

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
پروفایل ایدهآل یک دانشمند داده چه شکلی است؟

منتشرشده در towardsdatascience
لینک مقاله اصلی: What Does an Ideal Data Scientist’s Profile Look Like?
یافتههای تحلیل ۱۰۰۰ شغل
اگر شما جوینده شغل علم داده هستید، باید همیشه در این فکر باشید که چه مهارتهایی را باید در رزومه خود قرار دهید تا با شما تماس بگیرند؛ اگر به دنبال این هستید که وارد این حوزه شوید، ممکن است بارها فکر کرده باشید و بخواهید بدانید کدام تکنولوژیها را باید یاد بگیرید تا کاندیدای جذابی باشید.
ادامه این مطلب را بخوانید، من جوابی برایتان دارم.
اول، ما به الزامات مهارتی عناوین شغلی مختلف نگاهی میاندازیم. (جداول بعدی)
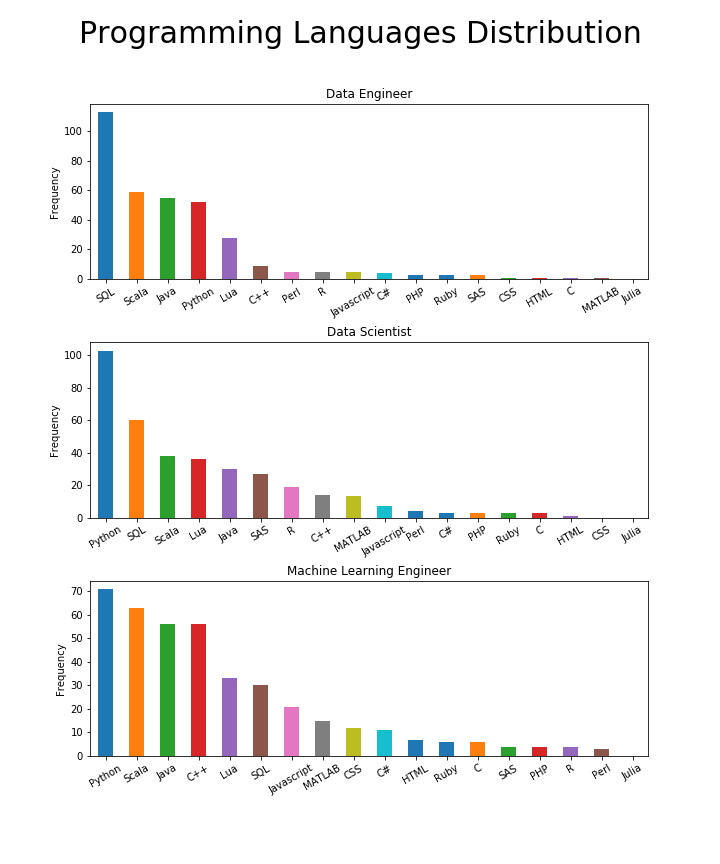
دیگر بحثی بین پایتون و R وجود ندارد چون اکنون پایتون رهبر غالب است
