

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
سه اصل برای انتخاب پلتفرم یادگیری ماشینی

منتشر شده در databricks به تاریخ ۲۴ ژوئن ۲۰۲۱
لینک منبع: Three Principles for Selecting Machine Learning Platforms
این پست وبلاگ دومین پست در یک سری از پلتفرمهای ML، عملیات، و حاکمیت است. برای اولین پست، پست رافی کورانسیک را در مورد «نیاز به پلتفرم ML داده محور» ببینید.
من به تازگی با مدیر Sr دیتا پلتفرمها در یک شرکت امنیت سایبری صحبت کردم، که اظهار داشت، «من نمیفهمم چطور میتوانید در آینده برای یادگیری ماشینی اثبات باشید، زیرا چنین آشفتگی در ابزارهای دائما در حال تغییر وجود دارد.» این یک احساس مشترک است. یادگیری ماشینی (ML) سریعتر از تقریبا هر فنآوری جدید دیگری پیشرفت کردهاست؛ کتابخانهها اغلب تازه از آزمایشگاه تحقیقاتی هستند، و فروشندگان بیشماری برای ابزارها و پلتفرمهای تبلیغاتی وجود دارند (پایگاهدادهها هم شامل میشوند). با این حال، همانطور که صحبت کردیم، مدیر پلتفرم درک کرد که آنها در موقعیت مناسبی برای اثبات آینده علم داده شرکت(DS) و ابتکارات ML هستند. شرکت آنها به پلتفرمی نیاز داشت که بتواند از تکنولوژی همیشه در حال تغییر پشتیبانی کند.
من در سالهای خودم در پایگاهدادهها، سازمانهای زیادی را دیدهام که پلتفرمهای داده را برای پشتیبانی از تیمهای DS و ML برای بلند مدت ایجاد میکنند. چالشهای اولیهای که معمولا این سازمانها با آن مواجه هستند را میتوان در چند حوزه گروهبندی کرد: جدایی بین پلتفرمهای داده آنها و ابزارهای ML، ارتباط ضعیف و همکاری بین تیمهای مهندسی و تیمDS و ML، و گزینههای فنآوری گذشته مانع تغییر و رشد میشود. در این پست وبلاگ، من توصیههای سطح بالای خود را جمعآوری کردم که این سازمانها را هنگام انتخاب فنآوریهای جدید راهنمایی کردند و پلتفرمهای DS و ML خود را بهبود دادند. این اشتباهات رایج -و راهحلهای آنها-در سه اصل سازماندهی میشوند.
اصل ۱: ساده کردن دسترسی به دادهها برای ML
در اصل DS و ML نیاز به دسترسی آسان به دادهها دارند. موانع رایج شامل فرمتهای داده اختصاصی، محدودیتهای پهنای باند داده و عدم همترازی حاکمیت است.
