
پژوهشگر، تمرکز بر روی سئو و پردازش زبان طبیعی
روش های شناسایی کلیک اسپم برای بهبود رتبهبندی در موتورهای جستجو

این پتنت به GOOGLE LLC اختصاص داده شده است.
https://patents.google.com/patent/US8694374B1/en :
2007-03-14 Application filed by Google LLC | 2031-04-09 Adjusted expiration
اسپم کلیک یا کلیک فیک چیست؟
اسپم کلیک (Click Spam) به انتخابهای نامعتبر یا جعلی لینکهای وب گفته میشود. این نوع فعالیت به عنوان فعالیت شبکه "غیرعادی" یا "انحرافی" شناخته میشود. هدف از آن معمولاً دستکاری نتایج موتورهای جستجو با افزایش یا کاهش مصنوعی رتبهبندی صفحات وب است. اگر اسپم کلیک فیلتر نشود، میتواند به طور جدی بر ارتباط بین پرسوجوهای جستجو و نتایج مرتبط تأثیر بگذارد.
مشکل اصلی:
اسپم کلیک و تأثیر آن بر رتبهبندی موتورهای جستجو تلاش میکنند تا مرتبطترین اسناد یا آیتمها را بر اساس نیاز کاربر شناسایی و ارائه دهند. یکی از ورودیهای مهم برای رتبهبندی، واکنش کاربران به نتایج جستجو است، مانند کلیکهایی که بر روی لینکها انجام میدهند (معمولاً کاربران بهترین داوران برای ارتباط نتایج هستند). "دادههای کلیک" (click data) مانند مدت زمانی که کاربر روی یک سند میماند ("long click" نشاندهنده ارتباط بالا، "short click" نشاندهنده عدم ارتباط) برای ایجاد آمار کیفیت نتیجه و بهبود رتبهبندی استفاده میشود. مشکل اینجاست که فعالیتهای شبکهای غیرمعمول، مانند "اسپم کلیک" (کلیکهای نامعتبر بر روی لینکها)، میتواند این سیگنالهای ارتباطی را تحریف کند. اگر این فعالیتهای غیرمعمول فیلتر نشوند، میتوانند همبستگی بین جستجوها و نتایج را کاهش دهند.
چرا شناسایی اسپم کلیک مهم است؟
شناسایی و کاهش تأثیر اسپم کلیک چندین مزیت مهم دارد:
بهبود رتبهبندی نتایج جستجو: با فیلتر کردن رفتارهای غیرعادی شبکه، رتبهبندی نتایج جستجو بر اساس رفتارهای واقعی کاربر، مانند انتخاب لینکها، بهبود مییابد.
افزایش دشواری اسپم: سیستمهایی که این تکنیکها را پیادهسازی میکنند، برای اسپمرها دشوار میسازند تا بخش قابل توجهی از دادههای کلیک را برای تغییر رتبهبندی نتایج جستجو دستکاری کنند، زیرا نیاز به سرمایهگذاری زمانی و منابع قابل توجهی برای دور زدن این سیستمها دارند.
افزایش دقت شناسایی اسپم: با ایجاد چندین لایه مستقل از معیارهای فیلترینگ اسپم، قابلیت شناسایی اسپم کلیک افزایش مییابد.