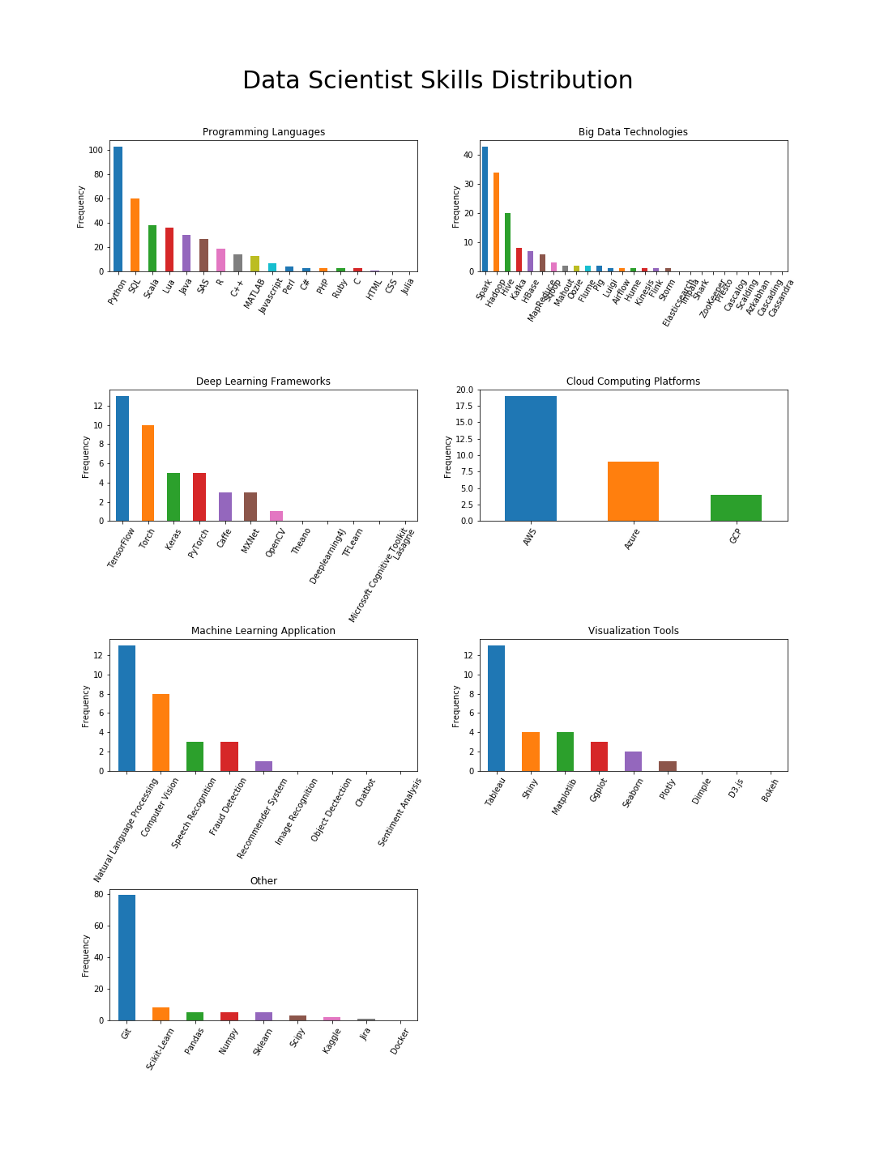
زمانی بحث بر سر این بود که پایتون زبان انتخابی در علم داده است یا R. واضح است که تقاضا در بازار به ما میگوید که پایتون در حال حاضر رهبر است. همچنین شایانذکر است که R حتی اشارات کمتری نسبت به SAS داشتهاست. بنابراین، اگر قصد دارید وارد علم داده شوید، تمرکز تلاشهای یادگیری خود را بر روی پایتون بگذارید. SQL به عنوان زبان پایگاهداده (و شاید هم داده!) ، دومین زبان مهم برای دانشمندان داده است. به دلیل ماهیت گسترده حرفه دانشمند داده، زبانهای دیگر نیز نقشهای مهمی ایفا میکنند.
به طور خلاصه، زبانهای برتر برای دانشمندان داده عبارتند از: پایتون، SQL، اسکالا، لوا، جاوا، SAS، R، C + + و Matlab.
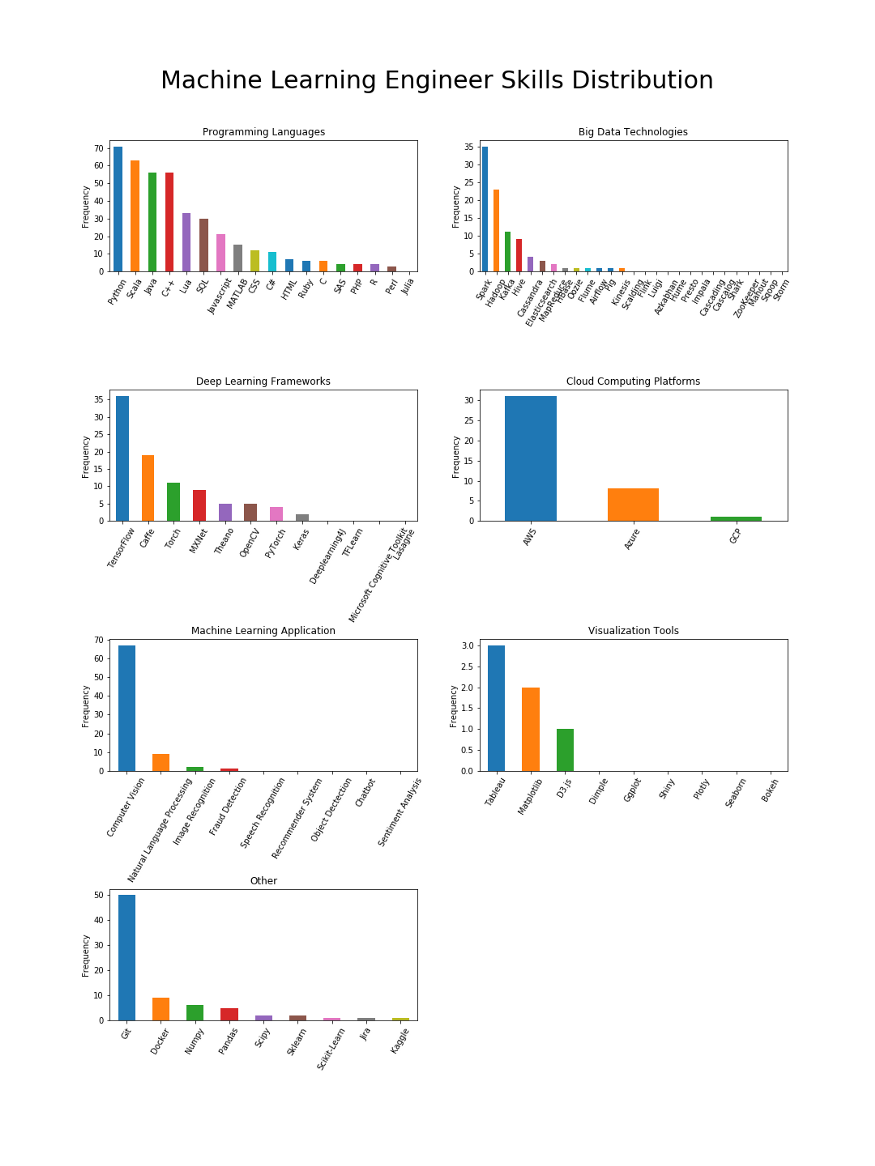
زبانهای مورد نیاز برای مهندسین یادگیری ماشین متنوعتر هستند
