
بعنوان یک معمار نرم افزار که بیشتر اوقات با مایکروسرویس ها درگیر هستیم، همیشه این سوال برامون پیش اومده که بهتره از RabbitMQ استفاده کنیم یا Kafka؟ خیلی از برنامه نویسا این دو ابزار رو یک جایگزینی برای هم میبینن. علارغم اینکه این حرف اشتباه نیست تفاوتهای مختلفی هم بین این دو پلتفرم وجود داره.
درنتیجه، سناریوهای مختلف به راهحلهای مختلف و مناسبی نیاز دارن، و انتخاب یک راهحل نامناسب میتونه به شدت طراحی، توسعه و نگهداری نرم افزار رو تحت تاثیر قرار بده.
تو قسمت اول این مقاله به بررسی مفاهیم پیاده سازی داخلی RabbitMQ و Kafka پرداختیم تو این قسمت قراره تفاوتهای قابل توجه این (تفاوتهایی که هر مهندس نرم افزار باید بدونه) دو تکنولوژی رو باهم بررسی کنیم.
نهایتا در مورد پترنهای معماری که اغلب سعی داریم با این ابزارها پیاده سازی کنیم، صحبت میکنیم و نقاط ضعف و قدرت هر ابزاری رو در سناریوهای مختلف مورد بررسی قرار میدیم.
درصورتی که با ساختار داخلی RabbitMQ و Kafka آشنا نیستین حتما پیشنهاد میکنیم که قسمت اول این مقاله رو مطالعه کنید یا حداقل یه نگاه مختصری به دیاگرامها و تصاویرش داشته باشین.
پیرو پست قبلی یکی از دوستان در مورد Apache Pulsar از من پرسیده بودن. Pulsar هم یک messaging platform هست و ادعا میکنه که ترکیبی از بهترین امکانات RabbitMQ و Kafka رو داره.
به عنوان یک پلتفرم مدرن خیلی امیدوار کننده به نظر میاد ولی در هر صورت این ابزار هم مانند سایر ابزارها میتونه نقاط ضعف و قوت خودشو داشته باشه. به هر حال سعی میکنم در آینده یک مقاله ای هم راجع به مقایسه Apache Pulsar بنویسم ولی فعلا بهتره روی RabbitMQ و Kafka تمرکز کنیم.
ربیت ام کیو یک Message broker هست در حالی که Kafka یک Dirtributed streaming platform هست. حالا شاید بنظرتون این دوتا فقط از لحاظ معنایی باهم تفاوت داشته باشن ولی این مستلزم پیامدهایی هست که میتونه بر توانیهای ما برای پیاده سازی راحت تو موارد مختلف تاثیر بزاره.
برای مثال بهترین کاربرد Kafka پردازش جریان داده هاس درحالی که RabbitMQ به اون صورت ترتیب پیامهارو در حین جریان تضمین نمیکنه.
از طرفی RabbitMQ از تلاش مجدد پیامهای fail شده و dead-letter exhanges داخل خودش پشتیبانی میکنه درحالی که Kafka یه همچین پیاده سازیهای رو در اختیار خود کاربر گذاشته.
تو این قسمت این تفاوتها و یکسری موارد دیگه برجسته شدن.

ربیت ام کیو تضمین و توجه آنچنانی رو ترتیب پیامهایی که به queue یا exchange ارسال میشن نداره درحالی که شاید بنظرتون این بدیهی باشه که consumer ها پیامهارو با همون ترتیبی که producerها به سمتشون میفرستن پردازش میکنن، ولی باز هم این مساله میتونه گمراه کننده باشه.
طبق مستندات RabbitMQ در مورد تضمین ترتیب پیامها این چنین بیان شده که:
ترتیب پیامها در صورتی رعایت میشه که اولا داخل یک channel ارسال بشن و از یک exchange یا queue عبور کنن و نهایتا توسط یک outgoing channel به دست consumer برسن. ــــــ RabbitMQ Broker Semantics
بنابراین در صورتی که ما فقط یک consumer داشته باشیم، پیامها به ترتیب ارسال میشن ولی اگر به ازای یک queue چندین consumer داشته باشیم ترتیب پیامها هیچ ضمانتی نداره.
