به قلم محمد متین حیدرنژاد، ورودی ۴۰۲ کارشناسی مهندسی کامپیوتر صنعتی اصفهان
بازنگریشده توسط پارسا شیرکوند، ورودی ۴۰۲ کارشناسی مهندسی کامپیوتر صنعتی اصفهان

با پیشرفت روزافزون تکنولوژی و به ویژه هوش مصنوعی، انتظار میرود روند پیشرفت پروندههای جنایی، سریعتر از هروقت دیگری در تاریخ پیش برود.
اما نکته قابل توجه این است که نرخ جرم و جنایت روزبه روز در حال افزایش است و تکنولوژی کمتر کمکی به ریشهکن کردن وقایع ناگوار جنایی میکند. چون طبق رابطه علت و معلول، باید جرمی رخ بدهد تا بتوان مجرمی را دستگیر و پرونده را حل کرد.
پس باید روشی برای کارآمدتر کردن تکنولوژی در راستای پیشگیری پیدا کرد.
در اینجا یک سوال پیش میآید؛ چه میشد اگر از روز اول تولد یک نفر بفهمیم که این شخص مجرم است یا نه؟
احتمالا فکر میکنید دیگر دوران فالگیری و طالعبینی تمام شده و این حرفها مزخرفاتی بیش نیستند.
اما باید این نکته را ذکر کنم؛ اگر به این موضوع واقف باشیم که علم همیشه انسانها را غافلگیر و هرگونه غیرممکنی را ممکن کرده است، به نتایج خیلی جالبی خواهیم رسید :)
چزاره لومبروزو (به ایتالیایی: Cesare Lombroso) زادهٔ ۶ نوامبر ۱۸۳۶ پزشک و جرمشناس ایتالیایی بود.

لومبروزو مکتب کلاسیک را -که معتقد بود جنایت یکی از ویژگیهای طبیعت انسان است- رد کرد.
در عوض، از مفاهیمی مثل قیافهشناسی (یعنی بررسی چهره برای شناخت ویژگیهای درونی)، نظریهی انحطاط (باوری که میگوید برخی جوامع یا افراد به سمت ضعف و زوال میروند)، روانپزشکی و داروینیسم اجتماعی استفاده کرد.
داروینیسم اجتماعی به این معناست که فقط افراد قویتر و توانمندتر باید در جامعه باقی بمانند و رشد کنند و افراد ضعیف یا بیفایده حذف شوند.
بر اساس این دیدگاهها، لومبروزو تلاش کرد ثابت کند جرم میتواند ارثی باشد.
او معتقد بود که بعضی انسانها به شکل مادرزادی مجرم به دنیا میآیند و میتوان آنها را از طریق برخی نقصهای جسمی و ویژگیهای ظاهری خاص شناسایی کرد.
به دلیل همین دیدگاه، او مطالعات خود را در راستای شناسایی علل وقوع جرم از منظر زیستی و فیزیولوژیکی آغاز کرد و در جستجوی کشف راز جرم، عامل محیطی و اجتماعی را کنار گذاشت و تمرکز خود را صرفاً بر ویژگیهای بدنی، ساختار اندامها و هیبت ظاهری مجرمان قرار داد.
او ابتدا به بررسی جمجمه ۳۸۳ فرد مجرم فوتشده پرداخت و سپس مطالعاتی بر روی ۵۹۰۷ مجرم زنده انجام داد تا ویژگیهای فیزیولوژیکی و آناتومیکی آنها را تحلیل کند.
در آخر برخی از ویژگیهای روانی مجرمان را چنین برشمرد:
حرکات غیرعادی و ناگهانی
خشونتطلبی و بیرحمی
فقدان عواطف لطیف و همدلی
همچنین ویژگی ظاهری افراد مجرم میتواند شامل موارد زیر باشد:
پیشانی کوتاه
ضخامت بیشازحد استخوان جمجمه
موهای ضخیم و زبر
بیمویی صورت در مردان
چپدستی
استفاده از زبان اوباش و کوچهبازاری
تمایل به خونریزی
غرور مفرط
رشد نامتناسب آروارهها
در مجموع بیش از ۷۲ نشانه ظاهری و رفتاری که به اعتقاد او، وجود تعدادی از آنها میتواند نشانهی تیپ مجرمانه باشد.(لزومی به وجود همزمان همهی آنها نبود).
