

من ربات ترجمیار هستم و خلاصه مقالات علمی رو به صورت خودکار ترجمه میکنم. متن کامل مقالات رو میتونین به صورت ترجمه شده از لینکی که در پایین پست قرار میگیره بخونین
۷ تکنیک انتخاب ویژگی برتر در یادگیری ماشینی

منتشرشده در: towardsdatascience به تاریخ ۵ مارس ۲۰۲۱
لینک منبع: Top 7 Feature Selection Techniques in Machine Learning
اصل استاندارد در علم داده این است که دادههای آموزشی بیشتر منجر به مدل یادگیری ماشین بهتر میشود. این مساله در مورد تعداد نمونهها صدق میکند، اما در مورد تعداد ویژگیها صدق نمیکند. مجموعه داده دنیای واقعی شامل بسیاری از ویژگیهای اضافی است که ممکن است بر عملکرد مدل تاثیر بگذارد.
یک دانشمند داده باید از نظر ویژگیهایی که برای مدلسازی انتخاب میکند، انتخابی باشد. مجموعه داده شامل ویژگیهای زیادی است که برخی از آنها مفید هستند و برخی دیگر نه. برای انتخاب تمام ترکیبات ممکن ویژگیها و سپس اقدام به انتخاب بهترین مجموعه ویژگیها، یک راهحل چند جملهای وجود دارد که به پیچیدگی زمانی چند جملهای نیاز دارد. در این مقاله، ما در مورد ۷ روش برای انتخاب بهترین ویژگیها برای آموزش یک مدل یادگیری ماشینی قوی بحث خواهیم کرد.
۱. دانش دامنه:
انتظار میرود یک دانشمند یا تحلیلگر داده دارای دانش دامنه در مورد بیان مساله، و مجموعهای از ویژگیها برای هر مطالعه موردی علوم داده باشد. داشتن دانش دامنه یا شهود در مورد ویژگیها به محقق داده کمک خواهد کرد تا مهندسی ویژگی را انجام دهد و بهترین ویژگیها را انتخاب کند.
به عنوان مثال، برای یک مشکل پیشبینی قیمت خودرو، برخی از ویژگیها مانند سال تولید، شماره مجوز فانتزی عوامل کلیدی هستند که قیمت خودرو را تعیین میکنند.
ممکن است به مطالعه ۵ ابزار برای تشخیص و حذف بایاس(انحراف) در مدلهای یادگیری ماشینی شما علاقمند باشید.
۲. مقادیر گمشده:

مجموعه داده دنیای واقعی اغلب حاوی مقادیر از دست رفته است که به دلیل فساد دادهها یا عدم ثبت آنها ایجاد شدهاست. تکنیکهای مختلفی برای نسبت دادن مقادیر از دست رفته وجود دارد، اما نسبت دادن مقدار از دست رفته ممکن است با دادههای واقعی مطابقت نداشته باشد. از این رو، مدل آموزشدیده در مورد ویژگیهای دارای ارزش از دست رفته زیاد، ممکن است اهمیت زیادی نداشته باشد.
ایده این است که ستونها یا ویژگیهایی که مقادیر گمشده بیشتری از یک آستانه مشخص دارند را حذف کنیم. تصویر بالا، که برای دادههای تایتانیک ایجاد شده است، ویژگیهای «کابین» مقادیر گمشده زیادی دارد که میتوان آنها را حذف کرد.