این اتفاق زمانی رخ میده که consumerها پیامی رو بنا به دلایلی دوباره داخل queue برگردونن. (مثلا زمانی که پردازش fail میشه)
به محض اینکه یک پیام مجددا وارد queue میشه یک consumer دیگه برمیداره و پردازشش میکنه درحالیکه قبل همین پیام، همین consumer پیامی جدیدتر از اینو پردازش کرده بود. بنابراین consumer groupها پیامهارو خارج از ترتیب پردازش میکنن.
به این دیاگرام دقت کنید:
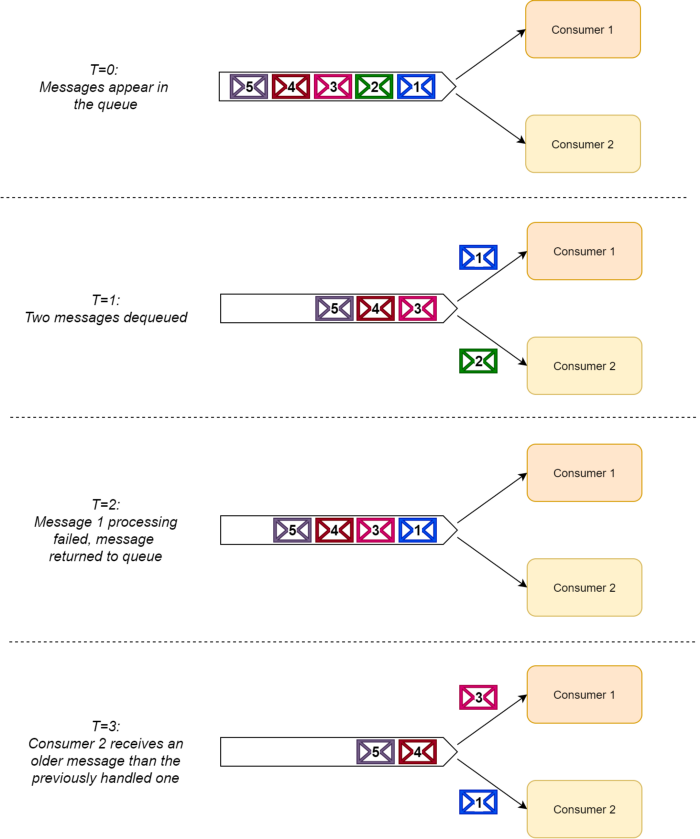
البته ما میتونیم با محدود کردن پردازش همزمان (concurrency) هر consumer باعث بشیم که ترتیب رعایت بشه یا دقیقتر اگه بخوام بگم تعداد thread ها در consumer باید به 1 محدود بشه چون پردازش موازی میتونه همین مشکل رو برامون بوجود بیاره.
ولی خب تو این حالت ما خودمون رو به یک single-threaded consumer محدود کردیم بنابراین زمانیکه سیستم ما رشد کنه و ما مجبور به scale کردن consumer ها بشیم قطعا با مشکل بزرگی روبرو میشیم.
