

C# enthusiast. NET foundation member
بررسی و پیاده سازی Logging حرفه ای در Asp Net Core با استفاده از Serilog و ElasticSearch و Kibana

در این مقاله به یکی از مهم ترین و در عین حال پرچالش ترین مسئله در معماری میکروسرویس، مانیتور و مدیریت میکروسرویس ها و ثبت رویدادها می پردازیم
توجه کنید که در این مقاله از Gist استفاده شده است و ممکن است لود شدن قسمت مربوط به کد ها کمی زمانبر باشد
در دنیای Microservice یکی از چالش هایی که اغلب تیم ها با آن رو به می شوند مسئله Logging هست و اینکه چگونه باید با Log ها در هر میکروسرویس برخورد کنیم. دو روش کلی برای لاگ کردن رویداد ها در میکروسرویس ها وجود دارد
1- برای هر میکروسرویسی یک سیستم Logging جدا طراحی کنیم، این روش چند مشکل به همراه دارد:
- در هر میکروسرویس ممکن است که مجبور به نوشتن کد های تکراری شویم
- ردیابی و Trace کردن لاگ ها به راحتی ممکن نیست و در صورت بروز خطا پیدا کردن Source خطا کار سختی خواهد بود
- لاگ ها یک فرمت واحد و یکسانی نخواهند داشت و اطلاعاتی که توسط هر میکروسرویس ثبت میشوند یکسان نخواهد بود
2- یک سیستم مرکزی برای Log کردن رویداد ها وجود داشته باشد. در اینصورت مشکلات روش قبلی را نخواهیم داشت ولی طراحی چنین سیستمی چالش های خاص خودش را به همراه دارد. خوشبختانه ابزار هایی برای Centralized Logging وجود دارند که کار ما را بعنوان برنامه نویس بسیار آسان میکنند که مجبور به اختراع چرخ از ابتدا نباشیم. در ادامه با یکی از ابزار های بسیار خوب در این زمینه آشنا میشویم.
آشنایی با Serilog. محبوب، آسان و جامع!
فکر میکنم که اکثر برنامه نویسان دات نت در مورد Serilog شنیده باشند. Serilog یک کتابخانه مخصوص logging در دات نت هست که برای structured logging طراحی و بهینه سازی شده است. در زمان نوشتن این مقاله، پکیج Serilog بیش از 172 میلیون دانلود داشته است!
استفاده از Serilog بسیار سرراست و آسان است بدون کوچک ترین مشکلی میتوانیم آن را با لاگر پیش فرض در Asp Net Core ادغام کنیم.
یکی از ویژگی های خوب Serilog که موجب محبوبیت آن شده است، وجود Provider های مختلف( یا به اصطلاح سازندگان آن Sink ) هست. به کمک Sink ها میتوانیم Serilog را برای استفاده در Provider های مختلف تنظیم کنیم و به نوعی بتوانیم از امکانات Serilog در هر محیطی استفاده کنیم.
به طور مثال، یکی از Sink های بسیار محبوب و کاربردی Console می باشد که به کمک آن میتوانیم لاگ هایی را که در کنسول ثبت میشوند سازماندهی و مرتب کنیم.
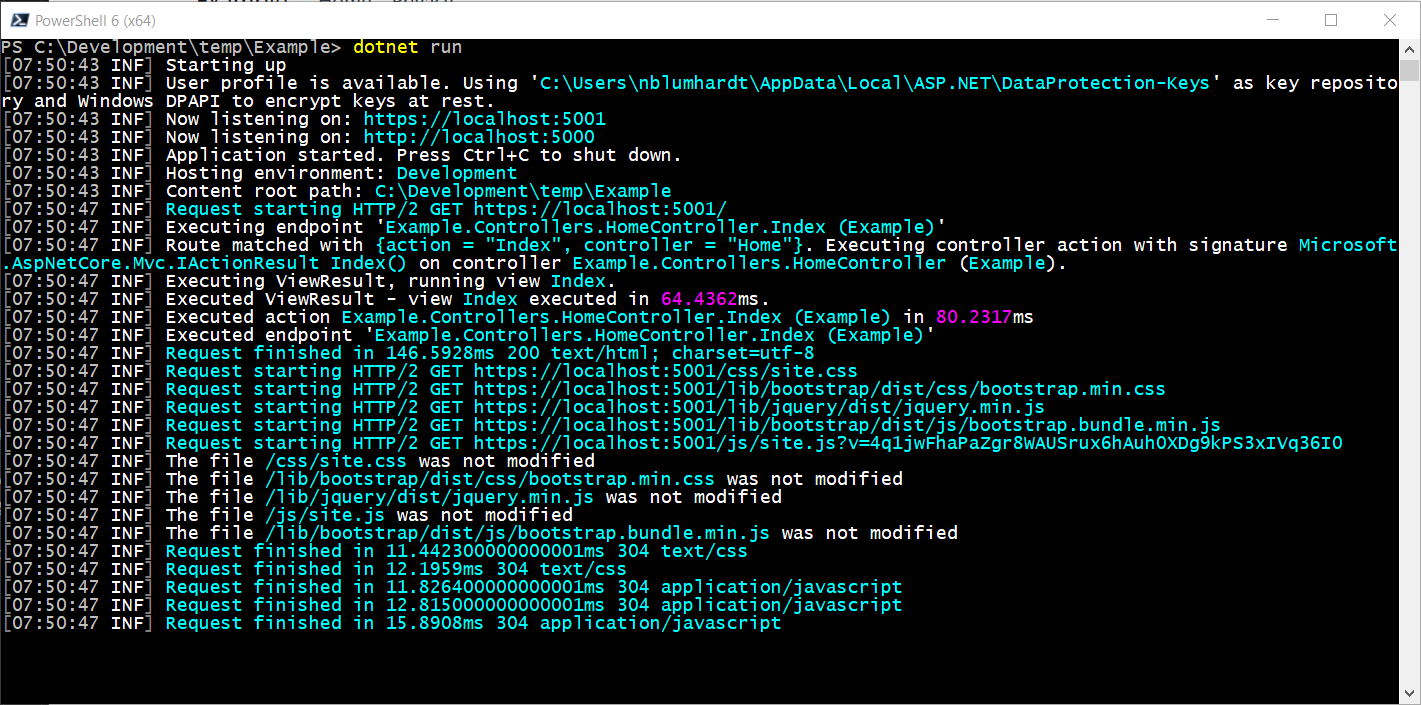
آشنایی با مفهوم Structured Logging
در Structured Logging از یک فرمت واحد برای ثبت لاگ ها استفاده میکنیم. با این کار خوانایی لاگ ها افزایش پیدا میکند، اطلاعات بیشتری را توسط لاگ ها می توانیم به دست بیاوریم و همچنین ثبت لاگ ها در محیط های مختلف کار آسان تری خواهد بود.
