وقتی از بیرون به یک فروشگاه اینترنتی بزرگ نگاه میکنیم، همه چیز ساده به نظر میرسد.
کاربر وارد سایت میشود، محصولی را جستجو میکند، صفحه محصول را باز میکند، کالا را به سبد خرید اضافه میکند، پرداخت میکند و منتظر دریافت سفارش میماند.
اما پشت همین مسیر ساده، یکی از پیچیدهترین چالشهای مهندسی نرمافزار قرار دارد.
در پلتفرمی مثل دیجیکالا، ما فقط با چند صفحه محصول و چند کاربر همزمان روبهرو نیستیم. با میلیونها بازدید، صدها هزار فروشنده، تعداد زیادی کالا، تغییرات لحظهای قیمت و موجودی، کمپینهای فروش، پیشنهادهای شخصیسازیشده و حجم زیادی از درخواستهای همزمان سروکار داریم.
برای مثال، یک کاربر ممکن است وارد دستهبندی گوشی موبایل شود و محصولات را بر اساس معیارهای مختلف مرتب کند:
مرتبطترین
پربازدیدترین
جدیدترین
پرفروشترین
ارزانترین
گرانترین
سریعترین ارسال
پیشنهاد خریداران
کالاهای منتخب
هر کدام از این انتخابها، از دید کاربر فقط یک کلیک ساده است. اما از دید سیستم، هر کلیک یعنی اجرای چندین درخواست، خواندن داده از چند منبع، اعمال فیلترها، بررسی قیمت، بررسی موجودی، محاسبه زمان ارسال و در نهایت ساختن خروجی مناسب برای کاربر.
در چنین مقیاسی، سیستم باید در هر لحظه به چند سؤال مهم پاسخ دهد:
در نتایج جستجو چه محصولاتی باید نمایش داده شوند؟
قیمت دقیق محصول در همین لحظه چقدر است؟
آیا کالا هنوز موجود است؟
کدام فروشنده باید به عنوان پیشنهاد اصلی نمایش داده شود؟
زمان ارسال برای این کاربر، با توجه به موقعیت مکانی او، چقدر است؟
کدام بخش از صفحه را میشود کش کرد؟
اگر قیمت یا موجودی تغییر کند، چه اتفاقی برای دادههای کششده میافتد؟
اینجاست که کشینگ دیگر یک تکنیک ساده برای افزایش سرعت نیست. در این مقیاس، کشینگ به یکی از پایههای اصلی معماری سیستم تبدیل میشود.
این مقاله تلاش میکند معماری کشینگ در یک پلتفرم بزرگ تجارت الکترونیک را با زبانی سادهتر بررسی کند. تمرکز اصلی روی الگوهایی است که در پلتفرمهایی هممقیاس با دیجیکالا استفاده میشوند.
در یک فروشگاه اینترنتی کوچک، معماری سیستم معمولا ساده است.
کاربر صفحه اصلی را باز میکند.
سرور از دیتابیس محصولات را میخواند.
نتیجه به کاربر برمیگردد.
کاربر صفحه محصول را باز میکند.
سرور دوباره از دیتابیس اطلاعات همان محصول را میخواند.
کاربر کالا را به سبد خرید اضافه میکند.
دیتابیس بهروزرسانی میشود.
این مدل برای یک فروشگاه کوچک قابل قبول است. اما وقتی ترافیک بالا میرود، دیگر نمیشود برای هر درخواست مستقیما سراغ دیتابیس اصلی رفت.
اگر میلیونها کاربر همزمان وارد سایت شوند و هر کدام چندین بار جستجو کنند، صفحه محصول باز کنند، فیلتر بزنند و قیمتها را بررسی کنند، دیتابیس اصلی زیر فشار شدید درخواستهای خواندن قرار میگیرد.
در معماریهای بزرگ، دیتابیس اصلی باید نقش منبع مرجع حقیقت را داشته باشد. یعنی جایی که داده معتبر و نهایی در آن نگهداری میشود. اما همه درخواستها نباید مستقیم به آن برسند.
در چنین معماریای، دادهها معمولا از چند لایه عبور میکنند:
دیتابیس اصلی
جریان رویدادها
ایندکس جستجو
لایههای کش
CDN
لایه API
کاربر
چالش اصلی اینجاست:
کدام داده را میشود برای چند دقیقه کش کرد؟
کدام داده باید همیشه تازه باشد؟
کدام داده قبل از پرداخت باید حتما از منبع اصلی بررسی شود؟
پاسخ این سؤالها، کیفیت معماری کشینگ را مشخص میکند.
