

تنها اکانت رسمی دیوار، پلتفرم خرید و فروش بیواسطه آنلاین، در ویرگول. اینجا بچههای دیوار درباره محیط کاری، دغدغهها، چالشهای حرفهای و زندگی در دیوار حرف میزنند.
از زیرساخت آزمایشها تا هوش مصنوعی: سفر چهار ساله تیم بهرهوری مهندسی دیوار
تو دنیای پرسرعت فناوری، بهبود مداوم فرآیندها و ابزارهای توسعه نرمافزار یه ضرورته که نمیشه انکارش کرد. تیم بهرهوری مهندسی دیوار حدود چهار سال پیش، برای بهبود این مسئله با یک ایده شکل گرفت: بهرهورتر کردن فرآیند توسعه و کم کردن بار ذهنی توسعه دهندهها. این هدف ما رو به سمت ساخت یه سری ابزار و فرآیند برد که الان دیگه جزء جداییناپذیر زیرساخت فنی دیوار شدن.
تو این پست میخوایم از موفقیتها، شکستها و درسهایی که تو این چهار سال گرفتیم بگیم. از توسعهی سیستمهای پیچیده مثل زیرساخت آزمایش و سندباکسمون گرفته تا تمرکز روی هوش مصنوعی در فرآیند توسعه. اگه میخواید بدونید پشت پرده یه تیم بهرهوری مهندسی چه خبره، با ما همراه باشید!

کلود سندباکسینگ
دیوار با گذر زمان، بزرگ و پیچیده شده و کلی میکروسرویس داره. این یعنی تست کردن حتی یه سرویس کوچک، نیاز به کلی وابستگی (dependency) داره. به خاطر همین توسعهدهندهها عموما نمیتونن راحت یک سرویس رو روی ماشین شخصی خودشون (local) بالا بیارن و تست کنن.
برای حل این مشکل، سرویس کلود سندباکسینگ رو توسعه دادیم تا مهندسا بتونن سریع و راحت یه محیط تست بسازن. قبل از اون نیاز بود تا بتونیم ترافیک دیوار رو به سادگی و خودکار مدیریت کنیم، پس سرویس «کنترلپلین» رو ساختیم که سرویس مرکزی مدیریت ترافیک دیوار به کمک فریم ورک آرپیسی خودمون یعنی divar-rpc بود و به کلود سندباکسینگ api میداد.
دیوارآرپیسی فریمورک داخلی rpc دیواره که یک رپر دور gRPC حساب میشه و چیزهایی مثل متریک انداختن، تریسینگ، روتینگ رو در دیوار استاندارد کرده.
ساختار کلود سندباکسینگ اینطوریه که ما یه سری «پروفایل» داریم از پروژهها و سرویسهای مختلف (که در واقع Helm chartهایی هستن با کانفیگهای لازم). توسعهدهنده با انتخاب یکی از این پروفایلها، یه دیپلویمنت جدید توی محیط ایزوله میسازه و به کنترلپلین میگه ترافیک کلاینتِ تو رو، به این سندباکس بفرسته. کلاینتها با هدرهای خاصی که میفرستند از هم متمایز میشن. «جعبه ابزار دیوار» که توی همه کلاینتهامون پیاده شده، استفاده از این هدرها رو خیلی ساده میکنه.
