
پژوهشگر، تمرکز بر روی سئو و پردازش زبان طبیعی
روشهای تشخیص لینک اسپم در پایگاههای داده ابرپیوند با تحلیل گراف جهتدار
روشهای تشخیص لینک اسپم در پایگاههای دادهای که دارای ابرپیوند هستند، شامل محاسبه یک مقدار احتمال اسپم برای گرهها در یک گراف جهتدار از گرههای پیوندی است. این مقدار احتمال اسپم از اهمیت گره و مقدار مشتق تابع اهمیت گره نسبت به یک عامل کوپلینگ (Coupling Factor) محاسبه میشود. احتمال اینکه اهمیت یک گره بهصورت مصنوعی و از طریق لینک اسپم افزایش یافته باشد، از طریق محاسبه نسبت مقدار مشتق تابع اهمیت به رتبه گره تخمین زده میشود. همچنین میتوان از روش مستقیمتری استفاده کرد که شامل بررسی یک مؤلفه از بردار ویژه اصلی ماتریس پیوندها در دو مقدار متفاوت از عامل کوپلینگ است. این مقادیر نرمالشده میتوانند برای رتبهبندی گرهها و شناسایی اسپم استفاده شوند.
این پتنت (Method for detecting link spam in hyperlinked databases) به GOOGLE LLC اختصاص داده شده است.
https://patents.google.com/patent/US7509344B1/en :
2004-08-18 Application filed by Google LLC | 2026-03-25 Adjusted expiration
مقدمه
در دنیای وب، ساختار پیوندهای هایپرلینک (Hyperlinks) به عنوان یکی از مؤلفههای اصلی برای تعیین اهمیت و رتبهبندی صفحات وب استفاده میشود. موتورهای جستجو از الگوریتمهایی مانند PageRank برای تحلیل این ساختارها بهره میگیرند. این الگوریتمها اهمیت یک صفحه را بر اساس تعداد و کیفیت لینکهای ورودی به آن صفحه تخمین میزنند. با این حال، این روشها به دلیل وابستگی به لینکها، در معرض سوءاستفاده قرار دارند.
تعریف لینک اسپم
لینک اسپم به معنای ایجاد لینکهایی است که هدف اصلی آنها دستکاری الگوریتمهای رتبهبندی موتورهای جستجو است و نه ارائه ارزش واقعی به کاربران. این لینکها ممکن است از طریق روشهایی مانند لینک فارمها (Link Farms)، حلقههای وب (Web Rings)، یا خرید و فروش لینک ایجاد شوند.
نمونههای رایج لینک اسپم
لینک فارمها (Link Farms): لینک فارمها مجموعهای از صفحات وب هستند که بهصورت عمدی به یکدیگر لینک میدهند تا رتبه صفحات افزایش یابد. این صفحات اغلب محتوای کمی دارند و هدف اصلی آنها ایجاد لینکهای ورودی است.
مشکل: در لینک فارم، تعداد زیادی صفحه یا سایت (که معمولاً ارزش و اعتبار بسیار پایینی دارند)، تنها به یک صفحه هدف خاص لینک میدهند. هدف این است که به موتور جستجو این تصور دروغین را بدهند که آن صفحه هدف، بسیار مهم و معتبر است.
مثال سئویی: فرض کنید شما یک فروشگاه آنلاین جدید برای "لوازم آرایشی" دارید. برای اینکه سریعاً در جستجوی "خرید لوازم آرایشی" بالا بیایید، میروید و 100 تا وبلاگ یا سایت بیکیفیت (که شاید با نرمافزارهای تولید محتوای خودکار پر شدهاند) ایجاد میکنید. همه این 100 وبلاگ بیارزش، فقط و فقط به صفحه اصلی فروشگاه شما لینک میدهند.
موتور جستجو ابتدا ممکن است فریب بخورد و فکر کند که فروشگاه شما چون از 100 جا لینک گرفته، مهم است و رتبهاش را بالا ببرد. این همان "بالا رفتن مصنوعی رتبه" است.
