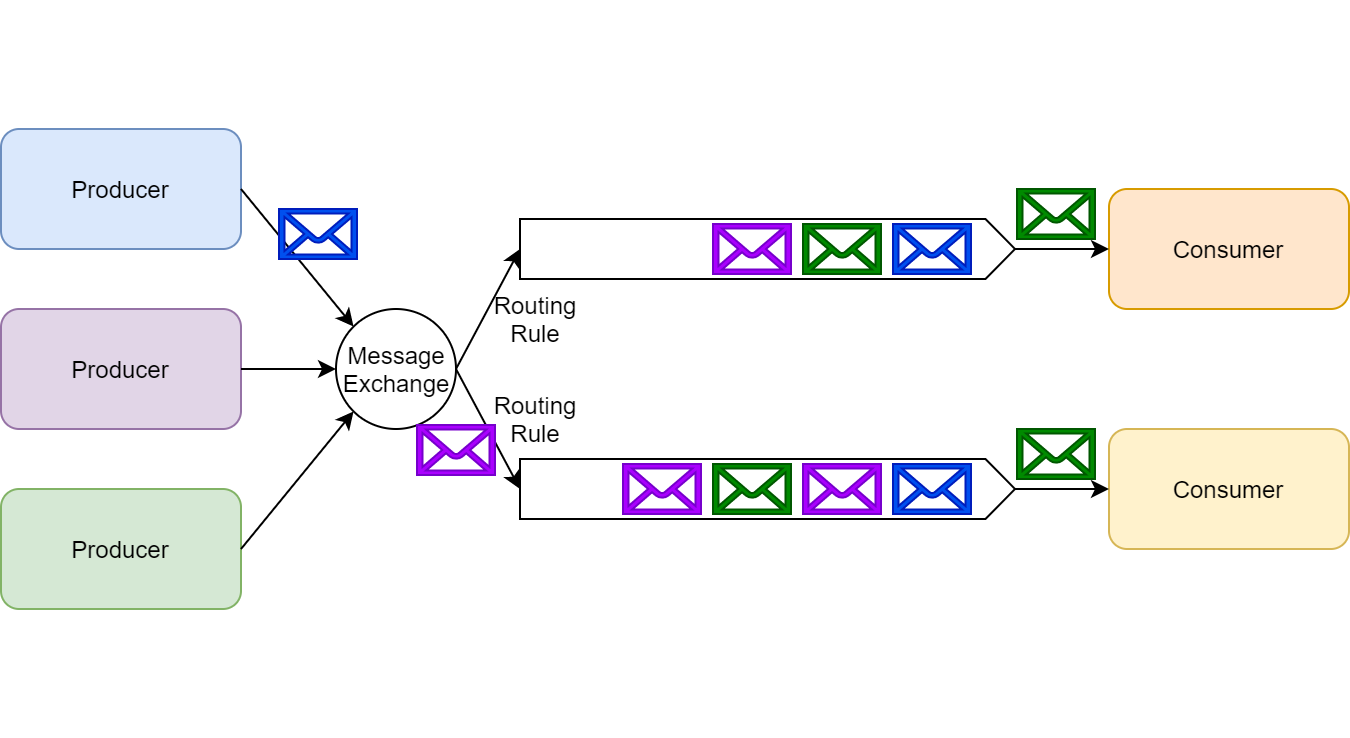
نکته مهمی که وجود داره اینه که RabbitMQ از هر دو حالت durable و ephemeral پشتیبانی میکنه. این consumer هست که میتونه تصمیم بگیره که کدوم حالت انتخاب بکنه و این کار رو توسط API ربیت انجام میده.
