

بعضی وقتا زمانی که در یک جای تاریک هستید فکر میکنید دفن شدهاید اما در واقع شما کاشته شدهاید
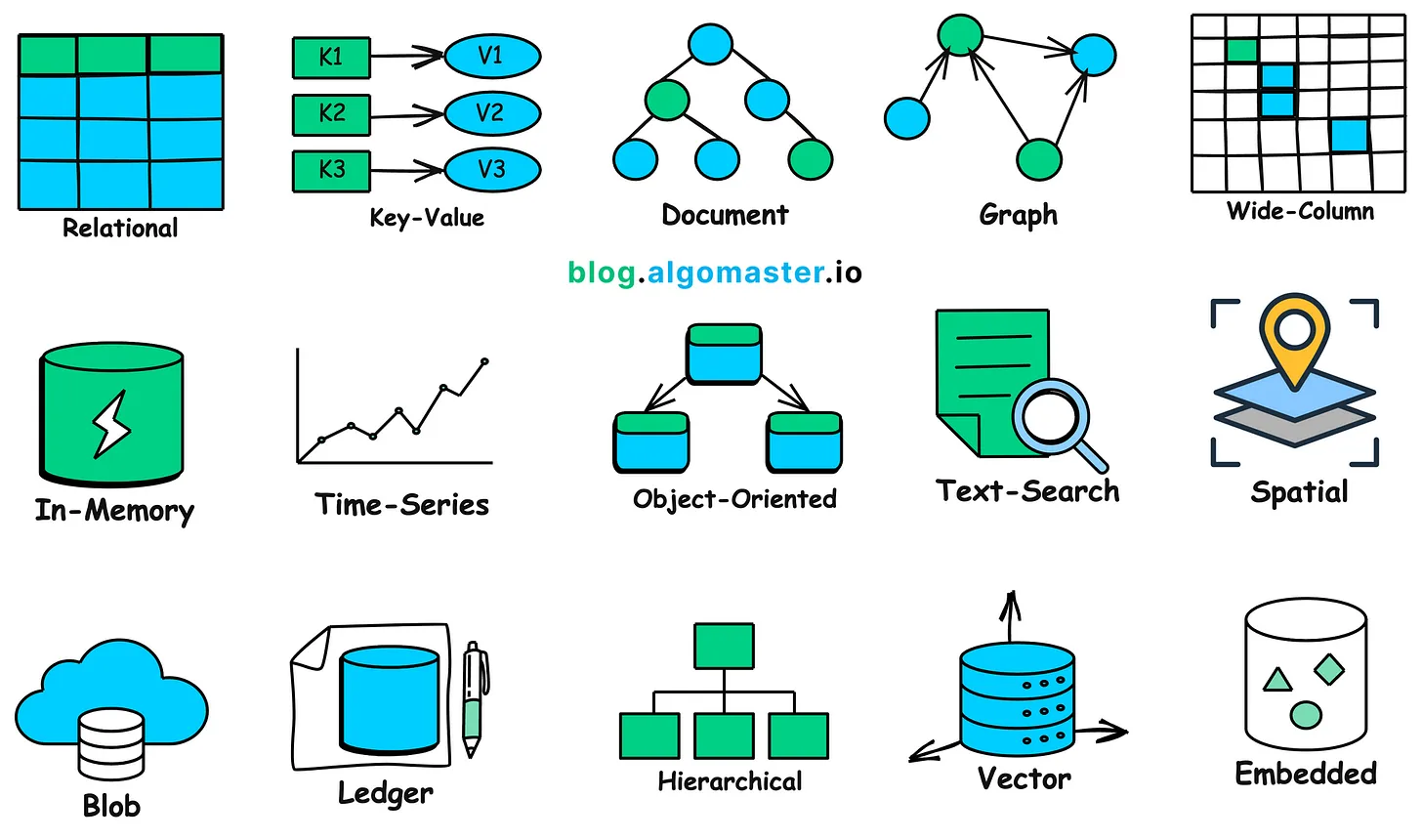
انواع دیتابیسها در System Design
کِی از کدوم دیتابیس استفاده کنیم؟ (خیلی ساده و کاربردی)
وقتی صحبت از طراحی سیستم میشود، یکی از اولین و مهمترین تصمیمها این است:
دادهها را کجا و چطور ذخیره کنیم؟
انتخاب اشتباه دیتابیس یعنی:
سیستم کند
هزینهی بالا
مقیاسپذیری سخت
و در نهایت بازنویسی دردناک
در این بلاگ، قدمبهقدم با نمونههای مختلف دیتابیس آشنا میشویم؛ نه با تعریفهای دانشگاهی، بلکه با این سؤال کلیدی:
«این دیتابیس دقیقاً به چه دردی میخورد و کِی باید سراغش بروم؟»
دیتابیسهای رابطهای (Relational Databases)
ایدهی اصلی چیست؟
دیتابیسهای رابطهای دادهها را داخل جدول ذخیره میکنند.