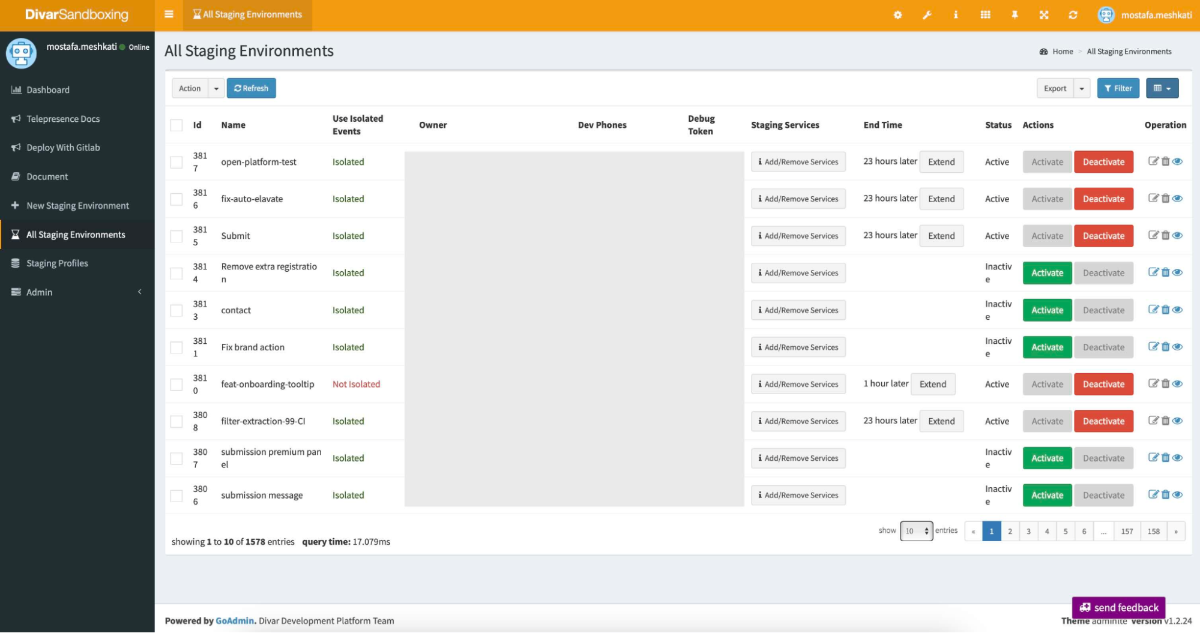
در حال حاضر روزانه بیش از 80 تا سندباکس با این سیستم ساخته میشه که نشون میده چقدر مورد استقبال قرار گرفته. این زیرساخت به بچههای QA هم کمک زیادی کرده که تغییرات رو قبل از انتشار راحتتر و کاملتر بررسی کنن. این پروژه یکی از تأثیرگذارترین کارهایی بوده که انجام دادیم. زمان توسعه رو کاهش داده و به مهندسها اعتماد به نفس بیشتری داده تا ایدههای جدید رو امتحان کنن. البته بدیهایی هم داشته، مثل این که آدمها عادت میکنن کمتر برای کدهای خودشون تست بنویسن. صحبتهای دقیقتر از این جنس رو ایشالا میذاریم تو بلاگ پستهای بعدی.
زیرساخت آزمایش (experiment) و فیچر فلگ
The only way to win is to learn faster than anyone else.
حالا چطوری سریعتر از بقیه یاد بگیریم؟ با آزمایش کردن!
بعد از کلود سندباکسینگ، نوبت به یکی از مهمترین زیرساختهای ما رسید: سیستم آزمایشهای دیوار. این سیستم در کنار فیچر فلگها، قلب تپنده نوآوری در دیواره. با این زیرساخت تو دیوار ما میتونیم سریعتر و با ریسک کمتر، آزمایشهای بیشتری کنیم تا خلق ارزش بیشتری رو برای کاربر رقم بزنیم.
اول لازمه یه توضیح کوچیک بدیم درباره فیچر فلگها. تو divar-rpc هر جزئی از کانفیگهای ما، در واقع یک فیچر فلگه.
فیچر فلگ در حالت ساده یک متغیر با یک تایپ و یک مقداره. این مقدار میتونه بسته به شرایط مختلف، مثل نوع کلاینت یا نسخهی کاربر تغییر کنه. برای مثال مقدارش در صورتی که از کلاینت وب بود، با کلاینت اندروید متفاوت باشه.
