منبع اصلی این پست، دوره NLP استنفورد (CS224N) از کانال یوتیوب Stanford Online است. لطفاً برای حفظ حقوق منتشر کننده اصلی، ویدیوهارو از منبع اصلی دنبال کنید. همچنین، در انتهای هر جلسه، به ویدیو مربوط به آن جلسه ارجاع داده شده است.

سعی کردم هرچیزی که از ویدیوها فهمیدم رو به صورت متن در بیارم و در این پلتفورم با بقیه به صورت کاملاً رایگان به اشتراک بذارم. کل ویدیوها 23 تاست که سعی میکنم ماهی حداکثر یک الی دو جلسه رو منتشر کنم. تا جایی که تونستم سعی کردم خوب و کامل بنویسم، اما اگر جایی ایرادی داشت، حتما تو کامنتها بهم بگید تا درستش کنم. لازم به ذکره که برای فهم بهتر مباحث این دوره، دونستن مفاهیم پایهای در یادگیری ماشین، جبر خطی و آمار و احتمال پیشنهاد میشه.
این جلسه بر خلاف جلسات گذشته که بیشتر از جنس ریاضی و مفاهیم پایهای یادگیری ماشین و شبکههای عصبی بود، از جنس مباحث linguistic و زبانی خواهد بود. به صورت خاص قراره در مورد ساختار نحوی و تحلیل وابستگی صحبت کنیم.

تو این جلسه میبینیم که آدما چطور در مورد ساختار یک جمله فکر میکنن و چطور زبان انسان معنا و مفهوم رو منتقل میکنه.
میدونیم که جملات از کنار هم قرار گرفتن کلمات (البته نه به صورت رندوم، بلکه به صورت معنادار) ساخته میشن و معنای هر کلمه نقش مهمی تو رسوندن معنای کل جمله داره. کوچیکترین ساختار قابل فهمی که میشه یک جمله رو بهش شکست کلمهست. تو این مرحله میتونیم بگیم که هر کلمه چه نقشی رو در جمله ایفا میکنه. مثلاً عبارت "گربه گوگولیِ کنارِ در" رو در نظر بگیرید. تو این عبارت کلمهای مثل "گربه" و "در" اسمه، یا کلمه "گوگولی" صفته، یا کلمه "کنار" تو این جمله نقش حرف اضافه داره.
اگه یه سطح از کلمه بالاتر بیایم و چند تا کلمه رو کنار هم قرار بدیم میتونیم عبارت بسازیم. مثلاً "گربه گوگولی" یا "کنار در" خودشون به تنهایی یک عبارت هستن. حتی میتونیم عبارتهای کوچیک کوچیک رو باهم ترکیب کنیم و عبارات بزرگتری رو بسازیم. مثل همین عبارت "گربه گوگولیِ کنارِ در" که یکم بالاتر دیدیم.
این ساختار سلسله مراتبی زبانی که میاد از کلمه به عبارت و از عبارت به عبارتهای بزرگتر میرسه رو میشه با Context-Free Grammar (CFG) مدل کرد.

قرار نیست وارد جزییات CFG بشیم، فقط یک مثال ازش میبینیم که بفهمیم کلیاتش به چه صورته.
قضیه از این قراره که ما یک سری قانون و گرامر و یک سری lexicon یا واژگان برای عبارات تعریف میکنیم. مثلاً عبارت the cat شامل دو واژه the و cat هست از طرفی یک noun phrase عه که تشکیل شده از دو واژه یکی با نقش determiner و دیگری با نقش noun. پس برای گرامر و واژگان به ترتیب داریم:
Rules:
NP -> Det N
Lexicon:
N -> cat
Det -> the
حالا اگه عبارت a dog رو هم اضافه کنیم گرامر که ثابته ولی واژگانمون به این صورت آپدیت میشه:
Rules:
NP -> Det N
Lexicon:
N -> cat, dog
Det -> the, a
حالا اگه گرامرهای زیر رو به قوانینمون اضافه کنیم:
NP -> Det (Adj)* N (PP)
PP -> P NP
به کمکش میتونیم عباراتی مثل a large barking dog on the table رو هم بسازیم. منظور از PP در واقع prepositional phrase هست، عباراتی مثل on the table یا by the door از این جنس هستن (حرف اضافه + noun phrase). پرانتزها در گرامر نشون میدن که اون نقش در عبارت میتونه باشه یا نباشه و علامت ستاره به این معنیه که صفر بار یا بیشتر اون عبارت تکرار بشه. مثلاً گرامری که بالا تعریف کردیم هم میتونه a dog on the table رو ساپورت کنه، هم a large brown barking dog رو هم حتی a dog رو.
حالا اگه بخوایم دو تا عبارت فعل دار talk to و walked behind رو اضافه کنیم، باید قوانین رو هم آپدیت کنیم:
VP -> V PP
و اگه بخوایم جملهای مثل the cat walked behind the dog رو ساپورت کنیم برای گرامر داریم:
S -> NP VP
پس گرامر و واژگانی که برای عبارتها و ساختارهایی که تا اینجا بررسی کردیم به صورت زیر در میاد:
Rules:
NP -> Det (Adj)* N (PP)
PP -> P NP
VP -> V PP
S -> NP VP
Lexicon:
N -> cat, dog
Det -> the, a
P -> in, on, by
V -> talk, walked
عبارات بالا از اسلاید زیر انتخاب شدن:

