

ویکینویس - وبلاگنویس - علاقهمند به برنامهنویسی - افغانستان - هزاره
چگونه با کمک پایتون، تصویر ابر کلمات توییتری ساختم! (مبتدی)
سلام دوستان عزیز، خسته نباشید.

مدتی قبل من در توییتی تصویر ابر کلمات خودم را قراردادم. برخی دوستان درخواست دادند تا برایشان ابر کلمات بسازم و برخی دیگر درخواست چطوری خودشان میتوانند تصویر ابر کلمات را بسازند. به همین دلیل تصمیم گرفتم مطلبی بنویسم که چگونه با کمک پایتون تصویر ابر کلمات را میسازم.
شوربختانه من برنامهنویس نیستم و سواد اینکه بهصورت یک برنامهنویس حرفهای توضیح بدهم را نیز ندارم. لحن این پُست به این صورت است که من برای ساخت تصویر ابر کلمات حساب توییتریام چهکارهایی انجام دادم تا بقیه دوستان نیز از همین روش بتوانند ابر کلماتشان را بسازند.
نکته بسیار مهم: کدهایی که استفاده کردم را هم میشود بهتر و بهینهتر نوشت. هدف من فقط یک سری کد بود که کار کند.
# بخش ۱
در ابتدا نیاز است که پایتون را در کامپیوتر نصب داشته باشیم. برای دانلود پایتون به لینک زیر رفته و با توجه به نسخه سیستمعاملی که استفاده میکنید، پایتون موردنظرتان را نصب کنید.
https://www.python.org/downloads
# بخش ۲
یک پوشه ایجاد کردم، در این پوشه، ۵ فایل پایتون و ۳ پوشه دیگه به صورت زیر ایجاد کردم.
+ data/ # اطلاعاتی که از توییتر دانلود میکنم و متنهای ویرایش شده در اینجا قرار میگیرد.
+ file/ # در این پوشه یک فونت و یک فایل ماسک توییتر به فرمت پیانجی.
+ final/ # تصاویر نهایی در ای پوشه ذخیره میشوند.
+ 01_download_twitter.py # در این فایل اطلاعات را از توییتر دانلود میکنم.
+ 02_remove_line.py # در این فایل خطهای اضافی را حذف میکنم.
+ 03_remove_emoji.py # در این فایل اموجیها را حذف میکنم.
+ 04_remove_kalamat.py # در اینجا کلمات اضافه را حذف میکنم.
+ 05_sakhte_kalamat.py # در اینجا تصاویر نهایی را میسازم.نکته ۱: در پوشه file فونت (ایران سنس) به نام sans وجود دارد. شما میتوانید از هر فونتی استفاده کنید؛ فقط باید اسم فونت را در بخش آخر به شکل درست به برنامه بدهید.
نکته ۲: یک تصویر با نام mask که به صورت png ذخیره شده نیز قرار دارد. (لینک تصویر)

برنامه پایتون را باز کنید و از منوی file بر روی new کلیک کنید تا یک پنجره جدید باز شود.
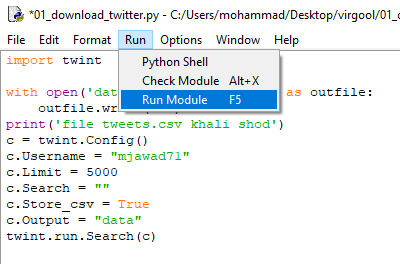
در پنجره خالی جدید که باز شده کد زیر را قرار دهید:
#tozihate 1 ro bebinid.
import twint
#tozihate 2 ro bebinid.
with open('data/tweets.csv', 'w+') as outfile:
outfile.write(" ")
print('file tweets.csv khali shod')
#tozihate 3 ro bebinid.
c = twint.Config()
c.Username = "mjawad71"
c.Limit = 4500
c.Search = ""
c.Store_csv = True
c.Output = "data"
twint.run.Search(c)- توضیحات ۱: در ابتدا کتابخانه twint را import کردم. این کتابخانه کمک میکند تا بتونم توییتهای حساب توییتری را ذخیره کنم.
