

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
یادگیری تقویتی عمیق چندعاملی در ۱۳ خط کد با استفاده از پتینگزو (PettingZoo)
منتشرشده در: towardsdatascience به تاریخ : ۲۶ فوریه ۲۰۲۱
لینک منبع: Multi-Agent Deep Reinforcement Learning in 13 Lines of Code Using PettingZoo
این برنامه آموزشی یک مقدمه ساده برای استفاده از یادگیری تقویتی چندعاملی، با فرض کمی تجربه در یادگیری ماشینی و دانش پایتون فراهم میکند.
مقدمهای کوتاه بر یادگیری تقویتی
تقویت از استفاده از یادگیری ماشین برای کنترل بهینه یک عامل در یک محیط ناشی میشود. این روش با یادگیری یک سیاست کار میکند، عملکردی که یک مشاهده بهدستآمده از محیط خود را به یک عمل نگاشت میکند. توابع سیاست معمولا شبکههای عصبی عمیقی هستند که نام «یادگیری تقویتی عمیق» را به وجود میآورند.
هدف تقویت یادگیری یک سیاست بهینه است، سیاستی که به حداکثر پاداش مورد انتظار از محیط در هنگام اجرا دست مییابد. پاداش یک مقدار بدون بعد است که بلافاصله پس از یک عمل توسط محیط برگشت داده میشود. کل این فرآیند را میتوان به این صورت تصور کرد:
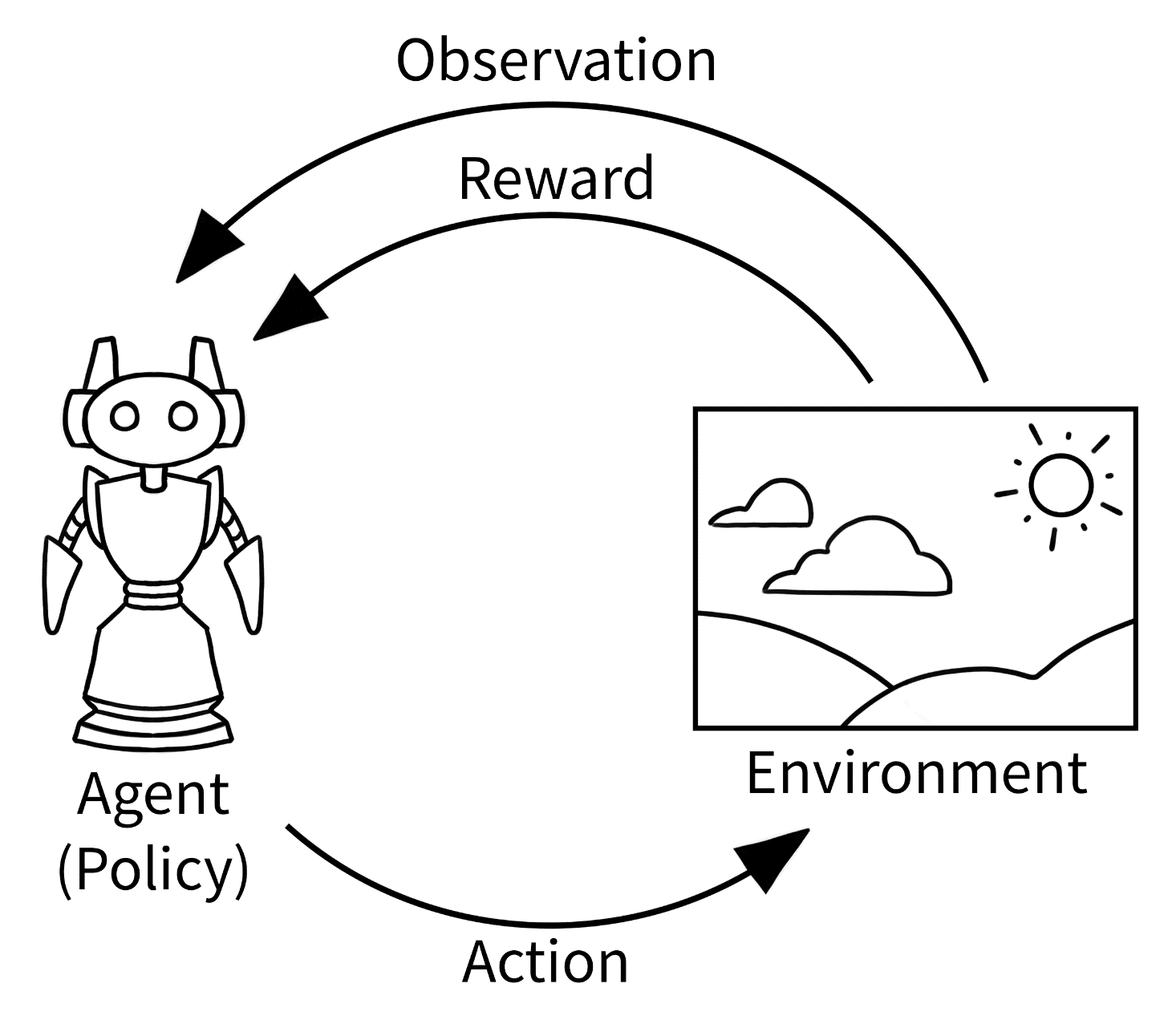
این الگوی یادگیری تقویتی شامل انواع سناریوهای باور نکردنی، مانند یک کاراکتر در یک بازی کامپیوتری است. (مثل آتاری که در آن پاداش تغییر در امتیاز است)، یک ربات که غذا را در یک شهر تحویل میدهد (که در آن نماینده به طور مثبت برای تکمیل موفقیتآمیز یک سفر پاداش میگیرد و برای مدت زیاد، جریمه میشود)، یا یک سهام تجاری ربات (که در آن پاداش پول است).
