

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
آیا میتوانید یک مدل یادگیری ماشینی برای نظارت بر یک مدل دیگر بسازید؟

منتشرشده در: towardsdatascience
لینک منبع: Can You Build a Machine Learning Model to Monitor Another Model?
آیا میتوانید یک مدل یادگیری ماشین را برای پیشبینی اشتباهات مدل خود آموزش دهید؟
هیچ چیز شما را از تلاش باز نمیدارد. ولی احتمالش هست که. تو بدون اون اوضاعت بهتره
ما دیدهایم که این ایده بیش از یکبار پیشنهاد شدهاست.
روی کاغذ منطقی به نظر میرسد. مدلهای یادگیری ماشینی اشتباه میکنند. بیایید این اشتباهات را انجام دهیم و یک مدل دیگر را آموزش دهیم تا اشتباهات مدل اول را پیشبینی کنیم! مجموعهای از یک «آشکارساز اعتماد»، براساس آموختههای مدل ما در گذشته.
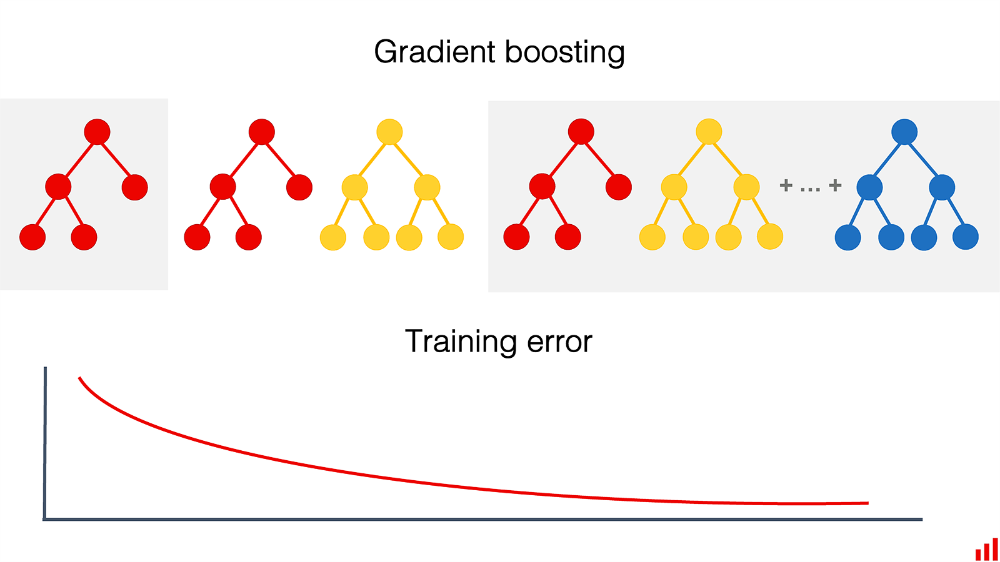
یادگیری از اشتباهات به خودی خود معنای زیادی دارد.
این رویکرد دقیق در پایه روش تقویت در یادگیری ماشینی قرار دارد. این روش در بسیاری از الگوریتمهای گروهی، مانند افزایش شیب بر روی درختهای تصمیمگیری، اجرا میشود. هر مدل بعدی برای اصلاح خطاهای مدلهای قبلی آموزش داده میشود. ترکیب مدلها بهتر از یک مدل عمل میکند.
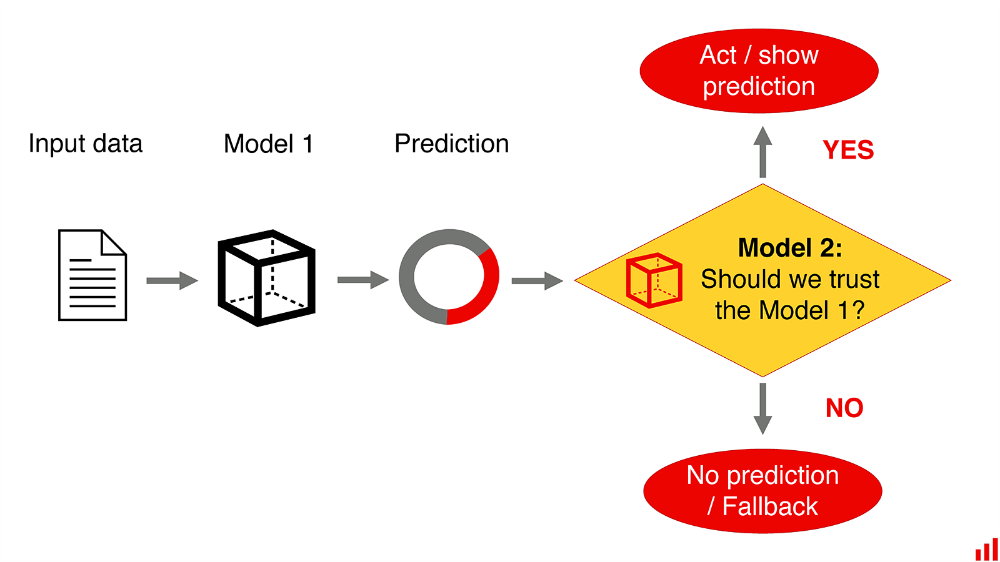
اما آیا به ما کمک میکند تا یک مدل جداگانه و دوم را آموزش دهیم تا پیشبینی کنیم که آیا مدل اول درست است؟
پاسخ ممکن است ناامید کننده باشد.