پایتون به عنوان زبان غیر رسمی یادگیری ماشین است و جای تعجب ندارد که به عنوان زبان برتر برای مهندسان یادگیری ماشین مطرح میشود. به دلیل نیاز به پیادهسازی الگوریتم ها از ابتدا و استقرار مدلهای ML در محیطهای داده بزرگ، زبانهای مربوطه مانند C + + و اسکالا نیز مهم هستند. به طور کلی، به نظر میرسد که نیاز زبانها در مقایسه با دو نقش دیگر گسترش بیشتری دارد.
به طور خلاصه، زبانهای برتر برای مهندسان یادگیری ماشین عبارتند از: پایتون، اسکالا، جاوا، سی + +، لوا، SQL، جاوا اسکریپت، متلب، CSS و سی شارپ.
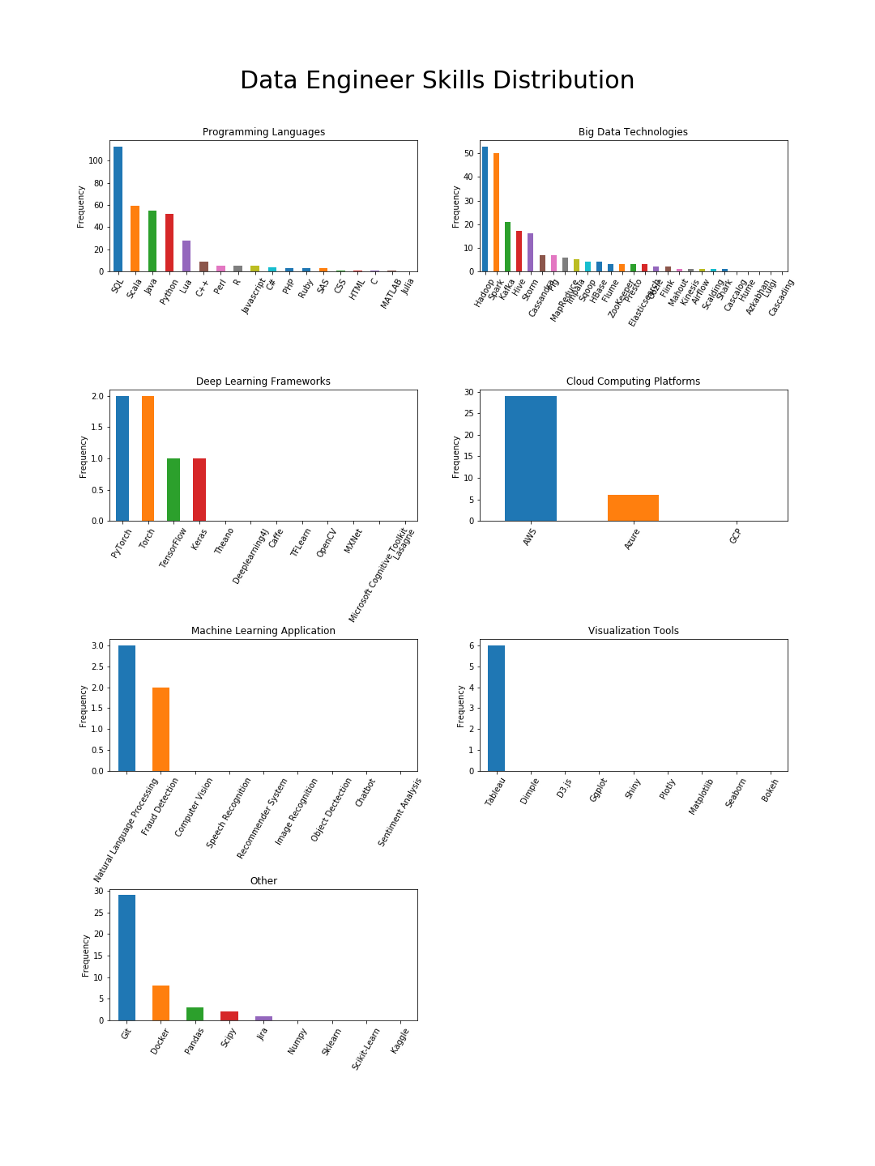
اگر میخواهید مهندس داده شوید، SQL یک «باید» مطلق است
مهندسان داده همیشه با پایگاهداده سر و کار دارند و SQL زبان پایگاهداده است، بنابراین تعجبی ندارد که SQL زبان برتر است.