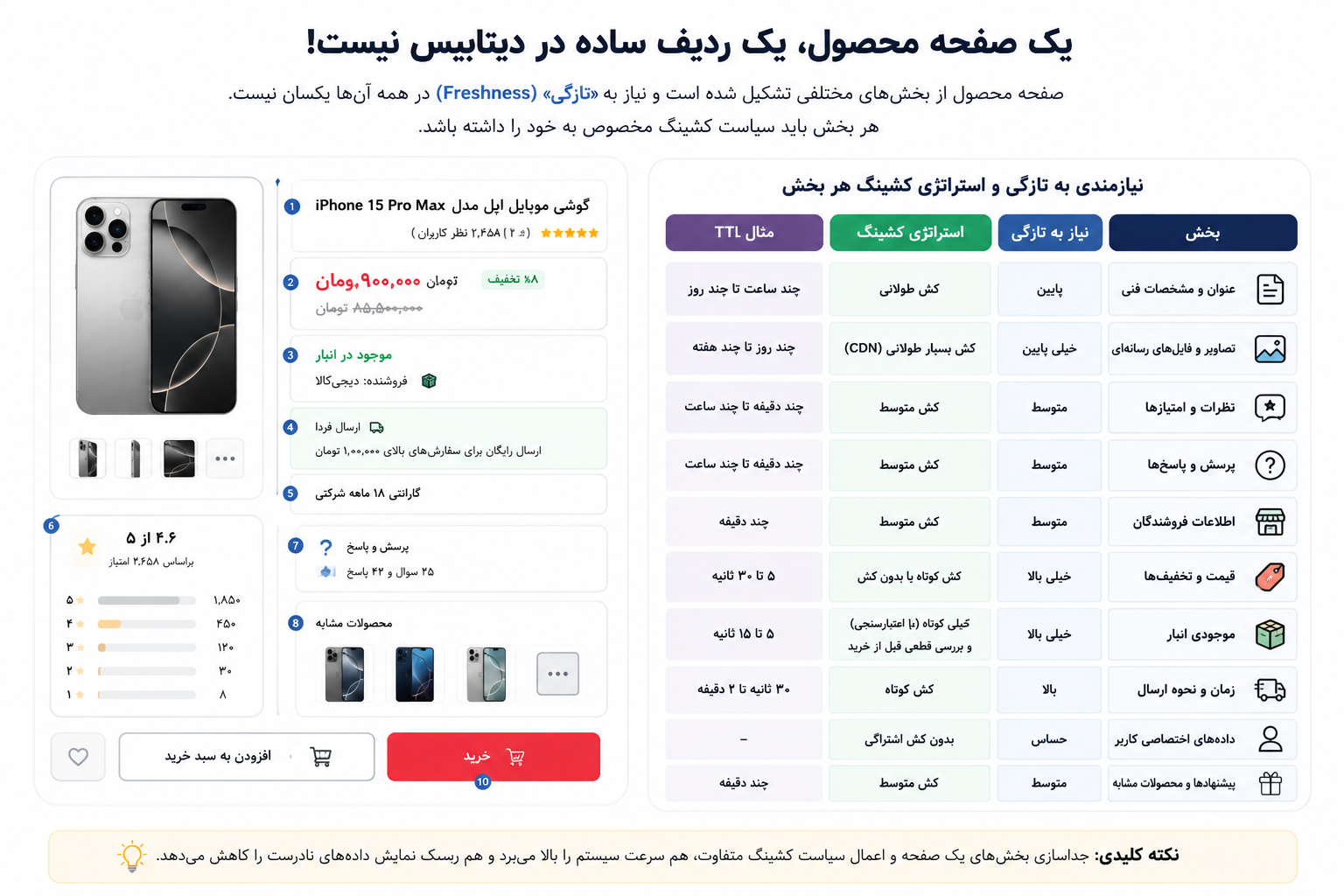
از نگاه کاربر، صفحه محصول یک صفحه واحد است. اما از نگاه فنی، این صفحه از چندین بخش مستقل ساخته شده است.
یک صفحه محصول ممکن است شامل این دادهها باشد:
عنوان و مشخصات کالا
تصاویر محصول
اطلاعات فروشندگان
قیمت فعلی
تخفیفها و کمپینها
موجودی انبار
زمان و روش ارسال
اطلاعات گارانتی
امتیازها و نظرات کاربران
پرسش و پاسخها
محصولات مشابه
وضعیت سبد خرید کاربر
وضعیت علاقهمندیهای کاربر
همه این دادهها اهمیت یکسانی ندارند. همه آنها هم نیاز به تازگی یکسان ندارند.
عنوان محصول ممکن است ساعتها تغییر نکند.
تصاویر محصول ممکن است هفتهها ثابت بمانند.
نظرات کاربران با چند دقیقه تأخیر هم قابل قبول هستند.
اما قیمت و موجودی حساساند.
اگر کاربر قیمتی قدیمی ببیند، مشکل ایجاد میشود. اگر کالایی را موجود ببیند ولی هنگام خرید متوجه شود ناموجود است، اعتماد او به سیستم کم میشود.
پس یک صفحه محصول نباید فقط یک سیاست کش داشته باشد. باید هر بخش صفحه جداگانه بررسی شود.
بخشهای پایدار، کش بلندتر میگیرند.
بخشهای نیمهپویا، کش کوتاهتر میگیرند.
