

مدرس آنالیزداده | یادگیری ماشین | یادگیری عمیق در مجتمع فنی تهران
فصل 21 - شبکههای عصبی

21.0 مقدمه
در هستهی شبکههای عصبی ساده، واحدی به نام نود یا نورون قرار دارد. هر نورون یک یا چند ورودی دریافت میکند، هر ورودی را در یک پارامتر (به نام وزن) ضرب میکند، مقادیر وزندار شده را به همراه یک مقدار بایاس (معمولاً صفر) جمع میکند و سپس این مقدار را به یک تابع فعالسازی میفرستد. خروجی این فرآیند به نورونهای دیگر در لایههای عمیقتر شبکه عصبی (در صورت وجود) منتقل میشود.
شبکههای عصبی را میتوان به صورت مجموعهای از لایههای متصل به هم تصور کرد که ویژگیهای یک مشاهده را از یک طرف به مقدار هدف (مثلاً کلاس مشاهده) در طرف دیگر متصل میکنند. شبکههای عصبی فیدفوروارد (که به آنها پرسپترون چندلایه نیز گفته میشود) سادهترین نوع شبکههای عصبی مصنوعی هستند که در کاربردهای واقعی استفاده میشوند. نام "فیدفوروارد" از این واقعیت میآید که مقادیر ویژگیهای یک مشاهده به صورت "رو به جلو" در شبکه حرکت میکنند و هر لایه به ترتیب این ویژگیها را تغییر میدهد تا خروجی شبکه به مقدار هدف نزدیک شود یا با آن برابر شود.
به طور خاص، شبکههای عصبی فیدفوروارد شامل سه نوع لایه هستند:
1. لایه ورودی: در ابتدای شبکه قرار دارد و هر واحد در این لایه، مقدار یک ویژگی از مشاهده را نگه میدارد. برای مثال، اگر یک مشاهده 100 ویژگی داشته باشد، لایه ورودی شامل 100 واحد خواهد بود.
2. لایه خروجی: در انتهای شبکه قرار دارد و خروجی لایههای میانی (به نام لایههای مخفی) را به مقادیری تبدیل میکند که برای وظیفه موردنظر مفید هستند. برای مثال، در یک مسئله طبقهبندی باینری، میتوان از یک لایه خروجی با یک واحد استفاده کرد که با استفاده از تابع سیگموید خروجی خود را به مقداری بین 0 و 1 تبدیل میکند تا احتمال کلاس پیشبینیشده را نشان دهد.
3. لایههای مخفی: بین لایههای ورودی و خروجی قرار دارند و به ترتیب ویژگیهای لایه ورودی را به چیزی تبدیل میکنند که پس از پردازش توسط لایه خروجی، شبیه به کلاس هدف باشد. شبکههای عصبی با تعداد زیادی لایه مخفی (مثلاً 10، 100 یا 1000 لایه) به عنوان شبکههای عمیق شناخته میشوند و فرآیند آموزش این شبکهها به نام یادگیری عمیق شناخته میشود.
شبکههای عصبی معمولاً با مقداردهی اولیه تمام پارامترها به مقادیر تصادفی کوچک از یک توزیع گاوسی یا یکنواخت ایجاد میشوند. پس از اینکه یک مشاهده یا معمولاً مجموعهای از مشاهدات به نام بچ(batch) از شبکه عبور کرد، مقدار خروجی با مقدار واقعی مشاهده با استفاده از یک تابع زیان مقایسه میشود. این فرآیند به نام انتشار رو به جلو(forward propagation) شناخته میشود. سپس الگوریتمی به صورت عقبگرد(back propagation) در شبکه حرکت میکند و میزان مشارکت هر پارامتر در خطای بین مقدار پیشبینیشده و مقدار واقعی را شناسایی میکند. این فرآیند به نام انتشار عقبگرد شناخته میشود. در هر پارامتر، الگوریتم بهینهسازی مشخص میکند که هر وزن چقدر باید تنظیم شود تا خروجی بهبود یابد.
شبکههای عصبی با تکرار فرآیند انتشار رو به جلو و عقبگرد برای هر مشاهده در دادههای آموزشی چندین بار یاد میگیرند. هر بار که تمام مشاهدات از شبکه عبور کنند، یک دوره (epoch) نامیده میشود و آموزش معمولاً شامل چندین دوره است. در این فرآیند، مقادیر پارامترها با استفاده از روشی به نام گرادیان کاهشی بهتدریج بهینه میشوند تا خروجی موردنظر به دست آید.
در این فصل، ما از همان کتابخانه پایتون که در فصل قبل استفاده کردیم، یعنی پایتورچ (PyTorch)، برای ساخت، آموزش و ارزیابی انواع شبکههای عصبی استفاده خواهیم کرد. پایتورچ به دلیل APIهای خوشساخت و نمایش بصری عملیاتهای تنسوری سطح پایین که شبکههای عصبی را پشتیبانی میکنند، در حوزه یادگیری عمیق بسیار محبوب است. یکی از ویژگیهای کلیدی پایتورچ، اتوگراد (autograd) است که به طور خودکار گرادیانهای موردنیاز برای بهینهسازی پارامترهای شبکه پس از انتشار رو به جلو و عقبگرد را محاسبه و ذخیره میکند.
شبکههای عصبی ساختهشده با کد پایتورچ میتوانند هم با CPU (مثلاً روی لپتاپ) و هم با GPU (روی کامپیوترهای تخصصی یادگیری عمیق) آموزش ببینند. در دنیای واقعی با دادههای واقعی، معمولاً آموزش شبکههای عصبی با GPU لازم است، زیرا فرآیند آموزش برای شبکههای پیچیده و دادههای بزرگ روی GPU بسیار سریعتر از CPU است. با این حال، تمام شبکههای عصبی در این کتاب به اندازه کافی کوچک و ساده هستند که میتوانند روی لپتاپ با CPU در چند دقیقه آموزش ببینند. فقط توجه داشته باشید که وقتی شبکههای بزرگتر و دادههای آموزشی بیشتری داشته باشیم، آموزش با CPU به طور قابلتوجهی کندتر از GPU خواهد بود.
21.1 استفاده از Autograd در پایتورچ
مشکل
میخواهید از ویژگیهای اتوگراد (Autograd) پایتورچ برای محاسبه و ذخیره گرادیانها پس از انجام انتشار رو به جلو و عقبگرد استفاده کنید.
راهحل
تنسورهایی ایجاد کنید که گزینه requires_grad آنها روی True تنظیم شده باشد:
# Import libraries
import torch
# Create a torch tensor that requires gradients
t = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
# Perform a tensor operation simulating "forward propagation"
tensor_sum = t.sum()
# Perform back propagation
tensor_sum.backward()
# View the gradients
t.gradخروجی:
tensor([1., 1., 1.])توضیحات
اتوگراد یکی از ویژگیهای اصلی پایتورچ و عامل مهمی در محبوبیت آن بهعنوان یک کتابخانه یادگیری عمیق است. توانایی محاسبه، ذخیره و تجسم آسان گرادیانها، پایتورچ را برای محققان و علاقهمندانی که شبکههای عصبی را از ابتدا میسازند، بسیار بصری و کاربردی میکند.
پایتورچ از یک گراف غیرمدور جهتدار (DAG) برای ثبت تمام دادهها و عملیات محاسباتی انجامشده روی آن دادهها استفاده میکند. این قابلیت بسیار مفید است، اما به این معناست که باید مراقب باشیم چه عملیاتی را روی دادههای پایتورچ که نیاز به محاسبه گرادیان دارند، اعمال میکنیم. هنگام کار با اتوگراد، نمیتوانیم بهراحتی تنسورها را به آرایههای نامپای (NumPy) تبدیل کنیم و دوباره برگردانیم بدون اینکه گراف را بشکنیم، عبارتی که برای توصیف عملیاتی استفاده میشود که از اتوگراد پشتیبانی نمیکنند:
import torch
tensor = torch.tensor([1.0,2.0,3.0], requires_grad=True)
tensor.numpy() خروجی:
RuntimeError: Can't call numpy() on Tensor that requires grad.