بیایید از طریق مثال فکر کنیم.
آموزش نگهبان
مثلا، شما یک مدل پیشبینی تقاضا دارید. شما میخواهید وقتی که اشتباه است آن را بگیرید.
شما تصمیم میگیرید که یک مدل جدید را در اشتباهات مدل اول آموزش دهید. این دقیقا به چه معناست؟
این یک کار رگرسیون است که در آن ما یک متغیر پیوسته را پیشبینی میکنیم. هنگامی که حجمهای فروش واقعی را بدانیم، میتوانیم خطای مدل را محاسبه کنیم. ما میتوانیم چیزی مانند MAPE یا RMSE را انتخاب کنیم. سپس، مدل را با استفاده از مقدار این معیار به عنوان یک هدف آموزش میدهیم.

یا اجازه دهید یک مثال طبقهبندی را در نظر بگیریم: احتمال عدم پرداخت وام اعتباری.
مدل پیشبینی وام ما تقریباً یک طبقهبندی احتمالی است. هر مشتری با توجه به احتمال عدم پرداخت بدهی از ۰ تا ۱۰۰ امتیاز میگیرد. در آستانه قطع مشخصی، ما یک وام را ممنوع میکنیم.
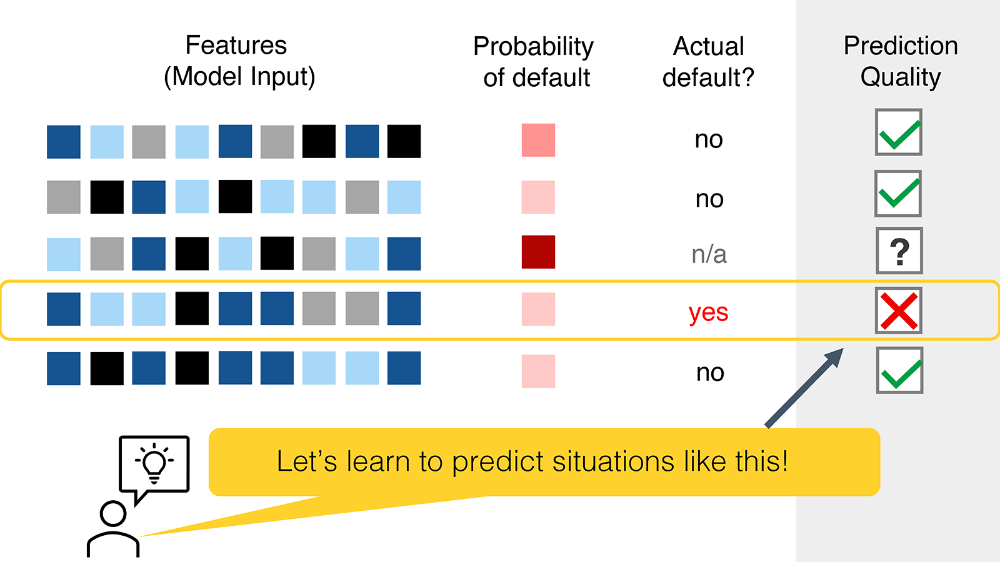
در مدتی، ما حقیقت را خواهیم دانست. برخی از پیشبینیهای ما منفی کاذب خواهد بود: ما به کسانی که هنوز کوتاهی نکردهاند وام میدهیم.
اما، اگر ما بدون بررسی بر روی همه پیشبینیها عمل کنیم، هرگز در مورد مثبت کاذب یاد نمیگیریم. اگر ما به اشتباه یک وام را ممنوع کنیم، این بازخورد برای مشتری باقی میماند.
