

مهندس یادگیری ماشین
سیستم یادگیری ماشین برای پیشبینی ETA، داستان یک بلوغ

مقدمه
پیشبینی ETA (تخمین زمان رسیدن سفر) یکی از مهمترین سرویسهای زیر مجموعه نقشه در هر اپلیکیشن تاکسی اینترنتی است. در اسنپ از سرویس ETA در جاهای گوناگون مثل قیمت گذاری سفر، پیشنهاد سفر به راننده و نمایش تخمین زمان رسیدن به راننده و مسافر در مراحل مختلف سفر، استفاده میشود. بنابراین دقت ETA همواره یکی از مهمترین متریکها در تیم نقشه است و تغییرات هرچند کوچک آن میتواند متریکهای مهم بیزینسی را تغییر دهد.
به طور کلاسیک برای محاسبه ETA از روشهای مبتنی بر دیتای ترافیکی و مسیریابی استفاده میشود. به این صورت که با در اختیار داشتن دادههای live و historical ترافیکی میتوان با استفاده از الگوریتمهای مسیریابی، مدت زمان حدودی هر سفر را پیشبینی کرد. در سالهای اخیر برای افزایش دقت ETA،از روشهای یادگیری ماشین در کنار روشهای مسیریابی، و یا به صورت مستقل استفاده شده است .
در این مقاله قصد داریم داستان استفاده از سیستم یادگیری ماشین برای کمک به محاسبه ETA و چالشهای مهندسی آن، و همینطور رویکرد ما برای حل این چالشها رو با شما به اشتراک بگذاریم.
از آنجایی که تجربههای جدی استفاده از سیستمهای یادگیری ماشین در فضای پروداکشن و در مقیاس بالا خیلی در دسترس نیست، سعی کردیم نگاه ما در این مقاله به جای بیان مشکلات و چالش های الگوریتمی و دیتاساینسی و یا بهبود دقت مدلها، نگاه به چالشهای این سیستم با هدف رسیدن به یک سیستم قابل اتکا، مقیاس پذیر و قابل نگهداری باشد.
فاز اول، تلاش برای کشف یک مسیر
در ابتدای مسیر پروژههای یادگیری ماشین، مهمترین مسئله، سریع بودن در رسیدن به یک نمونه اولیه است که اثبات کند مسئله با استفاده از روشهای یادگیری ماشین قابل حل است (PoC). دلیل این رویکرد و تفاوت آن نسبت به دیگر پروژههای توسعه نرم افزار این است که در مسائل یادگیری ماشین یک ابهام بزرگ برای مهندسان، تیم محصول و بیزینس وجود دارد که آیا مسئله اصولا قابل حل شدن با روش های یادگیری ماشین است یا خیر؟ دلیل این ابهام هم متفاوت بودن هر مسئله در یادگیری ماشین با توجه به دیتای موجود، نوع فرمول بندی مسئله و روشهای حل آن است. به طور مثال هیچ نمونه مشابهی در کارهای منتشر شده وجود ندارد که نشان دهد مسئله پیشبینی یا بهبود ETA (دقیقا با داده های موجود در اسنپ) قابل حل با روش X است. حال این مسئله را مقایسه کنید با توسعه یک API که تا حد خیلی زیادی برای اکثر چالشهای آن صدها ابزار، Best Practice و نمونههای موفق وجود دارد. بنابراین در شروع پروژههای یادگیری ماشین هدف اصلی برطرف کردن ابهامات و رسیدن به یک راه حل اولیه قابل قبول و انجام آزمایشات متنوع در سریع ترین زمان ممکن است و داشتن یک ساختار منظم برای توسعه، کدهای تمیز و رعایت همهی اصول مهندسی نرم افزار از اهمیت کمتری برخوردار است.
همین الگو در پروژه بهبود ETA اسنپ هم در دستور کار بود. در ابتدا سعی کردیم همه توانمان را بر روی مطالعه روشهای منتشر شده، جمع آوری و تمیز کردن داده، و آزمایش سناریو های مختلف صرف کنیم. پس از چندین ماه فاز تحقیق و توسعه به راهحلی رسیدیم که حداقل نیازمندیهای بیزینس را چه از نظر دقت و چه از نظر سرعت و مصرف منابع برطرف میکرد. با توجه به اهمیت ETA در سرویسهای مختلف اسنپ به سرعت یک سرویس برای serve کردن مدل را توسعه دادیم و پس از چند مرحله تست سرویس بر روی production مستقر شد.