هر جدول:
سطر دارد (رکورد)
ستون دارد (فیلد)
و یک شناسهی یکتا (ID)
جدولها میتوانند به هم وصل شوند؛ دقیقاً مثل اکسل، اما بسیار قویتر.
مثال ساده:
جدول کاربران
جدول سفارشها
هر سفارش میداند متعلق به کدام کاربر است.
چرا هنوز اینقدر محبوباند؟
چون:
ساختار مشخص دارند
جلوی خراب شدن داده را میگیرند
برای دادههای حساس فوقالعادهاند
این دیتابیسها از چیزی به اسم تراکنش استفاده میکنند. یعنی:
یا همهی عملیات انجام میشود، یا هیچکدام.
این ویژگی برای پول، حساب، سفارش و پرداخت حیاتی است.
کِی انتخاب درستی هستند؟
اگر سیستم تو این ویژگیها را دارد:
دادهها ساختار مشخص دارند
ارتباط بین دادهها مهم است
خطا در داده فاجعه است
مثالهای واقعی:
سیستمهای بانکی
فروشگاههای آنلاین
نرمافزارهای سازمانی ( حقوق، انبار)
جمعبندی سریع
دیتابیس رابطهای = نظم، امنیت، اعتماد
اگر شک داری، معمولاً شروع با دیتابیس رابطهای انتخاب امنتری است.
دیتابیسهای Key-Value (کلید–مقدار)
ایدهی اصلی چیست؟
خیلی ساده:
key → valueمثل یک دیکشنری بزرگ.
مثال:
"user:123" → { name: "Ali", theme: "dark" }نه جدول داریم، نه رابطه، نه پیچیدگی.
چرا از اینها استفاده میکنیم؟
چون:
خیلی سریعاند
بهراحتی مقیاسپذیر میشوند
برای دادههای موقتی عالیاند
ولی حواست باشد:
این دیتابیسها برای تحلیلهای پیچیده ساخته نشدهاند.
کِی انتخاب درستی هستند؟
وقتی:
فقط میخواهی چیزی را سریع ذخیره و سریع بخوانی
رابطهی بین دادهها مهم نیست
سرعت از همه چیز مهمتر است
مثالهای واقعی:
ذخیرهی session کاربر
کش کردن اطلاعات
نگهداری توکنها
دادههای لحظهای
جمعبندی سریع
Key-Value = سرعت بالا، سادگی، مصرف کم
اگر دیتابیس رابطهای مغز سیستم است، Key-Value حافظهی کوتاهمدت آن است.
دیتابیسهای سندی (Document Databases)
ایدهی اصلی چیست؟
اینجا هر داده یک سند کامل است؛ معمولاً به شکل JSON.
مثال:
{
"name": "Laptop",
"price": 1200,
"features": ["SSD", "16GB RAM"],
"reviews": [...]
}هیچ اجباری نیست همهی سندها دقیقاً شبیه هم باشند.
چرا این انعطاف مهم است؟
چون در خیلی از سیستمها:
دادهها دائم تغییر میکنند
فیلدها اضافه یا حذف میشوند
ساختار ثابت ندارند
دیتابیسهای سندی این تغییرات را بدون دردسر میپذیرند.
