
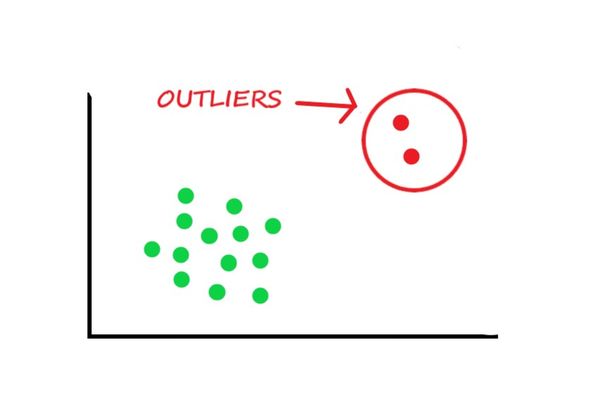
این تصویر رو ببینید:
همچنین کد زیر رو ببینید :
[23, 25, 26, 24, 27, 500]
وسط ۲۳ و ۲۷ بودیم که یک دفعه سر و کله ۵۰۰ پیدا شد !
یا تو تصویری که گذاشتم ببینید همه داده های سبز خیلی خوشگل کنار هم جمع شده بودن که ناگهان ۲ تا داده رفتن اون قسمت .
خب مگه مهمه ؟ بزاریم بمونه همونجا کاری باهاش نداریم که :)
چرا باید هندلش کنیم ؟
ببین اولا که Outlier میتونه خیییییلی خوب باشه چون میتونی باهاش تقلب ها رو کشف کنی , میتونی باهاش بیماری های خاص رو تشخیص بدی و ...
اما میتونه افتضاح هم باشه و مدلت رو داغون کنه .

همونطور که میبینید با خط سبزی که کشیده شده (که بعدا در موردش صحبت میکنیم) به راحتی میشه تشخیص داد اگر X ساعت درس خوانده شود Y مقدار نمره میگیریم اما Outlier زده کار رو داغون کرده چون یک دفعه با ۱ ساعت مطالعه طرف نزدیک ۱۰۰ نمره گرفته ! پس باید این رو بتونیم هندل کنیم که مدلمون دچار خطا نشه !
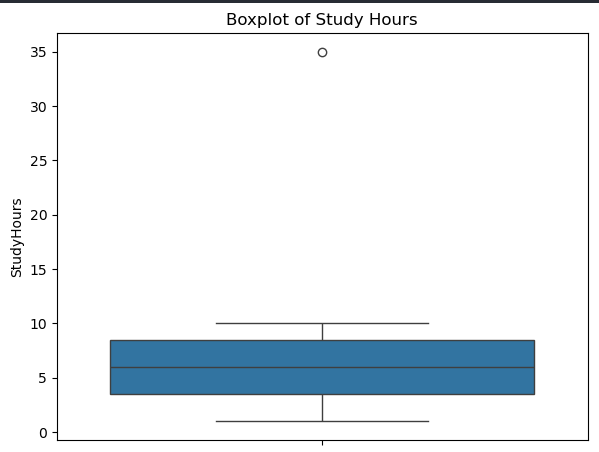
نقاطی که خارج از whiskers نمودار هستند، معمولاً Outlier محسوب میشن.
import seaborn as sns import matplotlib.pyplot as plt sns.boxplot(y='StudyHours', data=df) plt.title("Boxplot of Study Hours")
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd from sklearn.datasets import fetch_california_housing plt.figure(figsize=(14, 6)) sns.boxplot(data=df) plt.xticks(rotation=45) plt.grid(True) plt.tight_layout() plt.show()
هر دادهای که بیشتر از ۳ انحراف معیار از میانگین فاصله داشته باشه، معمولاً Outlier در نظر گرفته میشه.
from scipy import stats import numpy as np z_scores = np.abs(stats.zscore(df['Score'])) outliers = df[z_scores > 3]
نمره IQR یعنی اختلاف بین چارک ۳ و ۱
Q1 = df['Score'].quantile(0.25) Q3 = df['Score'].quantile(0.75) IQR = Q3 - Q1 outliers = df[(df['Score'] < Q1 - 1.5 * IQR) | (df['Score'] > Q3 + 1.5 * IQR)]
با استفاده از مدل سازی Isolation Forest میتونیم به عدد ۱ یا -۱ برسیم که
۱ : عادی
-۱ : داده پرت (Outlier) میباشد .
from sklearn.ensemble import IsolationForest iso = IsolationForest(contamination=0.1) df['outlier'] = iso.fit_predict(df[['Age', 'Score']]) # خروجی: 1 (عادی) یا -1 (پرت)
۱. حذف Outlierها (Outlier Removal)
اگر تعداد Outlier کم باشد و نبودشان تأثیر زیادی روی داده نگذارد، میتوان آنها را حذف کرد.
Q1 = df['StudyHours'].quantile(0.25) Q3 = df['StudyHours'].quantile(0.75) IQR = Q3 - Q1 lower_bound = Q1 - 1.5 * IQR upper_bound = Q3 + 1.5 * IQR df_no_outliers = df[(df['StudyHours'] >= lower_bound) & (df['StudyHours'] <= upper_bound)]
ساده و سریع
در صورت وجود outlierهای واقعی و اشتباهات اندازهگیری، مؤثر است
برای مدلهای حساس مثل Linear Regression مفید است
حذف داده میتواند باعث از دست رفتن اطلاعات مهم شود
در دیتاستهای کوچک باعث کاهش دقت مدل میشود
برای مدلهایی که نیاز به تعادل کلاس دارند ممکن است بد باشد
Linear Regression
KNN
SVM
۲. جایگزینی با مقدار میانه (Capping)
میتونی Outlierها رو با نزدیکترین مقدار قابلقبول جایگزین کنی (روش Winsorization).
df_capped = df.copy() df_capped.loc[df_capped['StudyHours'] > upper_bound, 'StudyHours'] = upper_bound df_capped.loc[df_capped['StudyHours'] < lower_bound, 'StudyHours'] = lower_bound
داده حذف نمیشود
نسبت به حذف مستقیم، اطلاعات بیشتری حفظ میشود
ممکن است داده را مصنوعی و غیرواقعی کند
در صورت زیاد بودن outlierها باعث اختلال در توزیع میشود
KNN
Tree-based models
Logistic Regression
بهجای حذف یا جایگزینی، میتونی از RobustScaler برای نرمالسازی استفاده کنی که نسبت به Outlier حساس نیست.
from sklearn.preprocessing import RobustScaler scaler = RobustScaler() df_scaled = df.copy() df_scaled[['StudyHours', 'Score']] = scaler.fit_transform(df[['StudyHours', 'Score']])
توزیع دادهها را نرمالتر میکند
بر عملکرد مدلهای خطی اثر مثبت دارد
نیاز به نرمال بودن داده دارد (برخی توابع فقط برای دادههای مثبت کار میکنند)
ممکن است تفسیر نتایج را سخت کند
Linear Models
SVM
Neural Networks
اگر نمیخوای دیتا حذف بشه ولی میخوای تأثیر outlierها کمتر شه، میتونی از log استفاده کنی
import numpy as np X_log = X.copy() X_log['Population'] = np.log1p(X_log['Population']) # log1p(x) = log(1 + x) X_log['AveOccup'] = np.log1p(X_log['AveOccup'])
برای وقت هایی که نمیخوای دیتا هات پاک بشن عالیه .
ممنون که همراهی میکنید , خوشحال میشم نظرتون رو بدونم .