خروجی این مرحله اولیه، تعداد زیادی Jupyter Notebook بود که آزمایشات مختلف بر روی آنها انجام شده بود و همینطور یک سرویس API بسیار ابتدایی با یک endpoint صرفا جهت serve مدل اولیه.
چالش های فاز اول
همانطوری که در بخش قبلی اشاره کردیم، از آنجایی که هدف ما در فاز اولیه صرفا رسیدن به یک جواب معقول برای مسئله بود، بسیاری از استانداردهای توسعه در این فاز رعایت نشده بود و ادامه دادن پروژه ازینجا به بعد با شرایط فعلی کمی چالش برانگیز بود. در ادامه به تعدادی از این چالشها اشاره میکنیم.
- نبود مستند سازی به شکل منظم و ساختارمند باعث شده بود پس از مدتی با اضافه شدن افراد جدید و خروج برخی از نیروها از پروژه، میزان زیادی از تاریخچه آزمایشات قبلی موجود نباشد و گاها مجبور به تکرار آزمایشات با افراد جدید باشیم.
- کدهای پروژه همگی بر روی تعداد زیادی Jupyter Notebook بود که روی هر کدام، آزمایشات مختلفی انجام شده بود؛ بخش های زیادی از کدها کامنت بودند، ترتیب اجرای کدها مشخص نبود، بخش های زیادی از کدها در نوتبوک های مختلف تکرار شده بودند، و در کل ادامه دادن آزمایشات قبلی و ایجاد بهبود بر روی همین کدها تا حد زیادی ناممکن بود.
- آموزش مدلها با دادههای به روز، کاری پرهزینه بود چرا که تعداد زیادی فرآیند دستی و غیر بهینه باید اجرا انجام میشد، که هم ساعتهای زیادی از تیم مهندسی میگرفت و هم از طرفی احتمال خطا در هر بخش را زیاد میکرد.
- مدل پیشنهادی یک مدل بسیار سنگین از نظر منابع مصرفی بود که هم زمان آموزش زیادی را میطلبید، و هم ذخیره سازی مدلها را با چالش همراه میکرد. از طرفی با وجود این مدل حجیم، سرویس نهایی سرویسی گران و پرمصرف از نظر مصرف منابع سخت افزاری مثل رم، سی پی یو و جی پی یو بود.
- سیستم serving مدلها بسیار نابالغ بود و observability و scalability لازم را نداشت. به عبارت دیگر فرآیند دیپلوی کردن یک مدل جدید هزینه مهندسی بالایی داشت و از طرفی سیستم monitoring و tracing مناسبی برای پایش سیستم و پیدا کردن خطاهای احتمالی موجود نبود.
- امکان تشخیص کاهش دقت مدلها در طول زمان به صورت آنلاین وجود نداشت و هر بار تیم مهندسی با چند روز تاخیر متوجه کاهش دقت مدل میشد که reliability سیستم از نظر پایداری دقت را کاهش میداد.
به طور خلاصه موارد بالا باعث شده بود تا نگهداری سیستم به طور reliable و scalable کاری بسیار پرهزینه باشه و از طرفی فرآیندهای بهبود دقت و اجرای ایدههای جدید هم با کندی زیادی پیش برود.
فاز دوم، تلاش برای بلوغ
پس از مشاهده چالشهایی که در بخش قبل عنوان کردیم، فاز دوم توسعه این سیستم یادگیری ماشین را با هدف ارائه سیستمی قابل نگهداری و قابل اتکا آغاز کردیم. به طور عمومی در این مرحله از توسعه، پس از اینکه از feasible بودن حل مسئله با استفاده از روشهای یادگیری ماشین اطمینان حاصل شد، تلاش میشود سیستم اولیه با استفاده از best practice های مهندسی نرم افزار و MLOps برای استفاده در محیط های پروداکشنی بازنگری شود.
در ادامه این بخش به مروری اجمالی از ماژولهای استفاده شده در این فاز برای غلبه بر چالشهای ذکر شده میپردازیم.