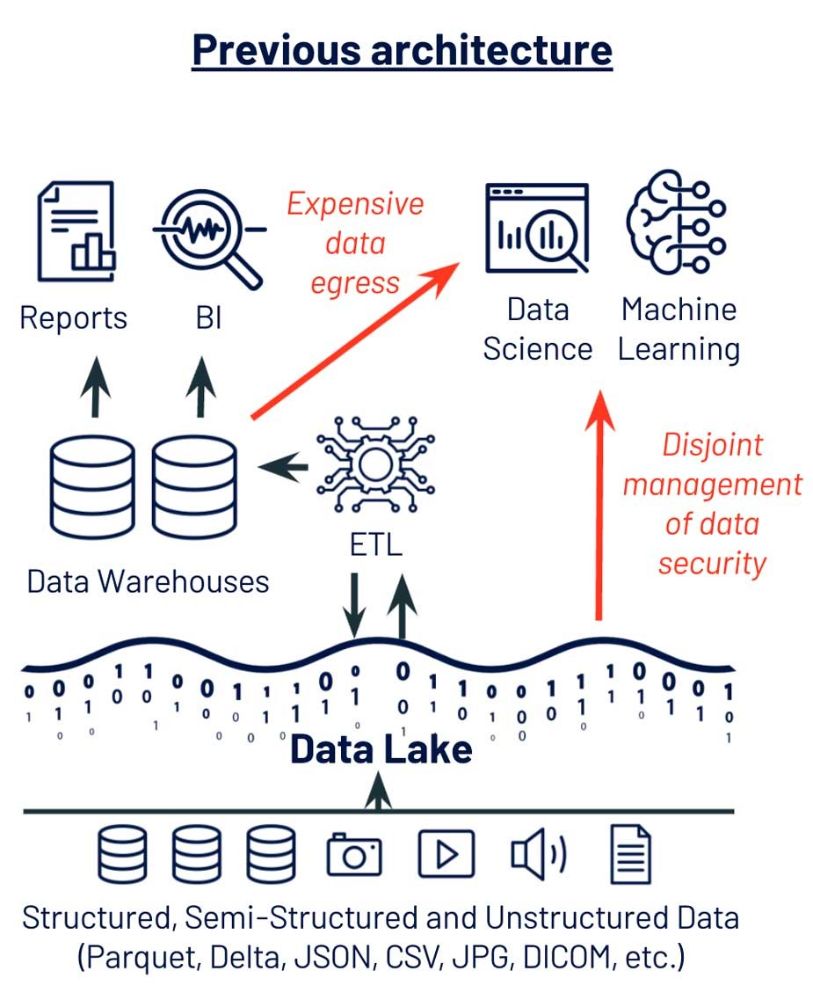
شرکتی که من با آن کار کردهام یک مثال نماینده ارائه میدهد. این شرکت یک انبار داده با دادههای تمیز داشت که توسط مهندسی داده نگهداری میشد. همچنین دانشمندان دادهای وجود داشتند که با واحدهای تجاری کار میکردند، با استفاده از ابزارهای مدرن مانند XGBoost و TensorFlow، اما آنها به راحتی نمیتوانستند دادهها را از انبار به ابزارهای DS و ML خود وارد کنند، و بسیاری از پروژهها را به تاخیر انداختند. علاوه بر این، تیم زیرساخت پلتفرم نگران بود که دانشمندان داده باید دادهها را بر روی لپتاپها یا ایستگاههای کاری خود کپی کنند و خطرات امنیتی را باز کنند. برای پرداختن به این اختلافات ناشی از روش مرکز انبار داده آنها در ML، ما چالشها را به سه بخش تقسیم کردیم.
قالبهای داده باز برای پایتون و R
در این مثال، مشکل اول استفاده از یک انبار داده اختصاصی بود. انبارهای داده از فرمتهای اختصاصی استفاده میکنند و نیاز به یک فرآیند خروجی داده گرانقیمت برای استخراج دادهها برای DS و ML دارند. از طرف دیگر، ابزارهای DS و ML عموما بر پایتون و R نه SQL بنا شدهاند و انتظار فرمتهای باز را دارند: پارکت، JSON ، CSV و غیره بر روی دیسک و Pandas یا Apache Spark Dataframe در حافظه. این چالش برای دادههای بدون ساختار مانند تصاویر و صوت تشدید میشود که به طور طبیعی در انبار دادهها جا نمیگیرند و برای پردازش به کتابخانههای تخصصی نیاز دارند.
معماری مجدد مدیریت دادهها در اطراف ذخیرهسازی دریاچه داده (Azure، ADLS ، AWS S3، GCP، GCS )به این شرکت اجازه داد تا مدیریت دادهها را هم برای مهندسی داده و هم DS و ML تقویت کند، که دسترسی دانشمندان به دادهها را بسیار آسانتر میکند. دانشمندان داده اکنون میتوانستند از پایتون و R استفاده کنند، و دادهها را مستقیما از حافظه اولیه به چارچوبData بارگذاری کنند که امکان توسعه و تکرار سریعتر مدل را فراهم میآورد. آنها همچنین میتوانند با فرمتهای خاصی مانند تصویری و سمعی و بصری که مسیرهای جدید تولید برقML را مسدود میکنند، کار کنند.
