

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
بهبود عملکرد مدل از طریق مشارکت انسانی

منتشرشده در kdnuggets به تاریخ آوریل ۲۰۲۱
لینک منبع Improving model performance through human participation
برخی صنایع، مانند پزشکی و مالی، به مثبتهای کاذب حساس هستند. استفاده از ورودی انسان در حلقه استنتاج مدل میتواند دقت و فراخوانی نهایی را افزایش دهد. در اینجا ما چگونگی ترکیب بازخورد انسانی در زمان استنتاج را شرح میدهیم، به طوری که ماشینها + انسانها = دقت و یادآوری بهتر.
حوزههای خاص به شدت به مثبت کاذب حساس هستند. مثالی از این مورد، تشخیص تقلب در کارت اعتباری است، که در آن طبقهبندی نادرست یک فعالیت به عنوان تقلب میتواند تاثیر منفی قابلتوجهی بر شهرت موسسه مالی صادر کننده کارت اعتباری داشته باشد .مثال دیگر، رباتهای چت خودکار هستند که از مدلهای زبانی (GPT-۳) برای تولید پاسخهای متنی به سوالات مشتری استفاده میکنند . تنظیم متن تولید شده مهم است تا اطمینان حاصل شود که، حداقل، زبان نامناسب تولید نمیشود (مانند سخنرانی نفرتآمیز، کلمات زشت و غیره).
حوزه بسیار حساس دیگر حوزه پزشکی است، که در آن چیزی مانند تشخیص سرطان به شدت به تشخیصهای مثبت کاذب حساس است .در بخشهای زیر، ما ابتدا سیستمی را توصیف میکنیم که از یک مدل ML برای استنباط استفاده میکند و سپس جزئیات اصلاحات مورد نیاز برای شامل کردن عوامل انسانی در حلقه استنتاج را شرح میدهیم.
استنباط مبتنی بر مدل

بیایید با یک سیستم معمولی شروع کنیم که به یک مدل یادگیری ماشین برای مورد استفاده تقلب کارت اعتباری خدمت میکند. شکل بالایک دیدگاه ساده شده از یک سیستم و توالی رویدادهایی را نشان میدهد که در آن مدل به تنهایی مسئول تصمیمگیری در مورد این است که آیا یک فعالیت دادهشده جعلی است یا خیر.
مطالعه مقاله آیا شرکت شما برای هوش مصنوعی بدون کد آماده است؟ توصیه میشود.
چگونه آستانه را انتخاب کنیم؟
آستانه بر اساس الزامات دقت و فراخوانی انتخاب میشود . در مثال نشاندادهشده در شکل ۱، دقت به این صورت تعریف میشود که تعداد فعالیتهای کلاهبردارانه که به درستی پیشبینی شدهاند (مثبتهای حقیقی) تقسیمبر تعداد کل فعالیتهایی است که کلاهبردارانه پیشبینی شدهاند (مثبتهای حقیقی + مثبتهای غلط). به یاد آوردن به عنوان تعداد فعالیتهای کلاهبردارانه که به درستی پیشبینی شدهاند (تشخیصهای مثبت واقعی) تقسیمبر مجموع تعداد فعالیتهایی که به درستی به عنوان تقلب پیشبینی شدهاند، و تعداد فعالیتهای کلاهبردارانه واقعی که غیرکلاهبردارانه پیشبینی شدهاند (تشخیصهای مثبت واقعی + تشخیصهای منفی غلط) تعریف میشود. در اغلب موارد، یک توازن بین دقت و یادآوری باید برای رسیدن به اهداف سیستم ایجاد شود. یک ابزار مفید که به این توازن کمک میکند منحنی دقت-بازیابی است. . شکل پایین یک منحنی دقت-بازیابی را نشان میدهد.