حالا اکسپریمنت چطور با این فلگها کار میکنه؟ اگه کاربر توی یه آزمایش خاص قرار گرفته باشه، سیستم اکسپریمنت میاد و مقادیر فلگهای مرتبط با اون آزمایش رو تغییر میده. این شکلی ما حالتهای مختلفی از بخشهای متفاوت دیوار میتونیم به کاربر نشون بدیم و تصمیمهامون رو سبک سنگین کنیم. (چه محصولی و چه فنی!)
اما چرا خودمون همچین سیستمی ساختیم و نرفتیم سراغ راهحلهای آماده مثل پروژههای اوپن سورس A/B تست یا پلتفرمهایی مثل Unleash؟ دلیلش اینه که این پلتفرمها خیلی ابتدایی هستن و یه محدودیت بزرگ دارن: از آزمایشهای عمود بر هم رو پشتیبانی نمیکنن. (حداقل تو زمانی که ما داشتیم این زیرساخت توسعه میدادیم).
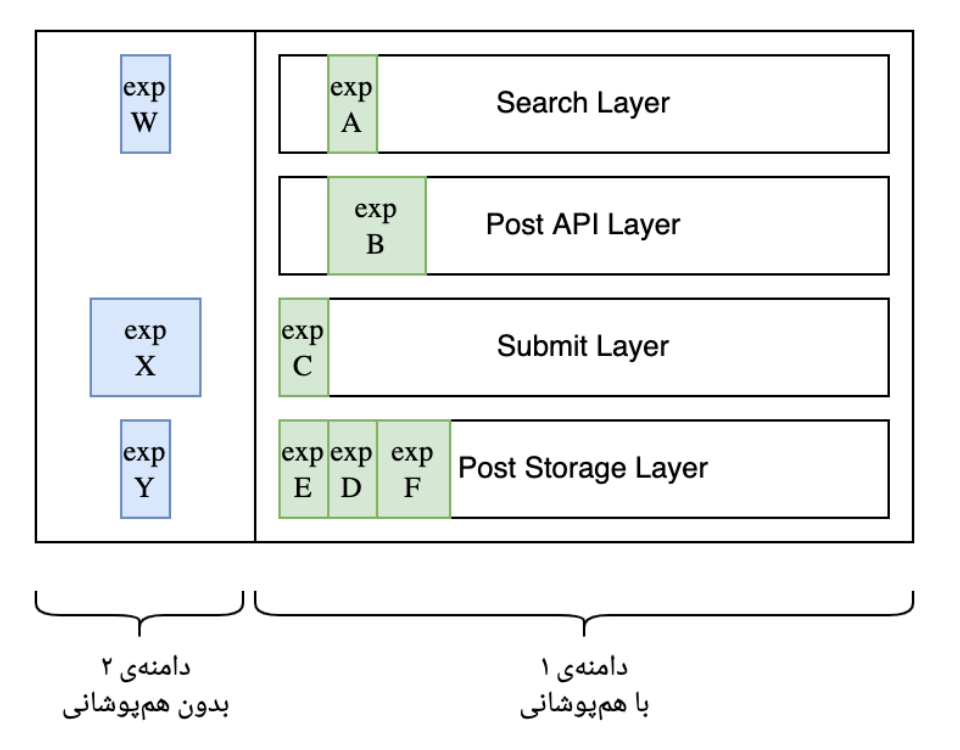
منظور از آزمایشهای عمود بر هم چیه؟ فرض کنید دو تا آزمایش داریم: یکی رنگ پسزمینه رو قرمز میکنه، یکی دیگه رنگ متن رو. اگه یه کاربر همزمان توی هر دو آزمایش بیفته، ممکنه نتیجه اصلاً قابل خوندن نباشه! حالا همین رو بیایم بسط بدیم رو کلی از متغیرهای محصولیمون. مثلا اگه پاشیم بیایم توی سرچ دیوار یک جور دیگهای آگهی به کاربرها پیشنهاد بدیم، باعث میشه زنگ خور اون آگهی بیشتر بشه یا نه و آیا چنین آزمایشی، رو آزمایش دیگهای که قراره مدل نردبان کردن آگهی تو دیوار رو تغییر بده تاثیر میذاره؟ مشخصا اگه تاثیر بذاره این دوتا آزمایش باید مستقل از هم انجام بشن.