بخشهای حساس مثل قیمت و موجودی، یا کش نمیشوند یا با دقت زیادی مدیریت میشوند.
این یکی از مهمترین اصول کشینگ در مقیاس بزرگ است.
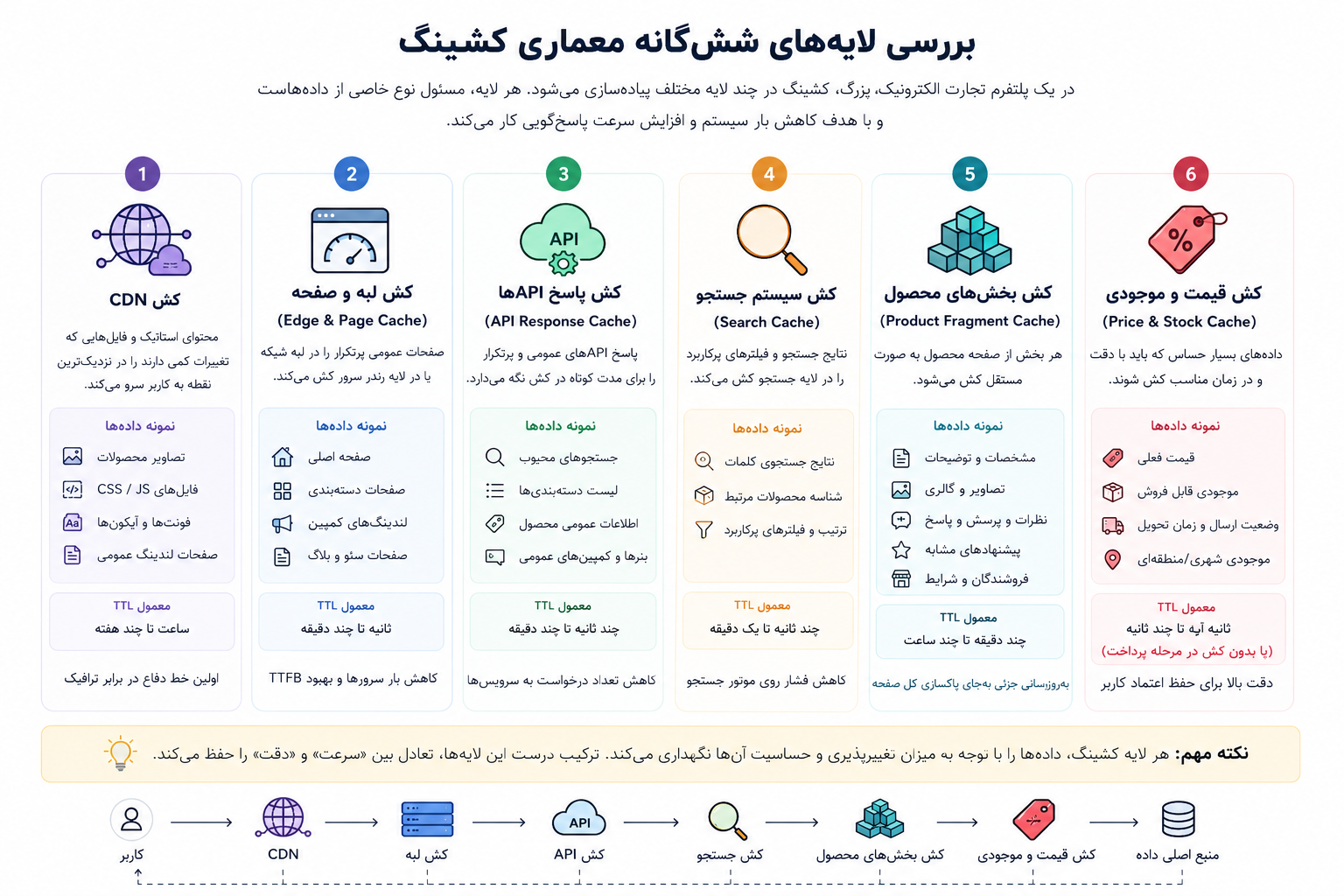
معماری کشینگ معمولا فقط یک Redis جلوی دیتابیس نیست. در سیستمهای بزرگ، کش در چند لایه مختلف قرار میگیرد. هر لایه هدف خاص خودش را دارد.
اولین لایه مهم، CDN است.
CDN برای نگهداری و ارائه فایلهایی استفاده میشود که تغییرات کمی دارند. مثل:
تصاویر محصولات
فایلهای JavaScript
فایلهای CSS
فونتها
آیکونها
صفحات عمومی و لندینگها
در یک فروشگاه تصویرمحور، حجم زیادی از ترافیک مربوط به تصاویر است. اگر همه تصاویر مستقیم از سرور اصلی خوانده شوند، سرورهای اصلی بخش زیادی از توان خود را صرف ارسال فایلهای استاتیک میکنند.
CDN این بار را از روی سرور اصلی برمیدارد. فایلها در نقاط مختلف شبکه نگهداری میشوند و کاربر از نزدیکترین نقطه پاسخ میگیرد.