Use tensor.detach().numpy() instead. برای تبدیل این تنسور به یک آرایه نامپای، باید متد ()detach را روی آن فراخوانی کنیم، که این کار گراف را میشکند و در نتیجه توانایی ما برای محاسبه خودکار گرادیانها را از بین میبرد. اگرچه این کار میتواند مفید باشد، اما باید توجه داشت که جدا کردن (detaching) تنسور باعث میشود پایتورچ نتواند گرادیان را بهصورت خودکار محاسبه کند.
21.2 پیشپردازش دادهها برای شبکههای عصبی
مشکل
میخواهید دادهها را برای استفاده در یک شبکه عصبی پیشپردازش کنید.
راهحل
هر ویژگی را با استفاده از StandardScaler کتابخانه سایکیت-لرن (scikit-learn) استاندارد کنید:
# Load libraries
from sklearn import preprocessing import numpy as np
# Create feature
features = np.array([[-100.1, 3240.1],
[-200.2, -234.1],
[5000.5, 150.1],
[6000.6, -125.1],
[9000.9, -673.1]])
# Create scaler
scaler = preprocessing.StandardScaler()
features = scaler.fit_transform(features)
# Convert to a tensor
features_standardized_tensor = torch.from_numpy(features)
# Show features
features_standardized_tensorخروجی:
tensor([[-100.1000, 3240.1000],
[-200.2000, -234.1000],
[5000.5000, 150.1000],
[6000.6000, -125.1000],
[9000.9000, -673.1000]], dtype=torch.float64) توضیحات
اگرچه این دستورالعمل بسیار شبیه به دستورالعمل 4.2 است، اما به دلیل اهمیت بالای آن برای شبکههای عصبی، ارزش تکرار دارد. معمولاً پارامترهای یک شبکه عصبی در ابتدا بهصورت اعداد تصادفی کوچک مقداردهی (ایجاد) میشوند. شبکههای عصبی اغلب زمانی که مقادیر ویژگیها بسیار بزرگتر از مقادیر پارامترها باشند، عملکرد ضعیفی از خود نشان میدهند. علاوه بر این، از آنجا که مقادیر ویژگیهای یک مشاهده در هنگام عبور از واحدهای مختلف ترکیب میشوند، مهم است که همه ویژگیها در یک مقیاس یکسان باشند.
به همین دلایل، بهترین روش (هرچند نه همیشه ضروری، مثلاً وقتی همه ویژگیها باینری هستند) این است که هر ویژگی را استاندارد کنیم تا مقادیر آن میانگین 0 و انحراف معیار 1 داشته باشند. این کار بهراحتی با استفاده از StandardScaler سایکیت-لرن قابل انجام است.
با این حال، اگر نیاز دارید این عملیات را پس از ایجاد تنسورهایی با requires_grad=True انجام دهید، باید این کار را بهصورت داخلی در پایتورچ انجام دهید تا گراف محاسباتی شکسته نشود. اگرچه معمولاً ویژگیها را قبل از شروع آموزش شبکه استاندارد میکنید، اما دانستن چگونگی انجام این کار در پایتورچ نیز ارزشمند است:
# Load library
import torch
# Create features
torch_features = torch.tensor([[-100.1, 3240.1],
[-200.2, -234.1],
[5000.5, 150.1],
[6000.6, -125.1],
[9000.9, -673.1]], requires_grad=True)
# Compute the mean and standard deviation
mean = torch_features.mean(0, keepdim=True)
standard_deviation = torch_features.std(0, unbiased=False, keepdim=True)
# Standardize the features using the mean and standard deviation
torch_features_standardized = torch_features - mean
torch_features_standardized /= standard_deviation
# Show standardized features
torch_features_standardized خروجی:
tensor([[-1.1254, 1.9643],
[-1.1533, -0.5007],
[ 0.2953, -0.2281],
[ 0.5739, -0.4234],
[ 1.4096, -0.8122]], grad_fn=<DivBackward0>) 21.3 طراحی یک شبکه عصبی
مشکل
میخواهید یک شبکه عصبی طراحی کنید.
راهحل
از کلاس nn.Module پایتورچ برای تعریف یک معماری ساده شبکه عصبی استفاده کنید:
# Import libraries
import torch
import torch.nn as nn
# Define a neural network
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.fc1 = nn.Linear(10, 16)
self.fc2 = nn.Linear(16, 16)
self.fc3 = nn.Linear(16, 1)
def forward(self, x):
x = nn.functional.relu(self.fc1(x))
x = nn.functional.relu(self.fc2(x))
x = nn.functional.sigmoid(self.fc3(x))
return x
# Initialize the neural network
network = SimpleNeuralNet()
# Define loss function, optimizer
loss_criterion = nn.BCELoss()
optimizer = torch.optim.RMSprop(network.parameters())
# Show the network
network خروجی:
SimpleNeuralNet(
(fc1): Linear(in_features=10, out_features=16, bias=True)
(fc2): Linear(in_features=16, out_features=16, bias=True)
(fc3): Linear(in_features=16, out_features=1, bias=True)
) توضیحات
شبکههای عصبی از لایههایی از واحدها تشکیل شدهاند. با این حال، تنوع زیادی در انواع لایهها و نحوه ترکیب آنها برای تشکیل معماری شبکه وجود دارد. اگرچه الگوهای معماری رایجی وجود دارند (که در این فصل به آنها خواهیم پرداخت)، حقیقت این است که انتخاب معماری مناسب بیشتر یک هنر است و موضوع تحقیقات زیادی است.
برای ساخت یک شبکه عصبی فیدفوروارد در پایتورچ، باید تصمیمهای متعددی درباره معماری شبکه و فرآیند آموزش بگیریم. به یاد داشته باشید که هر واحد در لایههای مخفی:
تعدادی ورودی دریافت میکند.
هر ورودی را با یک مقدار پارامتر (وزن) ضرب میکند.
تمام ورودیهای وزندار را به همراه یک مقدار بایاس (معمولاً صفر) جمع میکند.
اغلب یک تابع (به نام تابع فعالسازی) روی آن اعمال میکند.
خروجی را به واحدهای لایه بعدی منتقل میکند.
ابتدا، برای هر لایه در لایههای مخفی و خروجی، باید تعداد واحدها و تابع فعالسازی را مشخص کنیم. به طور کلی، هرچه تعداد واحدها در یک لایه بیشتر باشد، شبکه قادر به یادگیری الگوهای پیچیدهتر خواهد بود. با این حال، تعداد زیاد واحدها ممکن است باعث بیشبرازش (overfitting) شبکه به دادههای آموزشی شود که به عملکرد در دادههای آزمایشی آسیب میرساند.
برای لایههای مخفی، یک تابع فعالسازی محبوب، واحد خطی اصلاحشده (ReLU) است:
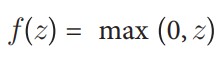
که در آن z مجموع ورودیهای وزندار و بایاس است. اگر z بزرگتر از صفر باشد، تابع فعالسازی مقدار z را برمیگرداند؛ در غیر این صورت، صفر برمیگرداند. این تابع فعالسازی ساده دارای ویژگیهای مطلوبی است (که بحث در مورد آنها خارج از دامنه این کتاب است) و به همین دلیل در شبکههای عصبی بسیار محبوب است. با این حال، باید بدانیم که دهها تابع فعالسازی دیگر نیز وجود دارند.
دوم، باید تعداد لایههای مخفی در شبکه را مشخص کنیم. لایههای بیشتر به شبکه اجازه میدهند روابط پیچیدهتری را یاد بگیرند، اما این کار هزینه محاسباتی بیشتری دارد.
سوم، باید ساختار تابع فعالسازی (در صورت وجود) برای لایه خروجی را تعریف کنیم. ماهیت تابع خروجی اغلب به هدف شبکه بستگی دارد. الگوهای رایج برای لایه خروجی عبارتند از:
طبقهبندی باینری: یک واحد با تابع فعالسازی سیگموید.