چگونه تشخیص داده میشود؟ (از دید این پتنت): این روش تشخیص میدهد که وقتی به "قدرت لینک" (یک فاکتور داخلی موتور جستجو) بیشتر اهمیت داده میشود، اهمیت صفحه هدف (فروشگاه شما) ناگهان به شدت کاهش مییابد. چرا؟ چون لینکهایی که از وبلاگهای بیکیفیت آمدهاند، واقعاً ارزشی ندارند و وقتی سیستم حساستر میشود، اثر آنها خنثی شده و حتی منفی میشود. این کاهش شدید اهمیت (یعنی مشتق تابع اهمیت منفی و بزرگ میشود (اگر اهمیت یک صفحه خیلی سریع و غیرعادی زیاد شود، میتواند نشانهای از اسپم بودن آن باشد.)) نشاندهنده اسپم است. در مقابل، برای یک سایت واقعاً مهم مثل Yahoo.com که طبیعی لینک گرفته، چنین افت شدیدی رخ نمیدهد چون لینکهایش از منابع معتبر هم میآیند.
حلقههای وب (Web Rings): در این روش، گروهی از وبسایتها با هم تبانی میکنند و بهصورت متقابل به یکدیگر لینک میدهند تا رتبه گروه افزایش یابد. این روش معمولاً در گروههای کوچکتر و با هماهنگیهای خاص انجام میشود.
مشکل: در این روش، مجموعهای از سایتها یا صفحات با هم تبانی میکنند و به صورت متقابل و در یک حلقه به یکدیگر لینک میدهند. هدف این است که به موتور جستجو این تصور دروغین را بدهند که این گروه از سایتها همگی معتبر و دارای اهمیت هستند.
مثال سئویی: فرض کنید 5 نفر از دوستانتان وبلاگهای مختلفی در مورد "گردشگری" دارند. شما با هم قرار میگذارید که هر وبلاگ به 4 وبلاگ دیگر در این گروه به صورت متقابل لینک بدهد. یعنی وبلاگ A به B, C, D, E لینک میدهد، وبلاگ B به A, C, D, E و الی آخر.
در ابتدا، موتور جستجو ممکن است فکر کند که این وبلاگها چون به هم زیاد لینک دادهاند، پس همگی معتبر و مهم هستند. این یک "حلقه وب" (Web Ring) است.
چگونه تشخیص داده میشود؟ (از دید این پتنت): این روش تشخیص میدهد که وقتی به "قدرت لینک" (همان فاکتور داخلی موتور جستجو) بیشتر اهمیت داده میشود، اهمیت این صفحات در حلقه ناگهان به شدت افزایش مییابد. چرا؟ چون این لینکها در داخل یک حلقه بسته میچرخند و "اهمیت" را در خود گروه نگه میدارند و آن را به خارج از حلقه منتقل نمیکنند. این افزایش شدید اهمیت (یعنی مشتق تابع اهمیت مثبت و بزرگ میشود) نشاندهنده اسپم است. در حالی که یک سایت طبیعی که عضو چنین حلقهای نیست، ممکن است لینکهای خروجی زیادی به سایتهای دیگر داشته باشد و این اهمیت را پراکنده کند.
چطور این "مشکات" شناسایی میشوند؟
کلید تشخیص در این پتنت، استفاده از چیزی به نام "مشتق تابع اهمیت یک گره نسبت به ضریب کوپلینگ" است.
تابع اهمیت گره (Node Importance Function): این همان فرمولی است که موتور جستجو برای محاسبه رتبه یک صفحه (مثل PageRank) استفاده میکند.
ضریب کوپلینگ (Coupling Factor): این یک عدد بین 0 تا 1 است.
وقتی این ضریب کم (نزدیک به 0) است، یعنی موتور جستجو کمتر به قدرت لینکها برای رتبهدهی اهمیت میدهد. در این حالت، همه صفحات تقریباً یکسان دیده میشوند.
وقتی این ضریب زیاد (نزدیک به 1) است، یعنی موتور جستجو خیلی زیاد به قدرت لینکها اهمیت میدهد و رتبه یک صفحه به شدت به بکلینکهایش وابسته میشود.
مشتق (Derivative): این مشتق به ما نشان میدهد که وقتی ضریب کوپلینگ را کمی تغییر میدهیم (یعنی مثلاً کمی بیشتر به لینکها اهمیت میدهیم)، رتبه یک صفحه چقدر تغییر میکند.
برای لینک فارمها: اگر یک صفحه به صورت اسپم لینک گرفته باشد، وقتی اهمیت لینکها را بالا ببریم، رتبهاش افت شدیدی میکند (مشتق منفی و بزرگ). چون لینکهایش بیارزش هستند.
