

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
چگونه شبکههای عصبی عمیق را برای طبقهبندی تصاویر رادار پیادهسازی کنیم

منتشرشده در: towardsdatascience به تاریخ ۶ ژوئن ۲۰۲۱
لینک منبع How to Implement Deep Neural Networks for Radar Image Classification
مقدمه
تشخیص و مکانیابی مبتنی بر رادار افراد و اشیا در محیط خانه مزایای خاصی نسبت به دید کامپیوتری دارد، از جمله افزایش حریم خصوصی کاربر، مصرف برق کم، عملیات نور صفر و قرار دادن سنسور انعطافپذیرتر.
تکنیکهای یادگیری ماشین کمعمق مانند ماشینهای بردار پشتیبان و رگرسیون منطقی را می توان برای طبقهبندی تصاویر از رادار استفاده کرد، و در کار قبلی من، آموزش رادار برای درک خانه و استفاده از تخلیه شعاعهای تصادفی به طبقهبندی کنندههای خطی قطار من برخی از این روشها را به اشتراک گذاشتم.
در این مقاله، شما یاد خواهید گرفت که چگونه شبکههای عصبی عمیق (DNN) را توسعه دهید و آنها را برای طبقهبندی اشیا در تصاویر رادار آموزش دهید. علاوه بر این، شما یاد خواهید گرفت که چگونه از یک شبکه راهنمای عمومی تحت نظارت (SGAN) استفاده کنید [ ۱ ] که تنها به تعداد کمی از دادههای برچسب دار برای آموزش یک طبقهبندی کننده DNN نیاز دارد. این امر در برخورد با مجموعه دادههای رادار به دلیل کمبود مجموعههای آموزشی بزرگ، در مقابل تصاویر مبتنی بر دوربین (به عنوان مثال، ImageNet) که به فراگیر کردن دید کامپیوتری کمک کردهاست، بسیار مهم است.
هر دو DNN ها (یا به طور خاص شبکههای عصبی کانولوشن) و SO هایی که در اصل برای طبقهبندی تصویر بصری توسعهیافته اند را می توان از دیدگاه معماری و روش آموزشی برای استفاده در کاربردهای رادار استفاده کرد.
تنظیم دادهها
به منظور کمک به شما در درک تکنیکها و کدهای استفادهشده در این مقاله، یک گام کوتاه از مجموعه دادهها در این بخش ارائه شدهاست. مجموعه دادهها از نمونههای رادار به عنوان بخشی از پروژه رادار-میلیلیتر جمعآوری شد و در اینجا یافت شد. این پروژه از یادگیری نظارت شده مستقل استفاده میکند که به موجب آن تکنیکهای استاندارد تشخیص شی مبتنی بر دوربین برای برچسب گذاری خودکار اسکنهای رادار افراد و اشیا مورد استفاده قرار میگیرند.
مجموعه دادهها یک فرمان پایتون از این فرم است:
{‘samples’: samples, ‘labels’: labels}
نمونهها لیستی از نمونه های ردیابی N رادار numpy.array در فرم زیر است:
[(xz_0, yz_0, xy_0), (xz_1, yz_1, xy_1),…,(xz_N, yz_N, xy_N)]
که در آن یک تصویر رادار حداکثر قدرت سیگنال بازگشتی یک شی هدف اسکن شده در فضای سهبعدی تصویر شده به محور x، y و z است. این نمایشهای دو بعدی معمولا پراکنده هستند زیرا یک تصویر بخش کوچکی از حجم اسکن شده را اشغال میکند. نمونهبرداری، ذخیرهسازی و استفاده از پیشبینیهای دو بعدی میتواند کارآمدتر از استفاده مستقیم از دادههای منبع سهبعدی باشد.
برچسبها لیستی از برچسبهای کلاس N numpy.array مربوط به هر نمونه طرح رادار از فرم است:
[class_label_0, class_label_1,…,class_label_N]
طرحها از یک نمونه واحد معمولی در تصویرسازی نقشه حرارتی در زیر نشانداده شدهاست. قرمز نشان میدهد که سیگنال بازگشت کجا قویتر است.
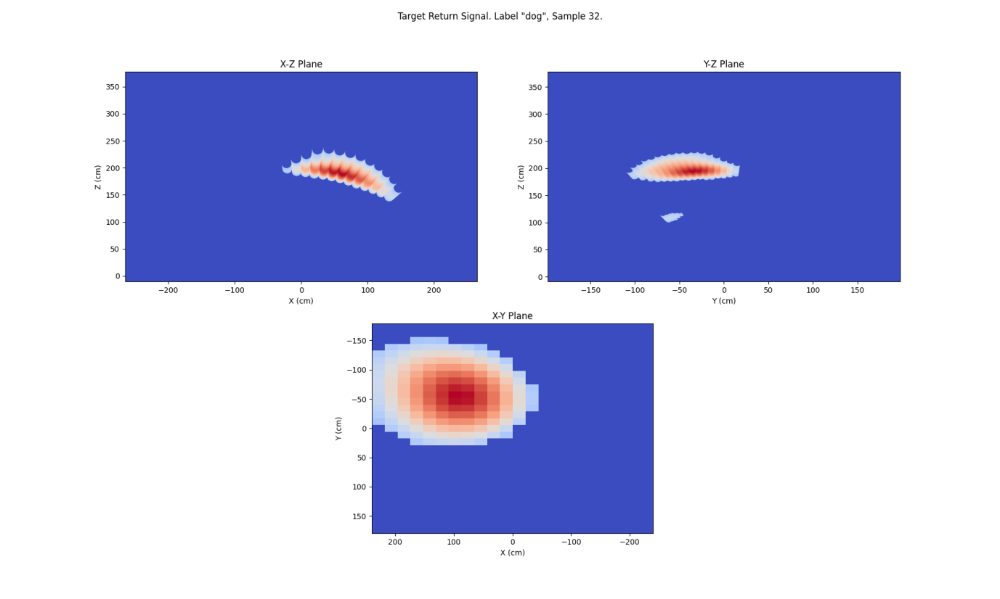
این دادهها در خانه من در مکانهای مختلف طراحی شدهبرای حداکثر کردن تنوع در اشیا کشفشده (در حال حاضر فقط مردم، سگها و گربهها) ، فاصله و زاویه از سنسور رادار گرفته شدهاست.
مجموعه داده تنها شامل چند هزار نمونه است (با خطاهای برچسب زدن شناختهشده) و تنها میتواند برای آموزش یک شبکه عصبی عمیق برای تعداد کمی از دورهها قبل از تکمیل به کار رود. خطای برچسبگذاری بر دقت طبقهبندی کننده رادار آموزشدیده از این مجموعه داده تاثیر خواهد گذاشت. در حالی که تلاش آینده برای تنظیم دقیق آشکارساز شی برای کاهش خطا تلاش خواهد کرد، استفاده از SGAN ممکن است نیاز به برچسب زدن مشاهدات آینده رادار را مرتفع یا حداقل کند. کاهش تعداد نقاط داده برچسبگذاری شده برای آموزش یک طبقهبندی کننده، در حالی که دقت قابل قبولی را حفظ میکند، انگیزه اصلی برای کشف استفاده از SOF ها در این پروژه بود.