کِی انتخاب درستی هستند؟
وقتی:
دادهها نیمهساختاریافتهاند
سرعت توسعه مهمتر از سختگیری دیتابیس است
مدل داده مرتب تغییر میکند
مثالهای واقعی:
سیستمهای محتوا (CMS)
فروشگاههایی با محصولات متنوع
دادههای IoT
پروفایل کاربران
دیتابیسهای گرافی (Graph Databases)
تا اینجا دربارهی جدول، کلید–مقدار و سند حرف زدیم.
اما یک سؤال مهم:
اگر خودِ «ارتباط» از خودِ داده مهمتر باشد چه؟
اینجاست که دیتابیسهای گرافی وارد بازی میشوند.
ایدهی اصلی چیست؟
در دیتابیس گرافی، دادهها به شکل نقشهی ارتباطات ذخیره میشوند، نه جدول.
سه مفهوم پایه داریم:
Node (گره): موجودیتها (مثل کاربر، محصول، مقاله)
Edge (یال): رابطهها (دوستِ، خریده، دنبال میکند)
Property: اطلاعات اضافه روی گره یا رابطه
مثال خیلی ساده:
علی ← دوستِ → رضا
علی ← خریده → لپتاپ
لپتاپ ← متعلق به → برند X
اینجا «چه کسی به چه کسی وصل است» مهمتر از خود عددهاست.
چرا دیتابیسهای معمولی اینجا کم میآورند؟
در دیتابیس رابطهای:
برای پیدا کردن ارتباطها باید JOIN پشت JOIN بزنی
هرچه ارتباطها پیچیدهتر شوند، کوئریها کندتر و سختتر میشوند
اما دیتابیس گرافی دقیقاً برای این سؤال ساخته شده:
«از این نقطه، چطور به بقیهی نقاط برسیم؟»
کِی انتخاب درستی هستند؟
وقتی:
روابط چندلایه و تو در تو هستند
تحلیل ارتباطها مهمتر از ذخیرهی عدد و متن است
سیستم باید سریع روی ارتباطها حرکت کند
مثالهای واقعی و ملموس
شبکههای اجتماعی (دوست، فالو، تعامل)
سیستمهای پیشنهاددهنده (این کاربر شبیه کیست؟)
گراف دانش (ارتباط مفاهیم، اشخاص، محتوا)
جمعبندی سریع
Graph DB = قدرت تحلیل رابطهها
اگر دیتابیس رابطهای برای «داده» خوب است،
دیتابیس گرافی برای «ارتباط» ساخته شده.
نمونهها:
Neo4j
Amazon Neptune
دیتابیسهای Wide-Column (ستونیِ گسترده)
اسمش ترسناک است، ولی ایدهاش سادهتر از چیزی است که فکر میکنی.
ایدهی اصلی چیست؟
این دیتابیسها شبیه جدولاند، اما:
هر ردیف میتواند ستونهای متفاوت داشته باشد
ستونها میتوانند خیلی زیاد باشند
داده روی چندین سرور پخش میشود
یعنی:
مقیاسپذیری بالا، حتی با حجم عظیم داده
چرا ساخته شدند؟
برای سیستمهایی که:
داده خیلی زیاد مینویسند
توزیعشدهاند
باید همیشه در دسترس باشند
اینجا سرعت نوشتن و تحمل خطا از «دقت لحظهای» مهمتر است.
محدودیت مهم (حواست باشد)
JOIN پیچیده ندارند
ACID کامل ندارند
برای تراکنشهای حساس مالی مناسب نیستند
کِی انتخاب درستی هستند؟
وقتی:
لاگ، رویداد، کلیک، رفتار کاربر ذخیره میکنی
دادهها پیوسته در حال اضافه شدناند
مقیاس خیلی بزرگ است (میلیونها یا میلیاردها رکورد)
مثالهای واقعی
آنالیتیکس وب
مانیتورینگ سیستمها
داشبوردهای لحظهای
جمعبندی سریع
Wide-Column = حجم بالا + توزیعشده + سریع
نمونهها:
Apache Cassandra
Apache HBase
Google Bigtable
دیتابیسهای In-Memory (در حافظه)
حالا برسیم به سریعترین عضو این خانواده.
ایدهی اصلی چیست؟
بهجای دیسک، داده مستقیماً داخل RAM نگهداری میشود.
