تا اینجای کار یاد گرفتیم ویژگی هامون رو مهندسی کنیم و دسته بندی کنیم و ...
اما حالا میخوام یک چیزی نشونتون بدم , در نهایت کدی که تو مقاله قبلی زدیم و مهندسی ویژگی انجام دادیم , اما میخوام یک چیزی نشونتون بدم :
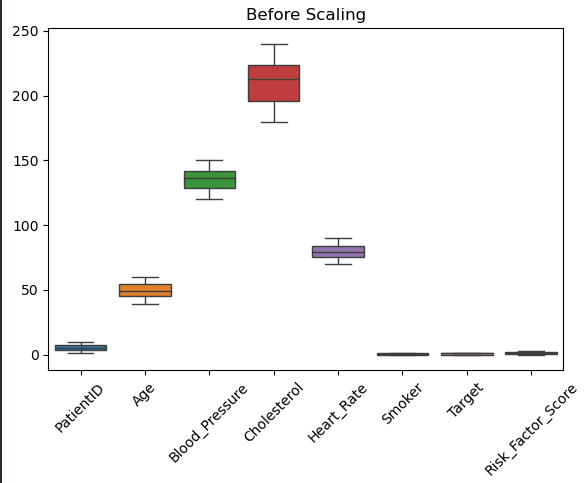
دقت کنید مثلا رنج اعداد کلسترول بین ۱۶۰ تا ۲۳۰ ولی رنج اعداد Heart_Rate بین ۴۰ تا ۱۰۰ هستش .
خب این الان چه مشکلی داره ؟
ببینید , مدل هوش مصنوعی اگر داده های یک ویژگی خیلی بزرگ باشن و اون یکی ویژگی خیلی کوچیک باشه , جواب درستی نمیده . یعنی فکر میکنه اون ویژگی که عددش خیلی بزرگتره خیلی هم مهم تره در صورتی که برای ما این نتیجه اصلا مطلوب نیست.
مدل هوش مصنوعی ما دوست داره که همه چیز تو یک رنج باشه تا نتیجه بهتری بده
جلوتر که بریم دقیق تر متوجه میشوید که چرا باید Feature Scaling انجام بدیم .
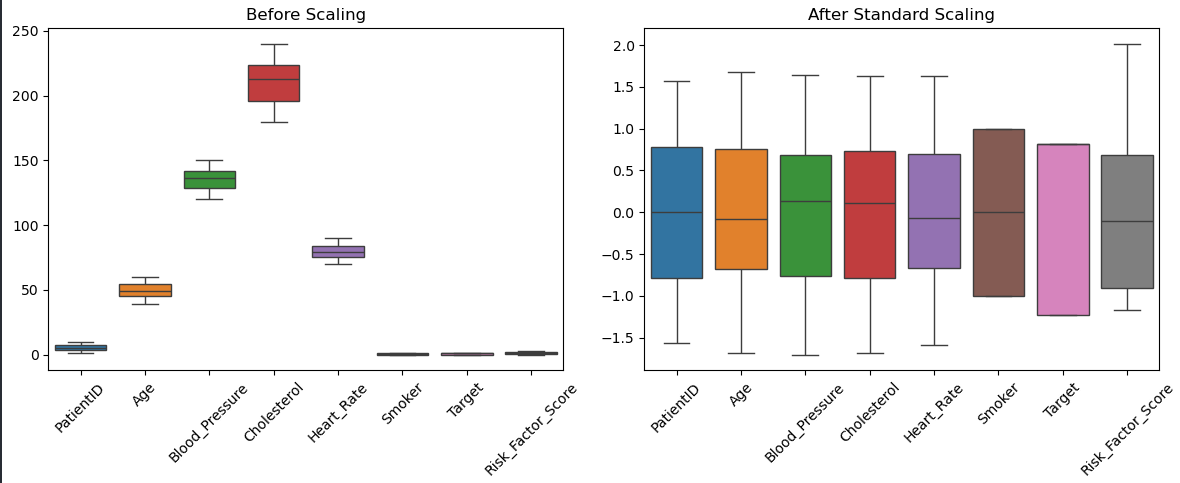
همانطور که در تصویر بالا مشاهده میکنید توزیع داده ها به شکلی که سمت راست تصویر موجوده برای مدل های ماشین لرنینگ مطلوب تره .
پس توی ذهنتون بدونید که شکل توزیع داده ها قبل و بعد از Feature Scaling چقدر متفاوته .
برای انجام Feature Scaling تمام مراحل قبلی Data Preprocessingتون رو کامل کرده باشین و ستون های عددیتون رو انتخاب کرده باشین :
numeric_cols = df.select_dtypes(include=["int64", "float64"]).columns
حالا باید بر اساس الگوریتمی که میخواید ازش استفاده کنید (که در پست های بعدی در موردشون صحبت خواهیم کرد) داده هاتون رو مقایس پذیر کنید .
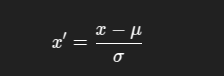
scaler = StandardScaler() scaled_array = scaler.fit_transform(df[numeric_cols]) scaled_df = pd.DataFrame(scaled_array, columns=numeric_cols)
کجا استفاده میشه ؟
الگوریتمهایی که از فرض نرمالبودن داده استفاده میکنن مثل:
Logistic Regression
Linear Regression
SVM
Neural Networks
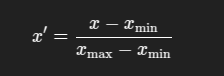
`from sklearn.preprocessing import RobustScaler scaler = RobustScaler() X_scaled = scaler.fit_transform(X)
کی استفاده کنیم؟
وقتی دادهها پراکندگی خاصی ندارن
KNN
Neural Networks (در خیلی از موارد)
PCA (برای بهتر شدن عملکرد کاهش ابعاد)
۳-نرمال سازی سطری (Normalizer)
from sklearn.preprocessing import Normalizer scaler = Normalizer() X_scaled = scaler.fit_transform(X)
هر نمونه (ردیف) رو طوری تغییر میده که طولش (norm) برابر با 1 بشه
کی استفاده کنیم؟
در مسائل بازیابی اطلاعات (IR) یا پردازش متن مثل TF-IDF یا Word Embedding
وقتی بردارها باید نرمال شده باشن

این قسمت هم تموم شد , در قسمت بعدی به آخرین مرحله پیش پردازش داده ها (Data Preprocessing) میرسیم و بعد از اون میریم سراغ مدل های مختلف , Classification , Clustering و سایر ماجرا ...