نکته مهم: کتابخانهها، یکسری کد، از قبل نوشته شده هستند. این کتابخانهها را معمولا باید خودمون دستی نصب کنیم. برای نصب کتابخانههای پایتون از دستور روبرو استفاده میکنیم: [نام کتابخانه] pip install
«برای نصب کتابخانهها در ویندوز میتوانید از cmd استفاده کنید - اگر دکمههای Win + R را کلیک کنید و در پنجره بازشده cmd بنویسید، محیط cmd باز میشود».
*** فهرست زیر اسامی تمام کتابخانههای مورد نیاز ما برای ساخت ابر کلمات هستند. هر خط را کپی کرده، اینتر بزنید تا کتابخانه نصب شود.
(در صورت نصب نشدن هرکدام از کتابخانهها ممکن است در مراحل بعدی به مشکل بربخورید).
pip install twint
pip install regex
pip install emoji
pip install arabic-reshaper
pip install matplotlib
pip install numpy
pip install python-bidi
pip install Pillow
pip install wordcloud
- توضیحات ۲: کتابخانه twint توییتهای حساب توییتری را در فایل tweets.csv در پوشه data ذخیره میکند. اگر بخواهید، چندین بار بوسیله این کتابخانه توییتها را ذخیره کنید، توییتهای جدید به توییتهای قبلی اضافه میشود. مثلا شما اگر توییتهای حساب توییتری من را ذخیره کنید سپس بخواهید توییتهای حساب کاربری خودتان را ذخیره کنید، توییتهای حساب شما به توییتهای قبلی من که در فایل وجود داشته اضافه میشود.
در آخر ابر کلماتی میخواهید بسازید ترکیبی از توییتهای من و توییتهای شما هستند. پس بهتر است قبل از اجرای کد اصلی، فایل tweets.csv را خالی کنیم. این کد را به همین دلیل قرار دادم.
- توضیحات ۳: این بخش از کد وظیفه اصلی ذخیره توییتها را بر عهده دارد. با توجه به نام کاربری که جلو متغیر c.Username قرار دادید، برنامه توییتهای این حساب را دانلود میکند. به جای mjawad71 میتوانید نام حساب کاربری توییتر مورد نظرتان را وارد کنید. «نام کاربری حتماً داخل " " باشد».
نکته ۱: به دلیل محدودیتهایی که وجود دارد، ممکن است همه توییتها + منشهای یک حساب ذخیره نشود.
نکته ۲: اگر نام حساب توییتری تغییر کرده باشد، ممکن است توییتهای قبلی این حساب پیدا نشود. (من بررسی نکردم که آیا میشود توییتهای نام کاربری سابق را یافت یا نه، شما میتوانید خودتان امتحان کنید).
برنامه را در پوشهای که ایجاد کردید، ذخیره کنید. از منوی run گزینه run module را انتخاب کنید تا کد شما اجرا شود تا توییتهای شما در فایل tweets.csv در پوشه data ذخیره شوند. «این بخش ممکن است مدتی طول بکشد»
وقتی کار جستجو توییتها به پایان رسید. فایل tweets.csv را با نوت پد باز کنید، متنی مثلاً شبیه زیر را مشاهده میکنید.
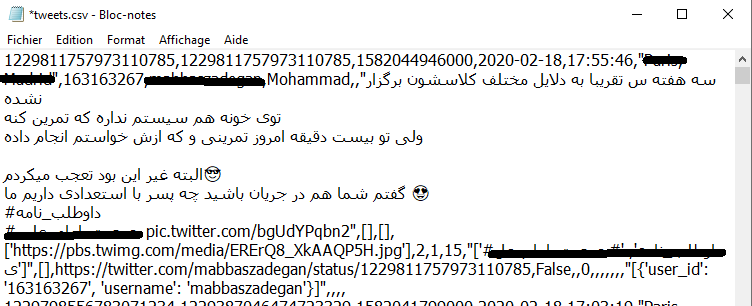
اگر بخواهید از همین متن ابر کلماتتان را بسازید با یک سری کلمات و حروف بیمعنی و الکی روبرو میشوید (مانند تصویر بنر همین پست). به جز این مورد، زبان فارسی هم در برنامه مشکل دارد و باید اصلاح شود.
# بخش ۳
در ادامه نیاز داریم که خطهای اضافه را پاک کنم، یعنی:
# متن زیر رو:
من
محمد
هستم.