معماری مدل
همانطور که در بالا اشاره شد، مجموعه دادهها شامل مجموعهای از نمایشهای دو بعدی از یک تصویر رادار سهبعدی است و خوشبختانه، کارهای قبلی از دنیای دید کامپیوتری در نشان دادن امکان طراحی و آموزش شبکههای عصبی بر روی چنین نمایشهای دو بعدی وجود دارد که با شبکههای خارجی آموزشدیده بر روی مجموعه داده سهبعدی بومی مطابقت دارند، [ ۲ ] و [ ۳ ]. این کار قبلی الهامبخش توسعه شبکههای زیر بود.
همه مدلها و آموزشهای مربوطه با استفاده از Keras API، API سطح بالا از tensorFlow به عنوان بخشی از پروژه رادار-میلیلیتر اجرا شدند.
طبقهبندی کننده شبکه عصبی عمیق (DNN)
اگر چه یک انسان قادر به تشخیص آن نیست، اما جمعآوری تصاویر رادار دو بعدی شامل ویژگیهایی است که نقشه را به شی اسکن شده برمی گرداند. هر یک از سه تصویر دو بعدی از طریق لایههای کانولوشن دو بعدی جداگانه عبور داده میشوند که این ویژگیها را یاد میگیرند و به طور موفقیت آمیزی تصویر را نمونه میگیرند. خروجی از این لایهها بهم پیوسته و سپس مسطح میشوند تا یک بردار از ویژگیهای واحد را تشکیل دهند که به عنوان ورودی به لایههای متراکم متصل عمیق و به دنبال آن یک لایه طبقهبندی استفاده میشود. این معماری در شکل زیر نشانداده شدهاست. ممکن است متوجه شوید که یک شاخه از این معماری شبیه به یک شبکه عصبی کانولوشن (CNN) است که در بینایی کامپیوتر استفاده میشود.
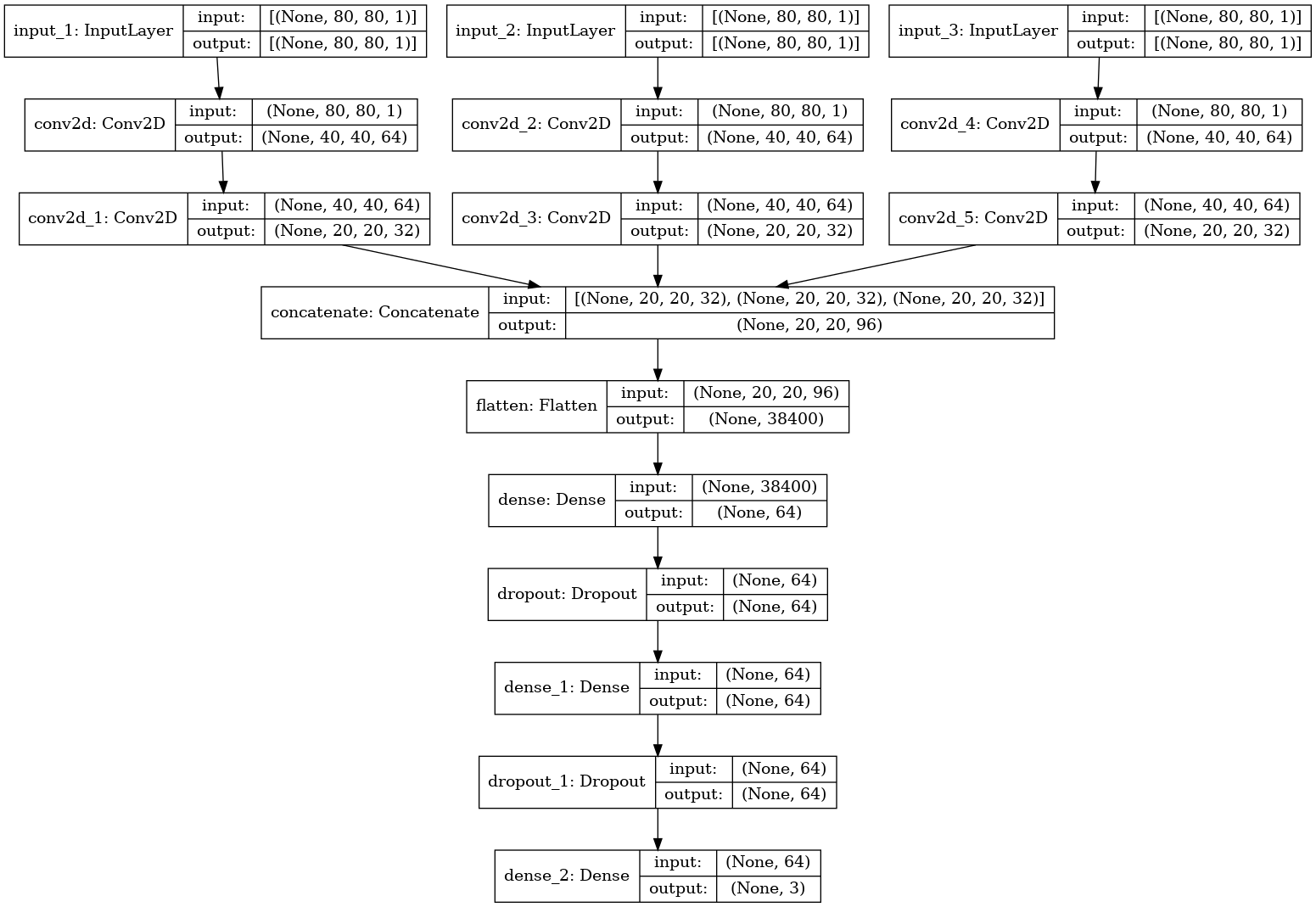
این مدل توسط مدول پایتون در فایل dnn.py در مخزن radar-ml پیادهسازی میشود. شما میتوانید کد را ببینید که مدل زیر را تعریف و تدوین میکند.
def create_conv_layers(input):
"""Creates convolutional layers."""
input_shape = input.shape[1:]
conv = tf.keras.layers.Conv2D(64, (3, 3), strides=(
2, 2), padding='same', activation='relu', input_shape=input_shape)(input)
conv = tf.keras.layers.Conv2D(
32, (3, 3), strides=(2, 2), padding='same', activation='relu')(conv)
return conv
def define_classifier(xz_shape, yz_shape, xy_shape, n_classes):
"""Define classifier model.
Args:
xz_shape, yz_shape, xy_shape (tuple): Shapes of radar projections.
n_classes (int): Number of classes for model.
