

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
چگونه سری زمانی را تجزیه و تحلیل نکنیم
منتشرشده در: towardsdatascience به تاریخ ۳۰ سپتامبر ۲۰۲۱
لینک منبع How NOT to Analyze Time Series
یکی از رایجترین اشتباهات دادههای سری زمانی که من میبینم دانشمندان دادههای جوان و داوطلبان مصاحبه انجام میدهند این است که فرض کنیم که دادهها تیک منظم دارند و هیچ شکافی ندارند. این فرض بدی است.
به عنوان مثال یک تمرین مصاحبه را در نظر بگیرید که در آن من یک مجموعه داده برای کاندیدا فراهم میکنم که شامل معیارهای دانلود و استفاده چند صد برنامه کاربردی در طول زمان است. من از نامزدها میخواهم که بفهمند کدام یک از برنامهها از نقطهنظر سرمایهگذاری جالب هستند، با این اشاره که رشد به احتمال زیاد شاخص خوبی از جذابیت است. نامزدها اغلب مستقیما به محاسبه نرخ رشد با مقایسه آخرین نقطه برای هر برنامه کاربردی و نقطه قبل از آخرین نقطه، و سپس رتبهبندی برنامهها براساس نرخ رشد محاسبهشده، میپردازند. فرض بر این است که آخرین نقطه داده در هر سری نشاندهنده همان نقطه در زمان است و نقطه قبلی متناظر ۱ واحد زمان با ما فاصله دارد. همانطور که معلوم شد، این در مورد مجموعه دادهای که من ارائه میدهم صادق نیست و منجر به نتایج نادرست میشود. بسیاری از سریهای زمانی در مجموعه داده دارای نقاط داده گمشده هستند و تیکها به طور مساوی یا پیوسته با هم فاصله ندارند. همانطور که در مثال تجسم زیر مشاهده میکنید، یک تحلیل ساده از لحاظ نقطهای که اندازه تیک و فاصله دادهها را مشخص نمیکند مانند مقایسه سیب با پرتقال است.
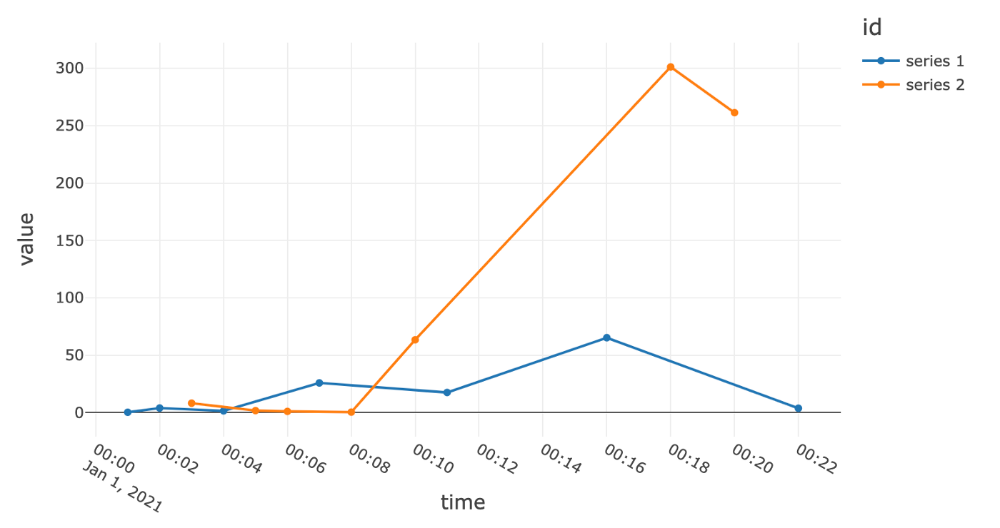
اکثر مجموعه دادههای جهان واقعی از این نوع مساله رنج میبرند، زیرا آنها معمولا با سیستمها و فرآیندهای ناقص که با در نظر گرفتن موارد استفاده تحلیلی طراحی نشدهاند، فرسوده میشوند. بنابراین، مهم است که این معایب در دادهها را درک کنیم و قبل از هر گونه تحلیل یا مدلسازی به درستی آن را در نظر بگیریم. در غیر این صورت به احتمال زیاد منجر به ورودی زباله و خروجی زباله خواهد شد.