بهروزرسانی پویا: مدلهای مورد استفاده برای شناسایی فعالیت غیرعادی شبکه میتوانند به صورت پویا و مستمر بهروز شوند.
چارچوب کلی سیستم: ارتباط بین کلیکها و رتبهبندی
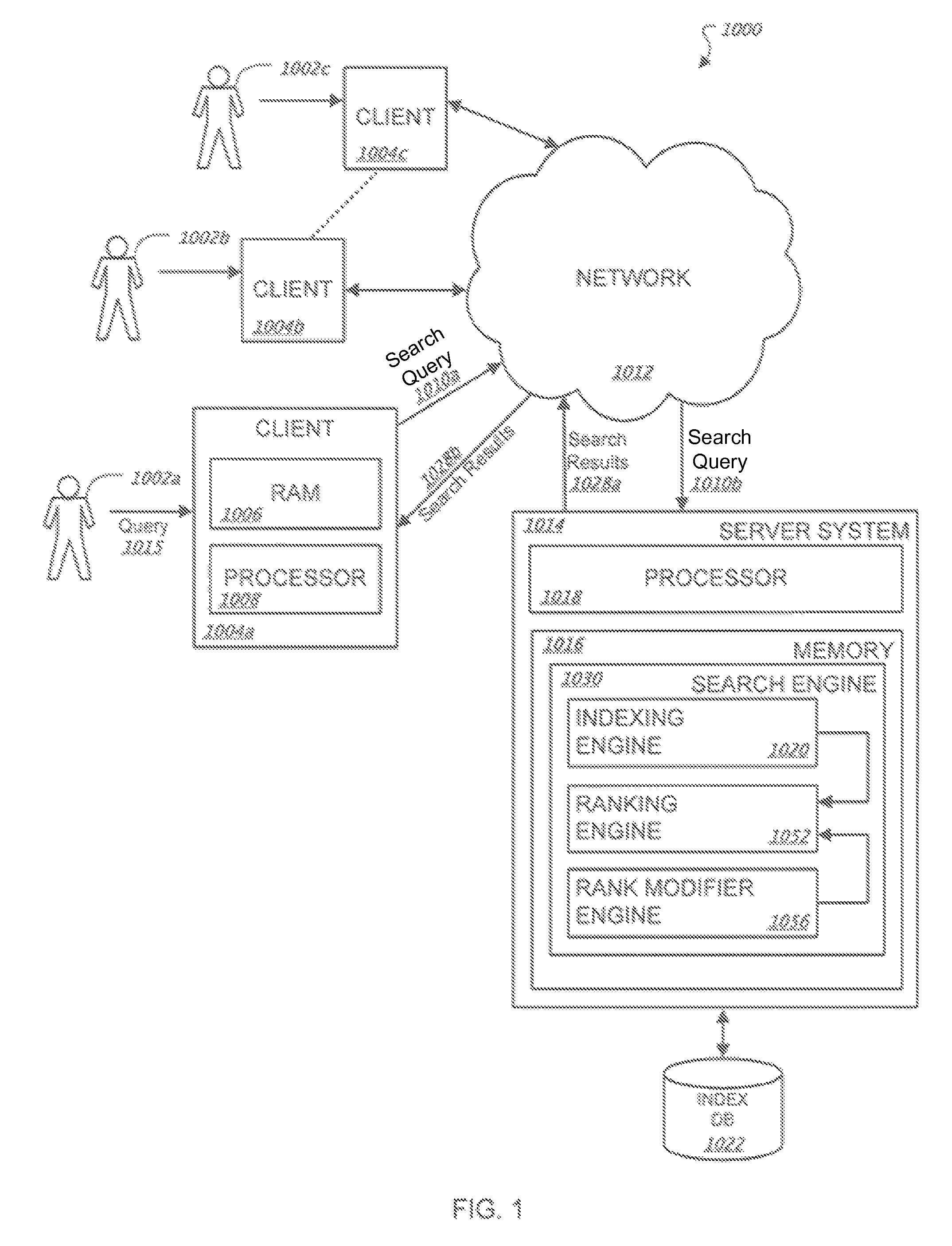
قبل از ورود به جزئیات تشخیص اسپم کلیک، باید مکانیزم اساسی رتبهبندی را درک کنیم. مطابق شکل 1 در پتنت، سیستم پایه شامل چندین جزء کلیدی است:
موتور ایندکسگذاری (Indexing Engine): اسناد وب را ایندکس میکند
موتور رتبهبندی (Ranking Engine): نتایج را بر اساس ارتباط با پرسوجو رتبهبندی میکند
موتور اصلاح رتبه (Rank Modifier Engine): از دادههای کلیک برای بهبود رتبهبندی استفاده میکند
موتور اصلاح رتبه بر اساس دادههای کلیک (Click Data) عمل میکند.
کلیک طولانی (Long Click): زمان ماندن زیاد روی صفحه → نشانه مرتبط بودن سند با پرسوجو
کلیک کوتاه (Short Click): زمان ماندن کم → نشانه عدم ارتباط سند با پرسوجو
مثال عملی: اگر کاربری روی نتیجه جستجوی "سئو حرفهای" کلیک کند و 7 دقیقه در آن صفحه بماند، این به عنوان کلیک طولانی ثبت شده و رتبه آن صفحه برای پرسوجوهای مرتبط افزایش مییابد. اما اگر کاربر در 5 ثانیه برگردد، سیستم این را به عنوان کلیک کوتاه ثبت کرده و رتبه آن صفحه کاهش مییابد.
مراحل تشخیص کلیک اسپم با جزئیات کامل
کلیک اسپم (Click Spam) به معنای کلیکهای غیرعادی یا تقلبی است که برای تأثیرگذاری بر رتبهبندی نتایج جستجو انجام میشود. موتورهای جستجو برای تشخیص و مقابله با این کلیکهای تقلبی از یک سیستم چندمرحلهای استفاده میکنند.
مرحله ۱: جمعآوری و ثبت فعالیتهای شبکه (Collecting and Logging Network Activities)
سیستم به طور مداوم تمام فعالیتهای شبکه را رصد و ثبت میکند.
فعالیتهای ثبتشده:
جستجوهای کاربران (Search Queries)
کلیکها بر روی نتایج جستجو (URI Selections / Hyperlink Clicks)
زمان باقیماندن روی صفحه (Dwell Time)
نوع کلیک: کوتاه (Short Click)، متوسط (Medium Click)، طولانی (Long Click)
شناسههای شبکه (Network Objects):
آدرس IP کاربر
کوکی (Cookie) مرورگر
آدرس MAC دستگاه
پیکربندی سختافزاری
مرورگر و سیستمعامل
ذخیرهسازی:
تمام این دادهها در لاگهای فعالیت شبکه (Network Activity Logs) ذخیره میشوند.
مرحله ۲: استخراج آمارهای کاربر و کوئری (Extracting Statistics)
سیستم از لاگها، آمارهای دقیقی برای هر شیء شبکه (مثل یک کوکی یا آیپی) و هر کوئری استخراج میکند.
