
الگوریتم گرادیان کاهشی تصادفی یا SGD

مقدمه
در یادگیری ماشین و هوش مصنوعی، توانایی بهینهسازی مؤثر مدلها برای موفقیت آنها بسیار حیاتی است. یکی از پرکاربردترین روشها برای بهینهسازی الگوریتم گرادیان کاهشی (Gradient Descent) است که نقشی اساسی در ترین مدلها ایفا میکند و هدف آن کاهش تابع خطا یا هزینه است. با این حال، نسخهای کارآمدتر از این تکنیک، بهویژه در دادههای حجیم و یادگیری عمیق، گرادیان کاهشی تصادفی یا SGD است. در این مقاله، به بررسی این الگوریتم، تفاوتهای آن با گرادیان کاهشی معمولی و دلایل محبوبیت آن خواهیم پرداخت.
گرادیان کاهشی چیست؟
گرادیان کاهشی یک الگوریتم بهینهسازی است که برای حداقل کردن یک تابع (در یادگیری ماشین میتواند تابع خطا باشد) از طریق حرکت تدریجی به سمت شیب منفی آن استفاده میشود. "گرادیان" به بردار مشتقات جزئی تابع اطلاق میشود که نشاندهنده جهت و میزان تغییرات آن تابع است. الگوریتم بهطور مداوم پارامترهای مدل را بر اساس جهت و میزان این گرادیان بهروزرسانی میکند.
در یادگیری ماشین، این تابع هزینه معمولاً نشاندهنده تفاوت بین پیشبینی مدل و مقادیر واقعی است. هدف از استفاده از گرادیان کاهشی، حداقل کردن این خطا با تنظیم مداوم پارامترهای مدل است. اندازه این تنظیمات از طریق پارامتر نرخ یادگیری کنترل میشود.

ویژگی تصادفی بودن در الگوریتم SGD
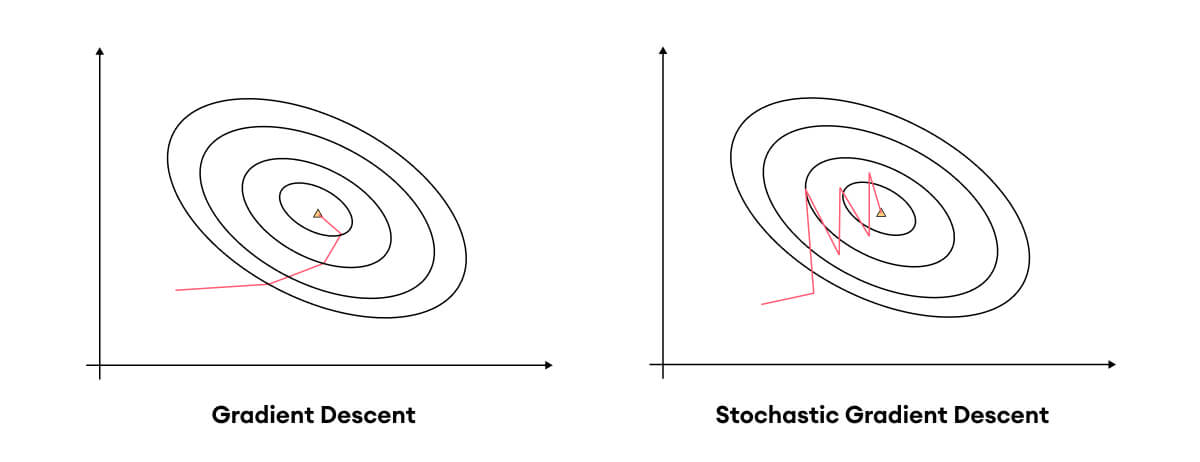
در حالی که گرادیان کاهشی معمولی، گرادیان را بر اساس تمام دادهها محاسبه میکند، گرادیان کاهشی تصادفی تفاوت مهمی دارد: بهجای محاسبه گرادیان بر اساس کل دادهها، پارامترها پس از پردازش هر نمونه داده بهصورت فردی (و یا مجموعهای کوچک از دادهها که به آن minibatch گفته میشود) بهروزرسانی میشوند.
