

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
ساخت سریع برنامههای کاربردی وب ML با Streamlit

منتشرشده در: towardsdatascience به تاریخ ۱۰ مارس ۲۰۲۱
لینک منبع: How you can quickly build ML web apps with Streamlit.
اگر شما یک دانشمند داده یا مهندس یادگیری ماشین هستید، احتمالا به توانایی خود در ساخت مدلها برای حل مشکلات کسبوکار در دنیای واقعی اطمینان دارید. اما شما در توسعه وب در ابتدا تا چه حد خوب هستید؟ آیا میتوانید یک برنامه کاربردی وب بصری جذاب برای به نمایش گذاشتن مدلهای خود بسازید؟ به احتمال زیاد، شما ممکن است یک متخصص پایتون باشید، اما نه یک متخصص جاوااسکریپت.
اما شما مجبور نیستید هر دو باشید! استریملایت یک چارچوب پایتون است که یادگیری ماشین و متخصصان علوم داده را برای ساخت برنامههای کاربردی وب در پایتون خالص بسیار آسان میکند. درست است، حتی لازم نیست نگران تگهای HTML، مولفههای بوتاستراپ، یا نوشتن توابع جاوااسکریپت باشید.
در این مقاله، من نشان خواهم داد که چگونه میتوانید از Streamlit برای ساخت سریع یک برنامه کاربردی وب که یک مدل طبقهبندی متن را نشان میدهد، استفاده کنید.
نصب Streamlit
شما به راحتی میتوانید با استفاده از دستور زیر، Streamlit را با pip نصب کنید.
pip install streamlitآموزش یک مدل طبقهبندی متن
من در این بخش یک مدل ساده طبقهبندی اسپم را آموزش میدهم که تعیین میکند آیا یک پیام متنی اسپم است یا نه. از آنجا که تمرکز اصلی این برنامه آموزشی نشان دادن نحوه استفاده از Streamlit است، من کد مورد استفاده برای ساخت این مدل را با حداقل نظرات در نظر خواهم گرفت. من از این مجموعه دادههای طبقهبندی اسپم از کاگل برای آموزش یک شبکه عصبی برای طبقهبندی اسپم استفاده کردم. مجموعه داده اصلی در اینجا به عنوان مجموعه SMS Spam در دسترس است. شما میتوانید کد کامل را برای این برنامه آموزشی در گیتهاب پیدا کنید.
کد بالا مراحل زیر را اجرا میکند:
- مجموعه داده اسپم را بازخوانی میکند.
- مجموعه دادههای اسپم را به مجموعههای آموزشی و آزمایشی تقسیم میکند.
- یک پیشپردازش متنی و خط یادگیری عمیق برای طبقهبندی اسپم ایجاد میکند.
- خط مدل را در مجموعه آموزشی ردیابی میکند.
- خط مدل در مجموعه آزمایش را ارزیابی میکند.
- خط مدل آموزشدیده را حفظ میکند.
ممکن است مطالعه مقاله چگونه با استفاده از موتور Tesseract OCR و پایتون، متن را از تصاویر استخراج کنیم؟ برای شما مفید باشد.
ساخت یک برنامه Streamlit
در همان فولدری که خط مدل ذخیره شده قرار دارد، من فایلی به نام مسیر stream_app.py ایجاد کردم و کد را به صورت تدریجی همانطور که در بخشهای زیر نشان داده شد، اضافه کردم. اگر میخواهید کد کامل این برنامه آموزشی را ببینید، به این مخزن Github مراجعه کنید.
ایمپورت کردن کتابخانهها
من کتابخانهها و ماژولهای لازم، از جمله Streamlit را وارد کردم، که برای اجرای این برنامه مورد نیاز بود، همانطور که در زیر نشانداده شده است.
import joblib
import re
from sklearn.neural_network import MLPClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
import streamlit as stایجاد یک هدر
اکنون که ما Streamlit را وارد کردهایم، میتوانیم با استفاده از پشتیبانی Markdown ، Streamlit، به سرعت یک عنوان ایجاد کنیم.
st.write("# Spam Detection Engine")برای دیدن نتایج این کد، میتوانیم دستور زیر را اجرا کنیم.
streamlit run streamlit_app.pyاجرای کد و هدایت به محل یابی: ۸۵۰۱ نتیجه زیر را به ما میدهد.