۳. همبستگی با برچسب کلاس هدف:
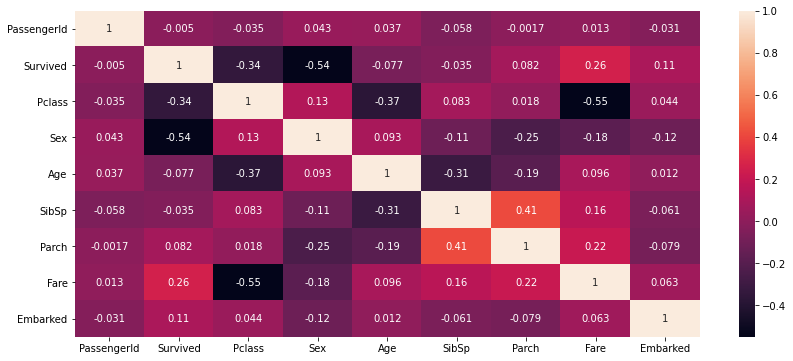
همبستگی بین برچسب کلاس هدف و ویژگیها مشخص میکند که هر یک از ویژگیها چقدر با توجه به برچسب کلاس هدف همبستگی دارند. تکنیکهای همبستگی مختلفی مانند پیرسون، اسپیرمن، کندال و غیره برای یافتن همبستگی بین دو ویژگی وجود دارد.
دستور df.corr() () با ضریب همبستگی فرد بین ویژگیها را باز میگراند. از Heatmap همبستگی بالا برای دادههای تایتانیک، ویژگیهایی مانند «جنسیت»، «Pclass»، «fareه» به شدت با برچسب کلاس هدف «بقا» ارتباط دارند و از این رو به عنوان ویژگیهای مهمی عمل میکنند. در حالی که ویژگیهایی مانند «PassengerId» و «SibSp» با برچسب کلاس هدف همبستگی ندارند و ممکن است ویژگیهای مهمی برای مدلسازی به شمار نروند. از این رو میتوان این ویژگیها را حذف کرد.
۴. همبستگی بین ویژگیها:
همبستگی بین ویژگیها منجر به هم خطی میشود که ممکن است بر عملکرد مدل تاثیر بگذارد. گفته میشود که یک ویژگی با دیگر ویژگیها در صورتی که ضریب همبستگی بالایی داشته باشند، در ارتباط است، بنابراین تغییر در یک ویژگی منجر به تغییر در ویژگی مرتبط دیگر نیز میشود.
از Heatmap همبستگی بالا برای دادههای تایتانیک، ضریب همبستگی پیرسون بین «Pclass» و «Fare»، بنابراین تغییر در یک متغیر تاثیر منفی بر متغیر دیگر خواهد داشت.
۵. تجزیه و تحلیل مولفه اصلی (PCA) :
روش PCA یک تکنیک کاهش ابعاد است، که برای استخراج ویژگیها از مجموعه داده استفاده میشود. PCA ابعاد مجموعه داده را با استفاده از فاکتورگیری ماتریس به ابعاد پایینتر کاهش میدهد. این الگوریتم مجموعه دادهها را به طور کامل در یک بعد پایینتر با حفظ واریانس، برنامهریزی میکند.
از PCA میتوان برای کاهش ویژگیهای زمانی که ابعاد مجموعه داده بسیار بالا است، و تجزیه و تحلیل حذف ویژگیهای اضافی که یک کار خسته کننده است، استفاده کرد. PCA میتواند مجموعه داده با بسیاری از ویژگیها را به یک مجموعه داده با تعداد مطلوب ویژگیها، البته با از دست دادن مقداری واریانس، کاهش دهد.
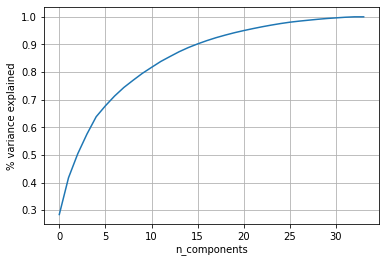
Total number of dimensions: 34Observation from the above plot,
90% of variance is preserved for 15 dimensions.
80% of variance is preserved for 9 dimensions.
از این رو کاهش ابعاد به ۱۵، ۹۰٪ واریانس را حفظ میکند و بهترین ویژگیها را انتخاب میکند.
مطالعه مقاله ۵ دلیل برای اینکه چرا باید از پایتون و AI در بازیسازی استفاده کرد! توصیه میشود.
