اول اینکه عنوان این مطلب اصلا چیزی که میخوام نیست ولی بهتر از این نمیشد.
یک کنجکاوی ای که من همیشه نسبت به سرویس Premium یوتوب داشتم این بود که شما میتونین ویدئو رو دانلود کنین و بعدا حتی آفلاین هم بهش دسترسی داشته باشین. اما یوتوب همینطوری بهتون یه فایل mp4 یا مشابه اش رو نمیده، یعنی عملا شما برای استفاده از اون محتوا باید مجدد وارد یوتوب بشید و برید قسمت دانلود هاتون و اونجا بهشون دسترسی دارید.
سوال بزرگ اینجاست که پس این ویدئو ها کجا ذخیره میشن؟ اصلا چطور این ذخیره سازی صورت میگیره و نحوه کارش چطوریه؟ و از اون جذاب تر: چطور میتونیم خودمون یه مدل مشابه (خیلی البته ساده تر) رو پیاده سازی کنیم؟!

برای اینکه مساله رو بررسی کنیم، بذارید توی چند قدم کلی و ساده موضوع رو ببینیم:
همین!
یوتوب کلا یکی از BadASS ترین سرویس هایی هست که اون بیرون وجود داره، توضیح کار هایی که پشت پرده داره اتفاق میوفته (کاری با الگوریتم و درآمدزاییش و ... ندارم) کار خیلی مشکلیه. ولی برای اینکه در ساده ترین حالت ممکن موضوع رو ببینیم این اتفاقیه که میوفته:
یک فرد به عنوان تولید کننده یک محتوای ویدئویی، با یک کیفیت مشخص مثلا در نظر بگیریم به صورت 4K یک ویدئو رو تهیه میکنه و از طریق یوتوب اون رو آپلود میکنه. در زمانی که ویدئو آپلود میشه، سرویس های داخلی یوتوب ویدئو رو با کیفیت های مختلف تبدیل و در یه فضایی (ما نمیدونیم کجا) ذخیره میکنن. این یعنی با وجودی که محتواساز ویدئو رو با بالاترین کیفیت آپلود کرده ولی کیفیت های پایین تر اون ویدئو هم ذخیره شدن پس بنابراین ما یک ویدئو داریم با چند کیفیت مختلف. دلیلش هم که دیگه واضحه. (سرعت اینترنت و اندازه screen کاربر و ... و ...)
بعد از اینکه ویدئو روی یک فضایی روی سرور (که ما نمیدونیم کجا) ذخیره شدن، حالا وقتشه که کاربرا بتونن بهش دسترسی داشته باشن. شما زمانی که یه ویدئو رو باز میکنید تا ببینید، حتما دقت کردید که پلیر شما یه مقداری از اونجایی که شما دارید میبینید جلوتره و دانلود شده (یا بهتره بگیم بافر شده):
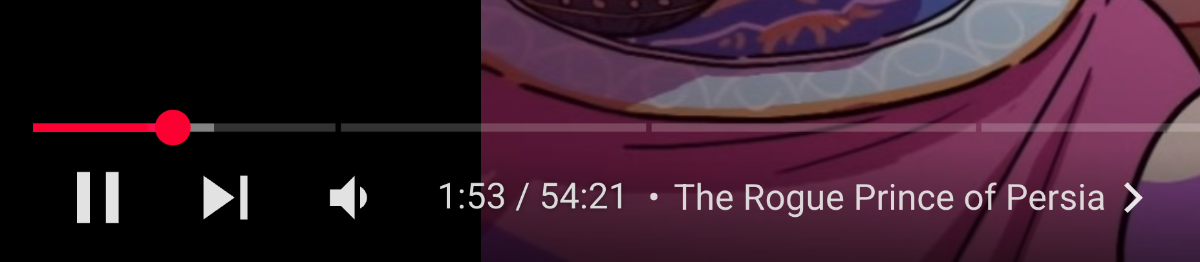
خب یوتوب برای اینکار چند تا قانون هم داره که جالب هستن، با وجودی که این ویدئو نزدیک به ۵۴ دقیقه هست، همیشه این مقدار دانلود شده به یک اندازه محدودی جلوتر میره نه کل ویدئو. یعنی اگه در نظر بگیریم من در دقیقه ۲ باشم، بافر تا دقیقه ۴۰ رو نیازی نیست دانلود کنه حتی اگه من مشکل سرعت اینترنت نداشته باشم) و فقط تا دقیقه ۶ رو داشته باشه براش کفایت میکنه.