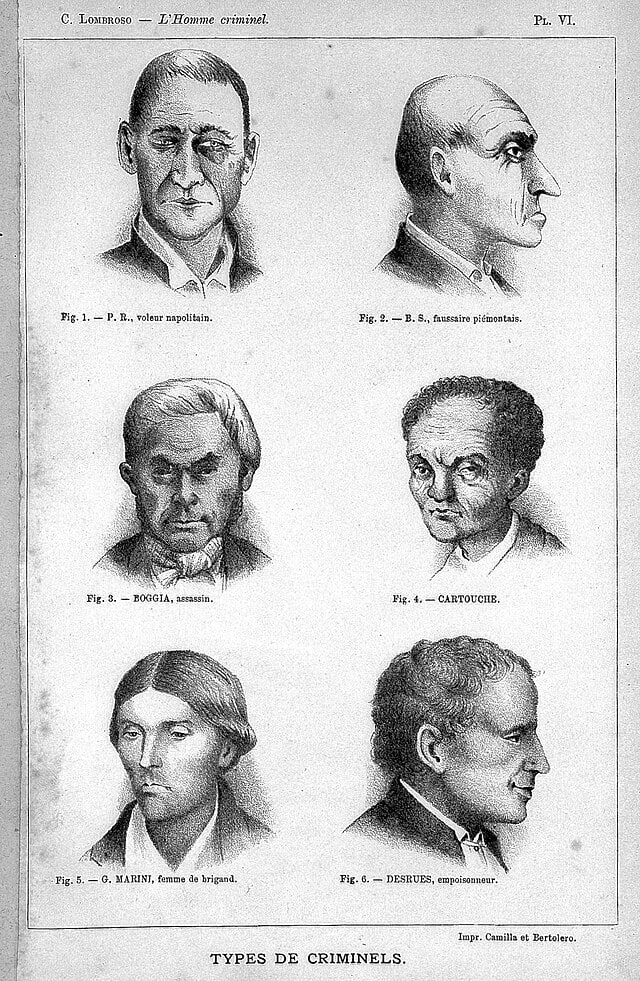
لومبروزو حتی از این آزمایشات هم فراتر رفت و باور پیدا کرد ظاهر مجرمانه فقط بر اساس چهره ارثی مانند بینی یا شکل جمجمه نیست، بلکه میتوان آن را از طریق ویژگیهای سطحی مانند خالکوبی روی بدن قضاوت کرد. چون این افراد حساسیت کمی دارند و کمتر احساس درد میکنند، به همین دلیل بدنشان خالکوبی شده است...
البته زمان زیادی نگذشت که نظریه او در طول قرن بیستم بهطور جدی از سوی جامعه علمی رد شد (ولی هنوز اول راهیم:)
حالا با چه استدلالاتی؟
مطالعات جدید نشان دادند که هیچ رابطه معنادار و قابل اعتمادی میان ظاهر فیزیکی و رفتار مجرمانه وجود ندارد و عوامل مهمتری مانند محیط اجتماعی، فقر، تربیت و آموزش نقش تعیینکنندهتری در گرایش به جرم دارند. همچنین، بسیاری از ویژگیهای معرفیشده توسط لومبروزو در افراد عادی هم دیده میشود و در بسیاری از مجرمان اصلاً وجود ندارد، بنابراین نمیتوان آنها را معیار تشخیص جرم دانست. از سوی دیگر، نظریه او به دلیل تقویت کلیشههای تبعیضآمیز، برچسبزنی افراد و سوءاستفاده در نظامهای سرکوبگر مانند نازیسم، از منظر اخلاقی و حقوق بشری نیز بهشدت مورد انتقاد قرار گرفت.
خب فکر میکنم تا همینجا برای آشنایی ابتدایی با خاستگاه چنین نظریههایی کافی باشد. البته روشن است که این دیدگاه بسیار گستردهتر از آن چیزی است که در این چند خط گنجانده شود، اما اکنون زمان آن رسیده که نگاهی به زمان حال بیندازیم.
با توجه به جمله «یک انسان میمیرد اما ایدههایش نه» خیلی سریع به بررسی نظریه لومبروزو در زمان حال میپردازیم.
در سال 2016، دو محقق چینی به نامهای Xiaolin Wu و Xi Zhang تحقیقی با عنوان “Automated Inference on Criminality Using Face Images” منتشر کردند.