پایتون مهم است، اما هنوز هم به اسکالا و جاوا میبازد، چرا که این زبانها به مهندسان داده کمک میکنند تا با کلاندادهها کار کنند.
به طور خلاصه، زبانهای برتر برای مهندسان داده عبارتند از: SQL، اسکالا، جاوا، پایتون و لوا.
اسکالا به عنوان دومین زبان وارد کننده در علم داده در حال ظهور است (نه R)
وقتی نقشهای مختلف را بررسی میکنیم، جالب است که اسکالا یا دوم یا سوم میشود. بنابراین میتوانیم بگوییم که سه زبان برتر در علم داده پایتون، SQL و اسکالا هستند. اگر به یادگیری یک زبان جدید فکر میکنید، اسکالا را در نظر بگیرید!
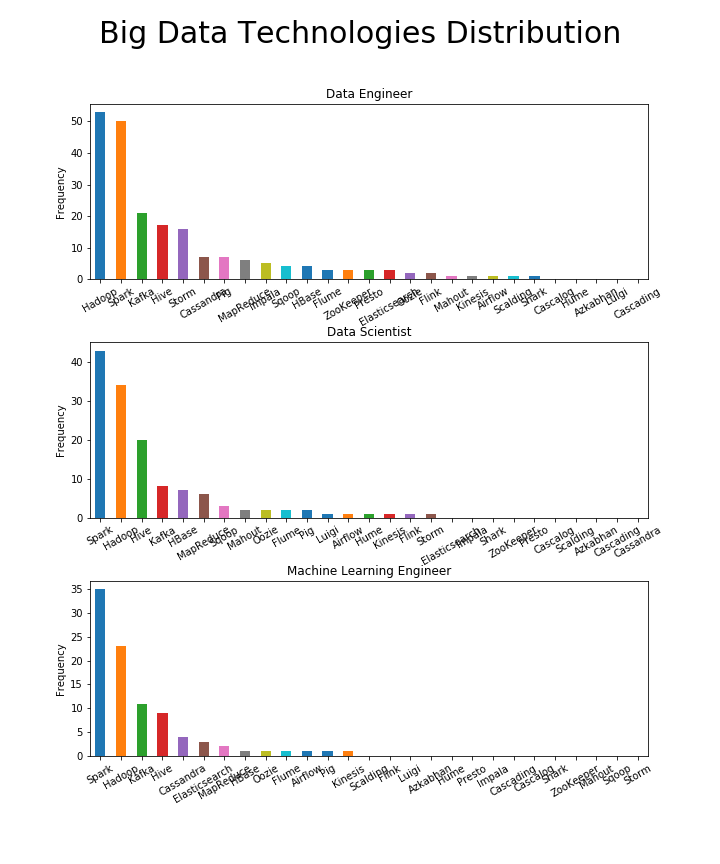
اسپارک بزرگترین مهارت کلاندادهها است؛ به جز برای مهندسان داده
فقط برای مهندسان داده، به هادوپ کمی بیشتر از اسپارک اشاره شدهاست، اما به طور کلی، اسپارک قطعا چارچوب کلاندادهای است که شخص باید اول از همه یاد بگیرد. کاساندرا برای مهندسان مهمتر از دانشمندان است، در حالی که به نظر میرسد استورم تنها مربوط به مهندسان داده باشد.
به طور خلاصه، فنآوریهای کلان داده برای علم داده عبارتند از: اسپارک، هادوپ، کافکا، هایو.