در Serilog به طور پیشفرض فرمتدهی بسیار خوبی را برای لاگ ها در نظر می گیرد. به طور مثال در Console ما میتوانیم زمان وقوع لاگ، سطح لاگ، اطلاعات ثبت شده در لاگ و همچنین زمان صرف شده برای اجرای یک Request را مشاهده کنیم. برای آشنایی بیشتر با فرمت دهی لاگ ها در Serilog میتوانید به این مقاله در گیت هاب Serilog مراجعه کنید.

غنی سازی (Log Enrichment) در Serilog
یکی از ویژگی های بسیار خوب و بسیار کاربردی در Serilog پیوست کردن اطلاعات اضافی به هر لاگ هنگام ثبت آن است. به طور مثال می توانیم که Thread Id ای که هر Thread برای اجزای یک Request دارد را به همراه لاگ های مربوط به آن Request ثبت کنیم. یا محیط اجرای برنامه را به همراه لاگ آن ثبت کنیم. با استفاده از این قابلیت علاوه بر اینکه فرمت مناسب هر لاگ حفظ میشود، با مراجعه به لاگ ها میتوانیم اطلاعات مفیدی را برای هرکدام از آنها مشاهده کنیم.
برای غنی سازی لاگ ها پکیج های بسیار زیادی وجود دارند که برای مشاهده و آشنایی با آنها میتوانید به این لینک مراجعه کنید.
نقش Serilog در Destributed Logging
همانطور که قبلا گفته شد، در Serilog بوسیله Sink های مختلف میتوان لاگ ها را در هر محیطی ثبت کرد. یکی از ابزار های بسیار خوب برای مدیریت لاگ ها ElasticSearch هست که بوسیله Sink مخصوص میتوان آن را برای ثبت لاگ ها به وسیله Serilog تنظیم کرد که در ادامه آن را بررسی می کنیم.
آشنایی مختصر با ELK Stack
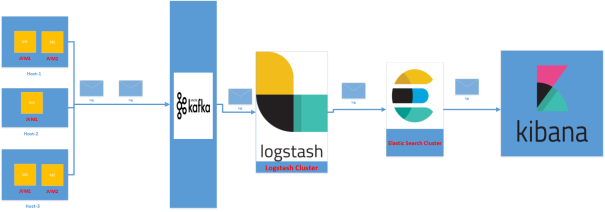
کلمه ELK نشان دهنده سه پروژه متن باز و محبوب ElasticSearch ، Logstash و Kibana می باشد که هر کدام را به اختصار توضیح میدهیم
یک Search Engine بسیار پیشرفته با قابلیت آنالیز و تبادل اطلاعات در قالب REST می باشد.
رابط کاربری و داشبورد ElasticSearch می باشد که کار با آن را بسیار آسان می کند. به وسیله Kibana میتوان به راحتی میتوان نمودار ها و چارت های گرافیکی مربط با اطلاعات ElasticSearch را مشاهده و تولید کرد و یا با تعیین فیلتر های مختلف از اطلاعات ElasticSearch گزارش گرفت.
یک پایپ لاین برای پردازش داده ای که ممکن است توسط Provider های مختلف فراهم شود. در واقع Logstash دیتا را از Provider های مختلف دریافت کرده و با تغییر شکل آن، آن را در Store های مختلف ذخیره می کند.
