

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
معرفی جستجو بر اساس مدل(Model Search): یک پلتفرم منبع باز برای یافتن مدلهای ML بهینه
منتشرشده در: ai.googleblog به تاریخ ۱۹ فوریه ۲۰۲۱
لینک منبع: Introducing Model Search: An Open Source Platform for Finding Optimal ML Models
موفقیت شبکه عصبی یا نورونی(NN) اغلب به این بستگی دارد که تا چه حد میتواند به کارهای مختلف تعمیم یابد. با این حال، طراحی NN هایی که میتوانند به خوبی تعمیم داده شوند، چالش برانگیز است زیرا درک جامعه تحقیقاتی از چگونگی تعمیم شبکه عصبی در حال حاضر تا حدی محدود است: شبکه عصبی مناسب برای یک مشکل خاص چگونه به نظر میرسد؟ چقدر باید عمیق باشد؟ کدام نوع از لایهها باید مورد استفاده قرار گیرند؟ آیا LSTM ها کافی خواهند بود یا اینکه لایههای ترانسفورماتور بهتر خواهند بود؟ یا شاید ترکیبی از این دو؟ آیا ترکیب گروهبندی و یا جداسازی باعث افزایش بازده میشود؟ این سوالات دشوار هنگام در نظر گرفتن حوزههای یادگیری ماشین(ML) حتی چالش برانگیزتر میشوند که در آن ممکن است درک بهتر و عمیقتر از دیگران وجود داشته باشد.
در سالهای اخیر، الگوریتمهای AutoML پدیدار شدهاند تا به محققان کمک کنند تا شبکه عصبی درست را به طور خودکار بدون نیاز به آزمایش دستی پیدا کنند. تکنیکهایی مانند جستجوی معماری عصبی (NAS) ، از الگوریتمهایی مانند یادگیری تقویتی (RL) ، الگوریتمهای تکاملی و جستجوی ترکیبی برای ساخت یک شبکه عصبی از یک فضای جستجو دادهشده استفاده میکنند. با راهاندازی مناسب، این تکنیکها نشان دادهاند که قادر به ارائه نتایجی هستند که بهتر از همتایان دستی طراحیشده هستند. اما اغلب اوقات، محاسبات این الگوریتمها سنگین هستند و نیاز به هزاران مدل برای آموزش قبل از همگرایی دارند. علاوه بر این، آنها فضاهای جستجو را کشف میکنند که خاص دامنه هستند و دانش اولیه اساسی انسان را که به خوبی در سراسر دامنه انتقال نمییابد، در خود جای دادهاند. به عنوان مثال، در طبقهبندی تصویر، NAS سنتی به دنبال دو بلوک سازنده خوب است (بلوکهای کانولوشن و نزولی) ، که طبق قراردادهای سنتی برای ایجاد شبکه کامل مرتب میشود.
ممکن است به مطالعه مقاله شبکه عصبی کانولوشن چیست؟ آموزش مبتدی برای یادگیری ماشینی و یادگیری عمیق علاقمند باشید.
برای غلبه بر این کاستیها و برای گسترش دسترسی به راهحلهای AutoML برای جامعه تحقیقاتی گستردهتر، ما هیجانزده هستیم تا نسخه منبع باز جستجو بر اساس مدل را اعلام کنیم، یک پلتفرم که به محققان در توسعه بهترین مدلهای ML، به طور موثر و خودکار کمک میکند. جستجو بر اساس مدل به جای تمرکز بر یک دامنه خاص، اگونستیک، انعطافپذیر و قادر به پیدا کردن معماری مناسب است که به بهترین نحو با مجموعه داده و مساله متناسب باشد، در حالی که زمان کدگذاری، تلاش و منابع محاسباتی را به حداقل میرساند. این سیستم بر روی tensorflow ساخته شدهاست و میتواند بر روی یک ماشین یا در یک محیط توزیعشده اجرا شود.
