

مدرس آنالیزداده | یادگیری ماشین | یادگیری عمیق در مجتمع فنی تهران
فصل 1. سازماندهی داده ها: موقعیت ، دامنه ، عمل و اعتبار
تحلیل امنیتی فرآیند استفاده از دادهها برای تصمیمگیریهای امنیتی است. تصمیمات امنیتی معمولاً مخل و محدودکننده هستند—مخل به این دلیل که چیزی را اصلاح میکنید، و محدودکننده به این دلیل که رفتارها را محدود میکنید. تحلیل امنیتی مؤثر نیازمند اتخاذ تصمیم درست و متقاعد کردن مخاطبی شکاک به درستی این تصمیم است. پایههای این تصمیمات، دادههای باکیفیت و استدلال باکیفیت هستند؛ در این فصل به هر دو مورد پرداخته میشود.
نظارت امنیتی در شبکههای مدرن نیازمند کار با حسگرهای متعددی است که انواع مختلفی از دادهها را تولید میکنند و توسط افراد مختلف برای اهداف گوناگون ایجاد شدهاند. حسگر میتواند هر چیزی باشد، از یک دستگاه شنود شبکه تا گزارشهای فایروال؛ چیزی که اطلاعات شبکه شما را جمعآوری میکند و میتواند برای قضاوت درباره امنیت شبکه استفاده شود.
میخواهم نکتهای بسیار مهم را برجسته کنم: دادههای منبع باکیفیت برای تحلیل امنیتی خوب ضروری هستند. علاوه بر این، تلاش برای بهدست آوردن منبع دادهای باکیفیت و پایدار در ادامه فرآیند تحلیل نتیجه میدهد—میتوانید از الگوریتمهای سادهتر (و سریعتر) برای شناسایی پدیدهها استفاده کنید، تأیید نتایج آسانتر خواهد بود و زمان کمتری برای تطبیق و بررسی دوباره اطلاعات صرف خواهید کرد.
حالا که مشتاق جمعآوری دادههای باکیفیت هستید، سؤال واضحی پیش میآید: داده باکیفیت چیست؟ پاسخ این است که جمعآوری دادههای امنیتی یک تعادل بین بیانگری(expressiveness) و سرعت(speed) است—دادههای ضبط بسته (pcap) از یک پورت span میتوانند نشان دهند که آیا کسی در حال اسکن شبکه شما است، اما ترافیک غیرقابل خواندنی از سرور HTTPS که نظارت میکنید، چندین ترابایت تولید خواهد کرد. گزارشهای سرور HTTPS اطلاعاتی درباره دسترسی به فایلها ارائه میدهند، اما هیچ اطلاعاتی درباره تعاملات FTP ندارند. سؤالاتی که میپرسید نیز به موقعیت بستگی دارد—نحوه برخورد با یک تهدید مداوم پیشرفته (APT) به میزان ریسکی که با آن مواجه هستید بستگی دارد و این ریسک با زمان تغییر میکند.
با این حال، میتوانیم اهداف اساسی برای دادههای امنیتی تعیین کنیم. ما میخواهیم دادهها تا حد ممکن اطلاعات را با کمترین حجم بیان کنند—بنابراین دادهها باید در قالبی فشرده باشند و اگر حسگرهای مختلف یک رویداد را گزارش کنند، این توضیحات نباید زائد باشند. میخواهیم دادهها تا حد ممکن در زمان مشاهده دقیق باشند، بنابراین اطلاعاتی که گذرا هستند (مانند رابطه بین آدرسهای IP و نامهای دامنه) باید در زمان جمعآوری ثبت شوند. همچنین میخواهیم دادهها بیانگر باشند؛ یعنی زمان و تلاشی که تحلیلگر برای تطبیق اطلاعات صرف میکند، کاهش یابد. در نهایت، میخواهیم هرگونه استنباط یا تصمیم در دادهها قابل پاسخگویی باشد؛ برای مثال، اگر هشداری به دلیل یک قاعده ایجاد شود، میخواهیم تاریخچه و منشأ آن قاعده را بدانیم.
اگرچه نمیتوانیم برای همه این معیارها بهینهسازی کنیم، میتوانیم از آنها بهعنوان راهنما برای متعادل کردن این نیازها استفاده کنیم. نظارت مؤثر نیازمند مدیریت حسگرهای متعدد با انواع مختلف است که دادهها را به شکلهای متفاوتی پردازش میکنند. برای کمک به این موضوع، حسگرها را بر اساس سه ویژگی دستهبندی میکنم:
موقعیت حسگر (Vantage):
مکان قرارگیری حسگرها در شبکه. حسگرهایی با موقعیت برتر مختلف، بخشهای متفاوتی از یک رویداد را میبینند.
حوزه (Domain):
اطلاعاتی که حسگر ارائه میدهد، چه در سطح میزبان، یک سرویس روی میزبان یا شبکه. حسگرهایی با موقعیت برتر یکسان اما حوزههای متفاوت، دادههای مکمل درباره یک رویداد ارائه میدهند. برای برخی رویدادها، ممکن است فقط از یک حوزه اطلاعات دریافت کنید. برای مثال، نظارت بر میزبان تنها راه برای فهمیدن دسترسی فیزیکی به یک میزبان است.
اقدام (Action):
نحوه گزارش اطلاعات توسط حسگر. ممکن است دادهها را فقط ضبط کند، رویدادها را ارائه دهد یا ترافیکی که دادهها را تولید میکند، دستکاری کند. حسگرهایی با اقدامات مختلف ممکن است با یکدیگر تداخل داشته باشند.