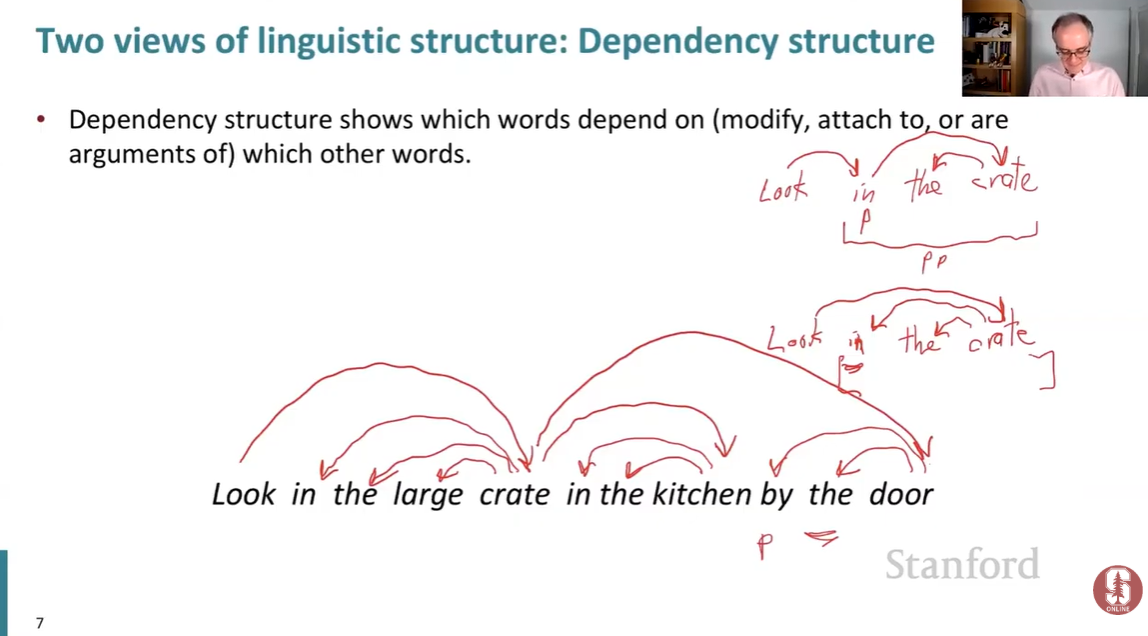
به صورت کلی، ساختار وابستگی نشون میده که کدوم واژهها به کدوم واژههای دیگه وابستگی دارن. به عبارتی دیگه، یعنی اون واژههارو توصیف میکنن، بهشون متصلن، یا جزءهای معنایی اونها هستن.
برای مثال اسلاید زیر رو در نظر بگیرید. مثلاً تو عبارت large crate واژه large توصیفکننده واژه crate عه. یا واژه the توصیفکننده crate عه. تو این مثال واژه look ریشه یا head جملهست. به این دلیل که تمامی کلمات به یه طریقی به crate وابستهن و خود واژه crate به look وابستهست.
در یک کلمه، نیاز داشتیم درک و فهمی که خودمون بعنوان انسان از زبان داریم رو به نحوی مدل کنیم (مدلهای زبانی بسازیم) تا در نهایت کامپیوترها بتونن زبان ما رو بفهمن.

بعضی ساختارها در زبان انسان وجود داره که پیچیدگی خاصی دارن، شاید مغز انسان به صورت خودکار بتونه این پیچیدگیهارو تشخیص بده و اصلاً حتی بهشون فکر هم نکنه، ولی درکشون برای سیستمها و کامپیوترها دشواره. در ادامه قراره تعدادی از این ابهامات و پیچیدگیهارو بررسی کنیم که از نظر نحوی و صرف کاملاً درست هستن، اما از نظر معنایی ممکنه نادرست باشن.
جمله زیر رو در نظر بگیرید:
San Jose cops kill man with a knife
یک معنایی نه چندان صحیح که میشه از این عبارت داشت به این صورته که San Jose cops فاعل و کننده کار باشه و man رو با knife کشته باشه. ساختار وابستگی تو این حالت به صورت زیر در میاد:

معنای صحیحتر این عبارت به این صورته که San Jose cops همچنان فاعل و کنندهی کاره و یک نفر رو هم کشته، اما کسی که کشته مردی بوده که چاقو داشته، نه اینکه San Jose cops با چاقو مرد رو کشته باشه. یعنی عبارت with knife توصیف کنندهی کلمه man به حساب میاد. به صورت صحیحتر noun modifier برای man به حساب میاد.

مثال دیگهای رو ببینیم:
Scientists count whales from space
این جمله هم میتونه ابهام آمیز باشه. معنای ناصحیحش به این صورته که دانشمندان نهنگهایی که از فضا اومدن رو میشمرن و معنای صحیحش به این صورته که دانشمندان نهنگهارو از فضا و مثلاً به کمک ماهوارهها میشمرن.

این مثالها و ابهاماتی که بررسی کردیم به صورت خاص در زبان انگلیسی وجود داره، شاید تو زبان چینی یا ژاپنی دقیقاً چنین ابهامی از نظر زبانی و ساختار زبانی نداشته باشیم، ولی هر زبان انسانی، قطعاً ساختارهای ابهامگونه داره. منظور ساختارهایی هست که از نظر صرف و نحو کاملاً صحیحن، اما از نظر معنایی ایراد دارن.
حتی عباراتی وجود دارن که میشه براشون چندین ساختار وابستگی و تحلیل نحوی مختلف داشت. مثلاً عبارت زیر رو در نظر بگیرید:
The board approved [its acquisition] [by Royal Trustco Ltd.] [of Toronto] [for $27 a share] [at its monthly meeting].
تو این عبارت چهارتا prepositional phrases داریم و هر کدوم از این گروهها ممکنه به اجزای مختلفی در جمله وابسته باشن. یکی از روشها برای نشون دادن نحوه ارتباط و اتصال بینشون اینکه به صورت زیر عمل کنیم:

از اونجایی که هر PP میتونه به اجزای مختلفی وصل بشه تعداد ترکیبهای ممکن برای تفسیر جمله هم خیلی زیاد میشه. منظور از خیلی زیاد واقعاً خیلی زیاده. به صورت نمایی زیاد میشه. زبانشناسها به این نتیجه رسیدن که این تعداد از دنباله اعداد کاتالان پیروی میکنه. در نتیجه، تحلیل نحوی (parsing) در زبان طبیعی (زبان انسان) از نظر محاسباتی واقعاً پیچیده است.
خبر بد اینه که در عمل هیچ راهی وجود نداره تا این ابهامها رو بهطور کامل برطرف کنیم. مثلاً نمیتونیم زبان طبیعی رو شبیه زبانهای برنامهنویسی طراحی کنیم، چون زبانهای برنامهنویسی عمداً طوری ساخته شدن که چنین ساختارهای ابهامآمیزی در اونها وجود نداشته باشه و همیشه فقط یک تحلیل نحوی ممکن باشه. به خاطر همینه که پردازش و درک زبان طبیعی برای ماشینها چالشبرانگیزه، چون باید از بین چندین تفسیر ممکن یکی رو انتخاب کنن.
بریم مثال دیگهای رو با ابهام دیگهای بررسی کنیم.
جمله اسلاید زیر رو در نظر بگیرید. دو برداشت متفاوت میشه از این جمله داشت. معنای ناصحیح اینکه انگار دو نفر به هیئت مدیره منصوب شده باشن. در حالیکه معنای صحیح به این صورته که یک نفر که دو عنوان مختلف داشته به عنوان هیئت مدیره منصوب شده.

یه مثال دیگه که باز هم از تیترهای روزنامههای واقعی انتخاب شده رو بررسی کنیم.
Doctor: No heart, cognitive issues
یک معنی میتونه این باشه که مشکل قلبی وجود نداره، تنها مشکلی که وجود داره مشکلات cognitive (شناختی) است. معنی دیگه میتونه این باشه که هیچگونه مشکل قلبی و شناختی وجود نداره. تو این حالت انقدر ابهام زیاده که حتی نمیشه تشخیص داد کدوم معنی صحیحتره.