الف) آمارهای مبتنی بر کاربر (User-based Statistics):
تعداد کل جستجوها
تعداد جستجوهای متمایز (Distinct Queries)
تعداد کل کلیکها (Total Clicks)
حداکثر تعداد کلیک روی یک نتیجه
تعداد کلیکهای کوتاه، متوسط، طولانی
نسبت کلیک به جستجو (Click to Query Ratio)
حداکثر تعداد کلیک در یک بازه زمانی (مثلاً 100 کلیک در ی ساعت)
توزیع موقعیت کلیک (مثلاً چند درصد کلیکها روی نتیجه اول بوده؟)
تعداد آیپیهای متفاوتی که یک کوکی از آنها فعال بوده
ب) آمارهای مبتنی بر کوئری (Query-based Statistics):
تعداد کوکیها و آیپیهایی که یک کوئری را جستجو کردهاند
تعداد کلیکهایی که از کوکیهای نامعتبر آمده
توزیع "امتیاز اسپم" (Spam Score) کوکیها و آیپیها برای یک کوئری
توزیع کلیکها بر اساس:
URI (کدام صفحه بیشتر کلیک شده؟)
موقعیت (کلیک روی نتیجه اول یا آخر؟)
طول کلیک (کوتاه یا طولانی؟)
توزیع سن کوکیها (مثلاً کوکیهای جدید بیشتر کلیک کردهاند؟)
این آمارها به صورت دورهای (مثلاً روزانه یا ساعتی) بهروزرسانی میشوند.
مرحله ۳: ایجاد مدل رفتار عادی (Generating a Model of Normal Behavior)
سیستم با استفاده از دادههای واقعی، یک مدل از رفتار عادی کاربران میسازد.
هدف: تعیین اینکه چه رفتاری "طبیعی" است و چه رفتاری "غیرعادی" یا مشکوک.
انواع مدلها: برای هر نوع شیء شبکه (آیپی، کوکی، کوئری و غیره) یک مدل جداگانه ساخته میشود.
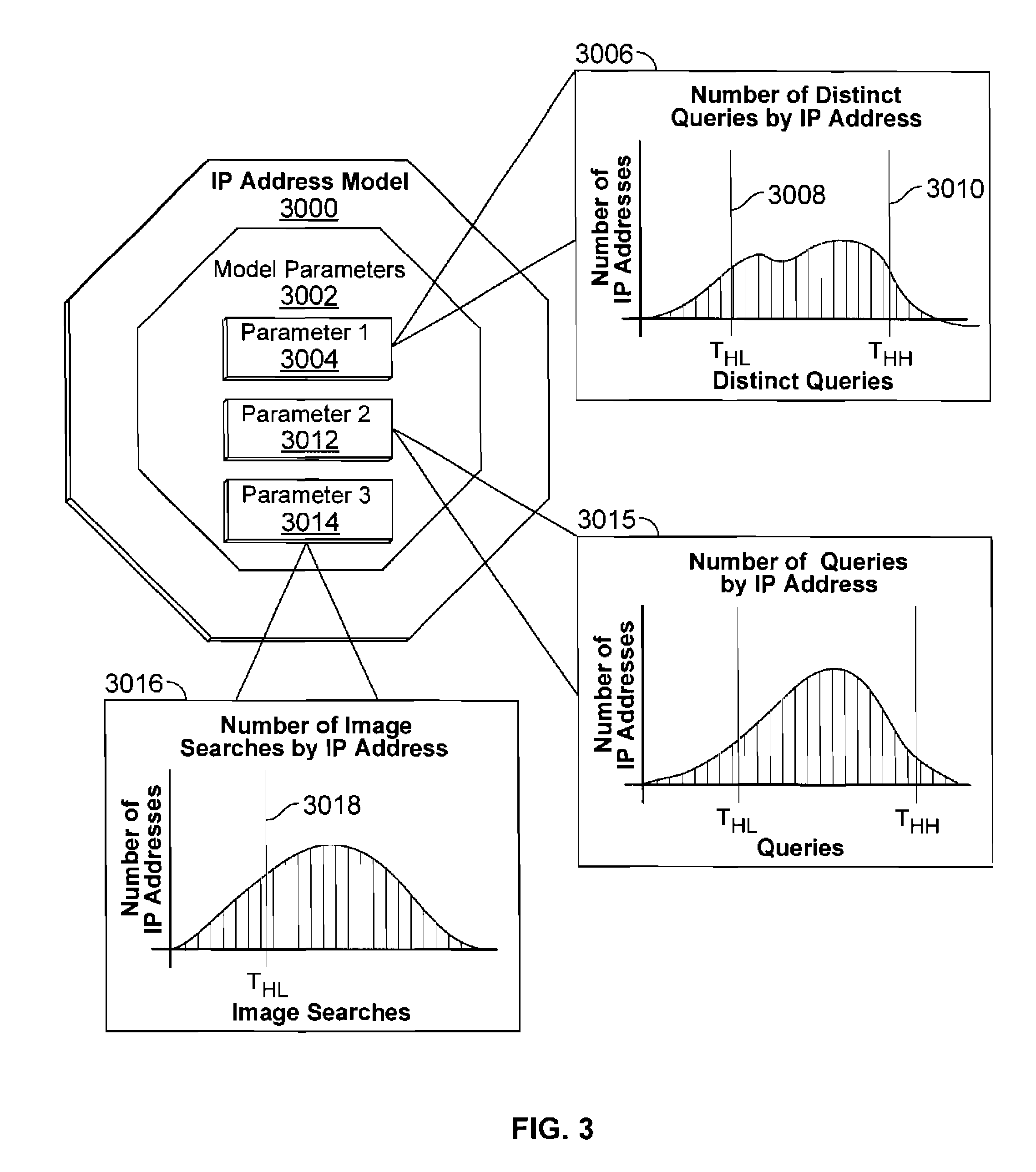
پارامترهای مدل: شامل توزیعها و آستانههایی است که رفتار طبیعی را تعریف میکنند.