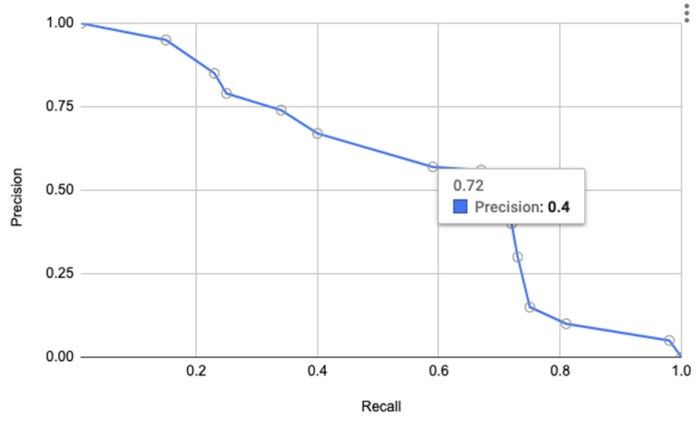
توجه کنید که چگونه دقت در سطوح بالاتر یادآوری کاهش مییابد. با یادآوری ۷۲/۰، میزان دقت به ۴/۰ کاهش مییابد. برای گرفتن ۷۰٪ موارد کلاهبرداری، ما تعداد زیادی مثبت کاذب با دقت ۴۰٪را متحمل میشویم. در مورد ما، تعداد مثبتهای غلط قابلقبول نیست زیرا منجر به تجربه بسیار بد مشتری میشود. ما به دقت بالاتری در مقادیر منطقی یادآوری نیاز داریم. توجه داشته باشید که آنچه به عنوان تعداد قابل قبولی از تشخیصهای مثبت کاذب واجد شرایط است، ذهنی است. برای مورد استفاده ما، از شکل۲ ما به دقت بیشتر از ۹۹/۰ نیاز داریم.
اگرچه ما یک موازنه به نفع دقت بالاتر، با دقت ۰.۹۹انجام دادیم، یادآوری ۰.۱۵است که کافی نیست. برای به یاد آوردن بیشتر، ما دقت کمتری به دست خواهیم آورد که برای کسبوکار قابلقبول نیست. در بخش بعدی، در مورد چگونگی استفاده از ورودی انسانی برای دستیابی به سطوح بالاتر دقت کلی در فراخوانی بالاتر بحث خواهیم کرد.
شاید مطالعه مقاله الگوریتم بوت کردن گرادیان چگونه کار میکند؟ برای شما مفید باشد.
مشارکت انسانی
شکل ۴ یک سیستم تغییر یافته را نشان میدهد که شامل تعامل انسان است.

یک راه برای افزایش یادآوری، درگیر کردن عوامل انسانی در حلقه استنتاج است. در این مجموعه، زیر مجموعهای از فعالیتها که در آن اعتماد به مدل پایین است، برای بازرسی دستی به یک عامل انسانی فرستاده میشود. هنگام انتخاب آستانهای که زیر مجموعهای از پیشبینیها را تعیین میکند که به عنوان پیشبینیهای کم اطمینان / مبهم واجد شرایط هستند، مهم است که حجم فعالیتهای مبهم که به عوامل انسانی فرستاده میشوند را در نظر بگیریم زیرا دومی یک منبع کمیاب است. برای کمک به انتخاب آستانه، نمودار دقت-فراخوانی-آستانه میتواند مورد استفاده قرار گیرد (شکل. ۵).
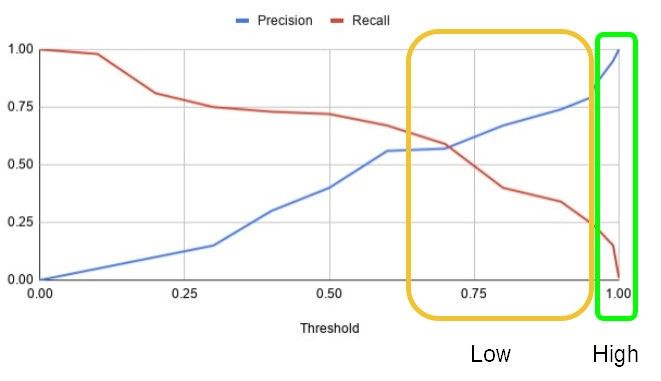
در مورد ما، فرض کنیم که یک امتیاز نزدیکتر به ۱.۰ نشاندهنده یک برچسب مثبت (تقلب)، و یک امتیاز نزدیکتر به ۰.۰نشاندهنده یک برچسب منفی (بدون تقلب) است. دو ناحیه وجود دارد که در شکل ۵ نشانداده شدهاند.