این مقاله ادعا میکرد میتوان از طریق هوش مصنوعی، صرفاً با بررسی عکس چهرهی افراد، احتمال مجرم بودن آنها را تشخیص داد.
هدف اصلی این تحقیق بررسی این سؤال بود که آیا میتوان با استفاده از الگوریتمهای یادگیری ماشین، فقط بر اساس عکس چهرهی یک فرد، احتمال مجرم بودن او را بررسی کرد یا خیر. محققان بر این باور بودند که الگوهای خاصی در چهره افراد وجود دارد که ممکن است با رفتار مجرمانه همبستگی آماری داشته باشد.
روش تحقیق هم به این صورت بود که حدود 1856 تصویر چهره مربوط به مردان چینی که 730 تصویر متعلق به مجرمان واقعی و مابقی برای افراد غیرمجرم بود را بدون رنگ، پس زمینه، نورپردازی خاص و با حالات خنثی، برای تحلیل داده به چند مدل الگوریتم یادگیری ماشین (logistic regression, KNN, SVM, CNN) دادند. همچنین از الگوریتمهایی برای استخراج ویژگیهای هندسی صورت از جمله زاویه بینی، فاصله بین چشمها، فرم لب بالا و نسبت فک به صورت استفاده کردند.

نتیجهی آزمایشات برای آن زمان به شدت متحیر کننده بود. الگوریتمها توانستند چهره مجرمان و غیرمجرمان را با دقت ۸۹ درصد از یکدیگرتشخیص دهند!
در نمونههای مورد آزمایش، مشخص شد برخی ویژگیها بین دو گروه تفاوت آماری معناداری دارند:
لب بالای خمیدهتر در غیرمجرمان
زاویه بینی خاص و فاصله بیشتر یا کمتر بین چشمها در برخی از مجرمان
کاهش "احساسات مثبت" (مانند لبخند ملایم) در چهره مجرمان

خب باید مژده بدهم تا این لحظه، تحقیقات و آزمایشها با موفقیت پیش رفتهاند و توانستهایم تمایز مشخصی را شناسایی کنیم. این بدان معناست که قادر خواهیم بود مجرم را پیش از ارتکاب جرم شناسایی و بازداشت کنیم. میتوان با قطعیت گفت که روح لومبروزو را در آرامگاهش شاد کردهایم.
از این پس نه تنها دیگر شاهد جنایتی نخواهیم بود، بلکه حتی فکرش هم به دهن کسی خطور نخواهد کرد و بدین ترتیب، یک گام دیگر به سوی دنیای آرمانیِ بشریت نزدیک میشویم.
به همان اندازه که علم توانایی اثبات یک چیز را دارد، توانایی رد آن را هم دارد. کم کم نواقص و مشکلات این تحقیق یکی پس از دیگری برملا شدند.
بیایید اول به رد نتایج به دست آمده از این تحقیق بپردازیم و سپس درباره ناتوانی هوش مصنوعی در اثبات این موضوعات حرف بزنیم.
یکی از اولین و ساده ترین پارامتری که میتوان برای رد این آزمایش به کار برد، عدم کنترل کامل متغیرهاست.
برای مثال عکس افراد مجرم احتمالاً در شرایط رسمی، پلیسی، با نور بد و بدون لبخند گرفته شدهاند. در مقابل، عکس غیر مجرمان ممکن است پرسنلیای باشد که برای رزومه استخدام آنهاست. بدیهیست در این شرایط فرد سعی میکند با لبخندی، حس بهتری به کارفرمایان خود القا کند و به همین دلیل محیطهای عادیتر و دوستانهتری برای شرایط محیطی عکس انتخاب شدهاند.
در نتیجه این احتمال وجود دارد که مدل بهجای یادگیری ویژگیهای زیستی چهره، صرفاً تفاوت در کیفیت عکسها، حالات چهره یا نورپردازی را یاد گرفته باشد (حال هر چقدر هم محققها سعی کردند شرایط را تا حد ممکن یکسان نگه دارند).
دلیل بعدی هم فقدان تنوع جمعیتشناختی (Demographic Bias) است که در اینجا یعنی فقط مردان چینی در مطالعه بودند و به همین دلیل نتایج را نمیتوان به بقیهی جمعیتها تعمیم داد.
