
پژوهشگر، تمرکز بر روی سئو و پردازش زبان طبیعی
شناسایی اسناد اسپم در یک سیستم بازیابی اطلاعات مبتنی بر عبارات
پیش زمینه
سیستمهای بازیابی اطلاعات که در حال حاضر به طور گسترده در موتورهای جستجو و سایر سیستمهای مشابه استفاده میشوند، نقش مهمی در جستجو و بازیابی دادهها از مجموعههای وسیع اطلاعاتی دارند. این سیستمها معمولاً از کلمات کلیدی برای ایندکس کردن و بازیابی اسناد استفاده میکنند. با این حال، استفاده تنها از کلمات به عنوان واحد ایندکس به ویژه در مواجهه با جملات یا عبارات پیچیدهتر، ممکن است منجر به عدم دقت در بازیابی اطلاعات شود. در این راستا، سیستمهای مبتنی بر عبارات (Phrases) به عنوان جایگزینی برای کلمات کلیدی به کار گرفته شدهاند. این روش به سیستمها اجازه میدهد تا ترکیبهای معنایی و مفهومی بهتری از متن را درک کنند و نتایج جستجو را بهبود بخشند.
با این وجود، مشکل دیگری که در کنار استفاده از سیستمهای بازیابی اطلاعات مبتنی بر عبارات مطرح میشود، پدیدهای به نام (Spam Documents) است. اسناد اسپم، اسنادی هستند که به صورت عمدی با استفاده از ترکیبهای رایج و عبارات محبوب ایجاد میشوند تا در نتایج جستجو جایگاه بالاتری کسب کنند، بدون آنکه محتوای معتبر و مفیدی ارائه دهند. این اسناد معمولاً تکرار زیادی از عبارات مشابه دارند و به گونهای طراحی شدهاند که موتورهای جستجو را فریب دهند، در حالی که اغلب هیچ ارتباط واقعی با جستجوی کاربر ندارند. شناسایی و فیلتر کردن این اسناد اسپم یکی از چالشهای عمده در سیستمهای بازیابی اطلاعات مدرن است.
در این مقاله، ما به بررسی یک روش جدید برای شناسایی اسناد اسپم در یک سیستم بازیابی اطلاعات مبتنی بر عبارات میپردازیم. این روش به شناسایی عبارات خاصی میپردازد که میتوانند پیشبینیکننده وجود عبارات مرتبط دیگر در یک سند باشند. اسناد بر اساس تعداد این عبارات مرتبط در آنها ایندکس میشوند و در نهایت با تحلیل و شناسایی ارتباطات غیرمعمول یا زیاد از حد میان عبارات مختلف، اسناد اسپم شناسایی میشوند. این رویکرد میتواند به طور موثری کیفیت نتایج جستجو را ارتقا دهد و تجربه کاربری بهتری را در سیستمهای بازیابی اطلاعات فراهم سازد.
این پتنت به GOOGLE LLC اختصاص داده شده است.
https://patents.google.com/patent/US8078629B2/en:
Detecting spam documents in a phrase based information retrieval system
2009-10-13 Application filed by Google LLC | 2026-06-28 Adjusted expiration
خلاصهای از پتنت
این پتنت ، یک سیستم و روش جدید بازیابی اطلاعات ارائه میدهد که از عبارات (Phrases) برای ایندکس کردن، جستجو، رتبهبندی و توصیف اسناد استفاده میکند. این سیستم قادر است عبارات معنادار و معتبر را که به اندازه کافی در اسناد تکرار شدهاند یا استفاده متمایزی دارند، شناسایی کند. به این ترتیب، میتوان عبارات چند کلمهای (چهار، پنج یا بیشتر) را شناسایی کند، بدون اینکه نیاز باشد تمام ترکیبهای ممکن از کلمات را بررسی کند.
این سیستم همچنین میتواند عبارات مرتبط را شناسایی کند. به عنوان مثال، اگر عبارت "رئیسجمهور ایالات متحده" در یک سند وجود داشته باشد، احتمالاً عبارت "کاخ سفید" نیز در همان سند خواهد بود. این ارتباط بر اساس یک معیار پیشبینیشده اندازهگیری میشود که میزان همزمان بودن دو عبارت را بررسی میکند.
علاوه بر این، سیستم میتواند اسناد اسپم را شناسایی کند، زیرا این اسناد معمولاً تعداد زیادی عبارات مرتبط را به صورت مصنوعی در خود جای میدهند.
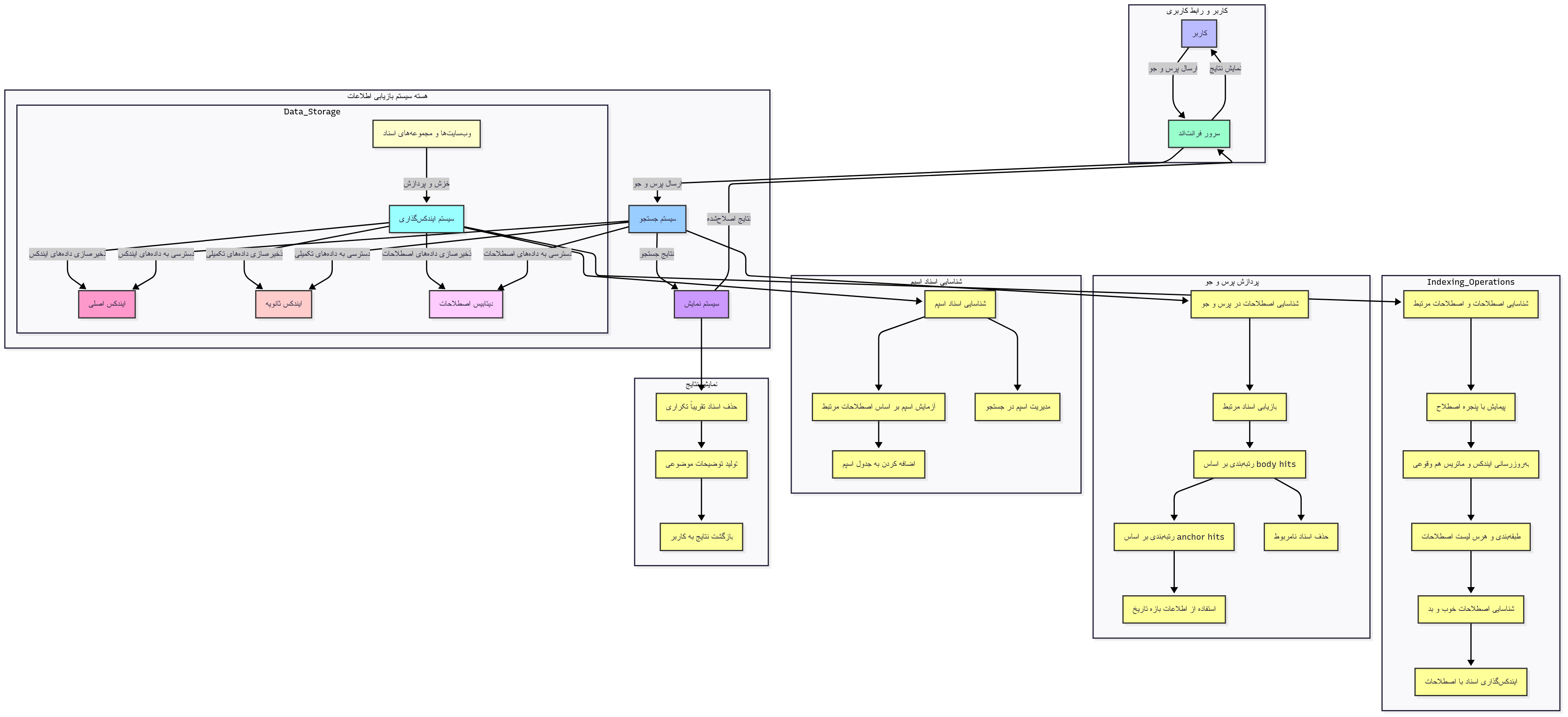
اجزای اصلی سیستم
سیستم فهرستگذاری (Indexing System):
مسئول شناسایی و فهرستگذاری عبارتها در اسناد.