# را به متن زیر تبدیل کنم:
من محمد هستم.
دلیلش را جلوتر توضیح دادم.
برای اینکار یک فایل جدید پایتون باز کنید و کد زیر را در آن قرار بدید:
# coding=UTF-8
#tozihate 1 (bala)
#tozihate 2
with open('data/tweets.csv', 'r') as infile,\
open('data/twline.txt', 'w') as outfile:
#tozihat 3
data = infile.read()
#tozihat 4
data = data.replace("\n", " ").replace( '"', " ").replace("'", " ").replace(" ", " ").replace("ي","ی").replace("ك","ک")
#tozihat 5
outfile.write("")
#tozihat 6
outfile.write(data)- توضیحات ۱: به دلیل مشکلی که ممکن است با زبان فارسی پیش بیاد coding=UTF-8 را در اول کد قرار دادم.
- توضیحات ۲: این کد فایل tweets.csv را به عنوان infile وارد، و فایل twline.txt را به عنوان outfile برای خروجی ایجاد کردم.
- توضیحات ۳: متن فایل tweets.csv را در متغیر data قرار دادم.
- توضیحات ۴: این کد، تمامی خطوط را از متن data «یعنی فایل tweets.csv» حذف میکند. همچنین تمامی ( ' )، ( " ) و ۴ فاصله را نیز با یک فاصله جایگزین (replace) میکند. در آخر، ي و ك (حروف عربی) را با ی و ک (حروف فارسی) جایگزین کردم.
نکته: ي و ك از حروف الفبای عربی هستند و کلمات كتك و کتک، ديدي و دیدی برای برنامه متفاوت هستند. برای ساخت ابر کلمات نیاز هست تا تمامی کلمهها با حروف الفبای فارسی نوشته شوند.
- توضیحات ۵: کد outfile.write("") فایل twline.txt را خالی میکند، که اگر از قبل متنی در آن قرار داشت، آنها حذف شوند.
- توضیحات ۶: این کد outfile.write(data) متن اصلاح شده نهایی را در twline.txt ذخیره میکند. در نتیجه فایلی که در تصویر زیر میبینید، ایجاد میشود.
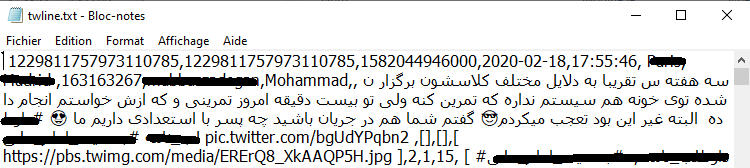
# بخش ۴
کتابخانه arabic-reshaper که از آن برای اصلاح کلمات فارسی استفاده کردم با اموجیها مشکل داشت و خطا میداد. به همین دلیل مجبور شدم از کتابخانه emoji استفاده کنم تا تمامی اموجیها از متن حذف شوند. یک فایل جدید پایتون ایجاد کنید و کد زیر را در آن وارد کنید و آن را اجرا کنید.
import re
import emoji
# tedad emojihaye peyda shode ro chap mikone
def strip_emoji(text):
print(emoji.emoji_count(text))
new_text = re.sub(emoji.get_emoji_regexp(), r"", text)
return new_text
# file ghabli ro baz/emojiha ro hazf karde va file jadid bedoone emoji mide.
with open("data/twline.txt", "r") as filee:
old_text = None
old_text = filee.read()
no_emoji_text = None
no_emoji_text = strip_emoji(old_text)
with open("data/twemoji3.txt", "w") as new_file:
new_file.write('')
new_file.write(no_emoji_text)- توضیحات کلی: کد بالا، تمامی اموجیها را از فایل twline.txt حذف، و متن بدون اموجی را در فایل twemoji3.txt ذخیره میکند.
# بخش ۵
متن twemoji3.txt هنوز نیاز به ویرایش دارد، ما باید کلمات اضافی که معنای خاصی ندارند را از متن حذف کنیم. مانند کلمات (که، به، را، از، افعال و ...)
