

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
ما به دانشمندان داده نیاز نداریم، به مهندسان داده نیاز داریم!

منتشرشده در: kdnuggets به تاریخ ۲۱ فوریه ۲۰۲۱
لینک منبع: We Don’t Need Data Scientists, We Need Data Engineers
وقتی افراد بیشتری وارد حوزه علوم داده میشوند و شرکتهای بیشتری برای نقشهای داده محور استخدام میکنند، چه نوع شغلی در حال حاضر بیشترین تقاضا را دارد؟ دادههای زیادی در دنیا وجود دارد، و فقط جریان را در خود نگه میدارد، اکنون به نظر میرسد که شرکتها کسانی را هدف قرار میدهند که میتوانند دادهها را بیش از کسانی که تنها میتوانند آنها را مدلسازی کنند، مهندسی کنند.
دادهها. همه جا هستند، و ما فقط مقدار بیشتری از آن را به دست میآوریم. در ۵ تا ۱۰ سال گذشته، علوم داده تازه واردانی را به خود جذب کردهاست که سعی میکنند طعم این میوه ممنوعه را بچشد. اما وضعیت استخدام علوم داده امروز چگونه به نظر میرسد؟
این راهنمای مقاله در دو جمله برای خواننده پرمشغله است.
بر اساس TLDR هفتاد درصد پتانسیل بیشتری در شرکتهای مهندسی داده در مقایسه با علم داده وجود دارد. همانطور که ما نسل بعدی متخصصان یادگیری ماشین و داده را آموزش میدهیم، بیایید تاکید بیشتری بر مهارتهای مهندسی داشته باشیم. به عنوان بخشی از کار من که در حال توسعه یک پلتفرم آموزشی برای متخصصان داده هستم، من فکر میکنم که چگونه بازار نقشهای دادهمحور (یادگیری ماشین و علم داده) در حال تکامل است.
در صحبت با دهها شرکتکننده بالقوه در زمینه داده، از جمله دانشجویان موسسات برتر در سراسر جهان، من شاهد سردرگمی زیادی در مورد این بودهام که چه مهارتهایی برای کمک به نامزدها برای برجسته شدن در میان جمعیت و آماده شدن برای حرفهایشان از همه مهمتر هستند. هنگامی که شما در مورد آن فکر میکنید، یک دانشمند داده میتواند مسئول هر زیر مجموعه از موارد زیر باشد: مدلسازی یادگیری ماشین، تجسم، پاکسازی دادهها و پردازش (به عنوان مثال، نزاع SQL) ، مهندسی، و توسعه تولید.
چگونه شروع به توصیه یک برنامه آموزشی برای تازه واردها میکنید؟
دادهها بلندتر از کلمات صحبت میکنند. بنابراین من تصمیم گرفتم که یک تحلیل از نقشهای دادهای که برای هر شرکتی که از سال ۲۰۱۲ از وای-کمبینتور بیرون میآید، به کار گرفته میشود، انجام دهم. پرسشهایی که تحقیق مرا هدایت میکردند:
- شرکتها اغلب چه نقشهای دادهای را برای چه استخدام میکنند؟
- چگونه یک دانشمند داده معمولی که ما در مورد آن بسیار صحبت میکنیم، مورد تقاضا است؟
- آیا همان مهارتهایی که انقلاب داده را امروز آغاز کردند، مربوط هستند؟
اگر جزئیات و تحلیلهای کامل را میخواهید، ادامه دهید.
مطالعه مقاله چگونه ظرف ۶ ماه بدون دانش کدنویسی دانشمند داده شدم توصیه میشود.
روششناسی
من تصمیم گرفتم یک تحلیل از شرکتهای اوراق بهادار YC انجام دهم که ادعا میکنند برخی از انواع دادهها بخشی از گزاره ارزش آنها هستند. چرا روی «YC» تمرکز کنیم؟ خب، برای شروع، آنها کار خوبی انجام میدهند تا یک دایرکتوری آسان و قابل جستجو از شرکتهایشان را فراهم کنند.
علاوه بر این، به عنوان یک مرکز رشد با تفکر رو به جلو که برای بیش از یک دهه، شرکتهای سراسر جهان را از حوزههای مختلف تامین مالی کردهاست، من احساس کردم که آنها یک نمونه نماینده از بازار را فراهم کردند تا تحلیلهای من را با آن انجام دهند. البته من شرکتهای فنآوری بسیار بزرگ را تجزیه و تحلیل نکردم.
