

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
هوش مصنوعی قابل توضیح (XAI)

منتشر شده در towardsdatascience به تاریخ ۹ نوامبر ۲۰۲۱
لینک منبع Explainable Artificial Intelligence (XAI). But, for Whom?
تلاش برای توضیح پیشبینیها یا ساخت مدلهای یادگیری ماشینی قابل تفسیر یک موضوع داغ است که به سرعت در حال گسترش است. هنگام اعمال یادگیری ماشینی در فرآیند تصمیمگیری در بسیاری از حوزهها مانند پزشکی، انرژی هستهای، تروریسم، بهداشت و درمان یا امور مالی، فرد نمیتواند کورکورانه به پیشبینیها اعتماد کند و الگوریتم را «در حیات وحش» رها کند، زیرا این امر ممکن است عواقب فاجعه باری داشته باشد.
عملکرد پیشبینی مدلها از طریق مجموعه وسیعی از معیارها مانند دقت، فراخوان، F1، AUC، RMSE، MAPE ارزیابی میشود. اما عملکرد پیشبینی بالا ممکن است تنها نیاز نباشد.
روند بزرگی در زمینه هوش مصنوعی قابل توضیح و ML قابل تفسیر برای ایجاد اعتماد در پیشبینیهای مدل وجود دارد. بسیاری از مقالات، بلاگها، و ابزارهای نرمافزاری قابلیت توضیح و قابلیت تفسیر را به روشی بسیار تعریفشده ارائه میدهند، اما …
پاسخگویی برای چه کسی؟ قابلیت توضیح برای چه کسی؟
من حدس میزنم که همه ما میتوانیم بر این حقیقت توافق کنیم که همه ما به یک نوع توضیح برای چگونگی رفتار یک مدل نیاز نداریم. متخصصان هوش مصنوعی مانند اندرو ان جی، جفری هینتون، یان گودمن … نیازی به توضیح مشابهی در مورد اینکه چرا یک مدل چه کاری و به چه دلیلی در مقایسه با دانشمند دادههای متوسط انجام میدهد، نخواهند داشت. علاوه بر این، کاربر عادی احتمالا نیاز به توضیح کاملا متفاوتی دارد زیرا آنها احتمالا هیچ دانشی از زمینه AI ندارند (و احتمالا نمیخواهند داشته باشند).
بنابراین، توضیحات در هوش مصنوعی مخاطبان متفاوتی دارند.
اندرو NG و یک کاربر به طور تصادفی انتخاب شده از سیستم توصیه Netflix نیازهای متفاوتی برای درک "چرا این سریال تلویزیونی توصیه شد؟" دارند. یک کاربر تصادفی ممکن است دریافت پیشنهاد یک فیلم اکشن خاص را کافی بداند زیرا در دو هفته گذشته هر شب فیلمهای اکشن تماشا میکرده است، اما پس از آن Andrew NG (به جای نام هر شخص مشهور دیگری با هوش مصنوعی) ممکن است نیاز به توضیح متفاوتی داشته باشد. .
توضیحات یادگیری ماشینی برای یک مخاطب خاص انجام میشود. به نظر میرسد روندهای کنونی xAI توضیحاتی را ایجاد میکنند که برای دانشمندان داده که دانش خوبی از یادگیری ماشینی دارند، ساخته شدهاند … اما آیا باید بر روی توضیح AI به محقق داده یا به کاربران عادی تمرکز کند؟
یکی از خطاهای معمول در توسعه نرمافزار این است که توسعهدهندگان در نهایت نرمافزار را برای خود توسعه میدهند و معلوم میشود که برای مخاطبان هدف آنها ضعیف طراحی شده است [3].
هوش مصنوعی قابل توضیح ممکن است در خطر سرنوشتی مشابه با توسعه ضعیف نرم افزار باشد. توضیحات AI ممکن است برای دانشمندان داده و محققان یادگیری ماشینی توسعه داده شود و نه برای کاربر روزمره.
مورد استفاده: Lime
یکی از تکنیکهایی که مفید بودن آن اثبات شدهاست، استفاده از مدلهای جایگزین محلی است. احتمالاً معروفترین آنها «توضیحات مدل تفسیرپذیر محلی» (LIME) است. ایده بسیار ساده است: هدف این است که بفهمیم چرا مدل یادگیری ماشینی یک پیشبینی فردی انجام داده است؛ به این می گویند توضیحات فردی. LIME آنچه را که برای پیشبینیها اتفاق میافتد وقتی که شما تغییرات دادههای خود را به مدل یادگیری ماشین میدهید، آزمایش میکند [ ۵ ].
