

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
چرا باید یادگیری تقویتی را به جعبهابزار علوم داده خود اضافه کنید؟

منتشرشده در: towardsdatascience به تاریخ ۲۰ فوریه ۲۰۲۱
لینک منبع: Why you should add Reinforcement Learning to your Data Science Toolbox
چیزهای زیادی وجود دارند که میتوانید به عنوان یک دانشمند داده یاد بگیرید. شرط میبندم اولین چیزهایی که یاد گرفتید در مورد آمار، تجزیه و تحلیل دادهها، تجسم، برنامهنویسی، پایگاههای داده، یادگیری ماشینی و یادگیری عمیق بود. زمانی که شما با این موضوعات آشنا هستید، با موضوعات خاصی مانند GANها، NLP، ابر، محفظه سازی، مهندسی نرمافزار و غیره ادامه میدهید. شما یک مسیر را براساس چیزهایی که دوست دارید و مهارتهایی که نیاز دارید انتخاب میکنید. این پست وبلاگ توضیح میدهد که چرا اضافه کردن یادگیری تقویتی (RL) به جعبهابزار علوم داده شما انتخاب خوبی است.
یک بازخورد کوتاه: یک عامل با یک محیط از طریق انتخاب اقدامات تعامل میکند. نماینده مشاهدات و پاداشها را دریافت میکند. هدف نماینده حداکثر کردن مجموع پاداشها است. این فرآیند در اپیزودها اتفاق میافتد، نماینده یاد میگیرد و در کارش بهتر و بهتر میشود.
در زندگی واقعی، یادگیری به طور مشابه عمل میکند. وقتی به یک سگ یاد میدهید که به دستورها گوش دهد، وقتی رفتار درست را نشان میدهد به او یک تشویقی میدهید. اگر این کار را نکند، چیزی نمیگیرد. شما میتوانید این وضعیت را به RL ترجمه کنید. حالت فرمانی است که او میشنود، عمل چیزی است که سگ در پاسخ به دستور انجام میدهد و پاداش تشویقی است. اگر سگ دوست داشته باشد، بهتر و بهتر گوش خواهد داد.

هشدار: اگر شما کار علمی اطلاعات خود را شروع کردهاید، من توصیه نمیکنم با RL شروع کنید! این یک موضوع پیشرفته است و شما باید اطلاعاتی در مورد ریاضیات و یادگیری عمیق داشته باشید.
مطالعه مقاله ما به دانشمندان داده نیاز نداریم، به مهندسان داده نیاز داریم! توصیه میشود.
سه دلیل اصلی یادگیری RL
چرا باید RL را یاد بگیرید؟
۱. بسیاری از مشکلات کسبوکار را میتوان با RL حل کرد.
روشRL دانش ارزشمندی را که میتوانید برای بسیاری از موارد کسبوکار استفاده کنید، اضافه میکند. برخی مثالها عبارتند از:
- شما میتوانید یک سیستم توصیه بهترین عمل بعدی بسازید. تصور کنید که مشتری دارید، و میخواهید سودآورترین اقدام را برای هر مشتری پیدا کنید. شما میتوانید حالات را برای مشتریان خود تعریف کنید، مانند مشتری جدید، برانگیزنده یا مشتری وفادار. با تست اقدامات فروش و بازاریابی میتوانید سودآورترین اقدامات مربوط به ایالتها را پیدا کنید.
- زمانبندی مشاغل یک کار جالب دیگر است. شما میتوانید یک مجموعه کار، منابع و زمان مورد نیاز برای هر کار را مشخص کنید. نماینده راهی برای بهینهسازی زمان تکمیل کار پیدا خواهد کرد.
- اتوماسیون و رباتیک. با استفاده از RL، رباتها میتوانند یاد بگیرند که یک کار را به طور کامل انجام دهند. مهندسی برخی از وظایف دشوار است و RL میتواند به این وظایف کمک کند. یک مثال خوب کنترل یک شبکه از سیگنالهای چراغ راهنمایی است: با پاداش دادن به عوامل RL برای تاخیر کمتر، عوامل راه مناسبی برای سازماندهی سیگنالها پیدا میکنند. آنها بهتر از مکانیزمهای کنترل چراغهای راهنمایی عادی عمل میکنند.