پهنای باند و مقیاس داده
این شرکت، فراتر از فرمتهای دوستانه DS و ML، با پهنای باند داده و چالشهای مقیاس مواجه شد. فیدینگ یک الگوریتم ML با دادههای یک انبار داده میتواند برای دادههای کوچک کار کند. اما نمودارهای برنامه کاربردی، تصاویر، متن، تلهمتری اینترنت اشیاء و دیگر منابع داده مدرن میتوانند به راحتی انبار دادهها را حداکثر کنند، ذخیره کردن و به طور غیر محتمل آهسته کردن استخراج برای الگوریتمهای DS و ML بسیار گران میشود.
این شرکت با ایجاد ذخیره در دریاچه داده لایه اولیه داده خود، قادر به کار با مجموعه دادههایی به اندازه ۱۰*۱۰ بود، در حالی که هزینههای ذخیرهسازی و حرکت داده را کاهش میداد. دادههای تاریخی بیشتر دقت مدلهای آنها را، به ویژه در رسیدگی به رویدادهای دور افتاده نادر، افزایش دادهاست.
امنیت و حاکمیت دادههای یکپارچه
از میان چالشهایی که این شرکت با سیستم مدیریت داده قبلی خود مواجه بود، پیچیدهترین و پرخطرترین آنها امنیت و حاکمیت داده بود. تیمهایی که دسترسی به دادهها را مدیریت میکردند، پایگاهداده مدیریت بودند که با دسترسی مبتنی بر جدول آشنا بودند. اما دانشمندان داده مورد نیاز برای صادرات مجموعه دادهها از این جداول کنترل شده تا دادهها را در ابزارهای ML مدرن بهدست آورند. نگرانیهای امنیتی و ابهام ناشی از این قطع ارتباط منجر به ماهها تاخیر در زمانی شد که دانشمندان داده نیاز به دسترسی به منابع داده جدید داشتند.
این نقاط درد، آنها را به سمت انتخاب یک پلتفرم متحدتر هدایت کرد که به ابزارهای DS و ML اجازه دسترسی به دادهها تحت همان مدل دولتی مورد استفاده توسط مهندسان داده و مدیریت پایگاهداده را میداد. دانشمندان داده قادر بودند مجموعه دادههای بزرگ را به راحتی در پانداس و فریمهای دادهPySpark بارگذاری کنند و مدیران پایگاهداده میتوانستند دسترسی دادهها را براساس هویت کاربر محدود کنند و از انتشار دادهها جلوگیری کنند.
موفقیت در سادهسازی دسترسی به دادهها
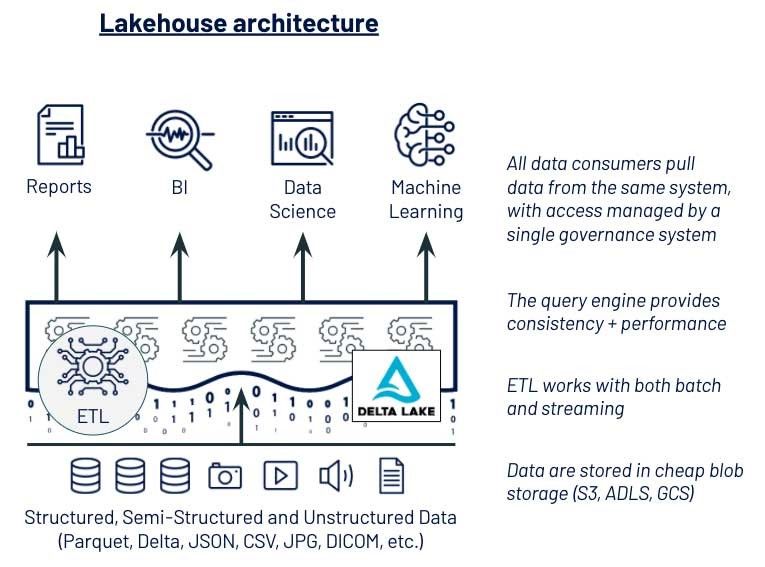
این مشتری دو تغییر کلیدی فنی برای تسهیل دسترسی به داده برایDS وML ایجاد کرد: (۱) استفاده از ذخیره در دریاچه داده به عنوان ذخیره اولیه داده و (۲) اجرای یک مدل حاکمیت مشترک بر روی جداول و فایلهای پشتیبانی شده توسط ذخیره در دریاچه داده. این انتخابها آنها را به سمت معماری یک خونه کنار دریاچه هدایت کرد، که از دریاچه دلتا برای ارائه مهندسی داده با قابلیت اطمینان خط لوله داده، علم داده با فرمت های داده باز مورد نیاز برای ML و ادمینها با مدل حاکمیت مورد نیاز برای امنیت بهره میبرد. با این معماری داده مدرن، دانشمندان داده قادر به نشان دادن ارزش موارد استفاده جدید در کمتر از نیمی از زمان بودند.
