

مهندس کلان داده | عضو هیئت مدیره شرکت داده پایای سپهر | عضو هیئت مدیره شرکت مدیریت دارایی راسا
بررسی عملی امنیت زیرساخت های کلان داده - بخش سوم
به روزرسانی: بخش چهارم این مستند منتشر شد. پس از مطالعه این بخش، به سراغ قسمت بعدی در این لینک بروید.
در بخش قبل به نصب و راه اندازی Kerberos و پیکربندی آن در هدوپ پرداخته شد. در این بخش به ادامه مباحث مربوطه خواهیم پرداخت.
توجه: اگر بخش قبل را مطالعه نکردید، به این لینک مراجعه کنید.
پیکربندی هدوپ با قابلیت دسترسپذیری یا High Availability
به منظور پیکربندی هدوپ با قابلیت دسترسپذیری، مراحل نصب هدوپ به صورت عادی می بایست انجام گیرد و تنها تفاوت این نوع نصب در این است که نیاز به اضافه کردن پیکربندی های بیشتری می باشد که در ادامه به آنها خواهیم پرداخت.
قبل از پرداختن به پیکربندی و تنظیمات موردنظر، می بایست با معماری این قابلیت آشنا شویم. در شکل 3 نمای کلی از معماری دسترسپذیری هدوپ را می توانید مشاهده کنید.
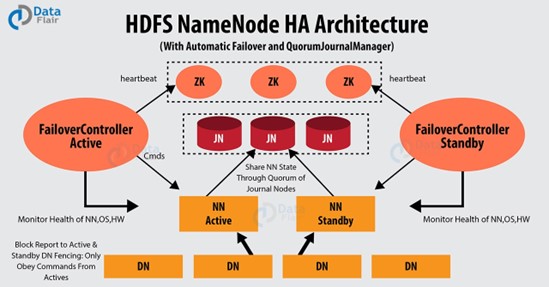
به منظور فراهم آوری قابلیت دسترسپذیری در زیرساخت هدوپ، ماشین های متعدد NameNode را راه اندازی می کنیم تا در زمان اشکال در یکی از این ماشین ها، دیگری بتواند پاسخگوی درخواست ها باشد. این قابلیت از طریق ایجاد معماری Active/Passive صورت می گیرد. به این صورت که اگر 2 ماشین NameNode داشته باشیم، یکی از آنها در حالت Active می ماند و دیگری در حالت Standby. در مواقع خطا و اشکال اگر ماشین Active از دسترس خارج شود، ماشین Standby به Active تغییر وضعیت داده و درخواست ها را مدیریت می کند. تعداد ماشین های NameNode می تواند از 2 بیشتر باشد اما به دلیل جلوگیری از افت کارایی ارتباط پیشنهاد می شود که از 5 عدد بیشتر نباشد. نکته قابل توجه در اینجا این است که این قابلیت مختص سرویس HDFS نیست و سرویس YARN نیز با ایجاد معماری Active/Passive برروی Resource Manager این کار را انجام می دهد. برای پیاده سازی این روش، نیاز به راه اندازی سرویس ها و پیکربندی خاصی است که در ادامه شرح خواهیم داد.
در این معماری موجودیت های زیر به ساختار اصلی هدوپ اضافه می شوند که در زیر آنها را معرفی خواهیم کرد:
1. سرویس ZooKeeper : این سرویس به منظور ایجاد قابلیت Automatic Failover راه اندازی می شود. پس از اینکه ماشین NameNode Active با مشکل و خطا روبرو شد، هدوپ به صورت خودکار قادر نخواهد بود که ماشین Standby را به Active تغیر وضعیت دهد و به نوعی مانع از انتقال احساس مشکل به کاربر شود. این فرآیند که Manual Failover نامیده می شود از مدیرسیستم می خواهد که خودش به صورت دستی فرآیند حل مشکل را انجام و ماشین Standby را به Active تغییر وضعیت دهد. با استفاده از سرویس ZooKeeper این فرآیند به صورت خودکار انجام خواهد شد. این سرویس که به صورت کلاستر راه اندازی می شود می تواند در برگیرنده چند ماشین باشد.