برای حل این مشکل، ما از یه مقاله گوگل الهام گرفتیم: "Overlapping Experiment Infrastructure: More, Better, Faster Experimentation". این مقاله یه مدل لایهای رو معرفی میکنه که آزمایشهای عمود بر هم رو ممکن میکنه.
مزیت دیگه این روش اینه که میتونیم تعداد خیلی زیادی آزمایش همزمان داشته باشیم. اگه هر آزمایش ۵٪ ترافیک رو میگرفت، نهایتاً میتونستیم ۲۰ تا آزمایش داشته باشیم. ولی با این روش لایهای، تعداد آزمایشها عملاً نامحدوده، به شرطی که لایهها رو درست طراحی کنیم. برای پیادهسازی این سیستم، یه سری کد توی Divar RPC زدیم، یه سری کد دیگه توی گیتویهامون، و یه پنل ساختیم که بچهها بتونن راحت آزمایش تعریف کنن. جالبه بدونید آزمایشهای ما زیر ۱ دقیقه توی کل سیستم اعمال میشن و حتی توی کلاینتها هم کار میکنن.
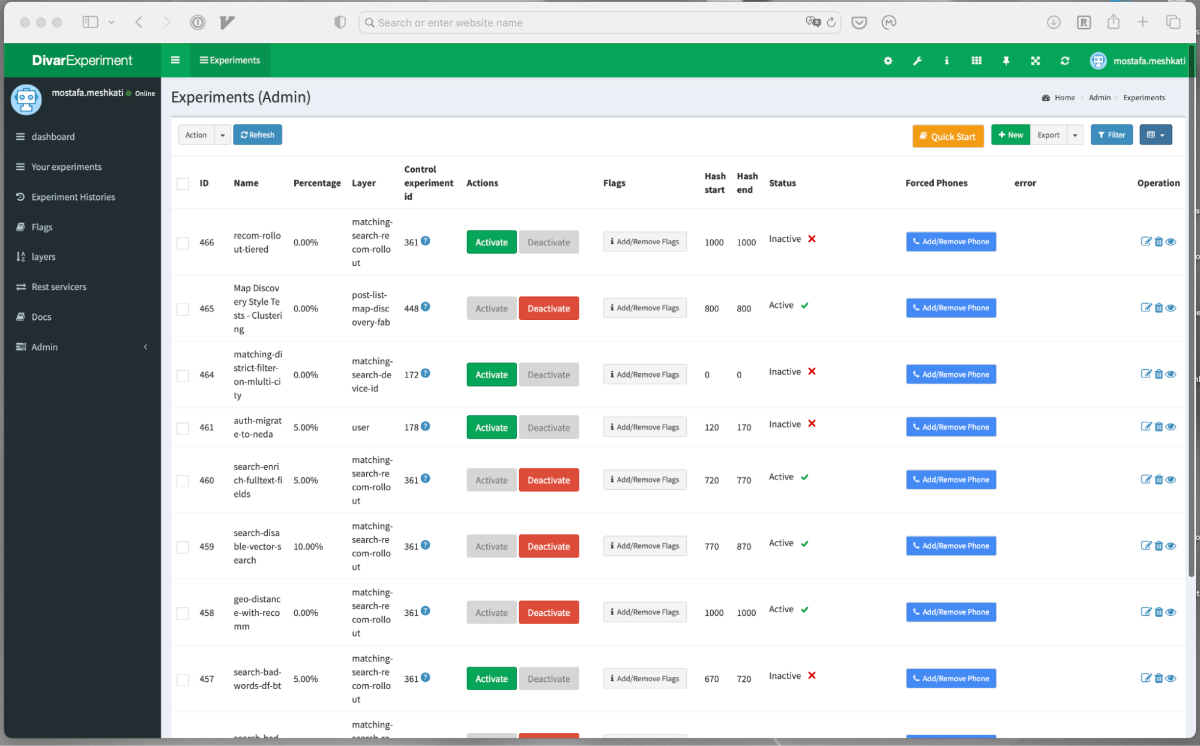
توی یک سال گذشته در دیوار، ما بیش از ۴۰۰ آزمایش به واسطهی همین زیرساخت انجام دادیم که بیشترشون روی جنبههای محصولی تمرکز داشتن. جالبه بگم همین الان که دارم این بلاگ رو مینویسم، ۷۵ آزمایش توی دیوار روشنن!
