

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
به سوی پایپلاین یادگیری کاملا خودکار
منتشرشده در: towardsdatascience به تاریخ ۷ ژوئن ۲۰۲۱
لینک منبع Towards a Fully Automated Active Learning Pipeline
من در پست قبلی خود، مقدمهای کوتاه بر نظریه و روشهای یادگیری فعال ارائه کردم. گام بعدی در سفر یادگیری فعال اجرای آن است. در این پست، من سفرم را به سمت یک پایپلاین یادگیری فعال کاملا خودکار به اشتراک خواهم گذاشت.
مرحله ۱-انگیزه برای پیادهسازی
در ابتدا، مانند دیگر توسعه دهندگان الگوریتم با انگیزه، من با اجرای روش یادگیری فعال انتخابی، یک گام برمی دارم. من به مراحل بعدی و «تصویر بزرگتر» فکر نکردم. از یک طرف، من را خیلی سریع به یک اجرای کاری (از نظر مهندسی) رساند. از سوی دیگر، گامهای بعدی را سختتر کرد. در مورد من دو قدم موازی داشتم که سه سوال مختلف را مطرح میکرد:
- چگونه یک پایپلاین یادگیری فعال بسازم؟
- چگونه پایپلاین را به روش مدولار و عمومی بسازیم؟
- چگونه چند کار مختلف را با پایپلاین ترکیب کنیم؟
مرحله ۲-یادگیری فعال پایپلاین-نیمه خودکار
اولین یادگیری فعال من اجرای پایپلاین نیمه خودکار بود. هر چرخه کاملا خودکار اجرا میشود اما به صورت دستی اجرا میشود. برای این منظور، اصلیترین مورد، انتخاب کننده داده است.
انتخابکننده داده
انتخابکننده داده هدف یادگیری فعال را در خود جای میدهد-انتخاب تصاویر بعدی که باید به شیوهای آگاهانه تفسیر شوند. ورودی آن مجموعهای از دادههای علامتگذاری نشده فعلی است و خروجی آن یک مجموعه فرعی است که باید علامتگذاری شود.
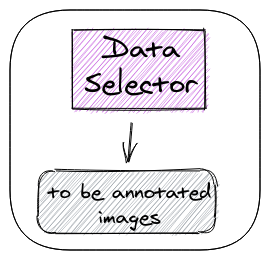
انتخابکننده داده میتواند یک شبکه عصبی اضافی، الگوریتم کلاسیک، پرس و جوی پایگاهداده، یا هر روش دیگری باشد که برای شما کار میکند.
در هر چرخه، انتخابکننده داده براساس بهترین مدل از چرخه قبلی است. مجموعه خروجی آن به مجموعه آموزشی چرخه قبلی اضافه میشود (پس از تفسیر آن).
چرا نیمه خودکار به اندازه کافی خوب نیست؟
یک پایپلاین نیمه اتوماتیک، علاوه بر سربار اجرای دستی هر چرخه، که زمانبر است، نیاز به نظارت دارد. منظور من از نظارت این است که ما باید به یاد داشته باشیم که میخواهیم کدام چرخه را اجرا کنیم، که در آن وضعیت چرخه قبلی را ذخیره کنیم، به صورت دستی مدل استنباطی را از چرخه قبلی انتخاب کنیم، و بیشتر. این فرآیند پتانسیل بالایی برای خطاها، اشکالات و سردرگمی دارد. در حالت ایدهآل ما یک پایپلاین کاملا اتوماتیک میخواهیم که موضوع بخش بعدی ما است.
مرحله ۳-یادگیری فعال مدولار و عمومی پایپلاین
من چندین مدل برای کارهای مختلف دارم. یک روز خودم را در حال کپی کردن از یک فایل به چهار فایل مختلف دیگر یافتم، دوباره و دوباره. در این مرحله، من تصمیم گرفتم که چیزی باید تغییر کند، و وقت استاندارد سازی است.
مولفه آموزشی پایپلاین مهمترین مولفه از نظر مهندسی نرمافزار است. حفظ معماری مدولار و استاندارد برای آموزش پایپلاین میتواند در زمان اجرای یک شبکه جدید مشکلات زیادی را برای شما به همراه داشته باشد.
من با الهام از این قالب، معماری کد یادگیری عمیق خود را با سه مولفه اصلی ایجاد کردم-بارگذار داده، گراف، و عامل.