2. سرویس JournalNode : ماشین های NameNode حاوی ابرداده ها یا metadata می باشند که همزمانی آنها برروی این ماشین ها از اهمیت بالایی برخوردار است. وجود سرویس JournalNode باعث می شود که تغییرات رخ داده برروی داده ها برروی تمامی NameNode های دیگر هم اعمال شود و همواره به روز باشد. این سرویس نیز به صورت کلاستر راه اندازی می شود و می تواند از یک ماشین بیشتر باشد.
نکته: به جای سرویس JournalNode می توان از قابلیت NFS یا Network File System به منظور ذخیره سازی یکپارچه ابرداده ها استفاده نمود. اما پیشنهاد می شود که از JournalNode استفاده شود. به این دلیل که مشکلات احتمالی در Mount کردن این فایل سیستم باعث از دسترس خارج شدن کل کلاستر و عدم دسترسی به داده ها خواهد شد.
3. سرویس ZKFC : این سرویس که مخفف ZooKeeper Failover Controller می باشد وظیفه بررسی سلامت NameNode ها و برگزاری انتخابات بین آنها را بر عهده دارد. در واقع ماشین NameNode وضعیت خود را به ZooKeeper اعلام نمی کند، بلکه این سرویس در مدت زمان مشخص سلامت NameNode را بررسی نموده و وضعیت آنرا به سرویس ZooKeeper اعلام می کند. سرویس ZKFC از نگاهی دیگر یک سرویس گیرنده ZooKeeper است. این سرویس عموما برروی همه ماشین های NameNode راه اندازی می شود تا هرکدام از آنها وظایف خود را برروی ماشین میزبان انجام دهند.
در ادامه به نصب و پیکربندی این قابلیت در هدوپ خواهیم پرداخت.
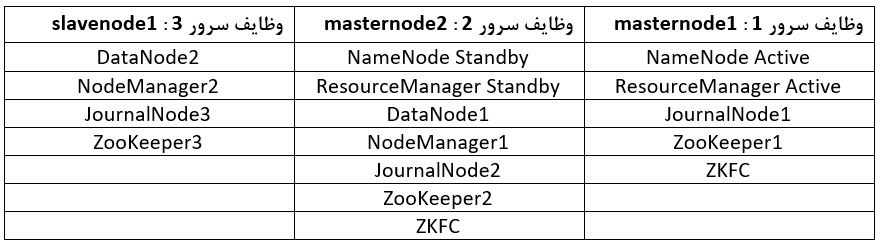
در این مثال کلاستر هدوپ ما دارای 3 ماشین می باشد که طبق جدول شماره 3 نقش های آنها را مشخص خواهیم کرد.
برای نصب و راه اندازی این قابلیت می بایست تمامی مراحل نصب اصلی هدوپ که پیش از این به آن پرداختیم، انجام شده باشد.
در ابتدا می بایست بسته باینری مربوط به نرم افزار ZooKeeper را از این لینک دانلود و در مسیر دلخواه(به طور مثال /usr/share) استخراج و مالک پوشه و دسترسی آنرا به کاربر zoo تغییر دهید(اگر این کاربر وجود ندارد آنرا ایجاد کنید). ما در این مثال، از نسخه 3.6.1 استفاده می کنیم. دقت نمایید که این عملیات را برروی تمامی ماشین هایی که نقش ZooKeeper را بازی می کنند، اجرا کنید.
پس از اینکار با مراجعه به پوشه conf فایل zoo_sample.cfg را با استفاده از دستور زیر تغییر نام دهید و سپس با یکی از ویرایشگرهای متنی جهت ویرایش باز کنید:
su zoomv zoo_sample.cfg zoo.cfgمقدار موجود در این فایل را به صورت زیر تغییر دهید:
dataDir=/usr/share/zookeeper/data
مقدار بالا مسیر دلخواه جهت ذخیره سازی فایل های داده ای ZooKeeper را مشخص می کند.