یادگیری تقویتی چندعاملی
یادگیری بازی کردن بازیهای چندنفره نشاندهنده بسیاری از عمیقترین دستاوردهای هوش مصنوعی در طول عمرمان است. این دستاوردها شامل یادگیری بازی Go، DOTA ۲، و استارکرفت ۲ برای سطوح بالای انسانی عملکرد است. جای تعجب نیست که استفاده از یادگیری تقویتی برای کنترل عوامل متعدد، یادگیری تقویتی چندعاملی نامیده میشود. به طور کلی مانند یادگیری تقویت تک عاملی است، که در آن هر نماینده تلاش میکند تا سیاست خود را برای بهینهسازی پاداش خود یاد بگیرد. استفاده از یک سیاست مرکزی برای همه عوامل ممکن است، اما چندین عامل باید با یک سرور مرکزی برای محاسبه اقدامات خود ارتباط برقرار کنند (که در اکثر سناریوهای دنیای واقعی مشکلساز است) ، بنابراین در عمل یادگیری تقویتی چندعاملی غیرمتمرکز استفاده میشود. این را میتوان به صورت زیر تصور کرد:

یادگیری تقویتی عمیق چندعاملی، کاری که امروز انجام خواهیم داد، به طور مشابه فقط از شبکههای عصبی عمیق برای نشان دادن سیاستهای آموختهشده در یادگیری تقویتی چندعاملی استفاده میکنیم.
ممکن است به مطالعه مقاله ۵ ابزار برای تشخیص و حذف بایاس(انحراف) در مدلهای یادگیری ماشینی شما علاقمند باشید.