پروسه مستندسازی منظم
یک بخش بسیار مهم از پروژههای یادگیری ماشین، دانشی است که در طول پروژه و با انجام آزمایشات مختلف در تیم به وجود میآید. این دانش که گنج بزرگی برای حال و آینده پروژه است، در صورت مستندسازی ناقص و غیر منظم، پس از مدتی از بین میرود و باعث میشود مجبور به تکرار آزمایشات قبلی شویم و یا نتوانیم به درستی برای آینده پروژه تصمیم بگیریم. اولین اقدامی که در این فاز انجام دادیم توسعه یک روش مستندسازی بود. به این شکل که پس از هر آزمایش، تیم باید یک کارت مستندسازی برای آن پر میکرد که خلاصهای از مهمترین اطلاعات آن آزمایش بود. اطلاعاتی که در هر کارت پر میشد شامل فرضیه ای که این آزمایش در تلاش تست آن بود، دیتای استفاده شده، روش آزمایش و نتایج حاصل بود. سعی کردیم این کارت تا حد ممکن خلاصه باشد تا پر کردن آن هزینه اضافه برای تیم نداشته باشد و از طرفی شامل همه موارد ضروری باشد. از طرفی پر کردن این کارتها را به بخشی از Definition of Done برای تسکها تبدیل کردیم تا از پر شدن منظم آن در طول زمان اطمینان کسب کنیم. با این کار آرشیوی ارزشمند از تاریخچه پروژه تهیه شد که به سوالات زیادی در آینده پاسخ میداد و باعث میشد تیم صرفا بر روی کارهای خلاقانه جدید تمرکز کند و بتواند از مشاهده کارهای گذشته دانش انباشتهای را کسب کند.
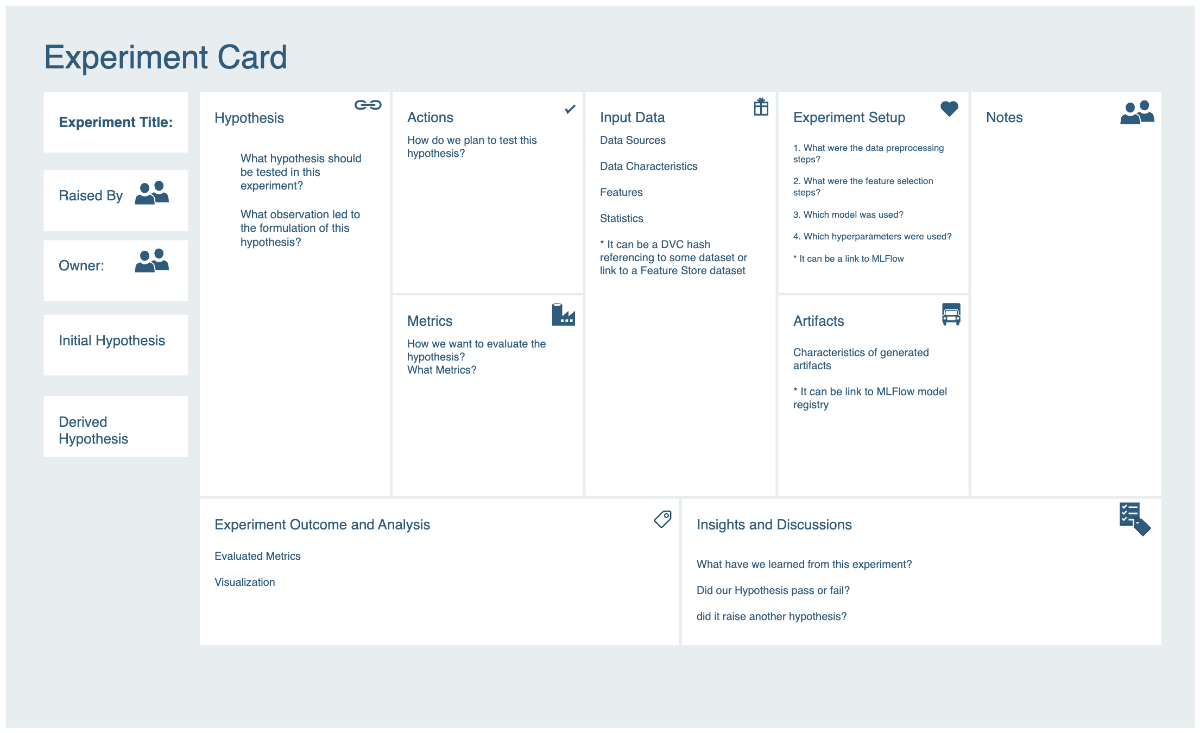
کدهای ماژولار
یکی از مواردی که در اکثر پروژههای یادگیری ماشین رعایت نمیشود رعایت حداقل استانداردهای مهندسی نرم افزار مانند نوشتن کدهای ماژولار و تمیز است. اکثر اوقات وقتی در مورد پروژههای یادگیری ماشین فکر میکنیم تعدادی فایل Jupyter Notebook به ذهن میآید که پر از کدهای کثیف، پرینت های طولانی، کدهای کامنت شده و در مجموع مشخص نبودن روند کدها است. همانطور که در فاز قبلی گفتیم این موضوع به ماهیت آزمایش محور پروژههای یادگیری ماشین برمیگردد. در ابتدای پروژه مهندسین تمام تمرکز خود را به اکتشاف مسئله و تست ایدههای مختلف میگذارند که ابزاری