این سیستم عبارتها را از اسناد مختلف جمعآوری کرده و اسناد را بر اساس این عبارات فهرست میکند.
دسترسی به وبسایتها و مجموعههای اسنادی برای این کار دارد.
سیستم جستجو (Search System):
مسئول دریافت پرسوجوها از کاربران و جستجو در فهرستها برای یافتن اسناد مرتبط.
عبارات موجود در پرسوجو را شناسایی کرده و اسناد را بر اساس تطابق عبارات رتبهبندی میکند.
سیستم نمایش (Presentation System):
نتایج جستجو را اصلاح کرده و به کاربران ارائه میدهد.
شامل حذف اسناد تکراری و تولید توضیحات برای اسناد.
سرور فرانتاند (Front-End Server):
دریافت پرسوجوها از کاربران و ارسال نتایج جستجو به کاربر.
فهرست اصلی و ثانویه (Primary and Secondary Indexes):
فهرست اصلی: ذخیره اطلاعات فهرستگذاری مربوط به اسناد.
فهرست ثانویه: برای ذخیرهسازی اطلاعات اضافی و پشتیبانی از عملکرد سیستم.
هر دو فهرست به صورت توزیعشده روی چندین سرور قرار دارند.
ذخیرهسازی دادههای عبارت (Phrase Data Store):
اطلاعات آماری مرتبط با عبارتها را ذخیره میکند.
این دادهها برای شناسایی عبارات مرتبط و رتبهبندی اسناد استفاده میشود.
سیستم شناسایی عبارتها (Phrase Identification System):
سیستم جستجو و شناسایی عبارتها در اسناد از طریق یک پنجره عبارت (phrase window).
عبارات ممکن و خوب را شناسایی و بر اساس فراوانی و همرخدادی طبقهبندی میکند.
عبارات خوب با استفاده از معیارهایی مانند فراوانی و رخدادهای جالب طبقهبندی میشوند.
سیستم تشخیص اسناد اسپم (Spam Detection System):
شناسایی اسناد اسپم بر اساس تعداد زیاد عبارتهای مرتبط.
اسناد اسپم شناسایی شده از نتایج جستجو حذف یا امتیاز آنها کاهش مییابد.
ماتریس همرخدادی (Co-occurrence Matrix):
نگهداری اطلاعات همرخدادی بین عبارات برای شناسایی روابط معنایی و ایجاد خوشههای مرتبط.
استفاده از معیار "افزایش اطلاعات" برای شناسایی عبارات مرتبط و خوشهها.
سیستم خوشهبندی عبارتها (Clustering System):
شناسایی خوشههای عبارتهای مرتبط بر اساس میزان افزایش اطلاعات.
خوشهها به گروههایی از عبارتهای مرتبط با مفاهیم مشابه تقسیم میشوند.
سیستم پُستینگ (Posting System):
برای هر عبارت خوب شناساییشده در اسناد، شناسه سند به لیست پُستینگ آن عبارت اضافه میشود.
اطلاعات پُستینگ شامل شناسه سند، شمارش رخدادها و بردار بیت برای عبارات مرتبط است.
سیستم بهینهسازی جستجو (Search Optimization System):
در زمان جستجو، لیستهای پُستینگ بر اساس عبارتهای پرسوجو مرتب شده و اسناد بر اساس آنها رتبهبندی میشوند.
استفاده از ویژگیهای اطلاعاتی برای مرتبسازی نتایج جستجو.
نکات مهم برای سئوکاران
در این بخش به صورت دقیق و عملی نکاتی را که برای موفقیت در بهینهسازی موتورهای جستجو (SEO) بر اساس سیستم بازیابی اطلاعات مبتنی بر عبارتها (Phrase-Based Information Retrieval System) حیاتی هستند، توضیح خواهیم داد.
۱. درک سیستم بازیابی اطلاعات مبتنی بر عبارتها
برخلاف سیستمهای سنتی که بر کلمات کلیدی تمرکز داشتند، این سیستم بر مفاهیم و عبارتهای طبیعی تمرکز میکند.
عبارتها شامل کلمات توقف (مانند "و"، "از"، "به") میشوند و درک معنایی را بهبود میدهند.
اقدام عملی:
محتوای خود را با توجه به عبارتهای طبیعی و مفاهیم مرتبط بهینه کنید.
روی عبارتهایی که کاربران به طور طبیعی استفاده میکنند، تمرکز کنید.
۲. شناسایی عبارتهای "خوب" و "مرتبط"
عبارتهای "خوب" عبارتهایی هستند که در متن به طور برجسته ظاهر میشوند، مثل:
مواردی که bold یا underline شدهاند.
متن Anchor در لینکها.
عبارتهای "مرتبط" از طریق هموقوعی زیاد با عبارتهای اصلی شناسایی میشوند.
اقدام عملی:
از عبارتهای کلیدی مرتبط و مفاهیم همبسته در محتوای خود استفاده کنید.
با فرمتبندی مناسب (مثل bold یا italic) عبارتهای مهم را برجسته کنید.
۳. تولید محتوای جامع و متمرکز
سیستم از خوشهها (clusters) برای شناسایی موضوعات اصلی و فرعی استفاده میکند.