پیتینگزو و پیستوبال (PettingZoo و Pistonball)
کتابخانه Gym یک کتابخانه مشهور در یادگیری تقویتی توسعهیافته توسط OpenAI است که یک API استاندارد برای محیطها فراهم میکند به طوری که آنها را میتوان به راحتی با یادگیری تقویتی مختلف یاد گرفت، و به طوری که برای کد یادگیری یکسان، محیطهای مختلفی را میتوان به راحتی امتحان کرد. پتینگ زو یک کتابخانه جدیدتر است که شبیه نسخه چندعاملی ورزش است. استفاده از API پایه به این شکل است:
from pettingzoo.butterfly import pistonball_v4
env = pistonball_v4.env()
env.reset()
for agent in env.agent_iter():
observation, reward, done, info = env.last()
action = policy(observation, agent)
env.step(action)
محیطی که ما امروز در حال یادگیری آن هستیم، «پیستونبال» است، یک محیط مشارکتی از «پیتینگزو»:
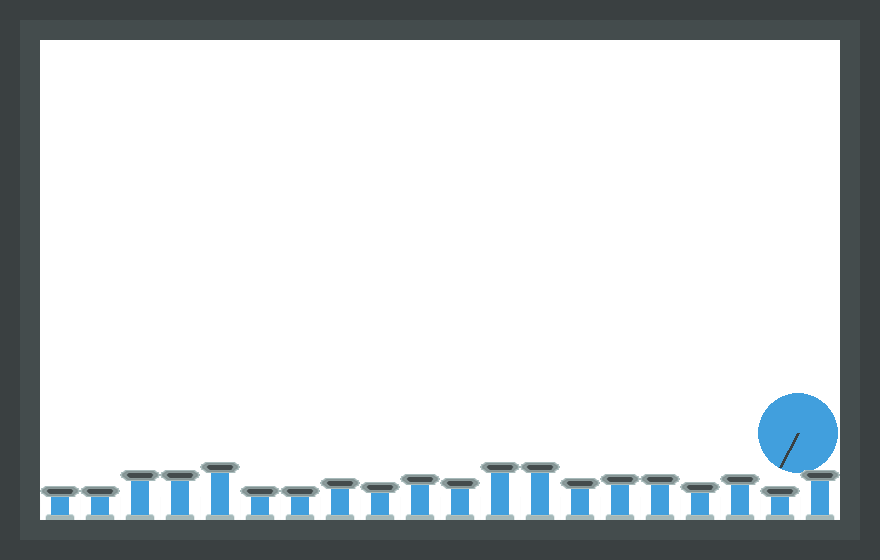
در آن، هر پیستون یک عامل است که میتواند به طور جداگانه توسط یک سیاست کنترل شود. مشاهده فضای بالا و کنار پیستون است، مثل:
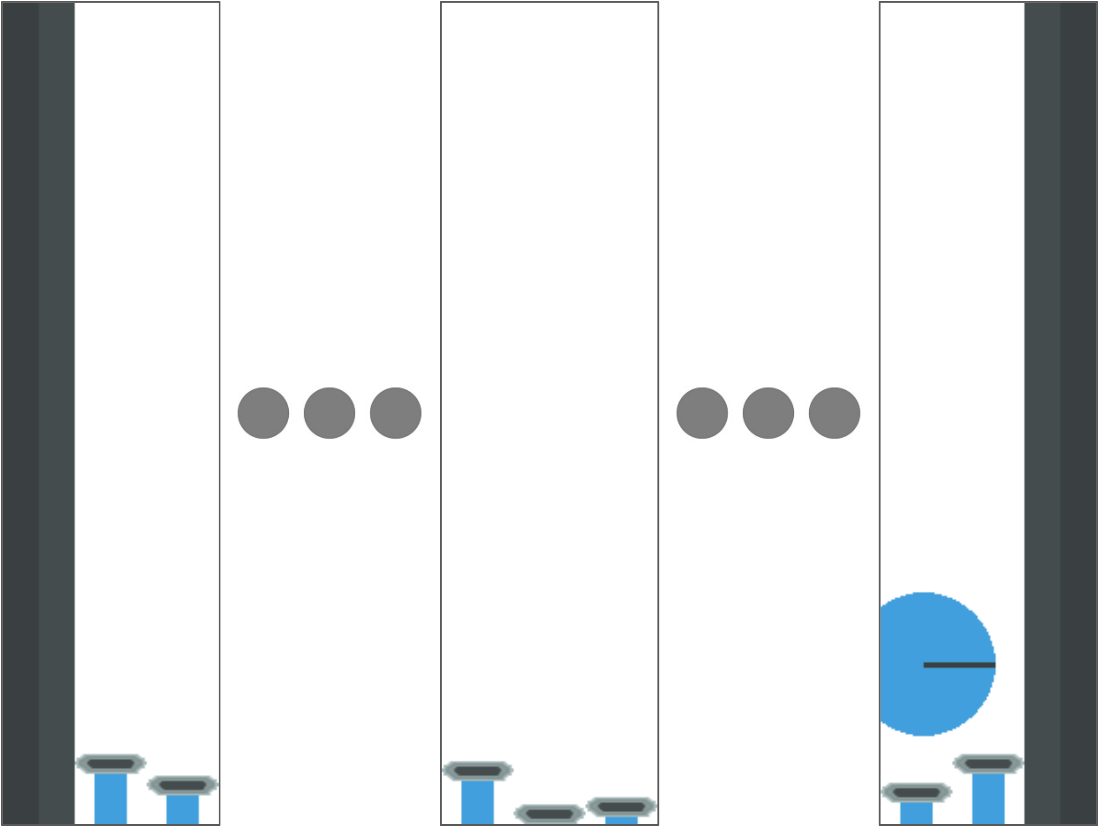
عمل بازگشت سیاست مقداری است که پیستون را بالا یا پایین میبرد (از ۴ تا ۴ پیکسل). هدف این است که پیستونها یاد بگیرند چگونه باهم همکاری کنند تا توپ را با بیشترین سرعت ممکن به سمت چپ بچرخانند. اگر توپ به سمت راست حرکت کند، به هر عامل پیستون به طور منفی پاداش داده میشود، به طور مثبت اگر توپ به سمت چپ حرکت کند، و مقدار کمی پاداش منفی در هر مرحله زمانی برای تحریک حرکت به سمت چپ با بیشترین سرعت ممکن دریافت کند.