نتیجه؟
سرعت بسیار بالا
تأخیر بسیار کم
پاسخ تقریباً آنی
چرا اینقدر سریعاند؟
چون:
دیسک حذف شده
I/O وجود ندارد
همهچیز در حافظه است
اما هیچ جادویی بدون هزینه نیست.
محدودیت مهم
RAM گران است
حجمش محدود است
اگر مراقب نباشی، داده از دست میرود (مگر با مکانیزمهای پشتیبان)
کِی انتخاب درستی هستند؟
وقتی:
سرعت از همه چیز مهمتر است
داده موقتی یا نیمهموقتی است
سیستم real-time میخواهی
مثالهای واقعی
بازیهای آنلاین (state بازی، session)
معاملات لحظهای مالی
کش کردن دادههای پرتکرار
جمعبندی سریع
In-Memory = سرعت برقآسا
نه برای همهچیز،
بلکه برای جاهایی که «کند بودن» غیرقابل قبول است.
نمونهها:
Redis
Memcached
یک نکتهی خیلی مهم (Blind Spot رایج)
سیستمهای واقعی معمولاً فقط یک دیتابیس ندارند.
مثلاً:
PostgreSQL برای دادههای اصلی
Redis برای کش
Cassandra برای لاگها
Graph DB برای پیشنهاددهی
این یعنی:
System Design = ترکیب هوشمندانه، نه تعصب روی یک ابزار
دیتابیسهای Time-Series (دادههای زمانی)
یک سؤال ساده اما کلیدی:
اگر مهمترین ویژگی داده، «زمان» باشد چه؟
مثلاً:
هر ثانیه CPU چقدر مصرف شده؟
قیمت سهم در طول روز چطور تغییر کرده؟
دمای سنسور هر ۵ ثانیه چقدر بوده؟
اینجا با «دادهی معمولی» طرف نیستیم؛ با دادهی زمانی طرفیم.
ایدهی اصلی چیست؟
دادههای Time-Series یعنی:
یک مقدار + یک timestamp
مثال:
(10:01:05) → CPU = 42%
(10:01:10) → CPU = 47%این دادهها:
پشت سر هم میآیند
حجمشان زیاد است
معمولاً قدیمیها کمتر استفاده میشوند
دیتابیسهای معمولی با این الگو زود به زانو درمیآیند.
TSDB چه کار متفاوتی میکند؟
این دیتابیسها برای زمان ساخته شدهاند:
نوشتن سریع پشتسرهم
فشردهسازی هوشمند
کوئریهای مبتنی بر بازهی زمانی
حذف خودکار دادههای قدیمی (Retention)
کِی انتخاب درستی هستند؟
وقتی:
داده مرتب تولید میشود
«روند» مهمتر از «رکورد تکی» است
تحلیل در طول زمان داری
مثالهای واقعی
مانیتورینگ سرورها
دادههای IoT و سنسورها
بازارهای مالی
داشبوردهای performance
جمعبندی سریع
Time-Series DB = استادِ دادههای زماندار
اگر دیتابیس رابطهای برای «وضعیت فعلی» خوب است،
TSDB برای «رفتار در طول زمان» ساخته شده.
نمونهها:
InfluxDB
TimescaleDB
Prometheus
دیتابیسهای شیگرا (Object-Oriented Databases)
حالا یک سناریوی آشنا برای برنامهنویسها:
اگر داده دقیقاً همان چیزی باشد که در کدت داری؟
نه جدول،
نه JSON،
نه مپینگ.
خودِ آبجکت.
ایدهی اصلی چیست؟
در دیتابیس شیگرا:
داده = object
object = instance از class
همراه با attribute و حتی behavior
یعنی همان چیزی که در Java، Python یا C++ مینویسی، مستقیم ذخیره میشود.
چرا این ایده جذاب است؟
چون:
نیاز به ORM کم میشود
تبدیل object ↔ table حذف میشود
مدلهای پیچیده راحتتر مدیریت میشوند
اما یک نکتهی مهم را نباید نادیده گرفت…
واقعیت بازار (نکتهی مهم)
این دیتابیسها:
رایج نیستند
اکوسیستم کوچکی دارند
در مقیاس بزرگ کمتر استفاده میشوند
به همین دلیل، بیشتر خاصمنظوره هستند.