توضیحات مهم: اگر کلمات اضافی را حذف نکنید، کلمات بیاستفاده مانند (را، که، در، هر، افعال، صفتها، تشکرها) در تصویر نهایی، بزرگتر نشان داده میشوند که به درد نمیخورند. ما نیاز داریم، کلمات مهمتر مانند (عدالت، ایران، افغانستان، امید و ...) بزرگتر نشان داده شوند.
برای اینکار، کد زیر را در یک فایل جدید پایتون، قرار بدید و آن را اجرا کنید.
# coding=UTF-8
#tozihate 1
listt = {"a": " "," ما ":" "}
#tozihate 2
with open('data/twemoji3.txt', 'r') as f, \
open('data/twemoji2.txt', 'w') as o:
s = f.read()
for key in listt:
s = s.replace(key, listt[key])
o.write(s)
with open('data/twemoji2.txt', 'r') as f, \
open('data/twemoji1.txt', 'w') as o:
s = f.read()
for key in listt:
s = s.replace(key, listt[key])
o.write(s)
with open('data/twemoji1.txt', 'r') as f, \
open('data/tweets.txt', 'w') as o:
s = f.read()
for key in listt:
s = s.replace(key, listt[key])
o.write(s)- توضیحات ۱: برای اینکه بتوانم کلمات اضافی را پیدا و حذف کنم از قابلیت دیکشنری پایتون استفاده کردم.
در " " اولی کلمهای که میخواهم حذف کنم را قرار دادم و در " " دومی مقداری که میخواهم جایگزین کنم.
listt = {"kalamei ke mikhaham hazf konam":"kalame Jaygozin"}- نکته ۱: در کد بالا به کلمه (ما) در دیکشنری توجه کنید؛ من این کلمه را در دیکشنری به صورت " ما " قرار دادم و به صورت "ما" ننوشتم. یعنی قبل و بعد (ما) یک فاصله (اسپس) قرار دادم. برای درک آن به مثال زیر توجه کنید.
اگر در توییتی نوشته بود: «آنها و ما مادرانمان را دوست داریم» و بخواهیم کلمه (ما) را حذف کنیم، نتیجه اینگونه میشود:
+ بدون فاصله ("ما") > «آنها و ما مادرانمان را دوست داریم»: در این صورت برنامه دو بار کلمه ما را پیدا میکند، اولی مال ضمیر ما و دومی از کلمه مادرانمان. که با حذف کلمه ما میشود: آنها و درانمان را دوست داریم. متوجه شدید که کلمه مادر تبدیل شده به درانمان.
+ با فاصله (" ما ") > «آنها و ما مادرانمان را دوست داریم»: در این صورت فقط یک ما که ضمیر است پیدا میشود، چون پس از کلمه مادرانمان فاصله وجود ندارد، که در نتیجه آن میشود: آنها و مادرانمان را دوست داریم.
پس حتماًُ قبل و بعد کلمات فارسی که میخواهید حذف شوند، در دیکشنری، فاصله قرار دهید.
- نکته ۲: گاهی برخی کلمات در ابتدای خط هستند و قبلشان فاصله نیست. به همین دلیل اگر کلمه (آنها) را اگر در دیکشنری به صورت (" آنها ") جستجو کرده باشیم پیدا نمیشود. به همین دلیل در # بخش ۳ خواستم که خطوط حذف شوند و به جای آن فاصله (اسپیس) جایگزین شود.
- نکته ۳: اگر دقت کرده باشید، در دیکشنری بجای کلمات یافت شده، یک فاصله (اسپس) را خواستم جایگزین شود. چون اگر اینکار را نکنم، با حذف کلمهای، کلمات بعد و قبل اون به یکدیگر میچسبند.
در مثال بالا اگر کلمه " ما " (با فاصله) را حذف کنیم متن به اینصورت تبدیل میشود : آنها ومادرانمان را دوست داریم. میبینید که کلمه مادرانمان تبدیل شده به ومادرانمان. به همین دلیل به جای کلمات حذف شده، یک فاصله را جایگزین کردم.