هنوز قانع نشده اید؟ اجازه دهید به دلیل بعدی بپردازیم.
۲. شما نیازی به دادههای برچسبدار ندارید.
اگرچه دادههای برچسبگذاری شده میتوانند در یک مساله RL مفید باشند، اما ضروری نیستند. شما میتوانید یک محیط RL را از ابتدا بسازید و نماینده راهی برای به حداکثر رساندن مجموع پاداش پیدا خواهد کرد.
این یک معامله بزرگ است. آمادهسازی و جمعآوری دادهها چالشهایی هستند که دانشمندان با آن مواجه هستند و یک بررسی نشان میدهد که تقریبا ۸۰٪زمان آنها را مصرف میکند. بدتر اینکه، اینها کارهایی هستند که دانشمندان کمترین لذت را از آنها میبرند. با استفاده از RL میتوان از این بخش صرفنظر کرد. نماینده میتواند از ابتدا یاد بگیرد و لزوما به دادههای برچسبدار نیاز ندارد. از سوی دیگر، ایجاد یک محیط میتواند دشوار باشد، به خصوص زمانی که شما تازه با RL شروع کردهاید و میخواهید یک مشکل پیچیده را حل کنید. وقتی اینطور است، میتوانید کار را آسان شروع کنید (با یک محصول با حداقل دوام) و مشکل خود را با اضافه کردن ویژگیها و با آزمایش تعاریف مختلف از حکمها، اقدامات و پاداشها گسترش دهید.
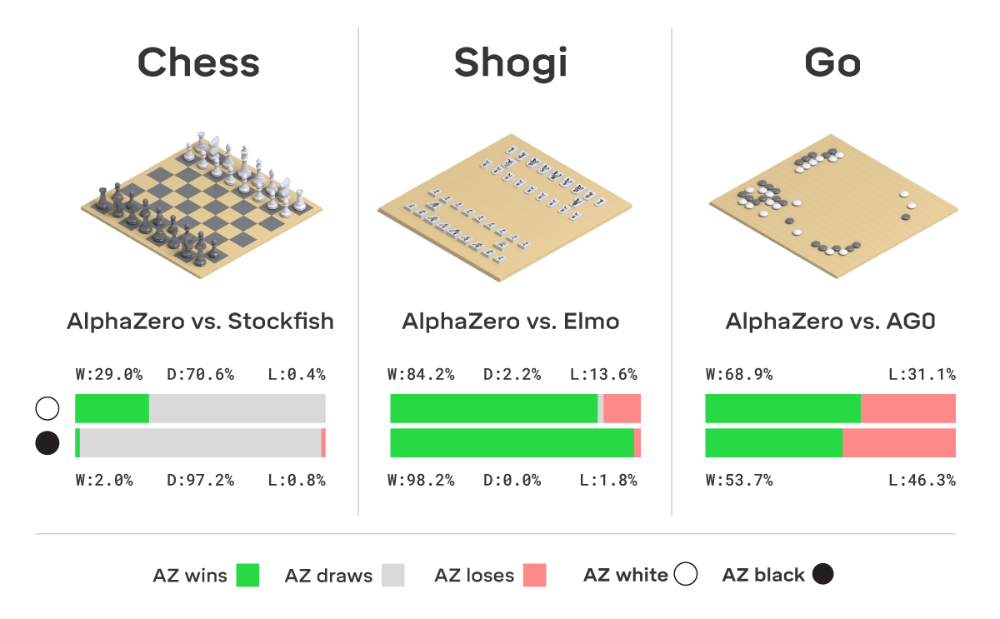
الففازیرو، که تنها از طریق خود بازی آموزشدیده بود، تنها قوانین شطرنج، شوگی و گو را میدانست. این بازی از تمام الگوریتمهای ابداع شده قبلی بهتر عمل کرد و روشهای جدید جالبی را برای انجام این بازیها نشان داد.
۳. خودتان را متمایز کنید.
بسیاری از مسیرهای یادگیری علم داده به صورت آنلاین وجود دارند. شما میتوانید سفر خود را در Coursera، datacamp، Udacity و یا deeplearning.ai آغاز کنید. یا میتوانید مدرک کارشناسی یا کارشناسیارشد بگیرید. اکثر دورهها در این مسیرهای یادگیری به شما آموزش میدهند که چگونه برنامهریزی کنید و چگونه دادهها را تحلیل، تجسم و مدل کنید. در ابتدا این خوب است، اما بعد از این که شما قادر به انجام این وظایف هستید، میتوانید خودتان را از دانشمند داده «منظم» متمایز کنید. یادگیری "یادگیری تقویتی" میتواند به شما در انجام این کار کمک کند.
روش RL در برنامههای استاندارد صدور گواهی علمی داده تدریس نمیشود و تسلط بر آن واقعا جالب است. شما میتوانید یک راهحل جدید و منحصر به فرد به جدول بیاورید و از زوایای مختلف به مسائل نزدیک شوید. اگر شما قادر به توسعه راهحلهای RL مربوط به مشکلات کسبوکار هستید، خودتان را از دیگر دانشمندان داده جدا میکنید.
علاوه بر این، مشکل RL مانند یک معما است. فکر کردن در مورد نحوه تعریف قانونها، پاداشها و اقدامات جالب است. راهحل کار جنبههای مثبت به همراه دارد. آزمایش کردن خوب است، چون با یک تغییر کوچک در پاداش، یک نماینده میتواند کارهای واقعا عجیبی انجام دهد.
کجا باید شروع به یادگیری کرد؟
امیدوارم متقاعد شده باشید و بخواهید شروع به یادگیری RL کنید! در زیر برخی از منابعی که میتوانید در سفر RL خود استفاده کنید آورده شدهاست.
یادگیری تقویتی، چاپ دوم: یک مقدمه
این کتاب توسط ساتون و بارتو به طور گسترده مورد استفاده قرار میگیرد و شامل تمام چیزهایی است که شما باید در موردRL بدانید.
این سری از دورهها، که توسط دانشگاه آلبرتا توسعهیافته است، یک منبع عالی است. این کار با اصول اولیه شروع میشود و به شما کمک میکند تا به درستی مفاهیم و الگوریتم های توضیح دادهشده در کتاب را درک کنید. پس از تکمیل این تخصص، میتوانید محیط خود را ایجاد کرده و مشکلات خود را باRL حل کنید.
دوره یادگیری تقویتی | ذهن عمیق وUCL
این مجموعه هایی از سخنرانیهایی از ذهن عمیق (سازندگان الففازیرو) هستند و با اصول اولیه شروع میشوند، اما همچنین در مورد موضوعات پیشرفته صحبت میکنند.
از یادگیری لذت ببرید!
این متن با استفاده از ربات مترجم مقالات دیتاساینس ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
اهمیت Alt Text برای سئو
مطلبی دیگر از این انتشارات
چتبات اپل، تغییردهنده بازی چت جیپیتی
مطلبی دیگر از این انتشارات
گامی به سوی محافظت از بیماران در برابر اشتباهات دارویی