کِی انتخاب درستی هستند؟
وقتی:
مدل داده خیلی پیچیده است
منطق برنامه شدیداً شیگراست
سادگی توسعه از همه چیز مهمتر است
مثالهای واقعی
سیستمهای شبیهسازی
دادههای چندرسانهای
اپلیکیشنهای علمی یا تحقیقاتی
جمعبندی سریع
OODB = طبیعی برای OOP، خاص برای موارد محدود
نمونهها:
ObjectDB
db4o
دیتابیسهای جستجوی متنی (Text Search Databases)
سؤال:
اگر کاربر بخواهد «جستجو» کند، نه فقط query ساده؟
مثلاً:
«لپتاپ سبک برای برنامهنویسی»
«خطاهای مربوط به timeout در لاگها»
اینجا LIKE و WHERE کافی نیست.
ایدهی اصلی چیست؟
این دیتابیسها برای:
ایندکسکردن متن
جستجوی سریع
رتبهبندی نتایج
ساخته شدهاند، نه برای ذخیرهی دادهی اصلی.
چه قابلیتهایی دارند؟
Full-Text Search
فازی سرچ (غلط املایی)
Ranking نتایج
فیلتر، highlight، aggregation
کِی انتخاب درستی هستند؟
وقتی:
حجم متن زیاد است
سرعت جستجو حیاتی است
تجربهی کاربر مهم است
مثالهای واقعی
جستجوی محصولات فروشگاه
موتورهای جستجو
تحلیل و جستجوی لاگها
جمعبندی سریع
Text Search DB = موتور جستجو، نه دیتابیس اصلی
معمولاً کنار دیتابیس اصلی میآید، نه بهجای آن.
نمونهها:
Elasticsearch
Apache Solr
Sphinx
نکتهی استراتژیک (جایی که خیلیها اشتباه میکنند)
TSDB برای گزارش و مانیتورینگ
Search DB برای جستجو
DB اصلی برای دادهی مرجع
دیتابیسهای مکانی (Spatial Databases)
یک سؤال ساده:
اگر «مکان» جزو دادهی اصلی باشد چه؟
نه فقط اسم شهر یا کشور،
بلکه:
فاصله
مسیر
محدوده
همپوشانی
اینجا دیتابیس معمولی جواب نمیدهد.
ایدهی اصلی چیست؟
دیتابیسهای مکانی برای ذخیره و تحلیل دادههای جغرافیایی ساخته شدهاند.
این دادهها میتوانند باشند:
نقطه (Point) → مثل موقعیت کاربر
خط (Line) → مثل مسیر حرکت
چندضلعی (Polygon) → مثل محدودهی یک شهر
و مهمتر از خود داده:
«رابطهی مکانی بین آنها»
چرا دیتابیس معمولی کم میآورد؟
سؤالات مکانی از این جنساند:
نزدیکترین رستوران به من کدام است؟
این مسیر از کدام مناطق عبور میکند؟
این دو محدوده همپوشانی دارند یا نه؟
برای اینها، دیتابیسهای مکانی از ایندکسهای مخصوص (مثل R-tree) استفاده میکنند تا کوئریها سریع باشند.
کِی انتخاب درستی هستند؟
وقتی:
مکان و فاصله مهم است
کاربر location دارد
تحلیل جغرافیایی انجام میدهی
مثالهای واقعی
نقشهها و مسیریابی
سرویسهای location-based
لجستیک و حملونقل
ردیابی خودرو و ناوگان
جمعبندی سریع
Spatial DB = داده + مکان + تحلیل جغرافیایی
اغلب بهصورت افزونه روی دیتابیسهای دیگر استفاده میشوند، نه بهتنهایی.
نمونهها:
PostGIS
Oracle Spatial
Blob Datastore (ذخیرهسازی فایلهای حجیم)
حالا یک اشتباه رایج:
ذخیرهی فایل داخل دیتابیس رابطهای.
اگر این کار را میکنی، احتمالاً داری اشتباه میروی.
