پرده اول (بهوقت اشتغال ذهنی)
ساعت اندکی از ده شب گذشته بود و من طبق معمول توییتر (x) را به آرامی اسکرول میکردم. زیر یک پست نسبتا ترند شده که در مورد حوادث اخیر روشنگری میکرد کامنتهای زیادی ردوبدل شده بود. عدهای هم برای بیان نظرشون از ایموجیهای لبخند، آتش و چیزهای دیگه استفاده کرده بودند. فضای جالبی بود و انبوهی از احساسات دیده می شد. در همین حین توهین های دسته از مردم که طبق روال عادت شروع کرده بودند به فحشدادن و تمسخرکردن توجهم رو جلب کرد.
اندکی درنگ کردم، این فکر از ذهنم گذشت که ما با شرایطی پیچیدهتر از مواجه صرف با چند تا کامنت منفی روبهرو هستیم و شاید نشت کاربران و ترک پلتفرم هم باید در این مسیر چیزی باشه که کمتر دیده شده است. همان لحظه یک سؤال ساده توی ذهنم شکل گرفت:
با تداوم این فحش ها و کدام نوعشون، دقیقاً چقدر به پلتفرم ضرر میزند؟
پرده دوم (مواجه با کامنتها)
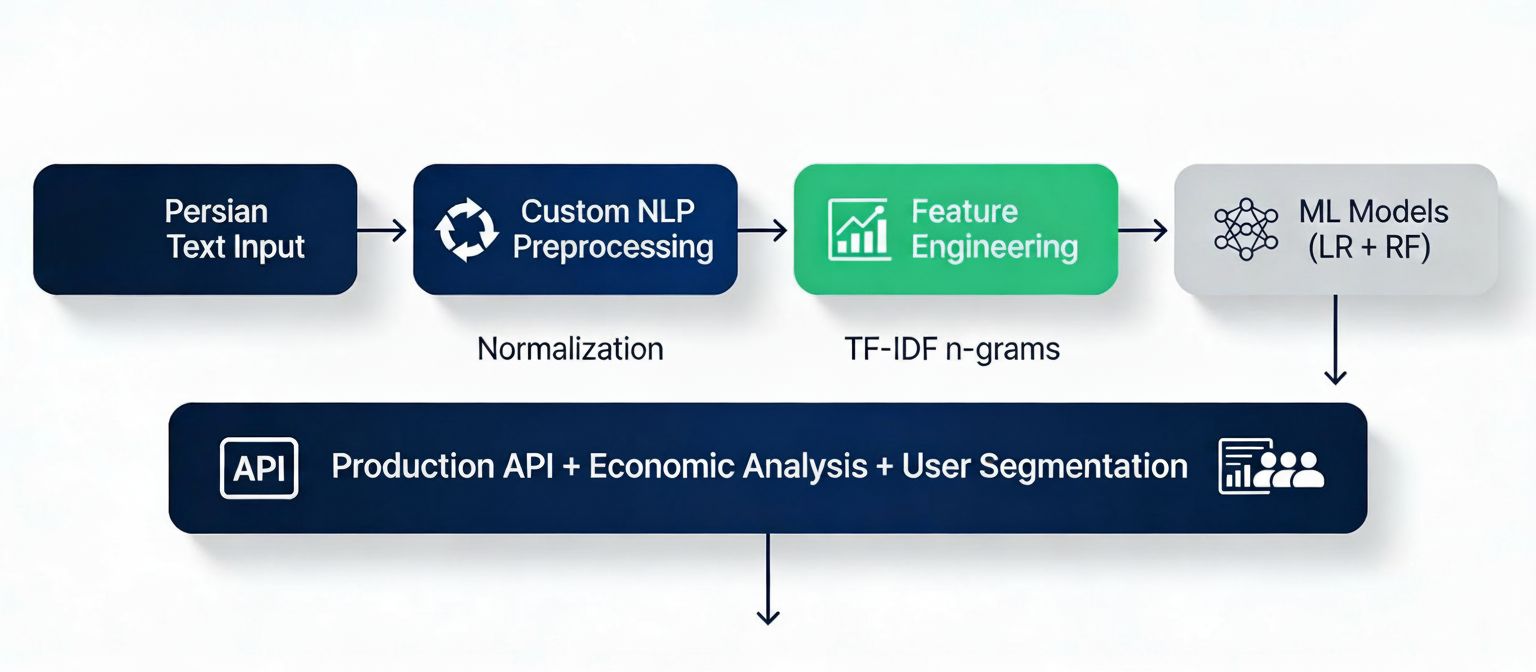
فردا صبح اول وقت بعد از اینکه کارهام کمی مرتب شد، شروع کردم به جستجوکردن در مورد نظریه ها در مورد تاثیر کامنت ها بر مردم و مدیریت نظرات و کامنتها در سوشالمدیا و بارها دیتابیسهای مختلف رو زیرورو کردم. با کمی جستجو یک دیتاست هشت هزارتایی کامنتهای فارسی در توییتر (x) به سال 2025 رو فراهم کردم. تو برآوردهای اولیه فهمیدم که حدود 61.8 درصد کامنتها خنثی و 38.2 درصد توهینآمیز هستند و این یعنی از هر سه جمله یکیاش توهینآمیز بودند. کامنتها رو با کمک فراوانی اصطلاح و فراوانی معکوس (TF‑IDF ) به عدد تبدیل کردم. حدود 500 هزار ویژگی تشخیص دادم از ایموجی تا فحش عریان و ترکیبهایی خلاقانهتر که به من کمک میکرد مدلی بسازم که بتونم توهینها رو تشخیص بدم و اینکه هزینه عدم مدیریت این کامنتها برای پلتفرم چقدر است؟.