Returns:
model (Keras object): Classifier model.
Note:
Input ordering is xz, yz, xy.
"""
# Make convolutional layers for each radar projection.
xz_input = tf.keras.layers.Input(shape=xz_shape)
xz_conv = create_conv_layers(xz_input)
yz_input = tf.keras.layers.Input(shape=yz_shape)
yz_conv = create_conv_layers(yz_input)
xy_input = tf.keras.layers.Input(shape=xy_shape)
xy_conv = create_conv_layers(xy_input)
# Concat convolutions.
conv = tf.keras.layers.concatenate([xz_conv, yz_conv, xy_conv])
# Create a feature vector.
fv = tf.keras.layers.Flatten()(conv)
# Create dense layers and operate on the feature vector.
dense = tf.keras.layers.Dense(64, activation='relu')(fv)
dense = tf.keras.layers.Dropout(0.5)(dense)
dense = tf.keras.layers.Dense(64, activation='relu')(dense)
dense = tf.keras.layers.Dropout(0.5)(dense)
# Classifier.
cls = tf.keras.layers.Dense(units=n_classes, activation='softmax')(dense)
# Create model and compile it.
model = tf.keras.Model(
inputs=[xz_input, yz_input, xy_input], outputs=[cls])
model.compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Adam(
lr=0.0002, beta_1=0.5), metrics=['accuracy'])
return model
شبکه تبلیغاتی عمومی با نظارت همهجانبه (SGAN)
جمعآوری تصاویر رادار برای آموزش مدل در مقایسه با ایجاد حقیقت زمینی که به یک انسان در حلقه نیاز دارد، یادگیری نظارت شده مستقل، یا یک تکنیک مانند Semi-Supervised که مقدار کمی از دادههای برچسبدار را با مقدار زیادی از دادههای برچسبدار نشده در طول آموزش ترکیب میکند، نسبتا ساده است. انگیزه استفاده از Semi-Supervised به حداقل رساندن تلاش مربوط به برچسب زدن اسکنهای رادار انسانها یا استفاده از یادگیری نظارت شده مستقل پیچیده (و احتمالا مستعد خطا) بود.
شبکه استنتاج عمومی (GAN) یک معماری است که از مجموعه دادههای بدون برچسب برای آموزش یک مدل تولید کننده تصویر همراه با یک مدل تشخیص دهنده تصویر استفاده میکند. در برخی موارد میتوانید از مدل متمایزکننده برای توسعه یک مدل طبقهبندی کننده استفاده کنید. GANها در تولید سیگنال رادار مورد استفاده قرار گرفتهاند [ ۴ ] و کاربرد گستردهای در کاربردهای بینایی کامپیوتری یافتهاند [ ۵ ].
مدل Semi-Supervised GAN (SGAN) تعمیمی از معماری GAN است که از آموزش مشترک یک تبعیدکننده تحت نظارت، تبعیدکننده بدون نظارت، و یک مدل ژنراتور استفاده میکند. در این پروژه، از تفکیککننده نظارت شده به عنوان یک مدل طبقهبندی استفاده میشود که به مجموعه دادههای جدید و یک مدل ژنراتور تعمیم داده میشود که نمونههای واقع گرایانه از پیشبینیهای رادار را نتیجه میدهد (که تنها به عنوان بررسی اعتبار استفاده میشود).
معماری تبعیض کننده تحت نظارت در شکل زیر نشانداده شدهاست و شما ممکن است متوجه شباهت آن با معماری DNN که در آن نزدیکی نشانداده شدهاست شوید، با برخی استثناها از جمله استفاده از LeakyReLU (واحد خطی با کیفیت پایین) به جای ReLU که بهترین تمرین GAN است [ ۷ ]. این مدل شامل لایههای Batch Normalization برای کمک به همگرایی آموزشی است که اغلب یک مشکل در آموزش GAN است [ ۶ ]. تبعیضگر بدون نظارت بیشتر لایهها را به جز لایههای خروجی نهایی به اشتراک میگذارد و بنابراین معماری بسیار مشابهی دارد. خروجی تبعیض کننده نظارت شده یک لایه متراکم با فعال سازی softmax است که یک طبقهبندی کننده 3-class را تشکیل میدهد در حالی که مدل بدون نظارت خروجی مدل تحت نظارت را قبل از فعالسازی softmax میگیرد، و سپس یک مقدار نرمال از خروجیهای نمایی را محاسبه میکند [6]
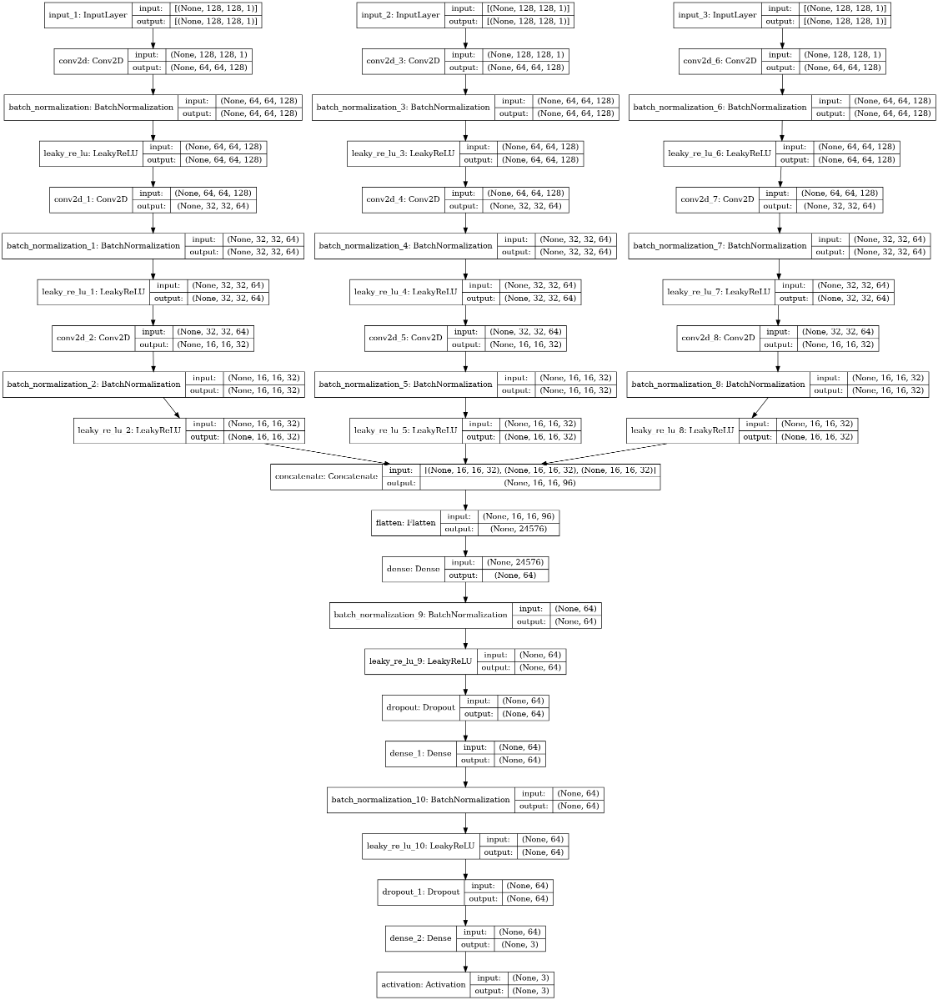
هر دو مدل تفکیککننده تحت نظارت و بدون نظارت توسط ماژول پایتون در فایل sgan.py در مخزن radar-ml پیادهسازی میشوند. یک کد که مدل زیر را تعریف و تدوین میکند.