طبقهبندی چندکلاسه: k واحد (که k تعداد کلاسهای هدف است) و تابع فعالسازی سافتمکس(softmax).
رگرسیون: یک واحد بدون تابع فعالسازی.
چهارم، باید یک تابع زیان تعریف کنیم (تابعی که میزان تطابق مقدار پیشبینیشده با مقدار واقعی را میسنجد)؛ این نیز اغلب به نوع مسئله بستگی دارد:
طبقهبندی باینری: آنتروپی متقاطع باینری(Binary cross-entropy).
طبقهبندی چندکلاسه: آنتروپی متقاطع دستهای(Categorical cross-entropy).
رگرسیون: خطای میانگین مربعات(Mean square error).
پنجم، باید یک بهینهساز تعریف کنیم، که به طور شهودی میتوان آن را بهعنوان استراتژی ما برای "گشتن" در تابع زیان برای یافتن مقادیر پارامتری در نظر گرفت که کمترین خطا را تولید میکنند. انتخابهای رایج برای بهینهسازها شامل گرادیان کاهشی تصادفی(stochastic gradient descent)، گرادیان کاهشی تصادفی با تکانه(stochastic gradient descent with momentum)، انتشار میانگین مربعات ریشه(root mean square propagation)، و تخمین لحظه تطبیقی(adaptive moment estimation) است.
ششم، میتوانیم یک یا چند معیار برای ارزیابی عملکرد، مانند دقت (accuracy)، انتخاب کنیم.
در مثال ما، از فضای نام torch.nn.Module برای ساخت یک شبکه عصبی ساده و متوالی استفاده میکنیم که قادر به انجام طبقهبندی باینری است. روش استاندارد پایتورچ برای این کار، ایجاد یک کلاس فرزند است که از کلاس torch.nn.Module ارث میبرد، معماری شبکه را در متد init تعریف میکند و عملیات ریاضی که میخواهیم در هر عبور رو به جلو انجام شود را در متد forward کلاس تعریف میکند. روشهای زیادی برای تعریف شبکهها در پایتورچ وجود دارد، و اگرچه در این مورد از روشهای تابعی برای توابع فعالسازی (مانند nn.functional.relu) استفاده میکنیم، میتوانیم این توابع فعالسازی را بهعنوان لایه نیز تعریف کنیم. اگر بخواهیم همه چیز را در شبکه بهعنوان لایه تعریف کنیم، میتوانیم از کلاس Sequential استفاده کنیم:
# Import libraries
import torch
# Define a neural network using Sequential
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, 16),
torch.nn.ReLU(),
torch.nn.Linear(16,16),
torch.nn.ReLU(),
torch.nn.Linear(16, 1),
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.sequential(x)
return x
# Instantiate and view the network
SimpleNeuralNet() خروجی:
SimpleNeuralNet(
(sequential): Sequential(
(0): Linear(in_features=10, out_features=16, bias=True)
(1): ReLU()
(2): Linear(in_features=16, out_features=16, bias=True)
(3): ReLU()
(4): Linear(in_features=16, out_features=1, bias=True)
(5): Sigmoid()
)
)در هر دو حالت، شبکه یک شبکه عصبی دو لایه است (هنگام شمارش لایهها، لایه ورودی را حساب نمیکنیم زیرا هیچ پارامتری برای یادگیری ندارد) که با استفاده از مدل متوالی پایتورچ تعریف شده است. هر لایه متراکم (dense) یا کاملاً متصل (fully connected) است، به این معنی که تمام واحدها در لایه قبلی به تمام واحدها در لایه بعدی متصل هستند.
در لایه مخفی اول، out_features=16 تنظیم شده است، به این معنی که این لایه شامل 16 واحد است. این واحدها دارای توابع فعالسازی ReLU هستند که در متد forward کلاس تعریف شدهاند:
x = nn.functional.relu(self.fc1(x))
لایه اول شبکه ما اندازه (10, 16) دارد، که به لایه اول میگوید انتظار داشته باشد هر مشاهده از دادههای ورودی 10 مقدار ویژگی داشته باشد. این شبکه برای طبقهبندی باینری طراحی شده است، بنابراین لایه خروجی تنها یک واحد با تابع فعالسازی سیگموید دارد که خروجی را به مقداری بین 0 و 1 محدود میکند (که نشاندهنده احتمال تعلق یک مشاهده به کلاس 1 است).
21.4 آموزش یک طبقهبند دودویی
مسئله
میخواهید یک شبکه عصبی طبقهبند دودویی را آموزش دهید.
راهحل
از PyTorch برای ساخت یک شبکه عصبی پیشخور (feedforward) استفاده کنید و آن را آموزش دهید.
# Import libraries
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
from torch.optim import RMSprop
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training and test sets
features, target = make_classification(n_classes=2, n_features=10, n_samples=1000)
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Set random seed
torch.manual_seed(0)
np.random.seed(0)
# Convert data to PyTorch tensors
x_train = torch.from_numpy(features_train).float()
y_train = torch.from_numpy(target_train).float().view(-1, 1)
x_test = torch.from_numpy(features_test).float()
y_test = torch.from_numpy(target_test).float().view(-1, 1)
# Define a neural network using Sequential
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, 16),
torch.nn.ReLU(),
torch.nn.Linear(16,16),
torch.nn.ReLU(),
torch.nn.Linear(16, 1),
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.sequential(x)
return x
# Initialize neural network
network = SimpleNeuralNet()
# Define loss function, optimizer
criterion = nn.BCELoss()
optimizer = RMSprop(network.parameters())
# Define data loader
train_data = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
# Compile the model using torch 2.0's optimizer
network = torch.compile(network)
# Train neural network
epochs = 3
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print("Epoch:", epoch+1, "\tLoss:", loss.item())
# Evaluate neural network
with torch.no_grad():
output = network(x_test)
test_loss = criterion(output, y_test)
test_accuracy = (output.round() == y_test).float().mean()
print("Test Loss:", test_loss.item(), "\tTest Accuracy:", test_accuracy.item()) خروجی:
Epoch: 1 Loss: 0.19006995856761932
Epoch: 2 Loss: 0.14092367887496948
Epoch: 3 Loss: 0.03935524448752403
Test Loss: 0.06877756118774414 Test Accuracy: 0.9700000286102295 توضیحات
در دستورالعمل 21.3، نحوه ساخت یک شبکه عصبی با استفاده از مدل Sequential در PyTorch توضیح داده شد. در این دستورالعمل، ما همان شبکه عصبی را با استفاده از 10 ویژگی و 1000 نمونه داده تقلبی برای طبقهبندی، که با تابع make_classification از scikit-learn تولید شدهاند، آموزش میدهیم.
شبکه عصبی استفادهشده در اینجا همان شبکهای است که در دستورالعمل 21.3 توضیح داده شد (برای جزئیات بیشتر به آن دستورالعمل مراجعه کنید). تفاوت در این است که در آنجا فقط شبکه را ایجاد کردیم و آن را آموزش ندادیم.
در پایان، از ()with torch.no_grad برای ارزیابی شبکه استفاده میکنیم. این دستور مشخص میکند که نباید گرادیانها برای عملیات تنسور در این بخش از کد محاسبه شوند. از آنجا که گرادیانها فقط در فرآیند آموزش مدل استفاده میشوند، نمیخواهیم گرادیانهای جدیدی برای عملیات خارج از فرآیند آموزش (مانند پیشبینی یا ارزیابی) ذخیره شوند.
متغیر epochs تعداد دورههای (epochs) مورد استفاده برای آموزش دادهها را مشخص میکند.
batch_size تعداد نمونههایی را تعیین میکند که قبل از بهروزرسانی پارامترها از طریق شبکه منتشر میشوند.
سپس، برای تعداد دورههای مشخصشده، شبکه را با استفاده از متد forward برای عبور رو به جلو و سپس عبور رو به عقب برای بهروزرسانی گرادیانها، آموزش میدهیم.
نتیجه، یک مدل آموزشدیده است.
