

توسعه دهنده فرانت -اند و طراح رابط/تجربه کاربری
وب اسکرپینگ (Web Scraping) با JavaScript و Node.js
جاوا اسکریپت با پیشرفتهایی که داشته و همچنین معرفی Node.js، حالا به یکی از محبوبترین و پر استفادهترین زبانهای برنامهنویسی دنیا تبدیل شده. فرقی نمیکنه قصد توسعه نرمافزار وب داشته باشید و یا نرم افزار موبایل و دسکتاپ، جاوااسکریپت برای هر کاری کلی ابزار قدرتمند در اختیارتان قرار میده. حالا قصد دارم تو این مقاله بهتون نشون بدم که چطوری با استفاده از Node.js میتونید وب اسکرپینگ کنید.

وب اسکرپینگ (Web Scraping) چیست؟
قبل از اینکه بریم سراغ اصل مطلب، بهتره که خیلی خلاصه وب اسکرپینگ رو بهتون توضیح بدم:
به فرآیند جمعآوری خودکار دیتاهای ساختار یافته وب، وب اسکرپینگ و یا استخراج دادههای وب میگیم.
و کاربردهای زیادی از جمله نظارت برروی قیمتها و اخبار، جذب مخاطب، تحقیقات بازاریابی و... داره.
روشهای مختلفی برای اسکرپ کردن وجود داره که هر کدوم مزایا و معایت خاص خودشون رو دارن و من قصد دارم تو این مقاله اسکرپ کردن به روشهای زیر رو توضیح بدم:
- JSON API
- Server-Side Rendered HTML
- JavaScript rendered HTML
و برای هر یک از این ۳ مورد، من از وبسایتهای
(به ترتیب) استفاده میکنم. برای اینکه متوجه بشیم چه چیزی رو باید اسکرپ کنیم، چطوری با استفاده از network request ها API های مربوطه رو پیدا کنیم و چگونه با اسکریپتهای Node.js، این فرآیند رو خودکار کنیم، لازمه که اول موارد رندر شده در صفحه رو بررسی کنیم.
روش شماره ۱: JSON API
یکی از رایجترین روشهای استفاده شده در وب برای لود کردن دیتا، استاده از درخواستهای asynchronous از طرف جاوااسکریپت به API Server و دریافت دادهها با فرمت JSON است که بعد از رندر شدن، به کاربر نمایش داده میشن. در این روش، ما با استفاده از اسکریپت نوشته شده در Node.js، درخواستهای API رو رهگیری میکنیم و سپس شروع به کار روی دادههای JSON میکنیم. برای یادگیری این روش از وبسایت nba.com/stats استفاده میکنیم.
پیدا کردن درخواستهای API
قراره اسکریپتی بنویسیم که اطلاعات مربوط به هر سال LeBron James (بازیکن بسکتبال) رو ذخیره کنه.
مرحله ۱: مطلع شدن از داینامیک بودن دادهها
از اونجایی که فقط میخوایم اطلاعات مروبط به LeBron James رو بگیریم، پس به آدرس nba.com/stats/player/2544 که صفحه این بازیکن میشه میریم.
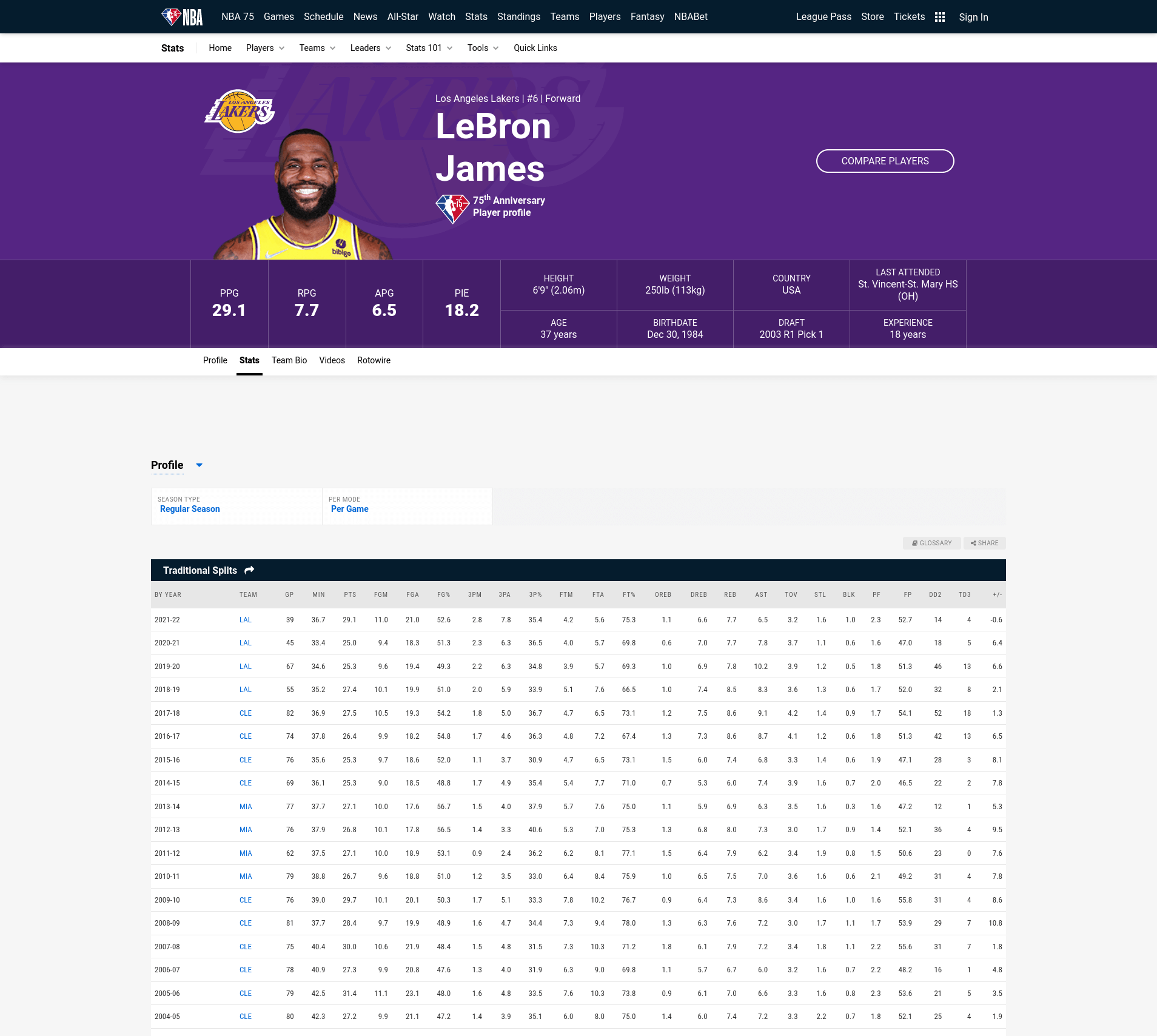
همونطور که میبینید، تمام دادههای مورد نظرمون تو این جدول وجود داره. اما قبل از هرکاری باید برسی کنیم و ببینیم که آیا دیتاها بهصورت استاتیک در جدول HTML قرار داده شدن و یا بهصورت داینامیک و از طریق JSON API لود شدن. برای انجام این کار، روی صفحه راست کلیک کنید و گزینه View Page Source رو بزنید و یا از میانبرهای Ctrl+U استفاده کنید.