def custom_activation(output):
"""Custom activation function for discriminator."""
logexpsum = tf.keras.backend.sum(
tf.keras.backend.exp(output), axis=-1, keepdims=True)
return logexpsum / (logexpsum + 1.0)
def create_d_conv_layers(input, init):
"""Creates discriminator conv layers."""
input_shape = input.shape[1:]
# Downsample to 64x64.
conv = tf.keras.layers.Conv2D(128, (3, 3), strides=(
2, 2), padding='same', input_shape=input_shape, kernel_initializer=init)(input)
conv = tf.keras.layers.BatchNormalization()(conv)
conv = tf.keras.layers.LeakyReLU(alpha=0.2)(conv)
# Downsample to 32x32.
conv = tf.keras.layers.Conv2D(64, (3, 3), strides=(
2, 2), padding='same', kernel_initializer=init)(conv)
conv = tf.keras.layers.BatchNormalization()(conv)
conv = tf.keras.layers.LeakyReLU(alpha=0.2)(conv)
# Downsample to 16x16.
conv = tf.keras.layers.Conv2D(32, (3, 3), strides=(
2, 2), padding='same', kernel_initializer=init)(conv)
conv = tf.keras.layers.BatchNormalization()(conv)
conv = tf.keras.layers.LeakyReLU(alpha=0.2)(conv)
return conv
def define_discriminator(xz_shape, yz_shape, xy_shape, n_classes):
"""Define supervised and unsupervised discriminator models.
Args:
xz_shape, yz_shape, xy_shape (tuple): Shapes of radar projections.
n_classes (int): Number of classes for supervised disc model.
Returns:
d_model (Keras object): Unsupervised discriminator model.
c_model (Keras object): Supervised discriminator model.
Note:
Input ordering is xz, yz, xy.
"""
init = tf.keras.initializers.RandomNormal(mean=0.0, stddev=0.02)
# Create conv layers for each radar projection.
xz_input = tf.keras.layers.Input(shape=xz_shape)
xz_model = create_d_conv_layers(xz_input, init)
yz_input = tf.keras.layers.Input(shape=yz_shape)
yz_model = create_d_conv_layers(yz_input, init)
xy_input = tf.keras.layers.Input(shape=xy_shape)
xy_model = create_d_conv_layers(xy_input, init)
# Concat convolutions.
conv = tf.keras.layers.concatenate([xz_model, yz_model, xy_model])
# Flatten to get feature vector.
fv = tf.keras.layers.Flatten()(conv)
# Pass feature vector to dense layers.
dense = tf.keras.layers.Dense(64, kernel_initializer=init)(fv)
dense = tf.keras.layers.BatchNormalization()(dense)
dense = tf.keras.layers.LeakyReLU(alpha=0.2)(dense)
dense = tf.keras.layers.Dropout(0.5)(dense)
dense = tf.keras.layers.Dense(64, kernel_initializer=init)(dense)
dense = tf.keras.layers.BatchNormalization()(dense)
dense = tf.keras.layers.LeakyReLU(alpha=0.2)(dense)
dense = tf.keras.layers.Dropout(0.5)(dense)
# Classifier.
cls = tf.keras.layers.Dense(n_classes, kernel_initializer=init)(dense)
# Supervised output.
c_out_layer = tf.keras.layers.Activation('softmax')(cls)
# Define and compile supervised discriminator model.
c_model = tf.keras.Model(inputs=[xz_input, yz_input, xy_input],
outputs=[c_out_layer], name='classifier')
c_model.compile(loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Adam(
lr=0.0002, beta_1=0.5), metrics=['accuracy'])
# Unsupervised output.
d_out_layer = tf.keras.layers.Lambda(custom_activation)(cls)
# Define and compile unsupervised discriminator model.
d_model = tf.keras.Model(inputs=[xz_input, yz_input, xy_input], outputs=[
d_out_layer], name='discriminator')
d_model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(lr=0.0002, beta_1=0.5))
return d_model, c_model
کد پایتون Snippet برای ایجاد تبعیضگران تحت نظارت و نظارت نشده
مدل مولد یک بردار را از فضای نهفته میگیرد (یک بردار نویز که از یک توزیع نرمال استاندارد گرفته شدهاست) و از سه شاخه لایههای کانولوشن انتقالی با فعالسازی ReLU به طور موفقیت آمیزی نمونهبردار فضای پنهان برای تشکیل هر یک از سه تصویر رادار استفاده میکند. ژنراتور در بالای مدل تفکیککننده روی هم سوار میشود و با وزن نهایی ثابت آموزش داده میشود. این معماری ترکیبی در شکل زیر نشانداده شدهاست. به استفاده از لایههای Batch Normalization برای کمک به همگرایی آموزش مدل توجه کنید.