این دستهبندی دو هدف دارد. اول، راهی برای تجزیه و طبقهبندی حسگرها بر اساس نحوه برخورد آنها با دادهها فراهم میکند. حوزه، توصیفی کلی از مکان و نحوه جمعآوری دادههاست. دیدگاه به ما اطلاع میدهد که مکان حسگر چگونه بر جمعآوری تأثیر میگذارد. اقدام توضیح میدهد که حسگر چگونه دادهها را دستکاری میکند. این ویژگیها با هم چالشهایی که جمعآوری داده برای اعتبار نتیجهگیریهای تحلیلگر ایجاد میکند، تعریف میکنند.
اعتبار ایدهای از طراحی آزمایش است و به قوت یک استدلال اشاره دارد. استدلال معتبر استدلالی است که نتیجه آن بهصورت منطقی از مقدماتش دنبال شود؛ استدلالهای ضعیف میتوانند از چندین جهت به چالش کشیده شوند و طراحی آزمایش بر شناسایی این چالشها تمرکز دارد. دلیل اهمیت این موضوع برای افراد امنیتی به نکتهای در مقدمه بازمیگردد: تحلیل امنیتی درباره متقاعد کردن مخاطبی است که تمایلی به ارزیابی منطقی یک تصمیم امنیتی و انتخاب پذیرش یا رد آن دارد. درک اعتبار و چالشهای آن، نتایج بهتر و تحلیلهای واقعبینانهتری تولید میکند.
به طور خلاصه:
موقعیت حسگر: حسگر کجا ایستاده؟
دامنه: حسگر به چه چیزی نگاه میکند؟
اقدام: حسگر با اطلاعاتی که بدست آورده چه کاری انجام میدهد؟
اعتبار: چقدر میتوانیم به نتیجه یا خروجی مطمئن باشیم؟
اینها کمک میکند بفهمید دادههای چطور جمع شدهاند و چقدر میتوانیم برای تصمیمگیری به آنها اعتماد کنیم.
دامنه (Domain)
اکنون به بررسی دقیقتر مفاهیم دامنه، موقعیت و اقدام میپردازیم. دامنه حسگر به نوع دادههایی اشاره دارد که حسگر تولید کرده و گزارش میدهد. از آنجا که حسگرها شامل ابزارهایی مانند آنتیویروس نیز میشوند و گاه منطق پشت پیامهایشان چندان شفاف نیست، تحلیلگر باید آگاه باشد که این ابزارها ممکن است با پیشداوریهای خاص خود همراه باشند.
جدول 1-1 چهار دسته اصلی دامنه را که در این کتاب به کار رفتهاند، تشریح میکند. این جدول دامنهها را بر اساس مدل رویداد و نوع حسگر تقسیمبندی کرده و توضیحات بیشتری در پی میآید.

حسگرهای دامنه شبکه: این حسگرها دادههای خود را از نوعی ضبط بسته، مانند pcap، سرآیند بستهها یا ساختارهایی نظیر NetFlow به دست میآورند. دادههای شبکه دیدی گسترده از شبکه فراهم میکنند، اما در مقایسه با حجم دادههای جمعآوریشده، اطلاعات مفید کمتری دارند. این دادهها باید تفسیر شوند، قابل خواندن باشند و معنادار باشند؛ زیرا ترافیک شبکه مملو از اطلاعات غیرضروری است.
حسگرهای دامنه سرویس: حسگرهای دامنه سرویس دادههای خود را از سرویسها به دست میآورند. نمونههایی از این سرویسها شامل برنامههای سروری مانند nginx یا apache (سرورهای HTTP) و همچنین فرآیندهای داخلی نظیر syslog و فرآیندهایی که توسط آن مدیریت میشوند، است. دادههای سرویس اطلاعاتی درباره آنچه واقعاً رخ داده ارائه میدهند، اما این کار از طریق تفسیر دادهها و ارائه یک مدل رویداد انجام میشود که ممکن است تنها بهصورت غیرمستقیم با واقعیت مرتبط باشد. علاوه بر این، برای جمعآوری دادههای سرویس، باید از وجود سرویس آگاه باشید، که با توجه به تمایل تولیدکنندگان سختافزار به گنجاندن وبسرور در هر پورت باز، گاهی بهطور شگفتانگیزی دشوار است.
حسگرهای دامنه میزبان: حسگرهای دامنه میزبان اطلاعاتی درباره وضعیت میزبان جمعآوری میکنند. برای اهداف ما، این نوع ابزارها در دو دسته جای میگیرند: سیستمهایی که اطلاعاتی درباره وضعیت سیستم، مانند فضای دیسک، ارائه میدهند و سیستمهای تشخیص نفوذ مبتنی بر میزبان، مانند نظارت بر یکپارچگی فایل(FIM) یا سیستمهای آنتیویروس. این حسگرها اطلاعاتی درباره تأثیر اقدامات بر میزبان فراهم میکنند، اما ممکن است با مشکلات زمانی مواجه شوند؛ بسیاری از سیستمهای مبتنی بر وضعیت در فواصل زمانی ثابت هشدار میدهند و سیستمهای تشخیص نفوذ اغلب از کتابخانههای امضای بزرگ استفاده میکنند که بهصورت نامنظم بهروزرسانی میشوند.