نصب و راه اندازی Kibana و ElasticSearch در محیط ویندوز
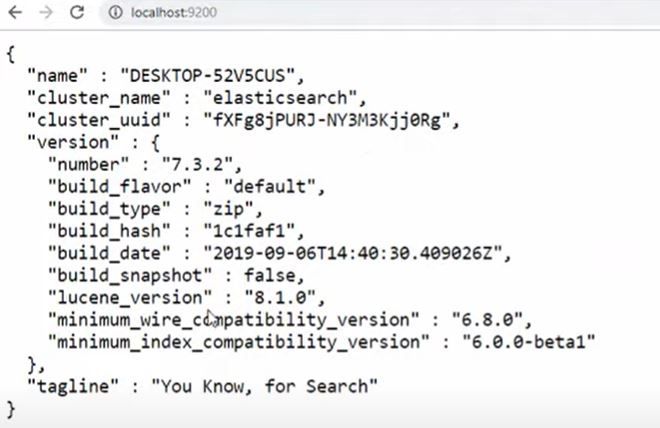
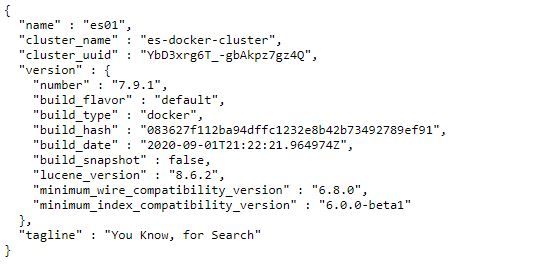
ابتدا باید از نصب Java SDK متناسب با ورژن ElasticSearch روی سیستم خود اطمینان حاصل کنید و همچنین از دسترس بودن پورت 9200 (پورتی که ElasticSearch به صورت پیشفرض از آن استفاده می کند) بر روی سیستم خود مطمئن شوید. سپس این فایل را دانلود کنید. پس از اتمام دانلود فایل elasticsearch.bat در پوشه bin را به صورت administrator اجرا نمایید. اگر مشکلی وجود نداشته باشد ElasticSearch به طور خودکار نصب خواهد شد.ممکن است پس از نصب نیاز باشد که سیستم خود را ریستارت نمایید.سپس به آدرس http://localhost:9200 روی سیستم خود مراجعه کنید، اگر نصب موفقیت آمیز بوده باشد یک فایل JSON حاوی اطلاعات ElasticSearch در مرورگر نمایش داده خواهد شد.
برای اطلاعات بیشتر و سایر تنظیمات نصب ElasticSearch میتوانید به این لینک مراجعه کنید.
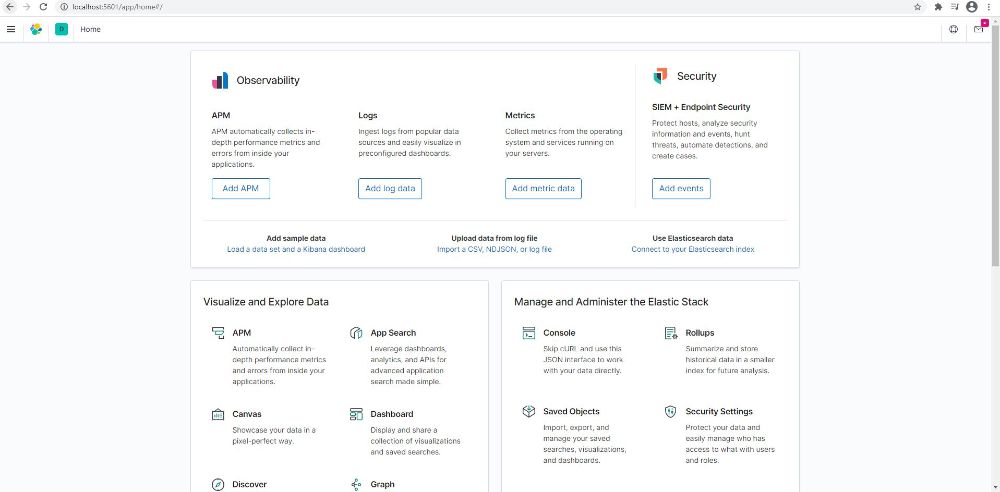
نصب Kibana نیز روال مشابه ای دارد. ابتدا از دسترس بودن پورت 5601 (پورتی که Kibana به صورت پیش فرض از آن استفاده میکند) اطمینان حاصل کنید. سپس این فایل را دانلود کنید. پس از اتمام دانلود به پوشه bin رفته و فایل kibana.bat را به صورت administrator اجرا نمایید. اگر مشکلی وجود نداشته باشد، نصب Kibana به صورت خودکار انجام خواهد شد. پس از نصب ممکن است که نیاز باشد سیستم خود را ریستارت نمایید. سپس آدرس http://localhost:5601 را در مرورگر خود وارد نمایید اگر نصب موفقیت آمیز بوده باشد، داشبورد Kibana در مرورگر نمایش داده خواهد شد.
برای اطلاعات بیشتر درباره نصب و همچنین تنظیمات نصب Kibana در ویندوز میتوانید به این لینک مراجعه کنید.
نصب و راه اندازی ElasticSearch و Kibana در Docker
طبق تجربه شخصی، نصب و راه اندازی ElasticSearch و Kibana در محیط ویندوز کار بی دردسری نیست. ممکن است که این دو روی ویندوز نصب نشوند و یا با تنظیمات اشتباه، نتوان آنها را اجرا کرد. ساده ترین و در عین حال بی دردسر ترین راه برای راه اندازی ElasticSearch و Kibana استفاده از Docker می باشد. ما در این مقاله به جزییات داکر نمی پردازیم. برای اطلاعات بیشتر میتوانید به سایت رسمی داکر مراجعه کنید. همچنین جادی عزیز در چند ویدیو داکر را به شکل گویا و روان توضیح داده است که میتوانید آنها را در این لینک مشاهده کنید.