برای حلقههای وب: اگر یک گروه از صفحات به صورت اسپم به هم لینک داده باشند، وقتی اهمیت لینکها را بالا ببریم، رتبهشان افزایش شدیدی میکند (مشتق مثبت و بزرگ). چون اهمیت در داخل حلقه محبوس میشود.
برای لینکهای طبیعی و سالم: تغییر رتبه آنقدر شدید نیست چون لینکها از منابع مختلف (هم قوی و هم ضعیف) میآیند و اثراتشان همدیگر را خنثی میکنند.
این "مشتق" پس از محاسبه، با یک عدد مرجع (threshold) مقایسه میشود تا اسپم بودن لینکها تشخیص داده شود. این روش به موتور جستجو کمک میکند تا تفاوت بین ساختارهای طبیعی و ساختارهای اسپم را درک کند.
چالشهای تشخیص لینک اسپم
تشخیص لینک اسپم به دلایل زیر دشوار است:
شباهت ساختارهای اسپمی به ساختارهای طبیعی: ممکن است یک سایت بهصورت طبیعی تعداد زیادی لینک دریافت کند که مشابه لینکسازی اسپمی به نظر برسد.
پنهانسازی اسپم: اسپمرها از روشهای پیشرفته برای پنهان کردن لینکهای اسپمی استفاده میکنند، مانند استفاده از لینکهای مخفی یا ریدایرکتهای پیچیده.
مفهوم کوپلینگ (Coupling)
کوپلینگ یک اصطلاح عمومی در علوم مختلف است که به معنای اتصال، وابستگی یا تعامل بین دو یا چند مؤلفه یا سیستم استفاده میشود. در زمینههای مختلف، این مفهوم ممکن است معانی متفاوتی داشته باشد.
عامل کوپلینگ (Coupling Factor)
عامل کوپلینگ (که معمولاً با c نشان داده میشود) یک پارامتر عددی بین 0 و 1 است. این پارامتر نشاندهنده میزان وابستگی الگوریتم به لینکها برای رتبهبندی است
وقتی کوپلینگ کوچک باشد (نزدیک به 0):
لینکها نقش کمتری در رتبهبندی صفحات ایفا میکنند.
رتبه صفحات بیشتر به ویژگیهای داخلی آنها (مانند محتوای صفحه) وابسته است.
در این حالت، الگوریتم اهمیت کمتری به لینکها میدهد.
وقتی کوپلینگ بزرگ باشد (نزدیک به 1):
لینکها نقش بیشتری در رتبهبندی صفحات ایفا میکنند.
رتبه صفحات بیشتر به تعداد و کیفیت لینکهای ورودی وابسته میشود.
در این حالت، الگوریتم تأثیر لینکها را به حداکثر میرساند.
مثال ساده:
فرض کنید یک موتور جستجو به دنبال رتبهبندی صفحات وب است. اگر کوپلینگ کوچک باشد، صفحات با محتوای قوی و بدون لینکهای ورودی ممکن است رتبه بالاتری بگیرند. اما اگر کوپلینگ بزرگ باشد، صفحات با لینکهای زیاد (حتی اگر محتوای ضعیفی داشته باشند) ممکن است رتبه بالاتری بگیرند.
کالبدشکافی

بخش اول: بستر پیادهسازی - معماری موتور جستجو (شکل ۱)
شکل ۱ یک معماری استاندارد از یک موتور جستجو را نشان میدهد و مشخص میکند که این اختراع در کجای این سیستم قرار میگیرد. موتور جستجو به دو بخش اصلی تقسیم میشود:
سیستم پشتیبان (Back End System 102): این بخش مسئول جمعآوری و پردازش دادههاست.
Crawler (خزنده) 104: وظیفهاش پیمایش وب و دانلود صفحات است.
Document Indexer (ایندکسکننده) 106: محتوای صفحات دانلود شده را پردازش و یک ایندکس عظیم (Document Index 108) از کلمات و محل آنها ایجاد میکند.
Link Records (رکوردهای لینک) 124: این بخش، تمام لینکهای موجود در هر صفحه را استخراج کرده و اطلاعاتی مانند URL مبدأ، URL مقصد و انکر تکست را ذخیره میکند. این دادهها، ماده خام برای تحلیل لینکها هستند.