مثال از پارامترهای مدل برای یک آیپی:
توزیع تعداد جستجوهای متمایز در روز
توزیع تعداد کل جستجوها در روز
توزیع تعداد کلیکهای کوتاه
توزیع زمان بین جستجو و کلیک
تعیین آستانهها (Thresholds):
آستانه پایین (THL): مقداری که زیر آن رفتار غیرعادی است (مثلاً 0 جستجو در روز)
آستانه بالا (THH): مقداری که بالای آن رفتار غیرعادی است (مثلاً بیش از 100 جستجو در روز)
برخی پارامترها فقط یک آستانه دارند (مثلاً فقط آستانه بالا برای کلیک کوتاه)
این آستانهها میتوانند:
به صورت خودکار با میانگینگیری از دادههای واقعی تعیین شوند.
یا به صورت دستی توسط مهندسان تنظیم شوند.
مرحله ۴: فیلترینگ اولیه و حذف کوکیهای مشکوک (Initial Filtering)
قبل از تحلیل آماری، سیستم چندین لایه امنیتی مستقل اعمال میکند:
حذف کوکیهای نامعتبر:
کوکیهایی که فرمت صحیح ندارند.
کوکیهایی که امضای دیجیتالی نادرست دارند.
حذف کوکیهای جدید (Young Cookies):
کوکیهایی که کمتر از 7 روز از صدور آنها گذشته است.
محدودیت تعداد "رأی" (Vote Limiting):
یک کوکی یا آیپی نمیتواند بیش از تعداد مشخصی "رأی" (یک جستجو + یک کلیک) برای یک جفت کوئری/نتیجه ارسال کند.
مثال: حداکثر 2 رأی در روز، 4 رأی در هفته، 10 رأی در سال.
رأیهای بیشتر از این حد، کاملاً حذف میشوند.
بررسی تنوع کاربر:
اگر چند کوکی مختلف همگی از یک آیپی واحد فعال باشند، مشکوک است.
این فعالیتها ممکن است حذف شوند.
مرحله ۵: شناسایی شیء شبکه غیرعادی (Identifying Anomalous Network Objects)
هر شیء شبکه (مثل یک آیپی خاص) را بررسی میکنند:
ویژگیهای آن را با پارامترهای مدل مقایسه میکنند.
اگر یک یا چند ویژگی خارج از آستانهها باشد، آن شیء "غیرعادی" (Anomalous) در نظر گرفته میشود.
روشهای تشخیص:
مقایسه مستقیم با آستانه: مثلاً اگر یک آیپی بیش از 100 جستجو در روز داشته باشد.
استفاده از طبقهبندیکنندههای یادگیری ماشین: مدلی که با دادههای اسپم شناختهشده آموزش دیده است.
مرحله ۶: محاسبه "اسپم بودن" (Spamminess) و تعیین منطقه
"اسپم بودن" (Spamminess) یا انحراف یک شیء شبکه، معیاری است که میزان انحراف یک شیء شبکه (مانند آدرس IP یا کوکی) را از مدل رفتار یا ویژگیهای مورد انتظار آن شیء نشان میدهد. هدف از این مرحله، شناسایی فعالیتهای شبکهای است که غیرمعمول به نظر میرسند، بهویژه آنهایی که ممکن است "کلیک اسپم" باشند، یعنی انتخابهای نامعتبر لینکهای هایپرلینک. کاهش یا حذف تأثیر این فعالیتهای غیرمعمول برای بهبود ارتباط بین کوئریهای جستجو و نتایج جستجو از اهمیت بالایی برخوردار است.
فرآیند شناسایی انحراف و محاسبه "اسپم بودن"
این فرآیند شامل چندین گام دقیق است که در ادامه به تفصیل توضیح داده میشود:
دسترسی به لاگهای فعالیت شبکه و انتخاب شیء شبکه: مرحله با دسترسی به لاگهای فعالیت شبکه آغاز میشود. این لاگها توسط یک مانیتور شبکه (مانند Network Monitor 2005) در سیستم سرور (Server System 1014) جمعآوری و ثبت میشوند. این لاگها حاوی اطلاعاتی در مورد فعالیتهای شبکه مانند کوئریهای جستجو، انتخابهای URI (لینکهای هایپرلینک)، و شناسههای اشیاء شبکه مرتبط با این فعالیتها (مانند آدرسهای IP یا کوکیها) هستند. در این مرحله، یک شیء شبکه خاص از این لاگها برای تحلیل انتخاب میشود، به عنوان مثال، یک آدرس IP.