تحقیق Wu & Zhang، اگرچه از نظر تکنیکی یک مدل یادگیری ماشین اجرا کرده، اما با بیتوجهی به سوگیری داده، مفروضات نادرست درباره چهره و جرم و بدون در نظر گرفتن پیامدهای اجتماعی خطرناک، راه را برای سوءاستفاده از فناوری هوش مصنوعی در راستای تبعیض و بیعدالتی که در حال حاضر هم به کرات شاهدش هستیم، هموارتر میکند. به همین دلیل، این نظریه در جامعهی علمی رد شده و اعتبار ندارد.
در حال حاضر تبعیض جنسیتی، نژادی و اشکال دیگر تبعیض، در الگوریتمهای یادگیری ماشین که زیرساخت بسیاری از سیستمهای هوشمند را تشکیل میدهند، گنجانده شدهاند؛ سیستمهایی که در نحوهی دستهبندی شدن ما و نوع برخورد هوش مصنوعی با ما نقش دارند.
با یک مثال کوچک شروع میکنم: کاربران متوجه شدند که اپلیکیشن عکس گوگل، که به طور خودکارعکسها را در آلبوم دیجیتال برچسب میزند، تصاویر افراد سیاهپوست را به عنوان گوریل شناسایی کرده است.(به معنای واقعی کلمه) البته گوگل عذرخواهی کرد و گفت که این اتفاق، عمدی نبوده است.
هدف از بیان این مثال، وارد شدن به داستان ناتمام رنگ پوست بود؛ مقاله "Gender Shades" نوشته جوی بوالاموینی و تیمنیت گبرو یکی از تحقیقات پیشگامان در زمینهی تبعیض الگوریتمی در سیستمهای تشخیص چهره، به بررسی نابرابری در دقت سیستمهای تجاری تشخیص جنسیت از چهره (مانند مایکروسافت، IBM، و ++Face) بر اساس رنگ پوست و جنسیت میپردازد.
برای سنجش این مسئله، نویسندگان دیتاستی تازه با نام PPB (Pilot Parliaments Benchmark) ساختند. این مجموعه شامل ۱۲۷۰ تصویر از نمایندگان زن و مرد پارلمان در شش کشور (سه کشور آفریقایی و سه کشور اروپایی) بود. چهرهها بر اساس سیستم Fitzpatrick – که پوست انسان را بر پایهی واکنش آن به نور خورشید طبقهبندی میکند – در دو گروه پوست روشن و پوست تیره دستهبندی شدند.
همونطور که داخل جدول قابل مشاهده است، بالاترین نرخ خطا برای زنان با پوست تیره بین ۲۰.۸ درصد تا ۳۴.۷ درصد بود، در حالی که برای مردان پوست روشن نزدیک به ۰٪ نشان میداد.
اختلاف نرخ خطا بین زن و مرد در همه سیستمها ۸.۱٪ تا ۲۰.۶٪ بود و در نهایت تفاوت دقت بین افراد با پوست روشن و تیره بین ۱۱.۸٪ تا ۱۹.۲٪ بود.

دراینجا ما مجدد به همان نکته عدم کنترل کامل متغیرها میرسیم چون بیشتر دیتاستهای مرجع (مثل IJB-A و Adience) شامل افراد با پوست روشن هستند. بهطور مثال، ۸۶٪ تصاویر دیتاست Adience مربوط به افراد با پوست روشن است.

اما اشتباهاتی مشابه در نرمافزار دوربین شرکت نیکون نیز ظاهر شد. این دوربین تصاویر افراد آسیایی را به اشتباه، پلک زده (چون چشم مردان آسیایی کوچکتر و نازکتر از مردان اروپا و آمریکاست) تشخیص میداد و در نرمافزار دوربین شرکت HP هم اختلالاتی در تشخیص چهرهی افراد با پوست تیره دیده شد.
در آخر به این میرسیم که مشکلات، در اصل یک مسئلهی دادهای است. الگوریتمها با دریافت مجموعهای از تصاویر که اغلب توسط مهندسان انتخاب شدهاند آموزش میبینند و بر پایهی آنها، مدلی از جهان میسازند. اگر یک سیستم تنها با عکسهایی از افراد عمدتاً سفیدپوست آموزش ببیند، در تشخیص چهرههای غیرسفید مشکل خواهد داشت.