21.5 آموزش یک طبقهبندیکننده چندکلاسی
مسئله
میخواهید یک شبکه عصبی طبقهبندیکننده چندکلاسی را آموزش دهید.
راهحل
از PyTorch برای ساخت یک شبکه عصبی پیشخور (feedforward) با لایه خروجی دارای تابع فعالسازی softmax استفاده کنید.
# Import libraries
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
from torch.optim import RMSprop
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
N_CLASSES=3
EPOCHS=3
# Create training and test sets
features, target = make_classification(n_classes=N_CLASSES, n_informative=9,
n_redundant=0, n_features=10, n_samples=1000)
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Set random seed
torch.manual_seed(0)
np.random.seed(0)
# Convert data to PyTorch tensors
x_train = torch.from_numpy(features_train).float()
y_train = torch.nn.functional.one_hot(torch.from_numpy(target_train).long(),
num_classes=N_CLASSES).float()
x_test = torch.from_numpy(features_test).float()
y_test = torch.nn.functional.one_hot(torch.from_numpy(target_test).long(),
num_classes=N_CLASSES).float()
# Define a neural network using Sequential
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, 16),
torch.nn.ReLU(),
torch.nn.Linear(16,16),
torch.nn.ReLU(),
torch.nn.Linear(16,3),
torch.nn.Softmax()
)
def forward(self, x):
x = self.sequential(x)
return x
# Initialize neural network
network = SimpleNeuralNet()
# Define loss function, optimizer
criterion = nn.CrossEntropyLoss()
optimizer = RMSprop(network.parameters())
# Define data loader
train_data = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
# Compile the model using torch 2.0's optimizer
network = torch.compile(network)
# Train neural network
for epoch in range(EPOCHS):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print("Epoch:", epoch+1, "\tLoss:", loss.item())
# Evaluate neural network
with torch.no_grad():
output = network(x_test)
test_loss = criterion(output, y_test)
test_accuracy = (output.round() == y_test).float().mean()
print("Test Loss:", test_loss.item(), "\tTest Accuracy:",
test_accuracy.item())خروجی:
Epoch: 1 Loss: 0.8022041916847229
Epoch: 2 Loss: 0.775616466999054
Epoch: 3 Loss: 0.7751263380050659
Test Loss: 0.8105319142341614 Test Accuracy: 0.8199999928474426توضیحات
در این راهحل، ما شبکه عصبی مشابهی با طبقهبندیکننده دوکلاسی (باینری) از مثال قبلی ساختیم، اما با تغییراتی قابل توجه. در دادههای طبقهبندی که تولید کردیم، تعداد کلاسها را ۳ تعیین کردیم (N_CLASSES=3). برای مدیریت طبقهبندی چندکلاسی، از تابع زیان ()nn.CrossEntropyLoss استفاده کردیم که انتظار دارد هدف (target) بهصورت one-hot encoded باشد. برای این کار، از تابع torch.nn.functional.one_hot استفاده کردیم که نتیجهاش یک آرایه one-hot encoded است؛ در این آرایه، موقعیت عدد ۱ نشاندهنده کلاس مربوط به یک مشاهده است.
# View target matrix
y_train خروجی:
tensor([[1., 0., 0.],
[0., 1., 0.],
[1., 0., 0.],
...,
[0., 1., 0.],
[1., 0., 0.],
[0., 0., 1.]]) از آنجا که این یک مسئله طبقهبندی چندکلاسی است، از یک لایه خروجی با اندازه ۳ (یکی برای هر کلاس) استفاده کردیم که شامل تابع فعالسازی softmax است. تابع softmax آرایهای از ۳ مقدار تولید میکند که مجموع آنها برابر با ۱ است. این ۳ مقدار نشاندهنده احتمال تعلق یک مشاهده به هر یک از ۳ کلاس است.
همانطور که در این مثال اشاره شد، از تابع زیان مناسب برای طبقهبندی چندکلاسی، یعنی تابع زیان دستهای متقاطع (categorical cross-entropy loss) با نام ()nn.CrossEntropyLoss استفاده کردیم.
21.6 آموزش یک مدل رگرسیون
مسئله
میخواهید یک شبکه عصبی برای انجام رگرسیون آموزش دهید.
راهحل
با استفاده از PyTorch یک شبکه عصبی پیشخور (feedforward) بسازید که دارای یک واحد خروجی بدون تابع فعالسازی باشد.
# Import libraries
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
from torch.optim import RMSprop
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
EPOCHS=5
# Create training and test sets
features, target = make_regression(n_features=10, n_samples=1000)
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Set random seed
torch.manual_seed(0)
np.random.seed(0)
# Convert data to PyTorch tensors
x_train = torch.from_numpy(features_train).float()
y_train = torch.from_numpy(target_train).float().view(-1,1)
x_test = torch.from_numpy(features_test).float()
y_test = torch.from_numpy(target_test).float().view(-1,1)
# Define a neural network using `Sequential`
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, 16),
torch.nn.ReLU(),
torch.nn.Linear(16,16),
torch.nn.ReLU(),
torch.nn.Linear(16,1),
)
def forward(self, x):
x = self.sequential(x)
return x
# Initialize neural network
network = SimpleNeuralNet()
# Define loss function, optimizer
criterion = nn.MSELoss()
optimizer = RMSprop(network.parameters())
# Define data loader
train_data = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
# Compile the model using torch 2.0's optimizer
network = torch.compile(network)
# Train neural network
for epoch in range(EPOCHS):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print("Epoch:", epoch+1, "\tLoss:", loss.item())
# Evaluate neural network
with torch.no_grad():
output = network(x_test)
test_loss = float(criterion(output, y_test))
print("Test MSE:", test_loss)خروجی:
Epoch: 1 Loss: 10764.02734375
Epoch: 2 Loss: 1356.510009765625
Epoch: 3 Loss: 504.9664306640625
Epoch: 4 Loss: 199.11314392089844
Epoch: 5 Loss: 191.20834350585938
Test MSE: 162.24497985839844 توضیحات
میتوان یک شبکه عصبی را برای پیشبینی مقادیر پیوسته (به جای احتمالات کلاس) طراحی کرد. در مورد طبقهبندی باینری (دستور 21.4)، ما از یک لایه خروجی با یک واحد و تابع فعالسازی سیگموید استفاده کردیم تا احتمالی بین 0 و 1 برای کلاس 1 تولید شود. تابع سیگموید باعث محدود شدن خروجی به بازه 0 تا 1 میشود. اما اگر این تابع فعالسازی را حذف کنیم، خروجی میتواند یک مقدار پیوسته باشد.
علاوه بر این، چون هدف ما رگرسیون است، باید از یک تابع زیان مناسب و معیار ارزیابی مناسب استفاده کنیم، در اینجا خطای میانگین مربعات (MSE):
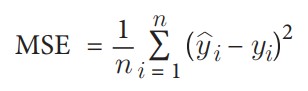
که در آن n تعداد مشاهدات است، y_i مقدار واقعی هدف برای مشاهده i است، و hat{y}_i مقدار پیشبینیشده توسط مدل برای y_i است.
در نهایت، چون در اینجا از دادههای شبیهسازیشده با تابع make_regression از scikit-learn استفاده شده، نیازی به استانداردسازی ویژگیها نبود. اما باید توجه داشت که در تقریباً تمام موارد واقعی، استانداردسازی ویژگیها ضروری است.
21.7 انجام پیشبینیها
مسئله
میخواهید از یک شبکه عصبی برای انجام پیشبینی استفاده کنید.
راهحل
با استفاده از PyTorch یک شبکه عصبی پیشخور (feedforward) بسازید و سپس با استفاده از متد forward پیشبینیها را انجام دهید.