تعاملی مثل Jupyter Notebook انتخاب مناسبی برای این نوع از اکتشافات و بررسی سریع نتیجه است. با گذشت زمان و بلوغ نسبی پروژه این رویکرد باعث کند شدن آزمایشات و عدم توانایی در استفاده از ابزارهای مختلف برای Scale کردن پروژه میشود. به عنوان مثال اگر بخواهیم یک پایپ لاین آموزش اتوماتیک را توسعه دهیم، باید کدهایی تمیز و ساختارمند داشته باشیم.
از این رو در این بخش پس از تحقیق بر روی چندین ابزار و فریمورک به ابزار Kedro رسیدیم که هدف آن همین ماژولار کردن کدهای یادگیری ماشین بر طبق استانداردهای توسعه نرم افزار بود. پس از این سعی کردیم همه کدهای موجود در Jupyter Notebook ها را بر طبق این فریمورک بازنویسی کنیم. در انتها موفق به توسعه یک کد بیس تمیز، ماژولار، و با ویژگی اضافه یا کم کردن یک قابلیت به هر بخش از فرایند آموزش شدیم. این کد بیس جدید شامل چهار پایپ لاین کاملا جدا از هم برای جمع آوری داده، پیش پردازش داده، آموزش مدل و ارزیابی مدل بود. هر پایپلاین شامل تعدادی node بود که هر یک وظیفه ای را بر عهده داشتند. همه پایپ لاین ها و node ها به راحتی با یک فایل Yaml قابل مدیریت و تغییر بود و آزمایشات مختلف را بسیار سریع و منظم میکرد. حالا کافی بود بجای گشتن در کدهای تو در تو برای تغییر یک پارامتر (مثل learning rate) صرفا در فایل کانفیگ، پارامتر مورد نظر را تغییر دهیم. از طرفی این کدبیس جدید قابلیتهای دیگری مثل integrate کردن فرایند آموزش با ابزارهای دیگر هم به ما داد. مثلا در سیستم آموزش اتوماتیک که جلوتر به آن می پردازیم، در هر راند از آموزش اتوماتیک صرفا یک فایل کانفیگ آماده و آموزش شروع میشد. در انتها ویژگی مهم دیگر این ساختار امکان آسان اضافه کردن ماژولهای جدید برای آزمایشات بود. به طور مثال اگر تیم سعی داشت تا یک feature جدید را به مدل اضافه کند به راحتی به پایپلاین پیش پردازش داده ها رجوع می کرد، ایده خود را در قالب یک node پیاده سازی میکرد و در فایل کانفیگ آن node را فراخوانی میکرد.