* استثنا: در نکته ۳ گفتم به جای کلمه حذف شده یک فاصله (اسپیس) را قرار بدهیم اما استثنایی وجود دارد. همانطور که خبرید ما در حروف الفبای فارسی حروف فتحه، کسره، تنوین و ... را داریم. اگر ما بجای این حروف فاصله قرار بدیم کلماتمان خراب میشوند. مثلاً اگر کسی نوشته بود مُحمد به م حمد که کلمه اشتباهی است تغییر پیدا میکند. البته به نظرم نیاز بود که مصوتهای کوتاه و تنوینها حذف شوند. چون ممکن بود بین محمد و مُحمد فرق گذاشته شود و دو حرف متفاوت حساب شوند.
- نکته شخصی: من اعداد فارسی و انگلیسی و حروف انگلیسی را این بخش حذف میکنم، چون نیازی نداشتم از آنها برای ایجاد ابر کلمات استفاده کنم.
- نکته دیگه: من چندین بار کد حذف کلمات اضافی را اجرا کردم، تا اگر کلمهای جا مانده باشد حذف شود. در پایان متن نهایی برای ساخت تصویر ابر کلماتمان در فایل tweets.txt ذخیره میشود.
# بخش ۶ - نهایی
فایل جدید پایتونی ایجاد کنید و کد زیر را در آن قرار دهید و سپس آن را اجرا کنید.
# coding=UTF-8
#tozihat 0
import os
from os import path
import arabic_reshaper
import matplotlib.pyplot as plt
import numpy as np
from bidi.algorithm import get_display
from PIL import Image
from wordcloud import STOPWORDS, WordCloud
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
#tozihat 1
text = open(path.join(d, 'data/tweets.txt')).read()
#tozihat 2
alice_mask = np.array(Image.open(path.join(d, "file/mask.png")))
#tozihat 3
stopwords = STOPWORDS
#tozihat 4
def make_farsi(x):
reshaped_text = arabic_reshaper.reshape(text)
farsi_text = get_display(reshaped_text)
return farsi_text
#tozihat 5
wc = WordCloud(background_color="white", font_path="file/sans.ttf", contour_width=3, contour_color='firebrick', max_words=2000, mask=alice_mask, stopwords=stopwords, max_font_size=250, random_state=10).generate(make_farsi(0))
#tozihat 6
wc.to_file(path.join(d, "final/mjawad71.png"))
#tozihat 7
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()توضیحات ۰: در اینجا تمام کتابخانههایی که نیاز داریم را وارد کردیم. (امیدوارم همینطور که در # بخش ۲ گفتم، کتابخانههای پایتون در سیستمتان نصب شده باشند).
- توضیحات ۱: در اینجا فایل نهایی (tweets.txt) را برای ساخت ابر کلمات وارد کردیم.
- توضیحات ۲: در این بخش از کد آدرس تصویر ماسک را به برنامه دادیم.
- توضیحات ۳: این بخش از کد همان کار # بخش ۵ برای حذف کلمات را انجام میدهد، اما نمیدانم چرا کلمات فارسی را حذف نمیکرد. به همین دلیل مجبور شدم دستی کلمات اضافی را حذف کنم.
- توضیحات ۴: این بخش، متن فایل نهاییمان برای ایجاد تصویر ابر کلمات به زبان فارسی را اصلاح میکند.
- توضیحات ۵: در این بخش، ابر کلماتمان با توجه به متن اصلاح شده (در توضیحات ۴) ساخته میشود. مطمئناً بهتر از من متوجه میشوید که چه امکاناتی وجود داره و چگونه آن را برای ایجاد تصویر ابر کلماتتان تغییر دهید.
- توضیحات ۶: این بخش، تصویر نهاییمان ساخته میشود «به جای mjawad71 میتوانید اسم مورد نظر خودتان را قرار بدهید».
- توضیحات ۷: این بخش از کد هم تصویر نهایی را در پنجره جدید نشان میدهد.
و در آخر، سورس کد فایلها به همراه تصویر ماسک را در گیتهاب قرار دادم. میتوانید از لینک زیر آن را دانلود کنید.
https://github.com/Mrahmani71/Abar_Kalamat
موفق و پیروز باشید.
مطلبی دیگر از این انتشارات
الگویِ طراحی Facade (جاوا و کاتلین)
مطلبی دیگر از این انتشارات
چگونه از تعطیلات عید بهترین استفاده را ببریم؟
مطلبی دیگر از این انتشارات
راه اندازی Powerline در ترمینال ویندوز