Link Maps (نقشه لینک) 128: با استفاده از رکوردهای لینک، یک پایگاه داده از ساختار اتصالات وب (گراف لینکها) ساخته میشود.
Page Ranker (محاسبهگر پیجرنک) 130: با استفاده از "نقشه لینک"، رتبه اهمیت (PageRank) هر صفحه را محاسبه میکند.
Inflation Detector (تشخیصدهنده تورم) 136: این همان قلب اختراع ماست. این ماژول، "نقشه لینک" (128) و "پیجرنک" (132) را تحلیل میکند تا گرههایی که به صورت مصنوعی رتبهشان افزایش یافته را شناسایی کند. این ماژول میتواند به عنوان خروجی، رتبهها یا نقشه لینک را اصلاح کند.
سیستم جلویی (Front End System 104): این بخش مسئول تعامل با کاربر و ارائه نتایج است. زمانی که کاربر عبارتی را جستجو میکند، این سیستم نتایج را از ایندکس استخراج کرده و بر اساس رتبهای که توسط سیستم پشتیبان (و اصلاحات انجام شده توسط Inflation Detector) محاسبه شده، آنها را مرتب و نمایش میدهد.
نکته کلیدی: این ساختار نشان میدهد که تشخیص اسپم یک فرآیند آفلاین است که در Back End و قبل از ارائه نتایج به کاربر انجام میشود.
بخش دوم: تعریف مسئله - ساختارهای اسپم (شکلهای ۲، ۳ و ۴)
این بخش مشکلات را به صورت بصری تعریف میکند:
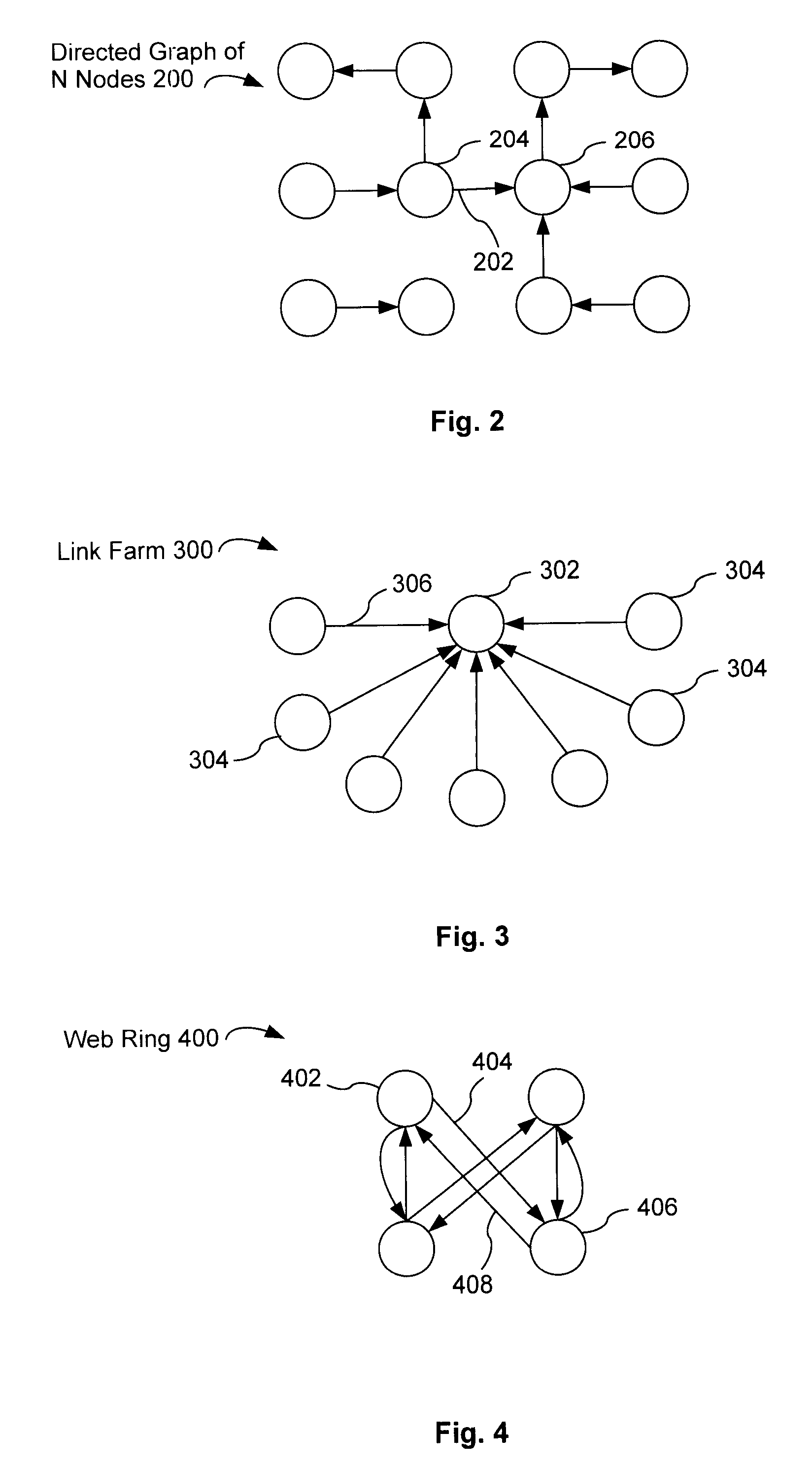
شکل ۲ (Linked Node Graph): یک نمایش ساده از گراف وب را نشان میدهد. هر صفحه یک "گره" (Node) و هر لینک یک "یال جهتدار" (Directed Connection) است. این مدلسازی، اساس تمام تحلیلهای بعدی است.