پس ما چگونه این کار را برای دادههای سری زمانی انجام میدهیم؟ گامهایی که من معمولا دنبال میکنم عبارتند از:
- محدوده زمانی و دانهبندی تیکهای سریهای زمانی را با بررسی بصری سریهای زمانی مثال درک کنید.
- تعداد واقعی تیکها در هر سری زمانی را با تعداد تیک نظری برگرفته از (حداکثر منهای حداقل زمان نشان) تقسیم بر فاصله تیک مقایسه کنید. گاهی اوقات از این نسبت به عنوان نسبت پر شدن یاد میشود-مقداری بسیار کمتر از ۱ به این معنی است که تعداد زیادی تیک گم شدهاند.
- سریهایی که نسبت پر شدن آنها کم است را فیلتر کنید. من اغلب از ۴۰٪ را به عنوان مقطع محتوای اطلاعات ناکافی استفاده میکنم، اما این ممکن است بسته به وظیفه خاصی که در دست است متفاوت باشد.
- استانداردسازی فاصله تیک در سریهای زمانی با نمونهافزایی تا وضوح بیشتر.
- تیکهای نمونهافزایی شده را با روش درونیابی مناسب برای تجزیه و تحلیل خود پر کنید. به عنوان مثال آخرین مقدار شناختهشده، یا درونیابی خطی/درجهدوم، و غیره را در نظر بگیرید.
در اینجا چند کد نمونه وجود دارد که من این روش استانداردسازی سریهای زمانی را با PySpark پیادهسازی میکنم:
یک نکته قابلتوجه - من از روش applyInPandas در مجموعه دادهPSPark برای درونیابی استفاده میکنم. در اصل این از آنچه به عنوانpandasUDF معروف است استفاده میکند، که باعث افزایش عملکرد عظیم نسبت بهUDFهای معمولی در PySpark میشود. این افزایش عملکرد با انتقال دادههای کارآمدتر