تحلیل ویژگیهای شیء شبکه و مقایسه با مدل:
انتخاب ویژگی: پس از انتخاب شیء شبکه، یکی از ویژگیهای آن برای تحلیل انتخاب میشود. این ویژگیها میتوانند شامل آمار مختلفی باشند که برای هر شناسه کاربری (مانند کوکی، آدرس IP، آدرس MAC، تنظیمات سختافزاری) جمعآوری شدهاند. به عنوان مثال، میتوان تعداد "کلیکهای کوتاه" (short clicks) که یک آدرس IP انجام داده است یا تعداد کلیکهایی که یک آدرس IP در یک ساعت معین انجام میدهد را انتخاب کرد.
مدل رفتار عادی: برای هر شیء شبکه، یک مدل از رفتار و ویژگیهای "عادی" یا "مورد انتظار" ساخته میشود. این مدلها شامل پارامترهایی هستند که با آمارهای جمعآوریشده (مانند توزیع کوئریهای متمایز، تعداد کل کوئریها، تعداد جستجوهای تصویری) مطابقت دارند. این پارامترها میتوانند بهصورت دستی یا خودکار (مثلاً با میانگینگیری از مقادیر یک ویژگی در بین همه اشیاء شبکه مشابه) تولید شوند.
تشخیص انحراف: ویژگی انتخابشده از شیء شبکه مورد نظر با پارامترهای متناظر در مدل رفتار عادی مقایسه میشود. اگر ویژگی شیء شبکه فراتر از یک آستانه مشخصشده توسط پارامتر مدل منحرف شود، این انحراف ثبت شده و با آن آدرس IP یا ویژگی خاص آن مرتبط میشود. به عنوان مثال، اگر تعداد کلیکهای کوتاه یک آدرس IP کمتر از یک آستانه پایین در مدل باشد، آن ویژگی به عنوان "منحرف" طبقهبندی میشود. حتی وجود یک ویژگی منحرف واحد میتواند برای طبقهبندی شیء شبکه به عنوان "اسپم" کافی باشد، به شرطی که انحراف از آستانه مورد انتظار فراتر رود.
تعیین توزیع انحراف و تقسیمبندی به "مناطق" (Zones):
توزیع "اسپم بودن": پس از بررسی تمام ویژگیهای یک شیء شبکه و شناسایی ویژگیهای منحرف، یک "امتیاز اسپم" (spam score) برای شیء شبکه تعیین میشود. این امتیاز میزان انحراف کلی شیء شبکه را نشان میدهد و میتواند بر اساس تعداد ویژگیهای منحرف آن باشد. سپس، یک توزیع از "اسپم بودن" اشیاء شبکه نسبت به یکدیگر ایجاد میشود. این توزیع نشان میدهد که چه تعداد از اشیاء شبکه دارای تعداد کمی از ویژگیهای منحرف هستند و چه تعداد دارای تعداد زیادی از آنها.
تعیین مناطق (Zones): این توزیع به "مناطق" (zones) مختلفی تقسیم میشود که هر منطقه یک محدوده خاص از انحراف را تعریف میکند. این مناطق توسط آستانههای از پیش تعیینشدهای مشخص میشوند.
منطقه بدون تخفیف: اشیاء شبکه که تعداد ویژگیهای منحرف آنها کمتر از یک آستانه اول باشد، در این منطقه قرار میگیرند و فعالیتهای آنها بدون تخفیف یا کاهش تأثیر در نظر گرفته میشوند.
منطقه اول: اشیاء شبکه با تعداد ویژگیهای منحرف بین آستانه اول و دوم.
منطقه دوم: اشیاء شبکه با تعداد ویژگیهای منحرف بین آستانه دوم و سوم.
منطقه سوم: اشیاء شبکه با تعداد ویژگیهای منحرف که از آستانه سوم فراتر رود.
تعیین سهم (Contribution) و تخفیف (Discount)
پس از اینکه شیء شبکه در یکی از مناطق "اسپم بودن" دستهبندی شد، یک "سهم" (contribution) یا "ضریب وزنی" (weighting coefficient) به فعالیت شبکه مرتبط با آن شیء اختصاص داده میشود. این ضریب وزنی میزان تأثیر فعالیت شبکه را در الگوریتم رتبهبندی نتایج جستجو کاهش میدهد.
ضریب کاهش تأثیر:
اگر یک آدرس IP در "منطقه اول" باشد، ممکن است یک ضریب (مثلاً 0.5) به فعالیت آن اختصاص یابد، که نشان میدهد تأثیر فعالیت شبکه آن به نصف کاهش مییابد. این ضریب میتواند شامل مؤلفههای متغیری باشد که به موقعیت دقیق شیء شبکه در منطقه بستگی دارد؛ هرچه شیء شبکه به منطقه بعدی نزدیکتر باشد، تخفیف بیشتری اعمال میشود.