شکل ۳ (Link Farm): به وضوح یک "مزرعه لینک" را به تصویر میکشد. تعداد زیادی صفحه بیاهمیت (Dummy Web Documents 304) همگی به یک صفحه هدف (Home Page 302) لینک میدهند. پتنت تاکید میکند که چالش اصلی این است که این ساختار، شبیه به ساختار یک سایت واقعاً مهم (مانند Yahoo.com) است که به طور طبیعی لینکهای زیادی میگیرد.
شکل ۴ (Web Ring / Clique Attack): یک "حلقه وب" را نشان میدهد که در آن گروهی از صفحات (مثلاً 402 و 406) به صورت متقابل و شدید به یکدیگر لینک میدهند (لینک 404 و 408). هدف، محبوس کردن و تقویت "اهمیت" در داخل این حلقه است.
بخش سوم: راهکار اصلی - فرآیند تشخیص تورم (شکل ۵)
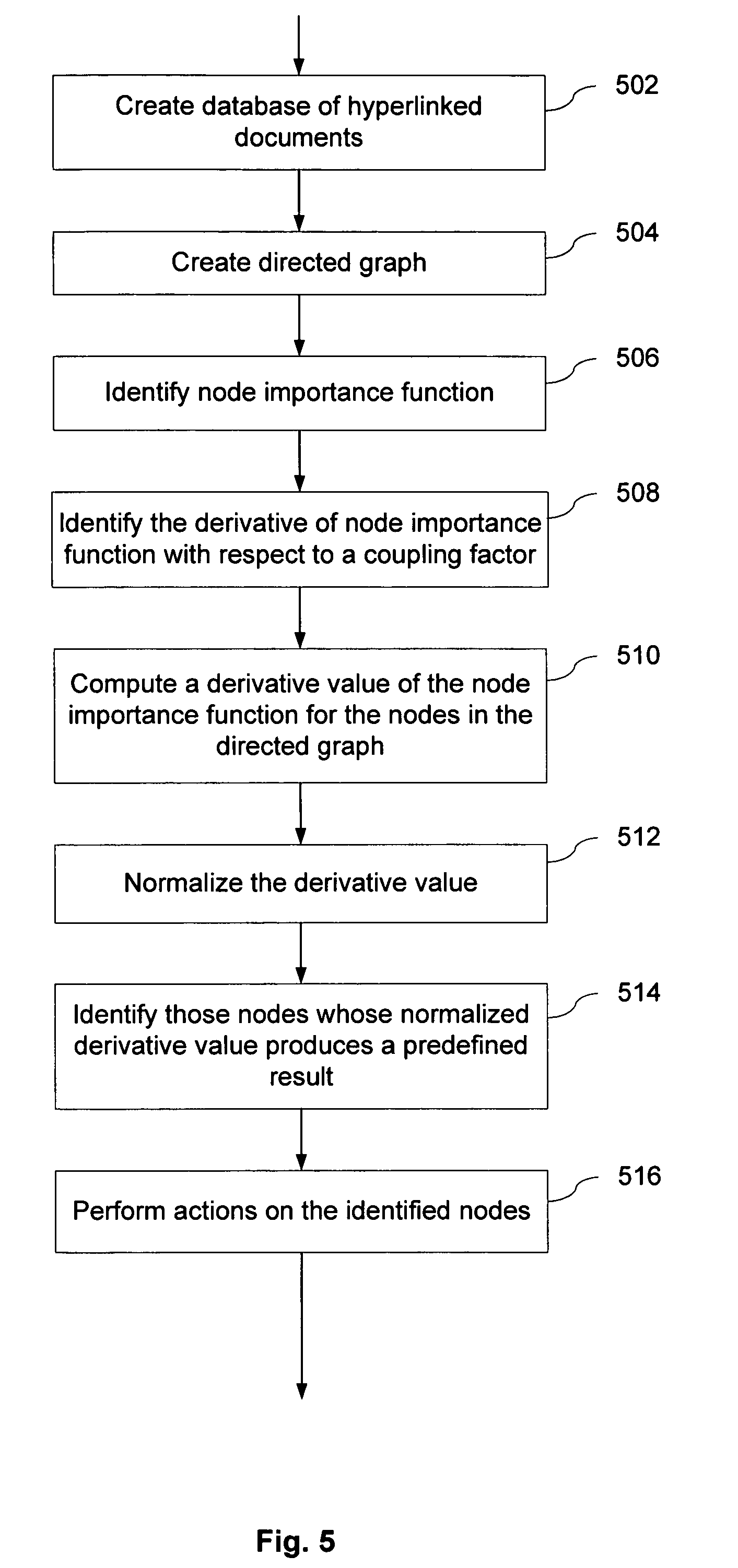
شکل ۵ یک فلوچارت است که گام به گام، متدولوژی تشخیص اسپم را توضیح میدهد:
گام 502 و 504 (ایجاد گراف): از رکوردهای لینک، یک "گراف جهتدار" ساخته میشود. این همان "نقشه لینک" در معماری است.
گام 506 (شناسایی تابع اهمیت): یک تابع برای محاسبه "اهمیت" گرهها انتخاب میشود. پتنت اشاره میکند که این تابع میتواند PageRank باشد، اما هر تابع رتبهبندی مبتنی بر لینک دیگری نیز قابل استفاده است.
گام 508 (شناسایی مشتق): این گام، نوآوری اصلی است. مشتق تابع اهمیت نسبت به "ضریب کوپلینگ لینک" (Link Coupling Factor) شناسایی میشود.