ابهام دیگهای در زبان انگلیسی میتونه به وجود بیاد وقتی که چند صفت پشت سر هم قرار میگیرن. مثلاً عبارت زیر رو در نظر بگیرید:
Students get first hand job experience
معنای صحیح به این صورته که first و hand رو باهم در نظر بگیریم و معنای جمله بشه دانشجویان تجربهی کاریِ دستاول (یا مستقیم) بهدست میارن. معنای ناصحیح وقتی پیش میاد که hand و job باهم در نظر گرفته بشن (!) و معنای جمله بشه دانشجویان اولین تجربهی چیز به دست میارن! حالا کی میدونه تو مغز نویسنده این مقاله چی میگذشته، شاید واقعاً منظورش مورد دوم بوده!

یک مثال دیگه رو هم ببینیم که باز هم از یک تیتر خبری واقعی انتخاب شده!
Mutilated body washes up on Rio beach to be used for Olympics beach volleyball
از نظر نحوی میشه دو حالت مختلف برای جملهای که اومده در نظر گرفت. یک بار به این صورت که عبارت to be used به فعل washes up بستگی داشته باشه، یک بار هم به این صورت که عبارت to be used به اسم Rio beach بستگی داشته باشه. که هیچ ایرادی هم بهشون وارد نیست، اما از نظر معنایی بینشون زمین تا آسمون فرق هست. معنای نادرست عبارت به صورت میشه که بدن تکهتکهشدهای در ساحل ریو پیدا شد تا برای والیبال ساحلی المپیک استفاده شود. در حالیکه معنای درست جمله به این صورته که بدن تکهتکهشدهای در ساحل ریو پیدا شد، همان ساحلی که قراره برای والیبال ساحلی المپیک استفاده شود.

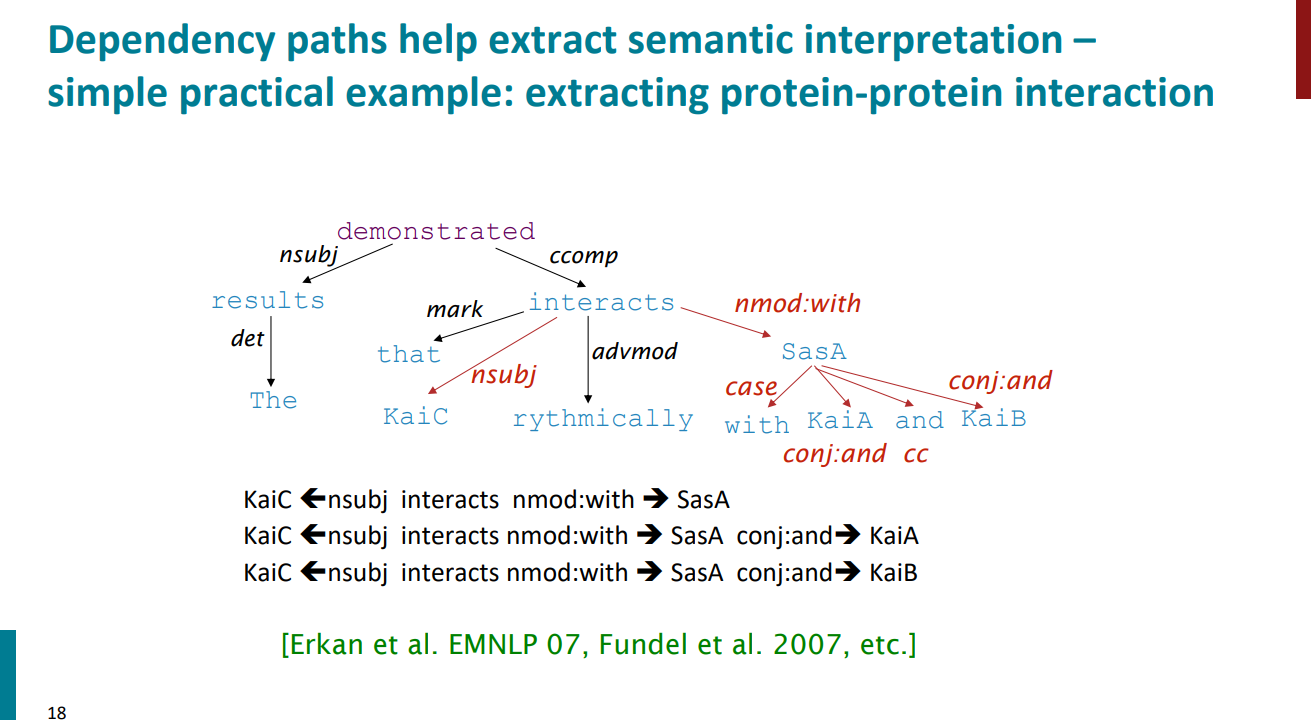
یک مثال دیگه ببینیم که چطور با استفاده از dependency parsing (تجزیه نحوی) میشه بدون نیاز به درک معنای کلی متن، و فقط از روابط نحوی بین کلمات روابط معنایی مثل تعامل بین پروتئینها رو استخراج کرد. جملهای که آورده شده اینه:
The results demonstrated that KaiC rhythmically interacts with SasA, KaiA and KaiB.
به کمک تجزیه نحوی میشه نشون داد که KaiC فاعل interacts هست و SasA مفعول غیر مستقیم interacts که با حرف اضافه with اومده. همچنین اینکه چطور حرف ربط and دیگر مفعولها رو مثل KaiA , KaiB بهم متصل کرده.
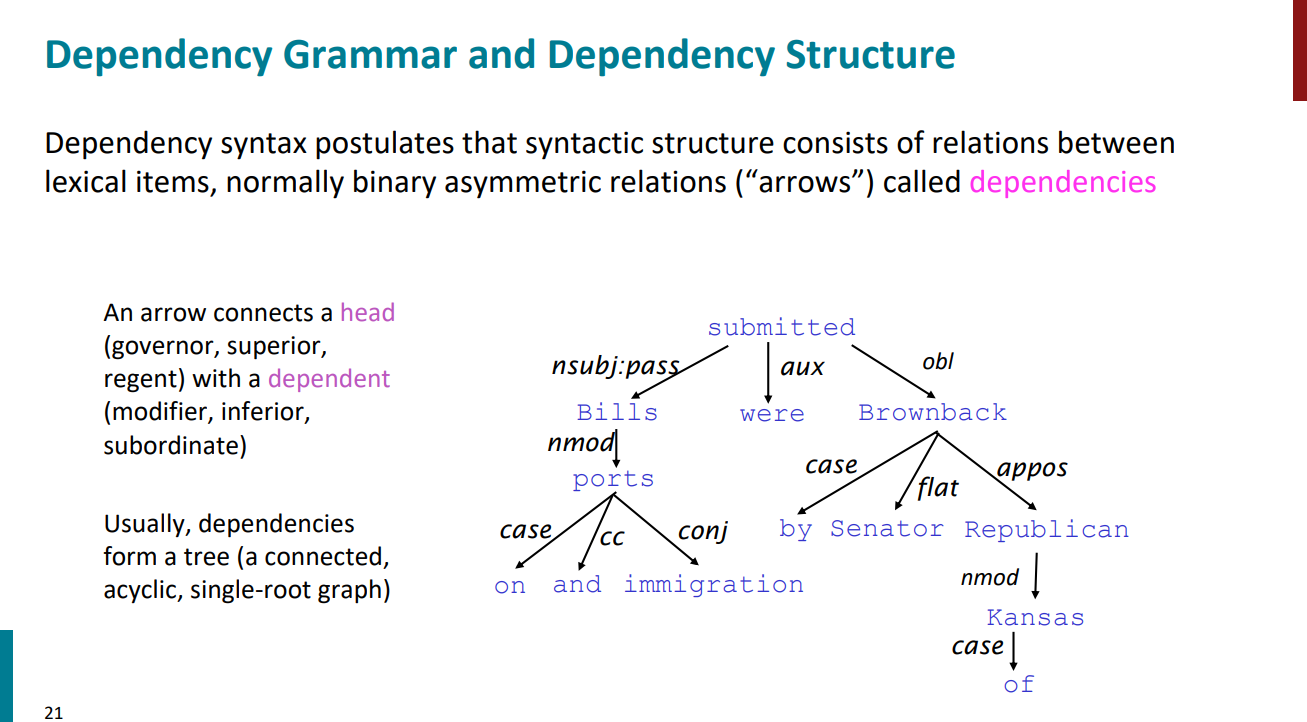
در زبان شناسی فرض dependency syntax اینکه ساختار نحوی جملات صرفاً از روابط بین کلمات تشکیل شده. یک کلمه head در نظر گرفته میشه، و کلمه بعدی وابسته به head و با یک پیکان از head به کلمه وابسته بهش این ارتباط نمایش داده میشه. در واقع نمایش جملات در نهایت به صورت یک درخت بین واژهها در میاد. منظور از درخت اینکه حلقه نداریم و برای هر جمله فقط یک head یا کلمه اصلی وجود داره که بعنوان ریشه درخت در نظر گرفته میشه.
تاریخچهی دستور وابستگی (Dependency Grammar) و تحلیل وابستگی (Dependency Parsing) به خیلی وقت پیش بر میگرده. اولین بار این ایده 5 قرن قبل از میلاد توسط Panini که یک زبان شناس هندی بود مطرح شد.
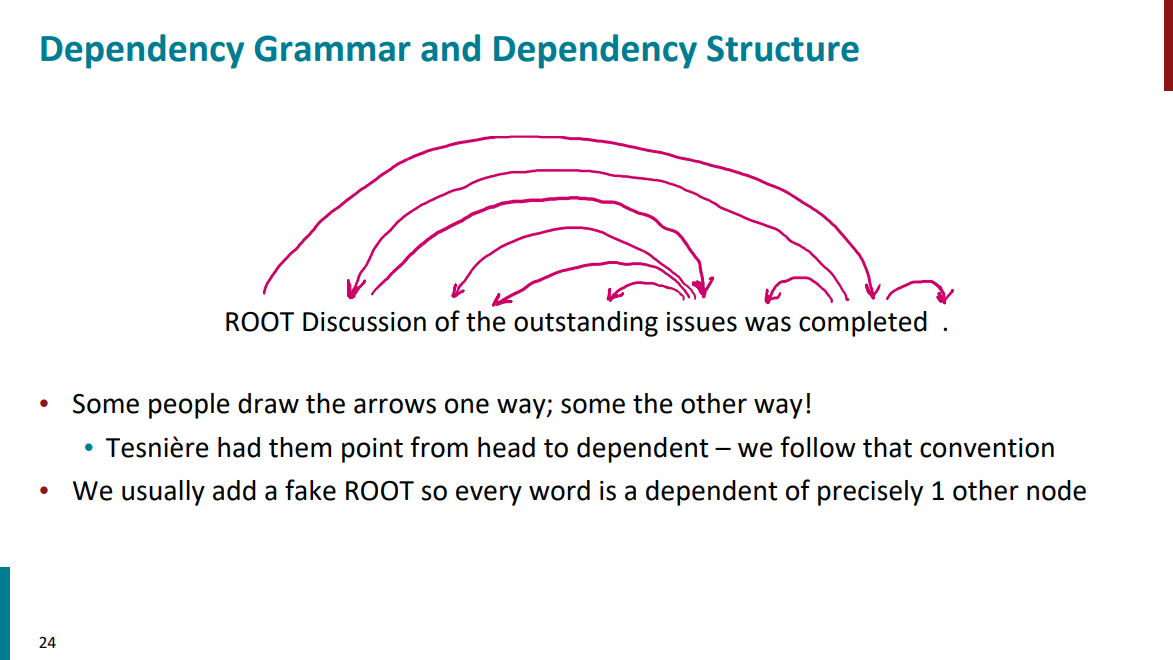
نسخهی مدرن دستور وابستگی به یک زبانشناس فرانسوی به اسم لوسین تسنییر (Lucien Tesnière) نسبت داده میشه که در سال 1959 مطرح شد. این نوع دستور در کشورهایی مثل روسیه و چین خیلی محبوب شد، چون برای زبانهایی که ترتیب کلمات درشون آزادتره (مثل روسی یا حتی فارسی) خیلی بهتر جواب میده.