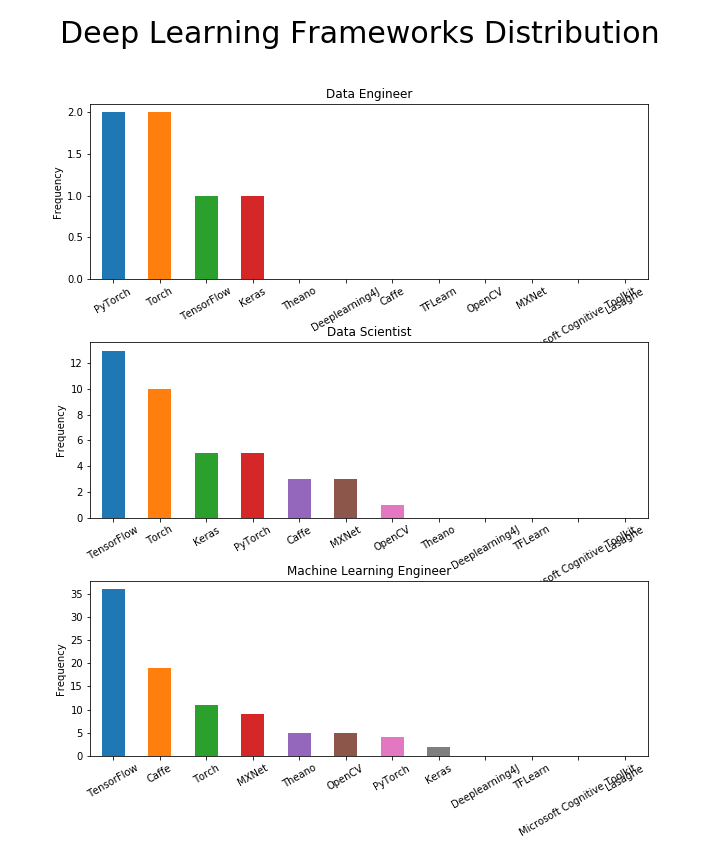
وقتی بحث آموزش عمیق پیش میآید، TensorFlow پادشاه است
چارچوبهای یادگیری عمیق (DL) به ندرت در شرح کار مهندس داده ذکر میشوند، بنابراین به نظر میرسد که چارچوبهای یادگیری عمیق برای این نقش لازم نیستند. بیشترین اشاره به چارچوبهای DL در نقشهای مهندس یادگیری ماشین است، که نشان میدهد مهندسان ML خیلی با مدلسازی یادگیری ماشین سروکار دارند، نه فقط بهکارگیری مدل. علاوه بر این، TensorFlow قطعا در زمینه یادگیری عمیق غالب است. اگرچه Keras به عنوان یک چارچوب یادگیری عمیق سطح بالا واقعا برای دانشمندان داده محبوب است، اما تقریبا برای نقشهای یادگیری ماشینی بیارتباط است، احتمالا نشان میدهد که فعالان ML اغلب از چارچوبهای سطح پایینتر مانند TensorFlow استفاده میکنند.
به طور خلاصه، مهمترین چارچوبهای یادگیری عمیق در علم داده عبارتند از: TensorFlow، تورچ، Caffee و MXNet.