ایدهی اصلی چیست؟
Blob Datastore برای نگهداری:
تصویر
ویدیو
صدا
فایل
بکاپ
ساخته شده، نه برای جدول و رکورد.
اینجا داده:
ساختار ندارد
بزرگ است
زیاد دانلود میشود
چرا دیتابیس معمولی مناسب نیست؟
چون:
حجم فایلها بالاست
Backup سخت میشود
Performance میریزد
هزینه بالا میرود
Blob Storage دقیقاً برای همین سناریو بهینه شده است.
کِی انتخاب درستی هستند؟
وقتی:
فایل زیاد داری
دسترسی global میخواهی
durability و scalability مهم است
مثالهای واقعی
ذخیرهی تصاویر اپلیکیشن
ویدیو استریم
لاگهای حجیم
بکاپ و آرشیو
جمعبندی سریع
Blob Storage = فایلها بیرون، دیتا داخل دیتابیس
این دو را قاطی نکن.
نمونهها:
Amazon S3
Azure Blob Storage
HDFS
دیتابیسهای Ledger (دفترکل / تغییرناپذیر)
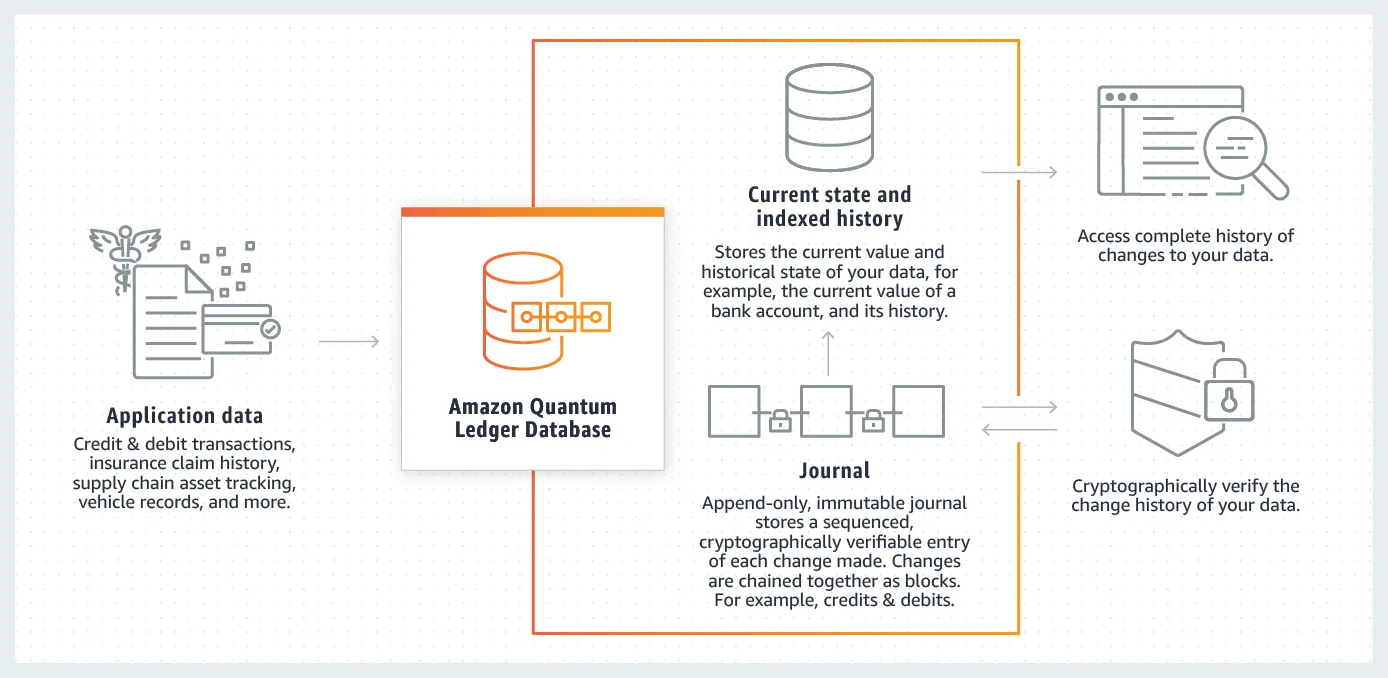
اینجا با یک مفهوم جدی طرفیم:
دادهای که نباید تغییر کند. حتی توسط ادمین.