معرفی Docker Compose
با استفاده از Docker Compose میتوانیم چند کانتینر و ترتیب ایجاد آنها، تعریف تنظیمات برای نحوه ایجاد هر کدام از کانتینر ها را در یک فایل YAML داشته باشیم. سپس با یک خط دستور docker-compose تمامی سرویس های مربوط به اپلیکیشن تنظیم و شروع به کار خواهند کرد. Docker Compose ابزاری فوق العاده برای توسعه، تست و مرحله بندی ساخت محیط توسعه می باشد. برای اطلاعات بیشتر می توانید به این لینک مراجعه کنید.
استفاده از Docker Compose برا تنظیم Kibana و ElasticSearch
برای تنظیم Kibana و ElasticSearch می توانیم از کد docker compose زیر استفاده کنیم
توجه داشته باشید که برای دانلود ایمیج های داکر نیاز به نرم افزارهای رفع تحریم هستید چرا که سایت داکر IP های مربوط به ایران را مسدود می کند.
پس از تعریف ورژن و سرویس ها در خط 4 داکر Image مربوط به ElasticSearch را دانلود میکند.
-در خط 5 یک نام برای کانتینری که قرار است از روی این ایمیج ساخته شود انتخاب میکنیم.
-از خط 6 تا 11 مربوط به تنظیمات و کانفیگ نصب ElasticSearch می باشد. node name و cluster name در واقع نام node مربوطه به ElasticSearch را تنظیم می کند که در صورتی که نیاز به Cluster کردن ElasticSearch با چند node باشد بتوانیم از نام آن استفاده کنیم. bootstrap memory lock مربوط به تنظیمات JVM و مدیریت GC در آن می باشد. برای بهبود عملکرد ElasticSearch توصیه می شود که مقدار آن را true قرار دهید. discovery type تعیین می کند که آیا برای ElasticSearch یک node وجود دارد یا بیشتر. در صورتی که این مقدار روی single-node قرار داده شود ElasticSearch به دنبال سایر node ها نمی گردد که در صورتی که فقط یک node برای ElasticSearch وجود داشته باشد موجب افزایش سرعت آن میشود. در خط 19 پورت پیش فرض ElasticSearch به یک پورت از سیستم مپ می شود.
-از خط 22 تنظیمات مربوط به Kibana شروع می شود که شباهت زیادی به تنظیمات ElasticSearch دارد. ابتدا ایمیج مربوط به Kibana دانلود می شود. سپس در خط 28 و 29 آدرس مربوط به ElasticSearch برای استفاده Kibana تنظیم می شود.
برای اطلاعات بیشتر در مورد فایل docker compose مربوط به ElasticSearch و Kibana می توانید به این لینک مراجعه کنید.
در نهایت در مسیر فایل docker compose ایجاد شده دستور زیر را در command prompt اجرا میکنیم
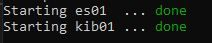
docker-compose up -dبسته به سرعت اینترنت دانلود و نصب ایمیج های مربوط به Kibana و ElasticSearch ممکن است مقداری طول بکشد. پس از اتمام دانلود و ایجاد کانتینر های مربوطه، ElasticSearch و Kibana در دسترس خواهند بود.
ایجاد پروژه ASP Net Core
برای استفاده بهتر از داشبورد Kibana و همچنین استفاده از ElasticSearch در Serilog یک پروژه نمونه ایجاد میکنیم.
پس از ایجاد پروژه، از طریق manage nuget package در ویژوال استودیو، پکیج Serilog.AspNetCore را نصب میکنیم.

Package Manager:
Install-Package Serilog.AspNetCore -Version 3.4.0توصیه میکنم که پکیج Serilog.Exceptions را هم در کنار Serilog نصب کنید. این پکیج در واقع یک Extension روی Serilog به همراه دارد که با Enrich کردن Serilog باعث ایجاد فرمت مناسب هنگام لاگ کردن Exception ها خواهد شد که میتوانیم از آن هنگام جست و جو میان لاگ ها در Kibana استفاده کنیم.

Package Manager:
Install-Package Serilog.Exceptions -Version 6.0.0همونطور که قبلا اشاره کردم یکی از نقاط قوت Serilog وجود Sink های مختلف هست. برای کانفیگ کردن Serilog با ElasticSearch تنها کافیست که پکیج Serilog.Sinks.Elasticsearch را روی پروژه نصب کنیم.

Package Manager:
Install-Package Serilog.Sinks.ElasticSearch -Version 8.4.1سپس url مربوط به ElasticSearch که در داکر کانفیگ کرده ایم را در appsettings.json قرار میدهیم.

برای جلوگیری از نوشتن کد تکراری، در solution پروژه یک Shared Project ایجاد میکنیم( البته میتوانیم از Class Library هم استفاده کنیم. Shared Project ها گزینه مناسبی برای Helper Method ها، Extension Method ها و کد های مشترک بین چند پروژه هستند. در این لینک میتوانید درباره تفاوت Shared Project و Class Library ها بیشتر بخوانید) روی Solution راست کلیک کرده و در تب Add گزینه New Project را انتخاب میکنیم.
سپس گزینه Shared Project را انتخاب کرده و یک اسم برای آن انتخاب میکنیم. من اسم Common را انتخاب میکنم.

تنظیم Serilog
در پروژه Common یک کلاس جدید با نام LoggingConfiguration ایجاد میکنیم. تمام تنظیمات مربوط به Serilog را در این کلاس انجام خواهیم داد.
ابتدا یک Action با پارامتر های HostBuilderContext و LoggerConfiguration ایجاد میکنیم و تنظیمات مربوط به Serilog را در آن اتخاذ میکنیم.