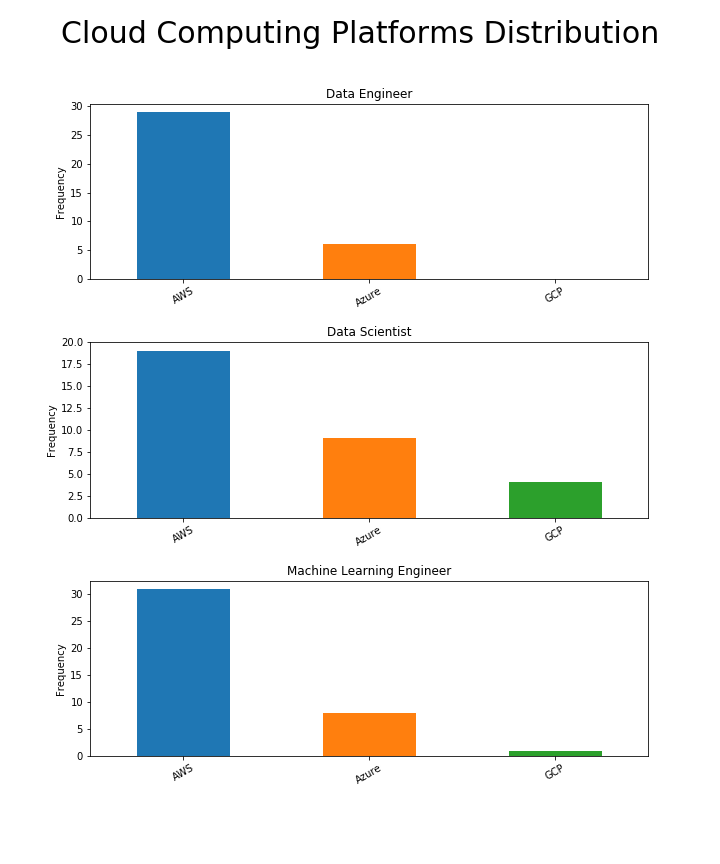
AWS در تمام موارد غالب است
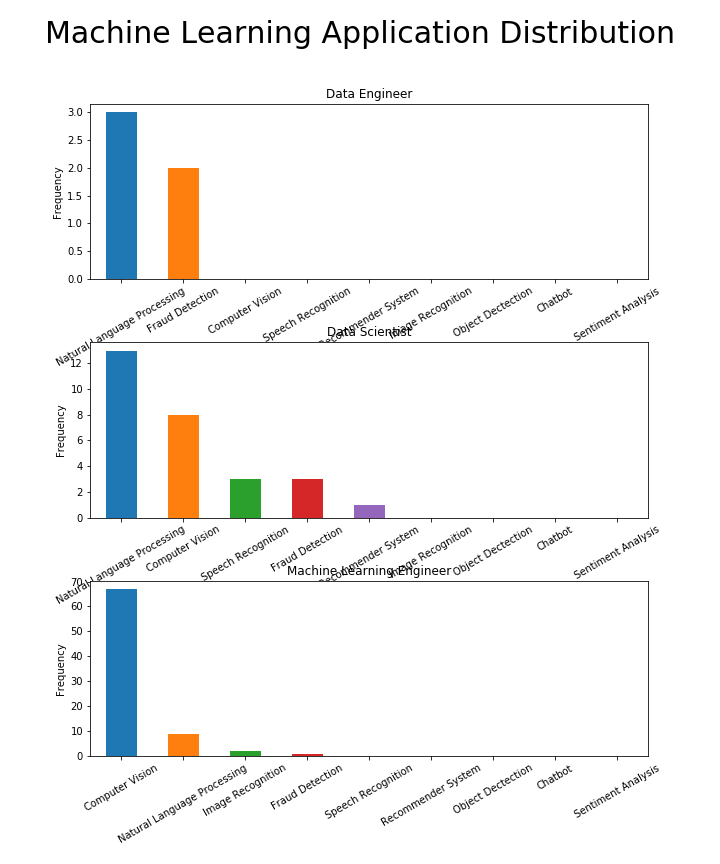
اغلب تقاضا در یادگیری ماشین از بینایی کامپیوتر است
برای دانشمندان عمومی داده، پردازش زبان طبیعی بزرگترین حوزه کاربردی ML است که توسط بینایی کامپیوتر، شناخت گفتار، تشخیص تقلب و سیستمهای پیشنهاد دهنده دنبال میشود. به طور شگفتانگیز، برای مهندسان یادگیری ماشین، بزرگترین تقاضا تنها از بینایی کامپیوتر میآید و دومین تقاضا، پردازش زبان طبیعی است. از سوی دیگر، مهندسان داده متخصصان متمرکز هستند-هیچ یک از این حوزههای کاربردی ML برای آنها مناسب نیستند.
بینش-اگر میخواهید به یک دانشمند داده تبدیل شوید، میتوانید انواع مختلفی از پروژههای ساختهشده را انتخاب کنید تا تخصص خود را براساس حوزهای که میخواهید وارد آن شوید نشان دهید، اما برای مهندسان یادگیری ماشین، بینایی کامپیوتر راه پیشرفت است!