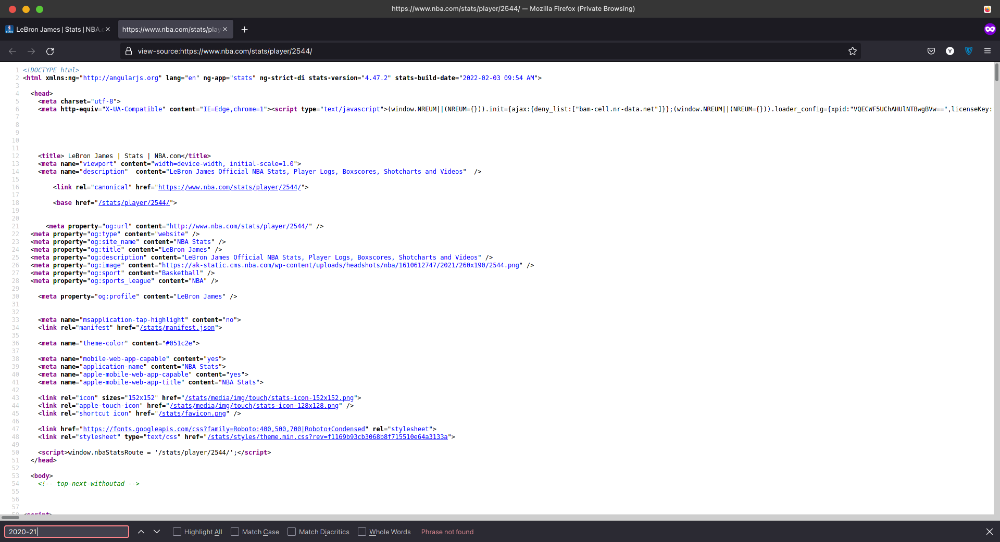
حالا تو صفحه سورس Ctrl+F بزنید و برای مثال عبارت "2020-21" رو سرچ کنید. اگه مثل تصویر پایین عبارتی که سرچ کردید تو سورس نبود، مطلع میشیم که دیتا بهصورت داینامیک و از طریق JSON API لود شده.
مرحله ۲: پیدا کردن API
حالا که از داینامیک بودن دیتاها مطمئن شدیم، وقشته بفهمیم که دیتاها از کجا میان. برای این کار، روی جدول راست کلیک کنید و گزینه inspect رو بزنید و یا از میانبر Ctrl+Shift+I استفاده کنید.
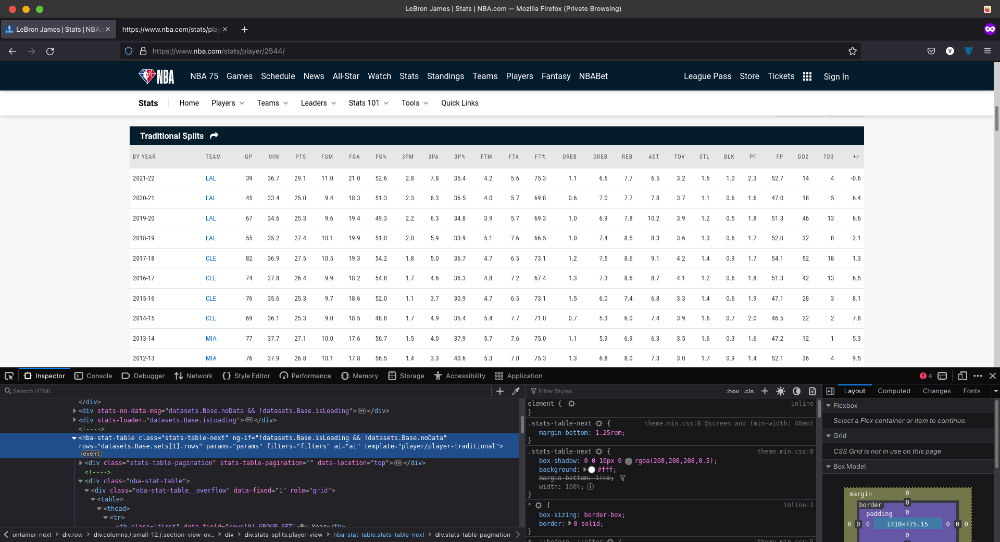
خوشبختانه در تگ <nba-stat-table> یکسری سرنخ وجود داره که کمی تو این کار کمکمون میکنه.
<nba-stat-table
ng-if="!datasets.Base.isLoading && !datasets.Base.noData"
rows="datasets.Base.sets[1].rows"
params="params"
filters="filters"
ai="ai"
template="player/player-traditional" >همونطوری که مشاهده میکنید، جدول به datasets.Base و datasets.Base.sets[1].rows اشاره میکنه. حالا باید به دنبال network call هایی بگردیم که با درخواستهای API تطابق دارن. برای انجام این کار، به تب Network میریم و صفحه رو یکبار رفرش میکنیم تا تمام درخواستها ثبت بشن.
بعد از اینکه به تب Network رفتید و صفحه رو رفرش کردید، چیزایی که در تصویر زیر مشاهده میکنید رو شماهم باید در تب Network مرورگرتون مشاهده کنید. (بسته به مرورگتون ممکنه developer tools شما با مال من کمی متفاوت باشه که چیز مهمی نیست)
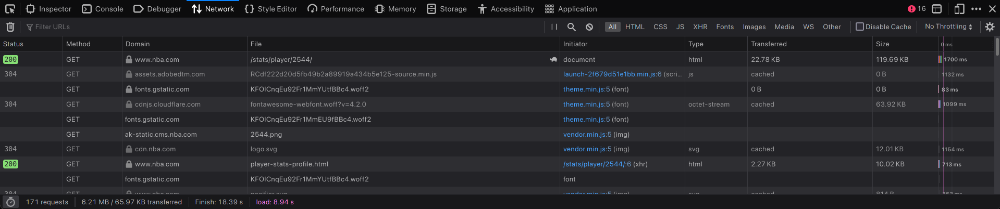
اینا تمام درخواستهایی هستند که مرورگر برای رندر کردن صفحه درست میکنه. حالا باید دنبال درخواست API مدنظرمون بگردیم. برای اینکار، روی آیکون XHR کلیک کنید و در کادر مربوط به سرچ، عبارت "Base" رو تایپ کنید.
بعد از اعمال فیلتر، از بین درخواستها دنبال درخواستی بگردید که مانند تصویر زیر، در Response آن یکسری اطلاعات JSON برامون برگردونده باشه:
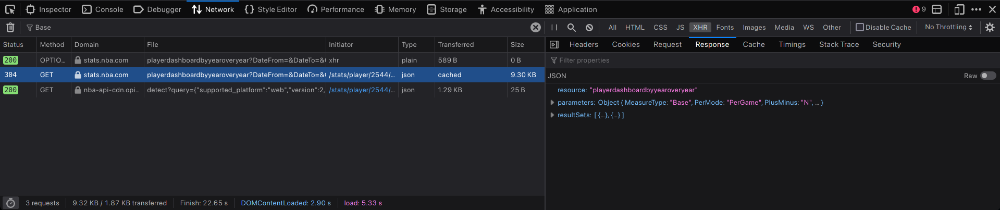
حالا با استفاده از سرنخهایی که قبلا از جدولمون پیدا کردیم، میدونیم که برای پیدا کردن دادههای جدول باید دنبال دیتاستی به اسم Base بگردیم. با کمی دقت به دادههای Response متوجه میشیم که دومین آیتم موجود در resultSets با دادههای جدول مطابقت داره و همین بهمون نشون میده که این همون درخواست API ای هست که دنبالشیم.
دانلود دادههای Response با استفاده از cURL
حالا که میدوینم چطوری میتونیم دادههایی که برامون از اهمیت برخورد دارن رو بهصورت دستی پیدا کنیم، وقشته که با استفاده از اسکریپت این کار رو خودکار انجام بدیم. در این مرحله قراره از ابزارهای curl و jq در ترمینال استفاده کنیم.
برای این کار نیاز که jq روی سیستمون نصب باشه و اگه نصب نیست برید نصبش کنید.
خب، حالا باز به تب Network برید و روی playerdashboardyearoveryear راست کلیک کنید و از منوی Copy گزینه Copy as cURL رو بزنید. الان تو کلیپبورد سیستممون یه چیزی شبیه به دستور زیر رو داریم:
curl 'https://stats.nba.com/stats/playerdashboardbyyearoveryear?DateFrom=&DateTo=&GameSegment=&LastNGames=0&LeagueID=00&Location=&MeasureType=Base&Month=0&OpponentTeamID=0&Outcome=&PORound=0&PaceAdjust=N&PerMode=PerGame&Period=0&PlayerID=2544&PlusMinus=N&Rank=N&Season=2021-22&SeasonSegment=&SeasonType=Regular+Season&ShotClockRange=&Split=yoy&VsConference=&VsDivision=' \
-H 'Connection: keep-alive' \
-H 'sec-ch-ua: " Not A;Brand"v="99", "Chromium"v="98", "Google Chrome"v="98"' \
-H 'Accept: application/json, text/plain, */*' \
-H 'x-nba-stats-token: true' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36' \
-H 'x-nba-stats-origin: stats' \
-H 'sec-ch-ua-platform: "Linux"' \
-H 'Origin: https://www.nba.com' \
-H 'Sec-Fetch-Site: same-site' \
-H 'Sec-Fetch-Mode: cors' \
-H 'Sec-Fetch-Dest: empty' \
-H 'Referer: https://www.nba.com/' \
-H 'Accept-Language: en-US,en;q=0.9,fa;q=0.8' \
-H 'If-Modified-Since: Sun, 13 Feb 2022 15:37:37 GMT' \
--compressedدستوری که کپی کردید رو با فلگ "--compressed" توی ترمینال paste کنید و بعد از زدن دکمه enter و کمی صبر، میبینیم که پاسخهای JSON برامون برمیگرده.