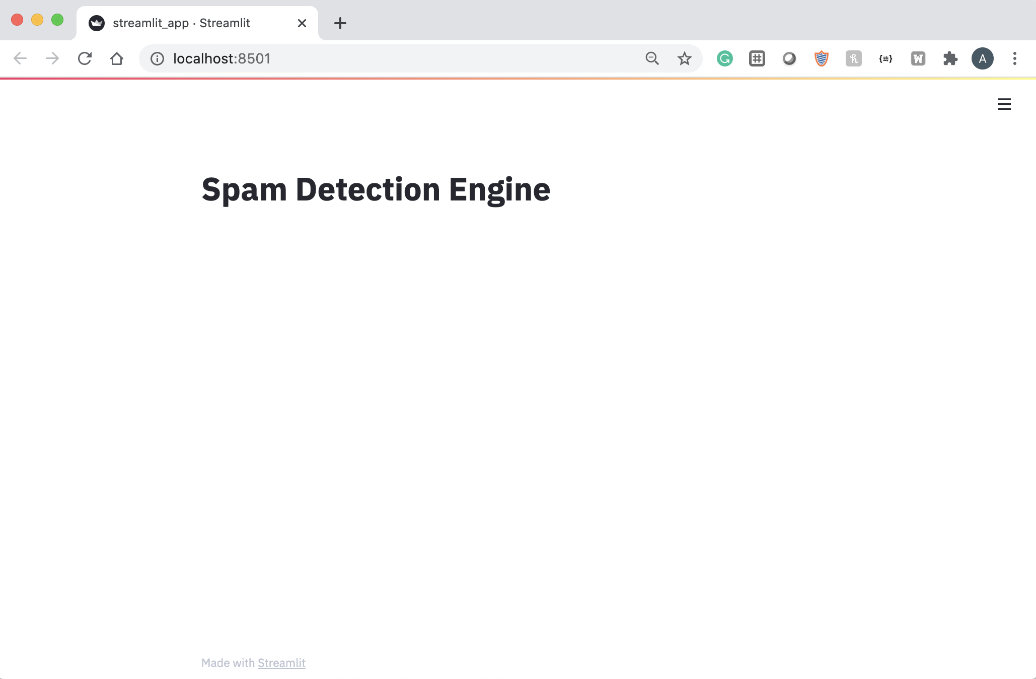
تنها با یک خط کد (بدون احتساب عبارات وارد کردن)، شما اکنون یک برنامه Streamlit در حال اجرا دارید! سپس، میتوانیم چند تعامل را با یک زمینه ورودی متنی به برنامه اضافه کنیم.
اضافه کردن ورودی متن
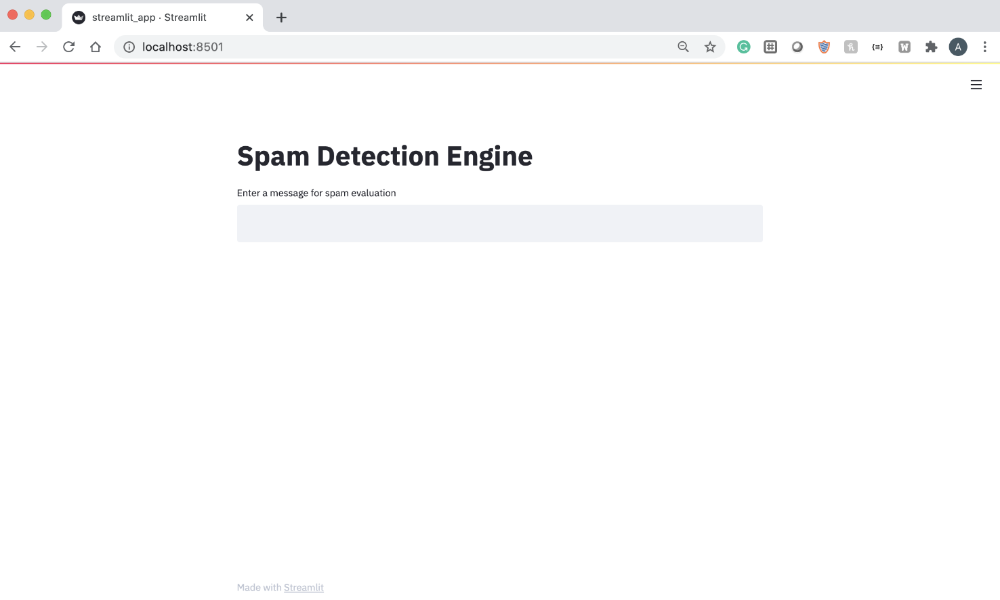
message_text = st.text_input("Enter a message for spam evaluation")بازیابی صفحه برنامه در محل میزبان: ۸۵۰۱ یک فیلد ورودی متن تمیز زیر عنوان را به ما میدهد.