# Import libraries
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
from torch.optim import RMSprop
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training and test sets
features, target = make_classification(n_classes=2, n_features=10, n_samples=1000)
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Set random seed
torch.manual_seed(0)
np.random.seed(0)
# Convert data to PyTorch tensors
x_train = torch.from_numpy(features_train).float()
y_train = torch.from_numpy(target_train).float().view(-1, 1)
x_test = torch.from_numpy(features_test).float()
y_test = torch.from_numpy(target_test).float().view(-1, 1)
# Define a neural network using Sequential
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, 16),
torch.nn.ReLU(),
torch.nn.Linear(16,16),
torch.nn.ReLU(),
torch.nn.Linear(16, 1),
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.sequential(x)
return x
# Initialize neural network
network = SimpleNeuralNet()
# Define loss function, optimizer
criterion = nn.BCELoss()
optimizer = RMSprop(network.parameters())
# Define data loader
train_data = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
# Compile the model using torch 2.0's optimizer
network = torch.compile(network)
# Train neural network
epochs = 3
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print("Epoch:", epoch+1, "\tLoss:", loss.item())
# Evaluate neural network
with torch.no_grad():
predicted_class = network.forward(x_train).round()
predicted_class[0]خروجی:
Epoch: 1 Loss: 0.19006995856761932
Epoch: 2 Loss: 0.14092367887496948
Epoch: 3 Loss: 0.03935524448752403
tensor([1.])
توضیحات
انجام پیشبینی در PyTorch ساده است. پس از آموزش شبکه عصبی، میتوانیم از متد forward (که در فرآیند آموزش نیز استفاده شده) استفاده کنیم. این متد مجموعهای از ویژگیها را به عنوان ورودی میگیرد و یک گذر رو به جلو (forward pass) در شبکه انجام میدهد. در این راهحل، شبکه عصبی برای طبقهبندی باینری تنظیم شده است، بنابراین خروجی پیشبینیشده، احتمال تعلق به کلاس 1 است. مشاهداتی که مقادیر پیشبینیشده آنها بسیار نزدیک به 1 باشد، به احتمال زیاد متعلق به کلاس 1 هستند، و مشاهداتی که مقادیر پیشبینیشده آنها بسیار نزدیک به 0 باشد، به احتمال زیاد متعلق به کلاس 0 هستند. به همین دلیل، از متد round استفاده میکنیم تا این مقادیر را به 1 و 0 برای طبقهبندی باینری تبدیل کنیم.
21.8 نمایش تاریخچه آموزش
مسئله
شما میخواهید «نقطه بهینه» در امتیاز خطا و یا دقت یک شبکه عصبی را پیدا کنید.
راهحل
از Matplotlib استفاده کنید تا خطای مجموعه آموزشی و آزمایشی را در هر دوره (epoch) بهصورت بصری نمایش دهید.
# Import libraries
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from torch.optim import RMSprop
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
# Create training and test sets
features, target = make_classification(n_classes=2, n_features=10, n_samples=1000)
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Set random seed
torch.manual_seed(0)
np.random.seed(0)
# Convert data to PyTorch tensors
x_train = torch.from_numpy(features_train).float()
y_train = torch.from_numpy(target_train).float().view(-1, 1)
x_test = torch.from_numpy(features_test).float()
y_test = torch.from_numpy(target_test).float().view(-1, 1)
# Define a neural network using Sequential
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, 16),
torch.nn.ReLU(),
torch.nn.Linear(16,16),
torch.nn.ReLU(),
torch.nn.Linear(16, 1),
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.sequential(x)
return x
# Initialize neural network
network = SimpleNeuralNet()
# Define loss function, optimizer
criterion = nn.BCELoss()
optimizer = RMSprop(network.parameters())
# Define data loader
train_data = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
# Compile the model using torch 2.0's optimizer
network = torch.compile(network)
# Train neural network
epochs = 8
train_losses = []
test_losses = []
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
with torch.no_grad():
train_output = network(x_train)
train_loss = criterion(output, target)
train_losses.append(train_loss.item())
test_output = network(x_test)
test_loss = criterion(test_output, y_test)
test_losses.append(test_loss.item())
# Visualize loss history
epochs = range(0, epochs)
plt.plot(epochs, train_losses, "r--")
plt.plot(epochs, test_losses, "b-")
plt.legend(["Training Loss", "Test Loss"])
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show();خروجی:
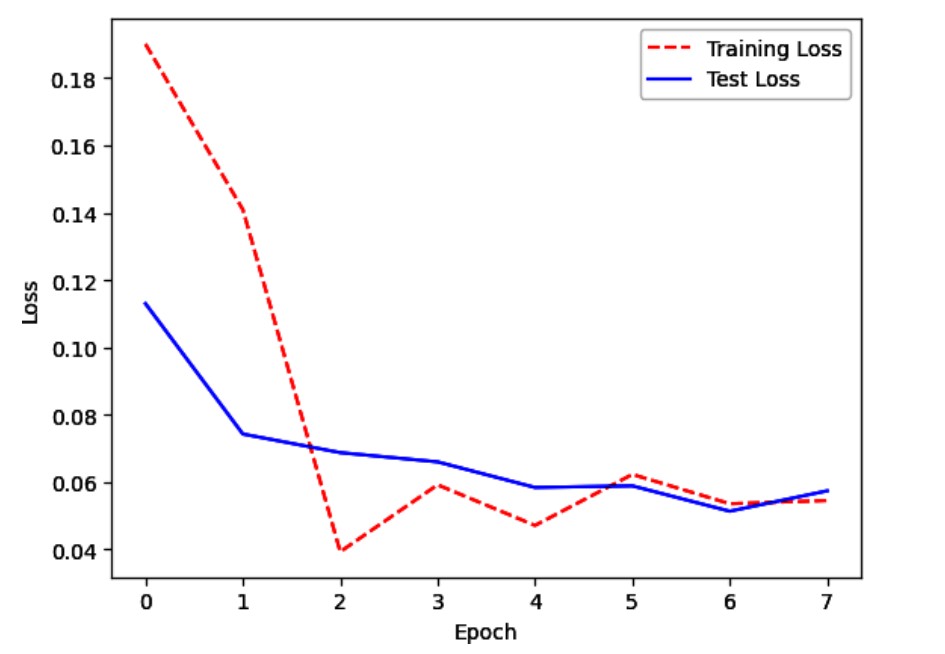
توضیحات
وقتی یک شبکه عصبی تازه ساخته شده است، عملکرد ضعیفی دارد. با یادگیری شبکه عصبی روی دادههای آموزشی، خطای مدل هم در مجموعه آموزشی و هم در مجموعه آزمایشی معمولاً کاهش مییابد. اما در نقطهای خاص، شبکه عصبی ممکن است شروع به «حفظ کردن» دادههای آموزشی کند و بیشازحد برازش (overfit) شود. وقتی این اتفاق میافتد، خطای آموزشی ممکن است همچنان کاهش یابد، اما خطای آزمایشی شروع به افزایش میکند. بنابراین، در بسیاری از موارد، یک «نقطه بهینه» وجود دارد که در آن خطای آزمایشی (که بیشتر به آن اهمیت میدهیم) در پایینترین سطح خود قرار دارد. این اثر در راهحل نشان داده شده است، جایی که خطای آموزشی و آزمایشی در هر دوره بهصورت بصری نمایش داده میشود. توجه کنید که خطای آزمایشی در حدود دوره ششم کمترین مقدار را دارد، اما پس از آن، خطای آموزشی به حالت ثابت میرسد، در حالی که خطای آزمایشی شروع به افزایش میکند. از این نقطه به بعد، مدل در حال بیشبرازش است.
21.9 کاهش بیشبرازش با منظمسازی وزنها
مسئله
میخواهید با منظمسازی وزنهای شبکه، بیشبرازش را کاهش دهید.
راهحل
سعی کنید پارامترهای شبکه را جریمه کنید، که به آن منظمسازی وزنها (weight regularization) نیز گفته میشود.