ما هنوز هم میتوانیم از یادگیریهای جزئی که به دست آوردیم استفاده کنیم. شاید، احتمالات پیشبینی شده برای مشتریان خطاکار را در نظر بگیرید و سپس یک مدل جدید برای پیشبینی خطاهای مشابه آموزش دهید؟
ممکن است مطالعه مقاله ۳ ترفند پایتون پانداس برای تجزیهوتحلیل کارآمد دادهها برای شما مفید باشد.
آیا این کار جواب خواهد داد؟
بله، و نه.
از لحاظ فنی میتواند کار کند. به این معنی که، شما ممکن است قادر به آموزش مدلی باشید که در واقع چیزی را پیشبینی میکند.
اما اگر اینطور است، به این معنی است که شما باید مدل اولیه را به جای آن مجددا آموزش دهید!
توضیح دهیم.
چرا مدلهای یادگیری ماشین میتوانند اشتباه باشند؟ گذشته از کیفیت داده، معمولا یکی از دو مورد زیر است:
- سیگنال کافی در دادههای آموزشدیده مدل وجود ندارد. یا دادههای کافی وجود ندارد. به طور کلی، یا برای یک بخش خاص که در آن شکست میخورد. این مدل چیز مفیدی یاد نگرفته است و حالا یک پاسخ عجیب و غریب میدهد.
- مدل ما به اندازه کافی خوب نیست. خیلی ساده است که سیگنال را به درستی از دادهها دریافت کنیم. چیزی را که نمیداند میتواند به طور بالقوه یاد بگیرد.
در مورد اول، خطاهای مدل هیچ الگویی ندارند. بنابراین، هر تلاشی برای آموزش مدل «نگهبان» با شکست مواجه خواهد شد. هیچ چیز جدیدی برای یادگیری وجود ندارد.
در مورد دوم، ممکن است بتوانید مدل بهتری را آموزش دهید! یک مورد پیچیدهتر که برای دادهها مناسبتر است تا تمام الگوها را ثبت کند.
اما اگر میتوانید این کار را انجام دهید، چرا «نگهبان» را آموزش دهید؟ چرا مدل اول را به جای آن بهروزرسانی نکنیم؟ آن میتواند از همان بازخورد دنیای واقعی که ما در زمان به کار بردن آن در مرحله اول به دست آوردیم، یاد بگیرد.
یک مدل که بر همه آنها حکومت کند
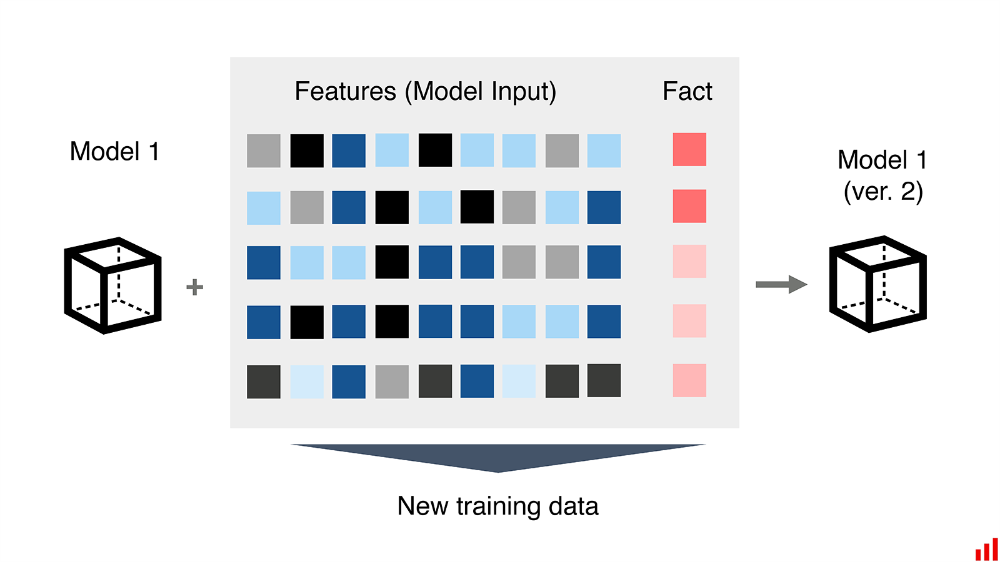
به احتمال زیاد، مدل اولیه ما «بد» نبود. اینها ممکن است مشتریانی باشند که تغییر کردهاند یا برخی شرایط دنیای واقعی که الگوهای جدیدی به ارمغان آوردهاند. پاندمی را در نظر بگیرید که هم بر فروش و هم بر رفتار اعتباری تاثیر میگذارد. همان اطلاعات قدیمی و انحراف مفهومی که قبلا در مورد آن صحبت کردیم.