چند داستان موفقیت مشتری مورد علاقه من در سادهسازی دسترسی به داده عبارتند از:
· در Outreach، مهندسانML برای تنظیم زمان خطوط لوله برای دسترسی به دادهها استفاده کردند، اما حرکت به یک پلت فرم مدیریتشده که هر دو ETL و ML را پشتیبانی میکند این اصطکاک را کاهش داد.
· در ادموندز، سیلوهای داده برای اختلال در بهرهوری دانشمندان داده مورد استفاده قرار میگیرند. در حال حاضر، همانطور که گرگ روکیتا (مدیر اجرایی) گفت، «Databricks دادهها، مهندسی داده و یادگیری ماشینی را دموکراتیک میکنند و به ما اجازه میدهند تا اصول برگرفته از داده را در سازمان وارد کنیم.»
· در شل، پایگاهدادهها دسترسی به دادهها را دموکراتیک کرده و اجازه تجزیه و تحلیل پیشرفته در مورد دادههای بسیار بزرگتر، از جمله شبیهسازی موجودی در تمام بخشها و امکانات و پیشنهادها برای ۱.۵ + میلیون مشتری را دادند.
اصل ۲: تسهیل همکاری بین مهندسی داده و علم داده
یک پلتفرم داده باید همکاری بین مهندسی داده و تیمهایDS وML را تسهیل کند، فراتر از مکانیک دسترسی به داده بحث شده در بخش قبلی. موانع رایج توسط این دو گروه با استفاده از پلتفرمهای گسسته برای محاسبه و استقرار، پردازش داده و حاکمیت ایجاد میشوند.
مشتری دوم من یک تیم علوم داده بالغ داشت اما تشخیص داد که آنها خیلی از همتایان مهندسی داده خود جدا هستند.
علم داده دارای یک پلتفرم DSمحور بود که آنها دوست داشتند، با نوتبوک، ایستگاههای کاری درخواستی (ابری) و پشتیبانی از کتابخانههای ML خود کامل شود.
آنها قادر به ساخت مدلهای جدید و با ارزش بودند، و مهندسی دادهها فرآیندی برای کنترل مدلها در سیستمهای تولید مبتنی بر آپاچی اسپارک برای استنتاج دستهای داشت. با این حال، این فرآیند دردناک بود. در حالی که تیم علوم داده با استفاده از پایتون و R با ایستگاههای کاری خود آشنا بودند، با محیط جاوا و محاسبات خوشهای که توسط مهندسی داده استفاده میشد، ناآشنا بودند. این شکافها منجر به یک فرآیند انتقال ناخوشایند میشد: از جمله بازنویسی مدلهای پایتون و R در جاوا، بررسی برای اطمینان از رفتار یکسان، بازنویسی منطق ویژگیسازی و به اشتراکگذاری دستی مدلها به عنوان فایلهای ردیابی شده در صفحات گسترده. این اقدامات باعث ماهها تاخیر و ایجاد خطا در تولید شده و اجازه نظارت بر مدیریت را نمیدهد.
مدیریت محیط میان تیمی
در مثال بالا، اولین چالش، مدیریت محیط بود. مدلهای ML اشیا مجزا نیستند؛ رفتار آنها به محیط آنها بستگی دارد، و پیشبینیهای مدل میتواند در سراسر نسخههای کتابخانه تغییر کند.
تیمهای این مشتری برای تکثیر محیطهای توسعه ML در سیستمهای تولید مهندسی داده به عقب خم میشدند.
دنیای ML مدرن به پایتون (و گاهی( R نیاز دارد، بنابراین آنها به ابزارهایی برای تکرار محیط مانند مجازیسازی، کاندا و کانتینرهای داکر نیاز دارند.