البته اگه از مرورگر کروم استفاده میکنید دیگه لازم نیست خودتون فلگ --compressed رو اضافه کنید. چون دستور کپی شده از اونجا، خودش این فلگ رو داره.
اگه به فلگهای "-H" توی دستور کپی شده دقت کنید، میبینید که کلی HTTP Header داریم که به خیلی از اونها اصلا نیازی نداریم.
میخوام که درخواستمون تا حد ممکن ساده باشه، پس تا جای ممکنه گزینههای اضافه رو حذف میکنم و چیزی که در آخر برامون میمونه، دستور زیره:
curl 'https://stats.nba.com/stats/playerdashboardbyyearoveryear?DateFrom=&DateTo=&GameSegment=&LastNGames=0&LeagueID=00&Location=&MeasureType=Base&Month=0&OpponentTeamID=0&Outcome=&PORound=0&PaceAdjust=N&PerMode=PerGame&Period=0&PlayerID=2544&PlusMinus=N&Rank=N&Season=2021-22&SeasonSegment=&SeasonType=Regular+Season&ShotClockRange=&Split=yoy&VsConference=&VsDivision=' \
-H 'Connection: keep-alive' \
-H 'x-nba-stats-token: true' \
-H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36' \
-H 'Referer: https://www.nba.com/' \
--compressedاز اونجایی که ریزالتی که تو ترمینال داریم مشاهده میکنیم، اصلا خوانا نیست، پس وقشته که از jq استفاده کنیم. برای این کار، آخر دستورمون "| jq" رو اضافه میکنیم. التبه jq بجز قشنگ و مرتب کردن ریزالت، قابلیتهای دیگهای هم داره. براث مثال، با قرار دادن "| jq .resultSets[1].rowSet[0]" آخر دستور، از jq میخوایم که برامون فقط سطر اول جدول رو برگردونه:
curl 'https://stats.nba.com/stats/playerdashboardbyyearoveryear?DateFrom=&DateTo=&GameSegment=&LastNGames=0&LeagueID=00&Location=&MeasureType=Base&Month=0&OpponentTeamID=0&Outcome=&PORound=0&PaceAdjust=N&PerMode=PerGame&Period=0&PlayerID=2544&PlusMinus=N&Rank=N&Season=2021-22&SeasonSegment=&SeasonType=Regular+Season&ShotClockRange=&Split=yoy&VsConference=&VsDivision=' \
-H 'Connection: keep-alive' \
-H 'x-nba-stats-token: true' \
-H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36' \
-H 'Referer: https://www.nba.com/' \
--compressed | jq '.resultSets[1].rowSet[0]'
خروجی دستور بالا:
[ "By Year", "2021-22", 1610612747, "LAL", "2022-02-12T00:00:00",
40, 20, 20, 0.5, 36.7, 11, 21.1, 0.52, 2.8, 7.9, 0.352, 4.3, 5.7, 0.746,
1.1, 6.8, 7.9, 6.5, 3.2, 1.6, 1, 0.8, 2.3, 5.3, 29, -0.9, 52.7, 15, 4, 19,
19, 11, 18, 14, 2, 3, 7, 1, 1, 8, 17, 17, 9, 10, 6, 6, 15, 17, 10, 4, 7, 2,
15, 4, 18, 6, 17, 9, 264, "2021-22" ]نوشتن اسکریپت Node.js برای اسکرپ کردن چند صفحه
تا اینجای کار URL و HTTP Header هایی که نیاز داریم رو پیدا کردیم و حالا میتونیم اسکریپتی بنویسم که API رو بطور اتوماتیک اسکرپ کنه. این اسکریپت رو میتونید تقریبا با هر زبانی که بخواید بنویسد، اما تو این مقاله قصد داریم تا با استفاده از Node.js و لایبری request این کارو کنیم.
برای ساخت پروژه جاوااسکریپت جدید، به دایرکتوری مد نظرتون برید و تو ترمینال این ۲ دستور زیر رو وارد کنید:
npm init -y
npm install --save request request-promise-nativeحالا باید درخواستمون رو از فرمت cURL به فرمت موردنیاز برای کتابخونه request، ترجمه کنیم. برای اینکه از مزایای async/await بهرهمند هم بشیم و بتونیم کدهای asynchronous و خوانا بنویسیم، از Promise استفاده میکنیم. فایلی به اسم "index.js" ایجاد کنید و کدهای زیر رو توش قرار بدید:
const rp = require("request-promise-native");
const fs = require("fs");
async function main() {
console.log("Making API Request...");
// request the data from the JSON API
const results = await rp({
uri: "https://stats.nba.com/stats/playerdashboardbyyearoveryear?DateFrom=&DateTo=&GameSegment=&LastNGames=0&LeagueID=00&Location=&MeasureType=Base&Month=0&OpponentTeamID=0&Outcome=&PORound=0&PaceAdjust=N&PerMode=PerGame&Period=0&PlayerID=2544&PlusMinus=N&Rank=N&Season=2021-22&SeasonSegment=&SeasonType=Regular+Season&ShotClockRange=&Split=yoy&VsConference=&VsDivision=",
headers: {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
"x-nba-stats-origin": "stats",
"Referer": "https://stats.nba.com/"
},
json: true
});
console.log("Got results =", results);
// save the JSON to disk
await fs.promises.writeFile("output.json", JSON.stringify(results, null, 2));
console.log("Done!");
}
// start the main script
main();و حالا در ترمینال با زدن دستور زیر، اسکریپت رو اجرا کنید:
node index.jsو تمام! حالا اگه به فایل "output.json" که بعد از اجرای دستور بالا، توی دایرکتوریمون ایجاد شده برید، دادههای JSON رو مشاهده میکنید.
گرفتن دیتای سایر بازیکنها
تا اینجا، کارمون تموم شده و اسکریپتی که نوشتیم دیتاهای مربوط به LeBron رو برامون اسکرپ میکنه. اما الان قصد دارم تا این یکم این اسکریپت رو ارتقاع بدم تا علاوه بر دیتای LeBron، دیتای چند بازیکن دیگه رو هم اسکرپ کنه.
اگه به API URL دقت کنید، عبارت "PlayerID" رو مشاهده میکنید:
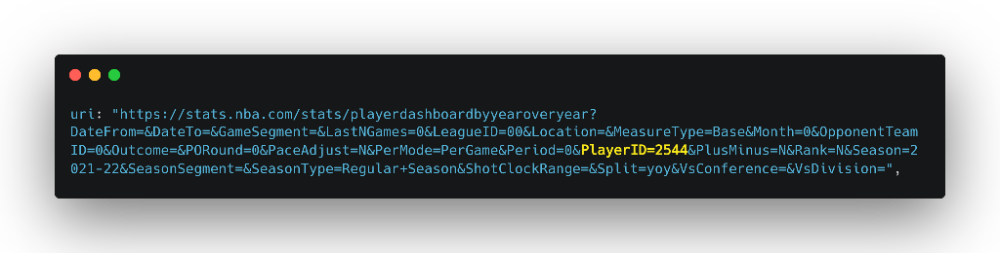
الان فقط به ID سایر بازیکنان نیاز داریم. به صفحه چندتا دیگه از بازیکنا میرم و PlayerID اونارو برمیدارم. در مجموع ما الان ۴ تا بازیکن زیر رو داریم:
Player ID | Player | URL
2544 | LeBron James | https://stats.nba.com/player/2544/
1629029 | Luka Doncic | https://stats.nba.com/player/1629029/
201935 | James Harden | https://stats.nba.com/player/201935/
202695 | Kawhi Leonard | https://stats.nba.com/player/202695/
حالا فقط اسکریپتمون رو به شکل زیر تغییر میدیم تا بتونیم دیتای سایر بازیکنها رو هم اسکرپ کنیم:
const rp = require("request-promise-native");
const fs = require("fs");
// helper to delay execution by 300ms to 1100ms
async function delay() {
const durationMs = Math.random() * 800 + 300;
return new Promise(resolve => {
setTimeout(() => resolve(), durationMs);
});
}
async function fetchPlayerYearOverYear(playerId) {
console.log(`Making API Request for ${playerId}...`);
// add the playerId to the URI and the Referer header
// NOTE: we could also have used the `qs` option for the
// query parameters.