تا اینجا دادهها مهیا شد، و حالا میرسیم به بخش هیجانانگیز: مدلسازی!
پرده سوم (مدلسازی)
الان دیگه تقریبا ابزار کارم فراهم شده بود و کار با داده ها رو پی گرفتم. پس از لیبلگذاری سعی کردم از لجستیک رگرسیون، درخت تصمیم و ترکیبش با فراوانی اصطلاح بهره بردم. نتایج شبیه یک مسابقةی دوی ۱۰۰ متر بود که رقیب های مختلف با سرعت سعی داشتند گوی سبقت رو بربایند.
LR_Text با دقت ۸۵.۸٪، F1‑macro برابر ۰.۸۴۲ و F1 کلاس توهینآمیز حدود ۰.۷۹۱ بهترین عملکرد را داشت.
منحنی ROC‑AUC آن ۰.۹۱۷ شد؛ یعنی نزدیک به وضعیت ایدئال در تفکیک توهین/ غیر توهین.
Brier score حدود ۰.۱۱۱۳ بود؛ یعنی احتمالهایی که مدل میدهد، نسبتاً با واقعیت منطبق است.
جالبتر اینکه این مدل برنده، فوقالعاده سبک بود: یک مدل خطی که روی یک سرور معمولی با scikit‑learn اجرا میشود و میتواند در چند میلیثانیه جواب بدهد. برای اینکه مطمئن شوم مدل فقط روی عددها خوب نیست، چند جملة واقعی را تست کردم:
این پست خیلی احمقانه است! → توهینآمیز با احتمال حدود ۶۴٪.
ممنون از اطلاعات مفید → خنثی با احتمال پایین توهین، حدود ۱۴٪.
تو واقعاً بیسواد هستی احمق → توهینآمیز؛ مدل تقریباً ۸۵٪ مطمئن بود.
عالی بود، دستت درد نکند → خنثی، حدود ۱۲٪ احتمال توهین.
تو این مرحله مدل، گوشش به توهین های فارسی عادت کرده بود.
پرده چهارم: (خطای مدل)
از اونجا که هیچ مدلی معصوم نیست و برای همین رفتم سراغ خطایابی مدل و ۴۷ کامنت بودند که مدل بهاشتباه توهینآمیز درکشون کرده بود، مثل:
• «تو هم زیرورو میکشی»
• «یه بینزاکت تمام»
اینها مرزیاند: لحن تند، شوخی خشن، یا طعنه. اگر مدل روی اینها سختگیر باشد، نهایتاً چند کامنت خاکستری میرود برای بررسی دستی.
• در مقابل، ۱۹۲ کامنت را داشتیم که واقعاً توهینآمیز بودند، ولی مدل نتوانسته بود تشخیص دهد مثل:
• «متنفرم ازت مطلق»
• «خیلی پرو ان والا خجالتم نمیکشن اشغال ها…»
• «بهزودی لحظه افتخارکردن به خودت تموم میشه نجاست»
برای یک پلتفرم، این دستة دوم خطرناکتر است. پس مسئله شد انتخاب یک آستانهای که این دو نوع خطا را متعادل کند. بعد از بررسی، threshold =0.5 نقطهای بود که به نظرم بهترین trade off را میداد: حساس نسبتاً بالا به توهین، بدون اینکه خطا ها کنترلناپذیر شوند.