تفاوت اصلی بین گرادیان کاهشی معمولی و گرادیان کاهشی تصادفی در نحوه محاسبه گرادیان است:
- گرادیان کاهشی: در این روش، گرادیان با استفاده از تمام دادهها محاسبه میشود که این کار بهطور دقیقتری پارامترها را بهروزرسانی میکند. با این حال، عیب آن این است که پردازش تمام دادهها ممکن است بسیار زمانبر و پرهزینه باشد (به ویژه در داده های بزرگ)، همچنین ممکن است در همان مراحل اول در مینیموم نسبی تابع متوقف شود .
- گرادیان کاهشی تصادفی: در الگوریتم SGD ، پس از پردازش هر داده یا minibatch، پارامترها بهروزرسانی میشوند. این موضوع باعث میشود که الگوریتم سریعتر و کاراتر باشد زیرا برای هر مرحله به حافظه و محاسبات کمتری نیاز دارد. اما این بهروزرسانیها ممکن است نوسانات زیادی داشته باشند چون گرادیان محاسبهشده برای هر داده بهتنهایی ممکن است تغییرات قابل توجهی داشته باشد. (هر چند این نوسانات میتوانند باعث رد کردن مینیموم های نسبی شوند)
مزایای الگوریتم SGD
- همگرایی سریعتر : الگوریتم SGD میتواند سریعتر به یک راهحل تقریبی برسد. این ویژگی بهویژه در دادههای حجیم مفید است.
- کارایی بالا: به دلیل اینکه نیازی به پردازش تمام دادهها بهطور همزمان ندارد، الگوریتم SGD از نظر منابع حافظه و محاسباتی کارآمدتر است. این ویژگی آن را برای یادگیری عمیق و مسائل با دادههای بزرگ مناسب میکند.
- فرار از مینیممهای نسبی: یکی از ویژگیهای جالب الگوریتم SGD نوسانی بودن آن است. این نوسانات میتوانند به الگوریتم کمک کنند تا از مینیممهای محلی و نقاط گرهای که ممکن است گرادیان کاهشی را گیر بیاندازند فرار کند و به مینیمم بهتری برسد.
معایب الگوریتم SGD
با وجود مزایای فراوان، الگوریتمSGD چند محدودیت نیز دارد. نوسانهای زیاد ممکن است باعث شوند که الگوریتم نتواند به درستی به مینیمم مطلق برسد و در اطراف آن نوسان کند. برای مقابله با این مشکلات، تغییرات مختلفی در الگوریتم SGD ایجاد شده است:
- گرادیان کاهشی minibatch: بهجای استفاده از یک داده بهتنهایی، در این نسخه از SGD از یک زیرمجموعه تصادفی از دادهها برای محاسبه گرادیان استفاده میشود. این رویکرد تعادلی میان دقت گرادیان کاهشی و سرعت الگوریتم SGD ایجاد میکند.
- تکانه: تکانه یکی از تغییرات الگوریتم SGD است که به کاهش نوسانات کمک میکند. این تغییر باعث میشود که بهروزرسانیهای جدید به گذشته توجه کنند و در نتیجه به بهبود همگرایی کمک کنند.
- نرخ یادگیری تطبیقی: میتوان برای کاهش نوسان گرادیان کاهشی از برنامه ریز ها (schedulers) یا الگوریتم های تطبیقی دیگر مثل adam بجای sgd استفاده کرد .
نتیجهگیری
الگوریتم گرادیان کاهشی تصادفی یک روش بهینهسازی قدرتمند و کارآمد است که در یادگیری ماشین، بهویژه در مسائل بزرگ و یادگیری عمیق، نقشی اساسی دارد. با اینکه الگوریتمSGD دارای معایبی مانند نوسانات زیاد است، مزایای آن در سرعت، کارایی حافظه و توانایی فرار از مینیممهای محلی باعث محبوبیت آن شده است. با وجود این محدودیتها، تغییرات مختلفی مانند minibatch SGD و استفاده از روشهای تطبیقی به بهبود عملکرد آن کمک کرده و این الگوریتم را به یکی از ابزارهای اصلی در بهینهسازی مدلها تبدیل کرده است.
مطلبی دیگر از این انتشارات
هوش مصنوعی کوانتوم(Quantum AI)
مطلبی دیگر از این انتشارات
محاسبات سرورلس: تحولی در استقرار برنامهها
مطلبی دیگر از این انتشارات
رقابت چتباتها: Google Bard در برابر ChatGPT