const results = await rp({
uri: "https://stats.nba.com/stats/playerdashboardbyyearoveryear?DateFrom=&DateTo=&GameSegment=&LastNGames=0&LeagueID=00&Location=&MeasureType=Base&Month=0&OpponentTeamID=0&Outcome=&PORound=0&PaceAdjust=N&PerMode=PerGame&Period=0&" +
`PlayerID=${playerId}` +
"&PlusMinus=N&Rank=N&Season=2019-20&SeasonSegment=&SeasonType=Regular+Season&ShotClockRange=&Split=yoy&VsConference=&VsDivision=",
headers: {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
"x-nba-stats-origin": "stats",
"Referer": `https://stats.nba.com/player/${playerId}/`
},
json: true
});
// save to disk with playerID as the file name
await fs.promises.writeFile(
`${playerId}.json`,
JSON.stringify(results, null, 2)
);
}
async function main() {
// PlayerIDs for LeBron, Harden, Kawhi, Luka
const playerIds = [2544, 201935, 202695, 1629029];
console.log("Starting script for players", playerIds);
// make an API request for each player
for (const playerId of playerIds) {
await fetchPlayerYearOverYear(playerId);
// be polite to our friendly data hosts and
// don't crash their servers
await delay();
}
console.log("Done!");
}
// start the main script
main();در کد بالا، من فانکشنی async به اسم fetchPlayerYearOverYear نوشتم و با استفاده از حلقه for، تمام ID های موجود در آرایه رو fetch کردم و از اونجایی هم که نمیخوام سرور رو با تعداد درخواستهای بالام بمب بارون کنم، بعد از هر مرحله fetch، از delay استفاده کردم.
اگه تعداد درخواستهامون در یک مدت زمانی کوتاه زیاد باشه، ممکنه به عنوان اسپمر شناخته بشیم و بلاک شویم.
اولین بخش از مقاله یعنی آموزش اسکرپ کردن به روش JSON API با استفاده از Node.js تموم شد و حالا روش ۲ و ۳ مونده.
روش شماره ۲: Server-side Rendered HTML
علاوه بر روش قبلی که گرفتن دیتا بهصورت async از طریق API بود، روش دیگهای وجود داره که در اون دیتا بهصورت مستقیم و قبل از اینکه صفحه وب لود بشه به HTML رندر میشه. روشی که وب سرورها استفاده میکنن. در این قسمت توضیح میدم که چطوری میتونیم با دانلود و parse کردن (تبدیل) HTML به کمک Cheerio، دیتا استخراج کنیم.
پیدا کردن HTML همراه با دیتا
در ایجا قراره دادههارو از box scores وبسایت espn.com استخراج کنیم.
مرحله ۱: مطلع شدن از داینامیک بودن دادهها
مثل روش اول، در این روش هم باید مطمئن بشیم که دادهها بهصورت داینامیک در صفحه لود میشن.
برای مثال، میخوایم دیتاهای box scores مربوط به یکی از بازیهای بسکتبال 76ers رو اسکرپ کنیم.
لینک گزارش بازی: https://www.espn.com/nba/boxscore?gameId=401160888.
دقیقا همون کاری که در روش ۱ برای دیدن Source صفحه کردیم، اینبار هم انجام میدیم. روی صفحه راست کلیک کنید و گزینه View Page Source رو بزنید و یا از میانبرهای Ctrl+U استفاده کنید.
حالا تو صفحه سورس Ctrl+F بزنید و یکی از نتایجی که تو جدول مشاهده میکنید رو سرچ کنید. برای مثال من "0-11" رو سرچ میکنم.
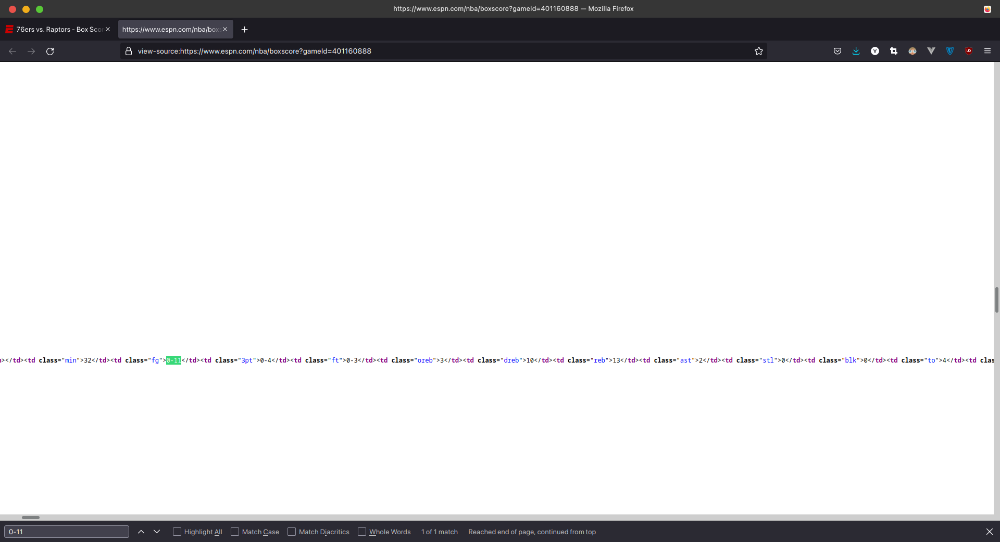
اینم از چیزی که دنبالش بودیم!
مرحله ۲: پیدا کردن نحوه دسترسی به دیتا
بعد از اینکه از وجود دادهها در HTML مطلع شدیم، حالا باید ببینیم که چطوری میتونیم به اونها از طریق مرورگر دسترسی پیدا کنیم. تو اینجا ما به یه چیزی نیاز داریم تا بخشهایی از HTML که برامون اهمیت دارن رو شناسایی کنه، چیزی که CSS Selector ها هم بهخوبی بتونن باهاش کار کنن.