حالا ما میتوانیم مدل طبقهبندی اسپم آموزشدیده خود را به برنامه اضافه کنیم.
بارگذاری مدل
قبل از بارگذاری مدل، من تابع پیشپردازش متن از پیش تعریفشده را در نظر گرفتم زیرا این بخشی از مدل ذخیرهشده است.
def preprocessor(text):
text = re.sub('<[^>]*>', '', text)
emoticons = re.findall('(?::|;|=)(?:-)?(?:\)|\(|D|P)', text)
text = re.sub('[\W]+', ' ', text.lower()) + ' '.join(emoticons).replace('-', '')
return textmodel = joblib.load('spam_classifier.joblib')پیشبینی تولید و نمایش
ما میتوانیم یک تابع خاص برای بازگرداندن برچسب پیشبینیشده توسط مدل (اسپم یا ham) و احتمال اسپم بودن پیام را همان طور که در زیر نشان داده شده است تعریف کنیم.
def classify_message(model, message): label = model.predict([message])[0]
spam_prob = model.predict_proba([message]) return {'label': label, 'spam_probability': spam_prob[0][1]}با استفاده از این تابع میتوانیم پیشبینیهای مدل را به عنوان یک فرهنگ لغت ارائه دهیم.
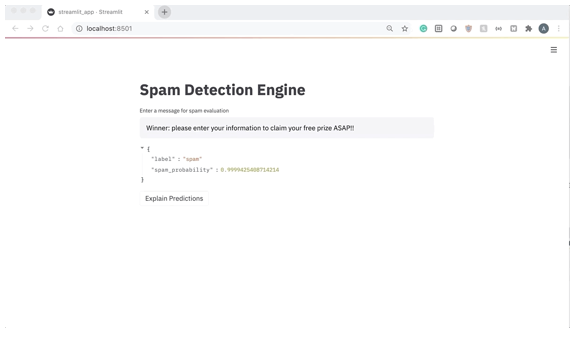
if message_text != '': result = classify_message(model, message_text) st.write(result)ما میتوانیم برنامه را دوباره احیا کنیم و در برخی از ورودیهای متن نمونه عبور کنیم. بیایید با چیزی شروع کنیم که به طور واضح اسپم است.
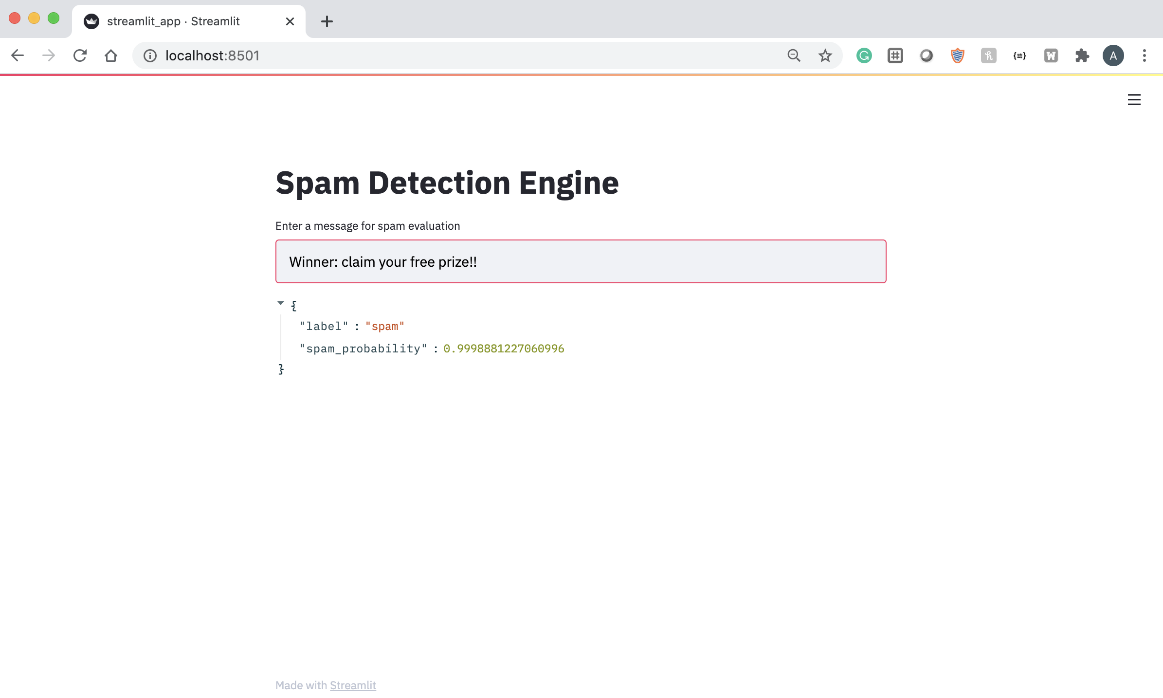
از تصویر بالا، میتوانیم ببینیم که مدل پیشبینی میکند که این پیام شانس بسیار بالایی (۹۸ / ۹۹درصد) اسپم بودن دارد.
حال، بیایید یک پیام در مورد قرار پزشک بنویسیم و ببینیم آیا مدل آن را به عنوان اسپم یا ham طبقهبندی میکند.
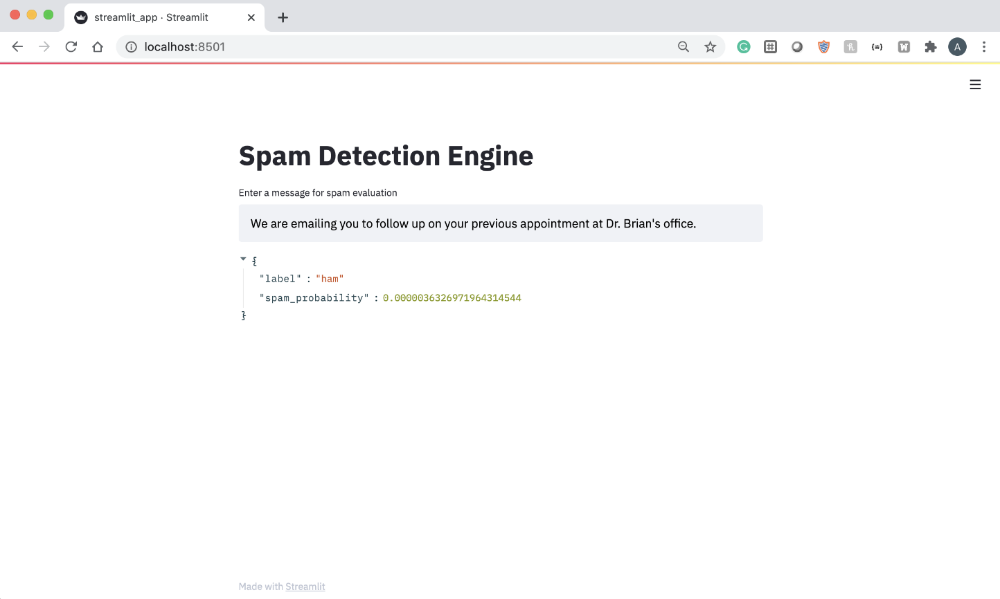
همانطور که در بالا میبینیم، این پیام احتمال بسیار کمی برای اسپم بودن بر اساس پیشبینیهای ایجاد شده توسط مدل دارد.
توضیح پیشبینیهای LIME
ما میتوانیم برخی توضیحات را برای پیشبینیهای ایجاد شده توسط مدل با استفاده از LIME، کتابخانهای برای یادگیری ماشین قابل توضیح اضافه کنیم.