دامنه فعال: این دامنه شامل حسگرهایی است که تحت کنترل تحلیلگر عمل میکنند، مانند اسکن برای یافتن آسیبپذیریها، ابزارهای نقشهبرداری مانند traceroute یا حتی برقراری ارتباط ساده با یک وبسرور جدید برای درک عملکرد آن. دادههای فعال همچنین شامل سیگنالدهی (beaconing) و اطلاعاتی است که برای اطمینان از وقوع یک رویداد ارسال میشوند.
موقعیت حسگر(Vantage)
موقعیت حسگر به بستههایی اشاره دارد که حسگر قادر به مشاهده آنهاست. این موقعیت از تعامل بین محل قرارگیری حسگر و ساختار مسیریابی شبکه تعیین میشود. برای درک عواملی که بر موقعیت اثر میگذارند، به شکل 1-1 توجه کنید. این شکل حسگرهای مختلفی را با حروف بزرگ مشخص کرده است:
A: رابط میان روتر و اینترنت را نظارت میکند.
B: رابط میان روتر و سوئیچ را زیر نظر دارد.
C: رابط میان روتر و میزبان با آدرس IP 128.2.1.1 را بررسی میکند.
D: میزبان 128.1.1.1 را نظارت میکند.
E: پورت span سوئیچ را رصد میکند (پورت span همه ترافیک عبوری از سوئیچ را ضبط میکند).
F: رابط میان سوئیچ و هاب را نظارت میکند.
G: گزارشهای HTTP روی میزبان 128.1.1.2 را جمعآوری میکند.
H: همه ترافیک TCP روی هاب را شنود میکند.
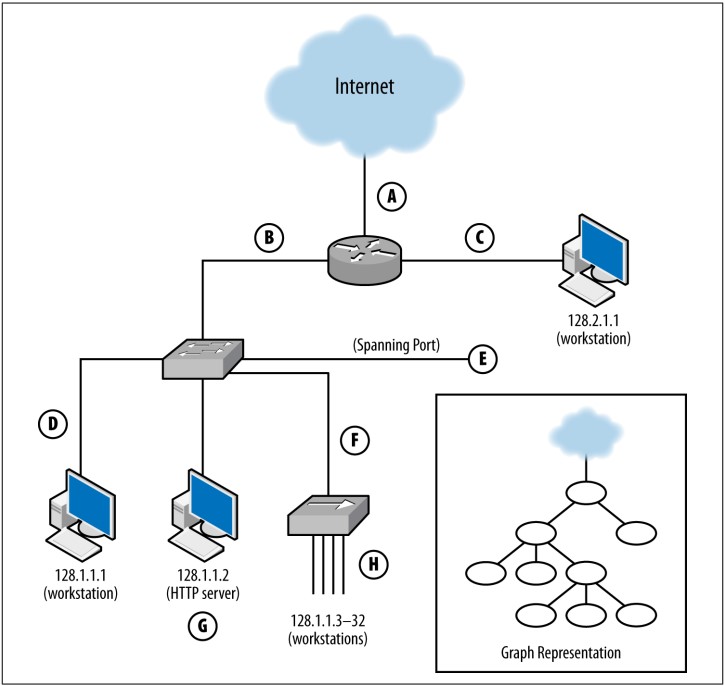
هر یک از این حسگرها موقعیت متفاوتی دارند و بر اساس آن، ترافیک متفاوتی را مشاهده میکنند. میتوانید موقعیت یک شبکه را با تبدیل آن به یک گراف ساده گره و لینک (مانند گوشه شکل 1-1) تخمین بزنید و سپس لینکهایی که بین گرهها عبور میکنند را ردیابی کنید. هر لینک میتواند ترافیکی را که از آن عبور میکند ثبت کند. برای مثال، در شکل 1-1:
حسگر A تنها ترافیک میان شبکه و اینترنت را میبیند و مثلاً ترافیک بین 128.1.1.1 و 128.2.1.1 را مشاهده نمیکند.
حسگر B هر ترافیکی را که از آدرسهای زیرین خود آغاز یا به آنها ختم شود (مانند 128.2.1.1 یا اینترنت) میبیند.
حسگر C تنها ترافیک مربوط به 128.2.1.1 را مشاهده میکند.
حسگر D، مانند C، فقط ترافیک مربوط به 128.1.1.1 را میبیند.
حسگر E هر ترافیکی را که بین پورتهای سوئیچ جابهجا شود (مانند ترافیک 128.1.1.1 یا 128.1.1.2 به هر مقصد دیگر) میبیند.
حسگر F زیرمجموعهای از آنچه E میبیند را مشاهده میکند، یعنی فقط ترافیک 128.1.1.3 تا 128.1.1.32 که به بیرون از هاب میرود.
حسگر G خاص است، زیرا تنها گزارشهای HTTP/S (پورتهای 80 و 443) را برای 128.1.1.2 میبیند.
حسگر H هر ترافیکی را که مبدأ یا مقصد آن بین 128.1.1.3 تا 128.1.1.32 باشد، مشاهده میکند.
هیچ حسگری بهتنهایی کل شبکه را پوشش نمیدهد. علاوه بر این، باید با ترافیک تکراری کنار آمد. برای مثال، اگر حسگرهای H و E را فعال کنید، ترافیک از 128.1.1.3 به 128.1.1.1 را دو بار خواهید دید. انتخاب موقعیتهای مناسب نیازمند ایجاد تعادل بین پوشش کامل ترافیک و اجتناب از غرق شدن در دادههای تکراری است.