۱. ناحیه سبز نشاندهنده ناحیه اعتماد بالا برای یک برچسب مثبت است، به عنوان مثال، که در آن تصمیمات مدل خودکار مجاز هستند، و دقت مدل حاصل قابلقبول است (نرخ پایین مثبت کاذب به طور کلی توسط کاربران نهایی که تحتتاثیر قرار میگیرند به خوبی تحمل میشود).
۲. ناحیه زرد نشاندهنده ناحیهای با اطمینان کم برای برچسبهای مثبت است که در آن تصمیمات مدل خودکار دارای سطوح دقت قابلقبول نیستند (نرخ بالای مثبت کاذب منجر به تاثیر منفی قابلتوجه بر کسبوکار میشود).
منطقه زرد منطقهای است که کاندید خوبی برای استفاده از عوامل انسانی برای افزایش دقت از طریق بازرسی دستی است. از همین فرآیند میتوان برای استدلال در مورد برچسبهای منفی استفاده کرد-مساحت نزدیک به ۰.۰یک ناحیه اعتماد به نفس بالا است، و بالاتر از یک آستانه خاص، نتیجه فازی است. همه آیتمها یا زیر مجموعهای از آیتمها از مناطق زرد را میتوان برای بازرسی دستی ارسال کرد. در طول یک بازرسی دستی، نماینده انسانی وقت صرف تصمیمگیری درباره نتیجه نهایی فعالیت-در مورد ما، تقلب یا عدم-با استفاده از صلاحدید و قضاوت توسعهیافته از طریق یک فرآیند آموزشی دقیق میکند. فرض کلیدی در اینجا این است که عوامل انسانی از نظر تصمیمگیری در موارد مبهم بهتر از مدل ML هستند.
همانطور که قبلا ذکر شد، منابع انسانی کمیاب هستند. از این رو، حجم درخواستهای ارسالشده به عوامل انسانی در هنگام انتخاب آستانه، یک ملاحظه مهم است. . شکل ۶ مثالی از حجم و فراخوانی رسم شده در برابر آستانه را نشان میدهد. حجم به صورت تعداد موارد در هر ساعت تعریف میشود که برای بررسی به عوامل انسانی ارسال خواهد شد. از شکل ۶، حجم در آستانه ۰.۷ برابر با ۱۶ K آیتم (در هر ساعت) است.
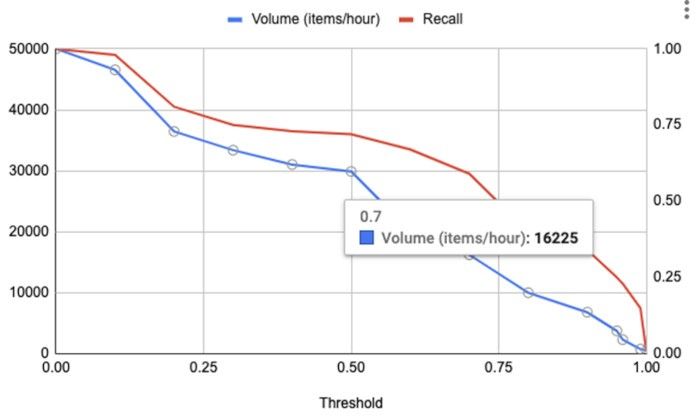
هر دو نمودار نشاندادهشده در شکل. ۵ و شکل ۶ را میتوان برای انتخاب آستانه مناسب برای یادآوری مطلوب در حجم قابل قبولی از مرور انسانی بکار برد. بیایید یک تمرین سریع در تعیین آستانه این دو نمودار انجام دهیم. در سطح فراخوانی ۰.۵۹ (آستانه ۰.۷) ، حجم (شکل. ۵) در حدود ۱۶ K آیتم / ساعت خواهد بود. دقت مدل حدود ۰.۶ است (شکل. ۵) در همان سطح یادآوری. با فرض اینکه مخزن عامل انسانی قادر به رسیدگی به حجم ۱۶ K آیتم / ساعت و همچنین با فرض اینکه دقت و فراخوانی عامل انسانی ۹۵٪ است، دقت حاصل پس از مرور انسان در سطح فراخوانی ۰.۵۹ بین ۰.۹۵ تا ۰.۹۹ خواهد بود. در مجموع، با استفاده از این راهاندازی، ما قادر به افزایش فراخوانی از ۰.۱۵ به ۰.۵۶ (مدل * ۰.۹۵ [ انسان ]) و در عین حال حفظ سطح دقت بالاتر از ۰.۹۵ بودیم.
