وظایف مدل های یادگیری نظارت شده کاملا مشخص هستند و میتوانند به سنواریو های متفاوتی اعمال شوند، مانند شناسایی هرزنامه ها و یا پیشبینی بارش باران.
یادگیری نظارت شده بر اساس مفاهیم زیر بنا شده است:
داده ها نیروی محرکه مدل های یادگیری ماشین هستند. داده ها در شکل کلمات و اعداد ذخیره شده در جداول و یا به صورت پیکسل هایی از یک تصویر و یا امواجی از صداها میایند. ما داده های مرتبط را در مجموعه داده ها ذخیره میکنیم. مثال هایی از مجموعه داده ها:
مجموعه داده ها از یکسری نمونه ها که شامل ویژگی ها و یک برچسب میباشند ساخته شده اند. به عنوان مثال یک نمونه را میتوان به یک سطر در یک فایل اکسل تشبیه کرد. ویژگی ها مقادیری هستند که یک مدل نظارت شده استفاده میکند تا برچسب را پیشبینی کند. برچسب را میتوان به عنوان پاسخ در نظر گرفت و یا جوابی که از مدل انتظار داریم تا برای ما پیشبینی کند. در یک مدل هواشناسی که بارش باران را پیشبینی میکند، ویژگی ها میتوانند طول و عرض جرافیایی، دما، رطوبت، پوشش ابر، جهت باد و فشار اتمسفر باشند.
نمونه هایی که شامل هر دوی ویژگی ها و یک برچسب باشند را نمونه های برچسبدار مینامند.

در مقابل، نمونه هایی که برچسب ندارند ولی فقط ویژگی ها را دارند نمونه های بدونبرچسب مینامند.