برای مدیریت تغییر تصاویر هم معمولا از نسخهگذاری در آدرس فایل استفاده میشود.
مثلا به جای اینکه تصویر اصلی محصول همیشه یک URL ثابت داشته باشد، با تغییر تصویر، آدرس آن هم نسخه جدید میگیرد:
/products/123/main_v4.webp
با این کار نیازی نیست همیشه کش قبلی به صورت دستی پاک شود. چون آدرس فایل جدید است، CDN آن را به عنوان فایل جدید میشناسد.
بعضی صفحات ترافیک زیادی دارند و برای همه کاربران تقریبا مشابه هستند.
مثلا:
صفحه اصلی
صفحات دستهبندی
لندینگهای کمپین
صفحات سئو
صفحات عمومی برندها
این صفحات گزینههای خوبی برای کش در لبه شبکه یا در لایه رندر سمت سرور هستند.
اما مشکل اینجاست که همه بخشهای این صفحات ثابت نیستند.
مثلا در صفحه دستهبندی، پوسته صفحه ممکن است ثابت باشد، ولی قیمت محصولات، موجودی و زمان ارسال باید تازهتر باشند.
راهکار مناسب، جدا کردن بخشهای صفحه است.
پوسته صفحه میتواند TTL طولانیتر داشته باشد.
لیست محصولات میتواند TTL کوتاهتری داشته باشد.
قیمت و موجودی میتوانند از API جداگانه با کش کوتاه یا داده زنده خوانده شوند.
اطلاعات اختصاصی کاربر نباید در کش عمومی قرار بگیرد.
این جداسازی باعث میشود هم سرعت بالا بماند، هم ریسک نمایش داده اشتباه کاهش پیدا کند.
در معماریهای امروزی، بخش زیادی از ترافیک از طریق APIها مدیریت میشود.
اپلیکیشن موبایل، وبسایت، پنلها و سرویسهای داخلی همگی به APIها درخواست میزنند. اگر هر درخواست API مستقیم به دیتابیس یا سرویسهای سنگین برسد، سیستم به سرعت تحت فشار قرار میگیرد.
بعضی APIها گزینههای خوبی برای کش هستند.
مثلا:
جستجوی کلمات محبوب
دستهبندیهای پربازدید
لیست محصولات یک دسته
اطلاعات عمومی محصول
بنرها و کمپینهای عمومی
اما بعضی APIها نباید در کش عمومی قرار بگیرند.
مثلا:
سبد خرید کاربر
آدرسهای کاربر
کیف پول
سفارشها
اطلاعات حساب کاربری
در کش API، طراحی Cache Key اهمیت زیادی دارد.
مثلا اگر کاربر در تهران و شیراز نتیجه متفاوتی برای زمان ارسال یا موجودی میگیرد، شهر باید بخشی از کلید کش باشد.
نمونه ساده:
search:v1:q=iphone:city=tehran
اگر شهر در کلید کش نباشد، ممکن است کاربر تهرانی نتیجهای را ببیند که برای شهر دیگری ساخته شده است. این خطا در مقیاس بزرگ میتواند تجربه کاربری را خراب کند.
موتورهای جستجو مثل Elasticsearch یا OpenSearch معمولا برای خواندن سریع دادهها استفاده میشوند. اما این موتورها منبع اصلی حقیقت نیستند.
در فروشگاههای بزرگ، جستجو فقط پیدا کردن یک کلمه نیست. سیستم باید فیلترها، مرتبسازیها، وضعیت کالا، دستهبندی، برند، قیمت، موجودی و رفتار کاربران را هم در نظر بگیرد.
برای کاهش فشار روی موتور جستجو، معمولا نتیجه جستجو به چند مرحله تقسیم میشود.
در مرحله اول، موتور جستجو فقط شناسه محصولات مرتبط را برمیگرداند.
مثلا:
[123, 456, 789]
این لیست میتواند برای مدت کوتاهی کش شود.
در مرحله دوم، سرویسهای دیگر اطلاعات کارت محصول را بر اساس این شناسهها کامل میکنند.
در مرحله سوم، قیمت و موجودی تازه روی کارتها قرار میگیرد.
این مدل باعث میشود موتور جستجو درگیر ساختن کامل همه دادههای محصول نشود. همچنین سیستم کنترل بیشتری روی تازگی دادههای حساس دارد.
یکی از اشتباههای رایج در کشینگ این است که کل صفحه محصول به عنوان یک واحد کش شود.
این کار در ظاهر ساده است، اما در عمل مشکل ایجاد میکند.
فرض کنید فقط قیمت محصول تغییر کرده است. اگر کل صفحه محصول کش شده باشد، باید کل کش صفحه پاک شود. در حالی که بسیاری از بخشهای صفحه، مثل توضیحات، تصاویر و مشخصات فنی، تغییری نکردهاند.
راه بهتر این است که صفحه محصول به بخشهای کوچکتر تقسیم شود.