ممکن است به مطالعه مقاله آموزش تمام مدلهای طبقهبندی یا رگرسیون در یک خط کد پایتون علاقمند باشید.
بهترین روشها در استفاده از نمایندههای انسانی
به منظور دستیابی به بررسیهای انسانی با کیفیت بالا، ایجاد یک فرآیند آموزشی به خوبی تعریفشده برای عوامل انسانی که مسئول بررسی دستی آیتمها خواهند بود، مهم است. یک برنامه آموزشی خوب فکر شده و یک حلقه بازخورد منظم برای عوامل انسانی به حفظ نوار با کیفیت بالا از موارد مرور شده دستی در طول زمان کمک خواهد کرد. این آموزش دقیق و حلقه بازخورد به حداقل رساندن خطای انسانی علاوه بر کمک به حفظ الزامات SLA برای هر مورد تصمیمگیری کمک میکند.
استراتژی دیگری که کمی گرانتر است استفاده از بهترین رویکرد برای هر آیتم است که به صورت دستی بررسی میشود، یعنی استفاده از ۳ نماینده برای بررسی همان آیتم و گرفتن اکثریت آرا از ۳ نماینده برای تصمیمگیری درباره نتیجه نهایی. علاوه بر این، اختلافات بین عوامل را ثبت کنید تا تیمها بتوانند به گذشته در مورد این اختلافات نگاه کنند تا سیاستهای قضاوت خود را اصلاح کنند.
بهترین تجارب قابلاجرا برای خدمات خرد نیز در اینجا مورد استفاده قرار میگیرند. این شامل نظارت مناسب بر موارد زیر است:
- تاخیر پایان به پایان یک آیتم از زمانی که در سیستم دریافت شد تا زمانی که یک تصمیم در مورد آن گرفته شد.
- سلامت کلی مخزن عامل
- حجم اقلامی که برای مرور انسان فرستاده شدهاند
- آمارهای ساعتی در طبقهبندی آیتمها
در نهایت، دقت و یادآوری مدل میتواند در طول زمان به دلایل مختلف تغییر کند .مهم است که با پیگیری دقت/یادآوری، آستانههای انتخابشده را بازبینی کنیم.
نتیجهگیری
ما بررسی کردیم که چگونه یک سیستم استنتاجML شامل عوامل انسانی میتواند به افزایش یادآوری کمک کند در حالی که سطوح بالایی از دقت را حفظ میکند. این رویکرد به ویژه در موارد استفاده که به تشخیصهای مثبت کاذب حساس هستند، مفید است. منحنی دقت-فراخوانی-آستانه یک ابزار عالی در انتخاب آستانه برای بررسی انسان و تصمیمات مدل خودکار است. با این حال، وارد کردن عوامل انسانی باعث افزایش هزینه میشود و میتواند باعث تنگناهایی در مقیاسبندی سیستمی شود که در حال تجربه رشد بیش از حد است. انجام دقیق معاملات بر روی این جنبهها در هنگام در نظر گرفتن چنین سیستمی مهم است.
این متن با استفاده از ربات مترجم مقاله تکنولوژی ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
کریپتوکارنسی یا ارز دیجیتال چیست؟
مطلبی دیگر از این انتشارات
اینستاگرام پس از اینکه به سانسور محتوای حامی فلسطین متهم شد، در الگوریتم خود تغییراتی ایجاد کرد
مطلبی دیگر از این انتشارات
اپل و گوگل با همکاری یکدیگر، تعقیب غیرقانونی AirTag را محدود میکنند