بهینه سازی مدل
به دلیل تمرکز زیاد بر دقت مدل در گامهای اولیه، احتمال استفاده از مدلهای حجیم و غیر بهینه بسیار زیاد است. در فاز اولیه شما اصلا ایدهای ندارید که راهحل شما به جواب معقولی میرسد یا نه. پس دلیلی وجود ندارد که ذهن خود را درگیر بهینه بودن راهحل از نظر استفاده از منابع یا سریع بودن بکنید. اما زمانی که از این مرحله عبور کردیم و به یک راهحل معقول رسیدیم همه این دغدغه ها اهمیت پیدا میکنند. پس در این مرحله، ماجراجویی ما در جهت بهینه کردن مدلها به هدف کم کردن منابع مصرفی، افزایش سرعت پاسخ مدل و مقیاس پذیر بودن مدل در عین حفظ دقت اولیه آغاز شد. همانطور که میدانیم در بسیاری از موارد یک مصالحه (Trade off) بین دقت مدل و سبک بودن آن برقرار است و محدودیتهای بیزینسی مثل حداقل دقت قابل قبول و یا حداکثر میزان منابع مصرفی مجاز تعیین کننده این موضوع هستند که تا چه میزان میتوانیم دقت را فدای بهینه کردن راهحل ها کنیم. در این مرحله چندین گزینه برای بهینه کردن مدل پیش روی ما بود. یک گزینه بهینه کردن هایپر پارامترهای مدل در جهت کوچک کردن مدل بود. تعداد لایههای شبکههای عصبی یا میزان عمق درخت در روشهای مبتنی بر درخت تصمیم از جمله این موارد هستند. گزینه دیگر استفاده از یک runtime بهینه تر مانند استفاده از LightGBM به جای Scikit Learn یا استفاده از ONNX به جای TensorFlow بود. پس از آزمایشات مختلف بر روی هر دوی این مسیرها به راهحلی رسیدیم که از نظر منابع مصرفی حدود ۵۰ برابر کمتر، از نظر سرعت حدود ۲ برابر سریعتر و تقریبا با همان دقت سابق بود. این مدل مسیرهای جدیدی مانند استفاده از این راهحل در شهرهای مختلف یا آموزش مدل بر روی فضای ابری اسنپ را به ما داد.
تشخیص دریفت
نگهداری سیستمهای یادگیری ماشین از جوانبی شبیه به نگهداری دیگر سیستمهای نرمافزاریست. هر دو این سیستمها نیازمند نگهداری در زمان بروز خطاهای انسانی در مرحله توسعه، بروز خطاهای سخت افزاری و معیوب شدن آنها و همچنین بروز باگهای پیش بینی نشده نرمافزاری هستند. سیستمهای یادگیری ماشین در ابعاد دیگری نیز نیازمند انواعی از نگهداری هستند که فقط مختص خود آنهاست. از آنجایی که مدلهای یادگیری ماشین در تعامل مستقیم با دنیای بیرون هستند و دقت آنها تابعی از رفتار محیط است، در صورت بروز تغییراتی در رفتار محیط امکان کاهش دقت این سیستمها وجود دارد که نیازمند نگهداری و توجه است. به مجموعه تغییرات محیط که باعث کاهش دقت مدلها می شود، دریفت (Drift) میگویند که به دسته های مختلفی، مثل Data Drift که شامل تغییر توزیع دادههای ورودی مدل است، و یا Concept Drift که به تغییر رابطه ورودی مدل با خروجی قابل انتظار مربوط میشود، تقسیمبندی میشوند. در صورت بروز Drift سیستم نیازمند تغییراتی است تا دقت سیستم حفظ شود. مهمترین و سرراست ترین کاری که در زمان بروز دریفت میتوان انجام داد، آموزش مجدد مدل با دادههای جدیدتر است (Retraining). در سیستم پیشبینی ETA ما هم بروز دریفتهای مختلف مثل تغییرات پترن ترافیکی به دلایل مختلف مثل بازگشایی مدارس در مهرماه یا تغییرات ترافیکی در روزهای بارانی یا برفی و یا هر پدیده از قبل پیشبینی نشده، باعث کاهش دقت مدل میشد که علاقمند بودیم با توسعه یک سیستم اتوماتیک، این دریفتها را تشخیص دهیم و قبل از آنکه دقت مدل به حد غیر قابل قبولی برسد، اقدامی در جهت تطبیق سیستم با شرایط به وجود آمده انجام دهیم.