من آدرسهای صفحه اصلی هر شرکتYC را از سال ۲۰۱۲ بررسی کردم، و یک مجموعه اولیه از ۱۴۰۰ شرکت را تولید کردم. چرا در سال ۲۰۱۲ توقف کنیم؟ خب، ۲۰۱۲ سالی بود که الکسنت در رقابت ImageNet برنده شد، به طور موثر یادگیری ماشین و موج مدلسازی داده را که ما در حال حاضر از طریق آن زندگی میکنیم را شروع کرد. منصفانه است که بگوییم این مساله برخی از نسلهای اولیه شرکتهای داده اول را ایجاد کردهاست.
از این مخزن اولیه، من فیلتر کلمه کلیدی را انجام دادم تا تعداد شرکتهای مرتبط که باید بررسی میکردم را کاهش دهم. به طور خاص، من تنها شرکتهایی را در نظر گرفتم که وبسایت آنها شامل حداقل یکی از اصطلاحات زیر بود: AI، CV، NLP، پردازش زبان طبیعی، بینایی کامپیوتر، هوش مصنوعی، ماشین، ML، دادهها. من همچنین شرکتهایی را که لینکهای وبسایتشان قطع شدهبود، نادیده گرفتم.
آیا این باعث ایجاد هزارات مثبت کاذب شد؟ البته! اما در اینجا، من سعی داشتم تا حد امکان یادآوری بالا را اولویتبندی کنم، با تشخیص این که یک بررسی دستی دقیقتر از وبسایتهای فردی برای نقشهای مرتبط انجام خواهم داد.
با این مخزن کاهشیافته، من به هر سایت رفتم، متوجه شدم که آنها در کجا کارهای تبلیغاتی انجام میدهند (معمولا یک کریرز، جابز، یا ما صفحه استخدام هستیم) ، و به هر نقشی که شامل داده، یادگیری ماشین، NLP، یا CV در عنوان بود توجه کردم. این به من مجموعهای از حدود ۷۰ شرکت متمایز را داد که برای نقشهای داده استخدام میکردند.
یک نکته در اینجا: قابل تصور است که من برخی از شرکتها را از دست دادم چون برخی از وبسایتهای خاص با اطلاعات بسیار کم (معمولا آنهایی که در نهان هستند) وجود داشتند که ممکن بود در واقع در حال استخدام باشند. علاوه بر این، شرکتهایی وجود داشتند که صفحه سرپرست رسمی نداشتند، اما از نامزدهای احتمالی میخواستند که به طور مستقیم از طریق ایمیل به آنها دسترسی پیدا کنند. من هر دوی این نوع شرکتها را نادیده گرفتم تا اینکه به آنها دسترسی پیدا کنم، بنابراین آنها بخشی از این تجزیه و تحلیل نیستند.
نکته دیگر: بخش عمدهای از این تحقیق به سمت هفتههای پایانی سال ۲۰۲۰ انجام شد. نقشهای موجود ممکن است زمانی که شرکتها صفحات خود را به صورت دورهای بهروزرسانی میکنند، تغییر کرده باشند. با این حال، من باور ندارم که این مساله تاثیر چشمگیری بر نتایج بهدستآمده داشته باشد.
مسئولیتهای داده برای چه چیزی هستند؟
قبل از پرداختن به نتایج، بهتر است کمی زمان صرف کنید تا مشخص شود که هر نقش داده چه مسئولیتی را بر عهده دارد. در اینجا به چهار نقشی که ما وقت خود را صرف نگاه کردن به آنها با توصیف کوتاهی از آنچه که آنها انجام میدهند میکنیم، میپردازیم:
- دانشمند داده: از تکنیکهای مختلف در آمار و یادگیری ماشین برای پردازش و تجزیه و تحلیل داده استفاده کنید. اغلب مسئول ساخت مدلها برای بررسی آنچه که میتوان از برخی منابع داده آموخت، هرچند اغلب در یک نمونه اولیه به جای سطح تولید است.
- مهندس داده: یک مجموعه قوی و مقیاس پذیر از ابزارها / پلتفرمهای پردازش داده توسعه میدهد. باید با نزاع پایگاهداده SQL / NoSQL و ایجاد / حفظ خطوط ETL راحت باشد.
- مهندس یادگیری ماشینی (ML) : اغلب مسئول هر دو مدل آموزشی و تولید آنها است. آشنایی با برخی از چارچوب ML سطح بالا ضروری است و همچنین باید در ساخت مقیاس پذیر آموزش، استنتاج، و استقرار خطوط برای مدلها راحت باشد.
