
ویژگیها همون متغیرها یا ستونهای داده هستند که به مدل میگیم براساس اونها پیشبینی یا تصمیم بگیره. مثلاً توی تشخیص بیماری، فیچرها میتونن سن، فشار خون، وزن و... باشن.
یادگیری ماشین خیلی ساده بهش نگاه کنیم دو بخشه :
۱-ویژگی ها (Features)
۲-هدف (Target)
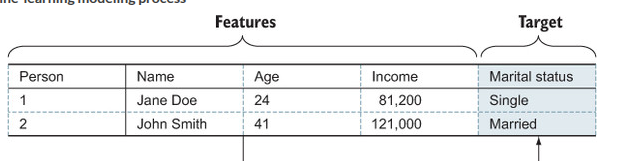
شما تو هر مثال یادگیری ماشین باید بتونید ویژگی ها رو مدیریت کنید و در نهایت به هدفی که میخواید پیش بینی بکنید برسید .
هر ستونی که توی اون دیتاست داریم رو ویژگی مینامیم.
حالا این ويژگی ها رو قراره مهندسی کنیم . یعنی چی ؟ الان بهتون میگم .
اولا که یکسری وقت ها نیازی به مهندسی ويژگی به صورت پیچیده نیست . مثل مثالی که برای درس خوندن زدیم , ما کلا دو تا ویژگی داریم : میزان ساعت درس خوندن و نمره .
تارگت : نمره
ویژگی : ۳ ساعت درس خوندن
مراحل :
بعد از رسم رگرسیون هم که خیلی راحت به مدل میرسیم و با مدلی که داریم میتونیم به راحتی پیش بینی کنیم که در ازای فیچر (۳ ساعت درس خوندن) چه تارگتی (نمره ای) میگیریم .
تمام مراحلی که در بالا اشاره کردیم رو در مراحل بعدی هم خواهیم داشت فقط خواستم بگم یک وقت هایی که ویژگی ها کم هستن و تارگت با همون تک ویژگی به راحتی هندل میشه میریم سریع سراغ این مراحل و تمام .
ولی وقتی مسئله یکم پیچیده تر باشه باید مهندسی ویژگی هم انجام بدیم که کار خیلی سختی نیست و در ادامه باهم یاد میگیریم . پس برو بریم ادامه مطلب ...
وقتی دادههای خام به دست میاد، معمولاً فقط یه سری اعداد و اطلاعات پراکنده و خام هستند. اما مدلهای یادگیری ماشین برای اینکه بهترین عملکرد رو داشته باشند، نیاز دارند دادهها به شکل قابل فهمتر، خلاصهتر و تاثیرگذارتر برای آنها آماده بشه.
مهندسی ویژگی یعنی:
انتخاب،
ساخت،
اصلاح، و
تبدیل ویژگیهای داده،
در نتیجه بهترین اطلاعات و مفاهیم ممکن از داده استخراج بشه و مدل بتونه با دقت و سرعت بیشتر یاد بگیره.
انتخاب ویژگی: حذف ویژگیهای کمارزش یا نویزی
ساخت ویژگی: ایجاد فیچرهای جدید با ترکیب فیچرهای موجود
تبدیل ویژگی: نرمالسازی، مقیاسبندی، کدگذاری متغیرهای دستهای (مثلاً one-hot encoding)
مدیریت مقادیر گمشده: جایگزینی یا حذف دادههای ناقص
این دیتاست رو ببینید :
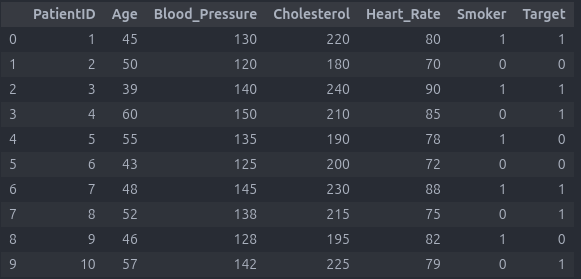
import pandas as pd data = { 'PatientID': range(1, 11), 'Age': [45, 50, 39, 60, 55, 43, 48, 52, 46, 57], 'Blood_Pressure': [130, 120, 140, 150, 135, 125, 145, 138, 128, 142], 'Cholesterol': [220, 180, 240, 210, 190, 200, 230, 215, 195, 225], 'Heart_Rate': [80, 70, 90, 85, 78, 72, 88, 75, 82, 79], 'Smoker': [1, 0, 1, 0, 1, 0, 1, 0, 1, 0], 'Target': [1, 0, 1, 1, 0, 0, 1, 1, 0, 1] } df = pd.DataFrame(data)
این دیتاست اطلاعات پزشکی بیماران یک بیمارستان میباشد .
ستون Target نشان دهنده اینه که آیا این فرد در ریسک ابتلا به بیماری قلبی هست یا خیر .
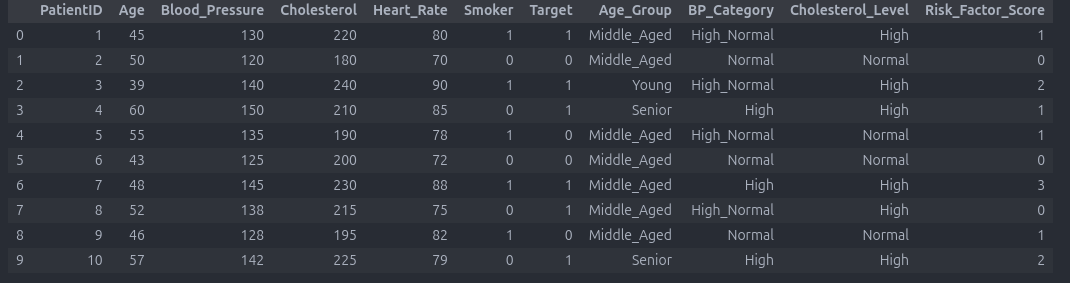
مهندس ویژگی که پیشنهاد میدم :
Age_Group: دستهبندی سن به گروههای جوان، میانسال و سالمند
BP_Category: دستهبندی فشار خون (طبیعی، بالا، خیلی بالا)
Cholesterol_Level: دستهبندی کلسترول (عادی، بالا)
Risk_Factor_Score: نمرهای ترکیبی از سیگنالهای خطر مثل سیگار کشیدن، فشار خون بالا و کلسترول بالا
مهندسی فیچر Age_Group
def age_group(age): if age < 40: return 'Young' elif 40 <= age <= 55: return 'Middle_Aged' else: return 'Senior' df['Age_Group'] = df['Age'].apply(age_group)
مهندسی فیچر BP_Category
def bp_category(bp): if bp < 130: return 'Normal' elif 130 <= bp <= 140: return 'High_Normal' else: return 'High' df['BP_Category'] = df['Blood_Pressure'].apply(bp_category)
مهندسی فیچر Cholesterol_Level
df['Cholesterol_Level'] = df['Cholesterol'].apply(lambda x: 'High' if x > 200 else 'Normal')
مهندسی فیچر Risk_Factor_Score (مثلا امتیاز از 3)
df['Risk_Factor_Score'] = df['Smoker'] + (df['Blood_Pressure'] > 140).astype(int) + (df['Cholesterol'] > 220).astype(int)
در نهایت :
خب , به انتهای مطلب رسیدیم , در قسمت بعدی آخرین مرحله از Data Preprocessing رو هم انجام میدیم و دیگه وارد بحث Train میشیم .