با شناخت این نیاز، آنها به MLflow روی آوردند، که از این ابزارها در زیر سرپوش استفاده میکند اما دانشمندان داده را از پیچیدگی مدیریت محیط محافظت میکند. با MLflow ، دانشمندان داده آنها بیش از یک ماه تاخیر در تولید را اصلاح کردند و نگرانی کمتری در مورد ارتقا به آخرین کتابخانههای ML داشتند.
گردش کار یادگیری ماشینی شامل دانشمندان داده، مهندسان داده و مهندسان استقرار میباشد
آمادهسازی دادهها برای ویژگیسازی
برای DS و ML، دادههای خوب همه چیز هستند، و خط بین) ETL / ELT اغلب متعلق به مهندسان داده) و ویژگی (اغلب متعلق به دانشمندان داده) اختیاری است. برای این مشتری، زمانی که دانشمندان داده به ویژگیهای جدید یا بهبود یافته در تولید نیاز داشتند، از مهندسان داده برای بهروزرسانی خطوط لوله درخواست میکردند. تاخیرات طولانی گاهی اوقات باعث هدر رفتن کار میشود زمانی که اولویتهای کسبوکار در طول انتظار تغییر میکنند.
هنگام انتخاب یک پلتفرم جدید، آنها به دنبال ابزارهایی برای پشتیبانی از منطق پردازش داده بودند. در نهایت، آنها پایگاههای اطلاعاتی جابز را به عنوان نقطه پایانی انتخاب کردند: دانشمندان داده میتوانستند کد پایتون وR را در واحدها (جابز) پنهان کنند، و مهندسی داده میتوانست آنها را با استفاده از ارکستریتور موجود خود (آپاچی ایرفلو) و سیستم CI / CD (جنکینز) گسترش دهد. فرآیند جدید بهروزرسانی منطق ویژگیسازی تقریبا به طور کامل خودکار بود.
به اشتراکگذاری مدلهای یادگیری ماشین
مدلهای ML اساسا مقادیر گستردهای از دادهها و اهداف کسبوکار هستند که در منطق کسبوکار خلاصه شدهاند. همانطور که با این مشتری کار میکردم، برای من جالب و ترسناک بود که چنین داراییهای ارزشمندی بدون حاکمیت مناسب ذخیره و به اشتراک گذاشته شوند. از نظر عملیاتی، فقدان حاکمیت منجر به فرآیندهای دستی و پر زحمت برای تولید (فایلها و صفحات گسترده)، و همچنین نظارت کمتر از رهبران و مدیران تیمی میشود.
برای آنها تغییر بازی بود تا به یک سرویس مدیریتشده MLflow بروند، که مکانیزمهایی را برای به اشتراکگذاری مدلهای ML و حرکت به سمت تولید فراهم کرد، همه تحت کنترلهای دسترسی در یک ثبت مدل واحد ایمن شدند. اجرای نرمافزار و فرآیندهای دستی خودکار قبلی، و مدیریت میتوانند به هنگام حرکت به سمت تولید، بر مدلها نظارت کنند.
موفقیت در تسهیل همکاری
گزینههای فنآوری کلیدی این مشتری برای تسهیل همکاری حول یک پلتفرم یکپارچه بود که هم از مهندسی داده و هم از نیازهای علم داده با مدلهای حاکمیت و امنیت مشترک پشتیبانی میکرد. با پایگاهدادهها، برخی از تکنولوژیهای کلیدی که موارد استفاده آنها را ممکن ساختند، عبارت بودند از زمان اجرا Databricks و مدیریت خوشه برای نیازهای محاسباتی و محیطی آنها، مشاغل برای تعریف واحدهای کاری (AWS / Azure/ Gdocs)، API های باز برای تنظیم(AWS/ Azure/ GCP docs) و یکپارچهسازی CI / CD (AWS /Azure/ GCP docs)، و مدیریت MLflow برای MLOps .