محتوای متمرکز بر یک موضوع و پوشش عمیق آن، ارزش بیشتری دارد.
اسناد با موضوعات پراکنده (بیش از دو خوشه) ممکن است حذف شوند.
اقدام عملی:
روی یک موضوع خاص تمرکز کنید و آن را به طور جامع پوشش دهید.
تعداد محدودی از موضوعات مرتبط را در هر صفحه استفاده کنید.
۴. جلوگیری از اسپم و محتوای بیکیفیت
keyword stuffing (پر کردن بیرویه کلمات کلیدی) باعث کاهش رتبه یا حذف محتوا میشود.
سندهای اسپم معمولاً تعداد زیادی عبارت مرتبط غیرطبیعی دارند.
اقدام عملی:
از تکرار غیرطبیعی کلمات کلیدی اجتناب کنید.
محتوای ارزشمند و طبیعی تولید کنید که نیاز کاربر را برطرف کند.
۵. اهمیت متن Anchor و لینکها
متن Anchor مناسب تأثیر زیادی در رتبهبندی دارد.
"مولفه امتیاز ورودی" و "مولفه امتیاز خروجی" توسط موتورهای جستجو ارزیابی میشوند.
اقدام عملی:
از متن Anchor توصیفی و مرتبط برای لینکها استفاده کنید.
بکلینکهای باکیفیت از منابع معتبر دریافت کنید.
۶. تازگی محتوا و تاریخ بهروزرسانی
موتورهای جستجو محتوای تازه و بهروزرسانی شده را ترجیح میدهند.
تاریخ انتشار و بهروزرسانی محتوا بر رتبهبندی تأثیرگذار است.
اقدام عملی:
محتوای خود را به طور منظم بهروزرسانی کنید.
در موضوعات حساس به زمان، تاریخ انتشار و آپدیت را مشخص کنید.
جزئیات کامل سیستم
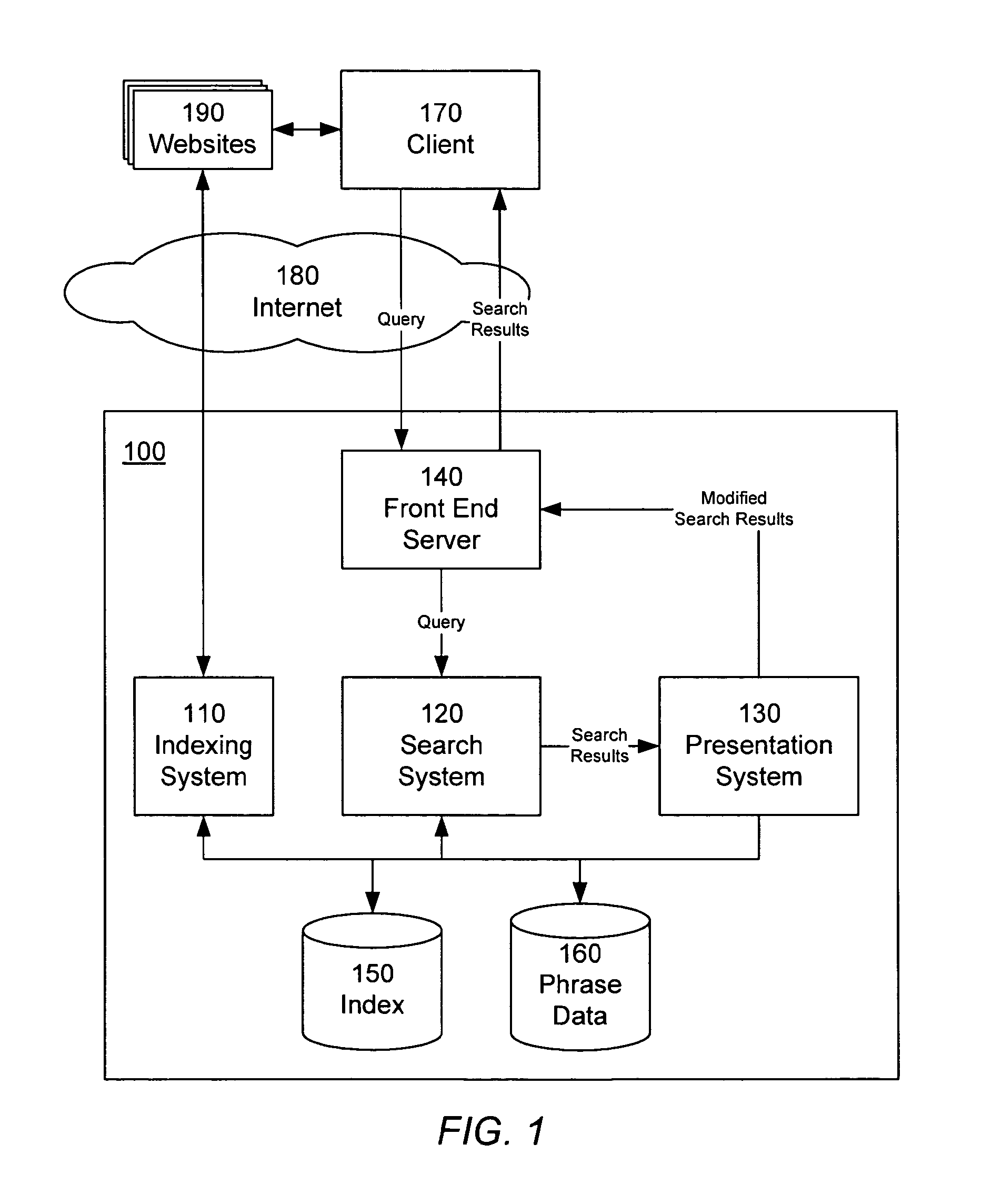
این شکل نمودار بلوکی معماری نرمافزاری یک سیستم جستجو (search system 100) را نشان میدهد. اجزای اصلی این سیستم عبارتند از:
سیستم فهرستگذاری (Indexing system 110): مسئول شناسایی عبارتها در اسناد و فهرستگذاری اسناد بر اساس این عبارتها است. این سیستم با دسترسی به وبسایتهای مختلف (various websites 190) و سایر مجموعههای اسناد این کار را انجام میدهد.
سیستم جستجو (Search system 120): وظیفه دریافت پرسوجوها از کاربر (client 170) از طریق سرور جلویی (front end server 140) را دارد. این سیستم اسناد مرتبط با پرسوجو را پیدا میکند، هر عبارتی در پرسوجو را شناسایی میکند و سپس اسناد را بر اساس حضور عبارتها رتبهبندی میکند. نتایج جستجو را به سیستم نمایش (presentation system 130) ارسال میکند.