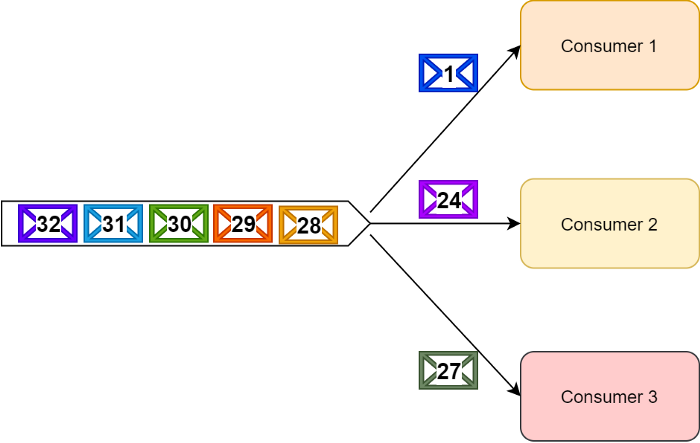
از طرفی Kafka با اطمنیان بسیار زیاد ترتیب پیامهارو تو ارسال و پردازش تضمین میکنه به عبارت دیگه Kafka تضمین میکنه پیامهایی که وارد یک پارتیشن در یک topic میشن، پردازششون هم به ترتیب انجام میشه.
تو قسمت قبل به این اشاره کردیم که Kafka برای جایگذاری پیامها داخل پارتیشنها از round-robin partitioner استفاده میکنه ولی درکنار این، هر producer ای میتونه یه partition-key روی هر پیامی ست کنه و بدین ترتیب یک جریان منطقی دیتا ایجاد کنه. (مثلا پیامهایی که از یک device خاصی میان)
اینگونه میشه که پیامهایی که از یک جریان خاصی دریافت میشن داخل یک پارتیشن قرار میگیرن پس درنتیجه ترتیب پردازششون توسط یک consumer group رعایت میشه.
با توجه به اینکه داخل هر consumer group هر پارتیشن توسط یک single-threaded consumer پردازش میشه، بنابراین ما نمیتونیم پردازش یک single partition رو scale بکنیم، در عوض میتونیم تعداد پارتیشنهای هر topic رو افزایش بدیم و بدین ترتیب پیامهای کمتری وارد هر پارتیشن میشن و بعد میتونیم برای هر پارتیشن یک consumer در نظر بگیریم.
برنده این بخش
مشخصه که Kafka برنده این بخش از مقایسه اس چون ترتیب پردازش پیامها توش رعایت شده ولی RabbitMQ تضمین خاصی رو این مساله نداره.

ربیت ام کیو میتونه پیامهارو برای consumerهای هر exchange ای، طبق قوانینی که خودشون مشخص کردن بفرسته. یک topic exchange میتونه پیامهارو براساس یک هدر اختصاصی بنام routing_key ارسال کنه.
همچنین یک headers exchange میتونه با header attribute های بیشتری پیامهارو ارسال کنه. هر دو exchange ها بطور قابل توجهی به consumerها کمک میکنن تا پیامهای مورد علاقشونو دریافت کنن. در نتیجه میشه گفت تو این زمنیه RabbitMQ یک معماری و راهحل انعطافپذیری فراهم آورده.
شاید بعنوان یک برنامه نویس بتونید از Kafka stream job استفاده بکنید، به این صورت که ابتدا پیامها از یک topic خونده و فیلتر بشن و بعد داخل یک topic دیگه ای قرار بگیرن ولی پیاده سازی این مدل، حفظ و نگهداریش هزینه سنگینی داره.
برنده این بخش
وقتی حرف از routing و filtering پیامها زده میشه قطعا RabbitMQ قابلیت بالاتری نسبت به Kafka داره.

ربیت ام کیو جهت زمان سنجی (Message timing) پیامهایی که به queue ارسال میشن، قابلیتهای مختلفی رو فراهم آورده.
برای هر پیامی که به RabbitMQ فرستاده میشه میتونیم یک TTL در نظر بگیرم که البته این کارو یا توسط publisher میتونیم انجام بدیم یا بعنوان یک policy برای queue در نظر بگیریم. در صورتی که consumer بعد از گذر یک زمان مشخص شده موفق به پردازش پیام نشه، پیام از صف حذف شده و داخل dead-letter exchange منتقل میشه.
عمر پیام یا TTL برای دستوراتی که به زمان حساس هستن یا به عبارت دیگه بعد از گذر یک زمان مشخصی اهمیت خودشونو از دست میدن، بسیار مهمه.