بررسی اجمالی
سیستم جستجو بر اساس مدل شامل چندین مربی، یک الگوریتم جستجو، یک الگوریتم یادگیری انتقال و یک پایگاهداده برای ذخیره مدلهای مختلف ارزیابی شدهاست. این سیستم هر دو آزمایش آموزش و ارزیابی را برای مدلهای ML مختلف (معماریهای مختلف و تکنیکهای آموزش) در یک روش تطبیقی، در عین حال غیرهمزمان اجرا میکند. در حالی که هر مربی آزمایشها را به طور مستقل انجام میدهد، همه مربیان دانش بهدستآمده از آزمایشها خود را به اشتراک میگذارند. در ابتدای هر چرخه، الگوریتم جستجو تمام آزمایشهای تکمیلشده را بررسی میکند و از جستجوی پرتو برای تصمیمگیری در مورد اینکه بعد از آن چه باید انجام شود استفاده میکند. سپس جهش را بر روی یکی از بهترین معماریهای تا به حال پیدا کرده و مدل حاصل را به یک مربی نسبت میدهد.
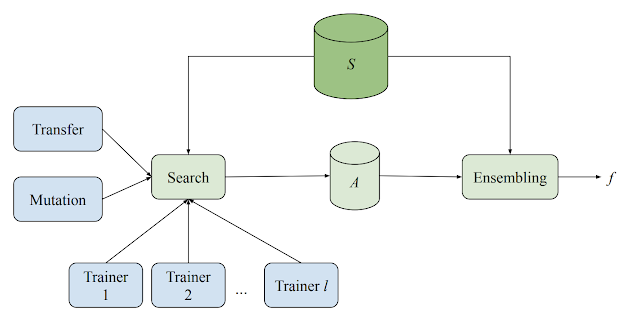
این سیستم یک مدل شبکه عصبی از مجموعهای از بلوکهای از پیش تعریفشده میسازد، که هر کدام از آنها نشاندهنده یک ریز معماری شناختهشده، مانند لایههای LSTM، ResNet یا ترانسفورمر هستند. جستجو بر اساس مدل با استفاده از بلوکهای اجزای معماری از پیش موجود، قادر به استفاده از بهترین دانش موجود از تحقیقات NAS در سراسر حوزهها میباشد. این رویکرد همچنین کارآمدتر است، زیرا ساختارها را بررسی میکند، نه اجزای اساسی و جزیی آنها، بنابراین مقیاس فضای جستجو را کاهش میدهد.

از آنجا که چارچوب جستجو بر اساس مدل بر روی tensorflow ساخته شدهاست، بلوکها میتوانند هر تابعی را که یک تانسور را به عنوان ورودی در نظر میگیرد، پیادهسازی کنند. به عنوان مثال، تصور کنید که فرد میخواهد یک فضای جستجو جدید را معرفی کند که با مجموعهای از میکرومعماریها ساخته شده است. این چارچوب بلوکهای به تازگی تعریفشده را میگیرد و آنها را در فرآیند جستجو قرار میدهد به طوری که الگوریتمها میتوانند بهترین شبکه عصبی ممکن را از مولفههای ارائهشده ایجاد کنند. بلوکهای ارائهشده حتی میتوانند به طور کامل شبکههای عصبی را تعریف کنند که در حال حاضر برای کار برای مساله مورد نظر شناخته شدهاند. در این صورت، جستجو بر اساس مدل را میتوان طوری کانفیگور کرد که به سادگی به عنوان یک ماشین ترکیبی قدرتمند عمل کند.
الگوریتمهای جستجو اجرا شده در جستجو بر اساس مدل تطبیقی، حریصانه و افزایشی هستند که باعث همگرایی سریعتر آنها نسبت به الگوریتمهای RL میشود. با این حال، آنها از ماهیت «کشف کد بهرهجو» الگوریتمهای RL با جداسازی جستجو برای یک کاندید خوب (مرحله اکتشاف) و افزایش دقت با ترکیب کاندیدهای خوب که کشف شدند (مرحله بهرهجو) ، تقلید میکنند. الگوریتم جستجوی اصلی پس از اعمال تغییرات تصادفی در معماری یا تکنیک آموزش (برای مثال عمیقتر کردن معماری) ، به طور تطبیقی یکی از k آزمایش اجرایی بالا (که در آن k میتواند توسط کاربر مشخص شود) را اصلاح میکند.