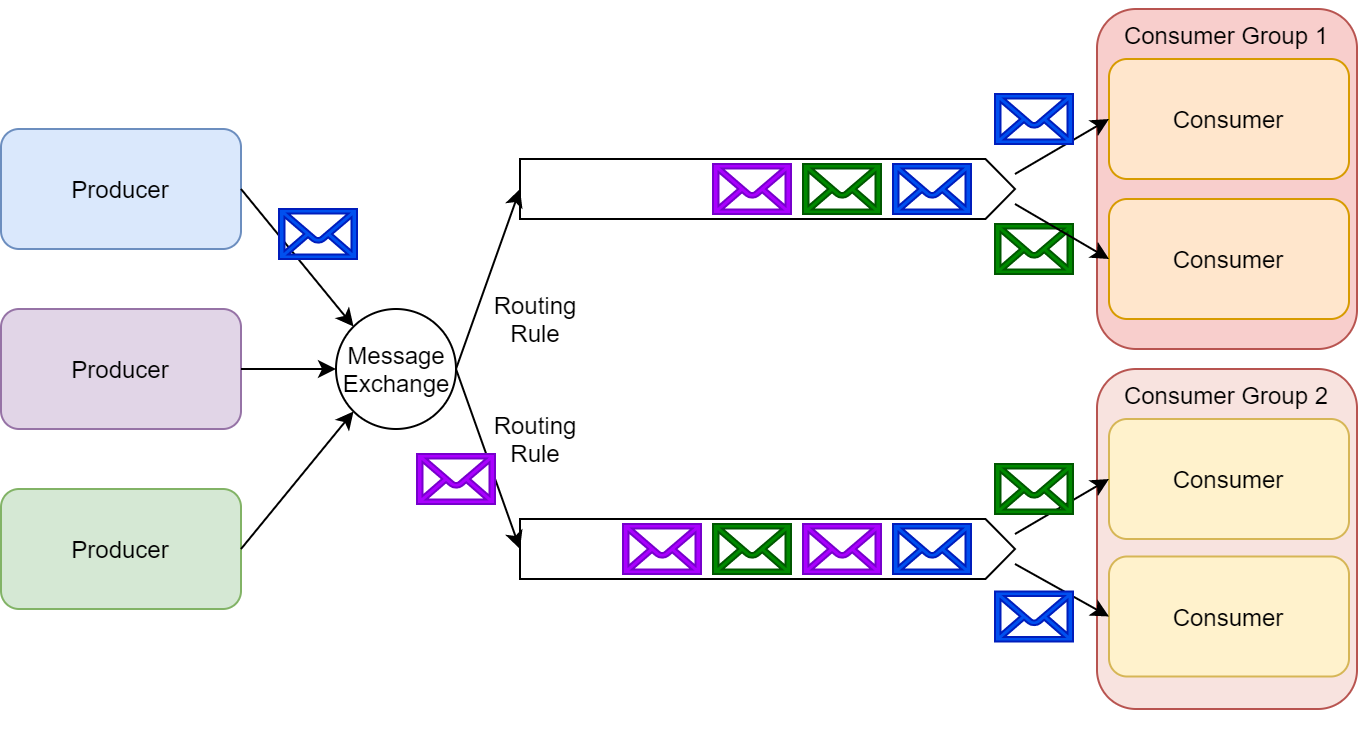
طبق معماری RabbitMQ همچنین میتونیم یک رویکرد ترکیبی داشته باشیم، به این صورت که یک گروهی از consumer هارو بزاریم که بتونن پیامهارو بصورت رقابتی بر روی یک صف پردازش بکنن. تو این حالت علاوه بر پیاده سازی pub/sub امکان scale کردن consumer هارو هم داریم.
کافکا یک message broker نیست بلکه یک distributed streaming platform هست.
برخلاف RabbitMQ که بر مبنای exchange و queue پیاده سازی شده، لایه ذخیره سازی کافکا با استفاده از partitioned transaction log پیاده سازی شده. همچنین کافکا یک Streams API فراهم کرده که با استفاده ازش میشه streamهارو بصورت real-time پردازش کرد و همچنین یک Connectors API جهت ادغام با data source های مختلف که این موضوعات خارج از بحث اصلی این مقاله هستن.
سرویس های ابری یک سری راهحل های جایگزین برای لایه ذخیره سازی Kafka تدارک دیدن از جمله Azure Event hubs یا تا حدودی AWS Kinesis Data Streams که هم مختص cloud هستن و هم Open source که در هر صورت باز خارج از موضوع این مقاله ان.
کافکا queue رو پیاده سازی نمیکنه در عوض مجموعه ای از رکوردهارو داخل دسته بندیهایی به نام topics ذخیره میکنه.
به ازای هر topic، کافکا پارتیشنهایی از پیامهارو نگه میداره. هر پارتیشن از یک سری پیامهای متوالی مرتب سازی شده، غیر قابل تغییر تشکیل یافته که هر پیامی بصورت پیوسته بهش الحاق میشه.
کافکا هر پیامی رو به محض اینکه میرسه به این پارتیشن ها اضافه میکنه. بصورت پیش فرض به منظور توزیع پیامها بصورت یکنواخت بین پارتیشن ها از round-robin partitioner استفاده میکنه.