سپس مقادیر زیر را در انتهای فایل موردنظر قرار دهید و فایل را ذخیره کنید:
Server.1=masternode1:2888:3888
Server.2=masternode2:2888:3888
Server.3=slavenode1:2888:3888
در خطوط 1 تا 3 نام میزبان سرورهایی که می خواهید برروی آنها سرویس ZooKeeper را فعال کنید قرار می گرد. در اینجا می توانید سرورهای بیشتری نیز انتخاب کنید. پس از نام میزبان دو شماره پورت قرار می گیرد که پورت اول برای ارتباط بین ماشین های ZooKeeper با همدیگر و پورت بعدی برای انتخابات بین ماشین ها انتخاب می شود.
با مراجعه به پوشه bin در هر ماشین، دستور زیر را برای اجرای سرویس ZooKeeper اجرا کنید:
./zkServer.sh startپس از اجرای موفقیت آمیز دستور بالا، با اجرای دستور jps می بایست سرویس QuorumPeerMain را در خروجی مشاهده کنید.
در مرحله بعد فایل core-site.xml از پوشه etc/hadoop در هر ماشین را با یکی از ویرایشگرهای متنی جهت ویرایش باز کنید و مقادیر مربوط به فایل موردنظر در مخزن گیت هاب این مستند را قرار دهید.
مقدار موجود در خط شماره 2 در واقع آدرس NameNode پیش فرض است که در حالت دسترسپذیری می بایست برای ماشین های NameNode یک فضای نام دلخواه انتخاب کنیم تا هرکدام از NameNode ها که در وضعیت Active بود پاسخگوی درخواست ها باشد. در اینجا این نام را به دلخواه hdfscluster انتخاب می کنیم.
در مرحله بعد فایل hdfs-site.xml از پوشه etc/hadoop در هر ماشین را با یکی از ویرایشگرهای متنی جهت ویرایش باز کنید و مقادیر مربوط به فایل موردنظر در مخزن گیت هاب این مستند را قرار دهید.
در خط شماره 2 نام دلخواه مربوط به فضای نام را که در اینجا hdfscluster انتخاب کردیم قرار می دهیم. در خط شماره 6 برای این فضای نام، شناسه های یکتای دلخواه مربوط به هر ماشین NameNode را قرار می دهیم. در خطوط شماره 10 تا 22 نیز به ترتیب آدرس های میزبان و شماره پورت های RPC و http مربوط به هر NameNode را مقداردهی می کنیم. در خط شماره 26 آدرس های ماشین های JournalNode را تعیین می کنیم. در خط شماره 30 تعیین می کنیم که نام کلاس استاندارد جاوایی است که هر سرویس گیرنده از آن برای اتصال به ماشین NameNode با وضعیت Active استفاده می کند. اگر این مقدار وجود نداشته باشد اجرای دستورات مربوط به کار با HDFS با خطای عدم دسترسی به NameNode مواجه می شود. به این دلیل که هدوپ به صورت پیش فرض فکر می کند که یک ماشین NameNode وجود دارد و به دنبال آدرس آن در پیکربندی می گردد. در خط شماره 34 قابلیت Automatic Failover را فعال می کنیم. بلافاصله در خط شماره 38 آدرس ماشین های میزبان و شماره پورت مربوط به ZooKeeper جهت فعال سازی Automatic Failover را تعیین می کنیم. در خط شماره 42 روش مربوط به عملکرد Fencing را مقداردهی می کنیم. عملکرد Fencing روشی برای جلوگیری از اجرا ماندن NameNode ای است که دچار خطا شده است اما هنوز در حالت Active قرار دارد و به درخواست ها پاسخ می دهد. به این معنی که در کلاستر دارای دو NameNode با وضعیت Active خواهیم بود. همواره هدوپ اجازه اجرای یک گره NameNode با وضعیت Active را می دهد تا داده ها دچار خرابی نشوند. در هنگام خطا اگر NameNode همچنان به فعالیت خود ادامه دهد، به دلیل استفاده از ابرداده های قدیمی و نامعتبر، پایداری داده ها را با مشکل مواجه خواهد کرد. روش موردنظر ما برای این عملکرد sshfence خواهد بود که در شرایط ذکر شده، پردازه مربوط به NameNode را Kill می کند. در خط شماره 46 نیز مسیر قرارگیری کلیدهای ssh برای ارتباط با ماشین NameNode را تعیین می کنیم. در خطوط شماره 50 تا 58 نیز Principal ها و مسیر قرارگیری فایل کلیدهای مربوط به ماشین های JournalNode که با NameNode یکسان می باشد را مشخص می کنیم. مقادیری که با رنگ قرمز و سبز مشخص شده اند مقدار دلخواهی می باشند که در پیکربندی تعیین می شوند.