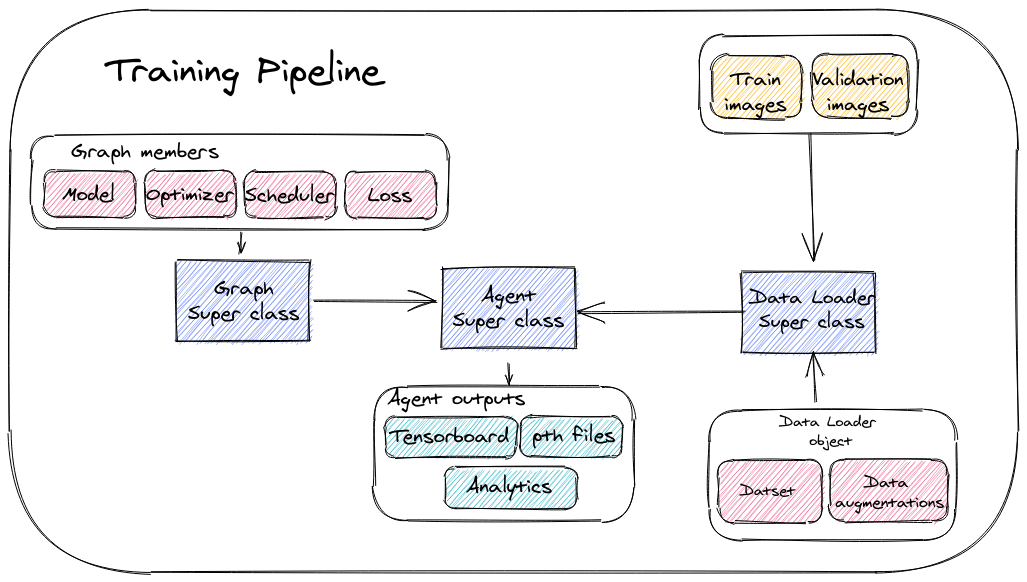
بارگذار داده -همانطور که از نامش پیداست، بارگذار داده تمام چیزی که نیاز داریم را در خود جای میدهد تا یک شی بارگذار داده ایجاد کنیم.
نمودار -نمودار شامل مدل شبکه ما و دیگر مولفههای مورد نیاز برای آموزش، مانند بهینهساز، زمانبند، و از دست دادن است.
با تعریف گراف، استفاده مجدد از مولفههای به اشتراک گذاشته شده آسانتر است. به عنوان مثال، من دو وظیفه قطعهبندی با استفاده از تابع زیان یکسان دارم. سوپرکلاس گراف من شامل اجرای تابع اتلاف است، و هر وظیفه به عنوان یک کلاس گراف اجرا میشود که آن را از سوپرکلاس گراف به ارث میبرد.
نماینده -نماینده کلاس آموزشی ما است. هر وظیفه خاص از یک سوپرکلاس نمایندهای به ارث میبرد و باید روشهای آموزش و اول را اجرا کند. یک حلقه آموزشی عمومی در ابر کلاس عامل اجرا میشود و هر کلاس دیگری که از آن به ارث میبرد میتواند آن را گسترش دهد.
مرحله ۴-یادگیری فعال پایپلاین -خودکار
با بازگشت به یادگیری فعال پایپلاین، در نهایت به مرحله آخر میرسیم. برای ایجاد یک پایپلاین کاملا خودکار، باید حلقه را ببندیم. اول، هر چرخه باید حالت قبلی را بارگذاری کند و حالت فعلی خود را ذخیره کند. دوم، ما باید به طور خودکار بهترین مدل استنباطی مورد استفاده را انتخاب کنیم. این کار با استفاده از مدول انتخابکننده مدل انجام میشود.
انتخابکننده مدل -تکمیل آموزش پایپلاین، چندین مدل ذخیرهشده از نقاط مختلف در حلقه آموزش داریم. انتخابکننده مدل با استفاده از یک معیار معین بهترین مدل را انتخاب میکند.
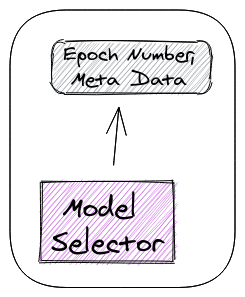
این مدل به عنوان مدل انتخابکننده داده در چرخه بعدی (برای روشهای مربوطه) و به عنوان مدل تولید جدید استفاده خواهد شد.
مرحله پاداش -مدول مقایسه
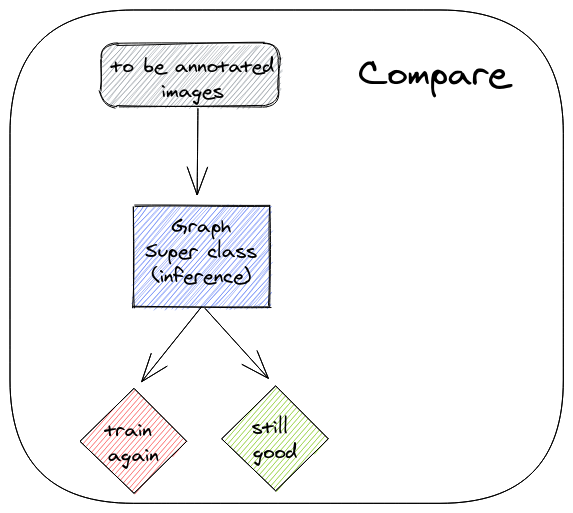
آیا ما همیشه میخواهیم شبکه خود را برای هر دسته انتخابی جدید که علامتگذاری نشده است، مجددا آموزش دهیم؟ احتمالا نه. ما میخواهیم مدل خود را هنگامی که متوجه وخامت نتایج میشویم، دوباره آموزش دهیم. برای این کار، ما از مدول مقایسه استفاده میکنیم.
