

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
بنجیو و تیمش چارچوب تعیین معیار GNN را معرفی میکنند.

منتشرشده در: مجله Syncedreview به تاریخ ۵ مارچ ۲۰۲۰
نویسنده: Fangyu Cai
لینک مقاله اصلی:https://medium.com/syncedreview/yoshua-bengio-and-team-introduce-gnn-benchmarking-framework-64553de9de54
یک مطالعه جدید یک چارچوب گراف شبکه عصبی (GNN) تکرارپذیر را برای مطالعه و کمی کردن تاثیر پیشرفتهای نظری GNNها معرفی میکند. در زمینه تجزیه و تحلیل و یادگیری از دادههای روی گراف، GNNها به یک ابزار ضروری تبدیل شدهاند. با برنامههای امیدوار کننده در حوزههای مختلف مانند شیمی، فیزیک، علوم اجتماعی، نمودارهای دانش، توصیه، و علوم اعصاب، چگونگی مطالعه و ساخت GNNهای قویتر یک موضوع داغ است.
بدون یک معیار استاندارد، حتی تعریف آنچه یک GNN "قدرتمند" میسازد دشوار است. در مقاله تعیین معیار شبکههای عصبی گراف، محققان یک چارچوب تعیین معیار GNN انعطافپذیر پیشنهاد کردهاند که میتواند نیازهای محققان برای اضافه کردن مجموعه دادهها و مدلهای جدید را نیز برآورده کند. این تیم شامل یوشع بنجیو و محققان از دانشگاه فنی نانیانگ، دانشگاه لویولا مریمونت، مایلا، دانشگاه مونترال و CIFAR است.
طراحی یک معیار منصفانه در ابتدا نیازمند تعریف مجموعه دادههای نماینده، واقع گرایانه و مقیاس بزرگ است. محققان مجموعه دادههای CORA و TU محبوب را رد کردند. پروفسور خاویر برسون، یکی از نویسندگان، توضیح داد: «هدف ما شناسایی روندها و بلوکهای ساختمانی خوب برای GNN ها بود.» چنین تحلیلی با مجموعه دادههای CORA و TU کوچک امکان پذیر نبود (تمام GNN ها همانند NNهای غیرگراف عمل میکنند) اگرچه بیشتر کارهای منتشر شده قبلی بر مجموعه دادههای کوچک متمرکز شدهاند - CORA و TU تنها چند صد نمودار دارند - اجتنابناپذیر بود که محققان با محدودیتهایی در این مورد مواجه شوند.
محققان مجموعهای از مجموعه دادههای مقیاس متوسط با ۱۲ تا ۷۰ هزار گراف با اندازه متغیر ۹ - ۵۰۰ گره از مدلسازی ریاضی (مدلهای بلوک تصادفی)، دید کامپیوتری (ابر پیکسل)، بهینهسازی ترکیبی (مساله فروشنده دورهگرد) و شیمی (حلالیت مولکولها) را برای بررسی معماریهای مختلف GNN برای تفاوتهای واضح و از نظر آماری معنیدار در هنگام مقایسه عملکرد پیشنهاد در نظر گرفتند.
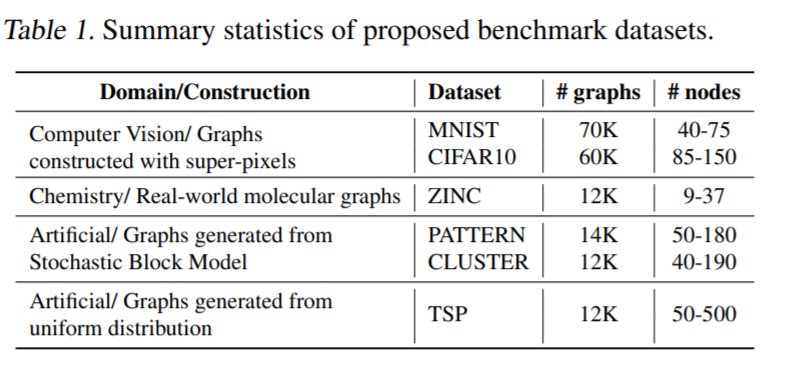
مساله دیگر در مجموعه دادههای کوچک بیشبرازش است. مجموعه دادههای کوچک زمانی مفید هستند که محققان ایدههای جدید را توسعه میدهند، اما در دراز مدت طراحی و توسعه مدلهای GNNهای بالغ و پیشرفته تنها مشکل برازش بیش از حد را بدتر خواهد کرد. مجموعه دادههای کوچک نیز میتوانند دلیل عدم تکرارپذیری نتایج تجربی باشند. بدون تنظیمات آزمایشی استاندارد مانند توافق بر سر آموزش، اعتبار سنجی و جداسازی تست و پروتکلهای ارزیابی، مقایسه عملکرد معماری GNNهای جدید ناعادلانه خواهد بود.