برای توسعه این سیستم پس از مطالعه و بررسی روشها و ابزارهای مختلف تصمیم گرفتیم که از ابزار DeepCheck که راهحل های مختلفی برای تشخیص انواع دریفت در اختیار قرار میداد، استفاده کنیم. معماری این سیستم به این شکل بود که در هر ساعت، یکبار دادههای موجود این ساعت با دادههای همین ساعت در هفتههای گذشته مقایسه میشد و یک متریک Drift Score در سیستم مانیتورینگ ثبت میشد. اگر در یک بازه زمانی مشخص تعداد مشخصی از Drift Score ها از حد آستانهای بیشتر بود، سیستم مانیتورینگ یک Alert تولید میکرد تا تیم فنی از بروز Drift مطلع شود و اقدام لازم را انجام دهد.
سیستم آموزش اتوماتیک
در سیستمهای بالغ یادگیری ماشین یکی از متریکها برای ارزیابی کارایی سیستم، زمان مورد نیاز برای آموزش یک مدل تا Deploy کردن مدل آموزش دیده است. در سیستم پیشبینی ETA هم علاقمند بودیم در کمترین زمان بتوانیم مدلی را آموزش دهیم. به این منظور کدبیس ماژولار شده ای که در بخشهای قبل ذکر کردیم را به عنوان یک DAG که مخفف (Directed Acyclic Graph) است در سرویس Apache AirFlow که یک Workflow Orchestrator برای مدیریت کردن اجرای تسکهای مختلف است، درآوردیم. با این کار کل فرآیند Retrain کردن مدل با زدن یک دکمه اجرا میشد و نتایج داخل ابزار Experiment management ما که یک سرویس MLFlow بود ذخیره میشد. توسعه این DAG به ما امکان Retrain کردن اتوماتیک، در بازههای زمانی مشخص مثلا هفتهای یک بار و یا بر اساس یک رویداد مشخص، مثل اعلام آلرت از سمت سیستم تشخیص دریفت را میداد. با توسعه این سیستم و اتصال آن به سیستم تشخیص دریفت مطمئن شدیم که مدل همواره میتواند خود را به سرعت با شرایط مختلف سازگار نگه دارد و از طرفی اگر قرار بود به هر دلیلی مدل را آموزش دهیم به جای صرف مدت زیادی از زمان نیروی فنی برای جمع آوری داده، آموزش مدل و ارزیابی آن، صرفا با زدن یک دکمه فرایند آموزش را اجرا میشد.
بلوغ سیستم سروینگ
همانطور که قبلتر شاره کردیم در فاز اولیه سیستم serve کردن مدلهای آموزش دیده، یک سیستم بسیار ساده بود. با بلوغ سیستم، بروز نیازمندیهای جدیدی مثل نیاز به تعامل API با دیگر سیستمها مثل سیستم آموزش اتوماتیک و یا نیاز به Serve شدن تعداد بیشتری مدل که در شرایط گوناگون نیاز به اجرا داشتند، باعث شد تا در این فاز سعی کنیم سیستم سروینگ را بهبود دهیم. در این مرحله یک کد Extendable برای افزودن انواع مدلها با انواع پیشپردازشها توسعه داده شد تا بر اساس شرایط مختلف بتواند، مدلها با کانفیگهای مختلفی را اجرا کنند. از طرف دیگر، امکان Serve چندین مدل به طور همزمان به این سرویس اضافه شد و همچنین با افزودن چندین endpoint سعی کردیم تعامل این سرویس با اجزای دیگر سیستم را برقرار سازیم.