ربیت ام کیو با استفاده از یک پلاگین از پیامهای delayed/scheduled پشتیبانی میکنه. پس از اینکه این پلاگین تو exchange فعال شد، producer میتونه یک delay روی پیام ست کنه که دراین صورت RabbitMQ پیامرو با تاخیر به سمت صف consumer ارسال میکنه.
این امکان به برنامه نویسها اجازه میده تا برای command های بعدی برنامه ریزی داشته باشن. بعنوان مثال اگر تعداد درخواستهای یک producer از یک حدی رد شد میتونیم درخواستهای بعدی رو به تعویق بندازیم.
کافکا از یه همچین امکاناتی پشتیبانی نمیکنه و هر پیامی رو بلافاصله بعد رسیدنش وارد پارتیشن ها میکنه که همون لحظه هم توسط consumer ها آماده پردازش میشن.
همچنین کافکا هیچ مکانیزمی برای پیاده سازی TTL نداره هرچند که میتونیم این بخشو تو لایه application پیاده سازی کنیم.
باید به یاد داشته باشیم که پارتیشن کافکا append-only هست و کافکا نمیتونه زمان پیام و موقعیتشو داخل پارتیشن دستکاری کنه.
برنده این بخش
تو این بخش RabbitMQ به خاطر ذاتی که داره، بدون هیچ زحمتی برنده اعلام میشه.

ربیت ام کیو هر پیامی رو بعد ازینکه با موفقیت پردازش شد از صف بیرون میبره. البته یکی از ویژگیهای هر message-broker ای هست و ما نمیتونیم اینو تغییر بدیم.
در عوض کافکا هر پیامی رو تا یک مدتی (طبق یکسری تنظیمات از قبل تعریف شده به ازای هر topic) نگه میداره. در کل Kafka به منظور نگه داری پیامها به این موضوع اهمیت نمیده که آیا این پیام پردازش شده یا خیر!
مصرف کننده (Consumer)ها به هر تعدادی که بخوان میتونن یک پیامی رو پردازش کنن همچنین میتونن با دستکاری ایندکس partition که تو خودشون نگه میدارن، عقبتر برگردن. بطور دورهای کافکا عمر پیامهارو داخل topic بررسی میکنه و اونایی که به حد کافی قدیمی هستن رو حذف میکنه.
کارایی Kafka به اندازه storage بستگی نداره و بصورت نظری میتونه تعداد نامحدودی از پیامهارو نگه داره. (البته باید nodeهای شما به حد کافی ظرفیت داشته باشن)
برنده این بخش
کافکا طوری طراحی شده که بتونه پیامهارو نگه داره ولی RabbitMQ خیر. پس تو این قسمت هیچ رقابتی وجود نداره و بدون شک Kafka برنده این بخش اعلام میشه.

برنامه نویسها زمانی که با پیامها، صفها و رویدادها درگیر هستن گمان میکنن که پردازش پیامها همیشه با موفقیت انجام میشه. گذشته از همه اینا، زمانی که producer ها پیامی رو داخل صف یا topic قرار میدن حتی اگر consumer موفق به پردازش این پیام نشه این روند میتونه آنقدر تکرار بشه که نهایتا عملیات با موفقیت به اتمام برسه.
درحالیکه این مساله درسته، ما باید یه فکر دیگهای هم تو این فرآیند داشته باشیم. ما باید در نظر بگیریم که تو بعضی از سناریوها ممکن پردازش پیامی fail بشه بنابراین باید بتونیم این شرایط رو براحتی مدیریت کنیم حتی اگه راهحلش از طریق مداخله انسانی باشه.
در کل هنگام پردازش پیامها دو نوع خطا وجود داره:
2. خطاهای ماندگار ــــ این نوع خطاها به دلیل یک مشکل دائمی بوجود میان که با تلاشهای مکرر نمیشه رفعشون کرد، مانند باگ یا ساختار پیام نامعتبر.