# Import libraries
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
from torch.optim import RMSprop
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training and test sets
features, target = make_classification(n_classes=2, n_features=10, n_samples=1000)
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Set random seed
torch.manual_seed(0)
np.random.seed(0)
# Convert data to PyTorch tensors
x_train = torch.from_numpy(features_train).float()
y_train = torch.from_numpy(target_train).float().view(-1, 1)
x_test = torch.from_numpy(features_test).float()
y_test = torch.from_numpy(target_test).float().view(-1, 1)
# Define a neural network using Sequential
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, 16),
torch.nn.ReLU(),
torch.nn.Linear(16,16),
torch.nn.ReLU(),
torch.nn.Linear(16, 1),
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.sequential(x)
return x
# Initialize neural network
network = SimpleNeuralNet()
# Define loss function, optimizer
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(network.parameters(), lr=1e-4, weight_decay=1e-5)
# Define data loader
train_data = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
# Compile the model using torch 2.0's optimizer
network = torch.compile(network)
# Train neural network
epochs = 100
train_losses = []
test_losses = []
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# Evaluate neural network
with torch.no_grad():
output = network(x_test)
test_loss = criterion(output, y_test)
test_accuracy = (output.round() == y_test).float().mean()
print("Test Loss:", test_loss.item(), "\tTest Accuracy:",
test_accuracy.item())خروجی:
Test Loss: 0.4030887186527252 Test Accuracy: 0.9599999785423279 توضیحات
یکی از راههای مقابله با بیشبرازش در شبکههای عصبی، جریمه کردن پارامترها (یعنی وزنها) است بهگونهای که مقادیر آنها کوچک شوند. این کار باعث ایجاد مدلی سادهتر میشود که کمتر در معرض بیشبرازش قرار میگیرد. این روش به نام منظمسازی وزنها یا وزنکاهی (weight decay) شناخته میشود. بهطور خاص، در منظمسازی وزنها، یک جریمه (مانند نرم L2) به تابع خطا اضافه میشود.
در PyTorch، میتوانیم منظمسازی وزنها را با افزودن weight_decay=1e-5 به بهینهساز (optimizer) اعمال کنیم، جایی که منظمسازی انجام میشود. در این مثال، مقدار 1e-5 تعیین میکند که چقدر وزنهای بزرگتر جریمه شوند. مقادیر بزرگتر از ۰ در PyTorch نشاندهنده استفاده از منظمسازی L2 است.
21.10 کاهش بیشبرازش با توقف زودهنگام
مسئله
میخواهید با توقف آموزش در زمانی که امتیازهای مجموعه آموزشی و آزمایشی از هم فاصله میگیرند، بیشبرازش را کاهش دهید.
راهحل
از PyTorch Lightning استفاده کنید تا استراتژیای به نام توقف زودهنگام (early stopping) را پیادهسازی کنید.
# Import libraries
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
from torch.optim import RMSprop
import lightning as pl
from lightning.pytorch.callbacks.early_stopping import EarlyStopping
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training and test sets
features, target = make_classification(n_classes=2, n_features=10, n_samples=1000)
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Set random seed
torch.manual_seed(0)
np.random.seed(0)
# Convert data to PyTorch tensors
x_train = torch.from_numpy(features_train).float()
y_train = torch.from_numpy(target_train).float().view(-1, 1)
x_test = torch.from_numpy(features_test).float()
y_test = torch.from_numpy(target_test).float().view(-1, 1)
# Define a neural network using Sequential
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, 16),
torch.nn.ReLU(),
torch.nn.Linear(16,16),
torch.nn.ReLU(),
torch.nn.Linear(16, 1),
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.sequential(x)
return x
class LightningNetwork(pl.LightningModule):
def __init__(self, network):
super().__init__()
self.network = network
self.criterion = nn.BCELoss()
self.metric = nn.functional.binary_cross_entropy
def training_step(self, batch, batch_idx):
# training_step defines the train loop.
data, target = batch
output = self.network(data)
loss = self.criterion(output, target)
self.log("val_loss", loss)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=1e-3)
# Define data loader
train_data = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
# Initialize neural network
network = LightningNetwork(SimpleNeuralNet())
# Train network
trainer = pl.Trainer(callbacks=[EarlyStopping(monitor="val_loss", mode="min",
patience=3)], max_epochs=1000)
trainer.fit(model=network, train_dataloaders=train_loader)خروجی:
GPU available: False, used: False
TPU available: False, using: 0 TPU cores IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
----------------------------------------------
0 | network | SimpleNeuralNet | 465
1 | criterion | BCELoss | 0
----------------------------------------------
465 Trainable params
0 Non-trainable params
465 Total params
0.002 Total estimated model params size (MB)
/usr/local/lib/python3.10/site-packages/lightning/pytorch/trainer/
connectors/data_connector.py:224: PossibleUserWarning:
The dataloader, train_dataloader, does not have many workers which
may be a bottleneck. Consider increasing the value of the `num_workers`
argument (try 7 which is the number of cpus on this machine)
in the `DataLoader` init to improve performance.
rank_zero_warn(
/usr/local/lib/python3.10/site-packages/lightning/pytorch/trainer/
trainer.py:1609: PossibleUserWarning: The number of training batches (9)
is smaller than the logging interval Trainer(log_every_n_steps=50).
Set a lower value for log_every_n_steps if you want to see logs
for the training epoch.
rank_zero_warn(
Epoch 23: 100%|███████████████| 9/9 [00:00<00:00, 59.29it/s, loss=0.147, v_num=5]توضیحات
همانطور که در بخش 21.8 بحث شد، معمولاً در چند دوره (epoch) ابتدایی آموزش، خطای مجموعه آموزشی و آزمایشی هر دو کاهش مییابد. اما در نقطهای، شبکه شروع به «حفظ کردن» دادههای آموزشی میکند، که باعث میشود خطای آموزشی همچنان کاهش یابد، در حالی که خطای آزمایشی شروع به افزایش میکند. به همین دلیل، یکی از رایجترین و مؤثرترین روشها برای مقابله با بیشبرازش، نظارت بر فرآیند آموزش و توقف آن در زمانی است که خطای آزمایشی شروع به افزایش میکند. این استراتژی به نام توقف زودهنگام شناخته میشود.
در PyTorch، میتوانیم توقف زودهنگام را بهصورت یک تابع callback پیادهسازی کنیم. توابع callback، توابعی هستند که در مراحل خاصی از فرآیند آموزش، مثلاً در پایان هر دوره، اجرا میشوند. با این حال، PyTorch بهصورت پیشفرض کلاسی برای توقف زودهنگام ارائه نمیدهد، بنابراین در اینجا از کتابخانه محبوب PyTorch Lightning استفاده میکنیم که این قابلیت را بهصورت آماده ارائه میدهد. PyTorch Lightning یک کتابخانه سطح بالا برای PyTorch است که ویژگیهای مفید زیادی را فراهم میکند. در راهحل ما، از
EarlyStopping(monitor="val_loss", mode="min", patience=3) استفاده شده است تا مشخص کنیم که میخواهیم خطای آزمایشی (validation loss) را در هر دوره نظارت کنیم، و اگر این خطا پس از سه دوره (بهصورت پیشفرض) بهبود نیابد، آموزش متوقف شود.
اگر از callback توقف زودهنگام را استفاده نمیکردیم، مدل تا پایان حداکثر تعداد دورهها (مثلاً 1000 دوره) بدون توقف خودکار به آموزش ادامه میداد.
# Train network
trainer = pl.Trainer(max_epochs=1000)
trainer.fit(model=network, train_dataloaders=train_loader) خروجی:
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
| Name | Type | Params
----------------------------------------------
0 | network | SimpleNeuralNet | 465
1 | criterion | BCELoss | 0
----------------------------------------------
465 Trainable params
0 Non-trainable params
465 Total params
0.002 Total estimated model params size (MB)
Epoch 999: 100%|████████████| 9/9 [00:01<00:00, 7.95it/s, loss=0.00188, v_num=6]
`Trainer.fit` stopped: `max_epochs=1000` reached.
Epoch 999: 100%|████████████| 9/9 [00:01<00:00, 7.80it/s, loss=0.00188, v_num=6]21.11 کاهش بیشبرازش با دراپاوت
مسئله
میخواهید بیشبرازش را کاهش دهید.