داستانهای موفقیت مشتری خاص همکاری بین مهندسی داده و علم داده شامل موارد زیر است:
- از شکستن دیوار بین تیمهایی که خطوط لوله دادهها را مدیریت میکنند و تیمهایی که تحلیل پیشرفته را مدیریت میکنند، Conde Nast بهره میبرد. همانطور که پائول فریزل (مهندس اصلی زیرساخت هوش مصنوعی) گفت، پایگاهدادهها یک راهحل بسیار قدرتمند برای ما بودهاست. این کار به اعضای مختلف تیم از زمینههای مختلف اجازه میدهد تا به سرعت وارد شوند و از حجم زیادی از دادهها برای تصمیمگیریهای تجاری قابلاجرا استفاده کنند.
- در قابلیت تکرار، عدم ارتباط بین مهندسی داده و تیمهای علم داده از آموزش و استقرار مدلهایML به شیوهای تکرار پذیر جلوگیری میکند. با حرکت به یک پلتفرم به اشتراک گذاشته شده در میان تیمهایی که چرخه عمر ML را ساده میکنند، تیمهای داده آنها تکرارپذیری را برای مدلها و فرآیندها ساده میکنند.
- در شوتایم، توسعه و استقرار ML دستی و مستعد خطا بود تا زمانی که به یک پلتفرم مبتنی برMLflow مدیریتشده منتقل شوند. پایگاهدادهها سرآیند عملیاتی را از جریان کار خود حذف کرده و زمان-به-بازار را برای مدلها و ویژگیهای جدید کاهش میدهند.
اصل ۳: برای تغییر برنامهریزی کنید
سازمانها و تکنولوژی تغییر خواهند کرد. اندازه دادهها رشد خواهد کرد؛ مهارتها و اهداف تیم تکامل خواهند یافت؛ و تکنولوژیها در طول زمان توسعه خواهند یافت و جایگزین خواهند شد. یک خطای آشکار، اما مشترک، برنامهریزی برای مقیاس نیست. یک خطای رایج دیگر اما ظریفتر، انتخاب فنآوریهای غیرقابل حمل برای دادهها، منطق و مدلها است.
من یک داستان مشتری سوم را برای نشان دادن این اصل آخر به اشتراک میگذارم. من با یک مشتری در مراحل اولیه کار کردم که امیدوار بود مدلهایML را برای طبقهبندی محتوا ایجاد کند. آنها پایگاههای اطلاعاتی را انتخاب کردند اما به دلیل فقدان تخصص به شدت به خدمات حرفهای ما وابسته بودند. یک سال بعد، با نشان دادن مقداری ارزش اولیه برای کسبوکار خود، آنها قادر به استخدام متخصصان داده بودند و در عین حال تقریبا ۵۰ داده دیگر جمعآوری کرده بودند. آنها نیاز به مقیاسبندی، تغییر به کتابخانههای ML توزیعشده، و ادغام نزدیکتر با دیگر تیمهای داده داشتند.
برنامهریزی برای مقیاسبندی
همانطور که این مشتری متوجه شد، دادهها، مدلها و سازمانها در طول زمان مقیاسگذاری خواهند شد. دادههای آنها در اصل میتوانستند در یک انبار داده جای گیرند، اما با افزایش اندازه دادهها و نیازهای تحلیلی، نیازمند مهاجرت به یک معماری متفاوت بودند. تیمهای DS و ML آنها میتوانستند در ابتدا بر روی لپتاپها کار کنند، اما یک سال بعد، آنها به خوشههای قویتر نیاز داشتند. با برنامهریزی پیش رو با معماری لیکهاوس و یک پلتفرم که هم از تک ماشین حمایت میکند و هم ML توزیعشده، این سازمان یک مسیر روان برای رشد سریع آماده میکند.
قابلیت حملونقل و تصمیم «ساخت در مقابل خرید».
قابلیت حملونقل چالش زیرکانهتری است. گاهی اوقات استراتژی تکنولوژی به یک تصمیم «ساخت در مقابل خرید»، مانند « ساخت یک پلتفرم داخلی با استفاده از بازتعریف تکنولوژی میتواند امکان سفارشیسازی و اجتناب از قفل شدن را فراهم کند، در حالی که خرید یک مجموعه ابزار اختصاصی میتواند امکان راهاندازی و پیشرفت سریعتر را فراهم کند.» این بحث یک انتخاب ناخوشایند را نشان میدهد: یا یک سرمایهگذاری بزرگ در یک پلتفرم سفارشی انجام دهید و یا در یک تکنولوژی اختصاصی قفل شوید.