مثلا:
کش مشخصات محصول
کش تصاویر
کش توضیحات
کش نظرات
کش پرسش و پاسخ
کش پیشنهادهای مشابه
کش فروشندگان
کش قیمت و موجودی
در این مدل، اگر فقط قیمت تغییر کند، لازم نیست همه بخشها از کش خارج شوند. فقط همان بخش مرتبط به قیمت بهروزرسانی میشود.
این کار باعث کاهش فشار روی دیتابیس، افزایش سرعت پاسخدهی و کنترل بهتر روی دادههای حساس میشود.
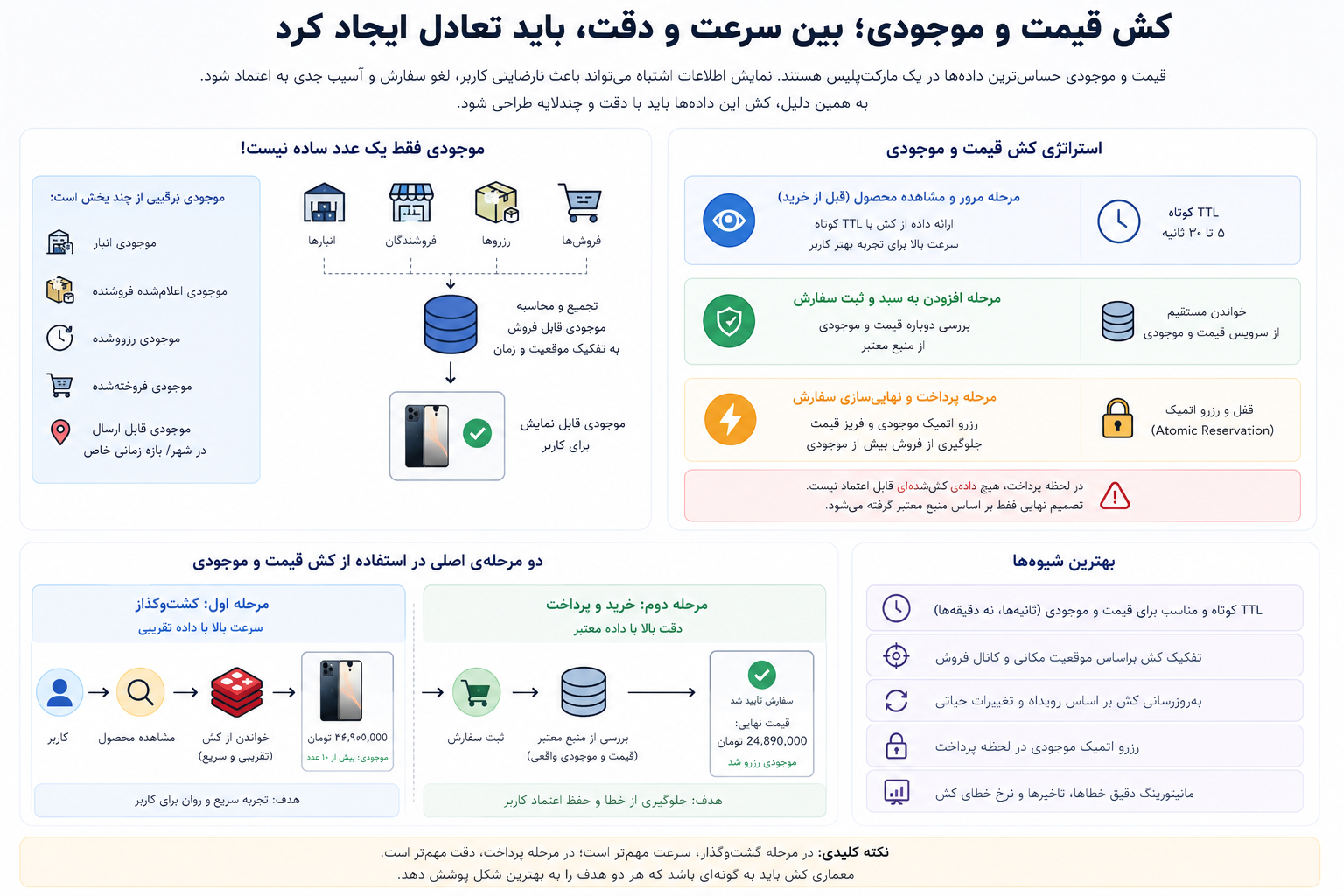
حساسترین بخش کشینگ در فروشگاه اینترنتی، قیمت و موجودی است.
قیمت و موجودی مستقیما با اعتماد کاربر و فرآیند پرداخت ارتباط دارند. اگر این دادهها اشتباه باشند، آسیب جدی به تجربه کاربر وارد میشود.
موجودی هم معمولا فقط یک عدد ساده نیست.
موجودی واقعی میتواند از چند بخش تشکیل شود:
موجودی اعلامشده فروشنده
موجودی انبار
موجودی رزروشده
موجودی فروختهشده
موجودی قابل ارسال در شهر یا بازه زمانی خاص
به همین دلیل، سیستمهای بزرگ معمولا بین دو مرحله تفاوت میگذارند.