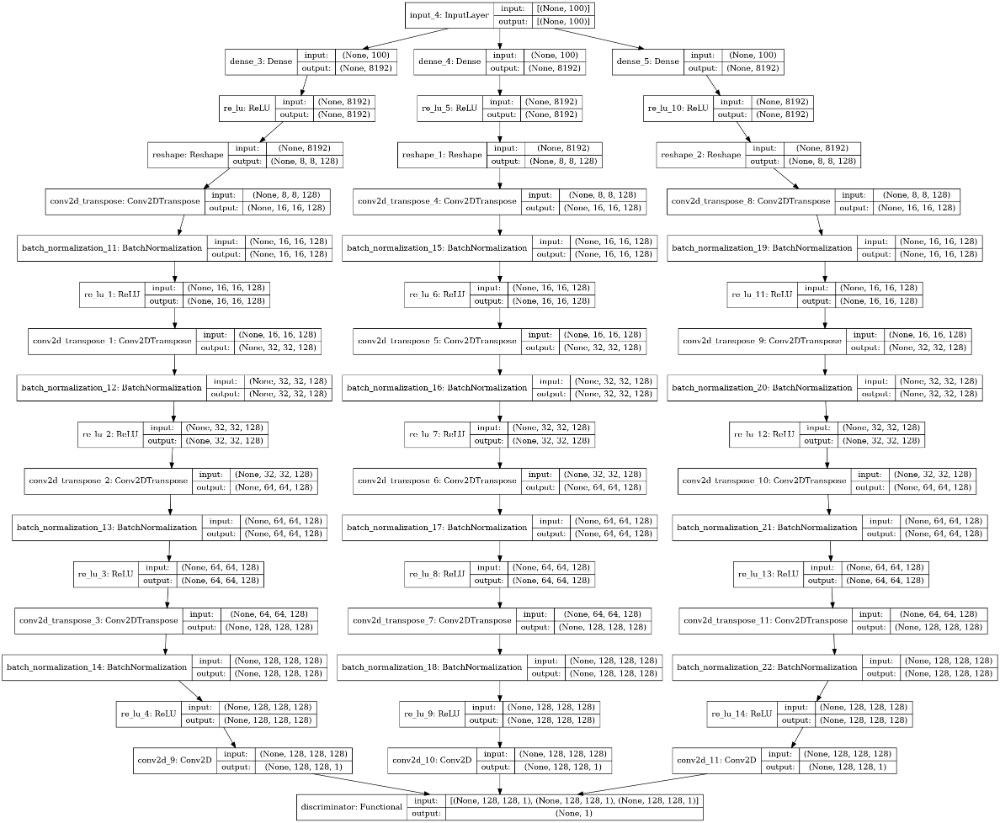
ژنراتور و GAN توسط ماژول پایتون در فایل sgan.py در مخزن radar-ml پیادهسازی میشوند. در زیر یک کد که مدل را تعریف و تدوین میکند، آمدهاست.
def create_g_conv_layers(input, init):
"""Creates generator convolutional layers."""
n_nodes = 8 * 8 * 128
conv = tf.keras.layers.Dense(n_nodes, kernel_initializer=init)(input)
conv = tf.keras.layers.ReLU()(conv)
conv = tf.keras.layers.Reshape((8, 8, 128))(conv)
# Upsample to 16x16.
conv = tf.keras.layers.Conv2DTranspose(
128, (4, 4), strides=(2, 2), padding='same', kernel_initializer=init)(conv)
conv = tf.keras.layers.BatchNormalization()(conv)
conv = tf.keras.layers.ReLU()(conv)
# Upsample to 32x32.
conv = tf.keras.layers.Conv2DTranspose(
128, (4, 4), strides=(2, 2), padding='same', kernel_initializer=init)(conv)
conv = tf.keras.layers.BatchNormalization()(conv)
conv = tf.keras.layers.ReLU()(conv)
# Upsample to 64x64.
conv = tf.keras.layers.Conv2DTranspose(
128, (4, 4), strides=(2, 2), padding='same', kernel_initializer=init)(conv)
conv = tf.keras.layers.BatchNormalization()(conv)
conv = tf.keras.layers.ReLU()(conv)
# Upsample to 128x128.
conv = tf.keras.layers.Conv2DTranspose(
128, (4, 4), strides=(2, 2), padding='same', kernel_initializer=init)(conv)
conv = tf.keras.layers.BatchNormalization()(conv)
conv = tf.keras.layers.ReLU()(conv)
# Single filter conv with tanh activation to make data fall in [-1, 1]
conv = tf.keras.layers.Conv2D(1, (7, 7), activation='tanh', padding='same',
kernel_initializer=init)(conv)
return conv
def define_generator(latent_dim=100):
"""Define the standalone generator model.
Args:
latent_dim (int): Latent space dimension,
e.g. a 100-element vector of Gaussian random numbers.
Returns:
model (Keras object): Generator model.
Note:
Model output is a list of xz, yz, xy generated radar projections
each with shape (n_batch, 128, 128, 1) with values in [-1,1]
"""
init = tf.keras.initializers.RandomNormal(mean=0.0, stddev=0.02)
input = tf.keras.layers.Input(shape=(latent_dim,))
# Create convolutional layers per projection.
xz_conv = create_g_conv_layers(input, init)
yz_conv = create_g_conv_layers(input, init)
xy_conv = create_g_conv_layers(input, init)
# Define model.
out = [xz_conv, yz_conv, xy_conv]
model = tf.keras.Model(inputs=input, outputs=out, name='generator')
return model
def define_gan(g_model, d_model):
"""Define combined generator and discriminator model for updating the generator."""
# Make weights in the discriminator not trainable.
for layer in d_model.layers:
if not isinstance(layer, tf.keras.layers.BatchNormalization):
layer.trainable = False
# Connect image output from generator as input to discriminator.
gan_output = d_model(g_model.output)
# Define gan model as taking noise and outputting a classification.
model = tf.keras.Model(inputs=g_model.input,
outputs=gan_output, name='gan')
# Compile model.
opt = tf.keras.optimizers.Adam(lr=0.0002, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=opt)
return model
آموزش مدل و نتایج
روش DNN
روش DNN از طریق روش تناسب کلاس tf.keras.mode آموزش داده میشود و توسط ماژول پایتون در فایل dnn.py در مخزن radar-ml پیادهسازی میشود. در زیر مجموعه کد تابع آموزش نشانداده نشده است که مراحل مورد نیاز برای پیش پردازش و فیلتر دادهها را نشان میدهد.
def train(model, X, y, X_val, y_val, w_classes):
"""Train model, save best model and log summary.
Args:
model (Keras object): dnn model to be trained.
X (numpy array): Training data, 4-D numpy array.
y (numpy array): Training data labels.
X_val (numpy array): Validation data, 4-D numpy array.
y_val (numpy array): Validation data labels.
w_classes (dict): Class weights.
"""
early_stop = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
mode='min',
verbose=1,
patience=10
)
fp = os.path.join(args.results_dir, 'c_model.h5')
model_ckpt = tf.keras.callbacks.ModelCheckpoint(
filepath=fp,
monitor='val_loss',
verbose=1,
save_best_only=True
)
X_train = [X[..., 0], X[..., 1], X[..., 2]]
X_val = [X_val[..., 0], X_val[..., 1], X_val[..., 2]]
hist = model.fit(
x=X_train,
y=y,
batch_size=64,
epochs=100,
validation_data=(X_val, y_val),
class_weight=w_classes,
callbacks=[early_stop, model_ckpt]
)
best_val_loss = min(hist.history['val_loss'])
best_val_loss_idx = hist.history['val_loss'].index(best_val_loss)
best_val_acc = hist.history['val_accuracy'][best_val_loss_idx]
best_loss = hist.history['loss'][best_val_loss_idx]
best_acc = hist.history['accuracy'][best_val_loss_idx]
logger.info(f'Best loss: {best_loss:.4f}, Best acc: {best_acc*100:.2f}%')
logger.info(
f'Best val loss: {best_val_loss:.4f}, Best val acc: {best_val_acc*100:.2f}%')
logger.info(f'Saved best model to {args.results_dir}')
نتایج حاصل از یک اجرای آموزشی معمولی در زیر آورده شدهاست. وضعیت فعلی مدل و مجموعه دادهها قادر به به دست آوردن دقت مجموعه اعتبارسنجی در میانه تا بالای ۸۰٪ s است. کارهای بیشتری برای مطابقت یا تجاوز از دقت ۹۰٪ بهدستآمده توسط مدلهای رگرسیون منطقی و SVM در کار قبلی مورد نیاز است [ ۸ ] [ ۹ ]. این تمرکز تلاشهای آینده خواهد بود.