ضریب کوپلینگ (c): همانطور که قبلاً بحث شد، این ضریب بین 0 و 1 است و میزان وابستگی رتبه به لینکها را کنترل میکند.
c=0: رتبهبندی کاملاً تصادفی، همه صفحات برابرند.
c=1: رتبهبندی کاملاً وابسته به ساختار لینکها.
گام 510 (محاسبه مقدار مشتق): برای یک مقدار مشخص از c (مثلاً c=0.85)، مقدار عددی مشتق برای هر گره محاسبه میشود.
گام 512 (نرمالسازی): مقدار مشتق محاسبه شده بر "اهمیت" خود گره تقسیم میشود
چرا نرمالسازی مهم است؟ یک سایت بسیار بزرگ و مهم مانند Wikipedia ممکن است به طور طبیعی تغییرات رتبه بزرگتری داشته باشد. با تقسیم بر رتبه خود سایت، ما "حساسیت نسبی" را اندازهگیری میکنیم و میتوانیم یک صفحه کوچک اسپم را با یک صفحه بزرگ و سالم به طور عادلانه مقایسه کنیم.
گام 514 (مقایسه با معیار از پیش تعریف شده): مقادیر نرمالشده با یک آستانه (Threshold) یا درصد مشخصی مقایسه میشوند.
مقادیر بزرگ و منفی: نشانه قوی برای لینک فارم.
مقادیر بزرگ و مثبت: نشانه قوی برای حلقه وب.
مقادیر قدر مطلق بزرگ (|مقدار نرمال شده| > آستانه): برای شناسایی همزمان هر دو نوع اسپم.
گام 516 (انجام اقدامات متقابل): پس از شناسایی گرههای مشکوک، اقدامات زیر انجام میشود:
کاهش اهمیت :رتبه گره به صورت دستی کاهش مییابد.