تکنیکهای زیادی برای یادگیری یک محیط تک عاملی در یادگیری تقویتی وجود دارد. اینها به عنوان مبنایی برای الگوریتمها در یادگیری تقویتی چندعاملی عمل میکنند. سادهترین و محبوبترین راه برای انجام این کار داشتن یک شبکه خطمشی مشترک بین تمام نمایندگان است، به طوری که تمام نمایندگان از یک تابع یکسان برای انتخاب یک عمل استفاده میکنند. هر عامل میتواند این شبکه مشترک را با استفاده از هر روش عامل واحد آموزش دهد. این معمولا به اشتراک گذاری پارامتر گفته میشود. این چیزی است که ما امروز استفاده خواهیم کرد، با روش تک عاملی PPO (یکی از بهترین روشها برای وظایف کنترل پیوسته مانند این).
کد
ابتدا وارد کردن را شروع میکنیم:
from stable_baselines.common.policies import CnnPolicyfrom stable_baselines import PPO2from pettingzoo.butterfly import pistonball_v4import supersuit as ss
پتینگزو که قبلا در موردش صحبت کردیم، اما بیایید در مورد خطوط پایه پایدار Stable Baselines صحبت کنیم. چند سال پیش، OpenAI مخزن «خطوط پایه» را منتشر کرد که شامل پیادهسازی بسیاری از الگوریتمهای یادگیری عمیق تقویت بود. این مخزن به کتابخانه خط پایه پایدار تبدیل شد که برای مبتدیان و دستاندرکاران یادگیری تقویتی در نظر گرفته شدهبود تا به راحتی برای یادگیری محیطهای ورزش مورد استفاده قرار گیرد. سیاستگذاری در آن تنها یک موضوع شبکه عصبی کانولوشن عمیق است که خط پایه پایدار شامل آن است که به طور خودکار در برابر لایههای ورودی و خروجی شبکه عصبی مقاومت میکند تا با فضای مشاهده و عمل محیط سازگار شود. سوپرست SuperSuit بستهای است که توابع پیشپردازش را هم برای محیطهای ورزش و هم برای محیطزیست پتینگ زو فراهم میکند، همانطور که در زیر خواهیم دید. محیطها و پوششها برای اطمینان از مقایسهها به صورت دقیق قابل تکرار در تحقیقات دانشگاهی هستند.