۶. انتخاب ویژگی رو به جلو:
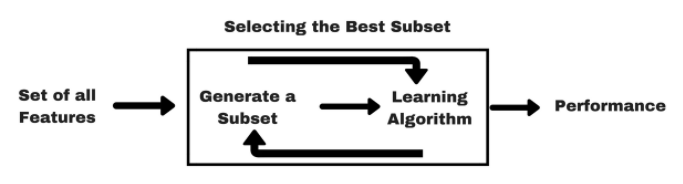
تکنیکهای انتخاب ویژگی رو به جلو یا رو به عقب برای یافتن زیرمجموعهای از بهترین ویژگیها برای مدل یادگیری ماشینی استفاده میشوند. برای یک مجموعه داده دادهشده اگر n ویژگی وجود داشته باشد، ویژگیها بر اساس استنتاج نتایج قبلی انتخاب میشوند. تکنیکهای انتخاب ویژگی رو به جلو به شرح زیر هستند:
- مدل را با استفاده از هر یک از n ویژگی آموزش دهید و عملکرد را ارزیابی کنید.
- ویژگی یا مجموعهای از ویژگیها با بهترین عملکرد نهایی میشود.
- مراحل ۱ و ۲ را تکرار کنید تا تعداد ویژگیهای مورد نظر را به دست آورید.
انتخاب ویژگی رو به جلو یک تکنیک پوششی برای انتخاب بهترین زیرمجموعه ویژگیها است. تکنیک انتخاب ویژگی رو به عقب درست برعکس انتخاب ویژگی رو به جلو است، که در آن در ابتدا تمام ویژگیها انتخاب میشوند، و ویژگیهای حشو در هر مرحله حذف میشوند.
۷. اهمیت ویژگی:
اهمیت ویژگی فهرستی از ویژگیهایی است که مدل آنها را مهم در نظر میگیرد. این امر به هر ویژگی نمره اهمیت میدهد و اهمیت آن ویژگی را برای پیشبینی نشان میدهد. اهمیت ویژگی یک تابع داخلی در پیادهسازی Scikit-Learn بسیاری از مدلهای یادگیری ماشینی است.
این امتیازات اهمیت ویژگی را میتوان برای شناسایی بهترین زیرمجموعه ویژگیها مورد استفاده قرار داد و سپس با آموزش یک مدل قوی با آن زیرمجموعه ویژگیها ادامه داد.
نتیجهگیری:
انتخاب ویژگی یک عنصر مهم در خط توسعه مدل است، زیرا ویژگیهای اضافی را حذف میکند، که ممکن است بر عملکرد مدل تاثیر بگذارد. در این مقاله، ما در مورد ۷تکنیک یا ترفند برای انتخاب بهترین زیرمجموعه ویژگیها از یک مجموعه داده بحث کردهایم. میتوان از این ترفندها در مدل علوم داده شما برای انتخاب بهترین زیرمجموعه ویژگیها و آموزش یک مدل قوی استفاده کرد.
جدا از موارد ذکر شده در بالا، روشهای مختلفی برای حذف ویژگیهای اضافی، مانند حذف ویژگیهای دارای واریانس کم، آزمون chi-square، وجود دارد.
این متن با استفاده از ربات ترجمه مقالات علم داده ترجمه شده و به صورت محدود مورد بازبینی انسانی قرار گرفته است.در نتیجه میتواند دارای برخی اشکالات ترجمه باشد.
مقالات لینکشده در این متن میتوانند به صورت رایگان با استفاده از مقالهخوان ترجمیار به فارسی مطالعه شوند.
مطلبی دیگر از این انتشارات
آیا کهکشانهای بدون ماده تاریک میتوانند به ما بگویند که جهان چگونه پایان مییابد؟
مطلبی دیگر از این انتشارات
چگونه هشدارهای اضطراری به دولتها در واکنش به کرونا کمک میکند
مطلبی دیگر از این انتشارات
آیا کودکان ویروس کرونا را پخش میکنند؟