برای اینکار هم چندتا دلیل وجود داره:
برای اینکه بتونه این بافر رو به بهترین شکل انجام بده که بهترین تجربه کاربری رو داشته باشه، یوتوب ویدئو رو به قسمت های (چانک) خیلی کوچکتری میشکنه. من نمیدونم دقیقا این الگوریتم دقیقا به چه شکلی اینکارو انجام میده. یعنی برای این ویدئو یک ساعته آیا اون رو به ۶۰ قسمت ۱ دقیقه ای یا ۱۲۰ قسمت ۳۰ ثانیه ای یا ۲۴۰ قسمت ۱۵ ثانیه ای یا ...
یا ممکنه حتی بستگی به حجم و طول ویدئو داشته باشه. ولی اینکار در هر صورت انجام میشه. این کار خیلی مهمه. جلوتر توی پیاده سازی میبینیمش.
برای پخش ویدئو با این تفاسیر نمیشه همینطوری یه فایل MP4 به یه تگ video داده بشه، اگر داریم ویدئو رو به صورت استریم لایو یا تیکه های کوچیک شده دریافت میکنیم نیاز به روشی هم داریم که بتونیم ویدئو رو همینطوری به خورد تگ video بدیم. اینجا میتونیم از MediaSource API استفاده کنیم (در واقع یوتوب هم داره همینکارو انجام میده). به طور خلاصه از طریق این API میتونیم کنترل کامل روی روند پخش ویدئو داشته باشیم، bitrate رو کم و زیاد کنیم، دیتا رو از استریم دریافت کنیم، چانک ها رو خورد خورد اضافه کنیم (به جای اینکه کل فایل رو یکجا لود کنیم).
پس تا اینجا همصفحه شدیم که در ساده ترین شکل ممکن یوتوب ویدئو رو چطوری بهمون نشون میده و ساز کارش به چه شکلیه. البته به شکل خییییییلی ساده شده. (منم یافته های خودم رو گفتم، اگه شما بهتر میدونید حتما بگید)
ما که یوتوب نیستیم، ولی به اندازه کافی کنجکاو هستیم که بخوایم یه سیستم مشابه اش رو پیاده کنیم.
کاری هم با استریم و پخش ویدئو نداریم. تمرکز ما تو این مطلب صرفا زمانی هست که کاربر Premium ویدئو رو دانلود میکنه (به طور کامل) و به صورت آفلاین بهش دسترسی داره. ولی همونطور که میدونید یوتوب برای دانلود فایل MP4 یا MOV یا و... رو در اختیار شما قرار نمیده و در عوض اون رو در یک فضایی (IndexedDB) ذخیره میکنه. این ذخیره سازی هم باید طوری انجام بشه که کسی مثل من نتونه این محتوا رو استخراج و توی یک فایل ذخیره کنه. پس محتوا باید به صورت Encrypt شده ذخیره بشه.