دوباره به صفحه بر میگردیم و روی جدول راست کلیک میکنیم و گزینه Inspect رو میزنیم. در نتجیه باید یه چی شبیه به چیزی که در تصویر زیر میبینید رو مشاهده کنید:
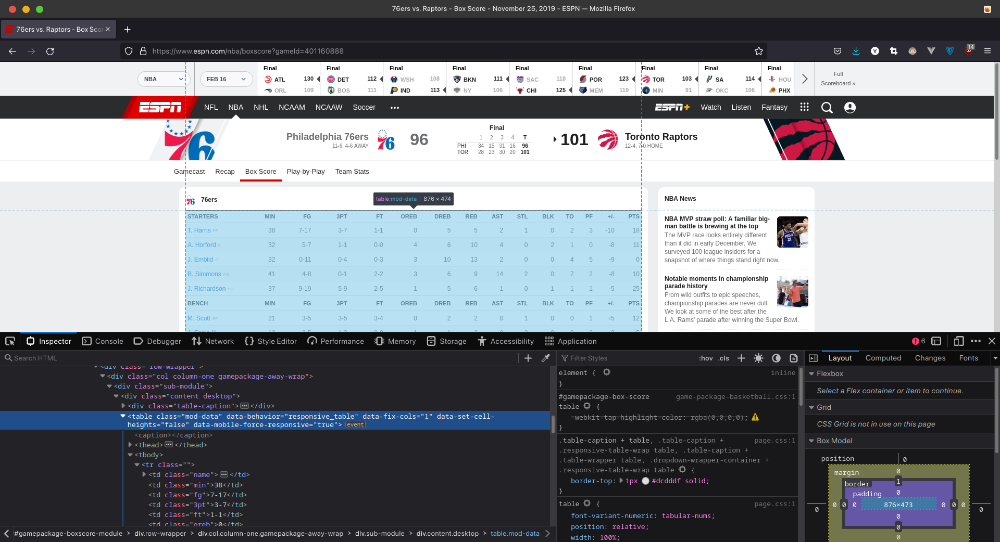
الان به یک Selector نیاز داریم که تمام سطرهای جدول یا همون <tr> هارو برامون برگردونه که این کار رو با استفاده از فانکشن "document.querySelectorAll()" انجام میدیم. برای این کار، توی Console مرورگرتون کد زیر رو بزنید و enter کنید:
document.querySelectorAll('tr')
خروجی کد بالا:
> NodeList(41) [tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr.highlight, tr.highlight, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr.highlight, tr.highlight, tr, tr, tr.highlight, tr.highlight, tr, tr]همونطور که میبینید استفاده از "tr" خیلی کلی هست و کدی که نوشتیم برامون ۴۱ سطر برگردوند و این در حالی است که تیم 76ers فقط ۱۳ بازیکن در جدول داره. دوباره به کدای HTML در Inspector نگاه کنید و متوجه میشید که المنتهای والد تگهای <tr>، یکسری ID و Class دارن:
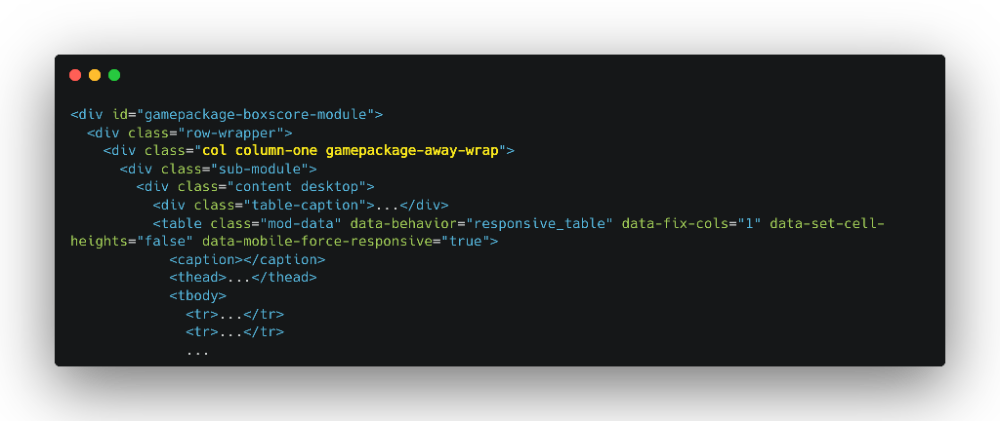
با استفاده از این ID و Class ها، کد Selector مون رو بازنویسی میکنیم:
document.querySelectorAll('.gamepackage-away-wrap tbody tr')خروجی کد بالا:
> NodeList(15) [tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr.highlight, tr.highlight]به هدفمون خیلی نزدیک شدیم. ولی اگه به خروجی نگاه کنید میبینید که دو تگ <tr> با کلاس highlight برامون برگردونده که خلاصه کل سطرهاست و بهشون نیازی نداریم. میتونیم خیلی راحت دستور Selector رو آپدیت کنیم تا اونارو فیلتر کنه:
document.querySelectorAll('.gamepackage-away-wrap tbody tr:not(.highlight)')
خروجی کد بالا:
> NodeList(13) [tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr, tr]عالی شد! حالا یک Selector داریم که تمام سطرهای بازیکنها رو از جدول صفحه Box Score برامون برمیگردونه. کار این قسمت تموم و میشه و حالا نوبت نوشتن اسکریپته.
نوشتن اسکریپت Node.js برای اسکرپ کردن صفحه
الان علاوه بر URL صفحهای که میخوایم اسکرپ کنیم، یک Selector هم داریم که برامون تمام سطرهایی که از جدول صفحه Box Score میخوایم رو برمیگردونه.
دانلود صفحه HTML
کاری که اینجا میخوایم بکنیم، دقیقا مثل کاریه که در روش قبلی انجام دادیم. به دایرکتوری که میخواید پروژتون رو اونجا ایجاد کنید برید و دستورات زیر رو تو ترمینال وارد کنید:
npm init -y
npm install --save request request-promise-nativeمن معمولا ترجیح میدم که فایل HTML رو تو دایرکتوری ذخیره کنم تا وقتی که دارم فرآیند Parse کردن رو تکرار میکنم، مدام به سرور درخواست نفرستم. پس اول بریم یک اسکریپت به اسم "index.js" بسازیم تا صفحه HTML رو برامون دانلود کنه:
const rp = require('request-promise-native');
const fs = require('fs');
async function downloadBoxScoreHtml() {
// where to download the HTML from
const uri = 'https://www.espn.com/nba/boxscore?gameId=401160888';
// the output filename
const filename = 'boxscore.html';
// download the HTML from the web server
console.log(`Downloading HTML from ${uri}...`);
const results = await rp({ uri: uri });
// save the HTML to disk
await fs.promises.writeFile(filename, results);
}
async function main() {
console.log('Starting...');
await downloadBoxScoreHtml();
console.log('Done!');
}
main();حالا با وارد کردن دستور زیر در ترمینال، اسکریپت رو ران میکنیم:
node index.jsحالا در دایرکتوری پروژه، فایلی به اسم boxscore.html داریم که حاوی HTML صفحهی مد نظرمونه.
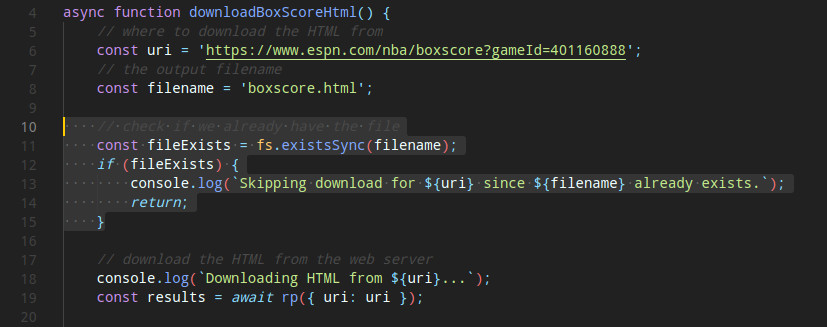
قبل از Parse کردن HTML، بیاید اسکریپت رو آپدیت کنیم تا فقط وقتی فایل رو دانلود که اون فایل در دایرکتوری وجود نداشته باشه. برای انجام این کار، تکه کد زیر (مثل تصویر پایینتر) رو قبل از قسمت ایجاد درخواست اضافه میکنیم:
// check if we already have the file
const fileExists = fs.existsSync(filename);
if (fileExists) {
console.log(`Skipping download for ${uri} since ${filename} already exists.`);
return;
}
تبدیل (Parse) کردن HTML با استفاده از Cheerio
بهترین راه برای بیرون کشیدن دیتا از HTML، استفاده از یک HTML Parser مثل Cheerio میباشد. Cheerio شباهت زیادی با jQuery داره، با این تفاوت که سمت سروره.