اگر آدرس IP در "منطقه دوم" باشد، تخفیف ممکن است بیشتر باشد (مثلاً ضریب 0.3)، زیرا احتمال فعالیتهای تقلبی افزایش مییابد.
اگر آدرس IP در "منطقه سوم" قرار گیرد، فعالیتهای ناوبری مرتبط با آن ممکن است به طور کامل کنار گذاشته شود یا به طور کامل تخفیف داده شود (مثلاً ضریب صفر)، به طوری که هیچ تأثیری بر الگوریتم رتبهبندی نداشته باشد.
اعمال سهم در الگوریتم رتبهبندی
این سهم یا ضریب تخفیفدهنده به الگوریتم رتبهبندی (ranking algorithm) و بهطور خاص به موتور اصلاحکننده رتبه (rank modifier engine) ارسال میشود. این موتور از این مقدار برای کاهش یا حذف تأثیر فعالیتهای شبکهای غیرعادی (مانند کلیک اسپم) در تعیین ارتباط و رتبهبندی نتایج جستجو استفاده میکند. با این کار، فعالیتهای شبکهای که دارای "اسپم بودن" بالا هستند، هنگام محاسبه ارتباط بین کوئریهای جستجو و نتایج جستجوی مرتبط، نادیده گرفته یا کمتر تأثیرگذار خواهند بود.
مسئولیت تخصیص تخفیف
تخصیص تخفیف میتواند توسط موتور مدلسازی (modeling engine 2014) یا یک جزء دیگر در دستگاه محاسباتی (computing device 2012) قبل از ارسال به سیستم سرور (server system 1014) انجام شود. همچنین، این تخفیف میتواند توسط اجزای موتور جستجو، مانند موتور اصلاحکننده رتبه (rank modifier engine 2013)، اختصاص یابد. در هر دو حالت، این اجزا میتوانند به یک جدول (مانند جدول 5030 در شکل 5C) یا ساختار داده دیگر برای تخصیص تخفیفها دسترسی داشته باشند.
مرحله ۷: اعمال ضریب تخفیف (Discount Coefficient)
برای فعالیتهای شبکهای که توسط اشیاء غیرعادی انجام شدهاند، یک ضریب وزنی اعمال میشود.
این ضریب به عنوان وزن در الگوریتم رتبهبندی استفاده میشود.
مثال: اگر یک آیپی در منطقه ۲ باشد، هر کلیک آن فقط 30% اثر خود را دارد.
مرحله ۸: ارسال به الگوریتم رتبهبندی (Input to Ranking Algorithm)
فعالیتهای شبکهای همراه با ضریب تخفیف مربوطه به الگوریتم رتبهبندی ارسال میشوند.
این اطلاعات در بهبود رتبهبندی نتایج جستجو استفاده میشوند، اما با اثر کمتری برای فعالیتهای مشکوک.
این کار از دستکاری نتایج جستجو جلوگیری میکند.
مرحله ۹: بهروزرسانی پویا مدل (Dynamic Model Update)
مدلها به صورت دورهای (مثلاً روزانه یا هفتگی) بهروزرسانی میشوند.
این کار باعث میشود سیستم بتواند به تغییرات در رفتارهای معمول کاربران پاسخ دهد.
مدلهای قدیمی حذف و مدلهای جدید بر اساس دادههای جدید ایجاد میشوند.
بنابراین، تمام تلاشهای آن سئوکار برای ارسال هزاران کلیک تقلبی بینتیجه میماند، زیرا سیستم به طور خودکار آن کلیکها را در "منطقه ۳" قرار داده و ارزش آنها را به صفر میرساند.
نکات مهم برای شما :
فکر دستکاری را از سرتان بیرون کنید: این پتنت نشان میدهد که گوگل سیستمهای بسیار پیچیدهای برای شناسایی الگوهای غیرطبیعی دارد. خرید کلیک، استفاده از ربات یا هر نوع کلیک فارمینگ (Click Farming) نه تنها غیراخلاقی است، بلکه از نظر فنی قابل ردیابی و بیاثر است.
تمرکز بر کاربر واقعی، نه ربات: تنها راه برای به دست آوردن "رأیهای" ارزشمند از گوگل، جذب کاربران واقعی است. این کار با تولید محتوای باکیفیت، بهبود تجربه کاربری (UX) و پاسخگویی واقعی به نیاز کاربر (Search Intent) ممکن میشود.
سیگنالهای باکیفیت مهم هستند: یک کلیک از یک کاربر واقعی با سابقه جستجوی طبیعی و کوکی قدیمی، هزاران بار ارزشمندتر از کلیکهای یک ربات است. الگوریتم برای کیفیت سیگنال ارزش قائل است، نه کمیت آن.
این یک سیستم پویاست: "مدل رفتار نرمال" گوگل دائماً در حال بهروزرسانی است. این یعنی روشهای اسپم که شاید دیروز کار میکردند، امروز به راحتی شناسایی میشوند.