تولید کننده های پیام میتونن این رفتار رو به منظور ایجاد یک جریان منطقی تغییر بدن. بعنوان مثال در یک اپلیکیشن multitenant شاید بخوایم یک جریان منطقی بر اساس هر tenant ID ایجاد کنیم. تو یک سناریویه IoT شاید بخوایم id هر producer ای مدام به یک پارتیشن خاصی map بشه تو این حالت خیالمون راحته که ترتیب پیامها و پردازششون رعایت میشه.
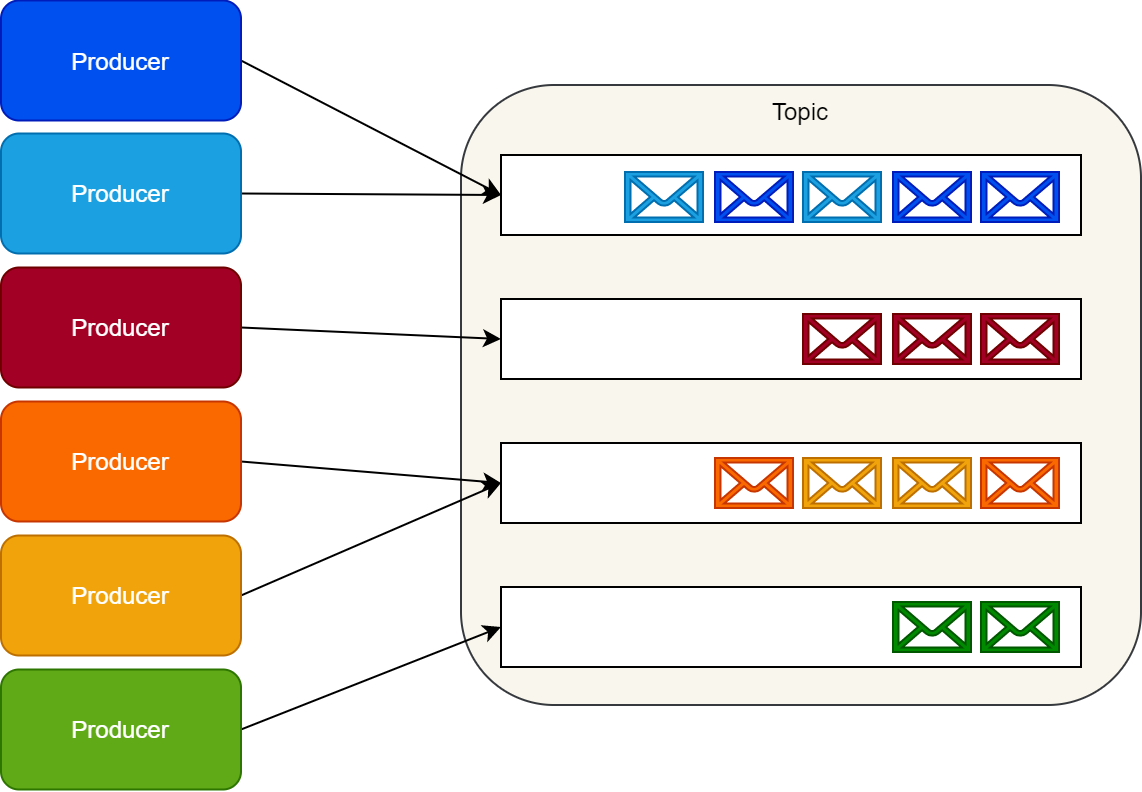
مصرف کننده (Consumer) ها ایندکس پارتیشن هارو نگه میدارن و بصورت پیدرپی پیامهارو میخونن.
هر consumer به تنهایی میتونه دیتای چندین topic رو بخونه، همچنین میشه تعداد consumer ها رو به تعداد پارتیشن های موجود scale کرد. درنتیجه زمانی که میخوایم یک topic بسازیم باید باید به دقت ، توان messaging ای که از topic انتظار داریم رو در نظر داشته باشیم.
به گروهی از consumer ها که باهم دیتای یک topic رو میخونن consumer group گفته میشه. Kafka API مدیریت balancing پردازش پارتیشن بین consumer ها، داخل consumer group و همچنین ذخیره ایندکس فعلی پارتیشن برای هر consumer رو به عهده داره.