-در خط 7 و 8 با استفاده از HostBuilderContext به یک نمونه از Hosting Environment دسترسی پیدا میکنیم. سپس Logger را با اطلاعاتی همچون نام اپلیکیشن و Environment Name غنی میکنیم. وجود این اطلاعات در آینده برای Trace کردن لاگ ها کمک کننده خواهند بود. همچنین در اینجا میتوانیم از پکیج Serilog.Exception برای فرمت دهی مناسب به Exception Message ها نیز استفاده کنیم. همچنین با استفاده از پکیج Serilog.Enrichers.Process میتوانیم لاگ ها را با آیدی و نام Process غنی کنیم.
-در خط 18 تنظیمات مربوط به ElasticSearch شروع می شود. با استفاده از Configuration در HostBuilderConext مقدارر url تنظیم شده برای ElasticSearch را بدست می آوریم. تنظیمات مهم مربوط به ElasticSearch بصورت زیر خواهد بود:
-در خط 24 AutoRegisterTemplate تعیین میکند که در ElasticSearch یک Index برای لاگ های Serilog ایجاد شود.
-در خط 25 AutoRegisterTemplateVersion ورژن مربوط به Template برای استفاده در ElasticSearch را تعیین میکند.
-در خط 26 IndexFormat مهم ترین بخش در تنظیمات میباشد. تعیین میکند که Index برای ثبت لاگ ها در ElasticSearch چگونه باشد. بعدا از این Index برای جست و جو و فیلتر کردن لاگ ها در Kibana استفاده میکنیم. دقت داشته باشید که Index Format باید تماما بصورت Lower Case نوشته شود.
-در خط 27 MinimumLogEventLevel تعیین میکند که کمترین سطح لاگ برای ثبت در ElasticSearch چقدر باشد.
در مرحله بعد در فایل Program.cs اکشن ConfigureLogger به همراه Serilog را بصورت زیر تنظیم میکنیم.

برای تنظیم Kibana ابتدا احتیاج به ثبت چند لاگ داریم پس برنامه را اجرا میکنیم. سپس به داشبورد Kibana بر میگردیم.
تنظیم داشبورد Kibana برای مشاهده و مدیریت لاگ ها
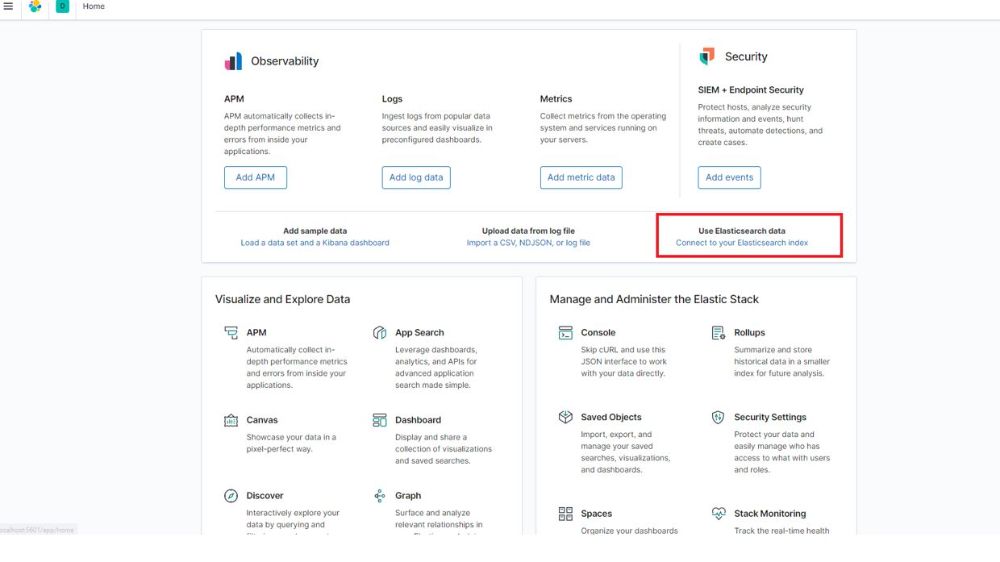
در صفحه Home گزینه Connect to your ElasticSearch index را انتخاب میکنیم.
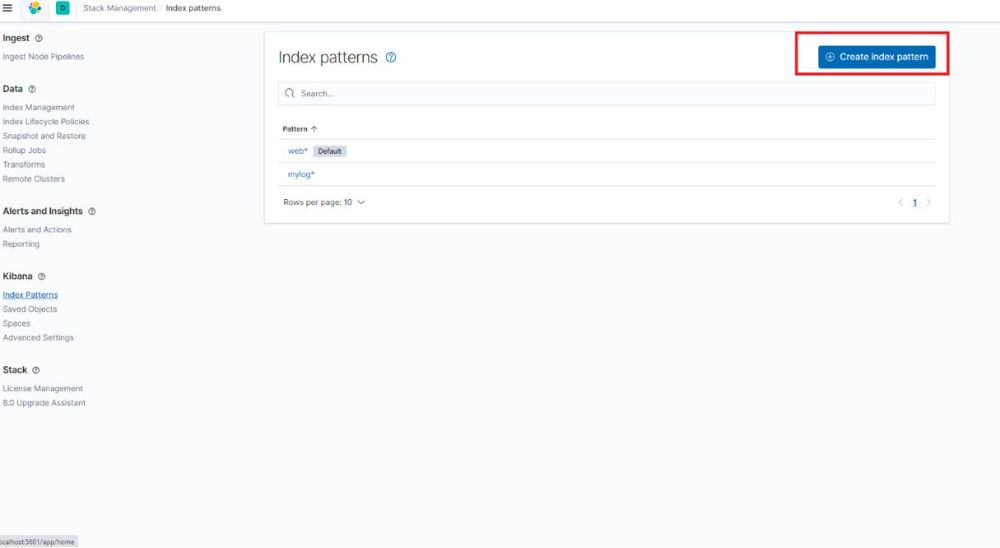
سپس در صفحه جدید گزینه Create index Pattern را انتخاب میکنیم.