دو مدل برای مشخص کردن کلمات ریشه یا head و کلمات وابسته بهشون وجود داره. در مدل اول که یکم بالاتر هم مشخص کردیم یک فلش از سمت کلمه head به کلمه وابسته بهش رسم میشه. در مدل دوم هر دو طرف پیکان فلش داره. مدل اول مرسومتره و ازش یک مثال هم در اسلاید پایین آورده شده.
از خیلی سالها قبل زبان شناسان و متخصصان NLP شروع کردن به برچسب زدن نقش جملات مختلف در جملات انگلیسی و یه پیکره خیلی بزرگ رو شامل میلیونها کلمه درست کردن که بهشون treebank گفته میشه. یه قسمت خیلی کوچیک ازش بعنوان مثال تو اسلاید پایین آورده شده. تو هر جمله کلمه head با رنگ سبز و بقیه کلمات وابسته با رنگ آبی مشخص شدن. اینکه هر کلمه چه نقشی داره یا با چه رابطهای به کلمات دیگه متصل میشه هم مشخص شده.

ممکنه سوال پیش بیاد که چرا اصلاً نیازه این همه وقت و انرژی بذاریم و به صورت دستی این treebankها رو بسازیم؟ اصلاً چه مزایایی برامون دارن؟
اول اینکه وقتی یک بار ساخته بشن، میتونیم بارها و بارها برای کاربردهای متفاوت ازشون استفاده کنیم. دوم اینکه به کمک treebankها (که شامل میلیونها کلمه و جمله هستن) مثالهای واقعی و بیشتری داریم که میتونیم تو موارد مختلف ازشون استفاده کنیم. سوم اینکه منبع خیلی مهمی برای اطلاعات آماری ان. مثلاً به کمکشون میتونیم بفهمیم که بعد از هر کلمه، کلمه بعدی با چه احتمالی ممکنه بیاد و به صورت کلی الگوهای توزیع واژههارو تحلیل کنیم. و در نهایت میتونیم ازشون برای ارزیابی سیستمهای NLP استفاده کنیم. مثلاً مدلهای زبانی یا parserهای مختلف رو باهاشون بسنجیم و خروجیشونو مقایسه کنیم.