سیستم نمایش (Presentation system 130): مسئول اصلاح نتایج جستجو است، از جمله حذف اسناد نزدیک به تکراری و تولید توضیحات موضوعی برای اسناد. سپس نتایج اصلاحشده را به سرور جلویی (front end server 140) برمیگرداند.
سرور جلویی (Front end server 140): پرسوجوها را از کاربر دریافت میکند و نتایج جستجو را به کاربر ارائه میدهد.
فهرست اصلی (Primary index 150) و فهرست ثانویه (secondary index 152): این دو اطلاعات فهرستگذاری مربوط به اسناد را ذخیره میکنند. هر دو فهرست به صورت توزیعشده روی چندین سرور قرار دارند.
ذخیرهسازی دادههای عبارت (Phrase data store 160): عبارتها و اطلاعات آماری مرتبط را ذخیره میکند.
این سیستم از عبارتها برای فهرستگذاری، جستجو، رتبهبندی و توصیف اسناد در یک مجموعه بزرگ (مانند اینترنت) استفاده میکند.
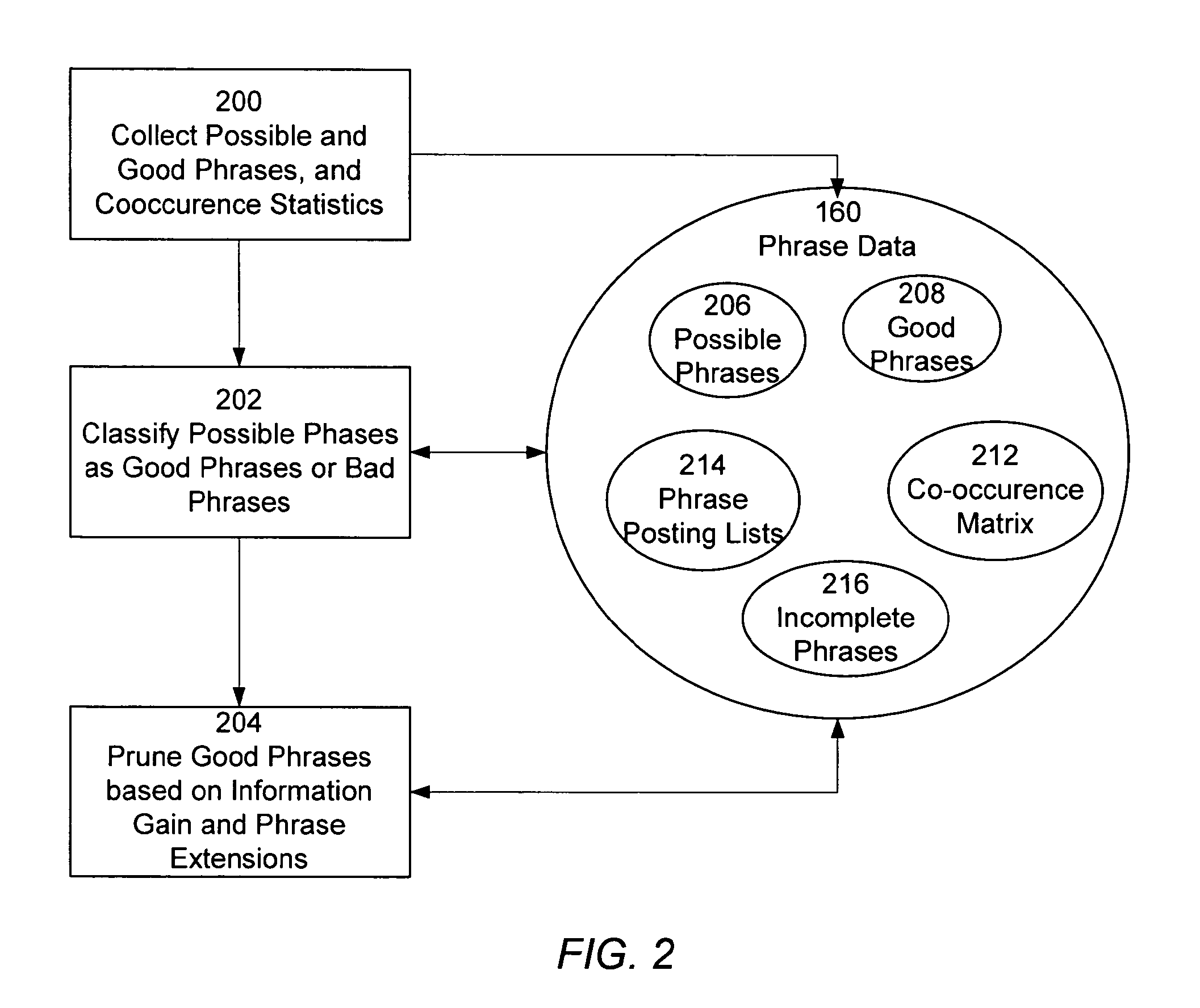
این شکل مراحل عملیاتی فرآیند شناسایی عبارت را نشان میدهد. این فرآیند شامل سه مرحله اصلی است:
مرحله ۲۰۰: جمعآوری عبارتهای ممکن و خوب، همراه با آمار فراوانی و همرخدادی آنها.
در این مرحله، سیستم فهرستگذاری (110) مجموعهای از اسناد را در مجموعه اسناد خزش (crawls) میکند و این کار را در بخشهای مکرر در طول زمان انجام میدهد.
برای هر سند، کلمات با استفاده از یک پنجره عبارت (phrase window) با طول حداکثر (مثلاً ۴ یا ۵ کلمه) پیمایش میشوند.
عبارتهای کاندیدا (candidate phrases) شناسایی میشوند و بررسی میشوند که آیا در «لیست عبارتهای خوب (good phrase list 208)» یا «لیست عبارتهای ممکن (possible phrase list 206)» حضور دارند یا خیر. اگر در لیست عبارتهای خوب باشند، شناسه سند به لیست پُستینگ (posting list) آن عبارت در فهرست 150 اضافه میشود.
علاوه بر این، ماتریس همرخدادی (co-occurrence matrix 212) نیز برای عبارتهای خوب بهروزرسانی میشود.
مرحله ۲۰۲: طبقهبندی عبارتهای ممکن به عبارتهای خوب یا بد بر اساس آمار فراوانی.
عبارتهای ممکن از لیست عبارتهای ممکن (206) به لیست عبارتهای خوب (208) منتقل میشوند اگر فراوانی و تعداد اسنادی که عبارت در آنها ظاهر میشود، نشاندهنده استفاده معنیدار معنایی باشد.
معیارهایی مانند تعداد اسناد حاوی عبارت (P(p)) و تعداد رخدادهای جالب (M(p)) (مثلاً در بولد، زیرخط یا متن لنگر) برای تعیین این طبقهبندی استفاده میشوند.