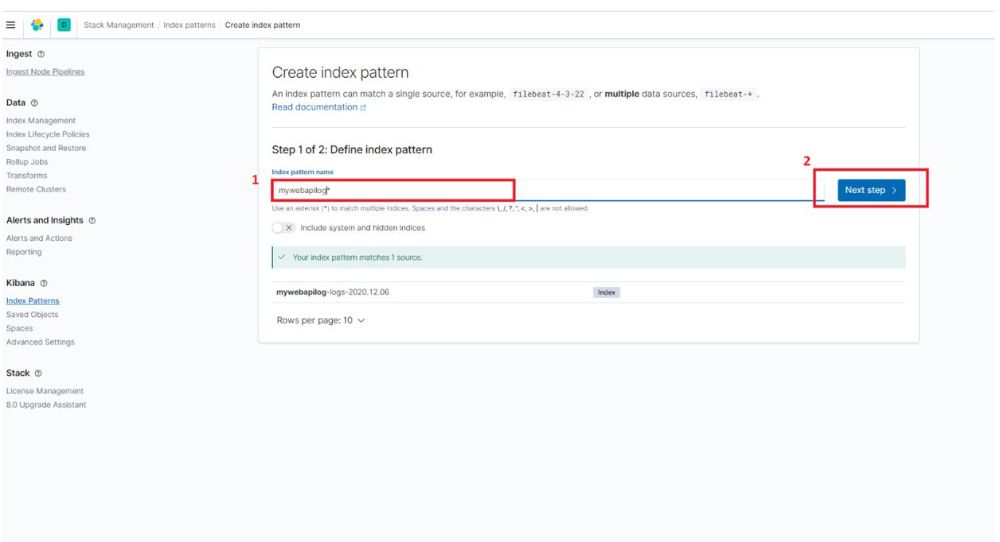
سپس در قسمت Index pattern name مقدار indexFormat ای که در Serilog تنظیم کرده ایم را وارد میکنیم( که در نمونه کد نام آن را mywebapilog قرار داده ایم). اگر Index ای در ElasticSearch ثبت شده باشد در این قسمت نشان داده خواهد شد
سپس برای Time field گزینه @timestamp را انتخاب کرده و Create index pattern را انتخاب میکنیم.
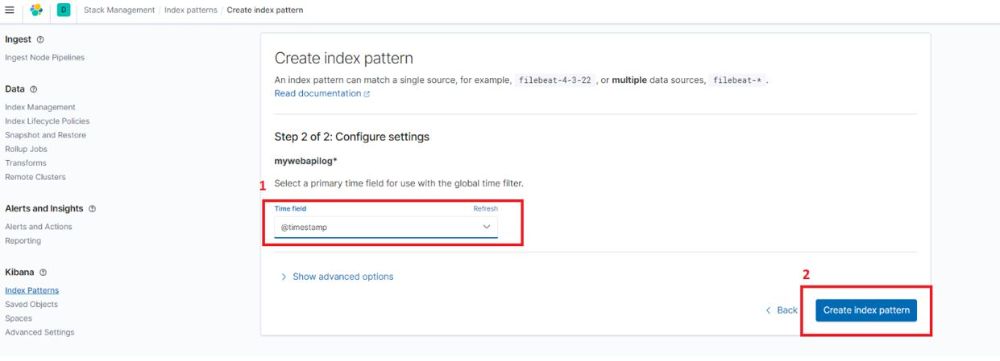
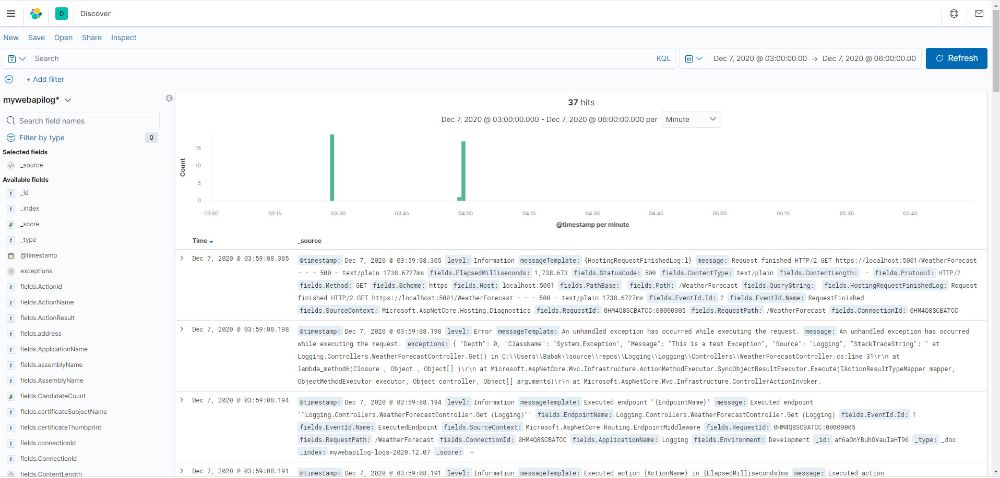
برای مشاهده لاگ های ثبت شده، از منوی کنار گزینه Discover را انتخاب میکنیم
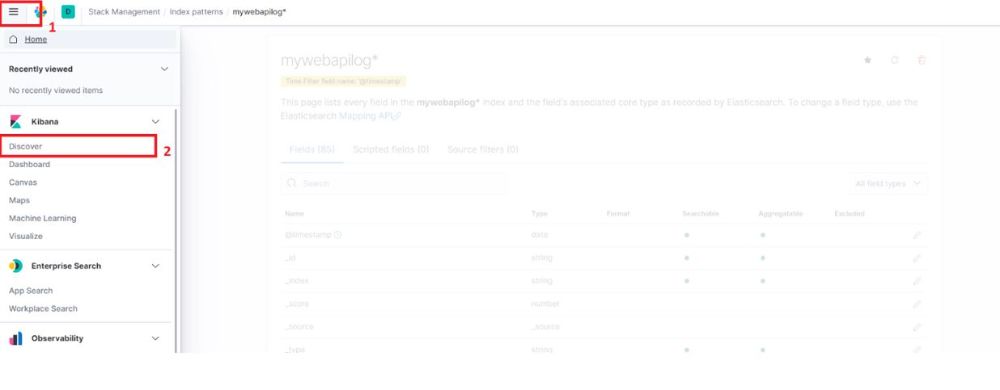
در صفحه جدید مجددا از منوی کنار index pattern مورد نظرمان را انتخاب میکنیم.قبلا در کد و تنظیمات Serilog نام index رو mywebapilog قرار داده ایم.