اگه بخوایم یه parser یا تحلیلگر نحوی بسازیم با این هدف که به کامپیوترها کلمات head و وابستههاشونو بشناسونیم چجوری عمل میکنیم؟ به عبارتی دیگه، برای ساختن parser از چه نشانههایی در جمله استفاده میکنیم؟ در واقع چهار مورد هست که parserها از اونها برای شناسایی کلمات head و وابستههاشون استفاده میکنن:
مورد اول - وابستگی دو کلمهای: یک سری کلمات هستن که معمولاً باهم دیگه میان و بعد از دیدن تعداد زیادی نمونه و جمله قابل تشخیص میشن. مثلاً دو کلمه "discussion" و "issues" اینطورن که بعنوان مثال تو اسلاید پایین آورده شده.
مورد دوم - فاصلهی وابستگی: هرچی فاصله بین کلمات کمتر باشه معمولاً وابستگی بینشون بیشتره. مثلاً تو زبان انگلیسی فاعل بعد از فعل میاد و از این نزدیکی بین دو کلمات میشه وابستگی بینشون رو تشخیص داد.
مورد سوم - intervening material یا به فارسی مواد بینابینی: به این معنیه که کلماتی که بهم وابسته هستن معمولاً از روی فعلهای دیگه یا punctuationها رد نمیشن. به عبارتی دیگه، اگه بین دو تا کلمه یک فعل یا یک علامت نگارشی مثل ویرگول قرار بگیره، احتمال اینکه اون دو کلمه بهم وابستگی داشته باشن کمتره.
مورد چهارم - ظرفیت نحوی head: به این معنیه که هر head میتونه تعداد محدودی کلمات وابسته در سمت چپ یا راستش داشته باشه. مثلاً یک فعل نمیتونه چند تا فاعل داشته باشه! معمولاً فقط یک فاعل داره.
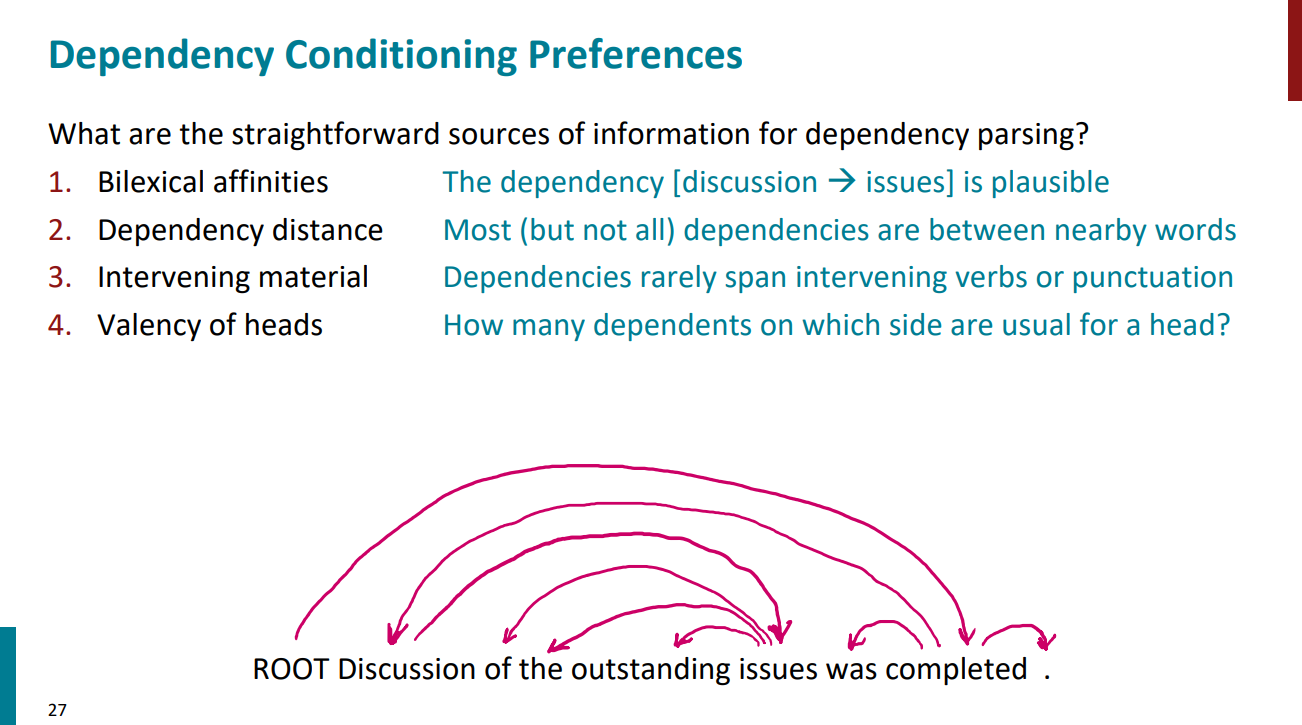
یک مثال رو بررسی کنیم. تو جملهی زیر:
I'll give a talk tomorrow on neural networks
فعل give ریشه یا head جملهست و بقیه کلمات به نحوی بهش وابستگی دارن. مثلاً کلمه talk به give وابستهست یا کلمه I'll هم به give وابستهست. کلمه tomorrow هم به کلمه give وابستگی داره. حالا کلمه talk خودش head کلمات a و networks به حساب میاد و کلمه network هم head کلمات on و neural حساب میشه.
قبلتر گفتیم که روابط بین کلمات به صورت یک درخت نمایش داده میشه که گرافی هست که دور نداره. به این معنی که دو تا کلمه نمیتونن هم head باشن هم وابسته باشن. مثلاً تو ترکیب neural network که تو جمله پایین اومده network ریشه کلمهست و neural بهش وابستهست. این رابطه نمیتونه به صورت برعکس هم برقرار باشه. همواره فقط یکی از کلمات head به حساب میاد.
هر جمله همواره فقط یک root داره. نمیتونیم جملهای داشته باشیم که شامل بیشتر از rootباشه.
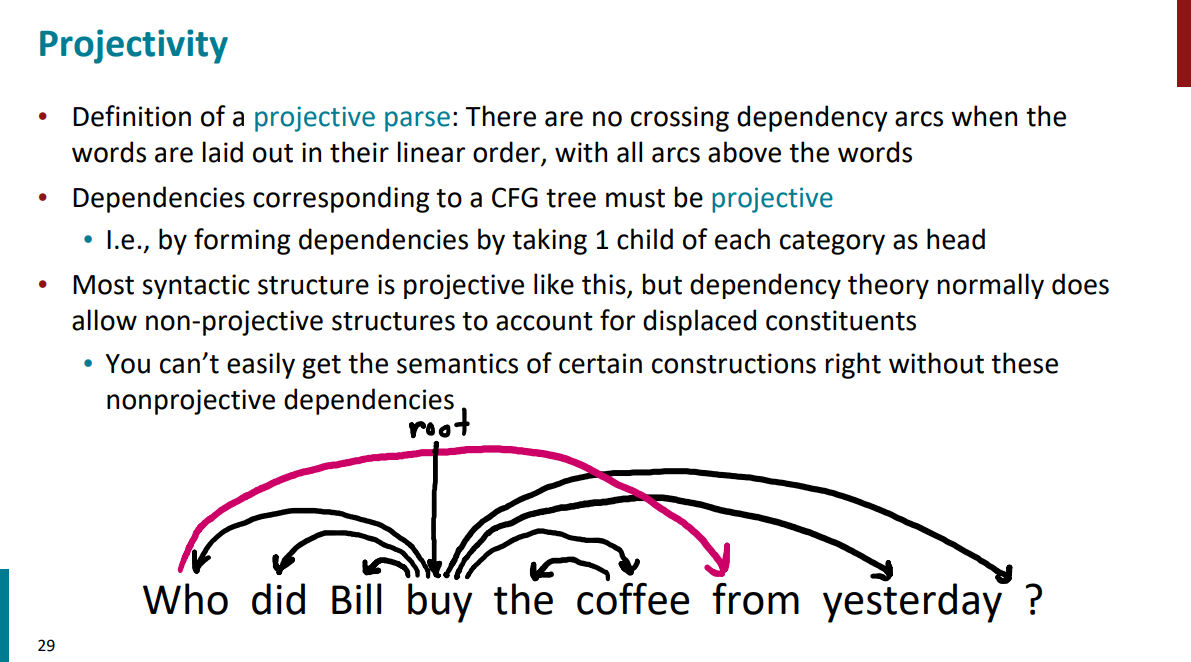
حالا سوال ممکنه پیش بیاد اگه این فلشهایی که تو جملات روابط رو مشخص میکنه از هم رد بشن ایراد داره یا نداره؟ مثلاً تو جملهای که مثال زدیم این اتفاق یک بار افتاده و تو اسلاید پایین هم مشخصه. جواب اینکه اگه از رو هم رد نشن جملهای که داریم projective به حساب میاد و سادهتر و منظمتره. اگر رد بشن جمله non-projective به حساب میاد و وابستگیها بیشتر در هم تنیده شدن.