حذف گره از گراف: گره به طور کامل از محاسبات بعدی حذف میشود.
استفاده از نیروی انسانی یا الگوریتم کمکی: برای تایید نهایی اینکه آیا یک گره واقعاً اسپم است یا خیر.

بخش چهارم: موتور محاسباتی - جزئیات ریاضی (شکل ۶)
این بخشها برای کسانی است که میخواهند بدانند "چگونه" این محاسبات در عمل انجام میشود.
شکل ۶ (محاسبه مشتق):
گام 602 (ایجاد ماتریس A(c)): ساختار لینکها به صورت یک ماتریس ریاضی به نام A(c) نمایش داده میشود. این ماتریس ترکیبی از دو ماتریس دیگر است:
ماتریس P: ماتریس انتقال بر اساس لینکهای واقعی. P(i,j) احتمال رفتن از صفحه j به i از طریق یک لینک است.
ماتریس E: ماتریس "پرش تصادفی". E(i,j) احتمال اینکه کاربر به صورت تصادفی و بدون دنبال کردن لینک، از هر صفحهای به صفحه i برود را نشان میدهد.
فرمول: A(c) = [cP + (1−c)E]ᵀ. ضریب c وزن بین این دو رفتار (دنبال کردن لینک یا پرش تصادفی) را تعیین میکند.
گام 604 (محاسبه تابع اهمیت): "اهمیت" یا رتبه هر صفحه، همان بردار ویژه اصلی (Principal Eigenvector) ماتریس A(c) است که با x(c) نمایش داده میشود.
گام 606 (محاسبه مشتق): مشتق این بردار ویژه، یعنی x'(c)، با حل یک دستگاه معادلات خطی به دست میآید. پتنت اشاره میکند که چون ماتریس M = I - cPᵀ بسیار بزرگ و خلوت (Sparse) است، از روشهای تکراری مانند Jacobi Relaxation برای حل آن استفاده میشود که برای این نوع مسائل بسیار کارآمد است.

بخش پنجم: شکل 7
۱. گام ۵۰۸: شناسایی مشتق تابع اهمیت نسبت به ضریب کوپلینگ
(Identify the Derivative of the Importance Function with Respect to a Link Coupling Factor)
هدف اصلی: ایجاد یک "ابزار اندازهگیری" برای سنجش میزان حساسیت یا شکنندگی رتبه یک صفحه نسبت به ساختار لینکهایش.
اهمیت برای سئو: این گام، نقطه شروع تشخیص اسپم است. این یعنی موتور جستجو فقط به وضعیت فعلی لینکهای شما نگاه نمیکند، بلکه این سوال را میپرسد: "اگر ما قوانین بازی را فقط کمی تغییر دهیم، آیا پروفایل لینک شما فرو میریزد؟" این نشان میدهد که ساختن یک پروفایل لینک بر پایههای سست و مصنوعی، به دلیل همین بیثباتی ذاتی، قابل شناسایی است.
۲. گام ۵۱۲: نرمالسازی مقدار مشتق
(Normalization of the Derivative Value)
هدف اصلی: ایجاد یک معیار عادلانه و استاندارد برای مقایسه "میزان اسپمی بودن" بین صفحات با اندازهها و رتبههای کاملاً متفاوت.
اهمیت برای سئو: این گام، عدالت و دقت را تضمین میکند. بدون نرمالسازی، سایتهای بسیار بزرگی مانند آمازون یا ویکیپدیا همیشه مشکوک به نظر میرسیدند، چون تغییرات عددی رتبه آنها به طور طبیعی بزرگتر است. نرمالسازی تضمین میکند که یک صفحه کوچک که به شدت با لینک فارم اسپم شده، حتی اگر تغییر رتبه مطلق آن کم باشد، به دلیل "نسبت" بالای تغییر، به عنوان یک سیگنال خطر شناسایی میشود. این یعنی الگوریتم، رفتار را از مقیاس جدا میکند.
۳. گام ۵۱۴: مقایسه مقدار نرمالشده با یک معیار از پیش تعریف شده
(Comparison with a Predefined Result/Threshold)
هدف اصلی: تصمیمگیری نهایی؛ آیا یک صفحه به عنوان اسپم "پرچمگذاری" (Flag) بشود یا خیر.