پرده پنجم (هر فحش چقدر می ارزه؟)
تصمیم گرفتیم چند فرض ساده ولی بیرحمانه داشته باشیم:
هر کاربر فعال در ماه، به طور متوسط ۱۰۰,۰۰۰ تومان برای پلتفرم ارزش داره و خب از هر ۱۰۰ کامنت توهینآمیز دیدهشده، تقریباً ۲ کاربر خوب تصمیم میگیرند «بس است» و میروند.
با این مفروضات، ناگهان هر پیام «بیادبانه» تبدیل شد به یک ردیف در اکسل با ستون «تومان». دیگر بحث «اخلاق» تنها نبود؛ بحث «زیان ماهانه» هم وسط بود. حالا وقت آن بود که مدل را روی سناریوهای اقتصادی هزینه–فایده بنشانیم. اگر اصلاً مدل نداشته باشیم:
در نمونه ما، ۶۴۴ کامنت توهینآمیز در ماه دیده میشود. با مفروضات بالا، این برابر است با حدود ۱,۲۸۸,۰۰۰ تومان زیان ماهانه؛ صرفاً بهخاطر کاربرانی که با دیدن این فضا تصمیم میگیرند که من دیگه به این فضا بر نمی گردم.
پرداه ششم: (زوم اوت روی آدمها)
کنجکاو بودم که بدونم پشت این اعداد چه تیپ کاربرانی پنهان شدهاند. برای همین، از دل دادهها ویژگیهای رفتاری بیرون کشیدم (طول کامنت، احتمال توهین، الگوهای نوشتن) و روی آنها خوشهبندی انجام دادم. نتیجه سه سگمنت جدی بود:
سگمنت ۰ - «منتقدهای مؤدب» (حدود ۲۴.۸٪)
میانگین طول کامنتها ۱۱۰ کاراکتر، نرخ توهین ۲۹.۲٪. اینها همانهاییاند که اگر از محصول ناراضی باشند، چندین پاراگراف نقد مینویسند؛ نه اینکه فحش بدهند و بروند. این گروه شایستهی امکانات VIP است: جواب گرفتن، دعوت به بنای امکانات جدید.
سگمنت ۱ - «واکنشیها» (حدود ۷۴.۱٪)
کوتاهنویس، سریع و پرریسک؛ میانگین طول ۲۷ کاراکتر و نرخ توهین ۴۱.۵٪. اینها همانهاییاند که زیر هر خبر یا پست جنجالی، اولین فحشها را مینویسند. سیستم moderation باید بیشترین انرژیاش را روی این گروه خرج کند؛ از فیلتر تا محدودیت موقت ارسال کامنت.
سگمنت ۲ - «هستة آرام» (حدود ۱.۱٪)
گروه کوچک، کامنتهای متوسططول (۵۴ کاراکتر)، نرخ توهین ۱۵.۱٪. شاید تعدادشان کم باشد، اما میتوانند بهترین منبع بازخورد برای طراحی قوانین و تجربة کاربری سالم باشند.
بهاینترتیب، مدل توهین تنها یک ابزار فیلتر نبود؛ تبدیل شده بود به لنزی برای دیدن جامعة کوچک داخل پلتفرم.
قسمت آخر: از الگوریتم تا حکمرانی گفتگو
نتیجة این پروژه برای من یک درس مهم داشت: اگر با «گفتگوهای آنلاین» مثل یک سیستم اجتماعی–اقتصادی رفتار کنیم، حتی یک لجستیک رگرسیون ساده هم میتواند ابزار حکمرانی باشد و می تواند کمک کند تصمیم بگیریم کجا سخت گیر باشیم و کجا فرصت دهیم و اینکه سیاست های ما چه خروجی خواهد داشت و مدیریت توهینها نه فقط ارزش اخلاقی دارد بلکه از لحاظ اقتصادی و اجتماعی نیز واجد اهمیت است.
این مدل در حال حاضر بر روی گیت هاب بارگذاری شده و در پایین لینکش قرار داده شده است. اگر شما هم تجربهای از مواجهه با کامنتهای توهینآمیز دارید – چه بهعنوان کاربر، چه بهعنوان مدیر محصول – خوشحال میشوم در کامنتها تعریف کنید. شاید همین داستانهای کوچک، دیتاست پروژه بعدی باشد.
لینک بررسی : https://github.com/sajadvahabi1996/persian-offense-detector