مزایای این رویکرد برای سئوکاران:
دقت رتبهبندی: با فیلتر کردن اسپم کلیک، رتبهبندی نتایج جستجو بر اساس رفتار واقعی و معتبر کاربر بهبود مییابد.
مقاومت در برابر دستکاری: این سیستم با لایههای متعدد فیلترینگ، دستکاری دادههای کلیک برای بهبود رتبه نتایج را بسیار دشوار میکند.
تشخیص پیشرفته اسپم: با تولید چندین لایه مستقل از معیارهای فیلترینگ اسپم، تشخیص اسپم کلیک افزایش مییابد.
بهروزرسانی پویا: مدلهای مورد استفاده برای شناسایی فعالیتهای غیرمعمول شبکه میتوانند به صورت پویا بهروز شوند، که به سیستم امکان میدهد با روشهای جدید اسپمینگ تطابق یابد.
به طور خلاصه، کلید موفقیت در رتبهبندی جستجو برای سئوکاران، تمرکز بر تولید محتوای واقعاً مرتبط و با کیفیت است که منجر به تعاملات واقعی و مثبت کاربر میشود، نه تلاش برای دستکاری سیستم از طریق فعالیتهای کلیک غیرمعمول و "اسپم" که این سیستم قادر به شناسایی و خنثی کردن آنهاست. این رویکرد باعث میشود که "رأی" های کاربران واقعی، بیشترین تأثیر را در تعیین ارتباط و رتبهبندی داشته باشند.
چگونه میتوان سیستم ضد اسپم رفتاری گوگل را دور زد؟
یک مهاجم برای فریب دادن این سیستم باید بتواند رفتار یک جمعیت بزرگ، متنوع و معتبر از کاربران واقعی را در یک بازه زمانی طولانی شبیهسازی کند. این چالش اصلی است. بیایید روشهای بالقوه را بررسی کنیم:
روش ۱: استفاده از رباتهای بسیار هوشمند (Advanced Botnets)
یک ربات ساده که فقط کلیک میکند، فوراً شناسایی میشود. اما یک ربات هوشمند تلاش میکند تا رفتار انسان را تقلید کند:
شبیهسازی پروفایل کاربری:
تنوع در کوئریها: ربات به جای جستجوی یک کوئری ثابت، از مجموعهای از کوئریهای مرتبط (LSI Keywords) استفاده میکند.
الگوی مرور تصادفی: قبل و بعد از کلیک روی سایت هدف، به صورت تصادفی صفحات دیگری را نیز مرور میکند (مثلاً ویکیپدیا یا سایتهای خبری).
شبیهسازی Dwell Time: زمان ماندگاری در سایت هدف را به صورت تصادفی و در یک بازه منطقی (مثلاً بین ۳۰ ثانیه تا ۵ دقیقه) تنظیم میکند.
حرکات موس و اسکرول: ربات حرکات موس و اسکرول کردن صفحه را شبیهسازی میکند تا به نظر برسد یک انسان در حال خواندن محتواست.
چرا این روش در نهایت شکست میخورد؟
مشکل مقیاس و تنوع IP: مهاجم به یک شبکه بسیار بزرگ و متنوع از IPهای مسکونی (Residential IPs) نیاز دارد، نه IPهای دیتاسنتر که به راحتی شناسایی میشوند. تهیه و مدیریت چنین شبکهای بسیار پرهزینه و پیچیده است.
تاریخچه کوکی و حساب کاربری (Cookie & Account History): کلیکها از کوکیهای "بیتاریخچه" (Stateless) یا جدید میآیند. سیستم گوگل به کوکیهایی که تاریخچه جستجوی طولانی و طبیعی دارند، وزن بسیار بیشتری میدهد. ساختن چنین تاریخچهای برای میلیونها ربات تقریباً غیرممکن است. رباتها حساب گوگل (Gmail)، تاریخچه یوتیوب یا سابقه خرید در گوگل پلی ندارند؛ همه اینها سیگنالهای اعتبار هستند.
اثر انگشت مرورگر (Browser Fingerprinting): گوگل میتواند جزئیات فنی مرورگر (نسخه، پلاگینهای نصب شده، رزولوشن صفحه، فونتها) را تحلیل کند. رباتها اغلب اثر انگشتهای تکراری یا غیرعادی دارند که به راحتی قابل شناسایی است.
همبستگیهای پنهان (Hidden Correlations): الگوریتمهای یادگیری ماشین گوگل میتوانند الگوهایی را پیدا کنند که برای انسان قابل مشاهده نیست. مثلاً ممکن است تمام رباتها در یک بازه زمانی خاص (مثلاً نیمهشب به وقت محلی) فعال شوند یا از یک نسخه خاص از یک کتابخانه نرمافزاری استفاده کنند. این همبستگیها آنها را لو میدهد.
روش ۲: استفاده از مزارع کلیک انسانی (Human Click Farms)
در این روش، به جای ربات از انسانهای واقعی برای انجام کلیکها استفاده میشود. این روش در ظاهر هوشمندانهتر است چون رفتار انسانی واقعی است.
