در مطلب قبلی درباره انواع برازش مدل ماشین لرنینگ توضیح دادیم. مدل کمبرازش حالتی است که در آن مدل بسیار ساده است و نمیتواند به درستی روی داده ها تطبیق بیابد و بعضی روند های موجود در مجموعه داده ها را از دست میدهد. مدل بیشبرازش حالتی است که در آن مدل بسیار پیچیده است و سعی میکند برای هر داده موجود در مجموعه داده ها، علتی پیدا کند و در نتیجه، روند هایی را حدس میزند که اصلا وجود خارجی ندارند.
جور دیگری که میتوان به این موضوع نگاه کرد، از دیدگاه خطا (Bias) و واریانس (Variance) است. این دو از دیگر بنیان های اساسی دیتا ساینس هستند و جور دیگری به برازش مدل ماشین لرنینگ نگاه میکنند.

هر دوی این اصطلاح ها توضیح میدهند که چگونه عملکرد یک مدل ماشین لرنینگ، بر اساس مجموعه داده ها تغییر میکند. رفتار مدل با دیدن مجموعه داده های جدید، یکسان نیست. این واکنش را میتوان با خطا و واریانس توجیه کرد.
خطا: خطا میزان تطابق مدل با داده های یادگیری را توصیف میکند. در واقع خطا، تفاوت میان مقداری که مدل حدس زده و مقدار واقعی ای که انتظارش داریم است.یک مدل با خطای بالا نمیتواند به خوبی با مجموعه داده ها تطابق بیابد و توجه خیلی کمی به داده های موجود میکند. این درحالی است که مدل با خطای کم، میتواند به خوبی خود را با داده ها تطبیق دهد. خطا در مدل هایی رخ میدهد که بیش از اندازه ساده هستند و در پیدا کردن روند های موجود در مجموعه داده ها، عملکرد بدی دارند.
واریانس: واریانس میزان تغییر مدل را، به هنگام آموزش با قسمت های مختلف مجموعه داده ها توصیف میکند.در واقع واریانس، تنوع حدس های یک مدل را برای یک داده نشان میدهد. یک مدل با واریانس بالا توانایی این را دارد که بتواند خود را با هر مجموعه داده ای که میبیند تطبیق دهد و توجه خیلی زیادی به داده ها بکند؛ به طوری که نمیتواند عمومیسازی کند و سعی میکند برای هر کدام از داده ها، یک علت بیاورد. این باعث میشود که هر بار با یک مدل کاملا متفاوت روبرو شویم. واریانس در مدل هایی رخ میدهد که پیچیدگی بالایی دارند و تعداد ویژگی های آموزش (Feature) متعدد است.
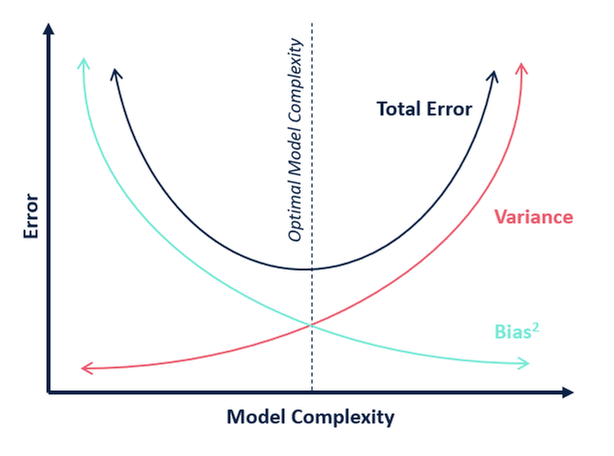
مدل هایی که خطای بالایی دارند، واریانس کم و مدل هایی که واریانس بالایی دارند، خطای کمی دارند. این روند به این خاطر است که این دو مقوله در دو نوع مدل کاملا متضاد وجود دارند. مدلی که به اندازه کافی انعطاف پذیر نیست که بتواند روی یک مجموعه داده تطابق بیابد (خطای زیاد) به اندازه کافی هم انعطاف پذیر نیست که بتواند روی داده های مختلف تغییر زیادی بکند.
کسانی که مطلب قبلی را خواندهاند، متوجه شباهت هایی خواهند شد. مدل های کمبرازش خطای بالا و واریانس کمی دارند. مدل های بیشبرازش واریانس بالا و خطای کمی دارند.
رابطه خطا-واریانس از موضوعات معمول مورد بحث در دیتا ساینس است. علت این امر این است که کار هایی که باعث کاهش خطا میشوند ( یعنی برازش بهتر مدل ) به طور همزمان به افزایش واریانس هم میانجامند ( یعنی افزایش خطر حدس اشتباه ) برعکس این قضیه هم صادق است. یعنی کم کردن واریانس باعث افزایش خطا میشود. با این عکس میتوانید به خوبی متوجه این رابطه شوید.

مهم است بدانید که افزایش واریانس همیشه یک عمل بد نیست. یک مدل کمبرازش، کمبرازش است چون به اندازه کافی واریانس ندارد و این باعث افزایش خطا میشود. این یعنی وقتی شما یک مدل را ارائه میدهید، باید مقدار واریانس و پیچیدگی را که احتیاج دارید، پیدا کنید. نکته اینجاست که باید پیچیدگی مدل را افزایش دهید، که این به معنای کاهش خطا و افزایش واریانس است؛ و این کار را تا زمانی انجام دهید که خطا کم شده و خطا های مربوط به واریانس هم نمایان نشدهاند.
راه دیگر این است که مجموعه داده هایی را که با آنها مدل را آموزش میدهیم، افزایش دهیم. خطا های مربوط به واریانس بالا، که به آنها مدل های بیشبرازش هم میگویند، هنگامی رخ میدهند که مدل ارائه شده برای مجموعه داده های موجود، بسیار پیچیده است. اگر بتوان از مجموعه داده های بیشتری استفاده کرد، میتوان مدل پیچیده را بدون رخ دادن خطای های مربوط به واریانس ارائه داد.
البته این راه خطا را کاهش نمیدهد.یک مدل با میزان خطای کم، که به آنها مدل های کمبرازش هم میگویند، به مجموعه داده ها حساس نیست. در نتیجه افزایش داده های موجود، عملکرد مدل را افزایش نمیدهد. در واقع نمیتواند به تغییر اعمال شده واکنشی نشان دهد. راهکار برای مدل با خطای بالا، افزایش واریانس است که معمولا به معنای افزایش تعداد داده های موجود است.
خطا و واریانس از مقوله های مهم در دیتا ساینس هستند. خطا نشان دهنده اشتباه در نقاط مربوط به داده ها است. این یعنی مدل به اندازه کافی پیچیده نیست. واریانس نشان دهنده پیچیدگی بیش از حد مدل برای داده های موجود است.
این دو خطا با هم معروف به Bias-Variance Trade-Off هستند. برای حل مشکل خطای زیاد، میتوان واریانس را افزایش داد. اما افزایش بیش از حد واریانس هم منجر به خطا های مربوط به واریانس خواهد شد. پیدا کردن تعادل این دو، تبدیل به یک هنر در ارائه مدل ماشین لرنینگ میشود.
اگر راهی برای حل مشکل خطا و واریانس کم وجود نداشت، باید تعداد داده ها را افزایش داد. مجموعه داده های بیشتر این امکان را میدهد که بدون اینکه خطای واریانس رخ دهد، یک مدل پیچیده تر ارائه داد. این باعث میشود که بتوان خطای مدل را کاهش داد و به طور همزمان به قدر کافی آن را پیچیده تر کرد تا خطای واریانس رخ ندهد.