

http://imuhammad.ir علاقه مند به Data Science و Machine Learning
چطور به صورت خودکار یک دیتاست تصویری برای آموزش مدل های یادگیری عمیق بسازیم؟
اگر بخواهیم از یادگیری عمیق برای حل از صفر یک مسئله خاص مثل مسائل بینایی ماشین استفاده کنیم معمولاً نیاز به حجم زیادی از دادهها داریم (علاوه بر توان پردازشی و GPU خیلی خوب). با این وجود، تقریباً در حال حاضر کسی در حوزه بینایی ماشین یک معماری را از صفر بر روی دادههایی که دارد آموزش نمیدهد و اغلب از مدلهای از پیش آموزش داده شده (pre-trained models) برای این کار استفاده میشود.
در این حالت ما از دانشی که با استفاده از آموزش دادن یک مدل بر روی یک دیتاست بزرگ به دست آمده است برای حل مساله جدید خودمان استفاده میکنیم. به طور مثال، فرض کنید میخواهیم یک مدل بسازیم که بتواند تصاویر قرمه سبزی و قیمه سیب زمینی را به درستی دسته بندی کند. منتها در این جا تعداد تصاویر قیمه و قرمه ای که داریم زیاد نیست و احتمالاً به خوبی نمیتوانیم یک مدل را از صفر بر روی دادهها آموزش دهیم. در این حالت میتوانیم از (وزنها) یک مدل از پیش آموزش داده شده مثل مدل ResNet بر روی دیتاست ImageNet که دارای تصاویر زیادی است تا کمی از مشکلات کم بودن دادههای ما استفاده شود. دلیل این است که این مدل از پیش آموزش داده شده دارای یک سری اطلاعات کلی و عمومی در خصوص تصاویر مثل لبههای عمودی و افقی است که معمولاً لازم نیست مدل را برای یادگیری این اطلاعات دوباره آموزش دهیم.
با تمام این گفتهها کماکان جمع کردن و آماده سازی دادههای مناسب و برچسب گذاری شده برای مسئله دسته بندی قیمه و قرمه کار چالش برانگیز و زمان بری است. مثلاً در نظر بگیرید که چه قدر زمان باید صرف کنید تا 1000 تصویر مختلف از قیمه سیب زمینی را به صورت دستی از اینترنت دانلود و برچسب گذاری کنید. خوشبختانه راه حل ساده تری هم وجود دارد و آن استفاده از یک کتابخانه پایتون به اسم google-images-download برای دانلود تصاویر به صورت خودکار از سرویس تصویر گوگل است. با نوشتن یک کد ساده میتوانیم تصاویری که دوست داریم را دانلود کنیم و به صورت خودکار در یک دایرکتوری که شکل رایجی برای ذخیره سازی دادههای مورد نیاز برای آموزش الگوریتمهای یادگیری عمیق است ذخیره کنیم. (لازم هست که بگم این کتابخانه توسط یکی از دانش آموزهای کورس یادگیری عمیق سایت fast.ai نوشته شده است)
نصب این کتابخانه خیلی ساده است و هیچ پیش نیازی برای نصب آن وجود ندارد مگر این که بخواهیم در هر بار اجرا بیش از 100 تصویر دانلود کنیم که در این حالت باید سلنیوم را نصب کنیم که در پستهای این مسئله را آموزش میدهم. برای نصب کتابخانه هم کافی است که با استفاده از دستور pip به صورت زیر این کتابخانه را نصب کنیم:
pip install google_images_downloadحالا که کتابخانه را نصب کردیم میتوانیم به دو صورت از این کتابخانه استفاده کنیم:
طریقه اول: نوشتن یک برنامه در محیط پایتون:
روش اول استفاده از این کتابخانه این است که یک محیط پایتون باز کنیم و این کتابخانه را به برنامه اضافه کنیم و با استفاده از آرگومانهای ورودی بگوییم که میخواهیم چه تصاویری و با چه ویژگیهایی به دانلود شوند و سپس برنامه را اجرا کنیم. بگذارید با یک مثال این روش را توضیح دهم. فرض کنید که میخواهیم فقط 20 تصویر با کلمههای کلیدی «قیمه سیب زمینی» و «قرمه سبزی» را دانلود و در یک دایرکتوری خاص ذخیره کنیم. برای این کار اول کتابخانه را با دستور به برنامه اضافه میکنیم و پس از این که یک نمونه از کلاس دانلودکننده تصاویر به نام response ساختیم، آرگومانهای ورودی برای دانلود تصاویر مدنظرمان را از طریق یک دیکشنری مشخص میکنیم. در نهایت هم با استفاده از متد download شی ساخته شده تصاویر را دانلود میکنیم.