بعنوان معمار و توسعه دهنده همیشه باید این سوالارو از خودمون بپرسیم: "اگر پردازش پیامی fail بشه چند بار باید تلاش مجدد داشته باشیم؟ بین هر تلاش مجدد چقدر باید وقفه داشته باشیم؟ چطور باید خطاهای دائمی و موقتی رو از هم تشخیص بدیم؟"
و از همه مهمتر: "بعد ازینکه تلاشهای مجدد نتیجهای ندادن باید چیکار کنیم؟"
درحالیکه جواب این سوالات domain-specific هستن، پلتفرمهای messaging برای پیادهسازی راهحلهامون ابزارهایی رو فراهم آوردن.
ربیت ام کیو ابزارهایی مانند delivery retries و dead-letter exchanges یا (DLX) برای مدیریت خطای پردازش پیامها در اختیارمون گذاشته.
ایده اصلی DLX اینه که RabbitMQ بصورت اتوماتیک message هایی که fail شدن رو طبق یکسری تنظمیات به DLX میفرسته و قانونهای پردازش بیشتری از جمله تاخیر تلاشهای مجدد، تعداد تلاشهای مجدد و تحویل به صف مداخله انسانی (Human intervention queue)، روشون اعمال میکنه.
با مطالعه این مقاله میتونید با پترنهای مدیریت تلاشهای مجدد تو RabbitMQ بیشتر آشنا بشید.
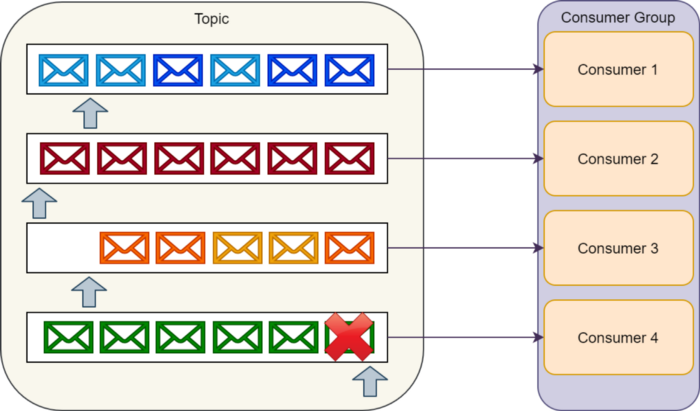
مهمترین نکته ای که باید به یاد داشته باشید اینه که تو RabbitMQ زمانی که یک consumer در حال پردازش یک پیامه یا داره تلاش میکنه تا مجددا پردازشش بکنه (حتی قبل از اینکه fail بشه و دوباره به صف برگردونه)، بقیه consumerها میتونن پیامهای بعدی رو بصورت همزمان پردازش کنن.
درکل عملیات پردازش پیامها، زمانی که یک consumer داره رو یه پیام خاصی تلاش مجدد میکنه، متوقف نمیشه درنتیجه یک consumer میتونه پردازش یک پیامو بارها و بارها بدون اینکه کل سیستم تحت تاثیر قرار بده، پردازش کنه.
برخلاف RabbitMQ ما همچین مکانیزمی رو تو Kafka نداریم و این بستگی به خودمون داره که یه همچین مکانیزمی رو تو لایه application پیاده سازی کنیم.
همچنین باید توجه داشت، زمانی که یک consumer در حال پردازش یک پیامه بقیه پیامهای اون پارتیشن نمیتونن پردازش بشن.
ما نمیتونیم پیامی رو رد یا پردازشش رو برای بعد موکول کنیم بخاطر اینکه consumer ها نمیتونن ترتیب پیامهارو تغییر بدن. همونطور که قبلا هم بهش اشاره شد پارتیشنهای کافکا append-only هستن.