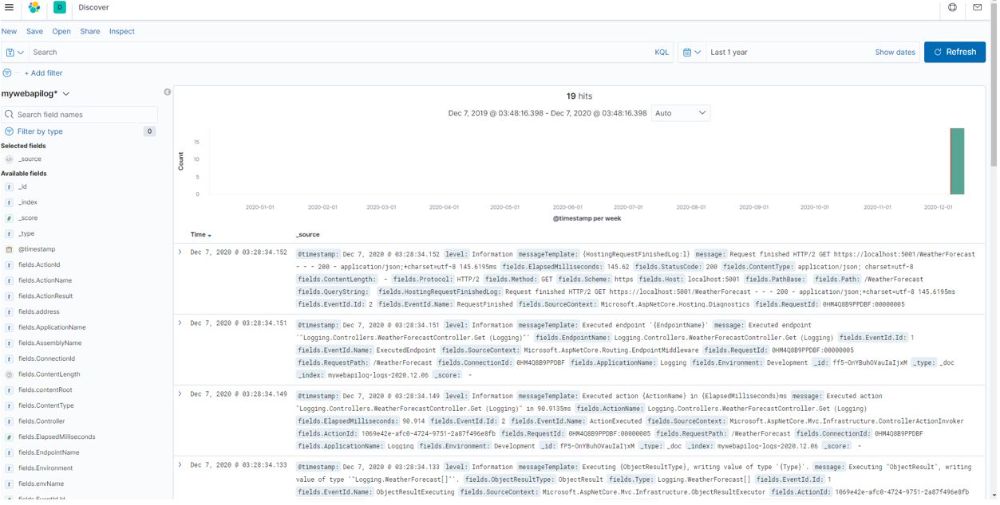
با استفاده از تنظیمات نوار بالایی میتوانیم لاگ های ثبت شده را فیلتر کنیم. مثلا میتوانیم لاگ های ثبت شده طی یک سال گذشته را فیلتر و مشاهده کنیم.

در نهایت لاگ های اپلیکیشن ما به تفیکیک زمانی قابل مشاهده هستند.
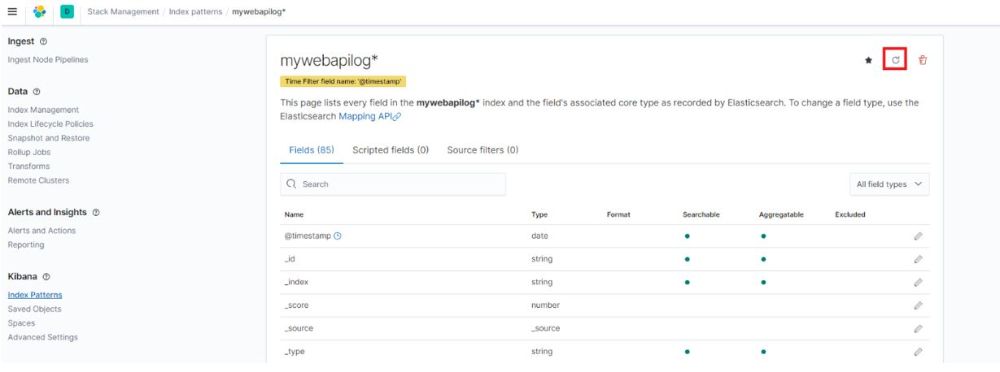
حل مشکل فیلد های بدون Index Pattern در Kibana
ممکن است کنار یک سری از فیلد ها علامت warning وجود داشته باشد

این اخطار بخاطر این است که ElasticSearch یک سری فیلد جدید پیدا کرده که در index pattern وجود نداشته است. برای حل این مشکل به index pattern برمیگردیم و یکبار آن را Refresh میکنیم.