ما میتوانیم دادههای جدید در مورد قصورهای فروش و وام را بگیریم و آن را به مجموعه آموزشی قدیمی خود اضافه کنیم.
ما «خطاها» را پیشبینی نمیکنیم. ما به مدلهای خود آموزش خواهیم داد که دقیقا همان چیزها را پیشبینی کنند. احتمال قصور یک فرد در پرداخت وام چقدر است؟ حجم فروش چقدر خواهد بود؟ اما این یک مدل جدید و به روز شده خواهد بود که از اشتباهات خودش یاد گرفتهاست.
همین!
مدل «نگهبان» در کنار آن، ارزشافزایی نخواهد کرد.
واقعا هیچ داده دیگری برای یادگیری از آن وجود ندارد. هر دو مدل از یک مجموعه ویژگی یکسان استفاده میکنند و به سیگنال یکسان دسترسی دارند.
اگر یک مدل جدید خطا ایجاد کند، مدل «نگهبان» نیز آن را از دست خواهد داد.
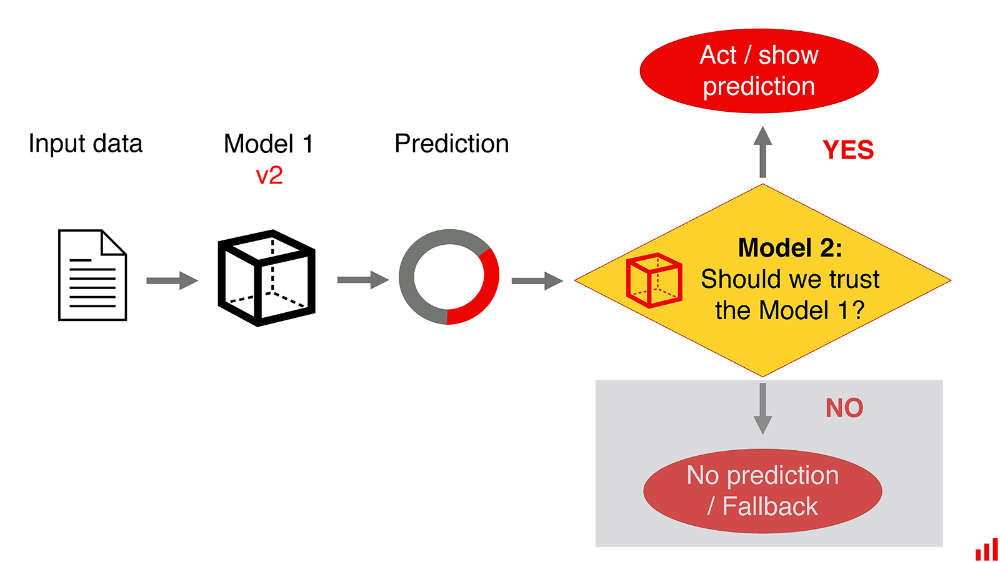
یک استثنا میتواند این باشد که ما هیچ دسترسی به مدل اصلی نداریم و نمیتوانیم آن را به طور مستقیم دوباره آموزش دهیم. برای مثال، آن متعلق به یک حزب سوم است و یا به دلیل مقررات ثابت است.
اگر دادههای جدیدی از زمینه برنامه زندگی واقعی و برچسبهای واقعی داشته باشیم، واقعاً میتوانیم مدل دوم را بسازیم. با این حال، این یک محدودیت مصنوعی است. انجام این کار در صورتی که ما خودمان مدل اصلی را حفظ کنیم، منطقی به نظر نمیرسد.
در عوض چه کار میتوانیم بکنیم؟
ایده مدل «نگهبان» جواب نداد. چه کار دیگری میتوانیم بکنیم؟
بیایید با دلیل شروع کنیم.
هدف اصلی ما ساخت مدلهای قابل اعتمادی است که در تولید عملکرد خوبی داشته باشند. ما میخواهیم پیشبینیهای اشتباه را به حداقل برسانیم. بعضی از آنها ممکن است برای ما گران تمام شود.