راهحل لایه اپلیکیشن اینگونه هست که میتونیم پیامهایی که fail میشن رو به یه topic دیگه بفرستیم ولی خب تو این حالت ترتیب پیامها بهم میریزه.
نمونه یه همچین پیاده سازی توسط مهندسی Uber رو میتونیم رو این سایت ببینیم. در صورتی که تاخیر پیامها اهمیتی نداشته باشن استفاده از مانیتورینگ Vanilla Kafka برای مدیریت خطاها میتونه کافی باشه.
برنده این بخش
ازونجایی که RabbitMQ برای مدیریت خطا مکانیزم خیلی خوبی فراهم آورده، بعنوان برنده این بخش اعلام میشه.

در کل معیارهای زیادی برای بررسی پرفورمنس RabbitMQ و Kafka وجود دارن.
درحالیکه که معیارهای عمومی قابلیت اجرائی محدودی تو شرایط مختلف دارن، میشه گفت Kafka پرفورمنس بهتری نسبت به RabbitMQ داره، به دلیل اینکه Kafka از sequential disk I/O به منظور تقویت کارایی خودش استفاده میکنه.
ازونجایی Kafka از پارتیشن ها استفاده میکنه پس میتونه horizantal scaling بهتری داشته باشه درحالی که RabbitMQ تو vertical scaling بهتر جواب میده. ( تفاوت بین horizonal scaling و vertical scaling)
سیستمهای گسترش یافته Kafka معمولا میتونن صدها هزار یا حتی میلیونها پیام رو در ثانیه مدیریت کنن.
در گذشته توسط Pivotal ثبت شده بود که یک کلاستر RabbitMQ در هر ثانیه یک میلیون پیام رو مدیریت میکنه. البته باید گفت این کارو با یک کلاستر 30 نودی و لود بهینه شده که بین چندین queue و exchange پخش میشد،انجام داده.
برنده این بخش
در حالیکه هر دو پلتفرم لود بسیار سنگینی رو میتونن مدیریت کنن، Kafka بهتر میتونه scale بشه و طبیعتا پرفورمنس بهتری نسبت به RabbitMQ داره و برنده این بخش اعلام میشه.

ربیت ام کیو از رویکرد smart-broker and dumb-consumer(دلال باهوش و مصرف کننده بی عقل) استفاده میکنه. به این صورت که هر consumer ای برای استفاده از queue رجیستر میکنه و به محض اینکه وارد شد RabbitMQ پیامهارو جهت پردازش به سمتش ارسال میکنه. همچنین RabbitMQ یک pull API هم داره که زیاد ازش استفاده نمیشه.
ربیت ام کیو مدیریت توزیع پیامها بین consumer ها و همچنین و حذف پیامها از queue رو به عهده داره. بنابراین دیگه نیازی نیست consumer خودشو درگیر این مسائل بکنه.
همچنین ساختار RabbitMQ طوری هست که در زمانهای لود سنگین بدون هیچ تغییر تو سیستم یک consumer group میتونه از یک consumer به چندین consumer افزایش پیدا کنه.