انتخاب موقعیت حسگر (Vantage)
هنگام نصب و پیکربندی ابزارهای نظارتی در یک شبکه، تعیین موقعیت حسگر (vantage) فرآیندی سهمرحلهای است: تهیه نقشه شبکه، شناسایی موقعیتهای بالقوه برای نصب حسگرها، و سپس تعیین پوشش بهینه.
مرحله اول: تهیه نقشه شبکه اولین گام شامل تهیه نقشهای از شبکه و نحوه اتصال اجزای آن، همراه با فهرستی از موقعیتهای بالقوه برای نصب حسگرها است. شکل ۱-۱ نسخهای سادهشده از چنین نقشهای را نشان میدهد.
مرحله دوم: تعیین موقعیت حسگر هر مکان این مرحله شامل شناسایی تمام مکانهای قابل تنظیم برای نصب حسگرها در شبکه و سپس تعیین دامنه دید هر یک از این موقعیتها است. این دامنه دید میتواند بهصورت مجموعهای از ترکیبهای آدرس IP و پورت بیان شود. جدول ۱-۲ نمونهای از این فهرست را برای شکل ۱-۱ نشان میدهد. استفاده از گراف میتواند تخمین اولیهای از آنچه هر موقعیت حسگر مشاهده میکند ارائه دهد، اما برای مدلسازی دقیقتر، نیاز به اطلاعات عمیقتری درباره مسیریابی و سختافزار شبکه است. برای مثال، هنگام کار با روترها، ممکن است موقعیتهایی وجود داشته باشند که دید آنها نامتقارن باشد (توجه کنید که ترافیک در جدول ۱-۲ همگی متقارن است). برای اطلاعات بیشتر، به بخش «مبانی لایهبندی شبکه» در صفحه ۱۹ مراجعه کنید.

مرحله سوم: انتخاب موقعیتهای حسگر بهینه آخرین گام، انتخاب موقعیتهای حسگر بهینه از فهرست تهیهشده است. هدف، انتخاب مجموعهای از موقعیتها است که نظارت را با حداقل افزونگی (redundancy) فراهم کنند. برای مثال، حسگر E مجموعهای کاملتر از دادههای حسگر F ارائه میدهد، بنابراین دلیلی برای استفاده از هر دو وجود ندارد. انتخاب موقعیتهای حسگر معمولاً با مقداری افزونگی همراه است که گاهی میتوان با استفاده از قوانین فیلتر کردن آن را محدود کرد. برای نمونه، برای تنظیم حسگرها برای ترافیک بین میزبانهای ۱۲۸.۱.۱.۳–۳۲، باید موقعیت H تنظیم شود، اما این ترافیک در موقعیتهای E، F، B و A نیز ظاهر خواهد شد. اگر حسگرهای این موقعیتها طوری تنظیم شوند که ترافیک ۱۲۸.۱.۱.۳–۳۲ را گزارش نکنند، مسئله افزونگی برطرف میشود.
اقدامات: حسگرها با دادهها چه میکنند؟
اقدام یک حسگر، نحوه تعامل آن با دادههای جمعآوریشده را توصیف میکند. بسته به حوزه کاری، حسگرها میتوانند اقدامات متفاوتی انجام دهند که هر یک تأثیری متفاوت بر اعتبار خروجی دارند:
گزارش (Report) حسگرهای گزارشدهنده صرفاً اطلاعاتی درباره تمام پدیدههایی که مشاهده میکنند ارائه میدهند. این حسگرها ساده هستند و برای ایجاد خط مبنا (baselining) اهمیت دارند. همچنین برای توسعه امضاها و هشدارها برای پدیدههایی که حسگرهای کنترلی هنوز برای شناسایی آنها پیکربندی نشدهاند، مفیدند. نمونههای حسگرهای گزارشدهنده شامل جمعآوریکنندههای NetFlow، ابزار tcpdump و لاگهای سرور هستند.
رویداد (Event) حسگرهای رویداد برخلاف حسگرهای گزارشدهنده، از چندین منبع داده استفاده میکنند تا رویدادی را تولید کنند که خلاصهای از بخشی از آن دادهها باشد. برای مثال، یک سیستم تشخیص نفوذ مبتنی بر میزبان (IDS) ممکن است تصویر حافظه را بررسی کند، امضای بدافزار را در حافظه بیابد و رویدادی تولید کند که نشاندهنده به خطر افتادن میزبان توسط بدافزار است. در حالتهای پیشرفته، حسگرهای رویداد مانند جعبههای سیاهی عمل میکنند که بر اساس فرآیندهای داخلی طراحیشده توسط متخصصان، رویداد تولید میکنند. این حسگرها شامل سیستمهای تشخیص نفوذ (IDS) و آنتیویروسها (AV) هستند.
کنترل (Control) حسگرهای کنترلی مانند حسگرهای رویداد، از چندین منبع داده استفاده میکنند و پیش از واکنش، قضاوتی درباره دادهها انجام میدهند. اما برخلاف حسگرهای رویداد، حسگرهای کنترلی هنگام تولید رویداد، ترافیک را اصلاح یا مسدود میکنند. این حسگرها شامل سیستمهای پیشگیری از نفوذ (IPS)، فایروالها، سیستمهای ضد هرزنامه و برخی سیستمهای آنتیویروس هستند.
اقدام یک حسگر نهتنها بر نحوه گزارش دادهها تأثیر میگذارد، بلکه بر نحوه تعامل آن با دادههای مشاهدهشده نیز اثر دارد. حسگرهای کنترلی میتوانند ترافیک را اصلاح یا مسدود کنند.