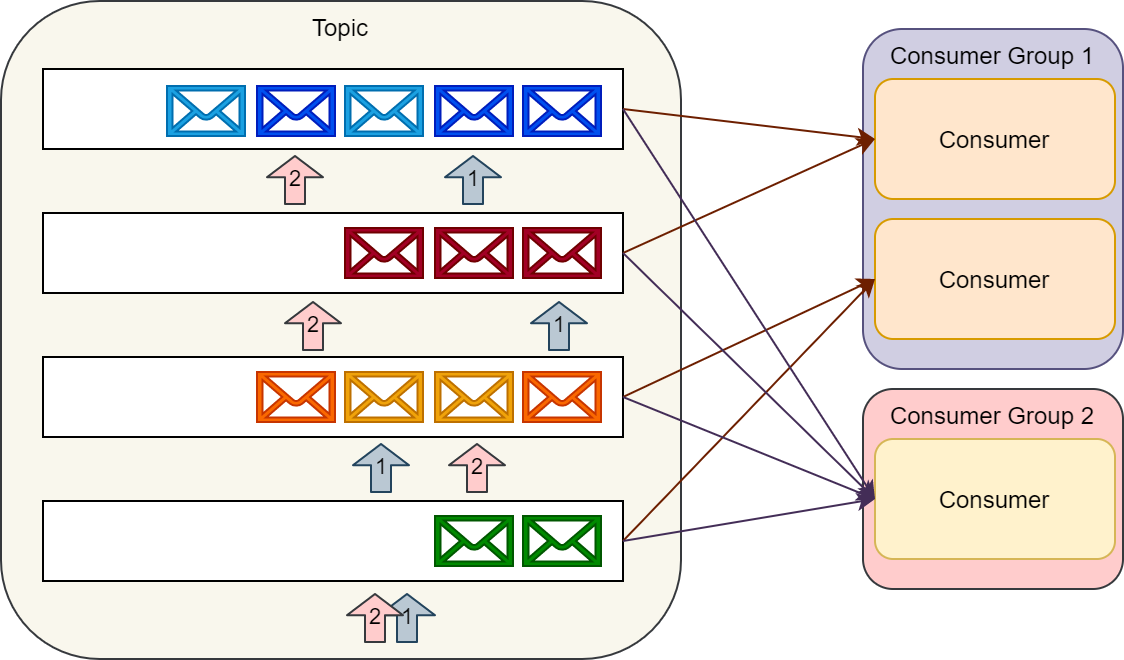
پیاده سازی Kafka یه جورایی مشابه pub/sub تو RabbitMQ.
یک producer میتونه پیامهایی رو به یک topic خاصی ارسال کنه و چندین consumer group میتونن این پیامو پردازش کنن. به منظور مدیریت Load هر consumer group میتونه بصورت جداگانه scale بشه. همچنین ازونجایی که consumer ها ایندکس پارتیشن رو نگه میدارن پس میتونن مشخص کنن که subscription شون بصورت durable باشه که بعد از هر بار ریستارت ادامه پیامهارو پردازش کنن یا بصورت ephemeral باشه و با هر بار ریستارت از آخرین پیامی که وارد پارتیشن شده کارشونو شروع کنن.
در هر صورت این پترن مناسبی برای message-queuing نیست. خب البته که میتونیم یه consumer group ساده برای شبیه سازی message-queuing کلاسیک داشته باشیم ولی خب این میتونه یه سری مشکلات داشته باشه که تو قسمت دوم این مقاله بصورت مفصل بهش اشاره خواهد شد.
نکته ای که باید بهش توجه کرد اینه که Kafka بدون در نظر گرفتن اینکه آیا پیامها consume شدن یانه اونارو تا یک مدت زمانی (که از قبل تنظیم شده) نگه میداره. به این معنی که consumer ها میتونن پیامهای قبلی رو دوباره بخونن. علاوه بر این برنامه نویس ها میتونن از لایه ذخیره سازی Kafka در جهت پیاده سازی سرویس هایی مانند audit log استفاده بکنن.
درحالی که RabbitMQ و Kafka میتونن جایگزینی برای هم باشن ولی باید اینم بدونیم که نحوه پیاده سازیشون کاملا متفاوته. در نتیجه ما نمیتونیم این دوتا رو عضوی از یک دسته بندی ببینیم چون یکیش message broker هست و اونیکی distributed streaming platform.
در کل دوستان عزیز ما همیشه باید تفاوت بین ابزارهارو خوب شناسایی کنیم و تشخیص بدیم که برای هر سناریو کدومیک گزینه بهتریه.تو قسمت دوم این مقاله به بررسی تفاوت های این دو میپردازیم و همچنین مشخص میکنیم تو چه شرایطی از چه ابزاری استفاده بکنیم.
دوستان این مقاله ترجمه شده مقاله زیر می باشد:
https://medium.com/better-programming/rabbitmq-vs-kafka-1ef22a041793