برای بهبود بیشتر کارایی و دقت، یادگیری انتقال بین آزمایشها داخلی مختلف فعال میشود. جستجو بر اساس مدل این کار را به دو روش انجام میدهد-از طریق جداسازی دانش یا تقسیم وزن. جداسازی دانش به فرد این امکان را میدهد تا دقت داوطلبان را با اضافه کردن یک عبارت زیان که با پیشبینیهای مدلهای با عملکرد بالا به علاوه حقیقت زمینی مطابقت دارد، بهبود بخشد. به اشتراک گذاری وزن، از سوی دیگر، بوت استرپ برخی از پارامترها (پس از اعمال جهش) در شبکه را از داوطلبان قبلا آموزشدیده با کپی کردن وزنهای مناسب از مدلهای قبلا آموزشدیده و به طور تصادفی راهاندازی میکند. این امر آموزش سریعتر را ممکن میسازد، که به فرصتها اجازه میدهد تا معماریهای بیشتر (و بهتر) را کشف کنند.
نتایج تجربی
جستجو بر اساس مدل از طریق مدل محصولات و تکرارهای کوچک بهبود مییابد. در مقاله اخیر، قابلیتهای جستجو بر اساس مدل را در حوزه صحبت با کشف مدلی برای تشخیص کلمات کلیدی و شناسایی زبان نشان دادیم. در کمتر از ۲۰۰تکرار، مدل حاصل با استفاده از مدلهای تولید سطح بالای داخلی طراحیشده توسط کارشناسان در دقت با استفاده از پارامترهای کمتر قابل تربیت (۱۸۴ K در مقایسه با ۳۱۵ K پارامتر) اندکی بهبود یافت.
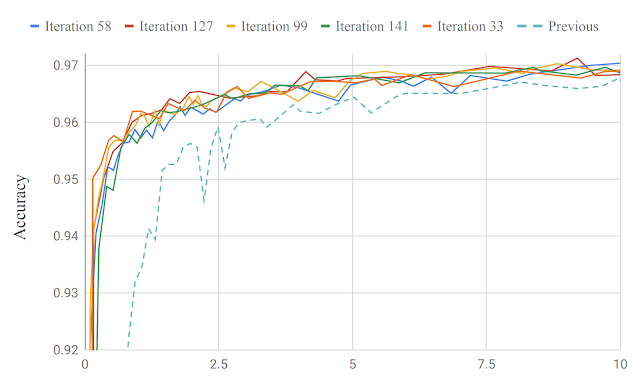
همچنین از جستجو بر اساس مدل برای یافتن یک معماری مناسب برای طبقهبندی تصویر بر روی مجموعه داده تصویربرداری CIFAR-۱۰ که به شدت مورد بررسی قرار گرفتهاست، استفاده کردیم. با استفاده از مجموعهای از بلوکهای کانولوشن شناختهشده، از جمله کانولوشن، بلوکهای بازشبکه (یعنی دو کانولوشن و یک اتصال حذفی)، سلولهای NAS-A، لایههای کاملا متصل و غیره، مشاهده کردیم که قادر بودیم به سرعت به دقت معیار ۹۱.۸۳ در ۲۰۹ آزمایش برسیم (یعنی تنها ۲۰۹ مدل را بررسی کنیم). در مقایسه، مجریان برتر قبلی به همان دقت آستانه در ۵۸۰۷ آزمایش برای الگوریتم NNNet (RL) و ۱۱۶۰ برای PNAS (RL + پیشرو) رسیدند.
نتیجهگیری
امیدواریم که کد جستجو بر اساس مدل برای محققان یک چارچوب انعطافپذیر، دامنه-لاادریستیک برای کشف مدل ML فراهم کند. با ایجاد دانش قبلی برای یک دامنه دادهشده، ما باور داریم که این چارچوب به اندازه کافی برای ساخت مدلهایی با عملکرد سطح بالا در مسائل به خوبی مطالعه شده زمانی که با یک فضای جستجو متشکل از بلوکهای سازنده استاندارد فراهم میشود، قدرتمند است.
این متن با استفاده از ربات مترجم مقالات هوش مصنوعی ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
ریاضیدانان کلاس جدیدی از اعداد اول دیجیتال را پیدا میکنند.
مطلبی دیگر از این انتشارات
زیرنویسهای ترجمه شدهی زنده Google Meet بهطور گستردهای شروع به انتشار کردند.
مطلبی دیگر از این انتشارات
نتایج واکسن ویروس کرونا در راه است-و نگرانیهای دانشمندان در حال افزایش است