به طور مثال، در اینجا میخواهیم به وسیله آرگومان keywords به پایتون بگوییم که فقط 20 تصویر (با آرگومان limit) از تصاویر مربوط به کلمه کلیدی قیمه را دانلود کن و با آرگومان output_directory آنها را در یک فولدر به آدرس d://pics ذخیره کن. سپس همین کار را برای کلمه کلیدی قرمه سبزی هم انجام میدهیم.
from google_images_download import google_images_download #importing the library
response = google_images_download.googleimagesdownload() #class instantiation
arguments = {"keywords":"قیمه سیب زمینی", "limit":20,
"print_urls":True, "output_directory":"d://pics"}
response.download(arguments)
arguments = {"keywords":"قرمه سبزی", "limit":20,
"print_urls":True, "output_directory":"d://pics"}
response.download(arguments)حالا فرض کنید که میخواهیم تنها تصاویر مربوط پیتزا که در سایت سفارش غذای چنگال وجود دارد را در گوگل جستجو و دانلود کنیم. برای این کار از آرگومان ورودی specific_site استفاده میکنیم و آن را به همراه متناظرش یعنی changal.com دیگر به دیکشنری آرگومانها اضافه میکنیم.
arguments = {"keywords":"پیتزا", "specific_site" : "http://changal.com/",
"limit":20, "print_urls":True, "output_directory":"d://pics",}
response.download(arguments)حالا میتوانیم به دایرکتوری که مشخص کردیم برویم و تصاویر دانلود شده را ببینیم.
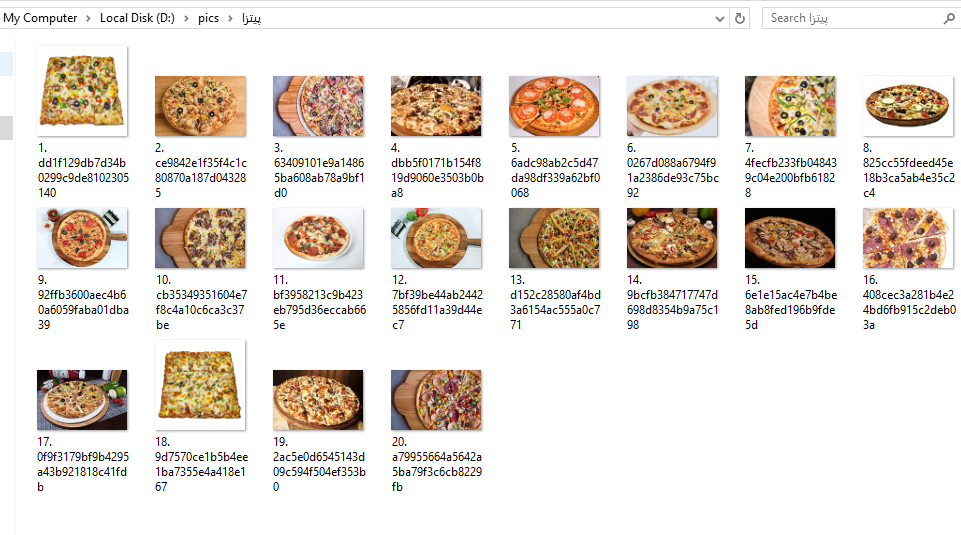
تعداد و تنوع آرگومانهای ورودی که میتوانیم برای شخصی سازی دانلود تصاویر از گوگل استفاده کنیم زیاد است و برای همین من همه آنها را اینجا بررسی نمیکنم. توصیه میکنم برای اطلاع پیدا کردن از بقیه آرگومانهایی که میتوانید استفاده کنید به آدرس سایت اصلی کتابخانه مراجعه کنید.
طریقه دوم: استفاده از طریق خط فرمان (Command Line):
بلافاصله بعد از نصب کتابخانه میتوانیم در محیطی که با آن کار میکنیم یک ترمینال باز کنیم و از دستور googleimagesdownload به همراه آرگومانهای ورودی مدنظرمان برای دانلود تصاویر مانند مثال زیر استفاده کنیم.مزیت این روش این است که لازم نیست که یک محیط پایتون باز کنیم و چندین خط کد بنویسیم و به صورت جدا برنامه را اجرا کنیم و همه این کارها را می توانیم با یک خط انجام دهیم.
googleimagesdownload --keywords Mourinho --limit 10در دستور بالا ما با آرگومان limit-- می گوییم که تنها 10 تصویر جستجو شده از مورینیو (Mourinho) را با آرگومان keywords-- را از گوگل دانلود کن. این تصاویر در فولدری به نام کلمه کلید جستجو شده درون یک فولدر ایجاد شده دیگر به نام downloads ذخیره می شوند. برای اطلاع از بقیه آرگومانهای که این دستور می گیرد مثل راه حل اول میتوانیم به سایت اصلی این کتابخانه مراجعه کنیم.
در پستهای بعدی توضیح میدهم که چطور میتوانیم بیش از 100 تصویر را دانلود کنیم.
با تشکر :)
مطلبی دیگر از این انتشارات
انتخاب ویژگیها براساس همبستگی و p-value
مطلبی دیگر از این انتشارات
احراز هویت غیر حضوری در بورس با استفاده از هوش مصنوعی
مطلبی دیگر از این انتشارات
هوش مصنوعی و روباتیک از یکدیگر متفاوت هستند