ایدهی اصلی چیست؟
Ledger Database یعنی:
فقط اضافه میکنی
حذف و ویرایش وجود ندارد
همهچیز تاریخچه دارد
تغییر قابل اثبات است
این شبیه بلاکچین است، ولی الزاماً عمومی یا رمزنگاریشده مثل کریپتو نیست.
چرا مهماند؟
چون در بعضی سیستمها:
اعتماد حیاتی است
دستکاری فاجعه است
ردپا باید بماند
کِی انتخاب درستی هستند؟
وقتی:
شفافیت مهم است
audit trail میخواهی
داده حقوقی یا حساس است
مثالهای واقعی
زنجیره تأمین
سوابق پزشکی
سیستم رأیگیری
قراردادها
جمعبندی سریع
Ledger DB = حقیقتی که قابل پاک شدن نیست
نمونهها:
Amazon QLDB
Hyperledger Fabric
دیتابیسهای سلسلهمراتبی (Hierarchical Databases)
و حالا یک مدل قدیمی، اما هنوز مهم برای فهم.
ایدهی اصلی چیست؟
دادهها به شکل درخت ذخیره میشوند:
هر نود یک والد دارد
میتواند چند فرزند داشته باشد
رابطه فقط یکطرفه است
مثل:
پوشهها
ساختار سازمانی
چرا امروز کمتر استفاده میشوند؟
چون:
انعطاف کمی دارند
تغییر ساختار سخت است
روابط پیچیده را خوب هندل نمیکنند
به همین دلیل، دیتابیسهای رابطهای و NoSQL جای آنها را گرفتهاند.
کِی هنوز کاربرد دارند؟
وقتی:
ساختار واقعاً درختی است
رابطهها ساده و ثابتاند
تغییر کم است
مثالهای واقعی
ساختار فایل سیستم
چارت سازمانی
تنظیمات سیستمی
جمعبندی سریع
Hierarchical DB = ساده، قدیمی، محدود
بیشتر برای فهم مدل داده مهماند تا انتخاب در پروژههای جدید.
نمونهها:
IBM IMS
Windows Registry
دیتابیسهای برداری (Vector Databases)
یک سؤال خیلی مهم در دنیای امروز:
اگر داده «شبیه» باشد، نه «برابر» چه؟
مثلاً:
این متن شبیه کدام متنهاست؟
این تصویر به کدام تصاویر نزدیکتر است؟
سلیقهی این کاربر به کدام کاربران میخورد؟
اینجا = و WHERE کاملاً بیمصرفاند.
ایدهی اصلی چیست؟
در دیتابیسهای برداری:
هر داده به یک بردار عددی تبدیل میشود
این بردارها در فضای چندبُعدی قرار میگیرند
جستجو بر اساس شباهت انجام میشود، نه تطابق دقیق
مثال ذهنی:
متن، تصویر یا صدا → تبدیل به لیست عدد
سپس: «نزدیکترینها» پیدا میشوند
چرا این دیتابیسها ناگهان مهم شدند؟
بهخاطر AI.
مدلهای یادگیری ماشین:
متن را embedding میکنند
تصویر را embedding میکنند
رفتار کاربر را embedding میکنند
و این embeddingها بدون دیتابیس برداری عملاً بلااستفادهاند.
کِی انتخاب درستی هستند؟
وقتی:
جستجوی معنایی میخواهی
recommendation هوشمند داری
با AI، NLP یا vision کار میکنی
مثالهای واقعی
جستجوی تصویری (شبیه این عکس)
پیشنهاد محتوا
تشخیص ناهنجاری
search هوشمند (semantic search)
جمعبندی سریع
Vector DB = قلب سیستمهای AI-محور
این دیتابیسها معمولاً کنار دیتابیس اصلی میآیند، نه بهجای آن.
نمونهها:
Faiss
Milvus
Pinecone
دیتابیسهای Embedded (توکار)
حالا بیاییم برگردیم به سادهترین، اما بسیار کاربردیترین نوع دیتابیس.