ابتدا با زدن دستور زیر در ترمینال، Cheerio رو نصب میکنیم:
npm install --save cheerioبرای شروع و استفاده از Cheerio، باید HTML رو به عنوان رشته (String) بهش پاس بدیم تا اونو برامون Parse و به قول معروف queryable یا قابل پرس و جو کنه و این کارو با استفاده از دستور load انجام میدیم:
const $ = cheerio.load('<html>...</html>')کار خوندن و load کردن فایل HTML توسط Cheerio رو با دستورات زیر انجام میدیم:
// the input filename
const htmlFilename = 'boxscore.html';
// read the HTML from disk
const html = await fs.promises.readFile(htmlFilename);
// parse the HTML with Cheerio
const $ = cheerio.load(html);بعد از اینه HTML پارس شد، میتونیم با استفاده از فانکشن $، Selector مون رو بنویسم:
const $trs = $('.gamepackage-away-wrap tbody tr:not(.highlight)')کدی که نوشتیم، تمام ندهای tr جدول رو برامون برمیگردونه و برای اینکه از این بابت هم مطمئن شیم، میتونیم از "$.html" استفاده کنیم:
console.log($.html($trs));خروجی کد بالا:
<tr>
<td class="name">
<a name="&lpos=nba:game:boxscore:playercard" href="https://www.espn.com/nba/player/_/id/6440/tobias-harris" data-player-uid="s:40~l:46~a:6440">
<span>T. Harris</span>
<span class="abbr">T. Harris</span>
</a>
<span class="position">SF</span>
</td>
<td class="min">38</td>
<td class="fg">7-17</td>
<td class="3pt">3-7</td>
<td class="ft">1-1</td>
<td class="oreb">0</td>
<td class="dreb">5</td>
<td class="reb">5</td>
<td class="ast">2</td>
<td class="ast">1</td>
<td class="ast">0</td>
<td class="ast">1</td>
<td class="ast">2</td>
<td class="ast">3</td>
<td class="plusminus">-10</td>
<td class="pts">18</td>
</tr>
...حالا میتونیم یک object mapping برای اتریبیوت class مربوط به <td> بسازیم تا مقادیر اونو ذخیره کنیم. این کارو روی هر سطر تکرار میکنیم تا تمام دادهها رو بیرون بکشیم:
const values = $trs.toArray().map(tr => {
// find all children <td>
const tds = $(tr).find('td').toArray();
// create a player object based on the <td> values
const player = {};
for (td of tds) {
// parse the <td>
const $td = $(td);
// map the td class attr to its value
const key = $td.attr('class');
const value = $td.text();
player[key] = value;
}
return player:
});حالا اگه یه نگاهی به خروجی کارمون بندازیم، یه چیزی شبیه به مقادیر زیر رو خواهیم داشت:
[
{
"name": "T. HarrisT. HarrisSF",
"min": "38",
"fg": "7-17",
"3pt": "3-7",
"ft": "1-1",
"oreb": "0",
"dreb": "5",
"reb": "5",
"ast": "2",
"stl": "1",
"blk": "0",
"to": "2",
"pf": "3",
"plusminus": "-10",
"pts": "18"
}
...
]به اون چیزی که میخوایم خیلی نزدیک شدیم، ولی چندتا مشکل کوچیک داریم. بهنظر میرسه مقدار name اشتباهه و تمام اعداد، بهصورت String ذخیره شده. این مشکل رو از روشهای مختلفی میشه حل کرد و ما از سریعترین روشهای ممکن برای حلش استفاده میکنیم.
اول میریم سراغ درست کردن name. اگه به کد HTML نگاه کنید، متوجه میشید که ستون اول نسبت به سایر ستونها، کمی متفاوته:
<td class="name">
<a name="&lpos=nba:game:boxscore:playercard" href="https://www.espn.com/nba/player/_/id/6440/tobias-harris" data-player-uid="s:40~l:46~a:6440">
<span>T. Harris</span>
<span class="abbr">T. Harris</span>
</a>
<span class="position">SF</span>
</td>به شکل زیر، اولین تگ <span> توی تگ <a> مربوط به ستون name رو انتخاب میکنیم:
for (td of tds) {
const $td = $(td);
// map the td class attr to its value
const key = $td.attr('class');
let value;
if (key === 'name') {
value = $td.find('a span:first-child').text();
} else {
value = $td.text();
}
player[key] = value;
}و حالا نوبت درست کردن اعداده. از اونجایی که میدونیم تمام مقادیرمون String هستن، خیلی ساده میتونیم تمام اعداد رو به شکل زیر، تبدیل به عدد کنیم:
player[key] = isNaN(+value) ? value : +value;با تغییراتی که انجام دادیم، خروجیمون بدین شکل میشه:
[
{
"name": "T. Harris",
"min": 38,
"fg": "7-17",
"3pt": "3-7",
"ft": "1-1",
"oreb": 0,
"dreb": 5,
"reb": 5,
"ast": 2,
"stl": 1,
"blk": 0,
"to": 2,
"pf": 3,
"plusminus": -10,
"pts": 18
},
...
]حالا تمام کاری که مونده انجام بدیم، ذخیره کردن مقادیر توی دایرکتوریمونه:
// save the scraped results to disk
await fs.promises.writeFile(
'boxscore.json',
JSON.stringify(values, null, 2)
);و تمام! ما HTML رو که دادهها از قبل توش رندر شده بود رو دانلود کردیم و بعد با استفاده از Cheerio اونارو لود و Parse کردیم و در نهایت دیتا رو با فرمت JSON در فایل مربوط، ذخیره کردیم.
کد کامل اسکریپتی که نوشتیم:
const rp = require('request-promise-native');
const fs = require('fs');
const cheerio = require('cheerio');
async function downloadBoxScoreHtml() {
// where to download the HTML from
const uri = 'https://www.espn.com/nba/boxscore?gameId=401160888';
// the output filename
const filename = 'boxscore.html';
// check if we already have the file
const fileExists = fs.existsSync(filename);
if (fileExists) {
console.log(`Skipping download for ${uri} since ${filename} already exists.`);
return;
}
// download the HTML from the web server
console.log(`Downloading HTML from ${uri}...`);
const results = await rp({ uri: uri });
// save the HTML to disk
await fs.promises.writeFile(filename, results);
}
async function parseBoxScore() {
console.log('Parsing box score HTML...');
// the input filename
const htmlFilename = 'boxscore.html';
// read the HTML from disk
const html = await fs.promises.readFile(htmlFilename);
// parse the HTML with Cheerio
const $ = cheerio.load(html);
// Get our rows
const $trs = $('.gamepackage-away-wrap tbody tr:not(.highlight)');
const values = $trs.toArray().map(tr => {
// find all children <td>
const tds = $(tr).find('td').toArray();
// create a player object based on the <td> values
const player = {};
for (td of tds) {
const $td = $(td);
// map the td class attr to its value
const key = $td.attr('class');
let value;
if (key === 'name') {
value = $td.find('a span:first-child').text();
} else {
value = $td.text();
}
player[key] = isNaN(+value) ? value : +value;
}
return player;
});
return values;
}
async function main() {
console.log('Starting...');
await downloadBoxScoreHtml();
const boxScore = await parseBoxScore();
// save the scraped results to disk
await fs.promises.writeFile(
'boxscore.json',
JSON.stringify(boxScore, null, 2)
);
console.log('Done!');
}
main():اینم از آموزش اسکرپ کردن به روش Server-side Rendered HTML. روشهای ۱ و ۲ تموم شد و حالا فقط روش شماره ۳ مونده.
روش شماره ۳: JavaScript rendered HTML
در این قسمت قراره روش اسکرپ کردن HTML بعد از اجرا شدن JavaScript در صفحه رو توضیح بدم. در بسیاری از موارد میتونیم این کارو به شکلی که در روش ۱ انجام دادیم، انجام بدیم، اما معمولا گرفتن HTML و کار روش، ممکنه راحتتر باشه. اینجا دیگه کتابخونه Request که قبلا ازش استفاده کردیم، به کارمون نمیاد. چون، این کتابخونه فقط HTML رو دانلود میکنه و هیچ جاوااسکریپتی رو در صفحه اجرا نمیکنه. پس نیازه که از یه کتابخونه دیگهای استفاده کنیم و Puppeteer همون کتابخونه قدرتمندیه که قراره در این قسمت ازش استفاده کنیم.
برای این قسمت، قراره دیتای مربوط به پرتابهای Steph Curry از وبسایت Basketball Reference رو اسکرپ کنیم.