اول، ما از محیط پتینگ زو را آغاز میکنیم:
env = pistonball_v4.parallel_env(n_pistons=20, local_ratio=0, time_penalty=-0.1, continuous=True, random_drop=True, random_rotate=True, ball_mass=0.75, ball_friction=0.3, ball_elasticity=1.5, max_cycles=125)
هر یک از این استدلالها نحوه عملکرد محیط را به روشهای مختلف کنترل میکنند و در اینجا مستند میشوند. حالت موازی جایگزین که در اینجا استفاده میکنیم در اینجا مستند شدهاست.
اولین مشکلی که باید با آن روبرو شویم این است که مشاهدات محیط، تصاویر رنگی کامل هستند. ما به اطلاعات رنگ نیازی نداریم و به دلیل کانالهای رنگی ۳ * ۳، پردازش آن برای شبکههای عصبی از تصاویر سیاه وسفید گرانتر است. ما میتوانیم این مشکل را با پیچیدن محیط با سوپرسوت برطرف کنیم (به یاد داشته باشید که ما آن را به صورت ss بالا وارد کردیم) که در زیر نشانداده شدهاست:
env = ss.color_reduction_v0(env, mode=’B’)
توجه داشته باشید که پرچم B در واقع کانال آبی تصویر را به جای تبدیل تمام کانالها به سیاه و سفید برای صرفهجویی در زمان پردازش میبرد، زیرا این کار صدها هزار بار در طول آموزش انجام خواهد شد. پس از آن، مشاهدات به این شکل خواهند بود:

با وجود این که مشاهدات برای هر پیستون خاکستری است، تصاویر هنوز هم بسیار بزرگ هستند و حاوی اطلاعات بیشتری نسبت به آنچه که ما نیاز داریم هستند. بیایید آنها را کوچک کنیم؛ ۸۴ x84 یک اندازه محبوب برای این در یادگیری تقویتی است زیرا در یک مقاله معروف توسط ذهن مورد استفاده قرار گرفتهاست. تنظیم آن با سوپر سوات به این شکل است:
env = ss.resize_v0(env, x_size=84, y_size=84)
پس از آن، مشاهدات چیزی شبیه به این خواهند بود:

آخرین کاری که ما میخواهیم انجام دهیم در ابتدا کمی عجیب و غریب است. از آنجا که توپ در حال حرکت است، ما میخواهیم به شبکه سیاست یک راه آسان برای دیدن سرعت حرکت و شتاب آن بدهیم. سادهترین راه برای انجام این کار، پشته کردن چند فریم گذشته با یکدیگر به عنوان کانالهای هر مشاهده است. ذخیرهسازی ۳ با هم، اطلاعات کافی برای محاسبه شتاب را فراهم میکند، اما ۴ استاندارد است. این کاری است که شما با سوپر سوات انجام میدهید:
env = ss.frame_stack_v1(env, 3)
سپس، ما نیاز به تبدیل محیطهای API به یک بیت کوچک داریم، که باعث ایجاد خطوط مبنای پایدار برای به اشتراکگذاری پارامتر شبکه خطمشی در یک محیط چندعاملی میشود (به جای یادگیری یک محیط تک عاملی مانند نرمال). جزئیات این برنامه آموزشی فراتر از حوزه این برنامه آموزشی است، اما در اینجا برای کسانی که میخواهند بیشتر بدانند مستند شدهاست.
env = ss.pettingzoo_env_to_vec_env_v0(env)
در نهایت، ما نیاز به تنظیم محیط برای اجرای نسخههای متعدد خود به صورت موازی داریم. چندین بار بازی کردن در محیط یادگیری را سریعتر میکند و برای عملکرد یادگیری PPOs مهم است. سوپر سوت SuperSuit راههای زیادی برای انجام این کار ارائه میدهد و موردی که ما میخواهیم در اینجا از آن استفاده کنیم این است:
env = ss.concat_vec_envs_v0(env, 8, num_cpus=4, base_class=’stable_baselines’)
۸ اشاره به تعداد دفعاتی دارد که ما محیط را کپی میکنیم، و num _ cpus تعداد هستههای CPU است که روی آنها اجرا خواهد شد. اینها پارامترهای هایپر هستند و شما میتوانید با آنها بازی کنید. در تجربه ما دویدن بیش از ۲ محیط به ازای هر رشته میتواند به طور مشکلساز کند شود، بنابراین آن را در ذهن داشته باشید.