با این حال، این استدلال گمراهکننده است، زیرا از یک سو بین پلتفرم داده و زیرساخت و از سوی دیگر بین فنآوری داده در سطح پروژه تمایز قائل نمیشود. لایههای ذخیرهسازی داده، ابزارهای تنظیم و خدمات متاداده انتخابهای تکنولوژی سطح پلتفرم مشترک هستند؛ فرمتهای داده، زبانها و کتابخانههای ML انتخابهای تکنولوژی سطح پروژه مشترک هستند. هنگام برنامهریزی برای تغییر، این دو نوع انتخاب باید به طور متفاوتی مورد توجه قرار گیرند. این امر به تفکر در مورد پلتفرم دادهها و زیرساخت به عنوان کانتینرها و خطوط لوله عمومی برای دادهها، منطق و مدلهای تخصصی یک شرکت کمک میکند.
برنامهریزی برای تغییرات تکنولوژی در سطح پروژه
تکنولوژیهای سطح پروژه باید برای مبادله در داخل و خارج ساده باشند. محصولات جدید و مجهز به ML ممکن است الزامات مختلفی داشته باشند که به منابع داده جدید، کتابخانههای ML یا ادغام خدمات نیاز دارند. انعطافپذیری در تغییر این گزینههای تکنولوژی در سطح پروژه به یک کسبوکار اجازه سازگاری و رقابتی بودن را میدهد.
این پلتفرم باید به این انعطافپذیری اجازه دهد و به طور ایدهآل، تیمها را تشویق کند تا از ابزارها و فرمتهای اختصاصی برای دادهها و مدلها اجتناب کنند.
برای مشتری من، اگرچه آنها شروع به یادگیری scikit کردند، آنها قادر به تغییر Spark ML و توزیع TensorFlow بدون تغییر سیستم عامل یا ابزار MLOps خود بودند.
برنامهریزی برای تغییرات پلتفرم
پلتفرمها باید قابلیت حمل را ممکن سازند. برای اینکه یک پلتفرم بتواند در بلندمدت به یک شرکت خدمت کند، باید از ورود به سیستم اجتناب کند: انتقال داده، منطق و مدلها به و از پلتفرم باید ساده و ارزان باشد. هنگامی که پلتفرمهای داده ماموریت و قدرت اصلی یک شرکت نیستند، برای سازمان منطقی است که یک پلتفرم را بخرد تا سریعتر حرکت کند-تا زمانی که پلت فرم اجازه دهد شرکت چابک بماند و داراییهای با ارزش خود را در صورت نیاز به جای دیگری منتقل کند.
برای مشتری من، انتخاب یک پلتفرم که به آنها اجازه استفاده از ابزارهای باز و APIها مانند علم-یادگیری، scikit، Spark ML و MLflow را میداد به دو روش کمک کرد.
ابتدا تصمیم پلتفرم را با اطمینان دادن به بازگشتپذیر بودن تصمیم، ساده کرد.
دوم، آنها قادر به ادغام با دیگر تیمهای داده از طریق انتقال کد و مدلها به و از سایر پلتفرمها بودند.
موفقیت در برنامهریزی برای تغییر
گزینههای کلیدی تکنولوژی این مشتری که به آنها اجازه میداد تا خود را با تغییرات وفق دهند، یک معماری بومی، یک پلتفرم پشتیبانی از هر دو تک ماشین و ML توزیعشده، و MLflow به عنوان یک چارچوب کتابخانهای-کتابشناختی برای MLOps بودند. این انتخابها مسیر مقیاسگذاری دادهها را با ۵۰x ساده کردند، به مدلهای ML پیچیدهتر تغییر مسیر دادند، و مقیاسگذاری تیم خود و مجموعه مهارتهای آن را انجام دادند.