تا به حال پیکربندی مربوط به HDFS را بررسی و انجام داده ایم و حال می بایست پیکربندی مربوط به YARN را انجام دهیم.
برای این کار فایل yarn-site.xml از پوشه etc/hadoop در هر ماشین را با یکی از ویرایشگرهای متنی جهت ویرایش باز کنید و مقادیر مربوط به فایل موردنظر در مخزن گیت هاب این مستند را قرار دهید.
در خط شماره 2 قابلیت دسترسپذیری را برای ResourceManager سرویس YARN فعال می کنیم. در خط شماره 6 نیز مشابه سرویس HDFS یک فضای نام یا شناسه کلاستر دلخواه را تعیین و انتخاب می کنیم. در اینجا این شناسه را yarncluster قرار می دهیم. در خط شماره 10 شناسه های مربوط به ماشین هایی که می خواهیم سرویس ResourceManager را برروی آنها اجرا کنیم را وارد می کنیم. خطوط شماره 14 تا 26 نیز به ترتیب نام میزبان و شماره پورت های ماشین های ResourceManager را مقداردهی می کنیم. در خط شماره 30 هم نام میزبان و شماره پورت های مربوط به ماشین های سرویس دهنده ZooKeeper را تعیین می کنیم.
در مرحله نهایی می بایست سرویس های ذکرشده در بالا را راه اندازی کنیم. تا به حال سرویس ZooKeeper را بر روی ماشین های موردنظر راه اندازی کردیم. در مرحله بعد با مراجعه به مسیر sbin از پوشه هدوپ، سرویس JournalNode را در هر ماشین با استفاده از دستور زیر راه اندازی می کنیم:
./hadoop-daemon.sh start journalnodeبرروی ماشین NameNode اول، دستور زیر را در پوشه bin جهت format کردن فایل سیستم اجرا می کنیم:
./hdfs namenode -formatسپس سرویس NameNode اول را با استفاده دستور زیر در پوشه sbin راه اندازی می کنیم:
./hadoop-daemon.sh start namenodeبرروی ماشین های دیگر NameNode نیاز به format کردن نیست و کافی است دستور زیر را از پوشه bin جهت انتقال یک کپی از ابرداده ها برروی آن ماشین اجرا می کنیم:
./hdfs namenode -bootstrapStandbyدر مرحله بعد سرویس NameNode برروی ماشین های Standby را با استفاده از دستور زیر راه اندازی می کنیم:
./hadoop-daemon.sh start namenodeسپس برروی ماشین NameNode اول، دستور زیر را جهت اجرای ماشین های DataNode اجرا می کنیم:
sudo ./start-secure-dns.shدر مرحله بعد سرویس ZooKeeper را جهت اجرای سرویس ZKFC فرمت می کنیم. دستورات زیر را برروی ماشین های برنامه ریزی شده اجرا می کنیم:
./hdfs zkfc -formatZK./hadoop-daemon.sh start zkfcدر مرحله نهایی، با اجرای دستور زیر می توانیم نسبت به اطلاع از وضعیت NameNode ها و مدیریت قابلیت دسترسپذیری هدوپ اقدام کنیم:
./hdfs haadmin -getServiceState nn1./hdfs haadmin -getServiceState nn2
./yarn rmadmin -getServiceState rm1./yarn rmadmin -getServiceState rm2به منظور تغییر وضعیت ماشین ها از Active به Standby و برعکس به صورت دستی می توانید از دستورات زیر استفاده کنیم :
./hdfs haadmin -transitionToStandby nn1 --forcemanual./hdfs haadmin -transitionToActive nn2 --forcemanualمعرفی ابزار Apache Ranger
دو شرکت بزرگ حوزه کلان داده در دنیا یعنی Cloudera و Hortonworks در توزیع های نرم افزاری خود دو ابزار مهم و کاربردی به نام Apache Sentry و Apache Ranger را در حوزه امنیت زیرساخت کلان داده معرفی و پیاده سازی کردند. این دو ابزار از مهم ترین ابزارهای این حوزه می باشند. اما با ادغام این دو شرکت در سال 2019 و خرید شرکت Hortonworks توسط Cloudera باعث شد ابزار Apache Sentry به دلیل عدم اقبال مناسب در مقایسه با ابزار Apache Ranger طراحی شده توسط شرکت Hortonworks به روزرسانی نشده و ابزار Apache Ranger به دلیل فعال بودن و همینطور سهولت در استفاده و دارا بودن امکانات کامل تر، تبدیل به پروژه اصلی شرکت Cloudera شود و این ابزار را تحت لیسانس بنیاد آپاچی ارائه دهد. به گفته جامعه متخصصین کلان داده، ابزار Apache Ranger از بلوغ بیشتری نسبت به رقبای خود برخوردار می باشد.