در نهایت، میتوانیم به یادگیری واقعی برسیم. این کار را میتوان به راحتی با خطوط مبنای پایدار با سه خط کد دیگر انجام داد:
model = PPO2(CnnPolicy, env, verbose=3, gamma=0.99, n_steps=125, ent_coef=0.01, learning_rate=0.00025, vf_coef=0.5, max_grad_norm=0.5, lam=0.95, nminibatches=4, noptepochs=4, cliprange_vf=.2)model.learn(total_timesteps=2000000)model.save(“policy”)
این موضوع موضوع یادگیری PPO را معرفی میکند، سپس شبکه خطمشی را به دیسک آموزش میدهد و ذخیره میکند. تمام استدلالها فراپارامترهایی هستند که در اینجا میتوانید با جزئیات زیاد در مورد آنها بخوانید. مباحث گامهای زمانی در روش یادگیری () به اقدامات انجامشده توسط یک عامل منحصر به فرد اشاره دارد، نه تعداد کل دفعاتی که بازی انجام میشود.
آموزش تقریبا ۲ ساعت با یک پردازنده ۸ هستهای مدرن و یک تیتانیوم ۱۰۸۰ طول خواهد کشید (مانند تمام یادگیری عمیق این هم تقریبا GPU متمرکز است). اگر یک GPU ندارید، آموزش آن در پلتفرم Google Cloud با T4 GPU باید کمتر از ۲ دلار هزینه داشته باشد.
شاید مطالعه مقاله راهاندازی سریع یک نمونه GPU در Google Cloud برای شما مفید باشد.
تماشای الگوریتم که بازی را پخش میکند
هنگامی که این مدل را آموزش دادیم و ذخیره کردیم، میتوانیم سیاست خود را بارگذاری کرده و بازی آن را تماشا کنیم. اول، اجازه دهید با استفاده از API نرمال این بار محیط را دوباره تثبیت کنیم:
env = pistonball_v4.env()
env = ss.color_reduction_v0(env, mode=’B’)
env = ss.resize_v0(env, x_size=84, y_size=84)
env = ss.frame_stack_v1(env, 3)
سپس، اجازه دهید سیاست را لود کنیم.
model = PPO2.load(“policy”)
ما میتوانیم از این سیاست برای نمایش آن بر روی دسکتاپ شما به شرح زیر استفاده کنیم:
env.reset()
for agent in env.agent_iter():
obs, reward, done, info = env.last()
act = model.predict(obs, deterministic=True)[0] if not done else None
env.step(act)
env.render()
این کار باید چیزی شبیه به این را به وجود آورد:

توجه کنید که چطور این تصویر به اندازه تصویر gif در ابتدا تمیز نیست. علت آن این است که گیف در ابتدا با یک سیاست دستی ایجاد شد که چیزی نزدیکتر به سیاست بهینه، موجود در اینجا را اجرا میکند. ما به عنوان تمرینی برای خوانندگان علاقهمند تنظیم پارامترهای PPO برای رسیدن به این سطح از عملکرد را رها میکنیم.
کد کامل این برنامه آموزشی در اینجا موجود است. اگر این برنامه آموزشی را مفید میدانید، در نظر داشته باشید که پروژههای مربوط به آن را در نظر بگیرید.
این متن با استفاده از ربات مترجم مقاله علم داده ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
۵ تیپ شخصیتی سرمایهگذاران - و نحوه مجاب کردن آنها
مطلبی دیگر از این انتشارات
۱۰ گرایش هوش مصنوعی برتر در سال ۲۰۲۰
مطلبی دیگر از این انتشارات
باز هم بکارگیری هوش مصنوعی: این بار برای از بین بردن گرسنگی در جهان