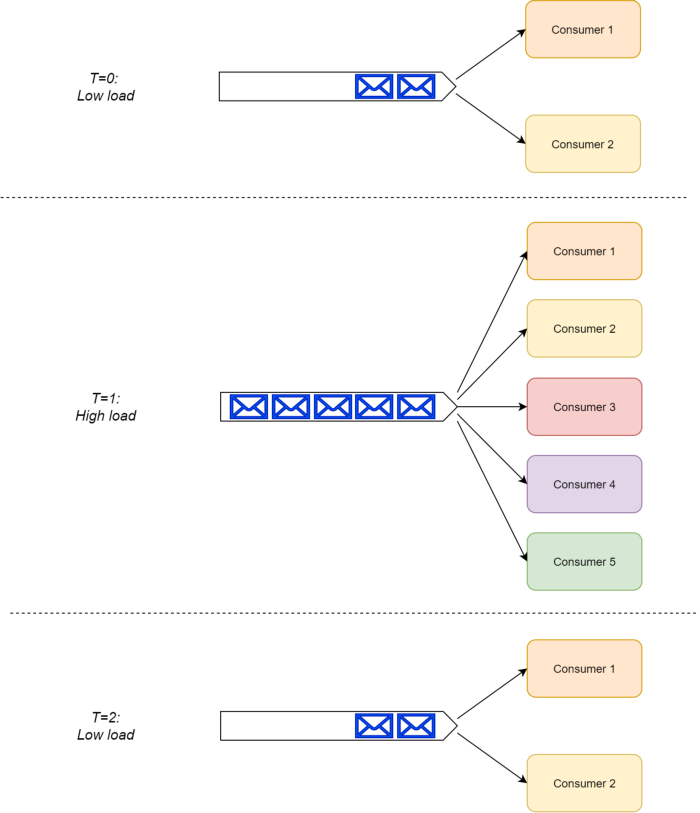
درحالیکه Kafka از رویکرود dumb-broker and smart-consumer (دلال بی عقل و مصرف کننده باهوش) استفاده میکنه یعنی consumer های داخل یک consumer group باید خودشون پارتیشن های یک topic رو باهم هماهنگ کنن. ( به خاطر همین هر consumer داخل یک consumer group فقط به یک پارتیشن گوش میده)
همچنین Consumer ها باید مدیریت و ذخیره سازی ایندکس پارتیشن هارو انجام بدن که خوشبختانه Kafka SDK این کارو برامون انجام میده و نیاز نیست فکرمونو با این موضوع درگیر کنیم.
باید توجه داشت که تو لود پایین یک consumer واحد باید عملیات پردازش و پیگیری چندین پارتیشن رو به تنهایی به عهده بگیره بنابراین سمت consumer به منابع زیادی نیاز خواهیم داشت.
تو لود سنگین تعداد consumerهای هر گروهی رو تا جایی میتونیم افزایش بدیم که تعدادشون از تعداد کل پارتیشنهای یک topic تجاوز نکنه در نتیجه مجبوریم Kafka رو طوری ست کنیم که تو همچین شرایطی پارتیشن های بیشتری اضافه کنه.
و زمانی که مجددا لود پایینتر میاد ما نمیتونیم پارتیشنهای اضافه رو حذف کنیم بنابراین این باعث سنگینتر شدن کار هر consumer ای میشه.
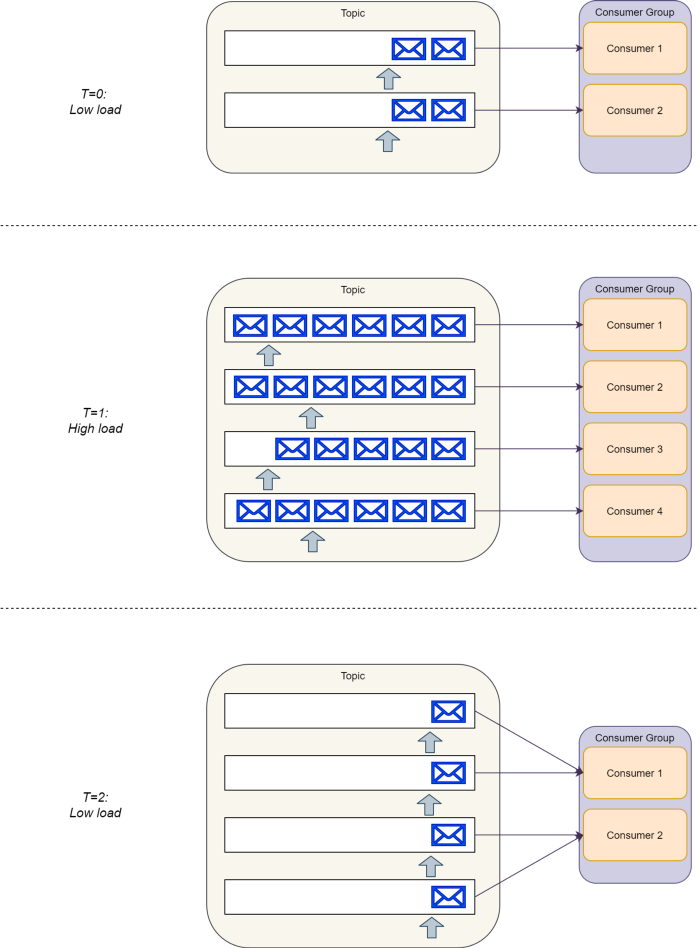
برنده این بخش
تو این بخش RabbitMQ به علت استفاده از رویکرد dumb-consumer برنده اعلام میشه.