2021-05-27 19:48:31,268 __main__ INFO Opening dataset: datasets/radar_samples_25Nov20.pickle
2021-05-27 19:48:31,284 __main__ INFO Opening dataset: datasets/radar_samples_22Feb21.pickle
2021-05-27 19:48:31,293 __main__ INFO Opening dataset: datasets/radar_samples_26Feb21.pickle
2021-05-27 19:48:31,303 __main__ INFO Opening dataset: datasets/radar_samples_28Feb21.pickle
2021-05-27 19:48:31,312 __main__ INFO Opening dataset: datasets/radar_samples_19Oct20.pickle
2021-05-27 19:48:31,313 __main__ INFO Opening dataset: datasets/radar_samples_20Sep20.pickle
2021-05-27 19:48:31,343 __main__ INFO Opening dataset: datasets/radar_samples_20Oct20.pickle
2021-05-27 19:48:31,344 __main__ INFO Opening dataset: datasets/radar_samples_31Oct20.pickle
2021-05-27 19:48:31,354 __main__ INFO Using aliased class names.
2021-05-27 19:48:31,355 __main__ INFO Maybe filtering data set.
2021-05-27 19:48:31,356 __main__ INFO Scaling samples.
2021-05-27 19:48:31,458 __main__ INFO Encoding labels.
2021-05-27 19:48:31,460 __main__ INFO Found 3 classes and 4868 samples:
2021-05-27 19:48:31,460 __main__ INFO ...class: 0 "cat" count: 450
2021-05-27 19:48:31,460 __main__ INFO ...class: 1 "dog" count: 1952
2021-05-27 19:48:31,460 __main__ INFO ...class: 2 "person" count: 2466
2021-05-27 19:48:31,460 __main__ INFO Class weights: {2: 1.0, 1: 1.26, 0: 5.48}
2021-05-27 19:48:32,534 __main__ INFO Creating model.
2021-05-27 19:48:33,326 __main__ INFO Training model.
2021-05-27 19:49:20,861 __main__ INFO Best loss: 0.6730, Best acc: 84.18%
2021-05-27 19:49:20,862 __main__ INFO Best val loss: 0.4657, Best val acc: 83.47%
2021-05-27 19:49:20,862 __main__ INFO Saved best model to ./train-results/dnn
روش SGAN
شبکههای تبلیغاتی عمومی، یا شبکهها، آموزش را به چالش میکشند. این به این دلیل است که معماری شامل یک ژنراتور و یک مدل متمایزکننده است که در یک بازی مجموع صفر رقابت میکند. این بدان معنی است که بهبود یک مدل به قیمت کاهش عملکرد در مدل دیگر انجام میشود. نتیجه یک فرآیند آموزشی بسیار ناپایدار است که اغلب میتواند منجر به شکست شود، به عنوان مثال، یک ژنراتور که تصویر یکسانی را در تمام مدت تولید میکند و یا چیزهای احمقانه تولید میکند. به این ترتیب، تعدادی شیوه اکتشافی یا بهترین شیوه وجود دارد که میتواند در پیکربندی و آموزش مدلهای GAN شما مورد استفاده قرار گیرد. این شیوههای اکتشافی به سختی توسط کارشناسان تست و ارزیابی صدها یا هزاران ترکیب از عملیات پیکربندی در طیف وسیعی از مشکلات در طول سالها به دست آمدهاست.
«شبکههای ارتباطی عمومی با پایتون»، جیسون براونلی، ۲۰۲۱.
شما میتوانید مقالات خوب زیادی پیدا کنید که به شما کمک میکند بفهمید چگونه بهترین شیوهها را برای آموزش به اوگاندا به کار ببرید. به طور خاص، جیسون براولی مقالات عملی بسیاری را منتشر کردهاست که میتوانند صرفهجویی در زمان را اثبات کنند [ ۷ ]. برخی از این کار برای تعیین یک روش آموزشی که به خوبی بر روی مدلهای رادار SGAN و مجموعه دادهها کار میکرد، مورد استفاده قرار گرفت. خواندن مقالات آنلاین او را در نظر بگیرید و کتابهای الکترونیکی او را بخرید اگر در مورد درک و استفاده از یادگیری ماشینی جدی هستید.
حلقه آموزش توسط ماژول پیتون در فایل sgan.py در مخزن radar-ml اجرا میشود. در زیر خلاصهای از حلقه آموزشی آورده شدهاست که مراحل مورد نیاز برای پیش پردازش و فیلتر مجموعه دادهها و همچنین چندین تابع کمکی را نشان نمیدهد. این کد براساس مرجع [ ۷ ] میباشد. توجه داشته باشید که مدل تفکیککننده با ۵ / ۱ دسته نمونه بهروزرسانی میشود اما مدل ژنراتور با یک دسته نمونه در هر تکرار بهروزرسانی میشود.
def train(g_model, d_model, c_model, gan_model,
train_set, val_set, n_classes, w_classes=None,
latent_dim=100, n_epochs=15, n_batch=32,
):
"""Train the generator and discriminator."""
# Select supervised dataset.
X_sup, y_sup = select_supervised_samples(train_set, n_classes=n_classes)
# Calculate the number of batches per training epoch.
bat_per_epo = int(train_set[0].shape[0] / n_batch)
# Calculate the number of training iterations.
n_steps = bat_per_epo * n_epochs
# Calculate the size of half a batch of samples.
half_batch = int(n_batch / 2)
logger.info(f'Starting training loop.')
logger.info('n_epochs=%d, n_batch=%d, 1/2=%d, b/e=%d, steps=%d' %
(n_epochs, n_batch, half_batch, bat_per_epo, n_steps))
# Manually enumerate epochs.
for i in range(n_steps):
# Update supervised discriminator (c).
[Xsup_real, ysup_real], _ = generate_real_samples(
[X_sup, y_sup], half_batch)
c_loss, c_acc = c_model.train_on_batch(
[Xsup_real[..., 0], Xsup_real[..., 1], Xsup_real[..., 2]], ysup_real)
# Update unsupervised discriminator (d).
[X_real, _], y_real = generate_real_samples(train_set, half_batch)
dr_loss = d_model.train_on_batch(
[X_real[..., 0], X_real[..., 1], X_real[..., 2]], y_real, class_weight=w_classes)
X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
df_loss = d_model.train_on_batch(X_fake, y_fake)
# Update generator (g).
X_gan, y_gan = generate_latent_points(
latent_dim, n_batch), np.ones((n_batch, 1))
y_gan = smooth_positive_labels(y_gan)
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# Summarize loss and acc on this batch.