مرحله اول، زمانی است که کاربر در حال گشتوگذار در سایت است. در این مرحله، سیستم میتواند از داده کششده یا کمی تقریبی استفاده کند.
مرحله دوم، زمانی است که کاربر وارد پرداخت و ثبت سفارش میشود. در این مرحله، سیستم باید قیمت و موجودی را از منبع معتبر بررسی کند.
در مرحله نهایی، موجودی باید به صورت اتمیک رزرو شود. یعنی سیستم باید مطمئن شود چند کاربر همزمان نمیتوانند آخرین موجودی یک کالا را همزمان بخرند.
پس کش قیمت و موجودی باید با احتیاط طراحی شود. سرعت مهم است، اما دقت در لحظه خرید مهمتر است.

کش کردن دادهها ساده است. اما اینکه بدانیم چه زمانی باید کش را پاک کنیم، بخش سخت ماجراست.
در یک مارکتپلیس بزرگ، دادهها مدام تغییر میکنند.
قیمت عوض میشود.
موجودی کم یا زیاد میشود.
فروشنده فعال یا غیرفعال میشود.
کمپین جدید شروع میشود.
کالا از دسترس خارج میشود.
الگوریتم مرتبسازی تغییر میکند.
برای مدیریت این تغییرات، چند روش رایج وجود دارد.
در این روش، برای هر داده یک زمان اعتبار مشخص میشود.
مثلا نظرات کاربران برای ۱۰ دقیقه کش شوند.
لیست محصولات یک دسته برای ۳۰ ثانیه کش شود.
بنرهای صفحه اصلی برای چند دقیقه کش شوند.
این روش ساده و مقاوم است. حتی اگر سیستم ابطال کش درست کار نکند، داده بعد از مدتی خودبهخود منقضی میشود.
اما این روش برای دادههای حساس کافی نیست. چون ممکن است در همان بازه کوتاه، داده اشتباه به کاربر نمایش داده شود.
در این روش، هر تغییر مهم یک رویداد تولید میکند.
مثلا وقتی قیمت تغییر میکند، رویدادی با این مفهوم منتشر میشود:
ProductPriceChanged
سپس Workerها این رویداد را دریافت میکنند و کلیدهای کش مرتبط را پاک میکنند یا بهروزرسانی میکنند.
این روش دقیقتر است، اما پیچیدگی بیشتری دارد.
باید مطمئن شویم پیامها از بین نمیروند.
باید تأخیر پردازش رویدادها کنترل شود.
باید در برابر تکرار پیامها مقاوم باشیم.
باید بدانیم هر رویداد دقیقا کدام کلیدهای کش را تحت تأثیر قرار میدهد.
در سیستمهای بزرگ، معمولا TTL و Event-Based Invalidation کنار هم استفاده میشوند. TTL نقش لایه ایمنی را دارد و رویدادها دقت سیستم را بالا میبرند.
گاهی پاک کردن میلیونها کلید کش کار درستی نیست. مخصوصا هنگام تغییرات بزرگ، مثل شروع کمپین یا تغییر الگوریتم مرتبسازی.
در این شرایط، نسخه کلید کش تغییر میکند.
مثلا:
search:v1:q=iphone
به این تبدیل میشود:
search:v2:q=iphone
با این کار، سیستم به جای پاک کردن همه کلیدهای قبلی، از نسخه جدید کلیدها استفاده میکند. کلیدهای قدیمی هم بعد از پایان TTL خودشان از بین میروند.
این روش برای تغییرات گسترده، امنتر و کمهزینهتر است.
در روزهای عادی، درخواستها بین محصولات مختلف پخش میشوند. اما در کمپینها، فروشهای ویژه یا زمان معرفی یک کالای محبوب، ممکن است همه کاربران همزمان به یک محصول خاص هجوم بیاورند.
در این حالت، یک کلید کش بیش از حد پرمصرف میشود. به این وضعیت Hot Key میگویند.
حالا فرض کنید همان کلید کش ناگهان منقضی شود. هزاران درخواست همزمان متوجه میشوند داده در کش وجود ندارد. اگر همه آنها مستقیم به دیتابیس بروند، دیتابیس تحت فشار شدید قرار میگیرد.
به این مشکل Cache Stampede میگویند.
برای جلوگیری از این اتفاق، چند الگوی مهم استفاده میشود.
اگر دادهای در کش وجود نداشته باشد، فقط یک درخواست اجازه دارد به دیتابیس برود و داده را دوباره بسازد.
بقیه درخواستها منتظر میمانند تا همان درخواست اول نتیجه را برگرداند و کش را پر کند.
این روش جلوی هجوم همزمان درخواستها به دیتابیس را میگیرد.
در این روش، اگر داده کمی قدیمی شده باشد، سیستم همان داده قدیمی را به کاربر نشان میدهد، اما همزمان در پسزمینه کش را بهروزرسانی میکند.
