
اگر بخواهیم شناسایی زبان را در دادههای متنی بررسی کنیم، اولین سوالی که پیش میآید این است که چگونه میتوانیم به راحتی زبان یک متن را شناسایی کنیم؟ برای این کار، ابزارها و تکنیک های متنوعی وجود دارد که یکی از آنها استفاده از امکانات موجود دیتابیس Elasticsearch است. در این مقاله، قصد داریم با استفاده از مدل lang_ident_model_1 در Elasticsearch، سرعت شناسایی زبان بر روی یک دیتاست فارسی به صورت ساده و مقدماتی انجام دهیم.
فرض کنید شما یک فروشگاه اینترنتی دارید که مشتریان به زبانهای مختلف نظرات خود را مینویسند. شما میخواهید تمام این نظرات را به صورت خودکار شناسایی زبان کرده و سپس تحلیلهای بیشتری بر اساس زبان انجام دهید.
ما یک دیتاست فارسی داریم که شامل نظرات کاربران در زمینه هتل و تلفن همراه است. دیتاست دارای دو بخش اصلی است: نظرات و درصد درستی آنها. درصد درستی، همان امتیازی است که خود کاربر هنگام نوشتن نظر داده است.
ابتدا فایل دادهها را از اینجا بارگذاری کرده و سپس نظرات را استخراج میکنیم:
import pandas as pd df = pd.read_csv("Hotel.csv", encoding='utf-16') reviews = df["review"].values.tolist()
در اینجا، نظرات به صورت لیستی از رشتهها استخراج میشوند. حالا که دادهها آماده شدند، وقت آن است که این نظرات را به Elasticsearch ارسال کنیم.
در این قسمت باید پایپلاین شناسایی زبان را در Elasticsearch ایجاد کنیم. این کار با استفاده از دستور PUT _ingest/pipeline/language_detection_pipeline انجام میشود. پایپلاین شناسایی زبان به مدل lang_ident_model_1 برای شناسایی زبان نیاز دارد و متنهای هر نظر را به این مدل ارسال میکند.
PUT _ingest/pipeline/language_detection_pipeline { "processors": [ { "inference": { "model_id": "lang_ident_model_1", "inference_config": { "classification": { "num_top_classes": 1 } }, "field_map": { "content": "text" } } } ] }
در اینجا، این پایپلاین با استفاده از مدل lang_ident_model_1 زبان متنهایی که در فیلد content قرار دارند را شناسایی میکند. مدل به طور پیشفرض، عمل دستهبندی را انجام میدهد و به بالاترین دسته (که همان زبان شناسایی شده است) توجه میکند.
حالا که دادهها آمادهاند، میخواهیم این دادهها را به Elasticsearch ارسال کنیم. از آنجایی که تعداد نظرات به 6432 رکورد است، ارسال آنها به صورت یکجا میتواند زمان زیادی ببرد. برای حل این مشکل، از پردازش موازی استفاده میکنیم تا به صورت همزمان چندین بخش از دادهها را ارسال کنیم و عملکرد مدل را در بهترین حالت ممکن انجام دهیم. این کار با استفاده از ThreadPoolExecutor در پایتون انجام میشود. کد زیر نشان میدهد که چگونه میتوانیم دادهها را به بخشهای کوچک تقسیم کرده و به صورت موازی ارسال کنیم:
from concurrent.futures import ThreadPoolExecutor from elasticsearch import Elasticsearch, helpers def send_chunk(chunk): _chunk = [ {"_index": "hotel", "_source": {"content": doc}, "pipeline": "language_detection_pipeline"} for doc in chunk ] helpers.bulk(es, _chunk) es = Elasticsearch([{'host': 'localhost', 'port': 9200}]) chunk_size = 500 def chunk_list(data, chunk_size): for i in range(0, len(data), chunk_size): yield data[i:i + chunk_size] with ThreadPoolExecutor(max_workers=8) as executor: executor.map(send_chunk, chunk_list(reviews, chunk_size)) es.close()
در این کد، دادهها به دستههای 500 تایی تقسیم میشوند و هر دسته به صورت موازی به Elasticsearch ارسال میشود. استفاده از 8 ترد در اینجا به این معنی است که 8 بخش از دادهها به صورت همزمان پردازش خواهند شد.
در نهایت، زمان اجرای این عملیات به صورت زیر است:
CPU times: total: 156 ms Wall time: 9.54 s
از آنجایی که تعداد رکورد های مجموعه داده ما 6432 است، هر ثانیه حدودا 674 داده را پردازش و به دیتابیس وارد کرده است.
نمونه ای از یک داده
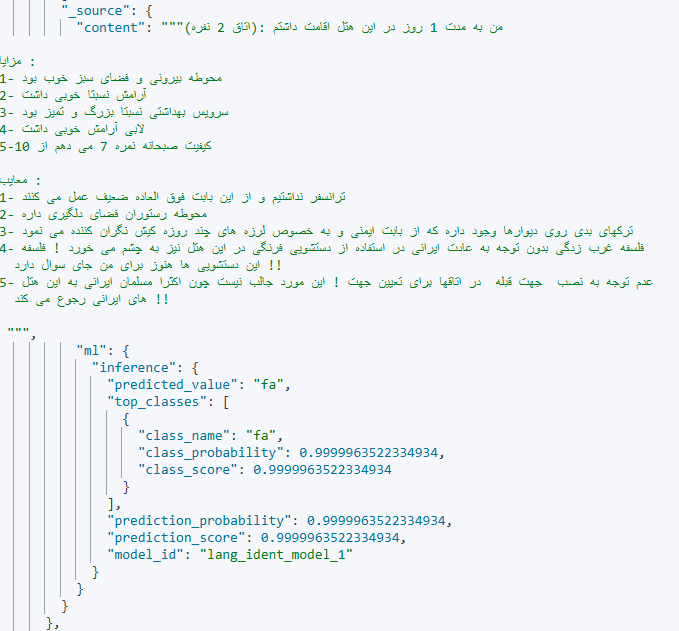
در این مقاله سعی شد بررسی مقدماتی و ساده ای از میزان سرعت مدل تشخیص زبان دیتابیس Elasticsearch داشته باشیم. با استفاده از مدل lang_ident_model_1، میتوانیم به راحتی زبان متنهای مختلف را شناسایی کرده و بر اساس آن تحلیلهای دقیقتری انجام دهیم. از طرفی، استفاده از پردازش موازی باعث شد که سرعت پردازش دادهها به شکل قابل توجهی افزایش یابد. با استفاده از پردازش موازی، این عملیات در کمتر از 10 ثانیه انجام شد که زمان مناسبی برای حجم دادههای متوسط محسوب میشود.