عبارتهای با فراوانی بسیار کم یا بدون رخدادهای جالب به عنوان عبارتهای بد شناسایی میشوند.
مرحله ۲۰۴: هرس کردن لیست عبارتهای خوب بر اساس یک معیار پیشبینیکننده مشتق شده از آمار همرخدادی.
این مرحله عبارتهای خوبی را که به اندازه کافی پیشبینیکننده حضور عبارتهای دیگر نیستند یا زیردنبالهای از عبارتهای بلندتر هستند، حذف میکند.
معیار "افزایش اطلاعات" (information gain) برای این منظور استفاده میشود که نشاندهنده افزایش احتمال ظاهر شدن یک عبارت در سند، با توجه به حضور عبارت دیگر است.
عبارتهای ناکامل (incomplete phrases) که فقط عبارتهای توسعهیافته (phrase extensions) خود را پیشبینی میکنند، از لیست عبارتهای خوب حذف شده و به یک لیست عبارتهای ناکامل (incomplete phrase list 216) اضافه میشوند. این لیست برای پیشنهاد جستجو به کاربر مفید است.

این شکل یک بخش از یک سند (300) را در حین پیمایش نشان میدهد که پنجره عبارت (phrase window 302) و یک پنجره ثانویه (secondary window 304) را به تصویر میکشد.
پنجره عبارت (302):
این پنجره بر روی کلمات سند حرکت میکند و طول آن حداکثر N کلمه است (مثلاً 5 کلمه).
تمام کلمات درون این پنجره، از جمله کلمات توقف (stop words) مانند "a" یا "the"، به عنوان بخشی از عبارت در نظر گرفته میشوند.
پنجره میتواند با نشانههایی مانند پایان خط، پاراگراف جدید یا تگهای HTML پایان یابد که نشاندهنده تغییر محتوا یا قالب هستند.
هر دنبالهای از کلمات درون این پنجره به عنوان یک عبارت کاندیدا (candidate phrase) در نظر گرفته میشود. به عنوان مثال، اگر پنجره روی "stock dogs for the Basque shepherds" باشد، عبارتهای کاندیدا شامل "stock"، "stock dogs" و... میشوند.
هنگامی که یک عبارت کاندیدا در لیست عبارتهای خوب (good phrase list 208) یافت میشود، شناسه سند (URL یا شماره سند) به لیست پُستینگ (posting list) آن عبارت در فهرست اصلی (index 150) اضافه میشود.
پنجره ثانویه (304):
این پنجره در اطراف کلمه فعلی در سند قرار میگیرد و به اندازه مشخصی (مثلاً ۳۰ کلمه) به چپ و راست گسترش مییابد.
هدف اصلی آن، بهروزرسانی ماتریس همرخدادی (co-occurrence matrix 212) برای عبارتهای خوب است.
این ماتریس سه نوع شمارش را برای هر جفت عبارت خوب (gj, gk) که در پنجره ثانویه با هم ظاهر میشوند، حفظ میکند:
R(j,k): تعداد دفعات همرخدادی خام (raw co-occurrence count).
D(j,k): تعداد دفعات رخداد جالب به صورت مجزا (disjunctive interesting count)، یعنی هر یک از عبارتها به صورت متن متمایز (مثلاً بولد) ظاهر شود.
C(j,k): تعداد دفعات رخداد جالب به صورت مشترک (conjunctive interesting count)، یعنی هر دو عبارت به صورت متن متمایز ظاهر شوند. این شمارش به ویژه برای اجتناب از عبارتهای غیرپیشبینیکننده (مانند اطلاعرسانیهای حق نشر در پاورقیها) مفید است.
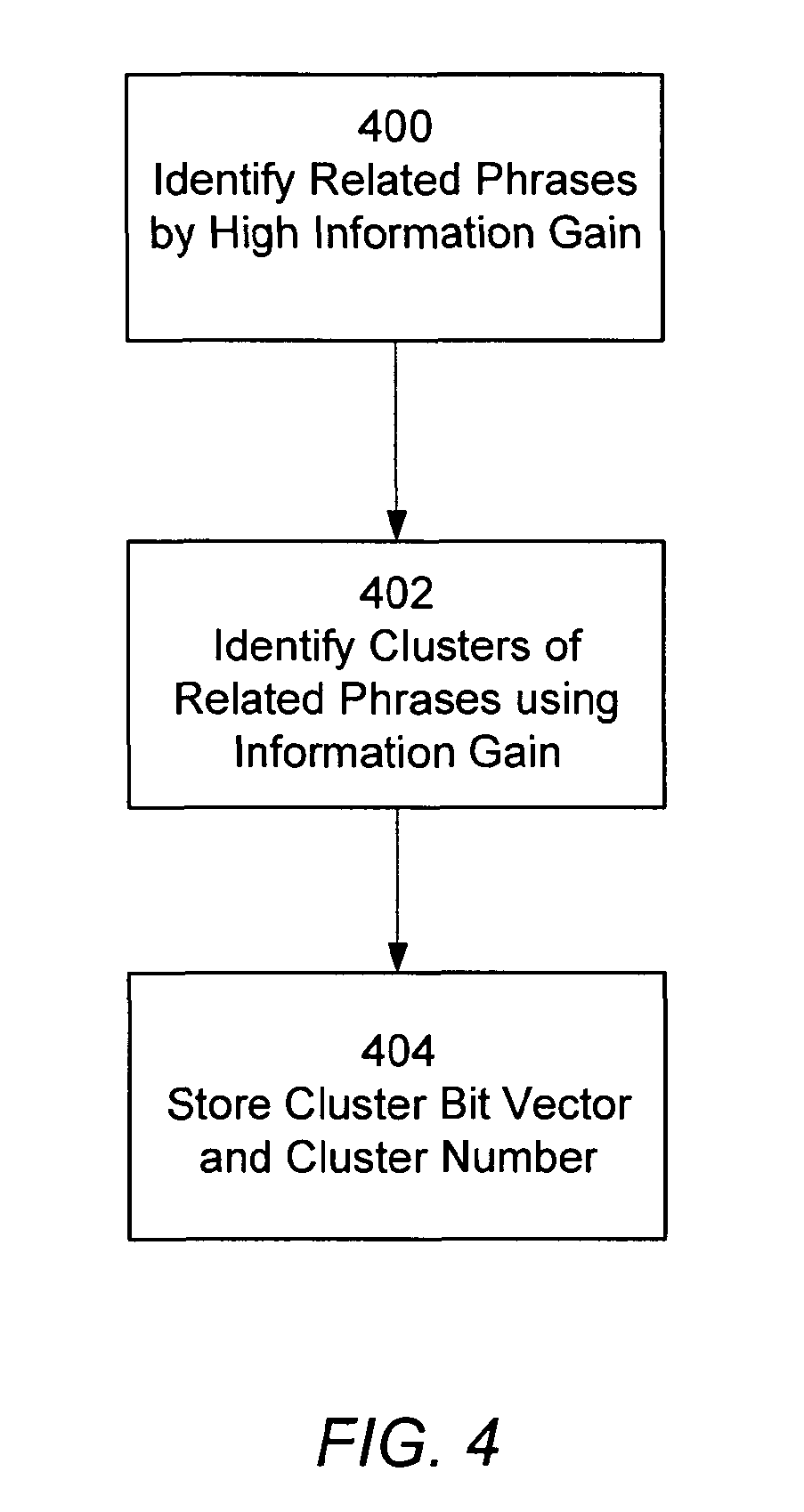
این شکل مراحل عملیاتی برای شناسایی عبارتهای مرتبط و خوشههای (clusters) آنها را توضیح میدهد.