نوشتن اسکریپت Node.js برای اسکرپ کردن صفحه بعد از اجرا شدن جاوااسکریپت
هدفمون اسکرپ کردن دیتا از چارت مربوط پرتابهای بازی Steph Curry موجود در صفحه زیره:
https://www.basketball-reference.com/players/c/curryst01/shooting/2020
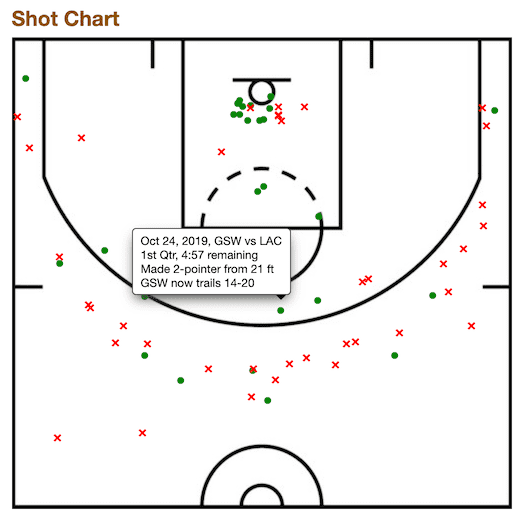
با راست کلیک روی یکی از نمادهای ● یا × روی عکس و زدن گزینه Inspect (مثل کاری که در روشهای ۱ و ۲ انجام دادیم)، میتونیم تگهای تو در تو <div> رو مشاهده کنیم:
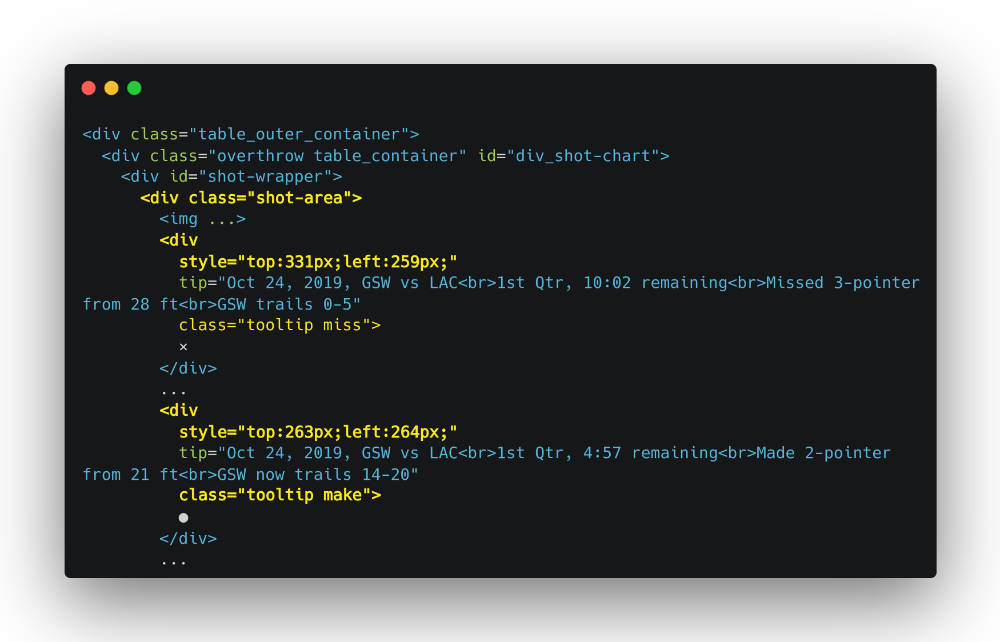
حالا با استفاده از Console مرورگر، یک Selector مینویسیم تا تگهای <div> که میخوایم رو برامون بگیره:
document.querySelectorAll('.shot-area > div')خروجی کد بالا:
> NodeList(66) [div.tooltip.miss, div.tooltip.miss, div.tooltip.miss, div.tooltip.make, div.tooltip.make, ...]حالا با استفاده از این Selector میریم تا اسکریپت Node.js رو بنویسیم.
راهاندازی Puppeteer
برای ساخت پروژه جاوااسکریپت جدید، به دایرکتوری مد نظرتون برید، یک فایل به اسم "index.js" بسازید و تو ترمینال این ۲ دستور زیر رو وارد کنید:
npm init -y
npm install --save cheerio puppeteerکار با لایبری Puppeteer، کمی از request پیچیدهتره، ولی سعی میکنم تا به سادهترین شکل ممکن کار باهاشو بهتون توضیح بدم. Puppeteer با اجرای یک مرورگر headless کروم کار میکنه، بنابراین بهصورت تئوری هر کاری که مرورگر شما بتونه انجام بده، اینم میتونه انجامش بده. برای شروع، نیاز داریم تا ابتدا puppeteer رو import کنیم و سپس مرورگر رو اجرا کنیم:
const fs = require('fs');
const puppeteer = require('puppeteer');
async function main() {
console.log('Starting...');
const browser = await puppeteer.launch();
// TODO download the HTML after running js on the page
await browser.close();
console.log('Done!');
}
main();در قدم بعدی، نیاز که یک صفحه جدید بسازیم تا HTML رو باش fetch کنیم. برای ساخت صفحه، دوست دارم که یه helper function (تابع کمکی) داشته باشم تا بتونم تمام گزینههایی که برای درخواستم میخوام رو، توش قرار بدم. تو اینجا من timeout رو ۲۰ ثانیه قرار دادم و از یک User Agent string جعلی هم استفاده کردم:
async function newPage(browser) {
// get a new page
page = await browser.newPage();
page.setDefaultTimeout(20000); // 20s
// spoof user agent
await page.setUserAgent('Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36');
// pretend to be desktop
await page.setViewport({
width: 1980,
height: 1080,
});
return page;
}پس از ست کردن صفحه، حالا باید کار fetch کردن و اجرای JS رو انجام بدیم که دوباره این کار رو با یک helper function دیگه انجام دادم:
async function fetchUrl(browser, url) {
const page = await newPage(browser);
await page.goto(url, {
timeout: 20000,
waitUntil: 'domcontentloaded'
});
const html = await page.content();
await page.close();
return html;
}دانلود صفحه HTML
با دو فانکشنی که نوشتیم، میتونیم کدی بنویسیم تا دیتای مربوط به پرتابها رو برامون دانلود کنه:
async function downloadShootingData(browser) {
const url = 'https://www.basketball-reference.com/players/c/curryst01/shooting/2020';
const htmlFilename = 'shots.html';
// download the HTML from the web server
console.log(`Downloading HTML from ${url}...`);
const html = await fetchUrl(browser, url);
// save the HTML to disk
await fs.promises.writeFile(htmlFilename, html);
}دوباره، از اونجای puppeteer ممکنه کمی کند باشه، توصیه میکنم که قبل از اجرای فانکشن fetchUrl، چک کنید که آیا فایل رو از قبل داریم یا نه:
async function downloadShootingData(browser) {
const url = 'https://www.basketball-reference.com/players/c/curryst01/shooting/2020';
const htmlFilename = 'shots.html';
// check if we already have the file
const fileExists = fs.existsSync(htmlFilename);
if (fileExists) {
console.log(`Skipping download for ${url} since ${htmlFilename} already exists.`);
return;
}
// download the HTML from the web server
console.log(`Downloading HTML from ${url}...`);
const html = await fetchUrl(browser, url);
// save the HTML to disk
await fs.promises.writeFile(htmlFilename, html);
}حالا فقط نیازه تا قبل از اینکه مرورگر رو اجرا کنیم، فانکشن رو صدا بزنیم.
async function main() {
console.log('Starting...');
// download the HTML after javascript has run
const browser = await puppeteer.launch();
await downloadShootingData(browser);
await browser.close();
console.log('Done!');
}سپس با دستور زیر در ترمینال، اسکریپت رو اجرا میکنیم:
node index.jsحالا اگه فایل shots.html رو چک کنید، تمام تگهای <div> که میخوایم رو توش میبینید که منتظرن تا اونارو Parse و سپس ذخیرشون کنیم.