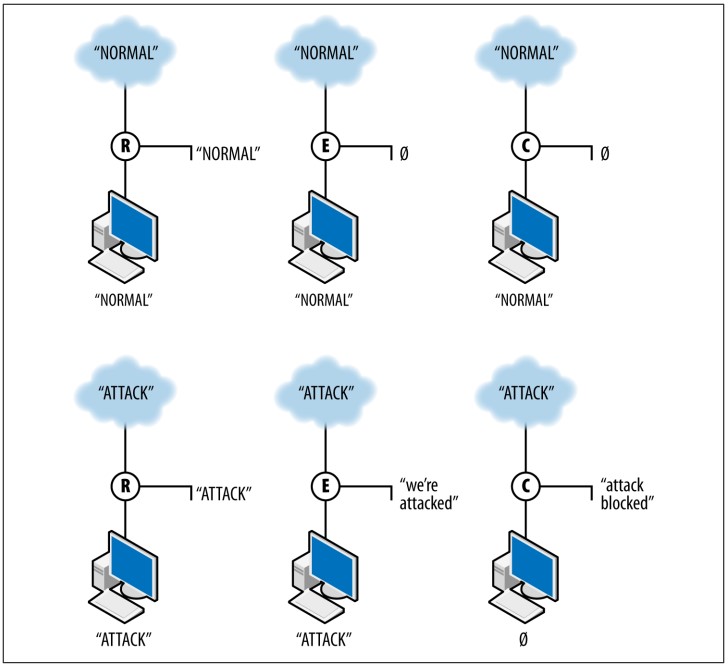
شکل ۱-۲ نشان میدهد که حسگرهای با سه نوع اقدام مختلف چگونه با دادهها تعامل میکنند. این شکل کار سه حسگر را نشان میدهد: R (حسگر گزارشدهنده)، E (حسگر رویداد) و C (حسگر کنترلی). حسگرهای رویداد و کنترلی سیستمهای تطبیق امضا هستند که به بردار حمله واکنش نشان میدهند. هر حسگر بین اینترنت و یک هدف واحد قرار گرفته است.
حسگر R (گزارشدهنده) صرفاً ترافیک مشاهدهشده را گزارش میکند. در این مورد، هم ترافیک عادی و هم ترافیک حمله را بدون تأثیر بر ترافیک گزارش میدهد و بهطور مؤثری دادههای مشاهدهشده را خلاصه میکند. حسگر E (رویداد) در حضور ترافیک عادی کاری انجام نمیدهد، اما هنگام مشاهده ترافیک حمله، رویدادی تولید میکند. این حسگر ترافیک را متوقف نمیکند؛ فقط رویداد را ارسال میکند. حسگر C (کنترلی) هنگام مشاهده ترافیک حمله، رویدادی تولید میکند و به ترافیک عادی واکنشی نشان نمیدهد. اما علاوه بر این، حسگر C ترافیک غیرعادی را از رسیدن به هدف مسدود میکند. اگر حسگر دیگری در مسیر پس از C قرار داشته باشد، ترافیکی که C مسدود کرده را هرگز نخواهد دید.
اعتبار و اقدام
اعتبار (Validity) مفهومی است که در طراحی آزمایشها استفاده میشود. اعتبار یک استدلال به قدرت آن استدلال و میزان معقول بودن ارتباط بین مقدمه و نتیجه اشاره دارد. استدلالهای معتبر ارتباط قوی دارند، در حالی که استدلالهای با اعتبار ضعیف بهراحتی قابل چالش هستند.
برای تحلیلگران امنیتی، اعتبار نقطه شروع خوبی برای شناسایی چالشهایی است که تحلیل آنها با آن مواجه خواهد شد (و قطعاً چالشهایی وجود خواهد داشت). آیا مطمئن هستید که حسگر درست کار میکند؟ آیا این تهدید واقعی است؟ چرا باید این سیستم حیاتی را بهروزرسانی کنیم؟ امنیت در اکثر سازمانها یک مرکز هزینه است و شما باید بتوانید هزینههایی که اعمال میکنید را توجیه کنید. اگر نتوانید به چالشهای داخلی پاسخ دهید، در برابر چالشهای خارجی نیز موفق نخواهید بود.
این بخش مقدمهای کوتاه درباره اعتبار است. من در طول کتاب به این موضوع بازمیگردم و چالشهای خاص را در زمینههای مختلف بررسی میکنم. ابتدا میخواهم واژگان کاری را معرفی کنم و با چهار دسته اصلی که در تحقیقات استفاده میشوند شروع کنم. در ادامه این دستهها را بهصورت خلاصه معرفی میکنم و سپس در بخشهای بعدی بهطور عمیقتر بررسی میکنم. چهار نوع اعتبار که در نظر میگیریم عبارتاند از:
اعتبار داخلی (Internal) اعتبار داخلی یک استدلال به رابطه علت و معلولی اشاره دارد. اگر آزمایشی را بهصورت «اگر A را انجام دهم، B اتفاق میافتد» توصیف کنیم، اعتبار داخلی به این موضوع میپردازد که آیا A به B مرتبط است یا خیر، و آیا عوامل دیگری وجود دارند که ممکن است بر این رابطه تأثیر بگذارند و مورد توجه قرار نگرفته باشند.