راهحل
با استفاده از دراپاوت (dropout)، نویز را به معماری شبکه خود اضافه کنید.
# Load libraries
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
from torch.optim import RMSprop
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training and test sets
features, target = make_classification(n_classes=2, n_features=10, n_samples=1000)
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Set random seed
torch.manual_seed(0)
np.random.seed(0)
# Convert data to PyTorch tensors
x_train = torch.from_numpy(features_train).float()
y_train = torch.from_numpy(target_train).float().view(-1, 1)
x_test = torch.from_numpy(features_test).float()
y_test = torch.from_numpy(target_test).float().view(-1, 1)
# Define a neural network using Sequential
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, 16),
torch.nn.ReLU(),
torch.nn.Linear(16,16),
torch.nn.ReLU(),
torch.nn.Linear(16, 1),
torch.nn.Dropout(0.1), # Drop 10% of neurons
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.sequential(x)
return x
# Initialize neural network
network = SimpleNeuralNet()
# Define loss function, optimizer
criterion = nn.BCELoss()
optimizer = RMSprop(network.parameters())
# Define data loader
train_data = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
# Compile the model using torch 2.0's optimizer
network = torch.compile(network)
# Train neural network
epochs = 3
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print("Epoch:", epoch+1, "\tLoss:", loss.item())
# Evaluate neural network
with torch.no_grad():
output = network(x_test)
test_loss = criterion(output, y_test)
test_accuracy = (output.round() == y_test).float().mean()
print("Test Loss:", test_loss.item(), "\tTest Accuracy:",
test_accuracy.item())خروجی:
Epoch: 1 Loss: 0.18791493773460388
Epoch: 2 Loss: 0.17331615090370178
Epoch: 3 Loss: 0.1384529024362564
Test Loss: 0.12702330946922302 Test Accuracy: 0.9100000262260437
توضیحات
دراپاوت یک روش رایج برای منظمسازی شبکههای عصبی کوچکتر است. در این روش، هر بار که یک دسته (batch) از دادهها برای آموزش آماده میشود، درصدی از واحدها (نرونها) در یک یا چند لایه بهصورت تصادفی با صفر ضرب میشوند (یعنی حذف یا «دراپ» میشوند). در این حالت، هر دسته روی همان شبکه (با پارامترهای یکسان) آموزش میبیند، اما هر دسته با نسخهای کمی متفاوت از معماری شبکه روبهرو میشود.
دراپاوت به این دلیل مؤثر است که با حذف تصادفی واحدهای هر دسته، واحدهای شبکه را مجبور میکند تا مقادیر پارامترهایی را یاد بگیرند که در معماریهای مختلف شبکه عملکرد خوبی داشته باشند. به عبارت دیگر، این روش باعث میشود واحدهای شبکه در برابر اختلالات (نویز) در واحدهای مخفی دیگر مقاوم شوند و این کار از حفظ کردن صرف دادههای آموزشی توسط شبکه جلوگیری میکند.
میتوان دراپاوت را هم به لایههای مخفی و هم به لایه ورودی اعمال کرد. وقتی لایه ورودی حذف میشود، مقدار ویژگیهای آن برای آن دسته به شبکه وارد نمیشود.
در PyTorch، میتوانیم دراپاوت را با افزودن یک لایه nn.Dropout به معماری شبکه پیادهسازی کنیم. هر لایه nn.Dropout درصدی از واحدهای لایه قبلی را در هر دسته، بر اساس یک هایپرپارامتر تعریفشده توسط کاربر، حذف میکند.
21.12 ذخیره پیشرفت آموزش مدل
مسئله
با توجه به اینکه آموزش یک شبکه عصبی ممکن است زمان زیادی طول بکشد، میخواهید پیشرفت آموزش را ذخیره کنید تا در صورت وقفه در فرآیند آموزش، کار از دست نرود.
راهحل
از تابع torch.save استفاده کنید تا مدل را پس از هر دوره (epoch) ذخیره کنید.
# Load libraries
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
from torch.optim import RMSprop
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training and test sets
features, target = make_classification(n_classes=2, n_features=10, n_samples=1000)
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Set random seed
torch.manual_seed(0)
np.random.seed(0)
# Convert data to PyTorch tensors
x_train = torch.from_numpy(features_train).float()
y_train = torch.from_numpy(target_train).float().view(-1, 1)
x_test = torch.from_numpy(features_test).float()
y_test = torch.from_numpy(target_test).float().view(-1, 1)
# Define a neural network using Sequential
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, 16),
torch.nn.ReLU(),
torch.nn.Linear(16,16),
torch.nn.ReLU(),
torch.nn.Linear(16, 1),
torch.nn.Dropout(0.1), # Drop 10% of neurons
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.sequential(x)
return x
# Initialize neural network
network = SimpleNeuralNet()
# Define loss function, optimizer
criterion = nn.BCELoss()
optimizer = RMSprop(network.parameters())
# Define data loader
train_data = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
# Compile the model using torch 2.0's optimizer
network = torch.compile(network)
# Train neural network
epochs = 5
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# Save the model at the end of every epoch
torch.save(
{
'epoch': epoch,
'model_state_dict': network.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
},
"model.pt"
)
print("Epoch:", epoch+1, "\tLoss:", loss.item())خروجی:
Epoch: 1 Loss: 0.18791493773460388
Epoch: 2 Loss: 0.17331615090370178
Epoch: 3 Loss: 0.1384529024362564
Epoch: 4 Loss: 0.1435958743095398
Epoch: 5 Loss: 0.17967987060546875 توضیحات
در دنیای واقعی، آموزش شبکههای عصبی ممکن است ساعتها یا حتی روزها طول بکشد. در این مدت، مشکلات زیادی ممکن است رخ دهد: کامپیوتر ممکن است خاموش شود، سرورها ممکن است از کار بیفتند، یا یک دانشجوی بیملاحظه لپتاپ شما را ببندد.
برای رفع این مشکل، میتوانیم از torch.save استفاده کنیم تا مدل را پس از هر دوره ذخیره کنیم. بهطور خاص، پس از هر دوره، مدل را در مکان مشخصشدهای مثل model.pt (آرگومان دوم تابع torch.save) ذخیره میکنیم. اگر فقط یک نام فایل (مثل model.pt) مشخص کنیم، این فایل در هر دوره با آخرین مدل بازنویسی میشود.
همانطور که میتوانید تصور کنید، میتوانیم منطق بیشتری اضافه کنیم، مثلاً مدل را هر چند دوره یکبار ذخیره کنیم، یا فقط زمانی مدل را ذخیره کنیم که خطا کاهش یافته باشد. حتی میتوانیم این رویکرد را با روش توقف زودهنگام (early stopping) در PyTorch Lightning ترکیب کنیم تا مطمئن شویم مدل در هر دورهای که آموزش متوقف شود، ذخیره میشود.
21.13 تنظیم شبکههای عصبی
مسئله
میخواهید بهترین هایپرپارامترها را برای شبکه عصبی خود بهصورت خودکار انتخاب کنید.
راهحل
از کتابخانه تنظیم Ray با PyTorch استفاده کنید.