ایدهی اصلی چیست؟
Embedded Database:
سرور جدا ندارد
داخل خود اپلیکیشن اجرا میشود
نصب و راهاندازی نمیخواهد
یعنی:
دیتابیس = بخشی از برنامه
چرا این مهم است؟
چون خیلی وقتها:
سیستم کوچک است
یک کاربر دارد
منابع محدودند
سادگی مهمتر از مقیاس است
راهاندازی PostgreSQL یا MongoDB برای این سناریوها زیادهروی است.
کِی انتخاب درستی هستند؟
وقتی:
اپلیکیشن لوکال است
game یا desktop app داری
داده پیچیده یا خیلی حجیم نیست
مثالهای واقعی
ذخیرهی progress بازی
تنظیمات نرمافزار
دادههای آفلاین موبایل یا دسکتاپ
جمعبندی سریع
Embedded DB = سادگی، سرعت، بدون دردسر
نمونهها:
SQLite
RocksDB
Berkeley DB
جمعبندی نهایی (نکتهی استراتژیک)
اگر تا اینجا یک چیز باید یادت مانده باشد، این است:
هیچ دیتابیسی برای همهچیز ساخته نشده.
انتخاب دیتابیس یعنی پاسخ دادن به این سؤالها:
دادهام چه شکلی است؟
سرعت مهمتر است یا دقت؟
رابطه مهم است یا شباهت؟
مقیاس چقدر است؟
هزینه چقدر مهم است؟
سیستمهای حرفهای:
ترکیبیاند
ماژولارند
تعصب ندارند
اگر بخواهم این بلاگ را یک جمله جمع کنم:
System Design یعنی انتخاب آگاهانه، نه استفادهی کورکورانه از ابزار محبوب.
سخن پایانی
در طراحی سیستمهای نرمافزاری، انتخاب دیتابیس یک تصمیم صرفاً فنی یا سلیقهای نیست؛ این انتخاب مستقیماً بر مقیاسپذیری، پایداری، هزینه و حتی آیندهٔ محصول اثر میگذارد. هر نوع دیتابیس—از رابطهای و سندی گرفته تا گراف، زمانی، مکانی و برداری—برای حل مسئلهای خاص طراحی شده است و استفادهٔ نادرست از آنها، معمولاً در مقیاس یا زمان رشد سیستم خودش را به شکل بحران نشان میدهد.
آنچه در System Design اهمیت دارد، نه دانستن نام ابزارها، بلکه درک عمیق الگوهای داده، رفتار سیستم تحت بار، و ترکیب هوشمندانهٔ چند فناوری در کنار یکدیگر است. سیستمهای واقعی معمولاً با یک دیتابیس ساخته نمیشوند، بلکه با معماری درست به تعادل میرسند.
اگر در حال طراحی یا توسعهٔ سامانههای نرمافزاری مقیاسپذیر، سیستمهای دادهمحور، یا محصولات مبتنی بر real-time، analytics یا AI هستید، تیم معماری و توسعهٔ نرمافزار شرکت راهکار نگار هوشمند (آرکان) میتواند از تحلیل مسئله و انتخاب معماری مناسب، تا طراحی زیرساخت داده و پیادهسازی عملیاتی، همراه شما باشد.
این مقاله با هدف انتقال تجربه و ارتقای نگاه معماری در انتخاب دیتابیسها، توسط تیم توسعهٔ نرمافزار شرکت راهکار نگار هوشمند (آرکان) تهیه شده است.
#System_Design
#Database_Architecture
#Software_Architecture
#Backend_Engineering
#Distributed_Systems
#Scalable_Systems
#Data_Engineering
#NoSQL
#AI_Systems
#RealTime_Systems
#شرکت_راهکار_نگار_هوشمند
#arcanco
مطلبی دیگر از این انتشارات
چرا Cohesion (یکپارچگی) و Coupling (وابستگی) مهماند؟
مطلبی دیگر از این انتشارات
چرا جمعآوری نیازمندیها اینقدر مهم است؟ یک گپ دوستانه با شما!
مطلبی دیگر از این انتشارات
معماری MaMa-CRM در قالب arc42