اعتبار خارجی (External) اعتبار خارجی به قابلیت تعمیم نتایج یک آزمایش به دنیای واقعی اشاره دارد. آزمایشی با اعتبار خارجی قوی، دادهها و روشهای آزمایش آن منعکسکننده دنیای واقعی هستند.
اعتبار آماری (Statistical) اعتبار آماری به استفاده صحیح از روشها و تکنیکهای آماری در تفسیر دادههای جمعآوریشده اشاره دارد.
اعتبار سازهای (Construct) سازه سیستمی رسمی برای توصیف یک رفتار است که میتوان آن را آزمایش یا چالش کرد. برای مثال، اگر بخواهم ثابت کنم کسی در حال انتقال فایل در شبکه است، ممکن است حجم داده منتقلشده را بهعنوان سازه استفاده کنم. اعتبار سازهای به این موضوع میپردازد که آیا این سازهها معنادار هستند، آیا دقیقاند، آیا قابلتکرارند و آیا میتوان آنها را به چالش کشید.
در طراحی آزمایشها، اعتبار اثبات نمیشود، بلکه به چالش کشیده میشود. این وظیفه پژوهشگر است که نشان دهد اعتبار مورد توجه قرار گرفته است. این موضوع چه برای دانشمندی که آزمایش انجام میدهد و چه برای تحلیلگر امنیتی که تصمیم مسدودسازی را توضیح میدهد، صادق است. شناسایی چالشهای اعتبار مسئلهای مرتبط با تخصص است—اعتبار یک مسئله پویا است و حوزههای مختلف از زمان توسعه این مفهوم، تهدیدهای متفاوتی برای اعتبار شناسایی کردهاند.
برای مثال، جامعهشناسان دسته اعتبار خارجی را به زیرمجموعههای اعتبار جمعیتی (population validity) و اعتبار زیستمحیطی (ecological validity) تقسیم کردهاند. اعتبار جمعیتی به قابلیت تعمیم نمونهگیری جمعیت به کل جهان اشاره دارد و اعتبار زیستمحیطی به قابلیت تعمیم محیط آزمایش به واقعیت اشاره میکند. بهعنوان پرسنل امنیتی، ما نیز باید چالشهای مشابهی را برای اعتبار دادههایمان در نظر بگیریم که از رفتارهای پیچیده مهاجمان ناشی میشوند.
اعتبار داخلی
اعتبار داخلی یک استدلال به رابطه علت و معلولی در یک آزمایش اشاره دارد. یک آزمایش زمانی از اعتبار داخلی قوی برخوردار است که بتوان بهطور معقول پذیرفت که نتیجه مشاهدهشده ناشی از علتی است که آزمایشگر فرض کرده است. در مورد اعتبار داخلی، تحلیلگر امنیتی باید بهویژه به مسائل زیر توجه کند:
زمانبندی
زمانبندی در اینجا به فرآیند جمعآوری دادهها و ارتباط آن با پدیده مشاهدهشده اشاره دارد. همبستگی بین دادههای امنیتی و رویدادها نیازمند درک روشنی از چگونگی و زمان جمعآوری دادههاست. این موضوع بهویژه هنگام مقایسه دادههایی مانند NetFlow (که زمانبندی جریانها تحت تأثیر مسائل مدیریت حافظه نهان جمعآوریکننده جریان قرار میگیرد) یا دادههای نمونهبرداریشده مانند وضعیت سیستم، چالشبرانگیز است. برای رفع این مسائل زمانبندی، باید از ثبت دقیق سوابق شروع کرد—یعنی نهتنها درک چگونگی جمعآوری دادهها، بلکه اطمینان از هماهنگی و یکپارچگی اطلاعات زمانی در سراسر سیستم.
ابزارها و تجهیزات
تحلیل صحیح نیازمند اعتبارسنجی این است که سیستمهای جمعآوری داده، اطلاعات مفیدی (یعنی دادههایی که بتوانند بهطور معناداری با دادههای دیگر همبسته شوند) جمعآوری میکنند و اصلاً دادهای جمعآوری میشود. آزمایش و ممیزی منظم سیستمهای جمعآوری داده برای تمایز بین حملات واقعی و اشکالات در جمعآوری داده ضروری است.
انتخاب
مسائل انتخاب به تأثیر انتخاب هدف یک آزمایش بر کل آزمایش اشاره دارد. برای تحلیلگران امنیتی، این شامل پرسشهایی درباره مأموریت یک سیستم (آیا برای تحقیق است؟ بازاریابی؟)، مکان قرارگیری سیستم در شبکه (قبل از منطقه غیرنظامیشده (DMZ)، رو به بیرون یا رو به داخل؟) و مسائل مربوط به تحرک (دسکتاپ؟ لپتاپ؟ سیستمهای نهفته؟) میشود.
تاریخچه
مسائل تاریخچه به رویدادهایی اشاره دارد که در حین انجام تحلیل بر آن تأثیر میگذارند. برای مثال، اگر تحلیلگری در حال بررسی تأثیر فیلترهای هرزنامه باشد و همزمان یک ارائهدهنده بزرگ هرزنامه غیرفعال شود، او باید بررسی کند که آیا نتایج بهدستآمده ناشی از فیلتر است یا نتیجه یک اثر جهانی.