به گفتهی بچههاییمون که از این زیرساخت استفاده میکنن، یه سری از کارهایی که توی یک سال اخیر روی سرچ دیوار انجام دادیم، بدون این زیرساخت ممکن بود ۴-۵ سال طول بکشه و احتمالا خیلیهاشون هیچوقت محقق نمیشدن. از اون طرف فلگها هم توی تیمهای کلاینتیمون به شدت دارن استفاده میشن و تقریبا هر فیچری، پشت یک فیچر فلگیه.
دشواریهایی هم با زیرساخت فعلیمون داریم، مثلا بحثهای تحلیلیش جزئیات زیادی دارن، مثلا وقتی ما روی یک گروه آماری، آزمایشی انجام میدیم، احتمال خوبی وجود داره که اون گروه نسبت به آزمایشهای بعدیمون سوگیری پیدا کرده باشن. فرضا اگه من فروردین یک آزمایش خاص ببینم و اردیبهشت یک آزمایش دیگه، خیلی امکان داره که رفتار تاثیرپذیرفتهای در آزمایشی که خردادماه روم انجام میشه داشته باشم و پیدا کردن چنین مسائلی دردسرهایین که هنوز نتونستیم حلشون کنیم.
دستیار، دوستی با هوش مصنوعی مولد
این روزا همه جا پر شده از خبرهای هوش مصنوعی. از chatGPT گرفته تا کلی ابزار دیگه که هر روز دارن معرفی میشن. اواخر ۱۴۰۲ بود که نشستیم فکر کردیم خب حالا با این همه هیاهو و ابزارهای جدید چیکار کنیم؟ چطوری میتونیم از این فناوری تو کارهای روزمرهمون استفاده کنیم؟ مشخص هم نبود کدوماشون واقعا اثر مثبت دارن تو کار روزمره و کدوما نه.
اینجا بود که تصمیم گرفتیم دو تا کار انجام بدیم تا هم بچهها با Generative AI آشنا بشن هم یاد بگیرن چطوری ازش تو کارهاشون استفاده کنن و یه جورایی اون مرز و موضعگیری بین بچهها و AI رو از بین ببریم:
- یه تجربه شبیه ChatGPT روی مدلهای مختلف هوش مصنوعی به بچههای شرکت بدیم
- به توسعهدهندهها اجازه بدیم APIهای هوش مصنوعی رو استفاده کنند و ایدههای جدید رو امتحان کنن
نتیجه؟ فراتر از انتظارمون بود. دستیار شد یه ابزار محبوب برای حل مسائل روزمره. توسعهدهندهها شروع کردن به استفاده از AI تو کارها و پروژههاشون و کارهای خیلی باحالی انجام دادن. مثلا بچههای فروشمون سعی کردن یک بار با چت کردن با دستیار و استفاده از مدلهایی که توانایی بیناییِ ماشین دارن، ببینن میتونن بنرهای تبلیغاتی دیوار رو تایید یا رد بکنن؟ و دیدن آره با دقیق کردن promptها این کار شدنیه. بعد به کمک نیروهای فنی براش یک سرویس نوشتن که همهی بنرهای تبلیغاتیمون رو مورد بررسی قرار میده!
از دستیار جالبتر، دسترسی راحت بچههای دیوار به APIهای مدلهای مختلف بود. خیلی زود آزمایشهای کوچیک کوچیک تو شرکت شروع شد و ناگهان به محصول نهایی دیوار نفوذ کرد و کار به جایی رسید که تیم زیرساختمون یکی از تمرکزهاش، فراهم کردن دسترسی به مدلهای مختلف هوش مصنوعی به صورت پایدار شد.