# Load libraries
from functools import partial
import numpy as np
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.optim import RMSprop
from torch.utils.data import random_split, DataLoader, TensorDataset
from ray import tune
from ray.tune import CLIReporter
from ray.tune.schedulers import ASHAScheduler
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training and test sets
features, target = make_classification(n_classes=2, n_features=10,
n_samples=1000)
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Set random seed
torch.manual_seed(0)
np.random.seed(0)
# Convert data to PyTorch tensors
x_train = torch.from_numpy(features_train).float()
y_train = torch.from_numpy(target_train).float().view(-1, 1)
x_test = torch.from_numpy(features_test).float()
y_test = torch.from_numpy(target_test).float().view(-1, 1)
# Define a neural network using `Sequential`
class SimpleNeuralNet(nn.Module):
def __init__(self, layer_size_1=10, layer_size_2=10):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, layer_size_1),
torch.nn.ReLU(),
torch.nn.Linear(layer_size_1, layer_size_2),
torch.nn.ReLU(),
torch.nn.Linear(layer_size_2, 1),
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.sequential(x)
return x
config = {
"layer_size_1": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)),
"layer_size_2": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)),
"lr": tune.loguniform(1e-4, 1e-1),
}
scheduler = ASHAScheduler(
metric="loss",
mode="min",
max_t=1000,
grace_period=1,
reduction_factor=2
)
reporter = CLIReporter(
parameter_columns=["layer_size_1", "layer_size_2", "lr"],
metric_columns=["loss"]
)
# Train neural network
def train_model(config, epochs=3):
network = SimpleNeuralNet(config["layer_size_1"], config["layer_size_2"])
criterion = nn.BCELoss()
optimizer = optim.SGD(network.parameters(), lr=config["lr"], momentum=0.9)
train_data = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
# Compile the model using torch 2.0's optimizer
network = torch.compile(network)
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
tune.report(loss=(loss.item()))
result = tune.run(
train_model,
resources_per_trial={"cpu": 2},
config=config,
num_samples=1,
scheduler=scheduler,
progress_reporter=reporter
)
best_trial = result.get_best_trial("loss", "min", "last")
print("Best trial config: {}".format(best_trial.config))
print("Best trial final validation loss: {}".format(
best_trial.last_result["loss"]))
best_trained_model = SimpleNeuralNet(best_trial.config["layer_size_1"],
best_trial.config["layer_size_2"])خروجی:
== Status ==
Current time: 2023-03-05 23:31:33 (running for 00:00:00.07)
Memory usage on this node: 1.7/15.6 GiB
Using AsyncHyperBand: num_stopped=0
Bracket:
Iter 512.000:None |
Iter 256.000:None |
Iter 128.000:None |
Iter 64.000: None |
Iter 32.000: None |
Iter 16.000: None |
Iter 8.000: None |
Iter 4.000: None |
Iter 2.000: None |
Iter 1.000: None
Resources requested: 2.0/7 CPUs, 0/0 GPUs, 0.0/8.95 GiB heap, 0.0/4.48 GiB objects
Result logdir: /root/ray_results/train_model_2023-03-05_23-31-33
Number of trials: 1/1 (1 RUNNING) توضیحات
در بخشهای 12.1 و 12.2، به استفاده از تکنیکهای انتخاب مدل در scikit-learn برای شناسایی بهترین هایپرپارامترهای یک مدل scikit-learn پرداختیم. اگرچه بهطور کلی رویکرد scikit-learn را میتوان برای شبکههای عصبی نیز بهکار برد، اما کتابخانه تنظیم Ray یک API پیشرفته ارائه میدهد که به شما امکان میدهد آزمایشها را روی CPU و GPU برنامهریزی کنید.
هایپرپارامترهای یک مدل اهمیت زیادی دارند و باید با دقت انتخاب شوند. با این حال، انجام آزمایش برای انتخاب هایپرپارامترها میتواند هم پرهزینه و هم زمانبر باشد. بنابراین، تنظیم خودکار هایپرپارامترهای شبکههای عصبی راهحل نهایی نیست، اما در شرایط خاصی ابزار مفیدی به شمار میرود.
در راهحل ما، جستوجویی برای پارامترهای مختلف، مانند اندازه لایهها و نرخ یادگیری بهینهساز، انجام دادیم. best_trial.config پارامترهایی را در تنظیمات Ray نشان میدهد که منجر به کمترین خطا و بهترین نتیجه آزمایش شدهاند.
21.14 تجسم شبکههای عصبی
مسئله
میخواهید معماری یک شبکه عصبی را بهسرعت تجسم کنید.
راهحل
از تابع make_dot در کتابخانه torch_viz استفاده کنید:
# Load libraries
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
from torch.optim import RMSprop
from torchviz import make_dot
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# Create training and test sets
features, target = make_classification(n_classes=2, n_features=10,
n_samples=1000)
features_train, features_test, target_train, target_test = train_test_split(
features, target, test_size=0.1, random_state=1)
# Set random seed
torch.manual_seed(0)
np.random.seed(0)
# Convert data to PyTorch tensors
x_train = torch.from_numpy(features_train).float()
y_train = torch.from_numpy(target_train).float().view(-1, 1)
x_test = torch.from_numpy(features_test).float()
y_test = torch.from_numpy(target_test).float().view(-1, 1)
# Define a neural network using `Sequential`
class SimpleNeuralNet(nn.Module):
def __init__(self):
super(SimpleNeuralNet, self).__init__()
self.sequential = torch.nn.Sequential(
torch.nn.Linear(10, 16),
torch.nn.ReLU(),
torch.nn.Linear(16, 16),
torch.nn.ReLU(),
torch.nn.Linear(16, 1),
torch.nn.Sigmoid()
)
def forward(self, x):
x = self.sequential(x)
return x
# Initialize neural network
network = SimpleNeuralNet()
# Define loss function, optimizer
criterion = nn.BCELoss()
optimizer = RMSprop(network.parameters())
# Define data loader
train_data = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
# Compile the model using torch 2.0's optimizer
network = torch.compile(network)
# Train neural network
epochs = 3
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
make_dot(output.detach(), params=dict(
list(
network.named_parameters()
)
)
).render(
"simple_neural_network",
format="png"
)خروجی:
'simple_neural_network.png' اگر تصویری که روی دستگاه ما ذخیره شده است را باز کنیم، میتوانیم موارد زیر را ببینیم:
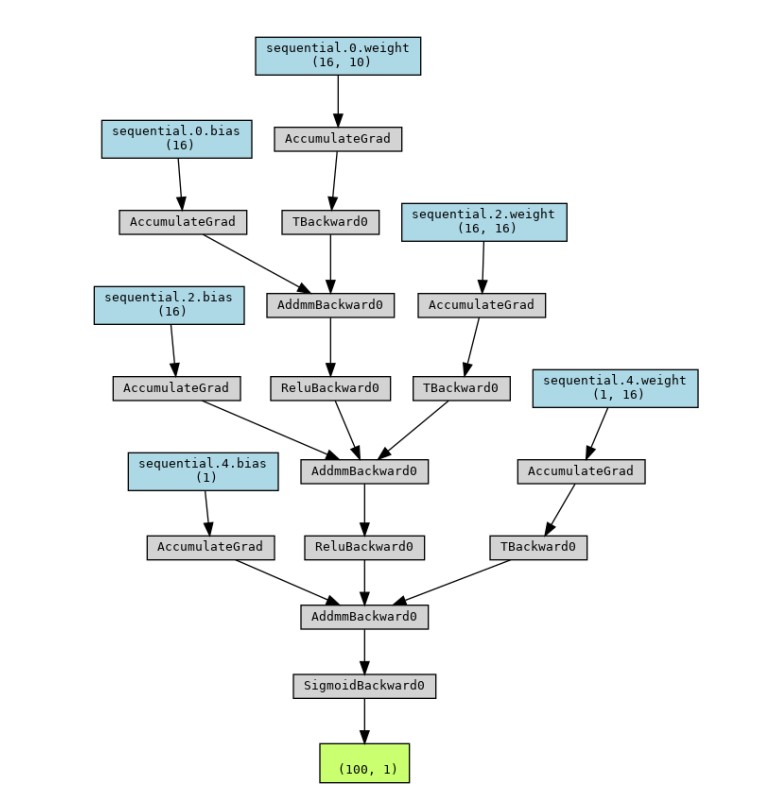
توضیحات
کتابخانه torchviz توابع کاربردی سادهای را ارائه میدهد تا بهسرعت شبکههای عصبی را تجسم کرده و آنها را بهصورت تصویر ذخیره کنیم.
مطلبی دیگر از این انتشارات
فصل 17 - ماشین بردار پشتیبان
مطلبی دیگر از این انتشارات
فصل 1. سازماندهی داده ها: موقعیت ، دامنه ، عمل و اعتبار
مطلبی دیگر از این انتشارات
فصل 20 -تنسورها با کتابخانه پایتورچ