- یادگیری ماشینی (ML) دانشمند: بر روی تحقیقات لبه برش کار میکند. معمولا مسئول بررسی ایدههای جدیدی هستند که میتوانند در کنفرانسهای دانشگاهی منتشر شوند. اغلب تنها نیاز به نمونه اولیه مدلهای هنری جدید قبل از تحویل آنها به مهندسان ML برای تولید دارد.
ممکن است به مطالعه مقاله آیا دانشمند داده شدن با روحیه شما سازگار است؟علاقمند باشید.
چند نقش داده وجود دارد؟
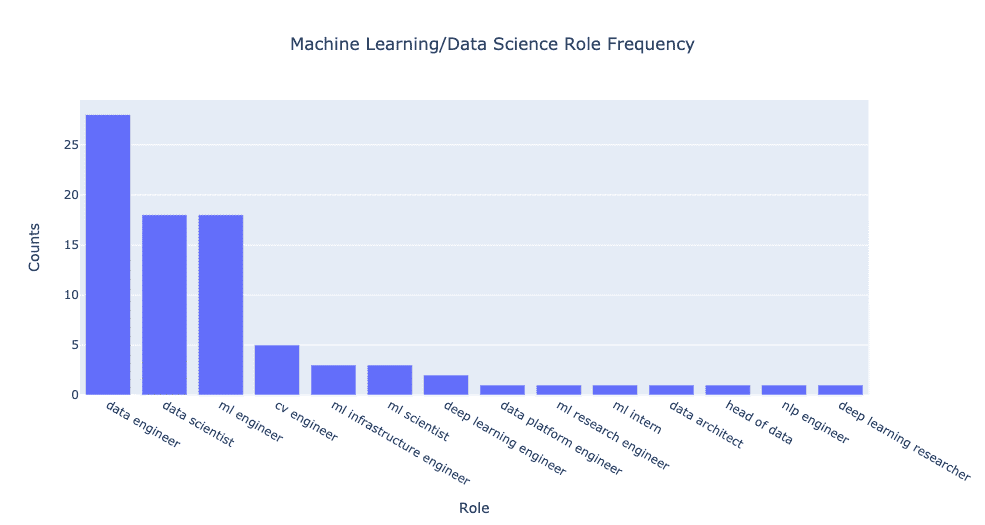
بنابراین چه اتفاقی میافتد وقتی ما فراوانی هر نقش دادهای که شرکتها برای آن استخدام میکنند را ترسیم میکنیم؟ داستان به این شکل است:
چیزی که فورا مشخص میشود این است که چه تعداد نقش مهندسی داده باز در مقایسه با دانشمندان سنتی داده وجود دارد. در این مورد، شمارش خام مربوط به شرکتهایی است که تقریبا ۵۵٪ بیشتر از دانشمندان داده برای مهندسان داده استخدام میکنند و تقریبا همان تعداد از مهندسان یادگیری ماشین به عنوان دانشمندان داده.
اما ما میتوانیم کارهای بیشتری انجام دهیم. اگر به عناوین نقشهای مختلف نگاه کنید، به نظر میرسد که چند تکرار وجود دارد. اجازه دهید تنها از طریق تحکیم نقش طبقهبندی عمده را ارائه دهیم. به عبارت دیگر، من نقشهایی را بر عهده گرفتم که توصیف آنها تقریبا معادل بود و آنها را تحت یک عنوان واحد تحکیم کردم.