این اتفاقیه که میوفته:
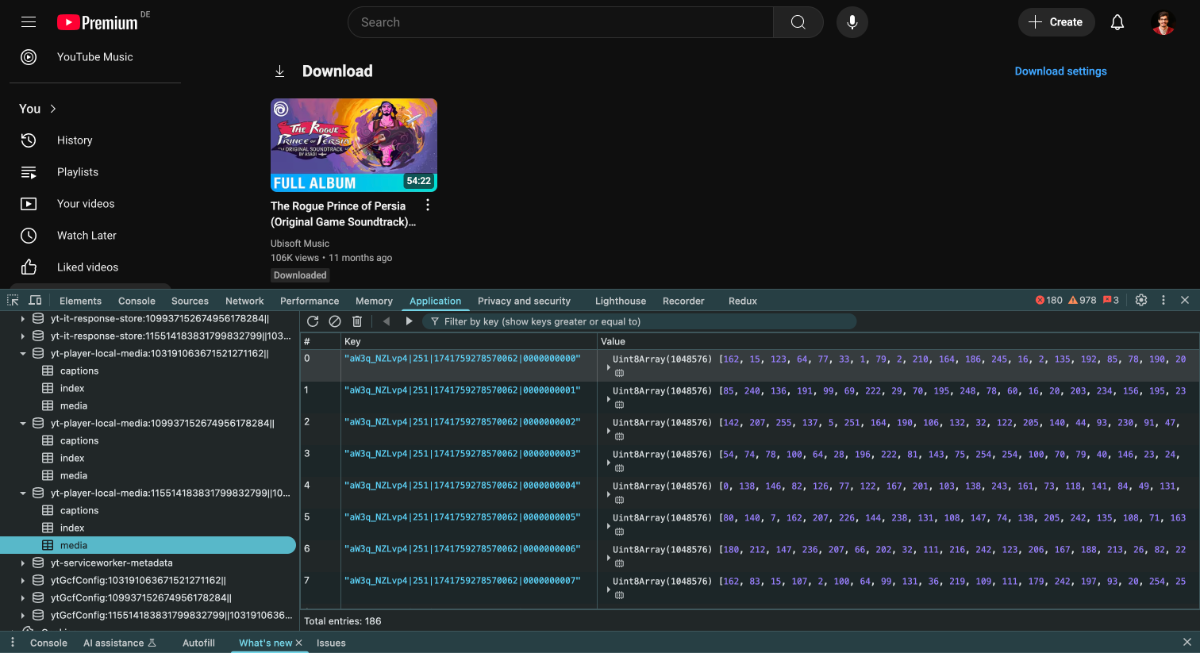
اینجا کامل مشخصه که ویدئو به صورت Chunk های کوچکتر تقسیم شدن و توی یک دیتابیس که با IndexedDB ساخته شده ذخیره شدن. IndexedDB قابلیت ذخیره Blob و یا ArrayBuffer رو داره که میتونیم به کمک همین ها محتوا مون رو ذخیره کنیم. بیاید فعلا در نظر بگیریم محتوای ما به این شکل میتونه ذخیره بشه:

بعدا برای پخش مجدد این ویدئو این ArrayBuffer یا Blob تجمیع میشه که به کمک MediaSource میتونیم اون رو به خورد پلیر بدیم که بتونه اون رو پخش کنه. دقت کنید که مثلا اینجا این chunkIndex مقدارش ۵ هست پس این پنجمین تیکه از n تیکه کل ویدئو هست.
بذارید یکم برگردیم به عقب تر، اصلا چرا IndexedDB؟ چرا Blob یا ArrayBuffer یا MediaSource؟
چرا IndexedDB
اساسا روی وب چند فضا برای برای ذخیره سازی وجود داره (وقتی میگم وب هم منظورم سرور نیست و فقط ساید مرورگر رو میگم): Localstorage, indexedDB و چندتای دیگه.
اگه روی هر کدوم از این فضا های ذخیره سازی یه مطالعه کوچیک بکنیم متوجه میشیم که localstorage فضای بیشتر از 5mb رو نمیتونه ذخیره کنه. Sessionstorage که همینه تازه بین تب ها هم دیتاش اشتراک نمیشه. کوکی هم که اصلا برای کار دیگریه. میمونه همین IndexedDB خودمون که میشه تنها انتخاب ما. قطعا این هم محدودیت هایی داره ولی انتخاب بهتری هم وجود نداره.
چرا Blob و ArrayBuffer
دلیل استفاده از blob خیلی پیچیده نیست. کلا شما اگه بخواید با هر مدلی از فایل توی کد کار کنید باید اون رو به شکل یه آبجکت دریافت کنید. Blob همون آبجکت ماست.

حالا چرا ArrayBuffer؟ اینجا دقیقا همونجایی هست که پیوند بین MediaSource و Blob شکل میگیره. درواقع به ArrayBuffer به شکل یه حامل میشه نگاه کرد که دیتا رو از blob تبدیل به ArrayBuffer میکنیم و اون رو به خورد MediaSource میدیم.