مرحله ۴۰۰: شناسایی عبارتهای مرتبط با مقدار افزایش اطلاعات (information gain) بالا.
سیستم از ماتریس همرخدادی (co-occurrence matrix 212) استفاده میکند که حاوی عبارتهای خوب است.
برای هر جفت عبارت خوب (gj, gk)، میزان افزایش اطلاعات (I(j,k)) محاسبه میشود. این معیار نسبت نرخ همرخدادی واقعی به نرخ همرخدادی مورد انتظار است.
دو عبارت (gj, gk) "مرتبط" (related) نامیده میشوند اگر I(j,k) از یک آستانه عبارت مرتبط (Related Phrase threshold) بالا (مثلاً 100) فراتر رود. این به این معنی است که عبارتها ۱۰۰ برابر بیشتر از نرخ آماری مورد انتظار با هم ظاهر میشوند.
ورودیهای زیر این آستانه در ماتریس صفر میشوند و تنها عبارتهای مرتبط باقی میمانند.
سپس، عبارتهای مرتبط برای هر عبارت خوب (gj) بر اساس مقادیر افزایش اطلاعات آنها مرتب میشوند، به طوری که مرتبطترین عبارتها ابتدا فهرست شوند.
مرحله ۴۰۲: شناسایی خوشههای عبارتهای مرتبط.
یک خوشه مجموعهای از عبارتهای مرتبط است که در آن هر عبارت نسبت به حداقل یک عبارت دیگر افزایش اطلاعات بالایی دارد.
سیستم افزایش اطلاعات بین هر جفت عبارت در مجموعه عبارتهای مرتبط (Rj) یک عبارت خوب (gj) را ارزیابی میکند تا عضویت در خوشه را تعیین کند. به عنوان مثال، "بیل کلینتون"، "رئیسجمهور" و "مونیکا لوینسکی" میتوانند یک خوشه تشکیل دهند.
مرحله ۴۰۴: ذخیره بردار بیت خوشه (cluster bit vector) و شماره خوشه.
هر خوشه یک شناسه خوشه (cluster ID) منحصر به فرد دریافت میکند.
یک بردار بیت خوشه برای هر عبارت خوب (gj) ایجاد میشود که نشان میدهد کدام یک از عبارتهای مرتبط آن (gk) در همان خوشه با gj قرار دارند (یعنی افزایش اطلاعات دوطرفه وجود دارد).
مقدار این رشته بیت، شماره خوشه است.
این اطلاعات، از جمله مقدار افزایش اطلاعات، شماره خوشه و بردار بیت خوشه، میتواند در ماتریس همرخدادی یا مستقیماً در لیست عبارتهای خوب ذخیره شود. نتیجه این فرآیند، شناسایی قوی عبارتهای مهم و نحوه استفاده طبیعی آنها در "خوشهها" است که بازتابدهنده مفاهیم و ایدههای معنایی مورد استفاده در مجموعه اسناد است. این رویکرد دادهمحور، تعصبات انتخاب دستی عبارتها و مفاهیم را از بین میبرد.
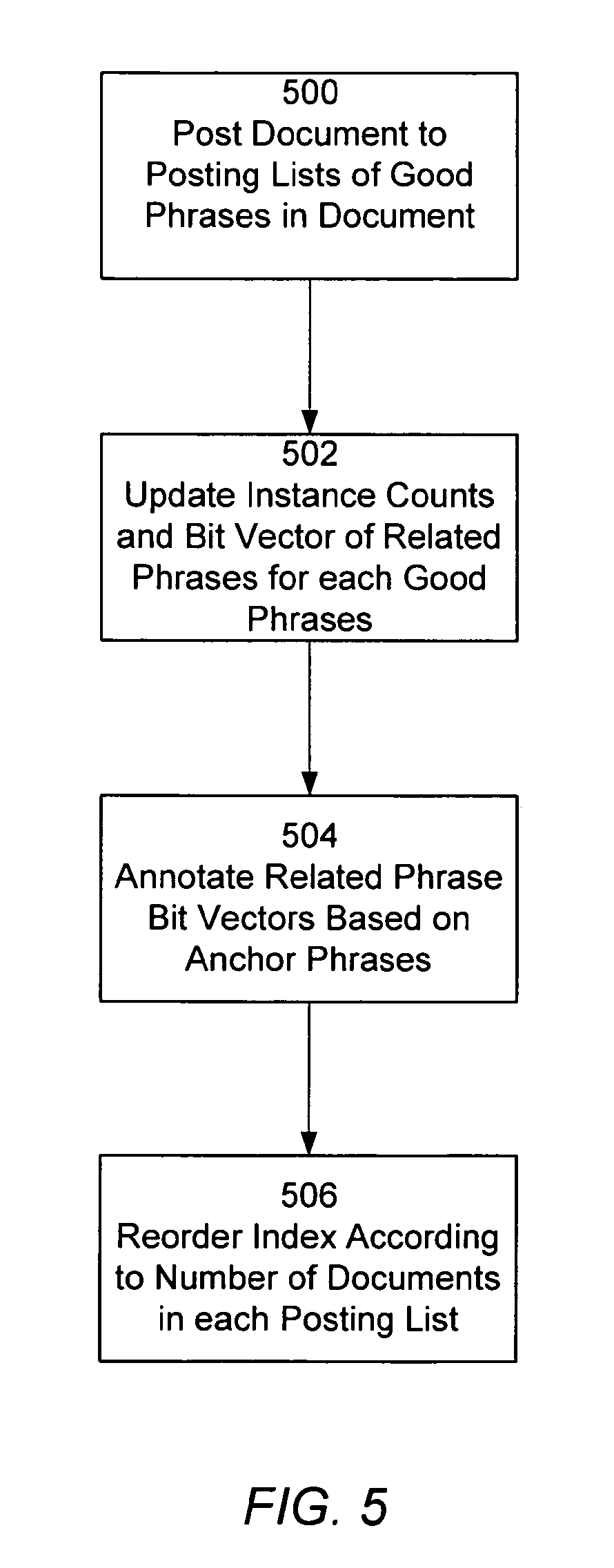
این شکل مراحل عملیاتی برای فهرستگذاری اسناد با توجه به عبارتهای خوب و خوشههای آنها را نشان میدهد.