بلوغ
بلوغ به اثرات بلندمدت یک آزمایش بر موضوع آزمایش اشاره دارد. بهویژه در تحلیلهای طولانیمدت، تحلیلگر باید تأثیر تخصیص پویا بر هویت را در نظر بگیرد—برای مثال، در یک شبکه DHCP، میتوان انتظار داشت که با انقضای اجارهها، رابطه آدرسهای IP با داراییها تغییر کند. تخصیص DNS بهصورت چرخشی یا شبکههای توزیع محتوا (CDN) نیز منجر به روابط متفاوتی بین درخواستهای HTTP میشود.
آزمایشهای طبیعی
آزمایش طبیعی نوعی آزمایش است که در آن پژوهشگر به گروهی متکی است که در معرض نوعی پدیده طبیعی (در طول زمان یا مکان) قرار گرفته و گروهها را بر اساس این مواجهه مقایسه میکند. نمونه McColo که در فصل پانزدهم ذکر شده، مثال خوبی از این نوع تحلیل است—این تحلیل از یک پروژه جمعآوری داده بلندمدت بهره برد که بهطور اتفاقی در زمان غیرفعال شدن McColo در حال اجرا بود تا تأثیر آن را بررسی کند. جمعآوری دادههای بلندمدت برای آزمایشهای طبیعی مناسب است، بنابراین توجه به تقویم برای رویدادهای امنیتی قابلتوجه، راه مفیدی برای مطالعه تأثیر (یا عدم تأثیر) آنها بر دادههاست.
اعتبار خارجی
اعتبار خارجی به توانایی تعمیم نتایج یک تحلیل به گروههای گستردهتر از گروه نمونه مورد بررسی اشاره دارد. اگر نتیجهای از اعتبار خارجی قوی برخوردار باشد، میتوان آن را به دستههای وسیعتری فراتر از گروه نمونه تعمیم داد. در تحلیلهای امنیتی، اعتبار خارجی بهویژه چالشبرانگیز است، زیرا درک جامعی از رفتار کلی شبکهها نداریم—مشکلی که دهههاست ادامه دارد.
راه اصلی برای دستیابی به اعتبار خارجی، اطمینان از این است که دادههای انتخابشده نماینده کل جمعیت هدف باشند و روشهای اعمالشده (مانند آزمایشها یا اقدامات) در کل مجموعه یکسان باشند. برای مثال، اگر مطالعهای روی دانشجویان انجام میشود، باید عواملی مثل درآمد، پیشینه و سطح تحصیلات در نظر گرفته شود و آزمایش بهصورت یکسان برای همه اجرا شود. با این حال، تا زمانی که دانش رفتار ترافیک شبکه پیشرفت نکند و مدلهای باکیفیتی برای توصیف رفتار عادی شبکه ایجاد نشود، تعیین اینکه آیا مدلها نمونهای واقعبینانه را نشان میدهند یا خیر، عملاً غیرممکن است. در حال حاضر، بهترین روش برای رفع این مشکل، استفاده از مجموعههای داده (corpora) اضافی است. در علوم کامپیوتر، سنت دیرینهای برای جمعآوری مجموعههای داده برای تحلیل وجود دارد؛ این مجموعهها اگرچه لزوماً نماینده کامل نیستند، اما بهتر از هیچ هستند.
مقدمهای کوتاه درباره مجموعههای داده امنیت اطلاعات
تحقیقات امنیت اطلاعات همیشه به دنبال مجموعههای داده باکیفیت است. یکی از مهمترین مقالات اولیه در زمینه تشخیص نفوذ، مطالعه آزمایشگاه لینکلن در سال ۱۹۹۹ (رجوع کنید به بخش «مطالعات بیشتر» در صفحه ۱۶)، بهطور گسترده به مشکل تولید داده پرداخته و مجموعه دادهای را ایجاد کرده که سالهاست توسط محققان استفاده میشود. وزارت امنیت داخلی ایالات متحده برنامهای به نام IMPACT را پشتیبانی میکند که بهعنوان کاتالوگ و بازار دادههای امنیتی عمل میکند.
چندین سازمان تحقیقاتی نیز داده تولید و به اشتراک میگذارند. از منابع برجسته میتوان به CAIDA، مرکز تحلیل دادههای کاربردی اینترنت دانشگاه UCSD، اشاره کرد. CAIDA مجموعههای مختلفی از دادههای نقشهبرداری شبکه را تولید و جمعآوری میکند. نیروی دریایی ایالات متحده مجموعههای دادهای از تمرین سالانه دفاع سایبری نگهداری میکند و CERT یک مخزن SiLK از یک تمرین گذشته دارد. کنفرانس تجسمسازی امنیتی (VizSec) نیز به مجموعههای داده جالبی اشاره میکند. بهترین منبع واحد برای همه این مجموعهها در حال حاضر توسط مایک اسکونزو (Mike Sconzo) نگهداری میشود؛ سایت Security Repo او لینکهایی به مجموعههای داده و اشارههایی به چندین مخزن برای دادههای میزبان، سرویس و شبکه ارائه میدهد.
این مجموعههای داده برای آموزش و تحلیل اکتشافی داده بسیار مناسباند، اما چند نکته مهم باید ذکر شود. اول اینکه، این دادهها به محض جمعآوری و انتشار، قدیمی میشوند—باید به زمان انتشار مجموعه داده توجه کنید، زیرا حسگرها، شبکه و اینترنت ممکن است از زمان جمعآوری داده بهطور قابلتوجهی تغییر کرده باشند. همچنین، اطلاعاتی مانند مکان قرارگیری حسگرها تقریباً هیچگاه در دسترس نیست، که بر دادههای مشاهدهشده تأثیر میگذارد.