ابزار Apache Ranger یک چارچوب یکپارچه امنیتی برای پلتفرم ها و ابزارهای مبتنی بر هدوپ می باشد که از طریق ایجاد سیاست های دسترسی(Access Policy) به پایش و مدیریت دسترسی های مربوط به زیرساخت کلان داده می پردازد.
این ابزار از اجزای زیر تشکیل می شود:
1. Ranger Admin Portal : یک پورتال تحت وب و کاربرپسند با قابلیت REST می باشد که با استفاده از آن می توان سیاست های کاربران و سرویس ها را تعریف، پایش و مدیریت کرد. در شکل 3 و 4 تصویر ورود به پورتال و صفحه اصلی این محیط را می توانید مشاهده کنید(برای ورود به پورتال تحت وب برای اولین بار می توانید از کلمه عبور admin و رمز عبور admin استفاده کنید).
2. Ranger UserSync : این ابزار برای همسان سازی کاربران موجود برروی سیستم عامل خانواده Unix و سیستم LDAP و Ranger Admin به کار می رود. همسان بودن کاربران موجود برروی Ranger Admin و سیستم عامل لینوکس از اهمیت بالایی برخوردار است که این ابزار به صورت خودکار این امکان را ایجاد می کند.
3. Ranger TagSync : این ابزار برای همسان سازی برچسب های مورد استفاده در سیاست های مبتنی بر برچسب در Ranger Admin به کار می رود. این ابزار از یک منبع مشخص که می تواند یک فایل و یا یک سرویس(به طور مثال Atlas و یا Kafka) باشد برچسب ها را به Ranger Admin وارد کند. استفاده از این ابزار اجباری نیست و می توان از نصب آن صرف نظر کرد.
4. Ranger KMS : این ابزار امکان مدیریت کلید در سیستم رمزنگاری داده های HDFS یا TDE را ایجاد می کند. استفاده از این ابزار اجباری نیست و می توان از نصب آن نیز صرف نظر کرد.
5. Ranger Plugins : نرم افزار Apache Ranger دارای پلاگین های آماده ای می باشد که برای متصل کردن سرویس هایی مثل HDFS، YARN، Hive و... استفاده می شود. در واقع برای ایجاد امنیت در ابزارهای زیرساخت کلان داده به این پلاگین ها نیاز است.
1.10 آشنایی با Ranger Admin
محیط تحت وب Apache Ranger که Ranger Admin نام دارد، راهبر اصلی مدیریت و ایجاد سیاست های امنیتی در زیرساخت کلان داده می باشد. این ابزار با استفاده از تعریف سرویس های موجود برروی زیرساخت و ایجاد سیاست های دسترسی برروی هر سرویس، امنیت اجزای اصلی زیرساخت کلان داده را مهیا می کند.
بخش های مختلف محیط کاربری این ابزار را در ادامه شرح خواهیم داد.