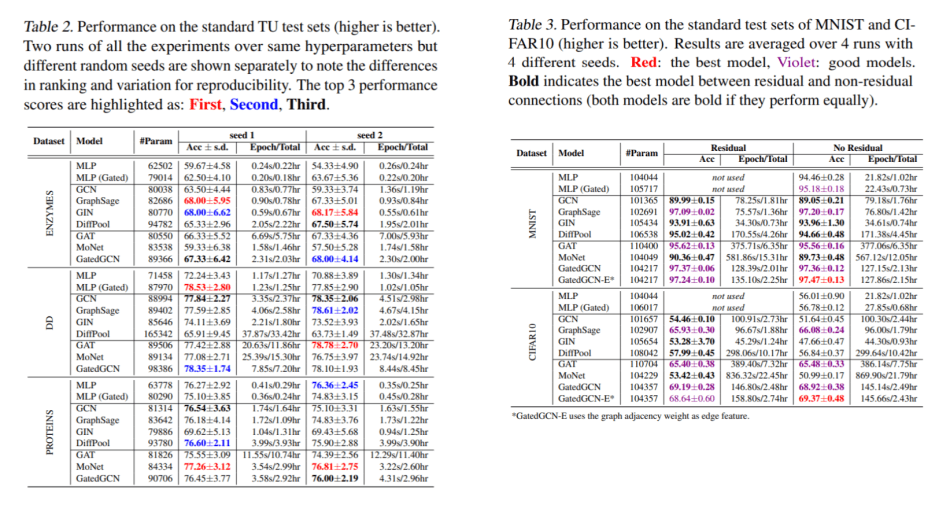
در این مطالعه، محققان آزمایشها عددی را با محکزنی منبع باز پیشنهادی گره چارچوب، یال، طبقهبندی گراف و رگرسیون گراف انجام دادند. در تجزیه و تحلیل طبقهبندی گراف با مجموعه دادههای TU و طبقهبندی گراف با مجموعه دادههای SuperPixel، محققان به این نتیجه رسیدند که NN های گراف - ندانمگرا نیز همانند GNNها در مجموعه دادههای کوچک عمل میکنند. علاوه بر این، آزمایش رگرسیون گراف با مجموعه داده مولکولی ZINC نشان داد، برسون اظهار داشت: «همانطور که انتظار میرفت، NN گراف برای مجموعه دادههای بزرگتر بهتر از NN های غیر گراف عمل میکند … هیچ چیز جدید و روشنتری وجود ندارد، اما نشان دادن تجربی آن مهم بود.»
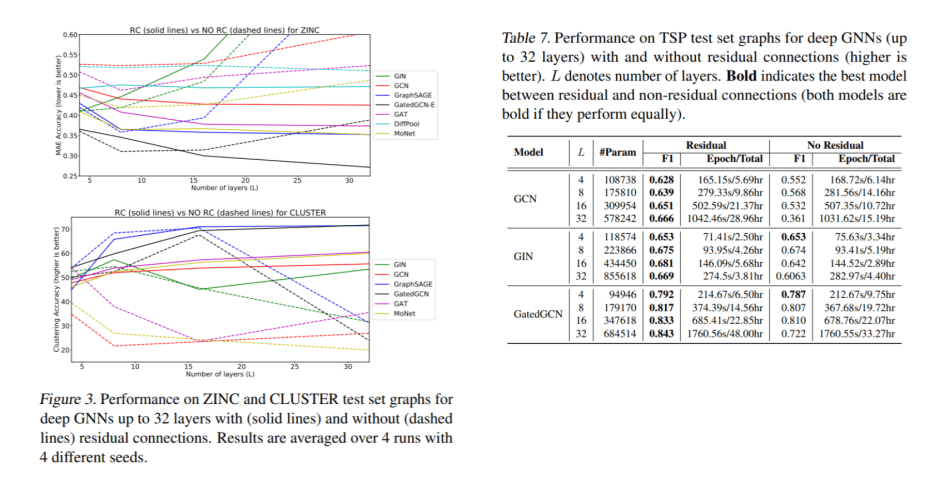
همچنین آزمایشها عددی نشان دادند که اتصالات مانده عملکرد را بهبود میبخشند و یک بلوک ساختمان مهم برای طراحی GNNهای عمیق هستند. با بررسی نتایج GNNهای عمیق برای گرافهای مجموعه آزمایش ZINC، CLUSTER و TSP، محققان مشاهده کردند که وقتی تعداد لایهها عملکرد همه مدلها به جز GIN را افزایش میدهد. آنها همچنین نتیجه گرفتند که «کانولوشن گراف، انتشار ناهمسانگرد، اتصالات مانده و لایههای نرمال سازی بلوکهای سازنده جهانی برای توسعه GNP های قوی و مقیاس پذیر هستند.»
تیم تحقیقاتی زیر ساخت معیار باز برای ارزیابی GNNها در گیتهاب را براساس PyTorch و DGL منتشر کردهاست.
این مقاله توسط مترجم تخصصی هوش مصنوعی و به صورت خودکار ترجمه شده و با حداقل ویرایش و بازبینی انسانی منتشر شده است.
مطلبی دیگر از این انتشارات
تاثیر ویروس کرونا بروی بارداری و زنان حامله
مطلبی دیگر از این انتشارات
گوگل دوباره این کار را کرد! مهندسي كه لامدا را حساس ناميد، اخراج كرد
مطلبی دیگر از این انتشارات
نه گام ساده برای کدهای پایتون با ظاهری بهتر