یک مجموعه داده بر اساس اندازه و تنوع آن شناخته میشود. اندازه، به تعداد نمونه ها گفته میشود. تنوع نشان دهنده محدوده ای که نمونه ها پوشش میدهند. یک مجموعه داده خوب هم بزرگ است و هم تنوع زیادی دارد.
برخی از مجومه داده ها هم بزرگ و هم متنوع هستند. با این حال، برخی مجموعه داده ها بزرگ هستند ولی تنوع کمی دارند. برخی کوچک ولی تنوع زیادی دارند. به عبارت دیگر، یک مجموعه داده الزاما تنوع داده را تضمین نمیکند. همچینین ک مجموعه داده متنوع میزان کافی نمونه را تضمین نمیکند.
به عنوان مثال، یک مجموعه داده ممکن است شامل ۱۰۰ سال ارزش داده باشد ولی تنها برای ماه شهریور. استفاده از این مجموعه داده برای پیش بینی ریزش باران در ماه اسفند ممکن است پیش بینی ضعیفی کند. در مقابل، یک مجموعه داده ممکن است تنها چند سال را شامل باشد ولی تمامی ماه ها را شامل باشد. این مجموعه داده نیز ممکن است پیش بینی های خوبی ندهد چرا که به اندازه کافی سال های متفاوت را شامل نمیشود.
تعداد زیادی مثال که انواع موارد استفاده را پوشش میدهند برای سیستم یادگیری ماشینی برای درک الگوهای اساسی در دادهها ضروری است. یک مدل آموزشدیده بر روی این نوع مجموعه دادهها احتمالاً پیشبینیهای خوبی روی دادههای جدید انجام میدهد.
در یادگیری نظارت شده، یک مدل مجموعه پیچیده ای از اعداد است که رابطه ای ریاضی از الگوهای مشخص خاص به مقادیر برچسب خروجی خاص تعریف می کند. مدل این الگو ها را از طریق آموزش کشف میکند.
قبل از اینکه یک مدل تحت نظارت بتواند پیش بینی کند، باید آموزش داده شود. برای آموزش یک مدل، به مدل مجموعه داده ای با نمونه های برچسب دار می دهیم. هدف این مدل یافتن بهترین راهحل برای پیشبینی برچسبها از روی ویژگیها است. مدل با مقایسه مقدار پیش بینی شده خود با مقدار واقعی برچسب بهترین راه حل را پیدا می کند. بر اساس تفاوت بین مقادیر پیش بینی شده و واقعی - که به عنوان ضرر تعریف می شود - مدل به تدریج راه حل خود را به روز می کند. به عبارت دیگر، مدل رابطه ریاضی بین ویژگی ها و برچسب را یاد می گیرد تا بتواند بهترین پیش بینی ها را روی داده های دیده نشده انجام دهد.
به عنوان مثال اگر مدل مقدار ۱.۱۵سانتیمتر باران را پیشبینیکند ولی مقدار واقعی ۰.۷۵ باشد بنابراین مدل راه حل خود را طوری تغییر میدهد که جواب نزدیکتر به ۰.۷۵ باشد. سپس مدل به هر نمونه در مجموعه داده نگاه میکند - و در برخی مواقع چندین بار - تا به راه حلی برسد که بهترین پیشبینی ها را به طور میانگین برای هر نمونه بتواند بکند.
در ادامه نحوه آموزش یک مدل نمایش داده شده است:
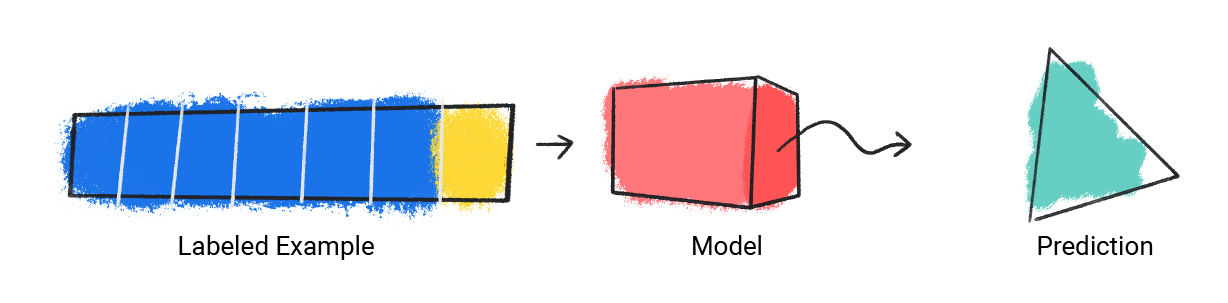
۲. مدل مقدار پیشبینی شده را با مقدار واقعی مقایسه میکند و راه حل خود را به روزرسانی میکند.
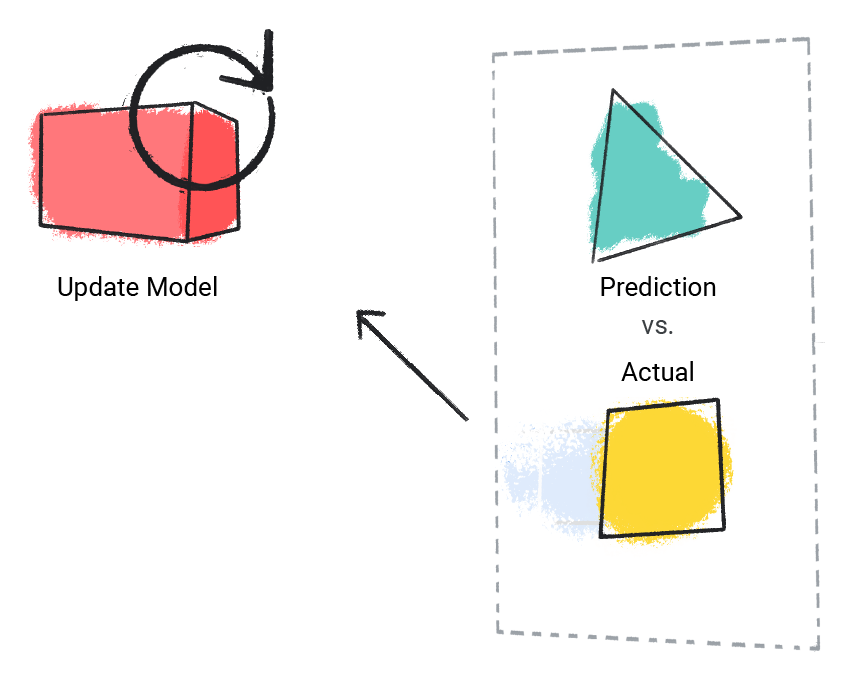
۳. مدل این روند را برای هر نمونه برچسب گذاری شده در مجموعه داده انجام میدهد.
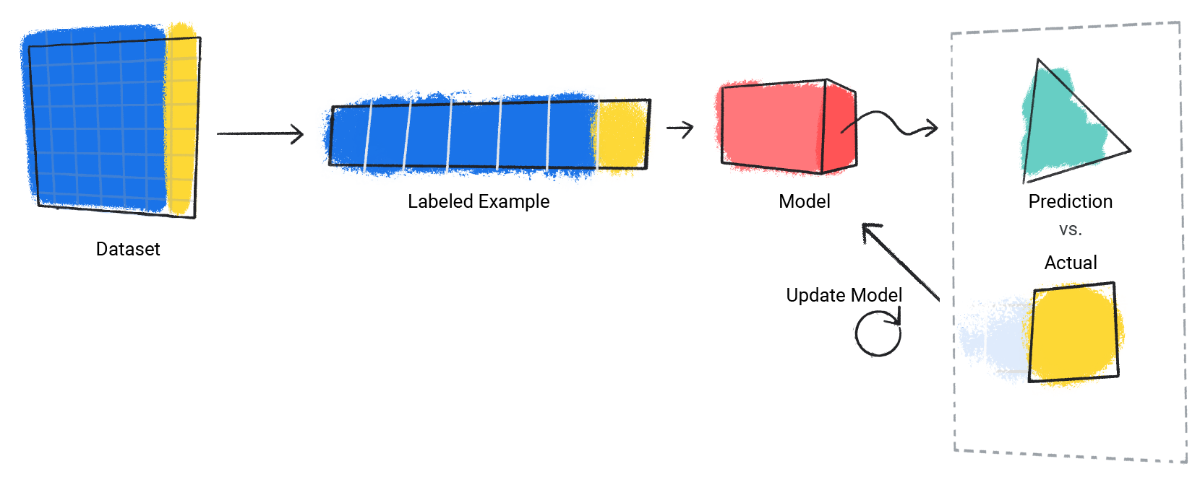
به این ترتیب، مدل به تدریج یاد میگیرد که به درستی رابطه بین ویژگی ها و برچسب را دریابد. این فهم تدریجی همچنین دلیل بر این است که یک مجموعه داده بزرگ و متنوع باعث ایجاد یک مدل بهتر میشود.
ما یک مدل آموزش دیده را ارزیابی میکنیم تا ببینیم چطور بازدهی ای دارد. وقتی که یک مدل را ارزیابی میکنیم ما از یک داده برچسب دار استفاده میکنیم ولی فقط ویژگی ها را به مدل میدهیم و سپس پیش بینی های مدل را با جواب های واقعی مقایسه میکنیم.

پس از اینکه از نتیجه ارزیابی مدل راضی شدیم میتوانیم از مدل استفاده کنیم تا پیش بینی بر روی داده های برچسب گذاری نشده برایمان انجام دهد. در مثال هواشناسی، میتوانیم ویژگی های هوا را به مدل بدهیم و این مدل برای ما میزان بارش را پیشبینی کند.