تشریح مفهومی (آنالوژی آزمایش خون):
بعد از اینکه "امتیاز بیثباتی" نرمالشده (گام ۵۱۲) برای هر صفحه محاسبه شد، این گام مانند پزشکی است که نتایج آزمایش خون شما را با "محدوده نرمال" مقایسه میکند.
برای هر معیار (مثلاً کلسترول)، یک محدوده سالم وجود دارد. اگر نتیجه شما خارج از این محدوده باشد، پزشک آن را به عنوان یک مشکل بالقوه علامتگذاری میکند.
در اینجا نیز، موتور جستجو آستانههایی (Thresholds) را تعریف میکند:
اگر امتیاز نرمالشده از یک آستانه مثبت بزرگتر باشد: احتمالاً عضو یک حلقه وب است. (پرچم قرمز)
اگر امتیاز نرمالشده از یک آستانه منفی بزرگتر (یعنی خیلی منفی) باشد: احتمالاً هدف یک لینک فارم است. (پرچم قرمز)
اگر امتیاز در محدوده نرمال باشد: صفحه احتمالاً سالم است. (چراغ سبز)
اهمیت برای سئو: این گام، مرحله قضاوت است. اینجا مشخص میشود که کدام سایتها از خط قرمز عبور کردهاند. این به متخصصان سئو میگوید که هدف باید نگه داشتن "امتیاز بیثباتی" در محدوده قابل قبول باشد. کمی نوسان طبیعی است، اما عبور از آستانههای الگوریتم منجر به جریمه خواهد شد. استراتژی سئو باید بر روی ایجاد پروفایلهای لینکی متمرکز باشد که به طور ذاتی پایدار هستند.
۴. گام ۷۰۲: ترکیب مقادیر چندگانه مشتق
(Combining Multiple Derivative Values)
هدف اصلی: افزایش دقت و قابلیت اطمینان تشخیص با بررسی رفتار صفحه در شرایط مختلف و جلوگیری از دور زدن الگوریتم.
تشریح مفهومی (آنالوژی تست در شرایط مختلف):
به جای انجام فقط یک "تست استرس" (گام ۵۰۸) در یک نقطه خاص، این گام پیشنهاد میدهد که چندین تست در نقاط مختلف انجام شود. مانند تست کردن یک خودرو نه فقط در یک جاده صاف، بلکه در جاده خاکی، در سربالایی و در هوای بارانی.
در اینجا، الگوریتم مشتق را برای چندین مقدار مختلف از ضریب c (مثلاً در c=0.7, c=0.8 و c=0.9) محاسبه میکند. سپس نتایج این تستها را با هم ترکیب میکند (مثلاً با گرفتن میانگین).
اگر یک صفحه در تمام این شرایط رفتاری ناپایدار و اسپمگونه از خود نشان دهد، الگوریتم با اطمینان بسیار بیشتری میتواند آن را اسپم تشخیص دهد. یک نتیجه غیرعادی در یک تست ممکن است تصادفی باشد، اما نتایج غیرعادی مداوم در چندین تست، یک الگوی قطعی را نشان میدهد.
اهمیت برای سئو: این بهینهسازی، سیستم را در برابر فریبکاری مقاومتر میکند. یک سئوکار ممکن است تلاش کند پروفایل لینک خود را طوری مهندسی کند که دقیقاً در یک مقدار خاص از c (که حدس میزند گوگل استفاده میکند) پایدار به نظر برسد. این روش چند-نقطهای، چنین استراتژیهایی را بیاثر میکند. پیام آن واضح است: پروفایل لینک شما باید به طور کلی و ذاتی سالم و پایدار باشد، نه اینکه فقط برای یک سناریوی خاص بهینه شده باشد. این امر بر اهمیت ایجاد یک پروفایل لینک متنوع و ارگانیک که در هر شرایطی طبیعی رفتار کند، تاکید مضاعف دارد.
مطلبی دیگر از این انتشارات
روش های شناسایی کلیک اسپم برای بهبود رتبهبندی در موتورهای جستجو
مطلبی دیگر از این انتشارات
شناسایی اسناد اسپم در یک سیستم بازیابی اطلاعات مبتنی بر عبارات
مطلبی دیگر از این انتشارات
تحلیل الگوریتم گوگل ساجست : معماری پردازش پیشنهادات تکمیل خودکار