1.1.10 بخش Access Manager
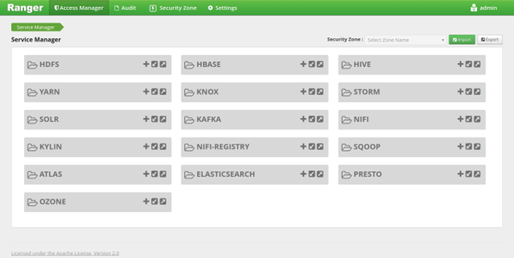
پیش از اینکه بتوان سیاست های دسترسی کاربران را تعریف نمود می بایست اتصال بین اجزای اصلی زیرساخت کلان داده برقرار گردد. این اتصال توسط پلاگین ها یا افزونه های ارائه شده توسط Apache Ranger و نصب و پیکربندی آن انجام می شود. این بخش که نام دیگر آن Service Manager می باشد، در نسخه های قبلی با نام Repository Manager شناخته می شده است. با نصب افزونه های مربوط به هر ابزار می توان در این بخش و کلیک برروی گزینه + می توان یک سرویس را ایجاد کرد. همچنین با استفاده از گزینه های فلش پایین و فلش بالا می توان سیاست های تعریف شده به تفکیک هر سرویس را Import و یا Export کرد. این گزینه ها در سمت راست بالای صفحه هم موجود می باشند که سیاست های تعریف شده در تمامی سرویس ها را Import و Export می کند. گزینه Security Zone در بخش خودش توضیح داده خواهد شد.
ابزارهای پشتیبانی شده توسط Ranger به شرح زیر می باشند:
HDFS
YARN
Hive
HBASE
Knox
Storm
Solr
Kafka
NiFi
Kylin
Sqoop
Atlas
ElasticSearch
Presto
Ozone
سوالی که ممکن است برای شما پیش آید این است که چرا ابزار مهم Spark در لیست وجود ندارد. آیا Ranger از این ابزار پشتیبانی نمی کند؟ پاسخ خیر است. اگرچه Ranger از این Spark به صورت رسمی پشتیبانی نمی کند اما با استفاده از پلاگین مربوط به Hive و نصب افزونه مربوطه در قسمت Hive می توان پشتیبانی از Spark SQL را در Ranger Admin برقرار نمود که در ادامه به آن خواهیم پرداخت. در شکل 5 می توانید تصویر مربوط به بخش Access Manager را که صفحه اصلی Ranger Admin است را مشاهده کنید.
این بخش دارای سه زیر منو می باشد که به شرح زیر است:
1. Resource Based Policies : این بخش سیاست های مبتنی بر منبع را می توان ایجاد و مدیریت نمود.
2. Tag Based Policies : در این بخش سیاست های مبتنی بر برچسب را می توان ایجاد و مدیریت کرد.
3. Reports : در این بخش می توان یک نگاه کلی به سیاست های تعریف شده داشت و آنها را مورد جستجو قرار داد.
2.1.10 تفاوت سیاست های مبتنی بر منبع و مبتنی بر برچسب
در Ranger دو نوع سیاست گزاری وجود دارد. سیاست مبتنی بر منبع و مبتنی بر برچسب. در سیاست نوع اول، ملاک تعریف سیاست و نوع دسترسی مبتنی بر منبع است. منبع در واقع موجودیت ها در سرویس ها می باشند. به طور مثال در HDFS منابع ما فایل ها و پوشه ها هستند. در Hive منابع ما پایگاه های داده، جدول ها و ستون ها هستند. اما در مقابل سیاست های مبتنی بر برچسب، نوع منبع در آن مهم نیست و دسترسی ها توسط برچسب هایی که برای منابع تعریف شده اند صورت می پذیرد. به طور مثال اگر در دو منبع HDFS و Hive داده های حساس مربوط به گزارشات مالی مشتریان، اطلاعات پزشکی و... موجود باشند، می توان برای آنها به طور مثال برچسب Confidential تعریف کرد تا دسترسی کاربران به منابعی که برچسب دارند به شکل دیگری مدیریت شود. اینکار باعث سهولت در تعریف سیاست های خاص می شود. به طوری که دیگر نیاز نیست به صورت پراکنده سیاست های دسترسی کاربران به منابع خاص را به صورت مجزا و تک به تک ایجاد کرد. در شکل شماره 6، فلوچارت مربوط به بررسی سیاست های مبتنی بر برچسب و تقدم عملکرد آنها را می توانید مشاهده کنید.
