

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
تحلیل انگیزه رسانههای اجتماعی با VADER

منتشرشده در: towardsdatascience به تاریخ ۱ می ۲۰۲۱
لینک منبع: Social Media Sentiment Analysis with VADER
با علم داده، ما به ابزارهای مختلفی برای رسیدگی به طیف متنوعی از مجموعه دادهها نیاز داریم. قبل از پرداختن به روشهای مختلف برای تجزیهوتحلیل احساسات، مهم است که توجه داشته باشید که این یک تکنیک در پردازش زبان طبیعی است. اغلب NLP ، مطالعه این است که چگونه کامپیوترها میتوانند زبان انسان را درک کنند. و اگرچه این یک تخصص است که در میان دانشمندان داده محبوب است، اما منحصر به این صنعت نیست.
کار کردن با دادههای متنی مجموعه منحصر به فردی از مشکلات و راهحلهایی را به همراه دارد که انواع دیگر مجموعه دادهها ندارند. اغلب، دادههای متنی نیاز به پاکسازی و پیشپردازش بیشتری نسبت به انواع دیگر دادهها دارند. با این حال، تکنیکهای تجزیهوتحلیل داده اکتشافی منحصر به فردی وجود دارد که ما میتوانیم با دادههای متنی، مانند ابرهای کلمه، تجسم رایجترین کلمات، و غیره اعمال کنیم. برای این وبلاگ، ما به تجزیهوتحلیل احساسات میپردازیم.
مطالعه مقاله ۳ ابزار برای پیگیری و تصویرسازی اجرای کد پایتون شما توصیه میشود.
تجزیهوتحلیل احساسات
تجزیهوتحلیل احساسی تجزیهوتحلیل این است که یک سند متنی چقدر مثبت، منفی و خودسر است. به عنوان مثال، این تکنیک معمولا در بررسی دادهها استفاده میشود، تا ببینیم مشتریان درباره محصول یک شرکت چه احساسی دارند. مشکل دادههای متنی این است که نشاندهنده زبان انسان است. بنابراین، متنوع است و به طور مداوم در حال تکامل است، یادگیری ماشینی باید به طور مداوم مدلها را بر اساس واژگان جدید مهار کند. به عنوان مثال، متن رسانه اجتماعی برای الگوریتم یادگیری ماشین بسیار ظریف و دشوار است.
کتابخانههای مختلف زیادی وجود دارند که میتوانند به ما در انجام تجزیهوتحلیل احساسی کمک کنند، اما ما نگاهی به یکی از آنها میاندازیم که به طور خاص برای دادههای رسانهای اجتماعی کثیف موثر است، VADER. VADER مخفف فرهنگ لغت معتبر برای اصلاح احساسات است و یک ابزار تحلیل احساسات است که هم به شدت و هم به جهت قطبیت احساسات در متن انسان حساس است. این واژهنامه یک سیستم مبتنی بر قاعده است که به طور خاص بر روی دادههای رسانههای اجتماعی آموزش داده میشود. شما میتوانید مخزن Github را برای این ابزار در اینجا بررسی کنید.
بلاب متنی (TextBlob)
برای درک موثر بودن این ابزار، ما میتوانیم ابتدا نگاهی به نحوه عملکرد بلوک متنی بر روی دادههای توییتر بیندازیم. برای اهداف این وبلاگ، نمونههایی از پروژه اخیرم، ردیابی گفتار نفرتآمیز توییتر را نشان خواهم داد، که در آن دادههای متنی قبلا پاک شدهاند.
لطفا توجه داشته باشید، با توجه به ماهیت پروژه، تجسمهای زیر در این وبلاگ شامل زبان ساده، غیرسانسور شده و توهینآمیز است.