و بلاخره رسیدیم به سوال میلیون دلاری: "کجا بهتره از RabbitMQ استفاده کنیم و کجا بهتره از Kafka استفاد کنیم؟"
اگه بخوایم تفاوتهای بالارو خلاصه کنیم به یه همچین نتیجه ای میرسیم:
ربیت ام کیو قابل ترجیحه زمانی که ما نیاز داریم به:
کافکا قابل ترجیحه زمانی که ما نیاز داریم به:
تو بیشتر مواقع میتونیم هر دو ابزارو پیاده سازی کنیم این بیشتر به عنوان معمار نرمافزار به ما بستگی داره که برای هرکاری کدومشو انتخاب کنیم. همچنین موقع انتخاب باید محدودیتهای عملکردی(که بالاتر بهش اشاره شد) و غیر عملکردی رو در نظر بگیریم.
این محدودیتها شامل:
هنگام توسعه نرم افزارهای پیچیده شاید بخوایم برای همه نیازهای پیام رسانی فقط از یک ابزار استفاده کنیم ولی طبق تجربیات من استفاده از هر دو میتونه فواید زیادی داشته باشه.
بعنوان مثال تو سیستمهای رویداد-گرا میتونیم از RabbitMQ برای ارسال دستورات بین سرویسها و از Kafka برای ارسال نوتیفیکیشن رویدادهای bussiness استفاده کنیم.
دلیلش اینه که نوتیفیکیشن رویدادها بیشتر برای تهیه منابع، عملیات دستهای(Batch operations) یا در راستای اهداف حسابرسی استفاده میشن، درنتیجه Kafka تو این حالت به خاطر نگه داشتن پیامها میتونه کارایی بهتری داشته باشه.
از طرفی دستورات بین سرویس ها به عملیات بیشتری سمت consumer ها نیاز دارن و هر پردازشی میتونه fail بشه و قطعا ما به مدیریت پیشرفته خطاها نیاز داریم که اینجا RabbitMQ بیشتر میدرخشه. احتمالا در آینده مقاله ای با جزئیات بیشتر راجع به همین بنویسم ولی شما همیشه تو ذهنتون داشته باشید: "نسبت به نیازهای سیستم ممکن مسیر شما عوض بشه"
من نوشتن این دو مقاله رو با این دیدگاه شروع کردم که ممکن خیلی از برنامهنویسا این دو ابزارو جایگزینی برای هم ببینن، در هر صورت امیدوارم با خوندن این دو مقاله به تفاوتهای ساختاری، فنی و پیاده سازی این دو ابزار پی برده باشید.
در کل تفاوتها میتونن رو موارد استفاده این دو ابزار تاثیر بزارن در نتیجه هر دو ابزار عالی هستن و میتونن تو موارد مختلفی استفاده بشن.
بنابراین به عنوان یک معمار نرمافزار باید نیازمندیهای یک سیستم رو خوب متوجه بشیم، اولویت بندی کنیم و نسبت به شرایط بهترین ابزارو انتخاب کنیم.
دوستان این مقاله ترجمه شده مقاله زیر می باشد:
https://medium.com/better-programming/rabbitmq-vs-kafka-1779b5b70c41