گفتیم اگر پیکانهایی که روابط بین کلمات رو در جملات مشخص میکنن از روی هم رد بشن یعنی جمله non-projective عه و اگر از روی هم رد نشن، جمله projective عه. به عبارتی دیگه، این ساختارها برای نشون دادن عناصر جابجا شده (displaced constituents) یا وابستگیهای از راه دور (long-distance dependencies) در جمله ضروری هستن. مثلاً تو مثال اسلاید پایین، who و from وابستگی از راه دور دارن.
روشهای مختلفی برای ساختن یک parser وجود داره. منتها در ادامه فقط یک مورد که به صورت حریصانه عمل میکنه رو قراره با جزییات بررسی کنیم و با بقیه روشها خیلی کاری نداریم.

یکی از روشها برای تحلیل نحوی (پارسر - parser) جمله (تشخیص اینکه کدوم کلمهها به کدوم کلمهها وابستگی دارن) استفاده از تجزیهگر Transition-Based است که به صورت حریصانه عمل میکنه. به صورت کلی، این روش دنبال اینکه هر دفعه برای هر کلمه بهترین ارتباط وابستگی رو در همون لحظه بسازه.
از چهار جز اصلی ساخته شده:
یک - استک که با σ نشون داده میشه و یه جور حافظهست و برای نگه داشتن کلمات در حال بررسی ازش استفاده میشه. اول کار فقط شامل کلمه ROOT هست.
دو - بافر که با β نشون داده میشه و شامل تمام کلمات پردازش نشدهست. اول کار تمام کلمات رو در بر میگیره.
سه - مجموعهای از وابستگیها که با A نشون داده میشه و اول کاری خالیه. در واقع روابط رو در خودش نگه میداره.
چهار - یک مجموعه از اکشنهایی که تو هر مرحله میشه انجام داد. مثل shift یا کاهش (reduce). در ادامه بیشتر باهاشون آشنا میشیم.

همه چیزایی که بالاتر گفتیم به صورت نمادین تو اسلاید پایین نشون داده شده. اول کار استکمون فقط حاوی ROOT هست و بافر هم شامل تمام کلمات متن. از اونجایی که هنوز هیچ رابطهای رو مشخص نکردیم، مجموعه A هم خالیه. سه تا اکشن داریم، که هر دفعه برای هر کلمه یکی از اکشنها انتخاب میشن:
اکشن اول - shift که میاد کلمه بعدی رو داخل استک میذاره.
اکشن دوم - کاهش left-arc که میاد کلمه چپی رو وابسته کلمه سمت راستی میکنه.
اکشن سوم - کاهش right-arc که میاد کلمه راستی رو وابسته کلمه سمت چپی میکنه.
اکشن کاهش هر دفعه میاد دو تا کلمه رو از استک بر میداره و یکیشو head در نظر میگیره و یکی دیگه رو وابسته head.
بعد اینکه اکشن کاهش انجام شد و رابطه وابستگی بین دو کلمه در اومد، کلمه head از استک حذف میشه و رابطه وابستگی داخل مجموعه A قرار میگیره.