چرا MediaSource
در حالت عادی تگ video داخل HTML از ما برای src اش یه فایل ویدئویی میخواد. مثلا اگه بخوایم یه ویدئو خیلی معمولی نشون بدیم باید دقیق آدرس ویدئو رو وارد کنیم و اون شروع به پخش میکنه. با یک سری کنترل محدود مثل Play, Pause و Volume و همه چیز های دیفالتی که داره.
ولی به کمک MediaSource همونطور که بالاتر هم گفتم میتونیم روی ذره ذره محتوای ورودی اون تگ video کنترل داشته باشیم. روش listener های مختلف داشته باشیم، ازش لاگ بگیریم و کلی چیز دیگه:

همه اش رو یکجا بدیم، خورد خورد بدیم، بافر کنیم، از مموری بخونیم، از worker و indexdb لود کنیم، از یه سرور به صورت live stream بگیریم یا ... حتی به کمک همین MediaSource و ترکیبش با کلی تکنیک دیگه میتونیم پلیر های خیلی منعطف تری بنویسیم که کارای خیلی خفنی بتونن انجام بدن که البته خارج از حوصله من و این مطلبه.
وقتشه همه این ها رو بذاریم کنار هم تا یه نتیجه گیری ای داشته باشیم. نمونه کامل اپلیکیشن اینجا قابل دسترس هست و میتونید ببینیدش. با vite استارت شده و روی vercel قرارش دادم.
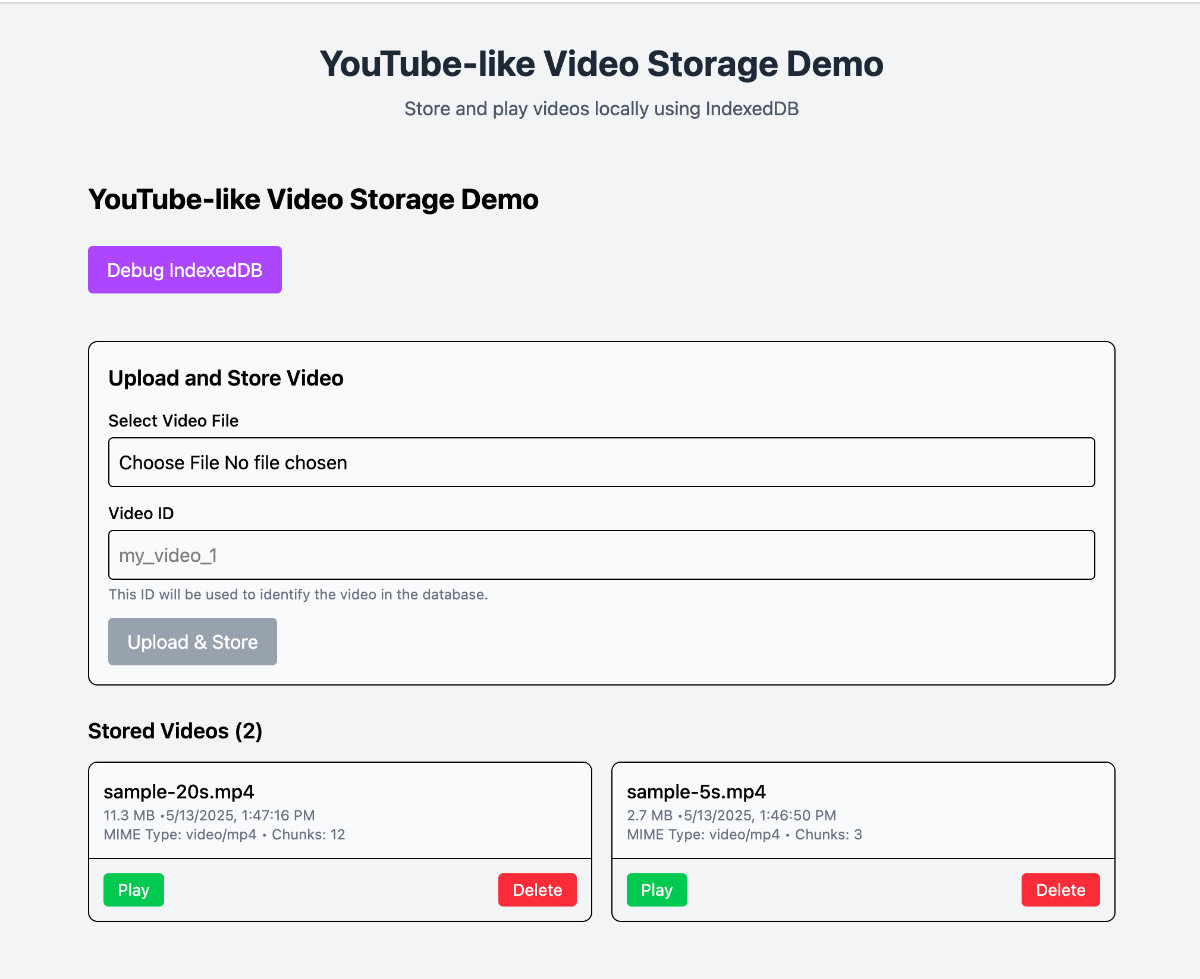
برای سادگی بیشتر، صرفا قرار هست یه ویدئو رو کاربر انتخاب کنه (حالا میتونه سورس های مختلفی داشته باشه) ولی اینجا برای سادگی میذاریم کاربر خودش آپلود کنه. در واقع آپلودی هم صورت نمیگیره، صرفا کاربر ویدئو رو انتخاب میکنه و ما اونو توی IndexedDB به صورت چانک های کوچک ذخیره میکنیم و بعد از همون چانک ها دوباره برای پخشش استفاده میکنیم.
کار هایی که تو این پروژه انجام میشه رو بیاید مرحله به مرحله مرور کنیم