برای اغلب پروژههای پردازش زبان طبیعی که دارای متن «عادی» مانند کتاب، مقاله خبری، بررسی فیلم و غیره هستند، ما معمولا میتوانیم از TextBlob استفاده کنیم. TextBlob یک کتابخانه است که یک API ساده را برای رسیدگی به دادههای متنی با وظایفی مانند دادههای بخشی از گفتار، استخراج عبارات اسمی، tokenization، طبقهبندی و غیره فراهم میکند. برای تحلیل احساسی، TextBlob منحصر به فرد است زیرا علاوه بر نمرات قطبیت، نمرات ذهنیت را نیز ایجاد میکند. اگر ما با مجموعه داده هر توییت در یک ردیف شروع کنیم، میتوانیم یک تابع لاندای ساده برای اعمال روشها به توییت ها ایجاد کنیم.
pol = lambdax: TextBlob(x).sentiment.polaritysub = lambda x: TextBlob(x).sentiment.subjectivity
پس از آن، میتوانیم از یک تابعgroupby برای مشاهده میانگین قطبیت و امتیاز ذهنیت برای هر برچسب Hate Speech یا نه Hate Speech استفاده کنیم.
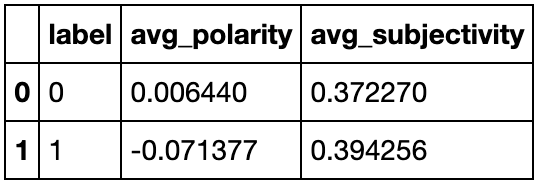
امتیاز قطبیت بافت بلوک در مقیاسی از ۱-(منفیترین) تا ۱ (مثبتترین) اندازهگیری میشود. به نظر نمیرسد متن سخنرانی نفرت (برچسب ۰) با میانگین امتیاز ۰.۰۰۶نسبتا خنثی باشد، درحالیکه متن سخنرانی نفرت (برچسب ۱) نیز میتواند با امتیاز -۰.۰۷۱ خنثی در نظر گرفته شود. و با نگاهی به ذهنیت آنها، به نظر میرسد که هر دو برچسب سطح مشابهی از نظر دارند. برای نگاه عمیقتر، میتوانید دفترچه Jupyter را برای این تجزیهوتحلیل در گیتهاب بررسی کنید.
در نهایت، به نظر میرسد که این امتیازات نشاندهنده توییتها در این مجموعه داده نیستند، که در آن متن از صحبت نفرتآمیز تا زبان توهینآمیز تغییر میکند. بنابراین، ما میتوانیم ببینیم که TextBlob زمان سختی برای تجزیهوتحلیل دادههای توییتر داشت. بیایید ببینیم VADER با این نوع دادههای رسانهای اجتماعی کثیف و بیمعنی چه کار میتواند بکند.
استفاده از VADER
حالا ما بالاخره میتوانیم بهVADER برسیم. نکته منحصر به فرد دربارهVADER این است که با دادن امتیاز مثبت، خنثی، منفی و ترکیبی، امتیاز قطبیت هر سند را از بین میبرد. مشابه TextBlob، ما میتوانیم این روش را برای تولید این امتیازات قطبیت برای کل مجموعه داده با استفاده از یک تابع لاندای ساده به کار ببریم.
pol = lambdax: analyser.polarity_scores(x)
این تابع امتیازات را به عنوان یک فرهنگ لغت برمیگرداند، بنابراین پس از چند خط کد دیگر، میتوانیم یک مجموعه داده با هر یک از امتیازات در ستونهای جداگانه ایجاد کنیم. دوباره، میتوانید کل کد را برای خودتان در دفترچه ژوپیتر چک کنید. این چیزی است که ما در نهایت به آن میرسیم.
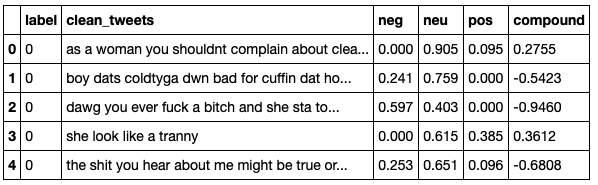
و با برخی توابع groupby، در اینجا میانگین امتیازات برای کل مجموعه داده که با برچسب از هم جدا شدهاند، آورده شده است.
ممکن است به مطالعه مقاله تجسم تحلیلهای بازاریابی- WordCloud علاقمند باشید.