بریم یک مثال ببینیم که این روش چطور در عمل کار میکنه. جملهای که داریم I ate fish هست. اکشن اولی که استفاده میکنیم شیفته. اولین کلمه یعنی I رو به استک اضافه میکنیم. اکشن دوم هم باز شیفته و کلمه دوم هم به استک اضافه میشه.
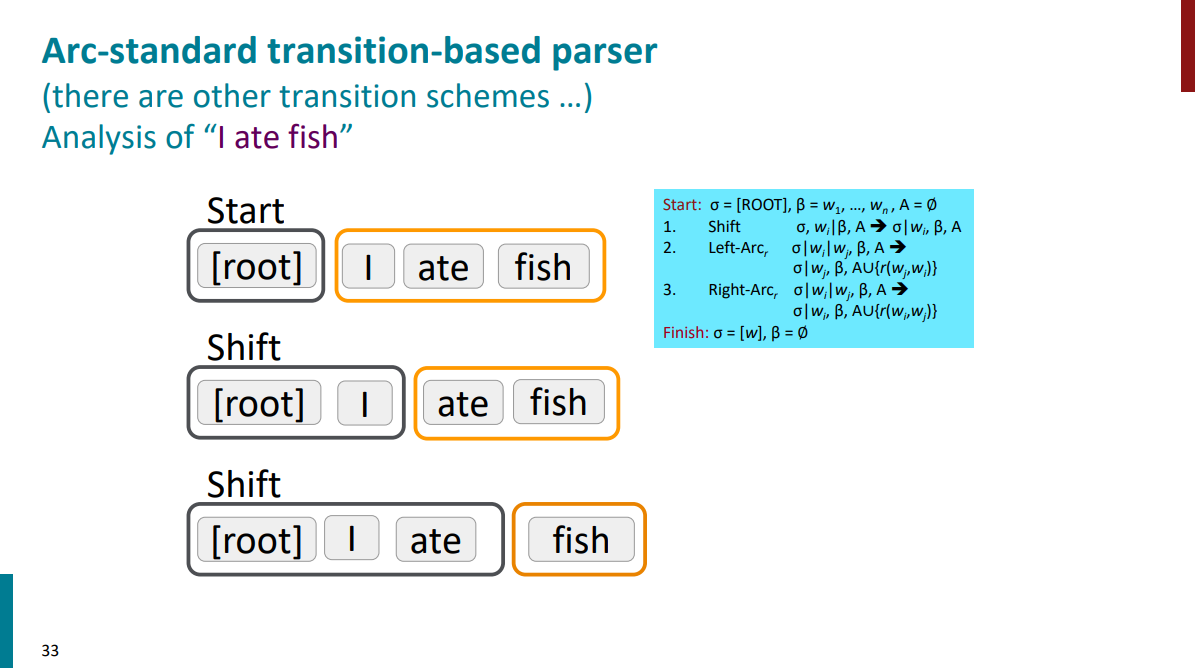
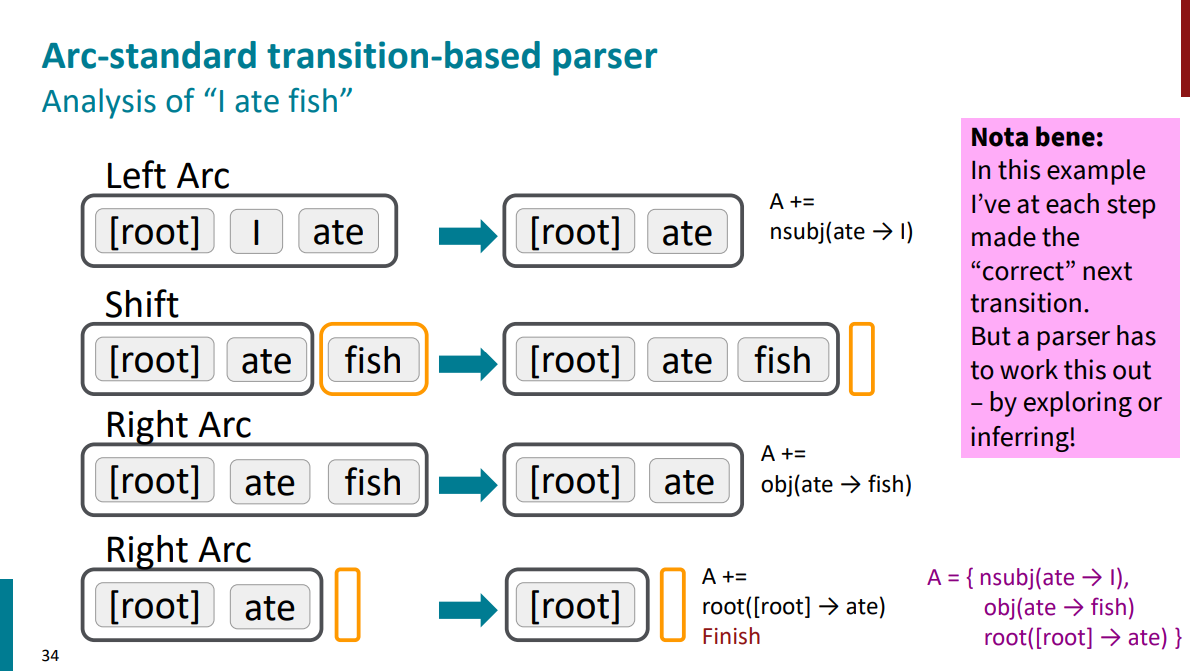
اکشن سوم کاهش left-arc هست و باعث میشه که کلمه I وابسته کلمه ate بشه. بعد از اینکه رابطه وابستگی (به این صورت که I فاعل ate هست) به مجموعه A اضافه شد، کلمه I از استک حذف میشه و میریم سراغ اکشن بعدی که شیفته و باعث میشه کلمه آخر یعنی fish به استک اضافه بشه.
اکشن پنجم کاهش right-arc عه و باعث میشه کلمه fish وابسته کلمه ate بشه. بعد اینکه رابطه وابستگی بین fish و ate به مجموعه A اضافه شد (به این صورت که کلمه fish مفعول کلمه ate هست)، کلمه fish از استک حذف میشه.
در نهایت دو کلمه ROOT و ate رو تو استک داریم که اکشن کاهش right-arc روش اعمال میشه و رابطه وابستگیشون به مجموعه A اضافه میشه و به این معنیه که ROOT جمله کلمه ate هست.
ممکنه سوال پیش بیاد که این اکشنها در هر مرحله چطور انتخاب میشن؟ مثلاً توی همین مثال بالا چرا اکشن دوم به جای شیفت کاهش نبود؟ یکی از به صرفهترین روشها برای انتخاب اکشنها در هر مرحله اینکه بیایم به کمک یادگیری ماشین یک کلاسیفایر بنویسیم و مواردی مثل POS (اینکه کلمه در جمله چه نقشی داره، اسمه، صفته، فعله و ...) یا آخرین کلمه استک به همراه POSش یا اولین کلمه بافر به همراه POSش رو بعنوان فیچر بدیم بهش و در نهایت ازش بخوایم که بهترین اکشن رو برامون انتخاب کنه. با این کار پیچیدگی زمانی به صورت خطی میشه (از حالت نمایی در میاد) و میتونیم در کوتاهترین زمان ممکن بهترین خروجی رو از پارسر داشته باشیم!