در خصوص دستیار برنامهنویسی هم، اوایل ۱۴۰۳ شروع کردیم Github Copilot سازمانی دادن به همهی بچهها، کم کم که جلو اومدیم تو تابستون ۱۴۰۳ دیدیم Cursor به نظر ابزار قدرتمندیه و به بهرهوری بیشتر خیلی کمک میکنه. اول چند ماهی با بچههای توسعهدهندهی وب تستش کردیم و بعد هم دسترسیش رو به تمام بچههای شرکت دادیم.
از اواسط ۱۴۰۳ و با اومدن مدل claude-3-5-sonnet-20241022 تصمیم گرفتیم تمرکز بیشتری بذاریم روی هوش مصنوعی مولد توی بهرهوری مهندسی و اولش یک پروژهی کوچیک و تقریبا سخت رو انتخاب کردیم: تلاش برای بازنویسی یک سرویس پایتونی به گولنگ، به صورت خودکار توسط AI، با human in the loop برای فاز اعتبارسنجی (validation).
انسان در چرخه (Human in the loop): «رویکردی در سیستمهای هوش مصنوعیه که انسان در نقاط کلیدی فرآیند تصمیمگیری یا اعتبارسنجی دخالت میکنه تا دقت و کیفیت خروجیها را تضمین یا بهبود ببخشه.»
هدفمون بیشتر این بود که پتانسیلهای AI رو توی توسعه بیشتر درک کنیم و از شکستن خوردن ترسی نداشتیم. با یک سرویس آسون شروع کردیم و خروجیهای جالبی گرفتیم، بعدش رفتیم سراغ سرویس احراز هویت دیوار و اونجا با دشواریهای دیگهای مواجه شدیم. در نهایت هر دو سرویس رو تو حدود ۳ ماه توسط AI بازنویسی کردیم، ولی خب انجام مجدد این کارو فعلا، با مدلها و ابزارهای فعلی به کسی پیشنهاد نمیکنیم.
با تجربهی بازنویسیمون، درک نسبتا خوبی پیدا کردیم از توانمندیهای AI تو توسعه و اونجا تیم رو چرخوندیم به سمت توسعهی ابزارهای مبتنی بر هوش مصنوعی مولد و تلاشمون اینه تا آخر ۱۴۰۴، بتونیم بخش خوبی از آزمایشهامون در دیوار رو به صورت خودگردان (Autonomous) بهوسیلهی هوش مصنوعی مولد انجام بدیم تا تیمهامون چابکتر شن و ظرفیت آدمهامون بیشتر بشه.
با دستیار، ما فقط یه ابزار نساختیم، بلکه داریم یه فرهنگ جدید رو تو کار کردن در دیوار شکل میدیم. فرهنگی که توش هوش مصنوعی نه یه چیز عجیب و غریب، بلکه یه همکار روزمرهست. و این، شاید مهمترین دستاورد ما تا الان بوده. چون وقتی همه بتونن از این فناوری استفاده کنن و باهاش راحت باشن، اون وقته که واقعاً میتونیم بگیم آمادهایم برای آیندهای که هوش مصنوعی توش نقش پررنگتری داره.
شکستها و کارهایی که هنوز ثمرهای ندادن
یکی از کارهایی که همیشه دوست داشتیم انجام بدیم محاسبهی کارایی تیمها بود. خیلی اینور اونور چرخیدیم که ببینیم چیکار میتونیم براش بکنیم و به کمک کتاب زیبای Accelerate و ریسرچهایی که DORA در اختیارمون گذاشته بود، ۴ متریک دورا برای محاسبه کردن در سطح پروژههامون انتخاب کردیم. چند بار تاحالا تلاش کردیم تا این متریکها رو برای پروژههامون محاسبه کنیم و یک بار هم با اقتباس از Test Certified Program گوگل سعی کردیم یک «مدل بلوغ» برای دیوار بسازیم و جا بندازیمش، اما فعلا هنوز هیچکدوم راه به جایی نبردن. اخیرا امیدواریم با یکپارچه کردن تجربهی توسعه دهندههامون با ابزار backstage، راهی برای ورود و بهبود این متریکها پیدا کنیم و ببینیم نتیجهی کارهای مختلفی که روی فرآیندهای توسعهمون تو دیوار میکنیم و فرهنگی که میسازیم، به چه شکله.