مرحله ۵۰۰: پُست کردن سند به لیستهای پُستینگ عبارتهای خوب موجود در سند.
سیستم سند را کلمه به کلمه پیمایش میکند و عبارتهای خوبی را که در پنجره عبارت (phrase window 302) یافت میشوند، شناسایی میکند.
برای هر عبارت خوب شناساییشده (مانند "President" یا "President of ATT")، شناسه سند (مثلاً URL) به لیست پُستینگ (posting list) آن عبارت در فهرست (index 150) اضافه میشود.
ورودی لیست پُستینگ برای یک عبارت شامل شناسه سند، لیستی از شمارشهای عبارتهای مرتبط و یک بردار بیت عبارت مرتبط (related phrase bit vector) است. این بردار بیت دارای دو موقعیت بیت برای هر عبارت مرتبط (bi-bit vector) است: یکی برای حضور عبارت مرتبط و دیگری برای حضور عبارتهای مرتبط ثانویه آن.
مرحله ۵۰۲: بهروزرسانی شمارش رخدادها و بردار بیت عبارت مرتبط برای عبارتهای مرتبط و عبارتهای مرتبط ثانویه.
سیستم در پنجره ثانویه (secondary window 304) در اطراف موقعیت فعلی در سند، به دنبال عبارتهای مرتبط (gk) عبارت اصلی (gi) میگردد.
اگر یک عبارت مرتبط در پنجره ثانویه یافت شود، شمارش آن برای سند جاری افزایش مییابد.
اولین بیت در بردار بیت عبارت مرتبط (gk-1) بر اساس حضور عبارت مرتبط تنظیم میشود (۱ اگر موجود باشد، ۰ اگر نباشد).
دومین بیت (gk-2) اگر هر یک از "عبارتهای مرتبط ثانویه" (secondary related phrases) (یعنی عبارتهای مرتبط با gk) نیز در سند موجود باشند، تنظیم میشود.
این فرآیند به سیستم کمک میکند تا برای هر عبارت خوب در یک سند، حضور عبارتهای مرتبط و عبارتهای مرتبط ثانویه را ثبت کند.
مرحله ۵۰۴: مرتبسازی مجدد ورودیهای فهرست بر اساس اندازه لیست پُستینگ.
عبارتها در فهرست 150 بر اساس فراوانی رخداد آنها در مجموعه اسناد شمارهگذاری میشوند (عبارتهای رایجتر، شماره کمتری میگیرند).
سپس، تمام لیستهای پُستینگ (posting lists 214) در فهرست اصلی (150) به ترتیب نزولی تعداد اسناد موجود در هر لیست مرتب میشوند، به طوری که رایجترین عبارتها ابتدا قرار بگیرند.
مرحله ۵۰۶: رتبهبندی ورودیهای فهرست در هر لیست پُستینگ بر اساس امتیاز یا ویژگی بازیابی اطلاعات.
هر سند در لیست پُستینگ بر اساس ارتباطش با عبارت، امتیاز بازیابی اطلاعات (IR-type score) دریافت میکند (مثلاً بر اساس الگوریتم PageRank، تعداد لینکهای ورودی و خروجی، و طول سند).
اسناد در لیست پُستینگ به ترتیب نزولی این امتیاز رتبهبندی میشوند، که این پیشرتبهبندی (pre-ranking) به بهبود عملکرد بازیابی اسناد در پاسخ به جستجو کمک میکند.
مرحله ۵۰۸: تقسیمبندی هر لیست پُستینگ بین سرور اصلی (primary server 150) و یک سرور ثانویه (secondary server 152).
ورودیهای لیست پُستینگ برای اولین K سند (مثلاً ۳۲,۷۶۸) در سرور اصلی باقی میمانند (لیست پُستینگ اصلی).
ورودیهای باقیمانده (n>K) به فهرست ثانویه (secondary index 152) منتقل میشوند (لیست پُستینگ ثانویه).
این تقسیمبندی به کاهش فضای ذخیرهسازی و افزایش قابل توجه تعداد اسناد قابل فهرستگذاری کمک میکند، زیرا اطلاعات رتبهبندی فقط برای اسناد رتبهبالا در فهرست اصلی ذخیره میشود.
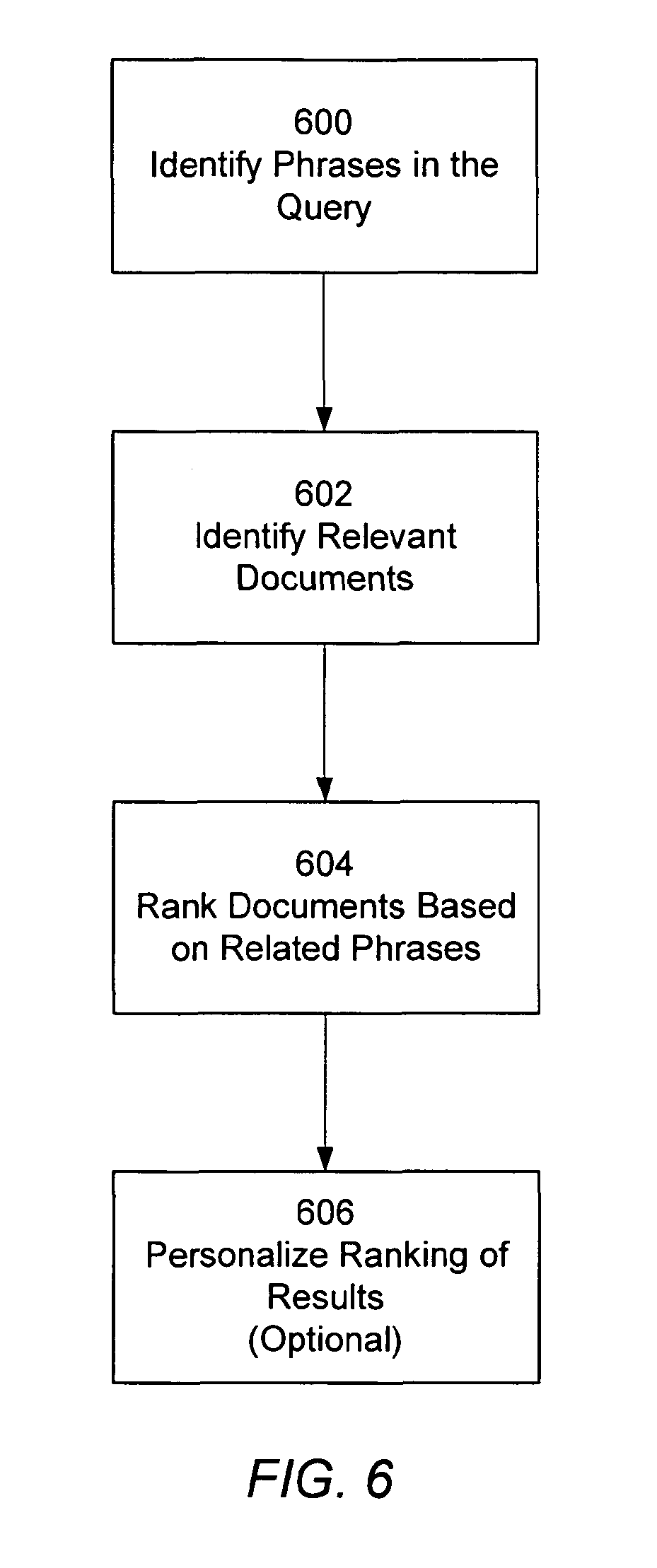
این شکل عملیات اصلی سیستم جستجو (search system 120) را نشان میدهد.