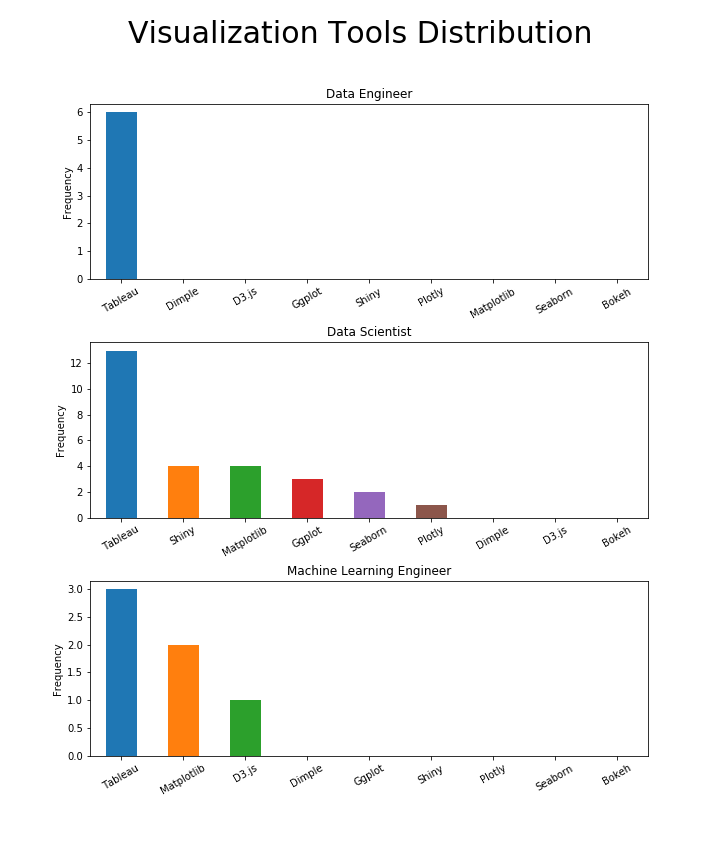
وقتی بحث مصورسازی مطرح میشود، تابلو یک اجبار است
ابزارهای تجسم اغلب برای دانشمندان داده مورد نیاز هستند و هم برای مهندسان داده و هم برای مهندسان یادگیری ماشین به ندرت به آنها اشاره میشود. با این حال، تابلو (Tableau) بهترین انتخاب برای تمام نقشها است. به نظر میرسد که برای دانشمندان داده، شاینی، Matplotlib، ggplot و Seaborn به یک اندازه مهم هستند.
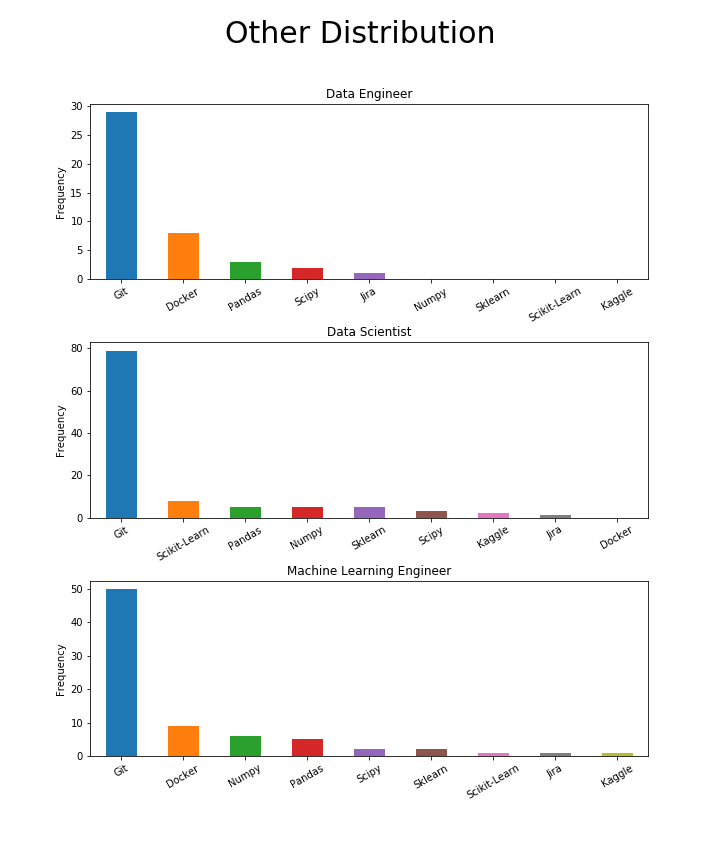
گیت برای همه مهم است، در حالی که داکر تنها برای مهندسان است
سپس، ما از ابر کلمات برای کشف پربسامدترین کلمات کلیدی برای هر نقش استفاده کرده و آنها را با مهارتهای مربوطه ترکیب میکنیم تا پروفایل های ایدهآل برای تمام نقشهای علم داده ایجاد کنیم!
دانشمند داده بودن بیشتر در مورد یادگیری ماشین است تا تجارت یا تجزیه و تحلیل
دانشمند داده بودن به عنوان حرفهای که به آمار، تجزیه و تحلیل، یادگیری ماشین و دانش تجاری نیاز دارد، در نظر گرفته شدهاست. به نظر میرسد که هنوز هم این مورد وجود دارد، یا حداقل، هنوز نیازهای مختلفی در یک دانشمند داده وجود دارد. با این حال، به نظر میرسد که در حال حاضر دانشمند داده بودن بیش از هر چیز دیگری در مورد یادگیری ماشین است.
الزامات دیگر عبارتند از: تجارت، مدیریت، ارتباطات، تحقیق، توسعه، تجزیه و تحلیل، محصول، فنی، آمار، الگوریتم، مدلها، مشتری و علوم کامپیوتر.