چهار متریک DORA ( یعنی deployment frequency, lead time, change failure rate, mean time to recovery ) توسط DevOps Research and Assessment برای سنجش کارایی سازمان استفاده میشن.
کارهایی هم بودن که تو هفتهها و ماههای اول خوب ثمر میدادن، ولی بعد از یه مدت رها میشدن. از اونجایی که هر کدوم از این ابزارها، به همراه خودشون یک فرآیندی هم میارن، بعد یه مدت استفادهشون کم میشد و ما هم خیلی روش هزینه نمیکردیم و کم کم از فرآیند توسعه خارج شدن. کلا این جنس مساله توی کارهایی که تیممون میکنه زیاد پیش میاد.
تلاشهای دیگهای هم برای بحث اشتراک دانش تو شرکت و جمع کردن مستنداتمون کردیم، ولی خب ظاهرا مثل خیلی جاهای دیگه، اصلا وضعیت خوبی تو این بخشا هم نداریم و یکی از چشم امیدهامون به هوش مصنوعی مولد تو این زمینهس تا یه مقداری وضعیت مستندسازی، خصوصا فنیهاش رو برامون بهتر کنه. تا الآن خروجیهای جالبی هم روش گرفتیم که توضیحاتش میمونه برای بعد.
تست نویسی در دیوار هم از اون چیزایی بود که باید خیلی روش سرمایهگزاری میکردیم. شاید اگه زیرساخت اکسپریمنتمون به بالا بردن «سرعت توسعه» کمک کرده باشه، تستهای بیشتر و حرفهایتر تو لایههای مختلف رو هم نیاز داریم تا «پایداری توسعه»مون رو بالا ببره و خب کلا تست نوشتن کار سختیه! تو تیممون سعی کردیم با یادگرفتن از پستها و کتابهای مختلف، خصوصا آموزههای بخش test کتاب Software Engineering at Google ( فصلهای ۱۶ تا ۱۹ ) کارهایی بکنیم، مثلا راه انداختن یک زیرساخت تست end to end API ولی عملا میتونیم روی این تلاش هم، برچسب «شکست خورده» رو بزنیم.
کار روی زیرساخت ci/cdمون هم به بخش مهم پایپلاین توسعه همیشه باهامون بوده و تجربههای شکست و موفقیت زیادی ازش داریم. از تلاش برای بردن زیرساخت ciمون روی سرورهای خارجی گرفته تا کارهای دیگه که اونارو هم جداگونه باید توضیح بدیم.
ادامهی راهمون چه شکلیه؟
بدهبستان (trade-off) وقت و انرژی گذاشتن روی هر کدوم از این کارها، سخت و قشنگه! مثلا این که الان بشینی پایپلاینهات رو ۱۰ ثانیه سریعتر کنی، یا زیرساخت اکسپریمنتت رو غنیتر کنی؟ یا تمام بچههارو بندازی روی ابزارهای AIای؟ از اونور هم خراب کردن هر کدومشون تاثیر عجیبی روی سیستم داره. مثلا یه باگ بزنی و اکسپریمنتها جابجا بشن و دادهها اشتباه تگ بخورن، یا فرضا ciهات رو ببری رو یه تکنولوژی دیگه و کل شرکت رو بدبخت کنی.