این روش برای دادههایی مناسب است که کمی تأخیر در آنها قابل قبول است.
مثلا نمایش تعداد تقریبی بازدید، نظرات، پیشنهادهای مشابه یا بعضی لیستهای عمومی.
اگر هزاران کلید کش TTL یکسان داشته باشند، ممکن است همه در یک زمان منقضی شوند.
برای جلوگیری از این اتفاق، به زمان انقضای کش مقدار کمی تصادفی اضافه میشود.
مثلا به جای اینکه همه کلیدها دقیقا ۶۰ ثانیه عمر کنند، بعضی ۵۲ ثانیه، بعضی ۶۸ ثانیه و بعضی ۷۴ ثانیه عمر میکنند.
این کار باعث میشود فشار روی سیستم پخش شود.
فروشهای شگفتانگیز یا Flash Sale یکی از سختترین سناریوها برای معماری کشینگ هستند.
در این شرایط، تعداد زیادی کاربر همزمان برای خرید یک کالای محدود تلاش میکنند. اگر سیستم درست طراحی نشده باشد، مشکل فقط کندی سایت نیست. ممکن است oversell رخ دهد، یعنی تعداد فروش از موجودی واقعی بیشتر شود.
برای کنترل این وضعیت، معمولا چند مکانیزم کنار هم استفاده میشود.
صف انتظار برای کاربران
Rate Limiting برای کنترل تعداد درخواستها
Token Bucket برای محدود کردن تعداد خرید معتبر
رزرو اتمیک موجودی در مرحله نهایی
بررسی قطعی قیمت و موجودی هنگام پرداخت
کش کوتاهمدت برای نمایش سریع داده در مرحله مرور سایت
در این مدل، کشینگ به تنهایی کافی نیست. کش باید کنار صف، محدودیت نرخ درخواست، قفل موجودی و پردازش تراکنش امن قرار بگیرد.
هدف اصلی این است که کاربر پاسخ سریع بگیرد، اما هسته اصلی سفارشگذاری قربانی ترافیک بالا نشود.
شخصیسازی برای فروشگاه اینترنتی مهم است. کاربر دوست دارد پیشنهادهایی ببیند که با علاقه و رفتار او مرتبط باشد.
اما اگر کل صفحه برای هر کاربر به شکل اختصاصی ساخته شود، نرخ موفقیت کش کاهش پیدا میکند. در این حالت، هر کاربر خروجی جداگانه دارد و کش عمومی کمتر استفاده میشود.
راهحل بهتر، شخصیسازی جزئی است.
یعنی بخشهای عمومی صفحه از کش مشترک خوانده شوند و فقط بخشهای کوچک اختصاصی برای هر کاربر جداگانه بارگذاری شوند.
مثلا:
پوسته صفحه از کش عمومی
بنرهای کمپین از کش عمومی
دستهبندیهای محبوب از کش عمومی
لیست محصولات پربازدید از کش عمومی
تعداد آیتمهای سبد خرید از API اختصاصی