این شامل مجموعه روابط هم ارزی زیر است:
مهندس NLP ≈ مهندس CV ≈ مهندس ML ≈ مهندس یادگیری عمیق (در حالی که دامنهها ممکن است متفاوت باشند، مسئولیتها تقریبا یکسان هستند)
دانشمند ML ≈ محقق یادگیری عمیق ≈ اینترنML (توصیف کارورز به نظر بسیار متمرکز بر تحقیق است)
مهندس داده ≈ معمار داده ≈ مسئول داده ≈ مهندس پلتفرم داده
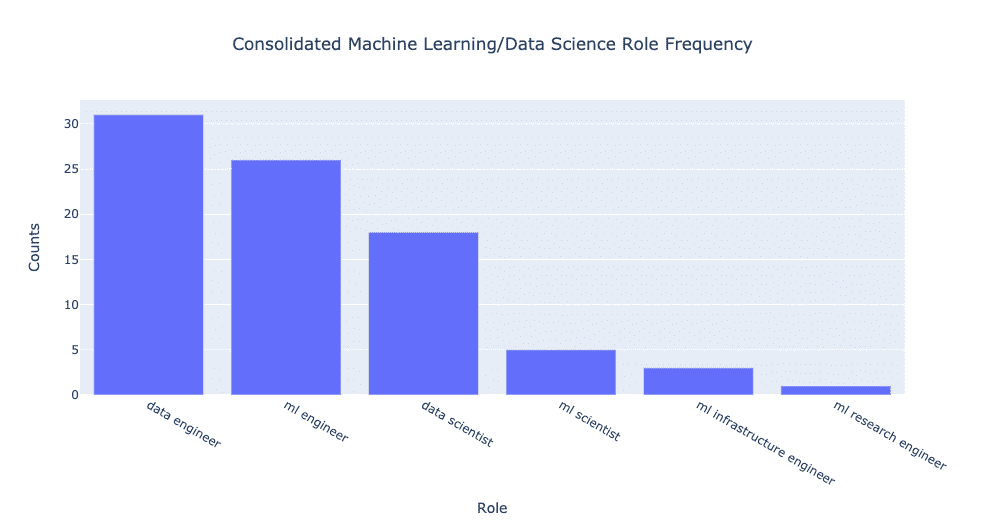
اگر دوست نداریم با اعداد خام سر و کار داشته باشیم، اینها چند درصد هستند که ما را راحت میکنند:
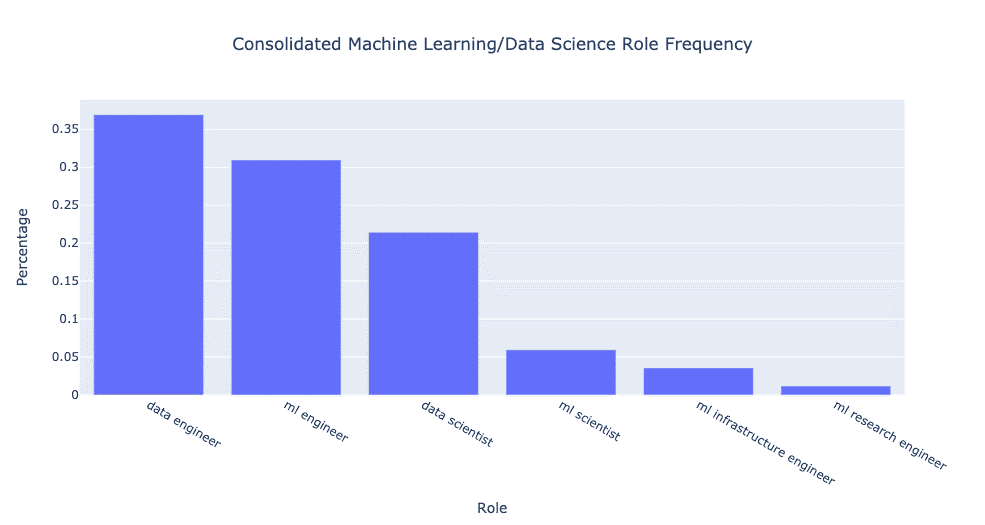
من احتمالا میتوانستم مهندس تحقیقML را در یکی از دانشمندان ML یا مهندس ML جمع کنم، اما با توجه به این که آن کمی از یک نقش ترکیبی بود، من آن را همانطور که هست ترک کردم.
روی هم رفته، ادغام تفاوتها را حتی برجستهتر کرد! ۷۰٪ بیشتر از موقعیت دانشمندان داده، موقعیت شغلی برای مهندس داده وجود دارد. علاوه بر این، حدود ۴۰ درصد موقعیت برای مهندس ML نسبت به موقعیت دانشمندان داده وجود دارد. همچنین تنها ۳۰٪ دانشمند ML به عنوان موقعیت دانشمند داده وجود دارد.
نتیجه گیری
مهندسان داده در مقایسه با دیگر حرفههای داده محور، تقاضای بالایی دارند. در یک معنا، این نشاندهنده یک تکامل برای زمینه گستردهتر است. زمانی که یادگیری ماشین ۵ تا ۸ سال پیش داغ شد، شرکتها تصمیم گرفتند که به افرادی نیاز داشته باشند که بتوانند طبقهبندی کننده دادهها باشند. اما پس از آن چارچوبهایی مانند تانسوری و پیتورچ واقعا خوب شدند، و توانایی شروع یادگیری عمیق و یادگیری ماشینی را دموکراتیک کردند.