برای استفاده از LIME و قرار دادن توضیح LIME در برنامه کاربردی وب، عبارات وارد کردن زیر را به بالای کد اضافه کنید.
from lime.lime_text import LimeTextExplainer
import streamlit.components.v1 as componentsماژول اجزا از Streamlit به ما اجازه میدهد تا مولفههای HTML سفارشی را در برنامه تعبیه کنیم. ما میتوانیم یک تصویرسازی با LIME ایجاد کنیم و آن را بر روی یک برنامه Streamlit به عنوان یک مولفه HTML نمایش دهیم.
سپس، میتوانیم کد زیر را در انتهای آخرین if-block به منظور ایجاد یک دکمه برای توضیح پیشبینیهای مدل اضافه کنیم.
explain_pred = st.button('Explain Predictions')مقدار متغیر explain_pred زمانی که روی دکمه یکبار کلیک شود، روی درست تنظیم خواهد شد. اکنون میتوانیم یک توضیح متنی را با LIME همان طور که در کد زیر نشان داده شده است، ایجاد کنیم.
if explain_pred:
with st.spinner('Generating explanations'):
class_names = ['ham', 'spam']
explainer = LimeTextExplainer(class_names=class_names)
exp = explainer.explain_instance(message_text,
model.predict_proba, num_features=10)
components.html(exp.as_html(), height=800)رفرش کردن برنامه به ما اجازه میدهد تا توضیحات برای پیشبینیهای مدل، همانطور که در GIF زیر نشانداده شدهاست، تولید کنیم. توجه داشته باشید که چگونه LIME توضیحات متنی به کاربر اجازه میدهد تا درک کند که چرا مدل پیام را به عنوان اسپم طبقهبندی میکند و مهمترین کلماتی که مدل در فرآیند تصمیمگیری خود استفاده کردهاست را برجسته میکند.
در این نقطه، برنامه کاملا کاربردی است و میتواند برای نمایش و توضیح پیشبینیهای ایجاد شده توسط مدل طبقهبندی اسپم استفاده شود.
قابلیتهای اضافی Stramlit
برنامهای که من در این مقاله ایجاد کردم قطعا مفید است و میتواند به عنوان یک نقطه شروع برای پروژههای مشابه عمل کند، اما تنها تعداد کمی از ویژگیهای قدرتمند Streamlit را پوشش میدهد. در اینجا چند ویژگی دیگر از Stramlit آورده شدهاست که باید حتما آنها را بررسی کنید:
- این Stramlit از فرمانهای markdown و Latex پشتیبانی میکند، که به شما اجازه میدهد تا معادلاتی را در یک برنامه کاربردی وب بگنجانید.
- نرمافزار Streamlit به شما این امکان را میدهد تا جداول و pandas را با یک خط کد نمایش دهید.
- «استریم لایت» به شما این امکان را میدهد تا نمودارها و تصویرسازیها را از طیف وسیعی از کتابخانهها از جمله «Matplotlib»، «Bokeh»، «Pyplot»، «Pydeck» و حتی «Graphviz» به نمایش بگذارید.
- برنامه Streamlit به شما این امکان را میدهد که به راحتی نقاط روی نقشه را نمایش دهید.
- «استریملایت» همچنین از تعبیه فایلهای تصویر، صوتی و تصویری در برنامههای شما پشتیبانی میکند.
- برنامه استریملایت، استقرار برنامههای متن باز با به اشتراک گذاری streamlit را آسان میسازد.
برای فهمیدن بیشتر در مورد کاری که Streamlit میتواند انجام دهد، مستندات Streamlit را بررسی کنید.
خلاصه
در این مقاله، من نشان دادم که چگونه میتوانید از Streamlit برای ساخت یک برنامه کاربردی وب استفاده کنید که یک مدل طبقهبندی متن ساده را در کمتر از ۵۰ خط کد به نمایش میگذارد. استریملایت قطعا یک ابزار قدرتمند و سطح بالا است که توسعه وب را برای دانشمندان داده آسان و ساده میکند. به طور معمول، شما میتوانید تمام کد این مقاله را در گیتهاب پیدا کنید.
این متن با استفاده از ربات ترجمه مقالات علم داده ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
۵ نکته مهم برای تبدیل شما به رهبر از راه دور بهتر در سال ۲۰۲۱
مطلبی دیگر از این انتشارات
به حداکثر رساندن سودآوری کسبوکار خود با پایتون
مطلبی دیگر از این انتشارات
چگونه خون بازماندگان ویروس کرونا میتواند جان افراد را نجات دهد