logger.debug('Training results at step %d: c[%.3f,%.0f], d_r[%.3f], d_f[%.3f], g[%.3f]' %
(i+1, c_loss, c_acc*100, dr_loss, df_loss, g_loss))
# Evaluate the model performance every so often.
if (i+1) % (bat_per_epo * 1) == 0:
summarize_performance(i, g_model, c_model, latent_dim, val_set)
کد پایتون Snippet حلقه آموزشی SGAN
شما متوجه خواهید شد که نتایج آموزش از اجرا تا اجرا به دلیل طبیعت تصادفی GAN متفاوت است، بنابراین بهترین تا میانگین نتایج آن بیش از چند اجرا است. یک جلسه آموزشی خوب دارای تلفات متوسط (~ ۰.۵) و نسبتا پایدار برای تبعیضگر و ژنراتور بدون نظارت خواهد بود در حالی که تبعیضگر تحت نظارت به یک تلفات بسیار کم (* ۰.۱) با دقت بالا (* ۹۵٪) در مجموعه آموزشی همگرا خواهد شد. نتایج دقت در مجموعه اعتبارسنجی تمایل دارد که در 70٪ پایین و بالا باشد و تلفات در حدود 1.2 باشد و فقط از 50 نمونه نظارت شده در هر کلاس استفاده شود. این یک نتیجه امیدوار کننده است اما به وضوح کار مدلسازی و جمعآوری دادهها برای به دست آوردن دقت اعتبار همانند دیگر روشهای یادگیری ماشین که بر روی این مجموعه داده به کار گرفته شدهاند، که معمولا ۹۰٪ بودند، نیاز است. این تمرکز کار آینده بر روی این پروژه خواهد بود. نتایج آموزش معمول در زیر نشانداده شدهاست.
2021-05-16 18:52:02,471 __main__ INFO Opening dataset: datasets/radar_samples_25Nov20.pickle
2021-05-16 18:52:02,488 __main__ INFO Opening dataset: datasets/radar_samples_22Feb21.pickle
2021-05-16 18:52:02,496 __main__ INFO Opening dataset: datasets/radar_samples_26Feb21.pickle
2021-05-16 18:52:02,507 __main__ INFO Opening dataset: datasets/radar_samples_28Feb21.pickle
2021-05-16 18:52:02,516 __main__ INFO Opening dataset: datasets/radar_samples_19Oct20.pickle
2021-05-16 18:52:02,517 __main__ INFO Opening dataset: datasets/radar_samples_20Sep20.pickle
2021-05-16 18:52:02,548 __main__ INFO Opening dataset: datasets/radar_samples_20Oct20.pickle
2021-05-16 18:52:02,548 __main__ INFO Opening dataset: datasets/radar_samples_31Oct20.pickle
2021-05-16 18:52:02,559 __main__ INFO Using aliased class names.
2021-05-16 18:52:02,560 __main__ INFO Maybe filtering data set.
2021-05-16 18:52:02,561 __main__ INFO Scaling samples.
2021-05-16 18:52:02,664 __main__ INFO Encoding labels.
2021-05-16 18:52:02,665 __main__ INFO Found 3 classes and 4868 samples:
2021-05-16 18:52:02,665 __main__ INFO ...class: 0 "cat" count: 450
2021-05-16 18:52:02,665 __main__ INFO ...class: 1 "dog" count: 1952
2021-05-16 18:52:02,665 __main__ INFO ...class: 2 "person" count: 2466
2021-05-16 18:52:02,665 __main__ INFO Class weights: {'person': 1.0, 'dog': 1.26, 'cat': 5.48}
2021-05-16 18:52:06,408 __main__ INFO Starting training loop.
2021-05-16 18:52:06,408 __main__ INFO n_epochs=15, n_batch=32, 1/2=16, b/e=231, steps=3465
2021-05-16 18:54:18,073 __main__ INFO Classifier accuracy at step 231: 41.13%
2021-05-16 18:54:18,259 __main__ INFO Saved: ./train-results/sgan/generated_data_0231.pickle, ./train-results/sgan/g_model_0231.h5, and ./train-results/sgan/c_model_0231.h5
2021-05-16 18:55:06,900 __main__ INFO Classifier accuracy at step 462: 40.30%
2021-05-16 18:55:07,051 __main__ INFO Saved: ./train-results/sgan/generated_data_0462.pickle, ./train-results/sgan/g_model_0462.h5, and ./train-results/sgan/c_model_0462.h5
2021-05-16 18:55:55,783 __main__ INFO Classifier accuracy at step 693: 61.81%
2021-05-16 18:55:55,933 __main__ INFO Saved: ./train-results/sgan/generated_data_0693.pickle, ./train-results/sgan/g_model_0693.h5, and ./train-results/sgan/c_model_0693.h5
2021-05-16 18:56:44,293 __main__ INFO Classifier accuracy at step 924: 64.42%
2021-05-16 18:56:44,444 __main__ INFO Saved: ./train-results/sgan/generated_data_0924.pickle, ./train-results/sgan/g_model_0924.h5, and ./train-results/sgan/c_model_0924.h5
2021-05-16 18:57:33,531 __main__ INFO Classifier accuracy at step 1155: 73.38%
2021-05-16 18:57:33,724 __main__ INFO Saved: ./train-results/sgan/generated_data_1155.pickle, ./train-results/sgan/g_model_1155.h5, and ./train-results/sgan/c_model_1155.h5
2021-05-16 18:58:22,376 __main__ INFO Classifier accuracy at step 1386: 59.88%
2021-05-16 18:58:22,530 __main__ INFO Saved: ./train-results/sgan/generated_data_1386.pickle, ./train-results/sgan/g_model_1386.h5, and ./train-results/sgan/c_model_1386.h5
2021-05-16 18:59:11,271 __main__ INFO Classifier accuracy at step 1617: 62.92%