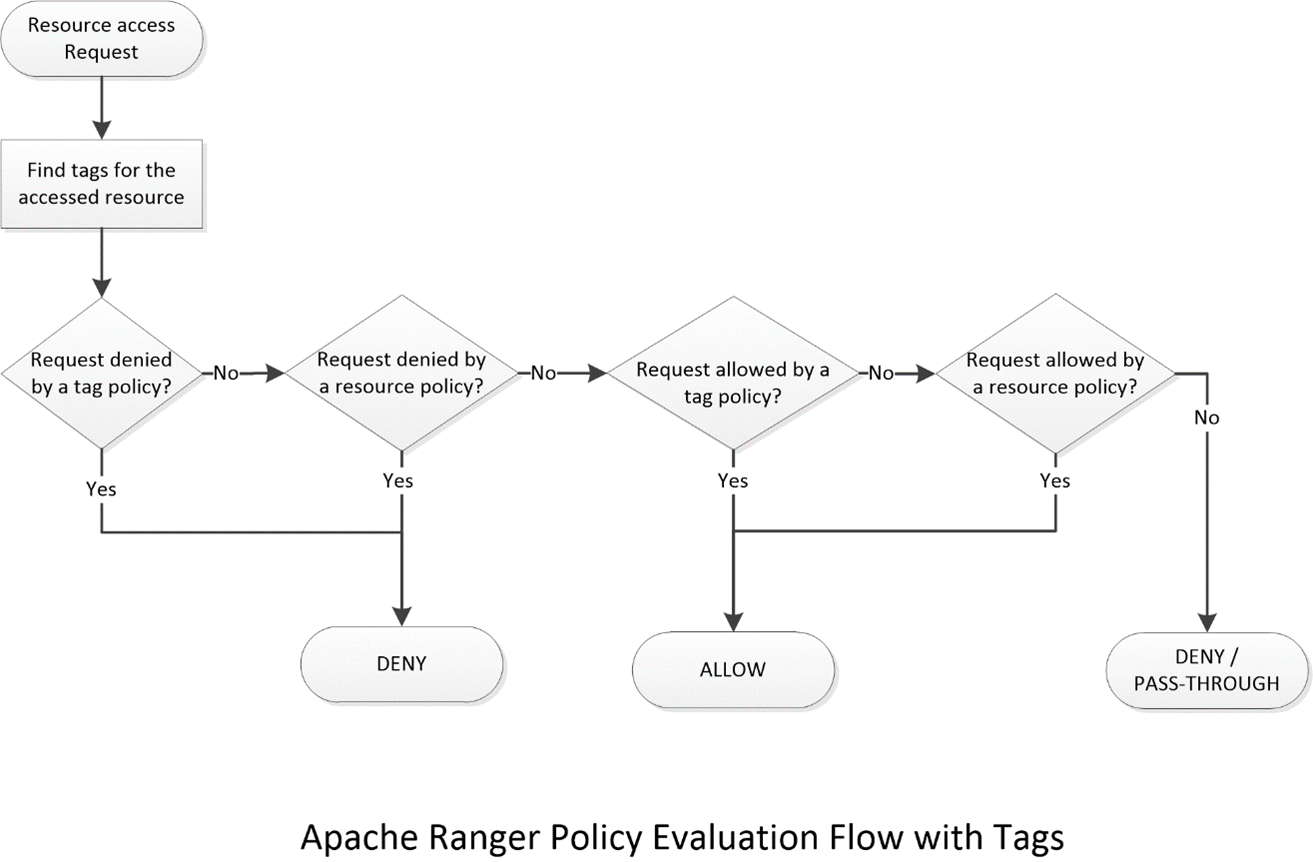
3.1.10 بخش Audit
در بخش Audit یا بازرسی به گزارشات سرویس پرداخته می شود. این گزارشات شامل گزارشات عملیات کاربری سرویس در سربرگ Access، گزارشات مربوط به مدیریت سیاست ها در سربرگ Admin، گزارشات مربوط به ورود کاربران به Ranger Admin در سربرگ Login Sessions، گزارشات مربوط به اتصال اجزای اصلی زیرساخت کلان داده از طریق افزونه ها در سربرگ Plugins، گزارشات مربوط به وضعیت افزونه ها در سربرگ Plugin Status و گزارشات مربوط به عملیات همسان سازی کاربران توسط Ranger UserSync در سربرگ User Sync می شوند. در این بخش می توان به جستجوی گزارشات نیز پرداخت. در شکل 7 تصویر مربوط به این بخش را می توانید مشاهده نمایید.