مدول مقایسه بسیار ساده است و به شرح زیر کار میکند:
- تصاویر علامتگذاری شده جدید را در مدول Data Selector منتقل کنید.
- کیفیت نتایج را اندازهگیری کنید و آنها را با شاخص عملکرد کلیدی خود (KPI) مقایسه کنید.
- با KPI ملاقات میکند-نیازی به آموزش مجدد نیست.
- آیا آموزش KPI را ملاقات نمیکند.
مدول مقایسه را می توان در مرحله توسعه حذف کرد. در مرحله توسعه، ما میخواهیم ثابت کنیم که رویکرد یادگیری فعال ما کار میکند. برای انجام این کار، ما از یک مجموعه داده علامتگذاری شده کامل شناختهشده استفاده میکنیم و نشان میدهیم که میتوانیم نمونههای آموزشی بعدی خود را به شیوهای آگاهانه انتخاب کنیم.
خط پایان
اکنون زمان جمعبندی و خلاصه کردن کل معماری است. در طرح زیر میتوانید پایپلاین خودکار را با تمام مدولها و ارتباطات آنها پیدا کنید.
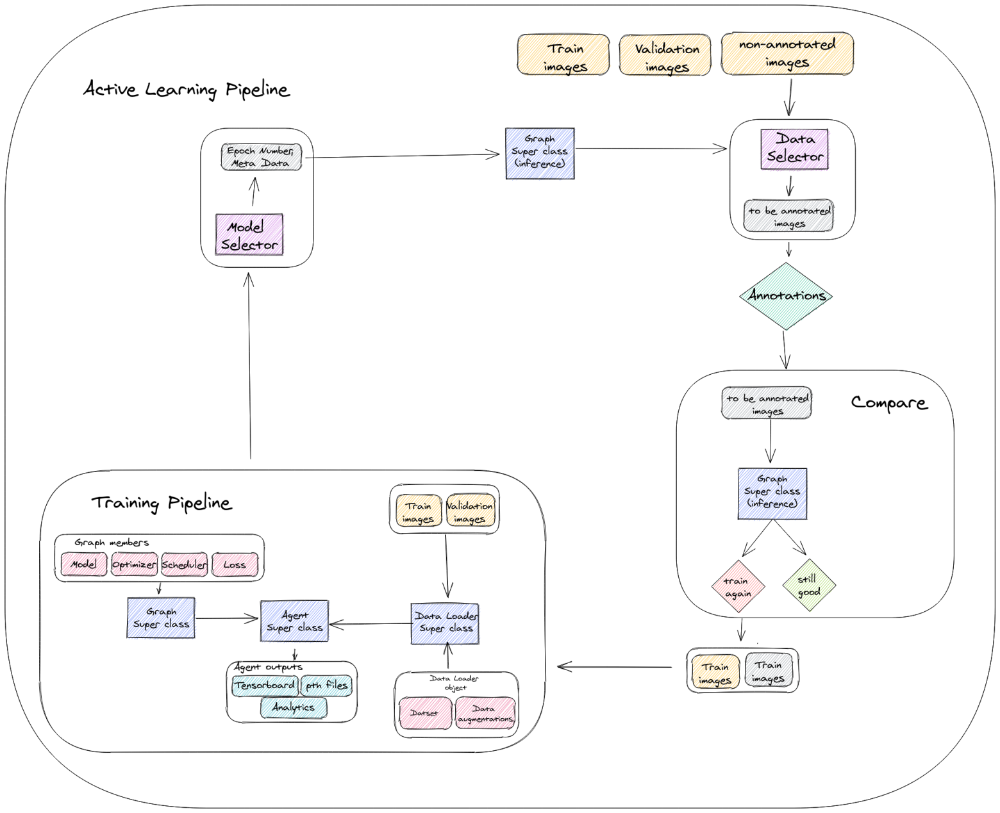
ما این کار را کردیم!

حالا همه ما با مراحل ایجاد یادگیری فعال بزرگ پایپلاین آشنا هستیم.
برای من مدتی طول کشید تا تمام کدهای موجود من با معماری پایپلاین هماهنگ شوند. اما بعد از این که این کار انجام شد، اضافه کردن یک کار جدید یا تغییر روش انتخابکنندهی داده من بسیار آسانتر شد.
موفق باشید!
این متن با استفاده از ربات مترجم مقالات علم داده ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
خودآزاری دیجیتال چیست؟
مطلبی دیگر از این انتشارات
اقتصاد در دوره کووید ۱۹
مطلبی دیگر از این انتشارات
نکاتی برای تقویت زبان انگلیسی