2021-05-16 18:59:11,418 __main__ INFO Saved: ./train-results/sgan/generated_data_1617.pickle, ./train-results/sgan/g_model_1617.h5, and ./train-results/sgan/c_model_1617.h5
2021-05-16 19:00:00,354 __main__ INFO Classifier accuracy at step 1848: 63.48%
2021-05-16 19:00:00,501 __main__ INFO Saved: ./train-results/sgan/generated_data_1848.pickle, ./train-results/sgan/g_model_1848.h5, and ./train-results/sgan/c_model_1848.h5
2021-05-16 19:00:49,175 __main__ INFO Classifier accuracy at step 2079: 74.53%
2021-05-16 19:00:49,326 __main__ INFO Saved: ./train-results/sgan/generated_data_2079.pickle, ./train-results/sgan/g_model_2079.h5, and ./train-results/sgan/c_model_2079.h5
2021-05-16 19:01:37,949 __main__ INFO Classifier accuracy at step 2310: 68.24%
2021-05-16 19:01:38,106 __main__ INFO Saved: ./train-results/sgan/generated_data_2310.pickle, ./train-results/sgan/g_model_2310.h5, and ./train-results/sgan/c_model_2310.h5
2021-05-16 19:02:26,343 __main__ INFO Classifier accuracy at step 2541: 69.72%
2021-05-16 19:02:26,493 __main__ INFO Saved: ./train-results/sgan/generated_data_2541.pickle, ./train-results/sgan/g_model_2541.h5, and ./train-results/sgan/c_model_2541.h5
2021-05-16 19:03:15,088 __main__ INFO Classifier accuracy at step 2772: 71.92%
2021-05-16 19:03:15,239 __main__ INFO Saved: ./train-results/sgan/generated_data_2772.pickle, ./train-results/sgan/g_model_2772.h5, and ./train-results/sgan/c_model_2772.h5
2021-05-16 19:04:04,030 __main__ INFO Classifier accuracy at step 3003: 72.49%
2021-05-16 19:04:04,181 __main__ INFO Saved: ./train-results/sgan/generated_data_3003.pickle, ./train-results/sgan/g_model_3003.h5, and ./train-results/sgan/c_model_3003.h5
2021-05-16 19:04:52,744 __main__ INFO Classifier accuracy at step 3234: 73.46%
2021-05-16 19:04:52,894 __main__ INFO Saved: ./train-results/sgan/generated_data_3234.pickle, ./train-results/sgan/g_model_3234.h5, and ./train-results/sgan/c_model_3234.h5
2021-05-16 19:05:41,900 __main__ INFO Classifier accuracy at step 3465: 72.51%
2021-05-16 19:05:42,065 __main__ INFO Saved: ./train-results/sgan/generated_data_3465.pickle, ./train-results/sgan/g_model_3465.h5, and ./train-results/sgan/c_model_3465.h5
نتایج آموزش SGAN
همچنین باید تصاویر تولید شده توسط ژنراتور را مشاهده کنید تا مشخص شود که آیا آنها معقول هستند یا نه. در این مورد، از آنجا که تصاویر، تصویر دو بعدی از اسکنهای راداری اشیا سهبعدی هستند و توسط یک انسان قابلتشخیص نیستند، تصاویر تولید شده باید با مثالهایی از مجموعه دادههای اصلی مانند تصویر بالا مقایسه شوند. شکل زیر مجموعهای از اسکنهای دوبعدی تولید شده است. شباهت در یکی از پیشبینیها (صفحه X-Y) مشهود است اما در دیگران، حداقل برای این اجرای آموزشی واضح نیست. این امر میتواند دقت پایین را در نظر بگیرد و راههایی را برای تبدیل سایر پیشبینیهای بصری تولید شده مشابه با مجموعه آموزشی به یک تمرین در آینده، پیدا کند.
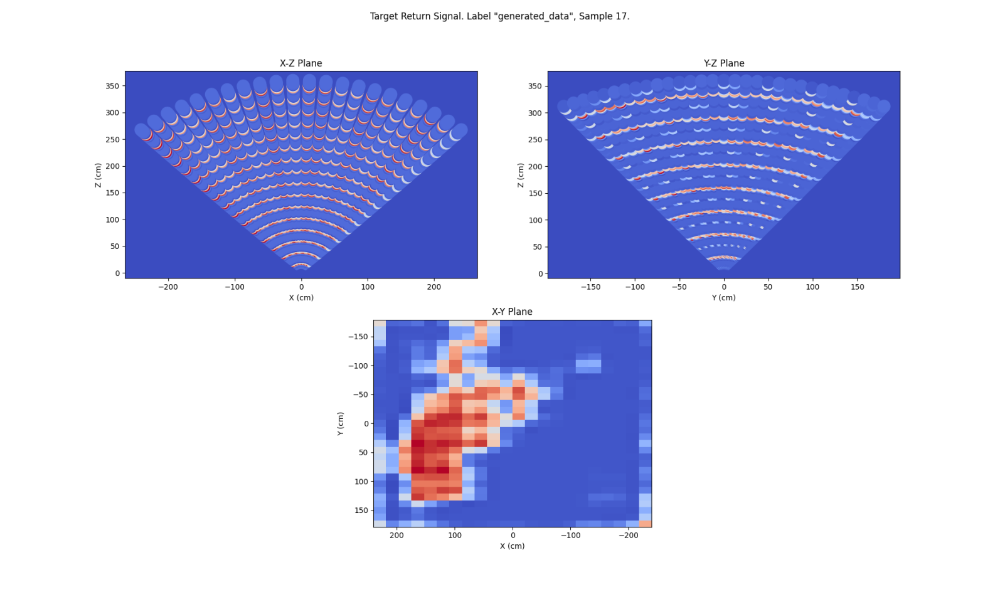
نتیجهگیری
شما میتوانید از معماریهای مدل سی ان ان، SGAN و تکنیکهای آموزشی مرتبط که برای دید کامپیوتری مبتنی بر دوربین توسعه داده شدهاند برای توسعه شبکههای عصبی برای طبقهبندی تصاویر رادار استفاده کنید. با توجه به کمبود مجموعه دادههای رادار، شما به طور معمول نیاز به جمعآوری مجموعه دادههای رادار دارید که میتواند منابع فشرده و در معرض خطا برای مشاهدات جدید رادار باشد. شما میتوانید از تکنیکهای خود نظارتی برای استفاده از دادههای بدون برچسب تنها با استفاده از چند ده یا کمتر از نمونههای برچسب دار در هر کلاس و یک SGAN استفاده کنید. به این ترتیب میتوانید طبقهبندی کنندههای تصویر رادار را با استفاده از مقادیر زیادی از دادههای بدون برچسب توسعه دهید.
کار قبلی از مدلهای یادگیری ماشین سطحی استفاده کرد و به دقت بالاتری در مجموعه دادهها نسبت به آنچه که در حال حاضر با استفاده از شبکهها و تکنیکهای توصیفشده در اینجا به دست آمدهاست، دست یافت. تلاشهای آینده برای از بین بردن این شکاف و افزایش اندازه مجموعه دادهها برای به دست آوردن دقت مجموعه اعتبارسنجی بهتر قبل از برازش بیش از حد برنامهریزی شدهاست.
این متن با استفاده از ربات مترجم مقاله علم داده ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
مجددا ۴ iOS با عشق به عنوان یک برنامه آیفون بازسازی شده است
مطلبی دیگر از این انتشارات
۶ مورد از بهترین IDE های پایتون و ویراستاران متن برای کاربردهای علوم داده
مطلبی دیگر از این انتشارات
فواید سلامتیبخش گیاهان آپارتمانی چیست؟