مرحله ۶۰۰: شناسایی عبارتها در پرسوجو (Query).
یک پنجره عبارت با اندازه N (مثلاً ۵) برای پیمایش کلمات پرسوجو (q) استفاده میشود.
عبارتهای ممکن در پنجره در لیست عبارتهای خوب (good phrase list 208) جستجو میشوند تا عبارتهای کاندیدا (candidate phrases) شناسایی شوند.
سیستم عبارتهای کاندیدا را مرتب میکند و عبارتهای پرسوجوی معتبر (valid query phrases - Qp) را انتخاب میکند.
همچنین، عبارتهای توسعهیافته (phrase extensions - Qe) برای Qp از طریق لیست عبارتهای ناکامل (incomplete phrase list 216) شناسایی میشوند.
مجموعه نهایی عبارتهای جستجو (Q) که شامل Qp و عبارتهای مرتبط با آن (Qr) است، تشکیل میشود.
مرحله ۶۰۲: بازیابی اسناد مرتبط با عبارتهای پرسوجو.
سیستم جستجو (120) لیستهای پُستینگ عبارتهای پرسوجو (Q) را بازیابی میکند و برای یافتن اسنادی که شامل همه (یا تعدادی) از این عبارتها هستند، آنها را اشتراک (intersect) میدهد.
عملیات اشتراک بر اساس اینکه عبارتهای پرسوجو "رایج" (common) یا "نادر" (rare) هستند (یعنی لیست پُستینگ آنها چگونه بین فهرست اصلی و ثانویه تقسیم شده است) بهینهسازی میشود.
مرحله ۶۰۴: رتبهبندی اسناد در نتایج جستجو بر اساس عبارتها.
اسناد در نتایج جستجو با استفاده از اطلاعات ارتباطی، ویژگیهای سند، و اطلاعات عبارتها (بردار بیت عبارت مرتبط و بردار بیت خوشه برای عبارتهای پرسوجو) رتبهبندی میشوند. این روش به عنوان "hitهای بدنه (body hits)" شناخته میشود.
هرچه یک سند عبارتهای مرتبط و عبارتهای مرتبط ثانویه بیشتری با عبارتهای پرسوجو داشته باشد، بردار بیت عبارت مرتبط آن دارای ارزش عددی بالاتری خواهد بود و در نتیجه، سند رتبه بالاتری در نتایج جستجو کسب میکند.
یک روش دیگر رتبهبندی این است که به هر عبارت مرتبط پرسوجو (Qr) بر اساس افزایش اطلاعات آن از پرسوجو (Q) امتیاز اختصاص داده میشود (مثلاً از N امتیاز برای مرتبطترین تا ۱ امتیاز برای کممرتبطترین). سپس اسناد بر اساس مجموع امتیازات عبارتهای مرتبطی که در خود دارند، امتیازدهی و مرتب میشوند.
سیستم میتواند اسناد را از نتایج حذف کند (cull) اگر آنها بیش از حد از موضوع اصلی دور باشند یا تعداد زیادی خوشه (topic) متفاوت را پوشش دهند، زیرا کاربران معمولاً اسناد متمرکز بر یک موضوع واحد را ترجیح میدهند.
رتبهبندی میتواند شامل "امتیاز hit لنگر (anchor hit score)" نیز باشد که به حضور عبارتهای پرسوجو در متن لنگر لینکهایی که به سند اشاره میکنند، بستگی دارد. این امتیاز با "امتیاز hit بدنه" ترکیب میشود.
اطلاعات محدوده تاریخ (date range information) نیز میتواند در رتبهبندی استفاده شود. این اطلاعات میتواند برای فیلتر کردن جستجو بر اساس تاریخ، وزندهی امتیازات ارتباطی (مثلاً کاهش وزن اسناد قدیمیتر یا افزایش وزن اسناد جدیدتر یا اسناد مرتبط با یک رویداد تاریخی خاص) یا مرتبسازی نتایج (مثلاً گروهبندی زمانی) به کار رود.
شناسایی اسناد اسپم: در این سیستم، اسناد اسپم نیز شناسایی میشوند. یک سند اسپم با داشتن تعداد بیش از حد عبارتهای مرتبط (مثلاً ۱۰۰ تا ۱۰۰۰) در مقایسه با اسناد عادی (۸ تا ۲۰) مشخص میشود. اسناد اسپم شناساییشده به یک جدول اسپم (SPAM_TABLE) اضافه میشوند. هنگامی که نتایج جستجو بازیابی میشوند، اگر سندی در این جدول باشد، امتیاز ارتباطی آن کاهش مییابد (مثلاً به یک پنجم تقسیم میشود) یا به طور کلی از نتایج حذف میشود. سپس نتایج جستجو دوباره مرتب شده و به کاربر ارائه میشوند.
مطلبی دیگر از این انتشارات
روشهای تشخیص لینک اسپم در پایگاههای داده ابرپیوند با تحلیل گراف جهتدار
مطلبی دیگر از این انتشارات
تحلیل الگوریتم گوگل ساجست : معماری پردازش پیشنهادات تکمیل خودکار
مطلبی دیگر از این انتشارات
روش های شناسایی کلیک اسپم برای بهبود رتبهبندی در موتورهای جستجو