مهندسی یادگیری ماشین درباره تحقیق، طراحی سیستم و ساختن است
به نظر میرسد که مهندسان یادگیری ماشینی در مقایسه با دانشمندان عمومی داده قطعا دارای یک پورتفولیوی متمرکزتر هستند که شامل تحقیقات، طراحی و مهندسی است. واضح است که راهحل، محصول، نرمافزار و سیستم موضوعات غالب هستند. به همراه آنها، تحقیقات، الگوریتم، هوش مصنوعی، یادگیری عمیق و بینایی کامپیوتر نیز وجود دارد. جالب توجه است که به نظر میرسد عواملی مانند تجارت، مدیریت، مشتری و ارتباطات نیز مهم هستند. این مساله را می توان در تکرار بعدی این پروژه بیشتر بررسی کرد. از سوی دیگر، پایپلاین و پلتفرم نیز برجسته هستند، و درک مشترک از مسئولیت مهندس یادگیری ماشین در ساخت پایپلاین داده برای استقرار سیستمهای ML را تایید میکنند.

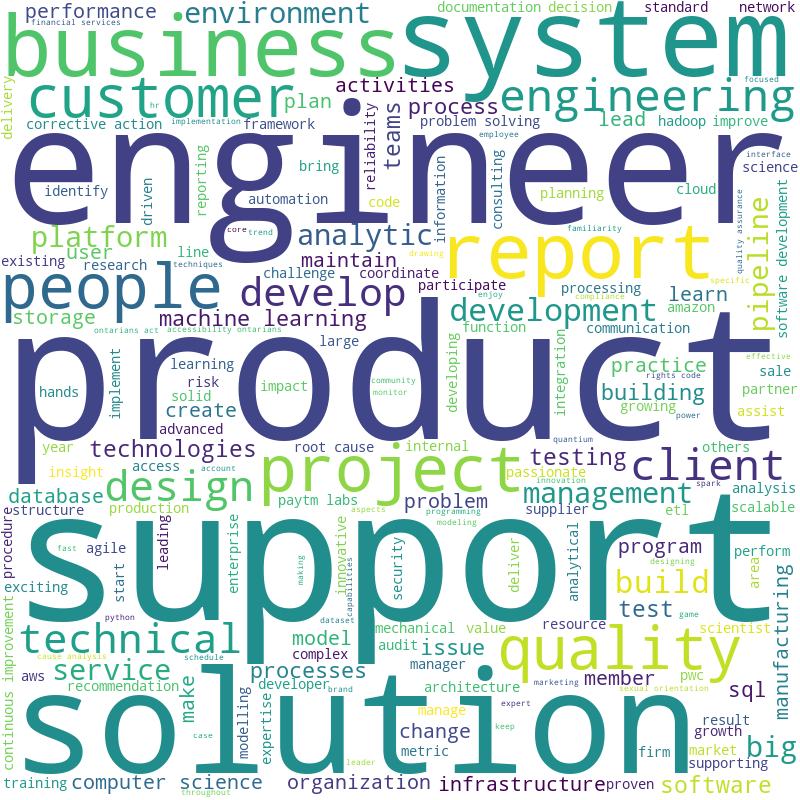
مهندس داده یک متخصص واقعی است
مهندسان داده دارای یک پورتفولیوی متمرکزتر نسبت به مهندسان یادگیری ماشین هستند. واضح است که تمرکز بر حمایت از محصول، سیستم و راهحل از طریق طراحی و توسعه پایپلاین است. الزامات اصلی عبارتند از مهارتهای فنی، پایگاهداده، ساختن، آزمایش، محیط و کیفیت. یادگیری ماشین نیز مهم است، احتمالا به این دلیل که پایپلاینها عمدتا برای پشتیبانی از نیازهای به کار گیری دادههای مدل ML ساخته شدهاند.
خودشه! امیدوارم این پروژه به شما کمک کند درک کنید که کارفرمایان به دنبال چه چیزی هستند، و از همه مهمتر به شما در مورد این که چطور رزومه خود را سفارشی کنید، چه فناوریهایی را یاد بگیرید و تصمیمات آگاهانه بگیرید،کمک کند!
این متن با استفاده از ربات ترجمه مقاله علمی ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مطلبی دیگر از این انتشارات
سه درس کلیدی که من از یک کسبوکار ناموفق یاد گرفتهام
مطلبی دیگر از این انتشارات
ترکیبات دارویی جدید علیه ویروس کرونا با هوش مصنوعی
مطلبی دیگر از این انتشارات
گوگل قصد دارد تا سال ۲۰۲۹ یک کامپیوتر کوانتومی تجاری بسازد.