تاثیر Exception Formatting در مشاهده و ثبت خطاها
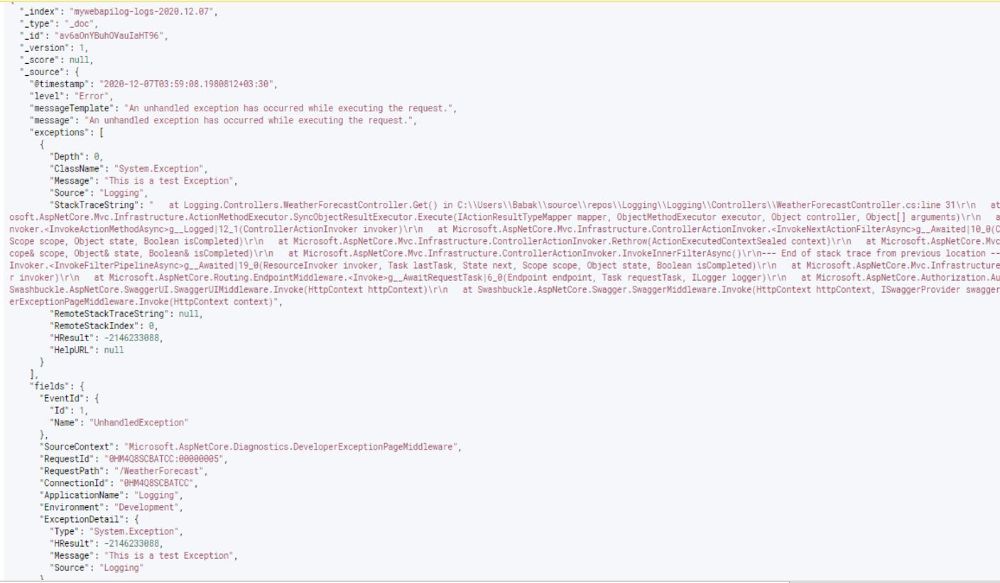
برای اینکه با Exception Formatting بیشتر آشنا شویم یک خطای تستی در پروژه ASP Net Core ایجاد میکنیم و سپس Index Pattern را مجددا Refresh میکنیم.
ملاحظه میکنیم که در فرمت Json با یک خطای Structured رو به رو هستیم که به خوبی source خطا و همچنین Request Id ای که باعث خطا شده رو نشون میده و به طبع تمام اپلیکیشن های دیگر در سیستم که از این تنظیمات استفاده کنند هم همین فرمت خطا را خواهند داشت.
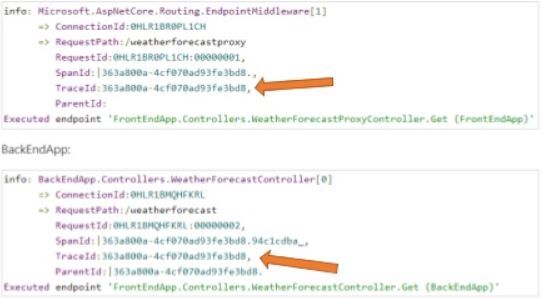
ردیابی لاگ ها با استفاده از Correlation ID
همواره ردیابی منبع خطا و یافتن اینکه کدام یک از میکرو سرویس ها مسبب این خطا بوده اند کاری دشوار است. برای حل این مسئله می توان به ازای هر ریکوئست، میکروسرویس هدف یک شناسه تصادفی و از جنس GUID تولید کند که وقتی درخواست از یک میکرو سرویس به میکروسرویس دیگر می رسد این شناسه را به همراه خود داشته باشد. به این صورت ردیابی لاگ ها بین میکرو سرویس ها تا رسیدن به منبع خطا یا ایجاد کننده لاگ آسان تر خواهد شد.
خوشبختانه لاگر پیش فرض Asp Net Core به صورت پیش فرض دنبال Trace ID لاگ میگردد و اگر وجود داشته باشد آن را ذخیره میکند، همچنین HttpClient پیش فرض در Asp Net Core این Trace ID را به صورت خودکار تولید میکند.
نتیجه گیری
در این مقاله به یکی از چالش های دنیای میکروسرویس ها، ثبت خطا و رویداد ها پرداختیم و ابزار مناسب برای آن را معرفی کردیم. ElasticSearch یک Search Engine فوق العاده هوشمند و با پرفرمنس بالاست که به بدون هیچ تردیدی میتوان از آن در پروژه های Enterprise استفاده کرد. همچنین با استفاده از داشبورد Kibanba میتوان از تمامی امکانات ElasticSearch بدون کوچک ترین دغدغه استفاده کرد و مدیریت جامعی بر روی لاگ های سیستم های مختلف داشت.
اگر به کدهای این مقاله نیاز داشتید میتوانید آن را از گیت هاب دریافت نمایید و اگر سوال یا موردی هست، خوشحال میشوم که آن را در بخش نظرات مطرح کنید.
مقالات بیشتر در دات نت زوم
مطلبی دیگر از این انتشارات
نکات Refactoring برای برنامه نویسان C#
مطلبی دیگر از این انتشارات
وب اسمبلی (WebAssembly) چیه؟ و چرا آینده Web هست؟!
مطلبی دیگر از این انتشارات
لب هم به رومون بسته شد + راهکار ها