درباره رنگ پوست مفصل صحبت کردیم اما هنوز نمیدانیم چهطور این مسئله ممکن است باعث تبعیض شود، به همین علت توجهتان رو جلب میکنم به اتفاقی که توسط رسانه تحقیقاتی افشا شد.
آنها گزارش دادند نرمافزاری که برای سنجش خطر بازگشت به جرم در متهمان استفاده میشود، دو برابر بیشتر احتمال دارد متهمان سیاهپوست را بهاشتباه در معرض خطر بالا تشخیص دهد. همچنین، دو برابر بیشتر احتمال دارد که متهمان سفیدپوست را بهاشتباه کمخطر نشان دهد.
در کمترین و بیخطرترین حالت، این نرمافزارها خطر تداوم یک چرخهی معیوب را ایجاد میکنند: حضور پلیس در همان مناطقی که پیشتر در آنها حضور داشتهاند افزایش مییابد و در نتیجه، بازداشتهای بیشتری از آن مناطق گزارش میشود. در ایالات متحده، این امر میتواند به افزایش نظارت بر محلههای فقیرتر و عمدتاً غیر سفیدپوست منجر شود، در حالی که محلههای ثروتمندتر و سفیدپوستتر کمتر مورد توجه قرار میگیرند.
به آخرین موضوع در این متن رسیدیم؛ تبعیض جنسیتی!
دانشمندان کامپیوتر در دانشگاه کارنگی ملون دریافتند که احتمال نمایش آگهیهای شغلی با دستمزد بالا به مردان، بیشتر از زنان است. پیچیدگی نحوهی نمایش تبلیغات توسط موتورهای جستوجو باعث میشود نتوان بهراحتی علت این موضوع را تعیین کرد، اینکه آیا خودِ تبلیغدهندگان ترجیح دادهاند آگهیها را به مردان نشان دهند یا اینکه این نتیجه ناخواسته عملکرد الگوریتم بوده است.
در هر صورت، نقصهای الگوریتمی بهسادگی قابل کشف نیستند: یک زن چگونه میتواند برای شغلی اقدام کند که هرگز آگهیاش را ندیده است؟ یا یک جامعهی سیاهپوست چگونه میتواند بفهمد که توسط یک نرمافزار بیشازحد زیر نظر گرفته شده است؟
الگوریتمهای پیشبینیگر، تنها به اندازهی دادههایی که با آن آموزش دیدهاند، مفید هستند و آن دادهها، پیچیدگیهای نهفتهای دارند.

در مقالههای جدیدتری که خواندهام، درصد خطای این مدلها داشت کم و کمتر میشد، دور از انتظار نیست که سیستمهای تشخیص چهره بینقص شوند اما باز یک سوال بیجواب خواهد ماند؛ اگر یک روزی بتوان از همان روز تولد فهمید این کودک مجرم خواهد شد یا نه، چه اقدامی صورت خواهد گرفت؟ شاید فکر کنید احتمالا آموزش درستتری به او داده میشود تا از جرم و جنایت به دور شود ولی باید اشاره کنم این حرفها زیادی آرمانی هستند.
طبق آنچه که از تاریخ میدانیم، در فرض احتمالی دو چیز ممکن است، فرض اول زندانی کردن نوزاد یا نگهداریاش در یک محیط ایزوله تا آخر عمرش و فرض دوم که به ظاهر بهتر است، وجود شناسنامهای با مهر مجرمزاده بودن که مانند داغی در پیشانیاش تا آخر عمر با او همراهی خواهد کرد، این شروع نوع جدیدی از تبعیض است، برای مثال نه کاری به او میدهند و نه رفتار درستی خواهند داشت تا موقعی که ناچار شود برای گذراندن روزگارش واقعا دست به جنایت بزند!
حالا از شما میپرسم، به نظرتان این تکنولوژی باید وجود داشته باشد یا خیر؟
زندگینامه چزاره لومبروزو:
https://www.simplypsychology.org/lombroso-theory-of-crime-criminal-man-and-atavism.html
Automated Inference on Criminality using Face Images:
https://arxiv.org/abs/1611.04135
Artificial Intelligence’s White Guy Problem:
https://www.nytimes.com/2016/06/26/opinion/sunday/artificial-intelligences-white-guy-problem.html
Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification
http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf
نشریه فرامتن رو در پلتفرمهای مختلف دنبال کنید :)