تفسیر نمرات نظرسنجی VADER
نمرات مثبت، منفی و خنثی نشاندهنده نسبت متنی است که در این دستهبندیها قرار میگیرد. بنابراین، توییتهای گفتار نفرت به طور متوسط ۸٪مثبت، ۶۱٪خنثی و ۳۰٪منفی هستند. از طرف دیگر، توییتهای سخنرانی نفرت به طور متوسط ۱۰٪ مثبت، ۶۵٪ خنثی و ۲۵٪ منفی هستند. این نوع تفکیک برای درک دامنه احساسات در مجموعه دادهها بسیار مفید است. این نشان میدهد که هر دو بدنه مشابه هستند، اما برچسب گفتار نفرت به طور متوسط توییتهای منفی بیشتری دارد. جالب است که اکثر توییتها در هر دو کلاس نسبتا خنثی در نظر گرفته شدند، اما حداقل ما یک تفکیک روشن داریم.
امتیاز گروهی مرکب
مهمتر از همه اینکه، کتابخانه امتیاز قطبیت ترکیبی را فراهم میکند، که معیاری است که مجموع تمام رتبهبندیهای واژگان را محاسبه میکند و آنها را بین -۱ و ۱ نرمال میکند. به نظر میرسد این امتیاز قابلاطمینانتر باشد زیرا احساس کلی این پیکره زبانی را در برمیگیرد. هر دو کلاس شامل زبان منفی و تهاجمی هستند. اما میتوانیم از امتیازات بالا ببینیم که توییتهایی که به عنوان سخنرانی نفرت طبقهبندی شدهاند، به ویژه منفی هستند.
گام بعدی تجسم توزیع تمام این نمرات است! شما میتوانید دفتر یادداشت را برای توزیع نمرات مثبت، خنثی و منفی بررسی کنید. اما این توزیع نمرات قطبیت مرکب است.
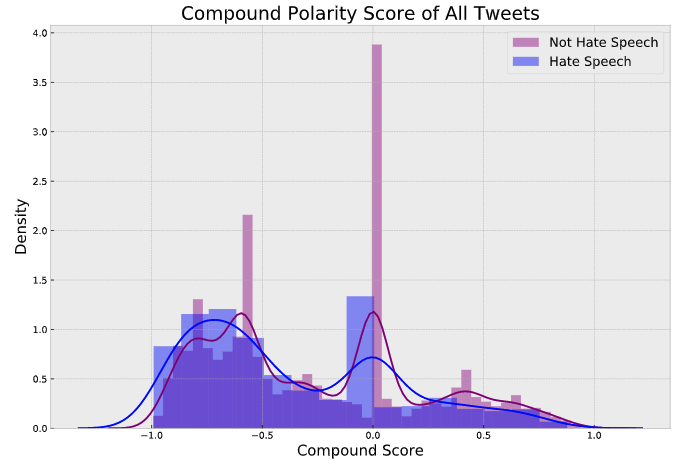
با این نمودار، میتوانیم ببینیم که توییتهای طبقهبندیشده به عنوان سخنرانی نفرت به خصوص منفی هستند، همانطور که قبلا شک داشتیم. همچنین بر تفاوت حاشیهای بین این برچسبها تاکید میکند.
بعد از همه اینها، واضح است کهVADER کتابخانه برتر برای انجام تحلیل احساسی بر روی دادههای رسانههای اجتماعی است. پردازش زبان طبیعی به طور کلی یک بخش بسیار تجربی از یادگیری ماشین است، و همه چیز در مورد پیدا کردن بستههای مناسب است که میتوانند با مجموعه داده شما سازگار شوند. در این مورد، با دادههای سخنرانی نفرت توییتر، ما به یک واژهنامه نیاز داشتیم که بر روی دادههای متنی کثیف و ظریف آموزش داده میشد. لطفا دفعه بعد که با دادههای رسانههای اجتماعی کار میکنید، VADER را امتحان کنید!
این متن با استفاده از ربات مترجم مقاله دیتاساینس ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
قیمت بیت کوین به ۲۰ هزار دلار میرسد
مطلبی دیگر از این انتشارات
کامپیوتر کوانتومی Zuchongzhi چین قدرتمندترین کامپیوتر در جهان است
مطلبی دیگر از این انتشارات
محققان «پیشرفتهترین ربات انساننما جهان، آمیکا» را در جیپیتی-۴ آموزش میدهند