تبدیل (Parse) کردن HTML با استفاده از Cheerio
فرآيند Parse کردن در این روش، به همون شکلی که در روش ۲ انجام دادیم، انجام میشه. یک فایل HTML داریم و میخوایم داده رو با استفاده از selector ازش استخراج کنیم. دوباره به تگ <div> مربوط به shot نگاه کنید. بهنظرتون چه دادههایی میتونیم ازش بدست بیاریم؟
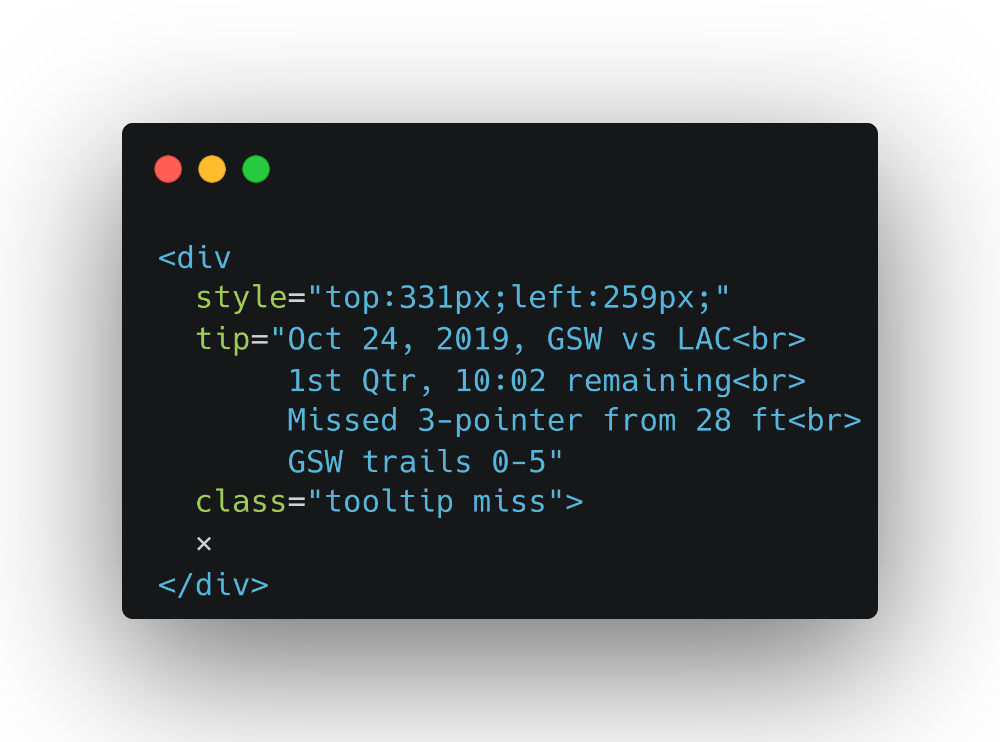
نظرتون چیه که موقیت x و y رو از اتریبیوت style، مقدار امتیاز پرتاب رو از اتریبیوت tip و اینکه پرتاب موفقیت آمیز بود یا خیر رو از اتریبیوت class بگیریم؟
پس بریم فایل HTML رو لود و سپس با استفاده از cheerio اونو Parse کنیم:
async function parseShots() {
console.log('Parsing shots HTML...');
// the input filename
const htmlFilename = 'shots.html';
// read the HTML from disk
const html = await fs.promises.readFile(htmlFilename);
// parse the HTML with Cheerio
const $ = cheerio.load(html);
// for each of the shot divs, convert to JSON
const divs = $('.shot-area > div').toArray();
// TODO: convert divs to shot JSON objects
return shots;
}الان تگهای <div> رو به عنوان آرایه در اختیار داریم. حالا با map کردن اونا به آبجکتهای JSON، مقادیر اتربیوبتهایی که در بالا بهشون اشاره کردیم رو برمیگردونیم:
const shots = divs.map(div => {
const $div = $(div);
// style="left:50px;top:120px" -> x = 50, y = 120
// slice -2 to drop "px", prefix with `+` to make a number
const x = +$div.css('left').slice(0, -2);
const y = +$div.css('top').slice(0, -2);
// class="tooltip make" or "tooltip miss"
const madeShot = $div.hasClass('make');
// tip="...Made 3-pointer..."
const shotPts = $div.attr('tip').includes('3-pointer') ? 3 : 2;
return { x, y, madeShot, shotPts };
});
کد بالا باید خروجی شبیه به زیر رو بهمون بده:
[
{
"x": 259,
"y": 331,
"madeShot": false,
"shotPts": 3
},
...
]حالا فقط باید فانکشن parseShots() رو به فانکشن main() وصل کنیم و نتیحه رو ذخیره کنیم:
async function main() {
console.log('Starting...');
// download the HTML after javascript has run
const browser = await puppeteer.launch();
await downloadShootingData(browser);
await browser.close();
// parse the HTML
const shots = await parseShots();
// save the scraped results to disk
await fs.promises.writeFile('shots.json', JSON.stringify(shots, null, 2));
console.log('Done!');
}و الان اگه فایل shots.json رو چک کنید، باید نتیجه کارمون رو مشاهده کنید.
کد کامل اسکریپتی که نوشتیم:
const fs = require('fs');
const cheerio = require('cheerio');
const puppeteer = require('puppeteer');
const TIMEOUT = 20000; // 20s timeout with puppeteer operations
const USER_AGENT =
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36';
async function newPage(browser) {
// get a new page
page = await browser.newPage();
page.setDefaultTimeout(TIMEOUT);
// spoof user agent
await page.setUserAgent(USER_AGENT);
// pretend to be desktop
await page.setViewport({
width: 1980,
height: 1080,
});
return page;
}
async function fetchUrl(browser, url) {
const page = await newPage(browser);
await page.goto(url, { timeout: TIMEOUT, waitUntil: 'domcontentloaded' });
const html = await page.content(); // sometimes this seems to hang, so now we create a new page each time
await page.close();
return html;
}
async function downloadShootingData(browser) {
const url =
'https://www.basketball-reference.com/players/c/curryst01/shooting/2020';
const htmlFilename = 'shots.html';
// check if we already have the file
const fileExists = fs.existsSync(htmlFilename);
if (fileExists) {
console.log(
`Skipping download for ${url} since ${htmlFilename} already exists.`
);
return;
}
// download the HTML from the web server
console.log(`Downloading HTML from ${url}...`);
const html = await fetchUrl(browser, url);
// save the HTML to disk
await fs.promises.writeFile(htmlFilename, html);
}
async function parseShots() {
console.log('Parsing box score HTML...');
// the input filename
const htmlFilename = 'shots.html';
// read the HTML from disk
const html = await fs.promises.readFile(htmlFilename);
// parse the HTML with Cheerio
const $ = cheerio.load(html);
// for each of the shot divs, convert to JSON
const divs = $('.shot-area > div').toArray();
const shots = divs.map(div => {
const $div = $(div);
// style="left:50px;top:120px" -> x = 50, y = 120
const x = +$div.css('left').slice(0, -2);
const y = +$div.css('top').slice(0, -2);
// class="tooltip make" or "tooltip miss"
const madeShot = $div.hasClass('make');
// tip="...Made 3-pointer..."
const shotPts = $div.attr('tip').includes('3-pointer') ? 3 : 2;
return {
x,
y,
madeShot,
shotPts,
};
});
return shots;
}
async function main() {
console.log('Starting...');
// download the HTML after javascript has run
const browser = await puppeteer.launch();
await downloadShootingData(browser);
await browser.close();
// parse the HTML
const shots = await parseShots();
// save the scraped results to disk
await fs.promises.writeFile('shots.json', JSON.stringify(shots, null, 2));
console.log('Done!');
}
main();اینم از روش شماره ۳ و آخرین روش! موفق شدیم تا یک صفحه رو پس اجرا شدن JavaScript روش دانلود، کدهای HTML اش رو Parse و دادهها رو ازش استخراج کنیم و در نهایت در یک فایل JSON ذخیره کنیم.
امیدوارم که این مقاله براتون مفید بوده باشه و تونسته باشم که به خوبی وب اسکرپینگ با جاوا اسکریپت رو توضیح داده باشم.
فقط حواستون باشه که با اسکرپ کردن میشه کارهای زیادی انجام داد و اگه قراره ازش استفاده کنید، در جای درست و به روش درست ازش استفاده کنید (از اسکرپ کردن خیلی راحت میشه سو استفاده ها کرد :) ) .
خلاصه اگه سوالی، پیشنهادی چیزی داشتید تو کامنت برام بنویسید. همچنین، من تمام کدهایی که نوشتیم + خروجی اونهارو تو ریپازیتوری گیتهابم هم قرار دادم که میتونید ازشون استفاده کنید.
- منبع
مطلبی دیگر از این انتشارات
3 خط فرمان مفید برای تست سرعت اینترنت
مطلبی دیگر از این انتشارات
نسخه 2 وبسایت زنیاک منتشر شد!
مطلبی دیگر از این انتشارات
ساخت modal های داینامیک در vue راحت تر از همیشه!