با فرض اینکه ما تمام تلاش خود را در بخش مدلسازی انجام دادیم، میتوانیم از روشهای دیگر برای اطمینان از این که مدلهای ما به طور قابل اعتمادی عمل میکنند، استفاده کنیم.
اول، یک فرآیند نظارت منظم ایجاد کنید.
بله، این رویکرد به طور مستقیم به خطاهای ایجاد شده توسط مدل نمیپردازد. اما راهی برای حفظ و بهبود عملکرد مدل ایجاد میکند و بنابراین خطاها در مقیاس را به حداقل میرساند.
این امر شامل تشخیص نشانههای اولیه داده و رانش مفهوم از طریق نظارت بر تغییرات در توزیعها و پیشبینیهای ورودی است.
مطالعه مقاله به حداکثر رساندن سودآوری کسبوکار خود با پایتون توصیه میشود.
دوم، یادگیری ماشین جفت با قوانین قدیمی خوب را در نظر بگیرید.
اگر ما رفتار مدل خود را با جزئیات بیشتر تحلیل کنیم، میتوانیم مناطقی را شناسایی کنیم که در آنها عملکرد خوبی ندارند. سپس میتوانیم کاربرد مدل را به مواردی محدود کنیم که میدانیم مدل شانس بیشتری برای موفقیت دارد.
در یک آموزش دقیق، ما کشف کردیم که چگونه این ایده را در یک کار پیشبینی فرسایش کارمند اعمال کنیم. ما همچنین افزودن یک آستانه سفارشی برای طبقهبندی احتمالی برای تعادل تشخیصهای مثبت غلط و خطاهای منفی غلط را در نظر گرفتیم.

سوم، میتوانیم بررسیهای آماری را بر روی ورودیهای مدل اضافه کنیم.
در مدل «سگ نگهبان»، ایده این بود که قضاوت کنیم آیا میتوانیم به خروجی مدل اعتماد کنیم. در عوض، ما میتوانیم دادههای پرت را در دادههای ورودی شناسایی کنیم. هدف، بررسی تفاوت آن با چیزی است که مدل در مورد آن آموزشدیده است. اگر یک ورودی خاص «خیلی متفاوت» از آنچه که مدل قبلا دیده، باشد، میتوانیم آن را برای یک بررسی دستی، برای مثال، ارسال کنیم.
یادداشت جانبی. به لطف یکی از خوانندگان ما که بحث را شروع کرده بود!
در مشکلات رگرسیون، گاهی اوقات میتوانید یک مدل «سگ نگهبان» بسازید. این اتفاق زمانی میافتد که مدل اصلی شما خطای پیشبینی را با در نظر گرفتن علامت آن بهینهسازی میکند. اگر دومین مدل «سگ نگهبان» در عوض یک خطای مطلق را پیشبینی کند، ممکن است چیزی بیشتر از مجموعه داده به دست آورد.
اما این یک چیز است: اگر جواب دهد، به شما نمیگوید که مدل «اشتباه» است یا اینکه چگونه آن را اصلاح کنید. در عوض، این یک روش غیر مستقیم برای ارزیابی عدم قطعیت دادههای ورودی است.
در عمل، این ما را به همان راهحل جایگزین برمی گرداند. به جای آموزش مدل دوم، اجازه دهید بررسی کنیم که آیا دادههای ورودی به توزیعهای مشابه تعلق دارند!
جمعبندی
همه ما میخواهیم که مدلهای یادگیری ماشین به خوبی اجرا شوند و بدانیم که میتوانیم به خروجی مدل اعتماد کنیم.
در حالی که یک ایده خوش بینانه برای نظارت بر مدلهای یادگیری ماشین با یک مدل نظارت شده دیگر «سگ نگهبان» شانس کمی برای موفقیت دارد، خود قصد و نیت ارزش خود را دارد. راههای دیگری نیز برای اطمینان از کیفیت تولید مدل شما وجود دارد.
این موارد شامل ایجاد یک فرآیند نظارتی کامل، طراحی سناریوهای کاربردی مدل سفارشی، تشخیص دادههای پرت و غیره است.
این متن با استفاده از ربات مترجم مقاله علم داده ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است. در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
بهترین و بدترین داشبوردهای مانیتورینگ ویروس کرونا
مطلبی دیگر از این انتشارات
کریستال زمان چیست؟ و چگونه محققان گوگل از کامپیوترهای کوانتومی برای ساختن آنها استفاده میکنند؟
مطلبی دیگر از این انتشارات
یک ایده از فیزیک کمک میکند که هوش مصنوعی در ابعاد بالاتر ببیند