هوش مصنوعی مولد هم داره به شکل خوبی سیستم رو عوض میکنه و یه سری از کارهایی که شاید در گذشته برای ما پر هزینه، چالشی و نیازمند نگهداری بالا بود رو قابل انجامتر میکنه. از اون طرف بهرهوری بقیهی فرآیندهای مهندسی و توسعهمون هم به قابل استفادهتر شدن هوش مصنوعی توی بخشهای مختلفمون کمک میکنه.
کلا این «بهرهوری مهندسی» مفهوم خیلی قشنگ، پر ابهام، سخت و چالشیایه و هر چیزی رو میشه بهش پیوند داد. این که بتونی کار به درد بخور و اثرگذار هم توش بکنی خیلی سخته، با وجود این که مشتریت داره کنارت میشینه! این شکلی نیست که فرضا برداری یک apiت رو ۸۰ درصد سریعتر کنی و ته هفته خوشحال باشی، این شکلیه که ۳ ماه وقت میذاری رو یک چیزی و تهشم نمیفهمی به درد خورد یا نخورد! یا صدای ملت واقعا در اومد یا چون رفیقاتن و کنارت توی همون شرکت میشینن، خیلی بهت گیر نمیدن و اذیتت نمیکنن. ولی خب با همهی این قصهها، ما خیلی دوستش داریم!
آدمهای زیادی بهمون کمک کردن تا این اتفاقها تو دیوار بیافته و ازشون کلی یاد گرفتیم. وقتی یکی از بچههای قدیمی دیوار میومد تو تیم، میدیدیم چقدر دانش بومیای که از سیستمهای شرکت داره بهمون کمک میکنه، یا وقتی یه نفر از یک شرکت دیگه، تازه وارد تیممون میشد میدیدیم چقدر ایدههای جدید و قشنگی میده و دیوار و فرآیندهاش رو از یک زاویه دیگه میبنیه، یا وقتی نیروهای تازه کار و با استعداد میگرفتیم، میدیدیم چقدر کار سختی توی آنبورد کردنشون روی تیم داریم، تا بتونیم وضعیت مهندسای دیگه تو دیوار رو بهتر کنیم.
من، سید مصطفی مشکاتی، ۳ سال و نیمی هست افتخار حضور در این تیم رو دارم و برای همین لازمه اینجا از همهی بچههایی که تو این تیم بودن و برامون خلق ارزش کردن تشکر کنم. پویای رضایی و محمد حسین خوشرفتار عزیز که آجرهای اول تیم رو گذاشتن و به ماموریت تیم اعتماد داشتن. از علی محیط و روزبه صیادی و محمد وطندوست و مریم یونسی، از عمران باتمانقلیچ و امین عارف زاده، از امیرحسام ادیبینیا و مرتضی رستگار راد و زهرا دارابی، کیهان اسدی و ساسان یساری که هر کدوم بخشی از این تیم رو ساختن و بالا کشیدن و با کیفیتترش کردن. الآن هم که با سجاد ایوبی، حسام زمانپور، مصطفی کاظمی، عرفان میرشمس و میلاد نوروزی که با اشتیاق بالا روی بخشهای هوش مصنوعی هستیم و تلاش میکنیم تجربهی توسعهی بهتری برای بچههامون و در نهایت کاربرها بسازیم.
[1] https://martinfowler.com/articles/feature-toggles.html
[2] https://research.google/pubs/overlapping-experiment-infrastructure-more-better-faster-experimentation/
[3] https://github.com/danny-avila/LibreChat
[4] https://itrevolution.com/product/accelerate/
[5] https://dora.dev/guides/dora-metrics-four-keys/
[6] https://mike-bland.com/2011/10/18/test-certified.html
[7] https://backstage.io/
مطلبی دیگر از این انتشارات
از نظارت انسانی تا هوش مصنوعی: داستان تحول بررسی آگهیهای دیوار
مطلبی دیگر از این انتشارات
از دستیار کدنویس تا همکار هوشمند؛ گام اول: کابوس مستندسازی
مطلبی دیگر از این انتشارات
پشت پردهٔ تیم زیرساخت دیتای دیوار!