فیچرهارو به صورت بردارهای باینری میسازن. معمولاً هم ابعاد خیلی بزرگی دارن و هم اینکه خیلی اسپارس هستن (یعنی تعداد خیلی زیادی صفر دارن). مثلاً یکی از فیچرها میتونه این باشه که ایا بین دو کلمهای که تو استک داریم رابطه فعل و فاعلی برقرار هست؟ اگر باشه اون فیچر مربوطه 1 میگیره و اگر نه 0 میگیره.
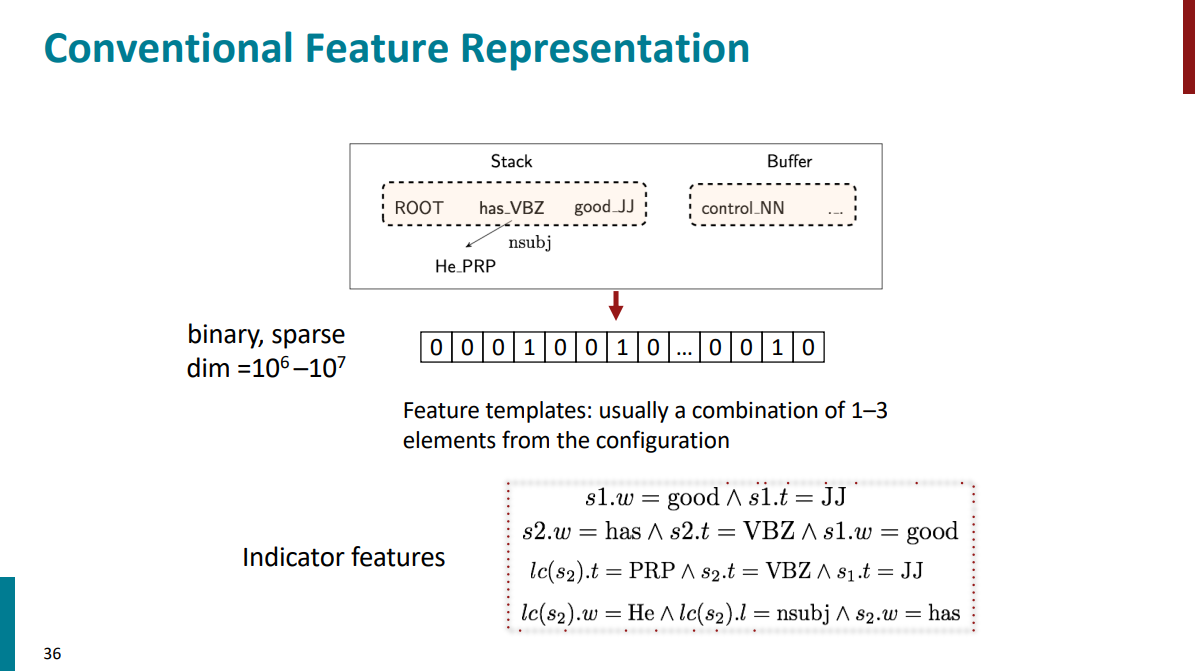
خیلی بالاتر اشاره کردیم به این موضوع که به صورت دستی یک سری treebankهایی رو افراد متخصص تو حوزه NLP طی سالهای مختلف ساختن و یکی از جاهایی که میشه از این treebankها استفاده کرد برای ارزیابی parserهایی هست که نوشته میشن.
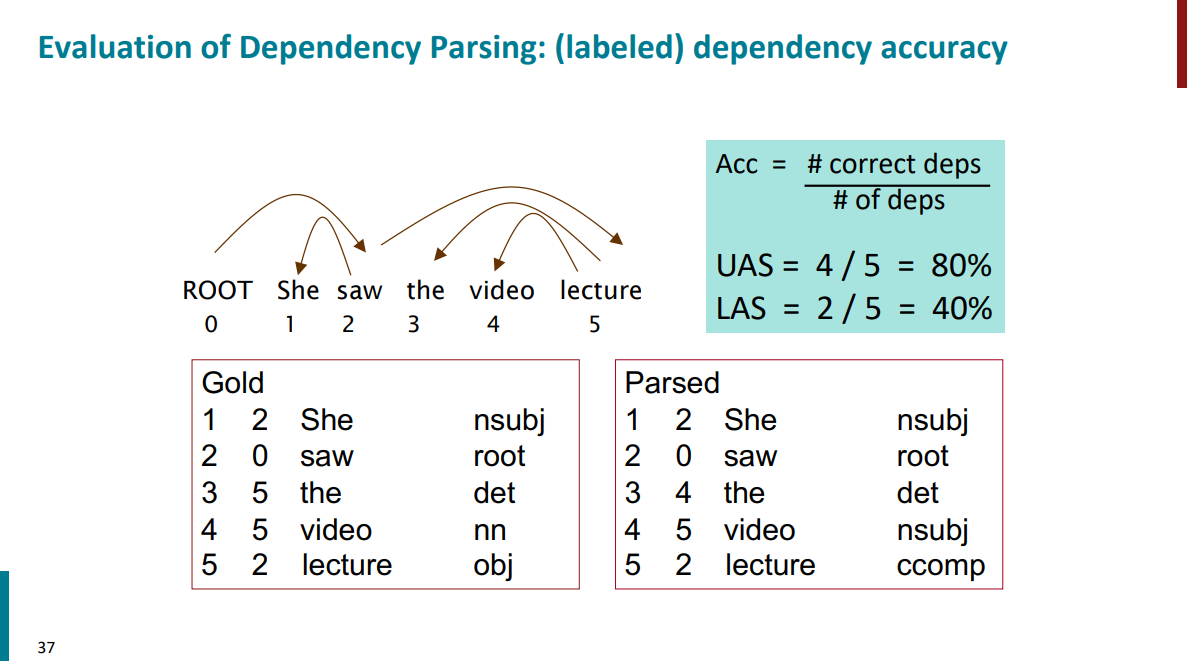
از اونجایی که تصمیم گیری برای اکشنها در هر مرحله توسط یک مدل اتفاق میفته، نیازه که در نهایت مدلمون رو ارزیابی کنیم و ببینیم که نتیجهای که ازش میگیریم چقدر به خروجی کار آدمها نزدیک بوده. مثلاً تو اسلاید پایین سمت چپ داره انواع وابستگی که توسط آدمها انجام شده رو نشون میده در حالیکه سمت راست خروجی یک پارسره که حاوی یک مدل هوش مصنوعیه. میشه معیارهای مختلف رو برای مقایسه نتایج مثل Accuracy تعریف کرد و دید که عملکرد پارسر در نهایت به چه صورت بوده.
با تحلیل نحوی جملات آشنا شدیم و دیدیم که چقدر تحلیلهای نحوی زبان حتی برای انسانها میتونه دشوار و چالش برانگیز باشه. مثالهای مختلفی از ابهامات زبان طبیعی رو بررسی کردیم و دیدیم که چطور حتی با ساختار نحوی درست، معنای جملات میتونه کاملاً متفاوت باشه. دیدیم که چطور کامپیوترها میتونن تحلیل نحوی انجام بدن و با یکی از پارسرها که به صورت حریصانه عمل میکنه هم آشنا شدیم.
اگر جایی ایراد یا مشکلی بود، حتماً بهم بگید تا تصحیح کنم. اگر هم پست رو دوست داشتید و محتواش به دردتون خورد، میتونید یه قهوه مهمونم کنید!
جزوه جلسه بعدی (جلسه پنجم) - به زودی