برخی از انتخابهای برتر من برای داستانهای موفقیت مشتری در برنامهریزی تغییر و قابلیت حمل عبارتند از:
- در ادموندز، تیمهای داده نیاز به زیرساخت داشتند که پردازش داده و الزامات ML را پشتیبانی میکرد، مانند آخرین چارچوبهای .ML حفظ این زیرساخت به خودی خود نیازمند تلاشهای بسیار مهم است. بانک اطلاعاتی پلتفرم را مدیریت کرد و در عین حال سرآیند DevOps را کاهش داد.
- همانطور که توسط رشد داده با تجربه به پتابایت های متعدد و تعداد مدلهای ML به ۱+ میلیون افزایش یافت، زیرساخت داده موروثی نمیتواند مقیاسگذاری یا اجرا مطمئن داشته باشد. مهاجرت به دریاچه دلتا و MLflow مقیاس مورد نیاز را فراهم کرد و مهاجرت ساده شد زیرا پایگاهدادهها از انواع ابزارهای مورد نیاز تیمهای مهندسی داده و علوم داده حمایت کردند.
- تیمهای داده در شل به طور گسترده هم در زمینه مهارتها و هم در پروژههای تحلیلی (۱۶۰ پروژه هوش مصنوعی با تعداد بیشتری در حال انجام) فعالیت میکنند. با استفاده از پایگاهدادهها به عنوان یکی از اجزای اساسی پلتفرم Shell.ai، شل انعطافپذیری مورد نیاز برای رسیدگی به نیازهای فعلی و آینده داده را دارد.
اعمال اصول
آسان است که اصول اصلی را ذکر کنید و بگویید، \"برو این کار را بکن!\" اما اجرای آنها مستلزم ارزیابی صریح فنآوری، سازمان و تجارت شما است و به دنبال آن برنامهریزی و اجرا میشود.
پایگاههای داده تجربه زیادی در ساخت پلتفرمهای داده برای پشتیبانی از DS و ML ارائه میدهند.
موفقترین سازمانهایی که ما با آنها کار میکنیم، برخی از بهترین روشها را دنبال میکنند: آنها میدانند که برنامهریزی معماری بلند مدت باید همزمان با نمایش کوتاهمدت تاثیر و ارزش رخ دهد. این ارزش با هماهنگی تیمهای علوم داده با واحدهای کسبوکار و موارد استفاده اولویتبندی شده آنها به مدیران اجرایی منتقل میشود. همترازی میان سازمانی به هدایت پیشرفتهای سازمانی، از سادهسازی فرآیندها تا ایجاد مراکز برتری (CoE) کمک میکند.
این پست وبلاگ تنها سطح این موضوعات را بررسی میکند. برخی دیگر از مواد عالی شامل:
- نکات کلیدی داده هوش مصنوعی اجلاس ۲۰۲۱: اینها انتشار یادگیری ماشینی پایگاههای داده، یک راهحل داده-بومی و مشارکتی ML برای چرخه عمر ML کامل را اعلام میکنند.
- پلتفرمهای یادگیری ماشینی ساختمان: شبکه اینترنتی ضبطشده شامل ماتری زاریا (CTO و یکی از موسسان، پایگاهدادهها)، بن لورکا (محقق ارشد داده، پایگاهدادهها) و کلمنز مدالد (مدیر، مدیریت محصول، علم داده و ML، پایگاهدادهها)
- رویداد مجازیMLOPS: عملیاتی کردن یادگیری ماشینی در مقیاس: شبکه اینترنتی ضبطشده از جمله Matei Zaharia (CTO و یکی از موسسان، پایگاهدادهها) و سخنرانانH&M و J.B. در سرشماری سال ۲۰۰۰، جمعیت این شهر ۱۰۸۵ نفر اعلام شد
- صفحات پایگاهداده برای راهحلهای علوم داده و MLflow مدیریتشده
این متن با استفاده از ربات ترجمه مقالات هوش مصنوعی ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
خطرناکترین حیوان در دنیا چیست؟ عجیبترین حیوانی که تا به حال دیدهاید.
مطلبی دیگر از این انتشارات
تطبیق الگو در پایتون ۳.۱۰
مطلبی دیگر از این انتشارات
با این افزونههای مرورگر،ChatGPT برای شما کارآیی بهتری خواهد داشت