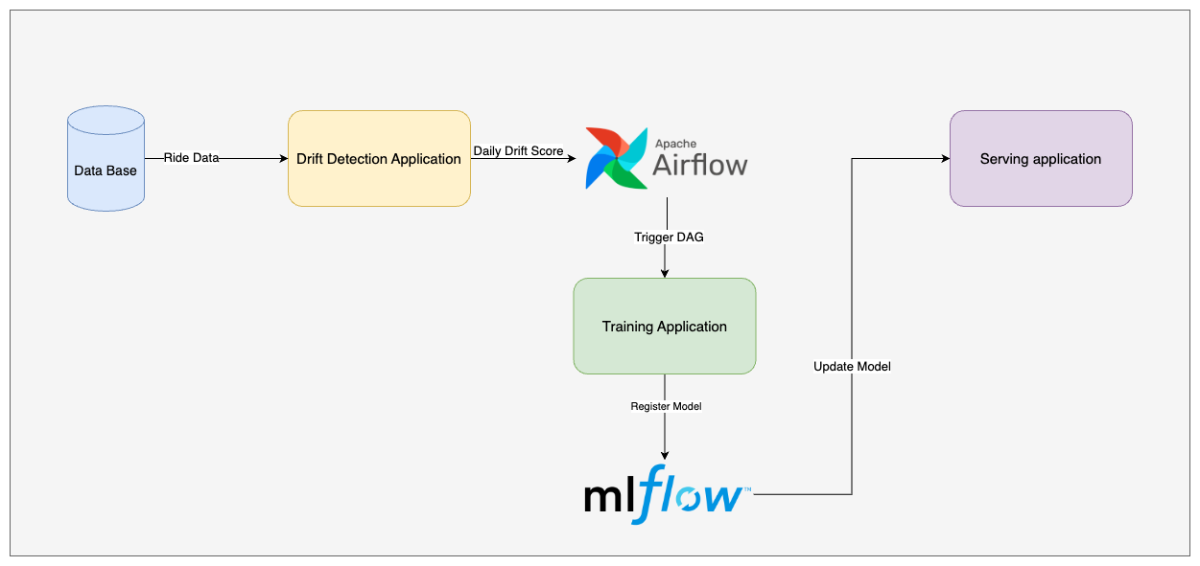
دستاوردها
با توسعه ماژولهایی که در بخش قبل ذکر کردیم موفق شدیم:
- مدت زمان آموزش تا Deploy یک مدل را از حدود ۱ روز، به ۲ ساعت کاهش دهیم.
- هزینه نیروی مهندسی برای کارهای تکراری، مانند Retrain کردن مدلها را به حداقل برسانیم و تمرکز نیروهای متخصص را بر توسعه روشهای جدید و بهبود کلی سیستم نگه داریم.
- مشاهده پذیری (Observability) سیستم را با مانیتور کردن مداوم رفتار مدل و رفتار محیط بهبود ببخشیم.
- در پاسخگویی به تغییرات چابکتر باشیم.
- امکان تست سریع ایدههای جدید را داشته باشیم.
- دانش انباشته از آزمایشات مختلف را به طور منظم نگهداری کنیم.
و در مجموع یک سیستم یادگیری ماشین قابل اتکا، قابل نگهداری و مقیاس پذیر را توسعه دهیم.
مسیر پیش رو
در ادامه مسیر برای بلوغ بیشتر این سیستم سعی داریم تا پایپلاینهای دادههای ورودی برای آموزش و inference را بهینه و غنی کنیم که در این راستا استفاده از تکنولوژیهای feature store را در دست بررسی داریم. همچنین استفاده از inference server ها برای serve کردن مدلها با قابلیتهای بیشتر مثل امکان A/B Testing، Canary Testing، auto scaling و batch inference را در دست بررسی داریم که در این راستا، در حال تست ابزارهایی مثل Seldon و KServe هستیم.
جمع بندی
در این مقاله سعی کردیم روایتی از یک مسئله واقعی یادگیری ماشین و چالشهای استفاده آن در محیطهای پروداکشنی حساس را بیان کنیم و رویکرد ما نسبت به حل مشکلات و چالشها را شرح دهیم. امیدواریم در ادامه بتوانیم از این دست از مقالهها که چالشهایی کمتر پرداخته شده، در حوزه یادگیری ماشین و علوم داده را عنوان میکند را بیشتر منتشر کنیم.
در انتها از همه اعضای تیم فنی و پروداکت تیم ETA Enabling نقشه اسنپ تشکر میکنم که با تلاش و انرژی همیشگی ساخت یک سیستم قابل اتکا را ممکن کردند.
مطلبی دیگر از این انتشارات
سرویسورکر در پروژه CRA؛ مزایا و چالشها
مطلبی دیگر از این انتشارات
نمایش نقاط پرتکرار برای مسافران اسنپ
مطلبی دیگر از این انتشارات
تاثیر CI/CD در تیم اندروید اسنپ