در شکل زیر میتوانیم یک تقریب محلی برای نمونه خاصی از مجموعه دادههای شناخته شده کیفیت شراب را ببینیم. مهم نیست که مدل اصلی چیست (مدل آگنوستیک)، میتوانیم یک تقریب محلی انجام دهیم تا ببینیم کدام ویژگیها و به چه میزان کمک میکنند.
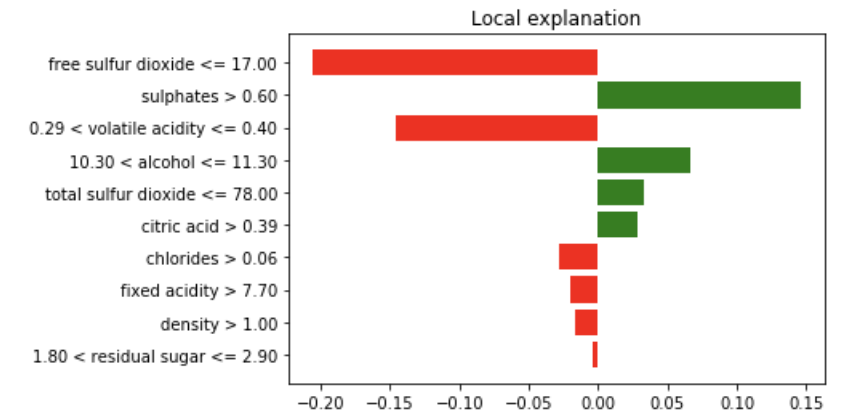
توضیح محلی Lime برای نمونه مجموعه داده با کیفیت شراب
با این تقریب محلی، ما یک مدل خطی داریم که فقط برای این نمونه داده به خوبی کار می کند. ما فضای داده ورودی را مختل کردهایم، یک تقریب محلی را تعریف کردهایم، و یک مدل را در آنجا برازش دادهایم.
برای چه کسی میتوانیم این موضوع را توضیح دهیم؟
یک نفر میتواند بگوید که این توضیح برای آنها شهودی است چون به عنوان یک برآورد کننده مدل خطی با ویژگیهای اندک ساخته شدهاست. سهم هر ویژگی خطی است. حتی می توان استدلال کرد که این نوع توضیح برای فردی که کمی دانش در این زمینه دارد، اما تجربه قبلی در ML ندارد، خوب خواهد بود. همچنین، این میتواند برای یک محقق داده مفید باشد که هیچ زمانی ندارد و به سرعت در حال عبور از میان نمونههای تفسیری مشابه به دلایلی است، بنابراین یک محقق داده بدون زمان است.
اما ما واقعا چه کار میکنیم؟ آیا ما از یک توضیح دهنده جعبه سیاه برای پیشبینی الگوریتم جعبه سیاه استفاده میکنیم؟ تنها بخشی از دانشمندان داده قادر به درک این موضوع هستند که یک جنگل تصادفی یا درخت تصمیم مبتنی بر گرادیان چگونه رفتار میکند، اما بخشی از دانشمندان داده که در واقع میدانند که LIME دقیقا زمانی که از یک جنگل تصادفی ساخته میشود، چه کاری انجام میدهد، حتی کوچکتر است. در نمودار توضیح محلی LIME چه چیزی نشانداده شدهاست؟ این توضیح چقدر پایدار است؟ در مورد ثبات آن چطور؟
حتی اگر افزایش علاقه به AI قابل توضیح واقعا سریع در حال تکامل باشد، برخی سوالات باقی میمانند. برای چه کسی توضیحات را میسازیم؟ آیا ما محققان / دانشمندان داده را هدف قرار میدهیم؟ یا ما مخاطب عام را هدف قرار میدهیم؟
این متن با استفاده از ربات ترجمه مقالات علم داده ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
۱۵ دوره آموزشی یادگیری عمیق برای مشاغل با حقوق بالا
مطلبی دیگر از این انتشارات
ویندوز ۱۱ یک طراحی Task Manager جدید دریافت میکند.
مطلبی دیگر از این انتشارات
نشانههای جدید در مورد ویروسهای متقارننما با ژنهای قابلبرگشت عجیب