4.1.10 بخش Security Zone
در این بخش می توان به تفکیک سرویس ها و کاربران به Zone ها یا مناطق مختلف پرداخت. به معنی دیگر می توان سیاست های دسترسی را براساس Zone به صورت تفکیک شده مدیریت و ایجاد کرد. به طور مثال فرض کنید در یک سازمان، داده های اداره مالی و اداره فروش برروی زیرساخت کلان داده ذخیره سازی، مدیریت و پردازش می شود. داده های اداره مالی برروی سرویس HDFS در مسیر /finance قرارگرفته اند. همچنین برروی سرویس Hive نیز پایگاه داده ای به همین نام در اختیار این اداره می باشد. بر روی سرویس Kafka نیز Topic های ساخته شده با پیشوند FIN_ متعلق به آنها است. از طرف دیگر اداره فروش نیز داده های مخصوص به خودش با نام های دیگر را برروی زیرساخت دارد. پس در این بخش، دو Zone به نام های finance و sales تعریف می کنیم. اگر کاربر ali بخواهد به پایگاه داده متعلق به محدوده finance دسترسی یابد، سیاست های خاص تعریف شده برای این Zone خاص ترتیب اثر داده می شود. اینکار باعث مدیریت بهتر سیاست های تعریف شده، گزارشات بازرسی و همچنین تفکیک کاربران و نقش های آنها می شود. در بخش های Access Manager و Audit و انتخاب Zone موردنظر می توانیم به سیاست ها و گزارشات بازرسی خاص این Zone دسترسی یابیم. همچنین می توان کاربری با نقش Auditor یا بازرس برروی Ranger Admin ساخت که بازرسی گزارشات مخصوص به یک Zone خاص را بر عهده داشته باشد. در شکل 8 تصویر مربوط به این بخش را می توانید مشاهده کنید.

5.1.10 بخش Settings
در این بخش میتوان تنظیمات کاربری مربوط به Ranger Admin را مدیریت نمود. با ورود به این بخش سربرگ های Users، Groups و Roles را مشاهده خواهیم کرد. در سربرگ اول لیست کاربران مربوط به Ranger Admin و همینطور کاربرانی که میخواهیم برای آنها سیاست های امنیتی تعریف کنیم قرار می گیرد. همچنین در این سربرگ امکاناتی از قبیل ویرایش و حذف کاربر وجود دارد. در سربرگ دوم می توان گروه های کاربری را ایجاد و مدیریت نمود. در سربرگ سوم هم می توان نقش های کاربری را تعریف و مدیریت کرد. تصویر صفحه اصلی این بخش را می توانید در شکل 9 مشاهده نمایید.
ادامه دارد ...
به روزرسانی: بخش چهارم این مستند منتشر شد. پس از مطالعه این بخش، به سراغ قسمت بعدی در این لینک بروید.
با من در بخش های دیگر این مستند همراه باشید و در صورت وجود ابهام و سوال و ارتباط با من می توانید با ایمیل من mobinranjbar1 روی جیمیل و یا لینکدین من مکاتبه کنید.
مطلبی دیگر از این انتشارات
بررسی عملی امنیت زیرساخت های کلان داده - مقدمه و بخش اول
مطلبی دیگر از این انتشارات
بررسی عملی امنیت زیرساخت های کلان داده - بخش پنجم
مطلبی دیگر از این انتشارات
بررسی عملی امنیت زیرساخت های کلان داده - بخش چهارم