برای اینکه کارمونم راحت تر بشه یه دکمه بنفش داریم که یه تگ pre رو باز میکنه و توش اطلاعات IndexedDB تون رو نشون میده. بیشتر نقشش یه debugger هست. خودتونم میتونید برید تو قسمت Application از inspector تون و اونجا هم همون اطلاعات رو ببینید.
قرار شد که قسمت UI رو بیخیال بشیم پس یه راست بریم سر وقت خورد کردن ویدئو
یه تابع داریم که فایل رو از input میگیره و فایل رو تبدیل میکنه به ArrayBuffer و اونو به چانک های ۱ مگابایتی میشکنه. مجدد تکرار کنم که این یه قرارداد هست مثلا من اینجا هر ویدئویی باشه رو اینطوری خورد کردم، ممکنه شما یه تصمیم دیگه بگیری
مهم ترین قسمتش همون حلقه while هست که داره چانک ها رو برامون میسازه.
خب حالا که چانک ها رو داریم باید توی دیتابیس مون ذخیره اش کنیم. برای اینکار من ویدئو رو به دو بخش تقسیم میکنم:
پس در واقع چیزی که به ازای هر ویدئو قرار میگیره به این صورته. الان که چانک ها رو داریم میمونه که metadata رو بگیریم و بعد هم بریم سر وقت ذخیره کردنش
همه این اطلاعات هم از روی فایل قابل دسترسه پس چیز سختی نیست.
میرسیم به قسمت ذخیره سازیش روی IndexedDB. اینجا هم میتونید از یه چیز ORM طور استفاده کنید مثل idb یا مستقیم باهاش کار کنید. ما که نمیخوایم آپولو هوا کنیم من ازش استفاده نمیکنم.
اول کار باید یه دیتابیس ایجاد کنیم و با همون instance بعدا بهش query بزنیم (دیتا ذخیره کنیم یا بخونیم یا پاک کنیم یا هرچی)
پس در واقع این تابع رو ما یکبار صدا میزنیم که اگر دیتابیس وجود نداشت اونو بسازه و اگر از قبل بود هم که از همون استفاده کنه. یه singleton پترن گوگولی.
بعد نوبت ذخیره ویدئو و metadata هست.