پیشنهادهای مبتنی بر بازدیدهای اخیر از API اختصاصی
وضعیت علاقهمندیها از API اختصاصی
این مدل تعادل خوبی ایجاد میکند. هم سایت سریع میماند، هم تجربه کاربر شخصیتر میشود.
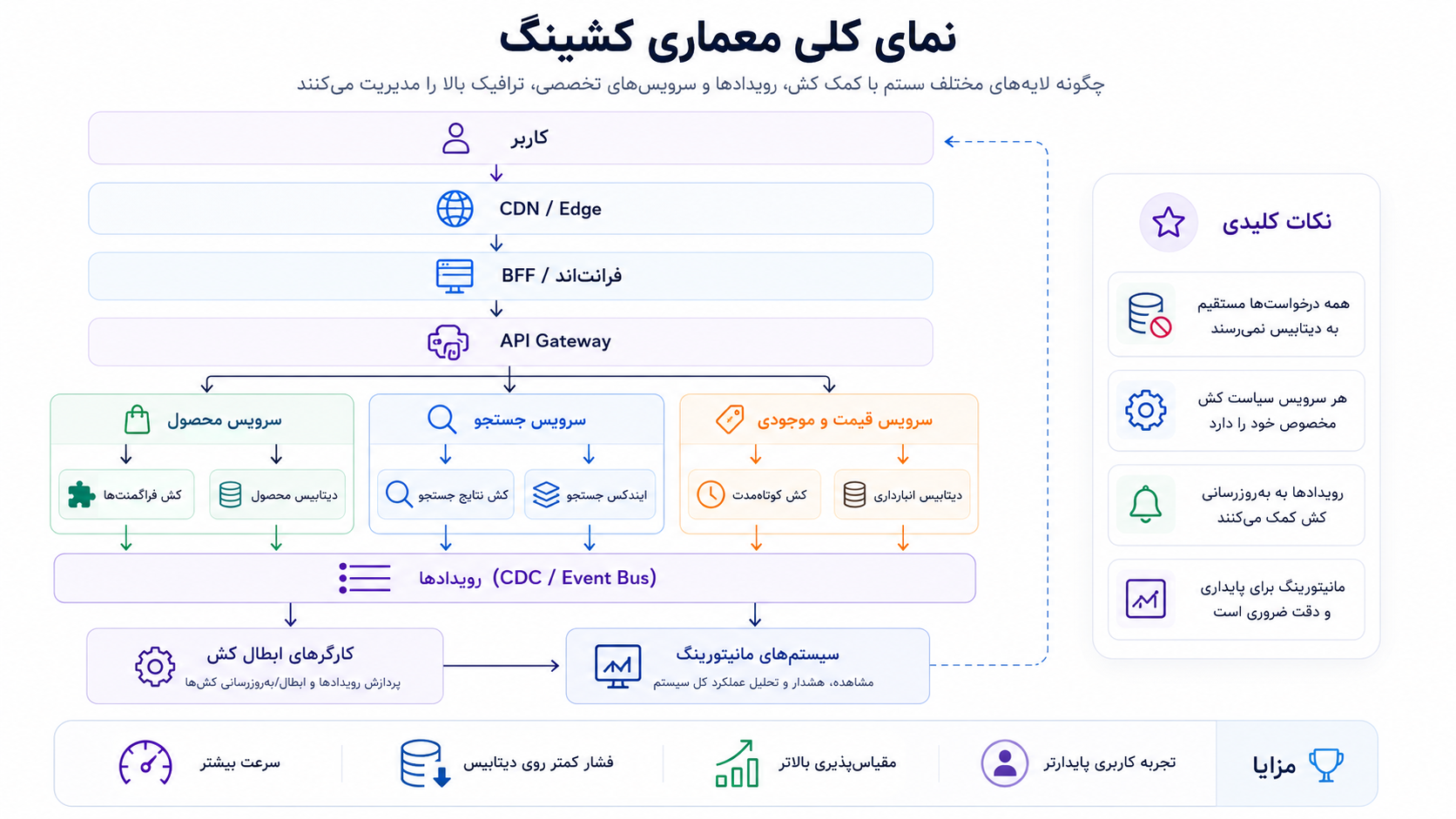
یک معماری حرفهای برای کشینگ در پلتفرمهای بزرگ میتواند به شکل زیر دیده شود:
کاربر
CDN و Edge Cache
لایه فرانتاند یا BFF
API Gateway
سرویس محصول
سرویس جستجو
سرویس قیمت و موجودی
کشهای اختصاصی هر سرویس
دیتابیسهای اصلی
بستر رویدادها
Workerهای ابطال کش
سیستم مانیتورینگ
در این معماری، هر سرویس مسئول بخشی از داده است.
سرویس محصول اطلاعات پایدارتر محصول را مدیریت میکند.
سرویس جستجو نتایج قابل جستجو و فیلتر را آماده میکند.
سرویس قیمت و موجودی دادههای حساستر را کنترل میکند.
بستر رویدادها تغییرات مهم را به بخشهای مختلف اطلاع میدهد.
Workerها کشهای مرتبط را پاک یا بهروزرسانی میکنند.
سیستم مانیتورینگ هم خطاها، تأخیرها، نرخ موفقیت کش و فشار روی سرویسها را بررسی میکند.
بدون مانیتورینگ، کشینگ به یک جعبه سیاه خطرناک تبدیل میشود. تیم فنی باید بداند:
Cache Hit Rate چقدر است؟
کدام کلیدها Hot Key شدهاند؟
کدام کشها بیشترین خطا را دارند؟
ابطال کش چقدر تأخیر دارد؟
چند درصد درخواستها به دیتابیس اصلی میرسند؟
در زمان کمپین فشار روی کدام سرویس بیشتر میشود؟
کشینگ بدون مشاهدهپذیری، قابل اعتماد نیست.
مدیریت میلیونها بازدید روزانه در یک مارکتپلیس بزرگ فقط با اضافه کردن Redis به پروژه حل نمیشود.
در چنین مقیاسی، کشینگ باید بخشی از معماری اصلی محصول باشد. هر نوع داده باید سیاست خودش را داشته باشد. بعضی دادهها میتوانند چند دقیقه قدیمی باشند. بعضی دادهها باید تقریبا تازه بمانند. بعضی دادهها مثل قیمت نهایی و موجودی هنگام پرداخت، باید حتما از منبع معتبر بررسی شوند.
هنر مهندسی در این نیست که همه چیز را کش کنیم. هنر اصلی این است که بدانیم چه چیزی را کجا کش کنیم، برای چه مدت کش کنیم، چه زمانی کش را باطل کنیم و چه زمانی اصلا نباید به کش اعتماد کنیم.
برای پلتفرمهایی مثل دیجیکالا، کشینگ فقط یک ابزار افزایش سرعت نیست. کشینگ بخشی از طراحی اعتماد، پایداری و مقیاسپذیری سیستم است.