این کار مجموعه مهارتهای مدلسازی داده را مشخص میکند. امروزه، تنگنای موجود، به شرکتها برای یادگیری ماشین و مدلسازی بینشها به مراکز تولید در مورد مشکلات داده کمک میکند. چگونه دادهها را تفسیر میکنید؟ چگونه اطلاعات را پردازش و پاک میکنید؟ چگونه آن را از A به B منتقل میکنید؟ چطور میتوانید هر روز این کار را با بیشترین سرعت ممکن انجام دهید؟
تمام اینها به معنای داشتن مهارتهای مهندسی خوب است. این ممکن است خستهکننده و غیر جذاب به نظر برسد، اما مهندسی نرمافزار قدیمی با گرایش به سمت داده ممکن است چیزی باشد که ما در حال حاضر واقعا به آن نیاز داریم. برای سالها، ما شیفته ایده متخصصان داده شدهایم که زندگی را به دادههای خام با توجه به نمایش دادههای جالب و شایعات رسانهای تبدیل میکنند. به هر حال، آخرین باری که یک مقاله تکنوکراچ را در مورد خط ETL دیدید، چه زمانی بود؟
اگر هیچ چیز دیگری نباشد، من معتقدم که مهندسی منسجم چیزی است که ما به اندازه کافی در آموزش کار علمی داده یا برنامههای آموزشی بر آن تاکید نمیکنیم. علاوه بر یادگیری نحوه استفاده از رگرسیون خطی، یاد بگیرید که چگونه یک یونیت تست نیز بنویسید! پس این به این معنی است که شما نباید علم داده را مطالعه کنید؟ نه.
این بدان معناست که رقابت سختتر خواهد شد. موقعیتهای کمتری برای آنچه که به دنبال فراوانی تازهواردان به بازار آموزشدیده برای انجام علم داده است، در دسترس خواهد بود. همیشه نیاز به افرادی وجود دارد که بتوانند به طور موثر دیدگاههای قابلاجرا را از دادهها تحلیل و استخراج کنند. اما آنها باید خوب باشند. دانلود یک مدل از قبل آموزشدیده از وب سایت tensorflow بر روی مجموعه داده Iris احتمالا برای به دست آوردن کار علم داده کافی نیست.
با این حال، واضح است، با تعداد زیادی از فرصتهای مهندس ML که شرکتها اغلب یک متخصص دادههای ترکیبی میخواهند: کسی که میتواند مدلها را بسازد و مستقر کند. یا به طور موجزتری گفت، کسی که میتواند از تانسوری استفاده کند اما همچنین میتواند آن را از منبع بسازد. نکته دیگر در اینجا این است که تنها تعداد زیادی از موقعیتهای تحقیقاتی ML وجود ندارد. تحقیقات یادگیری ماشینی تمایل دارد که سهم عادلانه خود را به دست آورد زیرا این جایی است که همه چیزهای لبه برش اتفاق میافتند، همه AlphaGo و GPT-۳ و نه.
اما برای بسیاری از شرکتها، به خصوص آنهایی که در مراحل اولیه هستند، ممکن است دیگر چیزی نباشد که به آن نیاز است. به دست آوردن مدلی که ۹۰٪ از راه وجود دارد اما میتواند به ۱۰۰۰ + کاربر برسد، اغلب برای آنها ارزشمندتر است. این بدان معنا نیست که مکان مهمی برای تحقیقات یادگیری ماشین وجود ندارد. البته که نه.
اما شما احتمالا بیشتر این نوع نقشها را در آزمایشگاههای تحقیقاتی صنعتی خواهید یافت که میتوانند به جای شروع مرحله تولید و تلاش برای نشان دادن تناسب محصول-بازار با سرمایهگذاران، برای مدتزمان طولانی، شرطهای سرمایهبر داشته باشند. اگر چیز دیگری نباشد، من معتقدم که مهم است که انتظارات تازهواردان به زمینه داده را منطقی و کالیبره کنیم. ما باید تصدیق کنیم که علم داده در حال حاضر متفاوت است. امیدوارم این پست بتواند وضعیت میدان را امروز روشن کند. تنها زمانی که بدانیم کجا هستیم، میدانیم که باید به کجا برویم.
این متن با استفاده از ربات ترجمه مقاله برنامه نویسی ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
۵ راهی که هوش مصنوعی میتواند در شرایط اضطراری فاجعه کمک کند
مطلبی دیگر از این انتشارات
۵ ابزار برای سرعت بخشیدن به پیشرفت پروژه علوم داده شما
مطلبی دیگر از این انتشارات
به اینترنت کوانتومی نزدیک میشویم!