توی قسمت ۲ ولی یکم داستان فرق داره. اینجا میایم در واقع به تعداد چانک های ویدئو که قبلا ایجادشون کردیم همون آبجکتی که بالا بالا ها نشون دادم رو ذخیره میکنیم. دیتا از قبل به صورت ArrayBuffer درومده و فقط باید ذخیره بشه. هر چانک هم index خودشو داره که بعدا برای نمایش ویدئو بهش نیاز داریم.
در نهایت اگر همه چی خوب پیش بره دیتای ما توی IndexedDB ذخیره شده.
اینجا دیگه میشه گفت ۹۰ درصد راه رو اومدیم. مونده گرفتن این دیتا و نمایش دادنش در قالب همون تگ video. بازم تاکید کنم که پلیر ما اینجا فقط یه تگ video سادست که دیتاش رو بهش فید میکنیم و امکانات خاصی نداره.
توابعی که داریم اینا هستن:
خب یکم حجم کد ها زیاد شده ولی همه شون همون چیزایی هستن که قبلا مرور کردیم. اول از همه تابع readVideoFromIndexedDB رو صدا میزنیم. این همون تابعی هست که گفتیم قراره ویدئو رو بگیره، همه چانک ها رو به ترتیب تجمیع کنه و به تگ ویدئو بده. اول metadata رو میخونیم که اطلاعات کلی ویدئو رو بگیریم. از پراپرتی chunkCount استفاده میکنیم که بدونیم کلا این ویدئو چند قسمت شده که توی loop ازش کمک بگیریم.
بازم اینجا دو تا کامنت INJA داریم که توضیحشون مفصل تره.
ببینید، ArrayBuffer یه ساختار داده باینری سطح پایین هست (حالا به نقل از MDN). یعنی اگه شما میخواید باهاش کار کنید باید یه بافر با یک طول ثابت ایجاد کنید. پس قابل تغییر نیست - پس بنابراین برای اینکه بتونید باهاش کار کنید اصطلاحا نیاز به یه view دارید. که میشه دقیقا همون Uint8Array که میبینید ایجاد شده. ما درواقع اینجا با یک واسطی (به مفهوم ساده البته) طرف هستیم که دیتا رو برای ما هندل میکنه.
امیدوارم تونسته باشم اینو خوب توضیح بدم چون فهمش برای خودمم یکم مشکل بود.
در نهایت ما فایلمون رو داریم. مونده فقط نحوه استفاده ازش:
حالا اگه همه چیز کنار هم درست کار کنه ما یه سیستمی داریم که میتونیم فایل ها رو روی indexedDB ذخیره کنیم و ازش دوباره استفاده کنیم.
این مطلب خیلی زمان برد نوشتن و آماده سازیش، قطعا خوندنش هم برای شما طول کشیده (اگه خونده باشید کلش رو). اگه با دقت دنبال کرده باشید کلی چیز این وسط هست که من اصلا نشون ندادم یا اصلا بحثی راجع بهشون نکردم. مثلا اون موضوع Encryption رو یه اشاره کوچیکی کردم ولی تو مدل پیاده سازی شده اصلا اونو نداریم.
یا مثلا این پروژه خیلی جا برای بهبود داره که میشه روش زمان گذاشت ولی برای من قسمت جذاب و فان اش همینی بود که اینجا گفتم. اما ایده هام رو لیست میکنم شاید شما دوست داشتین روش کار کنید:
کلا خوبه کنجکاو باشیم، اخیرا بیشتر دارم سرک میکشم اینور و اونور ببینم هرچیزی دقیقا چه اتقافی داره براش میوفته یکم از زیر و بم چیزا سر در بیارم. راجع به این موضوع و این مطلب که روبهروی شماست شاید ۳ سال هست که ایده نوشتنش رو داشتم ولی همیشه به تعویق مینداختم. موضوعی بود که همیشه برام جالب بود. چیزی نداره واقعا وقتی از نزدیک باهاش کار میکنی ولی انقدر پتانسیل داره که یوتوب اونو تو سرویس پولی خودش به کاربرا داره میده 😁
امیدوارم درکل مطلب براتون مفید بوده باشه و از خوندنش یه چیز جدید یاد گرفته باشین. دوست داشتین میتونید از طریق لینکدین باهام در ارتباط باشین.