همه اینها بر این فرض استوار است که شما به نتیجهای عمومی نیاز دارید. اگر نتایج را بتوان تنها به یک شبکه خاص (مثلاً شبکهای که تحت نظارت شماست) محدود کرد، اعتبار خارجی مشکل کمتری ایجاد میکند.
اعتبار سازهای
هنگام انجام یک تحلیل، شما ساختاری رسمی ایجاد میکنید تا آنچه را که به دنبالش هستید توصیف کنید. این ساختار رسمی ممکن است یک نظرسنجی باشد (مثلاً: «روی مقیاس ۱ تا ۱۰ بگویید سیستم شما چقدر مشکل دارد؟») یا یک معیار اندازهگیری (مثل تعداد بایت بر ثانیه به سمت سایت http://www.evilland.com). این ساختار رسمی، که به آن «سازه» میگویند، روشی است که تحلیل خود را ارزیابی میکنید.
سازههای شفاف و دقیق برای انتقال معنای نتایج تحلیل بسیار مهم هستند. اگرچه این موضوع ممکن است ساده به نظر برسد، اما شگفتانگیز است که اختلاف نظر بر سر سازهها چقدر سریع میتواند به تصمیمگیریهای علمی یا تجاری مهم منجر شود. برای مثال، سؤال «یک باتنت چقدر بزرگ است؟» را در نظر بگیرید. یک متخصص امنیت شبکه ممکن است بگوید باتنت شامل تمام دستگاههایی است که با یک سرور فرمان و کنترل (C&C) خاص ارتباط برقرار میکنند. یک متخصص جرمشناسی دیجیتال ممکن است استدلال کند که باتنت با وجود هش یکسان بدافزار روی دستگاههای مختلف تعریف میشود. اما یک مأمور اجرای قانون ممکن است بگوید باتنت توسط یک گروه جنایی خاص اداره میشود.
اعتبار آماری
اعتبار نتیجهگیری آماری به استفاده صحیح از ابزارهای آماری مربوط است. این موضوع در فصل یازدهم بهطور مفصل بررسی خواهد شد.
مسائل مربوط به مهاجم و حمله
در نهایت، باید تأثیر منحصربهفرد آزمایشهای امنیتی را در نظر بگیریم. آزمایش و تحلیل امنیتی با چالش خاصی همراه است، زیرا موضوع تحلیل ما—یعنی مهاجم—از ما متنفر است و میخواهد ما شکست بخوریم. به همین دلیل، باید چالشهایی را که از سوی مهاجم بر اعتبار سیستم وارد میشود، بررسی کنیم. این چالشها شامل مسائل مربوط به بهروز بودن، منابع و زمانبندی، و سیستم تشخیص هستند:
بهروز بودن
هنگام ارزیابی یک سیستم دفاعی، باید بررسی کنید که آیا این دفاع در برابر استراتژیهای فعلی یا قابل پیشبینی مهاجمان، منطقی و مؤثر است. تعداد زیادی آسیبپذیری در فهرست آسیبپذیریهای مشترک (CVE؛ به فصل هفتم مراجعه کنید) وجود دارد، اما اکثر بهرهبرداریها در دنیای واقعی از تعداد بسیار محدودی از این آسیبپذیریها استفاده میکنند. با حفظ آگاهی قوی از محیط تهدیدات کنونی (به فصل هفدهم مراجعه کنید)، میتوانید روی استراتژیهای مرتبطتر تمرکز کنید.
منابع و زمانبندی
سؤالات مربوط به منابع و زمانبندی به این موضوع میپردازند که آیا یک سیستم تشخیص یا آزمایش میتواند در صورتی که مهاجم سرعت حمله را کم یا زیاد کند یا حمله را بین چندین میزبان تقسیم کند، دور زده شود. برای مثال، اگر سیستم دفاعی شما فرض کند که مهاجم با یک آدرس خارجی ارتباط برقرار میکند، چه اتفاقی میافتد اگر مهاجم بین مجموعهای از آدرسها چرخش کند؟ اگر دفاع شما فرض کند که مهاجم یک فایل را بهسرعت منتقل میکند، چه میشود اگر مهاجم این کار را با حوصله و در طول ساعتها یا حتی روزها انجام دهد؟
تشخیص
در نهایت، سؤالات مربوط به سیستم تشخیص به این موضوع میپردازند که چگونه یک مهاجم میتواند خود سیستم تشخیص شما را هدف حمله قرار دهد یا آن را دستکاری کند. برای مثال، اگر از یک مجموعه داده آموزشی برای تنظیم یک حسگر استفاده میکنید، آیا حملاتی که ممکن است در این مجموعه داده وجود داشته باشند را در نظر گرفتهاید؟ اگر سیستم شما به نوعی اعتماد (مانند آدرس IP، رمزهای عبور یا فایلهای اعتبارسنجی) وابسته است، در صورت به خطر افتادن این اعتماد چه اتفاقی میافتد؟ آیا مهاجم میتواند با حملهای مانند حمله توزیعشده انکار سرویس (DDoS) یا بارگذاری بیش از حد سیستم تشخیص شما، آن را مختل کند، و در این صورت، پیامدهای آن چیست؟
مطلبی دیگر از این انتشارات
فصل 20 -تنسورها با کتابخانه پایتورچ
مطلبی دیگر از این انتشارات
فصل 21 - شبکههای عصبی
مطلبی دیگر از این انتشارات
فصل 17 - ماشین بردار پشتیبان