از طریق Apache Arrow و محاسبات کارآمدتر از طریق Vectorization Pandas فعال میشود. همیشه سعی کنید هر زمان که میتوانید از pandasUDF استفاده کنید. برای کسب اطلاعات بیشتر به اسناد API مراجعه کنید.
برای ارائه تصویری بیشتر آنچه که در زمان اجرای کد در سریهای زمانی اصلی اتفاق میافتد، در زیر نمودارها در مراحل مختلف فرآیند آورده شده است. امیدوارم این نکته را نشان دهد که هیچکس نمیتواند به سادگی محاسبه معیارهای رشد نقطه به نقطه را بدون عبور از استانداردسازی آغاز کند.
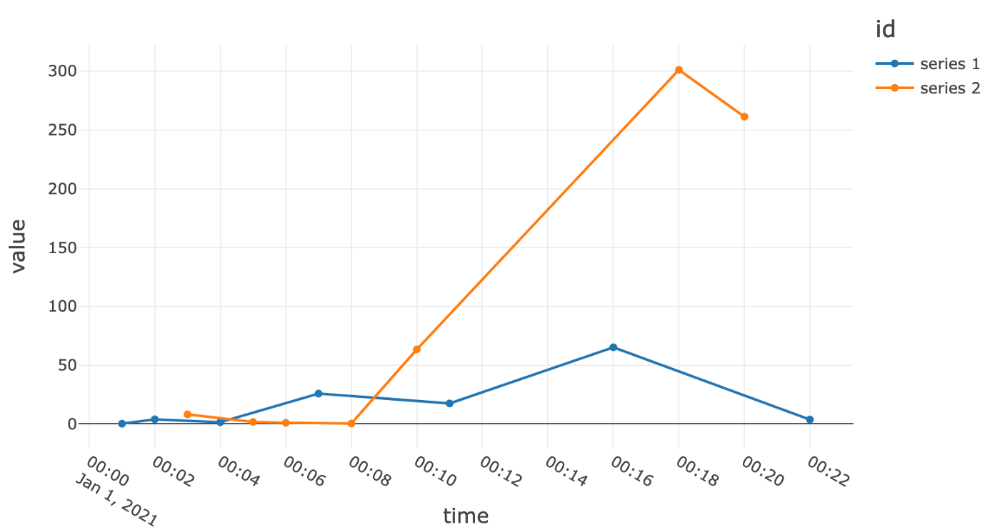
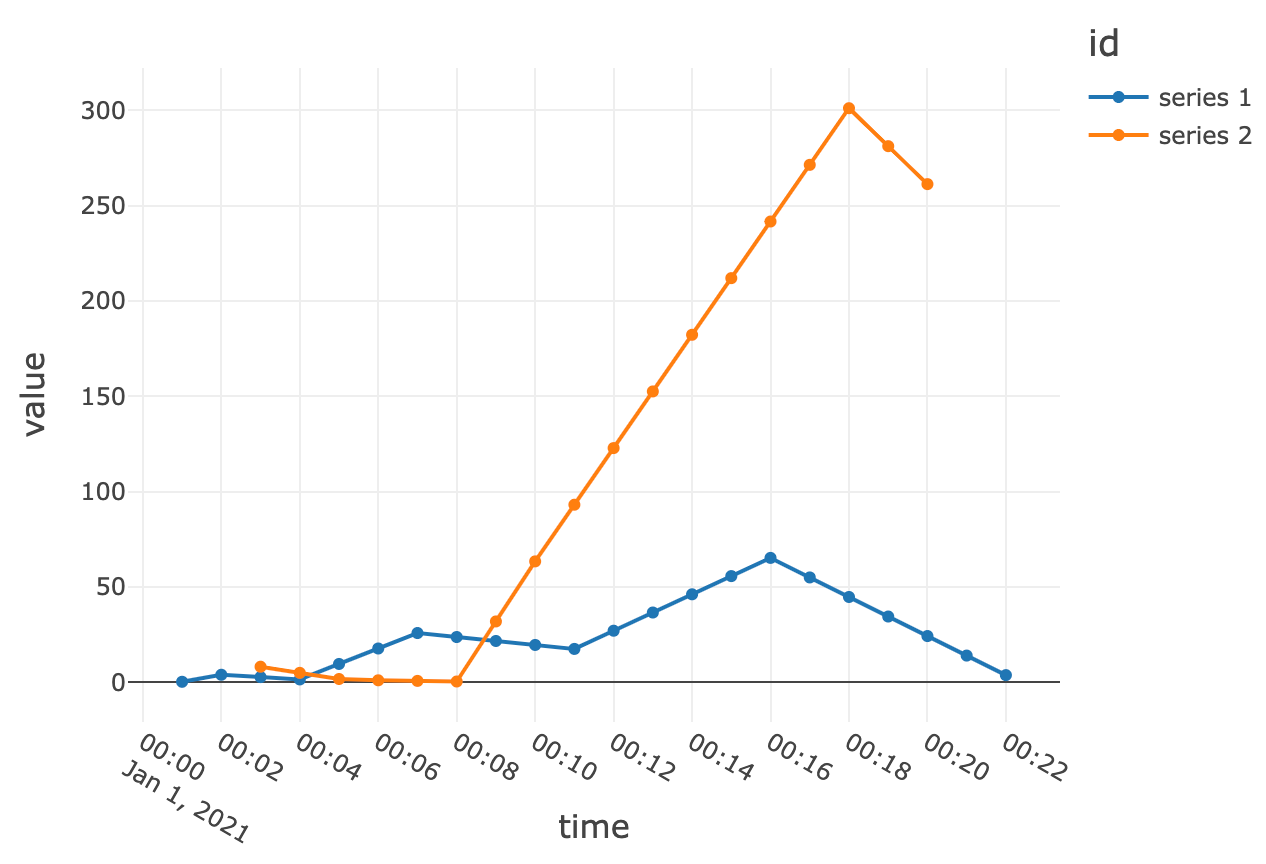
نمونهافزایی به فواصل ۱ دقیقهای و درونیابی با آخرین مقدار شناختهشده، سری زمانی زیر را نتیجه میدهد:
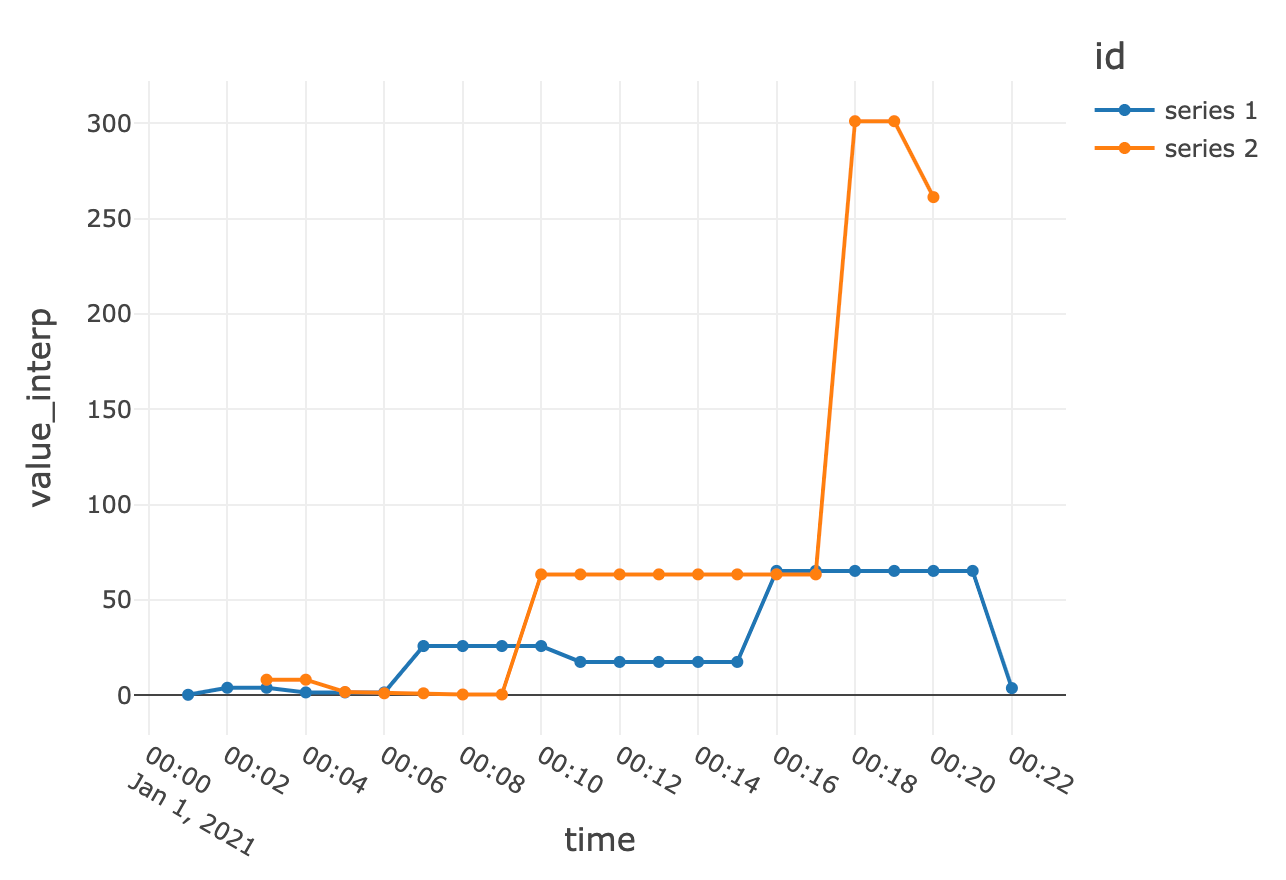
نمونهافزایی و درونیابی خطی در زیر به دست میآیند:
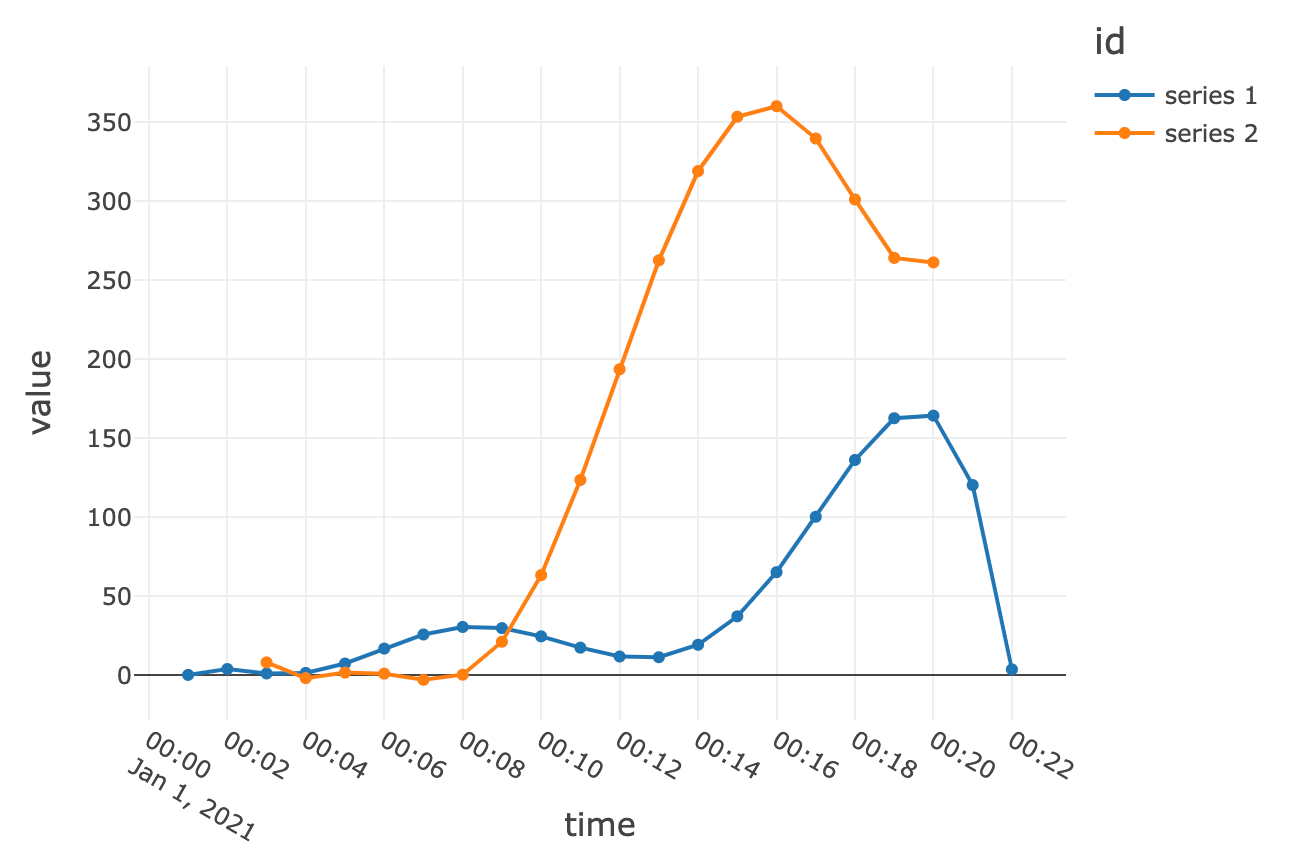
و فقط برای سرگرمی، درونیابی چند جملهای درجه 5
امیدوارم این یک بحث مفید باشد، و من به شما کمک کرده باشم تا از این اشتباه در آینده اجتناب کنید.
این متن با استفاده از ربات ترجمه مقالات علم داده ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
داستانهایی درباره رباتها و هوش مصنوعی که از شکسپیر الهام گرفتهاند
مطلبی دیگر از این انتشارات
سه دلیل برای اینکه COVID19 باعث «هیپوکسی خاموش» شود
مطلبی دیگر از این انتشارات
راهنمای انجام یک آزمایش در مکانیک کوانتومی با نتایج چشمنواز