چرا این روش نیز در نهایت شکست میخورد؟
الگوهای رفتاری غیرطبیعی در سطح کلان: حتی اگر هر فرد به صورت طبیعی رفتار کند، رفتار گروه غیرطبیعی است. مثلاً ممکن است ۱۰۰۰ نفر در یک کشور خاص (مانند هند یا بنگلادش) ناگهان شروع به جستجوی یک کوئری بسیار خاص تجاری در مورد یک شرکت لولهکشی در کالیفرنیا کنند. این یک ناهنجاری جغرافیایی و جمعیتی آشکار است.
ناهنجاری در پروفایل کاربری افراد: افرادی که در این شبکهها کار میکنند، معمولاً پروفایل جستجوی بسیار غیرعادی دارند. آنها در طول روز صدها کوئری نامرتبط را جستجو کرده و روی لینکهای خاص کلیک میکنند. پروفایل آنها با مدل "کاربر نرمال" که به دنبال حل یک مشکل واقعی است، هیچ شباهتی ندارد.
همبستگی در شبکه (Network Correlations): این افراد ممکن است از یک زیرشبکه (Subnet) خاص اینترنت استفاده کنند یا حتی از طریق یک پلتفرم یا نرمافزار مشترک دستورالعملها را دریافت کنند. اینها سیگنالهای قوی برای شناسایی فعالیت سازماندهی شده هستند.
روش ۳: هک کردن وبسایتها برای تزریق کلیک (Click Injection via Hacking)
یک روش بسیار پیشرفتهتر، هک کردن وبسایتهای پربازدید و تزریق یک اسکریپت نامرئی (iframe یا JavaScript) است. این اسکریپت باعث میشود که مرورگر بازدیدکنندگان آن سایت، بدون اطلاع آنها، یک جستجو در گوگل انجام داده و روی سایت هدف کلیک کند.
مزیت این روش: از IPها و کوکیهای کاربران واقعی و معتبر سوءاستفاده میکند. این کاربران تاریخچه جستجوی واقعی دارند و رفتارشان کاملاً طبیعی است.
چرا این روش هم محدودیت دارد و قابل شناسایی است؟
عدم تعامل پس از کلیک (No Post-Click Interaction): کلیک در پسزمینه انجام میشود و کاربر هیچ تعاملی با سایت هدف ندارد. Dwell Time نزدیک به صفر خواهد بود و هیچ حرکتی از موس یا اسکرول وجود ندارد. این یک سیگنال بسیار منفی و مشکوک است.
ناهنجاری در ارجاعدهنده (Referrer Anomaly): گوگل میتواند ببیند که حجم عظیمی از کلیکها برای یک کوئری خاص، از یک یا چند سایت ارجاعدهنده (که هک شدهاند) نشأت میگیرد. این الگو غیرطبیعی است.
شناسایی توسط ابزارهای امنیتی گوگل: ابزارهایی مانند Google Safe Browsing به طور مداوم وبسایتها را برای یافتن کدهای مخرب اسکن میکنند. دیر یا زود، سایت هک شده شناسایی و در لیست سیاه قرار میگیرد.
پیچیدگی و ریسک بالا: این یک فعالیت مجرمانه و بسیار پرریسک است که نیازمند مهارتهای هک پیشرفته است و پیامدهای قانونی سنگینی دارد.
نتیجهگیری:
امنیت این سیستم در رویکرد چندلایه و مبتنی بر آمار کلان آن نهفته است. یک مهاجم برای موفقیت باید تمام لایههای دفاعی را همزمان دور بزند، که تقریباً غیرممکن است:
سطح فردی (Individual Level): باید رفتار یک انسان را به دقت تقلید کند (حرکت موس، Dwell Time).
سطح پروفایل (Profile Level): باید یک تاریخچه کوکی و حساب کاربری معتبر و طولانی داشته باشد.
سطح شبکه (Network Level): باید از IPهای مسکونی متنوع و غیرمرتبط استفاده کند.
سطح جمعیتی (Demographic Level): باید رفتار گروهی منطقی و از نظر جغرافیایی قابل توجیه از خود نشان دهد.
سطح زمانی (Temporal Level): باید فعالیت خود را در یک بازه زمانی طولانی و طبیعی پخش کند، نه به صورت یک انفجار ناگهانی.
فریب دادن یک یا دو مورد از این لایهها ممکن است امکانپذیر باشد، اما فریب دادن همه آنها در مقیاس بزرگ نیازمند منابعی است که احتمالاً از خود گوگل کمتر نیست. بنابراین، هرگونه تلاش برای دستکاری انبوه، الگوهای آماری غیرعادی ایجاد میکند که توسط الگوریتمهای یادگیری ماشین گوگل شناسایی میشوند.
مطلبی دیگر از این انتشارات
روشهای تشخیص لینک اسپم در پایگاههای داده ابرپیوند با تحلیل گراف جهتدار
مطلبی دیگر از این انتشارات
تحلیل الگوریتم گوگل ساجست : معماری پردازش پیشنهادات تکمیل خودکار
مطلبی دیگر از این انتشارات
شناسایی اسناد اسپم در یک سیستم بازیابی اطلاعات مبتنی بر عبارات